Posts in Apr, 2023
Filters: Year: 2023 × Month: Apr × Sorted by date
MRSK. A new open source web application deployment tool from 37signals, developed to help migrate their Hey webmail app out of the cloud and onto their own managed hardware. The key feature is one that I care about deeply: it enables zero-downtime deploys by running all traffic through a Traefik reverse proxy in a way that allows requests to be paused while a new deployment is going out—so end users get a few seconds delay on their HTTP requests before being served by the replaced application.
Enriching data with GPT3.5 and SQLite SQL functions
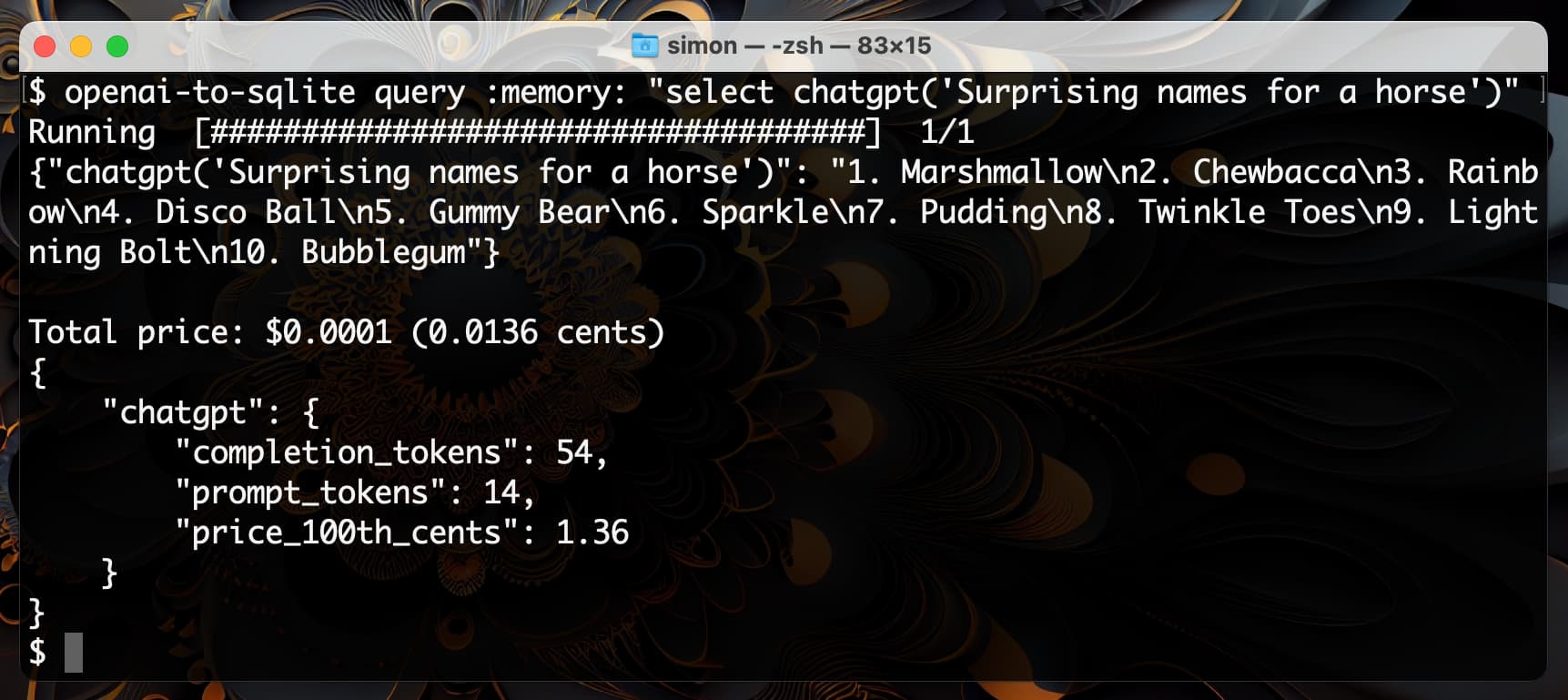
I shipped openai-to-sqlite 0.3 yesterday with a fun new feature: you can now use the command-line tool to enrich data in a SQLite database by running values through an OpenAI model and saving the results, all in a single SQL query.
[... 1,219 words]MLC LLM (via) From MLC, the team that gave us Web LLM and Web Stable Diffusion. “MLC LLM is a universal solution that allows any language model to be deployed natively on a diverse set of hardware backends and native applications”. I installed their iPhone demo from TestFlight this morning and it does indeed provide an offline LLM that runs on my phone. It’s reasonably capable—the underlying model for the app is vicuna-v1-7b, a LLaMA derivative.
IF by DeepFloyd Lab (via) New image generation AI model, financially backed by StabilityAI but based on the Google Imagen paper. Claims to be much better at following complex prompts, including being able to generate text! I tried the Colab notebook with “a photograph of raccoon in the woods holding a sign that says ’I will eat your trash’” and it didn’t quite get the text right, see via link for the result.
Trainbot (via) “Trainbot watches a piece of train track, detects passing trains, and stitches together images of them”—check out the site itself too, which shows beautifully stitched panoramas of trains that have recently passed near Jo M’s apartment. Found via the best Hacker News thread I’ve seen in years, “Ask HN: Most interesting tech you built for just yourself?”.
GPT-3 token encoder and decoder. I built an Observable notebook with an interface to encode, decode and search through GPT-3 tokens, building on top of a notebook by EJ Fox and Ian Johnson.
urllib3 v2.0.0 is now generally available. urllib3 is 12 years old now, and is a common low-level dependency for packages like requests and httpx. The biggest new feature in v2 is a higher-level API: resp = urllib3.request(“GET”, “https://example.com”)—a very welcome addition to the library.
How prompt injection attacks hijack today’s top-end AI – and it’s really tough to fix. Thomas Claburn interviewed me about prompt injection for the Register. Lots of direct quotes from our phone call in here—we went pretty deep into why it’s such a difficult problem to address.
The Consumer Financial Protection Bureau (CFPB) supervises, sets rules for, and enforces numerous federal consumer financial laws and guards consumers in the financial marketplace from unfair, deceptive, or abusive acts or practices and from discrimination [...] the fact that the technology used to make a credit decision is too complex, opaque, or new is not a defense for violating these laws.
The Dual LLM pattern for building AI assistants that can resist prompt injection
I really want an AI assistant: a Large Language Model powered chatbot that can answer questions and perform actions for me based on access to my private data and tools.
[... 2,632 words]Rye.
Armin Ronacher's take on a Python packaging tool. There are a lot of interesting ideas in this one - it's written in Rust, configured using pyproject.toml and has some very strong opinions, including completely hiding pip from view and insisting you use rye add package instead. Notably, it doesn't use the system Python at all: instead, it downloads a pre-compiled standalone Python from Gregory Szorc's python-build-standalone project - the same approach I used for the Datasette Desktop Electron app.
Armin warns that this is just an exploration, with no guarantees of future maintenance - and even has an issue open titled Should Rye exist?
Introducing PyPI Organizations. Launched at PyCon US today: Organizations allow packages on the Python Package Index to be owned by a group, not an individual user account. “We’re making organizations available to community projects for free, forever, and to corporate projects for a small fee.”—this is the first revenue generating PyPI feature.
Weeknotes: Citus Con, PyCon and three new niche museums
I’ve had a busy week in terms of speaking: on Tuesday I gave an online keynote at Citus Con, “Big Opportunities in Small Data”. I then flew to Salt Lake City for PyCon that evening and gave a three hour workshop on Wednesday, “Data analysis with SQLite and Python”.
[... 225 words]A lot of people who claim to be doing prompt engineering today are actually just blind prompting. "Blind Prompting" is a term I am using to describe the method of creating prompts with a crude trial-and-error approach paired with minimal or no testing and a very surface level knowedge of prompting. Blind prompting is not prompt engineering. [...] In this blog post, I will make the argument that prompt engineering is a real skill that can be developed based on real experimental methodologies.
Other tech-friendly journalists I know have been going through something similar: Suddenly, we’ve got something like a jetpack to strap to our work. Sure, the jetpack is kinda buggy. Yes, sometimes it crashes and burns. And the rules for its use aren’t clear, so you’ve got to be super careful with it. But sometimes it soars, shrinking tasks that would have taken hours down to mere minutes, sometimes minutes to seconds.
The AI Writing thing is just pivot to video all over again, a bunch of dead-eyed corporate types willing to listen to any snake oil salesman who offers them higher potential profits. It'll crash in a year but scuttle hundreds of livelihoods before it does.
Bard now helps you code (via) Google have enabled Bard’s code generation abilities—these were previously only available through jailbreaking. It’s pretty good—I got it to write me code to download a CSV file and insert it into a SQLite database—though when I challenged it to protect against SQL injection it hallucinated a non-existent “cursor.prepare()” method. Generated code can be exported to a Colab notebook with a click.
Data analysis with SQLite and Python for PyCon 2023
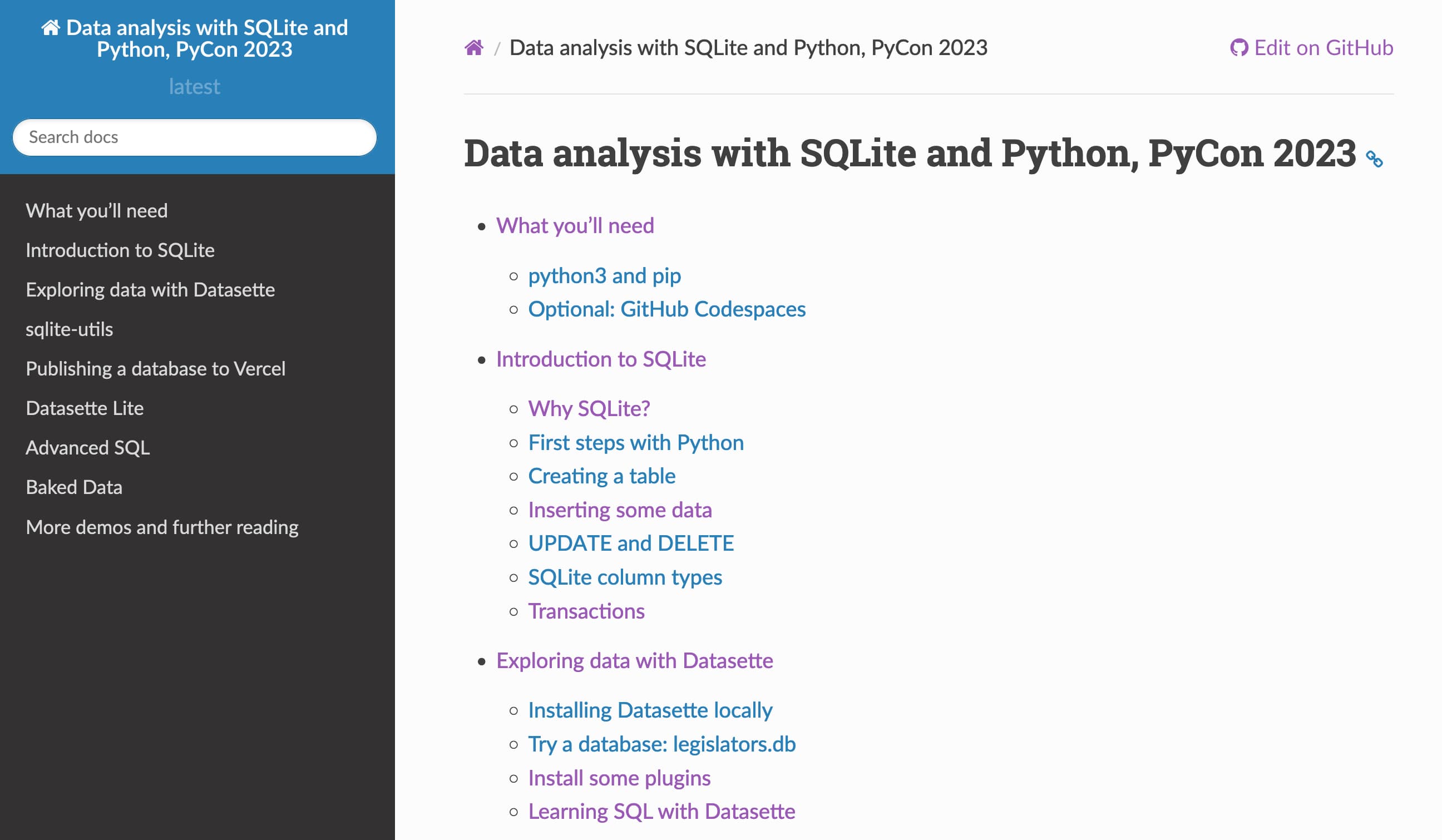
I’m at PyCon 2023 in Salt Lake City this week.
[... 347 words]Stability AI Launches the First of its StableLM Suite of Language Models (via) 3B and 7B base models, with 15B and 30B are on the way. CC BY-SA-4.0. “StableLM is trained on a new experimental dataset built on The Pile, but three times larger with 1.5 trillion tokens of content. We will release details on the dataset in due course.”
Inside the secret list of websites that make AI chatbots sound smart. Washington Post story digging into the C4 dataset—Colossal Clean Crawled Corpus, a filtered version of Common Crawl that’s often used for training large language models. They include a neat interactive tool for searching a domain to see if it’s included—TIL that simonwillison.net is the 106,649th ranked site in C4 by number of tokens, 189,767 total—0.0001% of the total token volume in C4.
LLaVA: Large Language and Vision Assistant (via) Yet another multi-modal model combining a vision model (pre-trained CLIP ViT-L/14) and a LLaMA derivative model (Vicuna). The results I get from their demo are even more impressive than MiniGPT-4. Also includes a new training dataset, LLaVA-Instruct-150K, derived from GPT-4 and subject to the same warnings about the OpenAI terms of service.
What’s in the RedPajama-Data-1T LLM training set
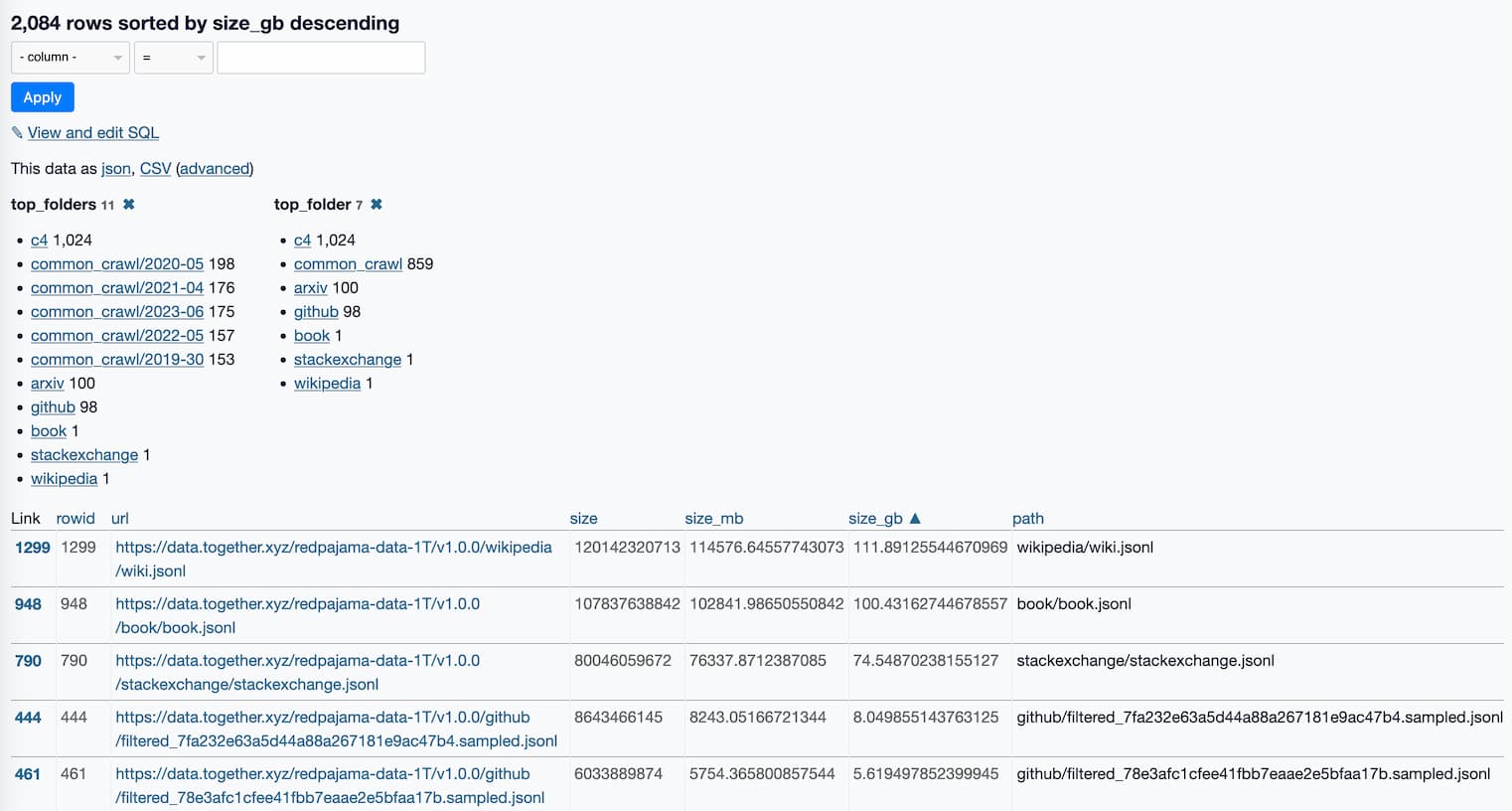
RedPajama is “a project to create leading open-source models, starts by reproducing LLaMA training dataset of over 1.2 trillion tokens”. It’s a collaboration between Together, Ontocord.ai, ETH DS3Lab, Stanford CRFM, Hazy Research, and MILA Québec AI Institute.
[... 1,077 words]RedPajama, a project to create leading open-source models, starts by reproducing LLaMA training dataset of over 1.2 trillion tokens. With the amount of projects that have used LLaMA as a foundation model since its release two months ago—despite its non-commercial license—it’s clear that there is a strong desire for a fully openly licensed alternative.
RedPajama is a collaboration between Together, Ontocord.ai, ETH DS3Lab, Stanford CRFM, Hazy Research, and MILA Québec AI Institute aiming to build exactly that.
Step one is gathering the training data: the LLaMA paper described a 1.2 trillion token training set gathered from sources that included Wikipedia, Common Crawl, GitHub, arXiv, Stack Exchange and more.
RedPajama-Data-1T is an attempt at recreating that training set. It’s now available to download, as 2,084 separate multi-GB jsonl files—2.67TB total.
Even without a trained model, this is a hugely influential contribution to the world of open source LLMs. Any team looking to build their own LLaMA from scratch can now jump straight to the next stage, training the model.
Latest Twitter search results for “as an AI language model” (via) Searching for “as an AI language model” on Twitter reveals hundreds of bot accounts which are clearly being driven by GPT models and have been asked to generate content which occasionally trips the ethical guidelines trained into the OpenAI models.
If Twitter still had an affordable search API someone could do some incredible disinformation research on top of this, looking at which accounts are implicated, what kinds of things they are tweeting about, who they follow and retweet and so-on.
MiniGPT-4 (via) An incredible project with a poorly chosen name. A team from King Abdullah University of Science and Technology in Saudi Arabia combined Vicuna-13B (a model fine-tuned on top of Facebook’s LLaMA) with the BLIP-2 vision-language model to create a model that can conduct ChatGPT-style conversations around an uploaded image. The demo is very impressive, and the weights are available to download—45MB for MiniGPT-4, but you’ll need the much larger Vicuna and LLaMA weights as well.
How I Used Stable Diffusion and Dreambooth to Create A Painted Portrait of My Dog (via) I like posts like this that go into detail in terms of how much work it takes to deliberately get the kind of result you really want using generative AI tools. Jake Dahn trained a Dreambooth model from 40 photos of Queso—his photogenic Golden Retriever—using Replicate, then gathered the prompts from ten images he liked on Lexica and generated over 1,000 different candidate images, picked his favourite, used Draw Things img2img resizing to expand the image beyond the initial crop, then Automatic1111 inpainting to tweak the ears, then Real-ESRGAN 4x+ to upscale for the final print.
Web LLM runs the vicuna-7b Large Language Model entirely in your browser, and it’s very impressive

A month ago I asked Could you train a ChatGPT-beating model for $85,000 and run it in a browser?. $85,000 was a hypothetical training cost for LLaMA 7B plus Stanford Alpaca. “Run it in a browser” was based on the fact that Web Stable Diffusion runs a 1.9GB Stable Diffusion model in a browser, so maybe it’s not such a big leap to run a small Large Language Model there as well.
[... 2,276 words]sqlite-history: tracking changes to SQLite tables using triggers (also weeknotes)
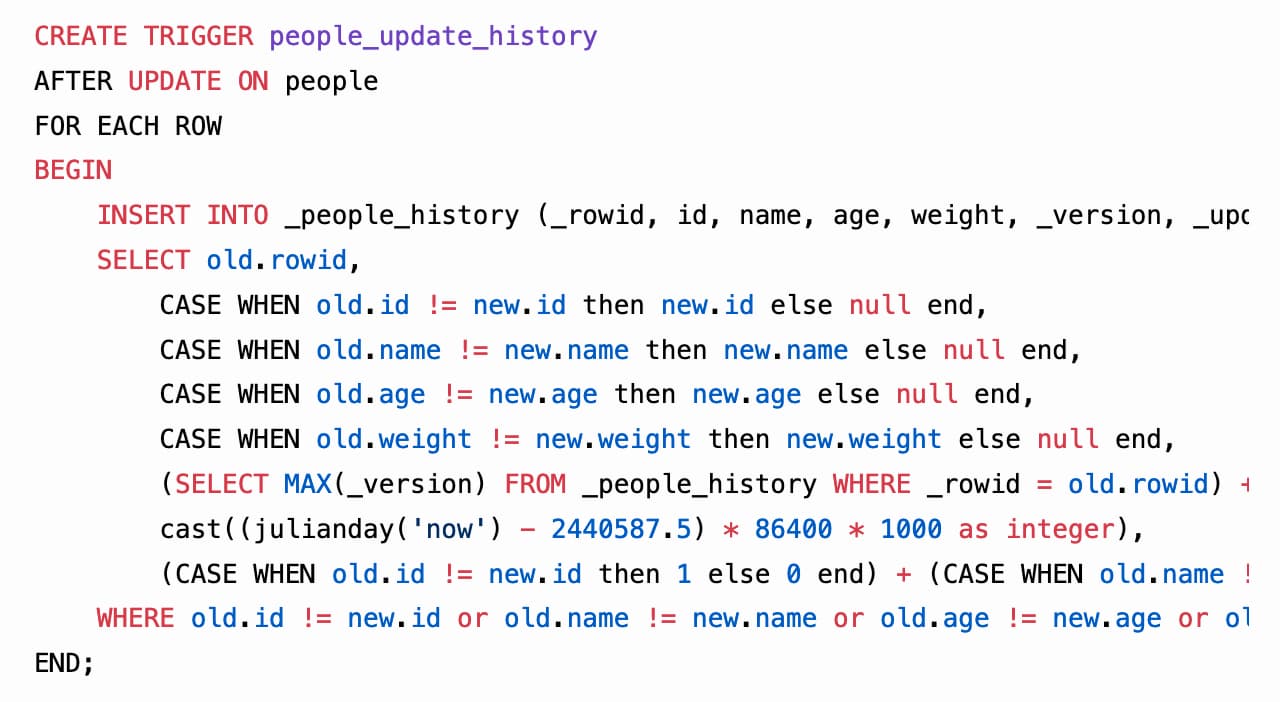
In between blogging about ChatGPT rhetoric, micro-benchmarking with ChatGPT Code Interpreter and Why prompt injection is an even bigger problem now I managed to ship the beginnings of a new project: sqlite-history.
[... 1,680 words]Although fine-tuning can feel like the more natural option—training on data is how GPT learned all of its other knowledge, after all—we generally do not recommend it as a way to teach the model knowledge. Fine-tuning is better suited to teaching specialized tasks or styles, and is less reliable for factual recall. [...] In contrast, message inputs are like short-term memory. When you insert knowledge into a message, it's like taking an exam with open notes. With notes in hand, the model is more likely to arrive at correct answers.
— Ted Sanders, OpenAI
codespaces-jupyter (via) This is really neat. Click “Use this template” -> “Open in a codespace” and you get a full in-browser VS Code interface where you can open existing notebook files (or create new ones) and start playing with them straight away.