473 posts tagged “sqlite”
SQLite is the world's most widely deployed database engine.
2026
sqlite-utils 4.0rc1 adds migrations and nested transactions
sqlite-utils is my combined Python library and CLI tool for working with SQLite databases. It provides an extensive set of higher-level operations on top of Python’s default sqlite3 package, including support for complex table transformations, automatic table creation from JSON data and a whole lot more.
[... 975 words]It would be neat if arbitrary SQL queries in Datasette could be rendered with additional information based on which columns from which tables were included in the results.
To build that, we would need to be able to look at a SQL query like select users.name, orders.total from users join orders on orders.user_id = users.id and programmatically identify the table.column for each result - navigating not just joins but also more complex syntax like CTEs.
I decided to set Claude Code (Opus 4.8, since Fable is currently banned by the US government) on the problem. It found several promising solutions - one using apsw, another that uses ctypes to access the SQLite sqlite3_column_table_name() C function (which is not otherwise exposed to Python), and one using clever interrogation of the output of EXPLAIN.
Another significant alpha release, with two new headline features.
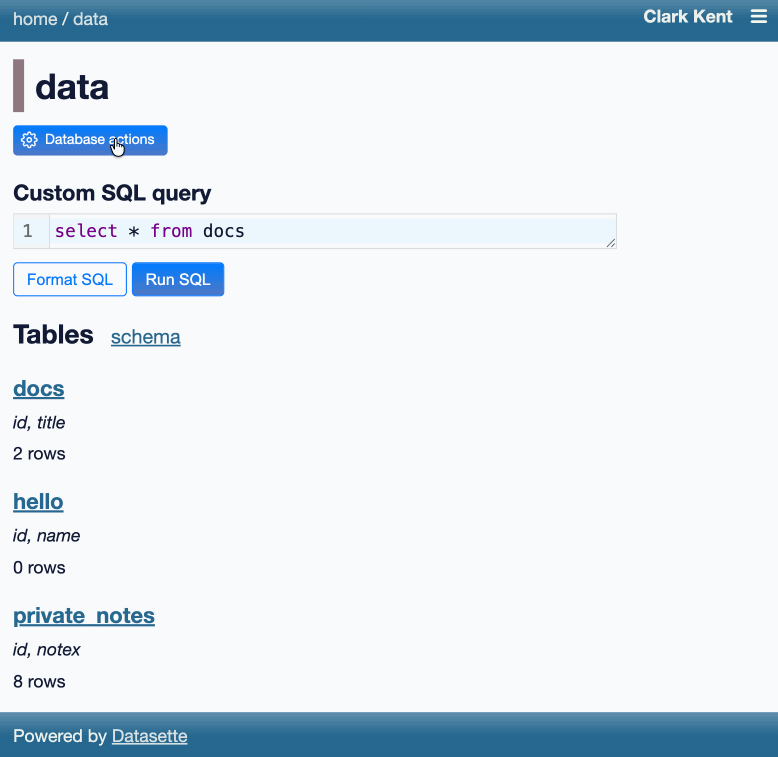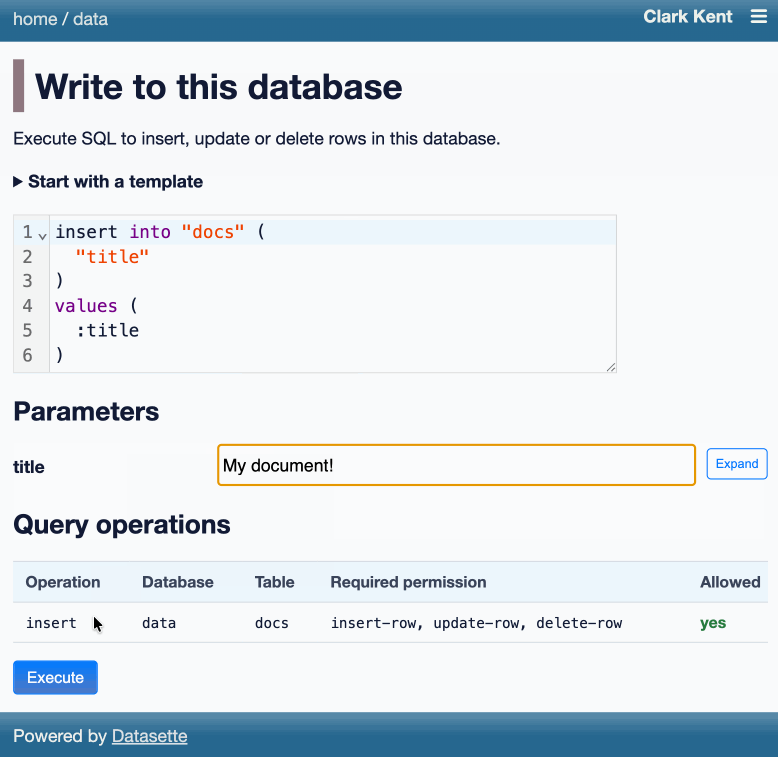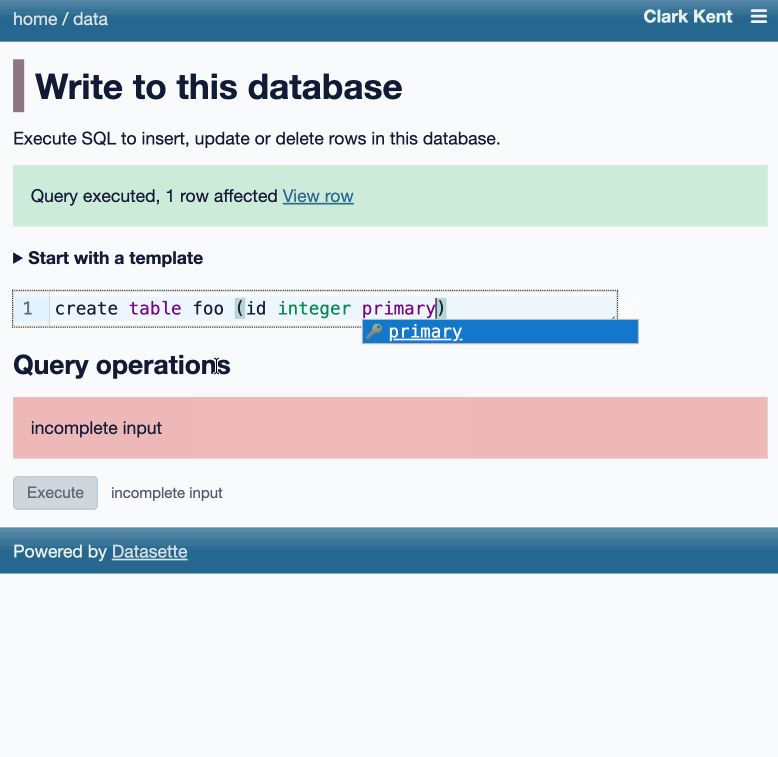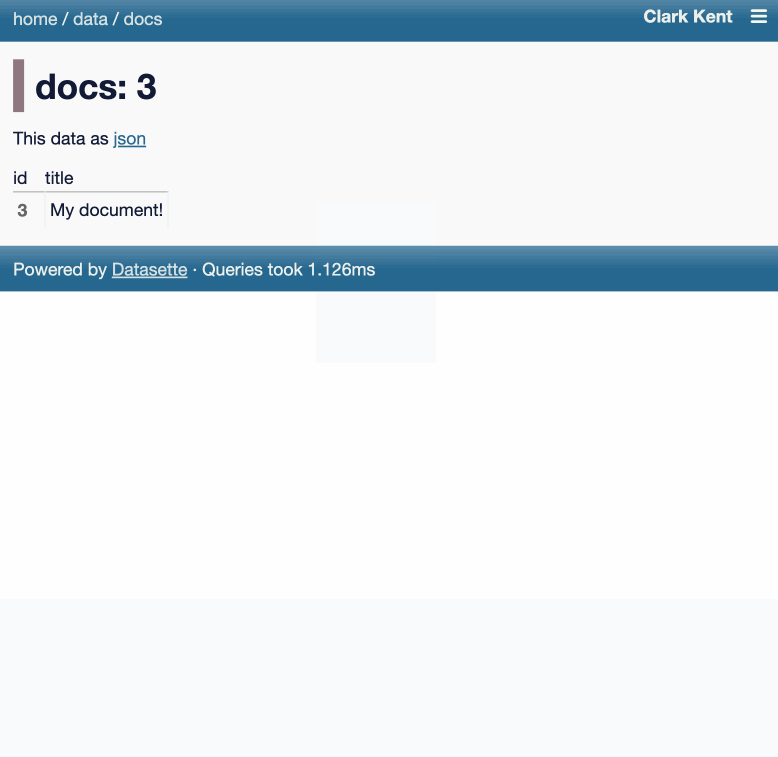
Datasette now offers users with the necessary permissions the ability to both execute write queries against their database and to save stored queries (renamed from "canned queries") both privately and for use by other members of their Datasette instance.
There's more detail in SQL write queries and stored queries in Datasette 1.0a31 on the Datasette blog, which now has three posts introducing new features since the blog launched two weeks ago.
Here's an animated demo from the blog post showing how the new execute query interface lets people get started with templated insert/update/delete queries from tables they have permission to edit:
sqlite AGENTS.md (via) SQLite gained an AGENTS.md file five days ago - but it's not intended for their own development, it's presumably aimed at people who are pointing agents at the SQLite codebase. It includes:
SQLite does not accept pull requests without prior agreement and/or accompanying legal paperwork that places the pull request in the public domain. However, the human SQLite developers will review a concise and well-written pull request as a proof-of-concept prior to reimplementing the changes themselves.
SQLite does not accept agentic code. However the project will accept agentic bug reports that include a reproducible test case. Patches or pull requests demonstrating a possible fix, for documentation purposes, are welcomed.
The most recent commit to that file removed "(currently)" from "SQLite does not (currently) accept agentic code", with the commit message "Strengthen the statement about not accepting agentic code".
Meanwhile the SQLite forum was being flooded with so many AI-generated bug reports - of varying quality - that they've now split those off into a new SQLite Bug Forum. D. Richard Hipp is resolving issues on there with a flurry of commits to the codebase.
Datasette Agent
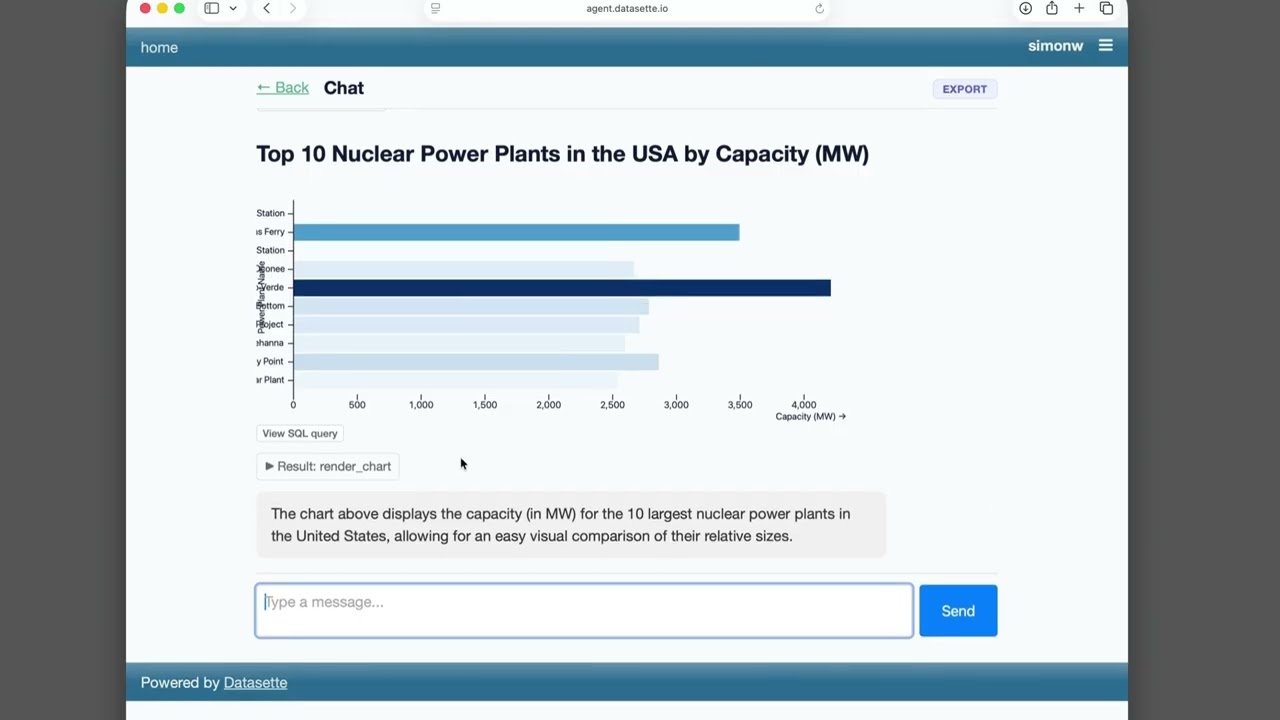
We just announced the first release of Datasette Agent, a new extensible AI assistant for Datasette. I’ve been working on my LLM Python library for just over three years now, and Datasette Agent represents the moment that LLM and Datasette finally come together. I’m really excited about it!
[... 659 words]One could say in the first quarter-century of my life, that while I was always fascinated by programming, I could never overcome the guilt of not really knowing whether the tool I am building right now isn’t already superceded by some much better implementation someone else has already written 30 or 40 years ago; I could write a TSV-aware search and replace, or I could find out about
awkand solve that entire class of problems in one fell swoop, for example. My central conceit is that this is a trap. You need to reinvent a couple of wheels to get to the edge of what we know about wheel-making, not a thousand wheels, and not zero; probably four or five is sufficient in most domains, maybe closer to twenty or thirty in the most epistemically rigorous and developed fields like mathematics or computer science. Each wheel you reinvent, and every directed question you ask along the way, will propel you faster to the true frontier than that same amount of time spend in idle study, or even five times that amount.
— Andrew Quinn, footnote on Replacing a 3 GB SQLite database with a 10 MB FST (finite state transducer) binary
russellromney/honker (via) "Postgres NOTIFY/LISTEN semantics" for SQLite, implemented as a Rust SQLite extension and various language bindings to help make use of it.
The design of this looks very solid. It lets you write Python code for queues that looks like this:
import honker db = honker.open("app.db") emails = db.queue("emails") emails.enqueue({"to": "alice@example.com"}) # Consume (in a worker process) async for job in emails.claim("worker-1"): send(job.payload) job.ack()
And Kafka-style durable streams like this:
stream = db.stream("user-events") with db.transaction() as tx: tx.execute("UPDATE users SET name=? WHERE id=?", [name, uid]) stream.publish({"user_id": uid, "change": "name"}, tx=tx) async for event in stream.subscribe(consumer="dashboard"): await push_to_browser(event)
It also adds 20+ custom SQL functions including these two:
SELECT notify('orders', '{"id":42}');
SELECT honker_stream_read_since('orders', 0, 1000);The extension requires WAL mode, and workers can poll the .db-wal file with a stat call every 1ms to get as close to real-time as possible without the expense of running a full SQL query.
honker implements the transactional outbox pattern, which ensures items are only queued if a transaction successfully commits. My favorite explanation of that pattern remains Transactionally Staged Job Drains in Postgres by Brandur Leach. It's great to see a new implementation of that pattern for SQLite.
Serving the For You feed. One of Bluesky's most interesting features is that anyone can run their own custom "feed" implementation and make it available to other users - effectively enabling custom algorithms that can use any mechanism they like to recommend posts.
spacecowboy runs the For You Feed, used by around 72,000 people. This guest post on the AT Protocol blog explains how it works.
The architecture is fascinating. The feed is served by a single Go process using SQLite on a "gaming" PC in spacecowboy's living room - 16 cores, 96GB of RAM and 4TB of attached NVMe storage.
Recommendations are based on likes: what else are the people who like the same things as you liking on the platform?
That Go server consumes the Bluesky firehose and stores the relevant details in SQLite, keeping the last 90 days of relevant data, which currently uses around 419GB of SQLite storage.
Public internet traffic is handled by a $7/month VPS on OVH, which talks to the living room server via Tailscale.
Total cost is now $30/month: $20 in electricity, $7 in VPS and $3 for the two domain names. spacecowboy estimates that the existing system could handle all ~1 million daily active Bluesky users if they were to switch to the cheapest algorithm they have found to work.
SQLite 3.53.0 (via) SQLite 3.52.0 was withdrawn so this is a pretty big release with a whole lot of accumulated user-facing and internal improvements. Some that stood out to me:
ALTER TABLEcan now add and removeNOT NULLandCHECKconstraints - I've previously used my own sqlite-utils transform() method for this.- New json_array_insert() function and its
jsonbequivalent. - Significant improvements to CLI mode, including result formatting.
The result formatting improvements come from a new library, the Query Results Formatter. I had Claude Code (on my phone) compile that to WebAssembly and build this playground interface for trying that out.
See my notes on SQLite 3.53.0. This playground provides a UI for trying out the various rendering options for SQL result tables from the new Query Result Formatter library, compiled to WebAssembly.
Inspired by this conversation on Hacker News about whether two SQLite processes in separate Docker containers that share the same volume might run into problems due to WAL shared memory. The answer is that everything works fine - Docker containers on the same host and filesystem share the same shared memory in a way that allows WAL to collaborate as it should.
Eight years of wanting, three months of building with AI (via) Lalit Maganti provides one of my favorite pieces of long-form writing on agentic engineering I've seen in ages.
They spent eight years thinking about and then three months building syntaqlite, which they describe as "high-fidelity devtools that SQLite deserves".
The goal was to provide fast, robust and comprehensive linting and verifying tools for SQLite, suitable for use in language servers and other development tools - a parser, formatter, and verifier for SQLite queries. I've found myself wanting this kind of thing in the past myself, hence my (far less production-ready) sqlite-ast project from a few months ago.
Lalit had been procrastinating on this project for years, because of the inevitable tedium of needing to work through 400+ grammar rules to help build a parser. That's exactly the kind of tedious work that coding agents excel at!
Claude Code helped get over that initial hump and build the first prototype:
AI basically let me put aside all my doubts on technical calls, my uncertainty of building the right thing and my reluctance to get started by giving me very concrete problems to work on. Instead of “I need to understand how SQLite’s parsing works”, it was “I need to get AI to suggest an approach for me so I can tear it up and build something better". I work so much better with concrete prototypes to play with and code to look at than endlessly thinking about designs in my head, and AI lets me get to that point at a pace I could not have dreamed about before. Once I took the first step, every step after that was so much easier.
That first vibe-coded prototype worked great as a proof of concept, but they eventually made the decision to throw it away and start again from scratch. AI worked great for the low level details but did not produce a coherent high-level architecture:
I found that AI made me procrastinate on key design decisions. Because refactoring was cheap, I could always say “I’ll deal with this later.” And because AI could refactor at the same industrial scale it generated code, the cost of deferring felt low. But it wasn’t: deferring decisions corroded my ability to think clearly because the codebase stayed confusing in the meantime.
The second attempt took a lot longer and involved a great deal more human-in-the-loop decision making, but the result is a robust library that can stand the test of time.
It's worth setting aside some time to read this whole thing - it's full of non-obvious downsides to working heavily with AI, as well as a detailed explanation of how they overcame those hurdles.
The key idea I took away from this concerns AI's weakness in terms of design and architecture:
When I was working on something where I didn’t even know what I wanted, AI was somewhere between unhelpful and harmful. The architecture of the project was the clearest case: I spent weeks in the early days following AI down dead ends, exploring designs that felt productive in the moment but collapsed under scrutiny. In hindsight, I have to wonder if it would have been faster just thinking it through without AI in the loop at all.
But expertise alone isn’t enough. Even when I understood a problem deeply, AI still struggled if the task had no objectively checkable answer. Implementation has a right answer, at least at a local level: the code compiles, the tests pass, the output matches what you asked for. Design doesn’t. We’re still arguing about OOP decades after it first took off.
Lalit Maganti's syntaqlite is currently being discussed on Hacker News thanks to Eight years of wanting, three months of building with AI, a deep dive into how it was built.
This inspired me to revisit a research project I ran when Lalit first released it a couple of weeks ago, where I tried it out and then compiled it to a WebAssembly wheel so it could run in Pyodide in a browser (the library itself uses C and Rust).
This new playground loads up the Python library and provides a UI for trying out its different features: formating, parsing into an AST, validating, and tokenizing SQLite SQL queries.
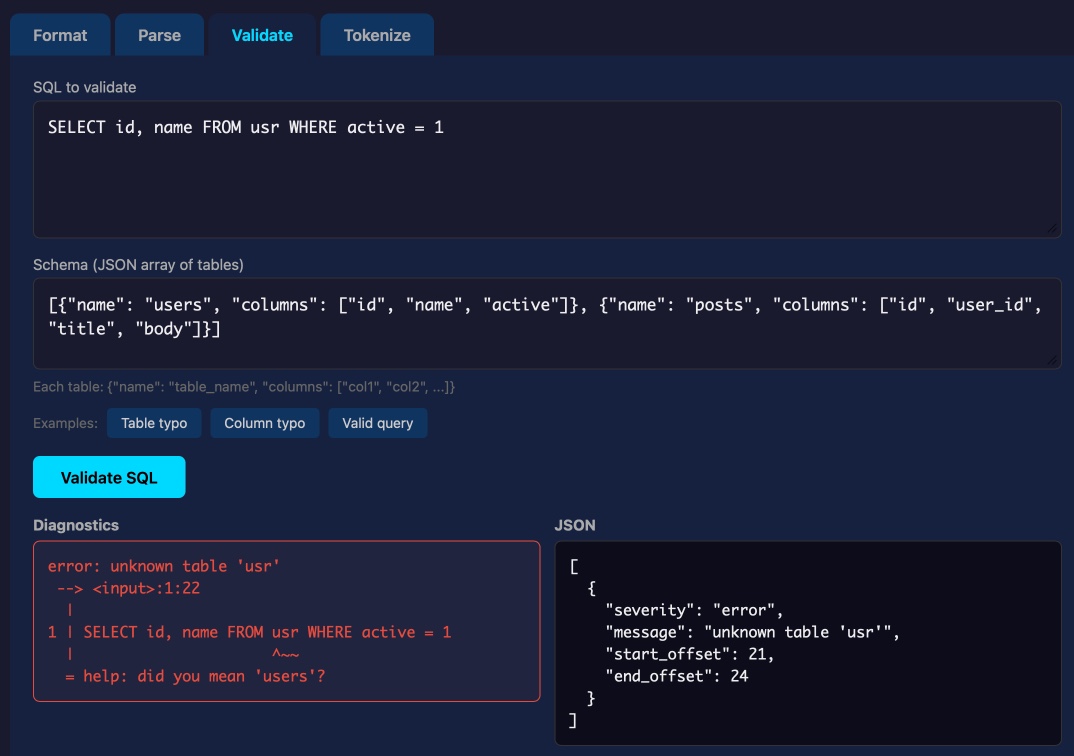
Update: not sure how I missed this but syntaqlite has its own WebAssembly playground linked to from the README.
I had Claude Code run a micro-benchmark comparing different approaches to implementing tagging in SQLite. Traditional many-to-many tables won, but FTS5 came a close second. Full table scans with LIKE queries performed better than I expected, but full table scans with JSON arrays and json_each() were much slower.
Coding agents for data analysis. Here's the handout I prepared for my NICAR 2026 workshop "Coding agents for data analysis" - a three hour session aimed at data journalists demonstrating ways that tools like Claude Code and OpenAI Codex can be used to explore, analyze and clean data.
Here's the table of contents:
I ran the workshop using GitHub Codespaces and OpenAI Codex, since it was easy (and inexpensive) to distribute a budget-restricted API key for Codex that attendees could use during the class. Participants ended up burning $23 of Codex tokens.
The exercises all used Python and SQLite and some of them used Datasette.
One highlight of the workshop was when we started running Datasette such that it served static content from a viz/ folder, then had Claude Code start vibe coding new interactive visualizations directly in that folder. Here's a heat map it created for my trees database using Leaflet and Leaflet.heat, source code here.

I designed the handout to also be useful for people who weren't able to attend the session in person. As is usually the case, material aimed at data journalists is equally applicable to anyone else with data to explore.
Production query plans without production data
(via)
Radim Marek describes the new pg_restore_relation_stats() and pg_restore_attribute_stats() functions that were introduced in PostgreSQL 18 in September 2025.
The PostgreSQL query planner makes use of internal statistics to help it decide how to best execute a query. These statistics often differ between production data and development environments, which means the query plans used in production may not be replicable in development.
PostgreSQL's new features now let you copy those statistics down to your development environment, allowing you to simulate the plans for production workloads without needing to copy in all of that data first.
I found this illustrative example useful:
SELECT pg_restore_attribute_stats(
'schemaname', 'public',
'relname', 'test_orders',
'attname', 'status',
'inherited', false::boolean,
'null_frac', 0.0::real,
'avg_width', 9::integer,
'n_distinct', 5::real,
'most_common_vals', '{delivered,shipped,cancelled,pending,returned}'::text,
'most_common_freqs', '{0.95,0.015,0.015,0.015,0.005}'::real[]
);
This simulates statistics for a status column that is 95% delivered. Based on these statistics PostgreSQL can decide to use an index for status = 'shipped' but to instead perform a full table scan for status = 'delivered'.
These statistics are pretty small. Radim says:
Statistics dumps are tiny. A database with hundreds of tables and thousands of columns produces a statistics dump under 1MB. The production data might be hundreds of GB. The statistics that describe it fit in a text file.
I posted on the SQLite user forum asking if SQLite could offer a similar feature and D. Richard Hipp promptly replied that it has one already:
All of the data statistics used by the query planner in SQLite are available in the sqlite_stat1 table (or also in the sqlite_stat4 table if you happen to have compiled with SQLITE_ENABLE_STAT4). That table is writable. You can inject whatever alternative statistics you like.
This approach to controlling the query planner is mentioned in the documentation: https://sqlite.org/optoverview.html#manual_control_of_query_plans_using_sqlite_stat_tables.
See also https://sqlite.org/lang_analyze.html#fixed_results_of_analyze.
The ".fullschema" command in the CLI outputs both the schema and the content of the sqlite_statN tables, exactly for the reasons outlined above - so that we can reproduce query problems for testing without have to load multi-terabyte database files.
cysqlite—a new sqlite driver
(via)
Charles Leifer has been maintaining pysqlite3 - a fork of the Python standard library's sqlite3 module that makes it much easier to run upgraded SQLite versions - since 2018.
He's been working on a ground-up Cython rewrite called cysqlite for almost as long, but it's finally at a stage where it's ready for people to try out.
The biggest change from the sqlite3 module involves transactions. Charles explains his discomfort with the sqlite3 implementation at length - that library provides two different variants neither of which exactly match the autocommit mechanism in SQLite itself.
I'm particularly excited about the support for custom virtual tables, a feature I'd love to see in sqlite3 itself.
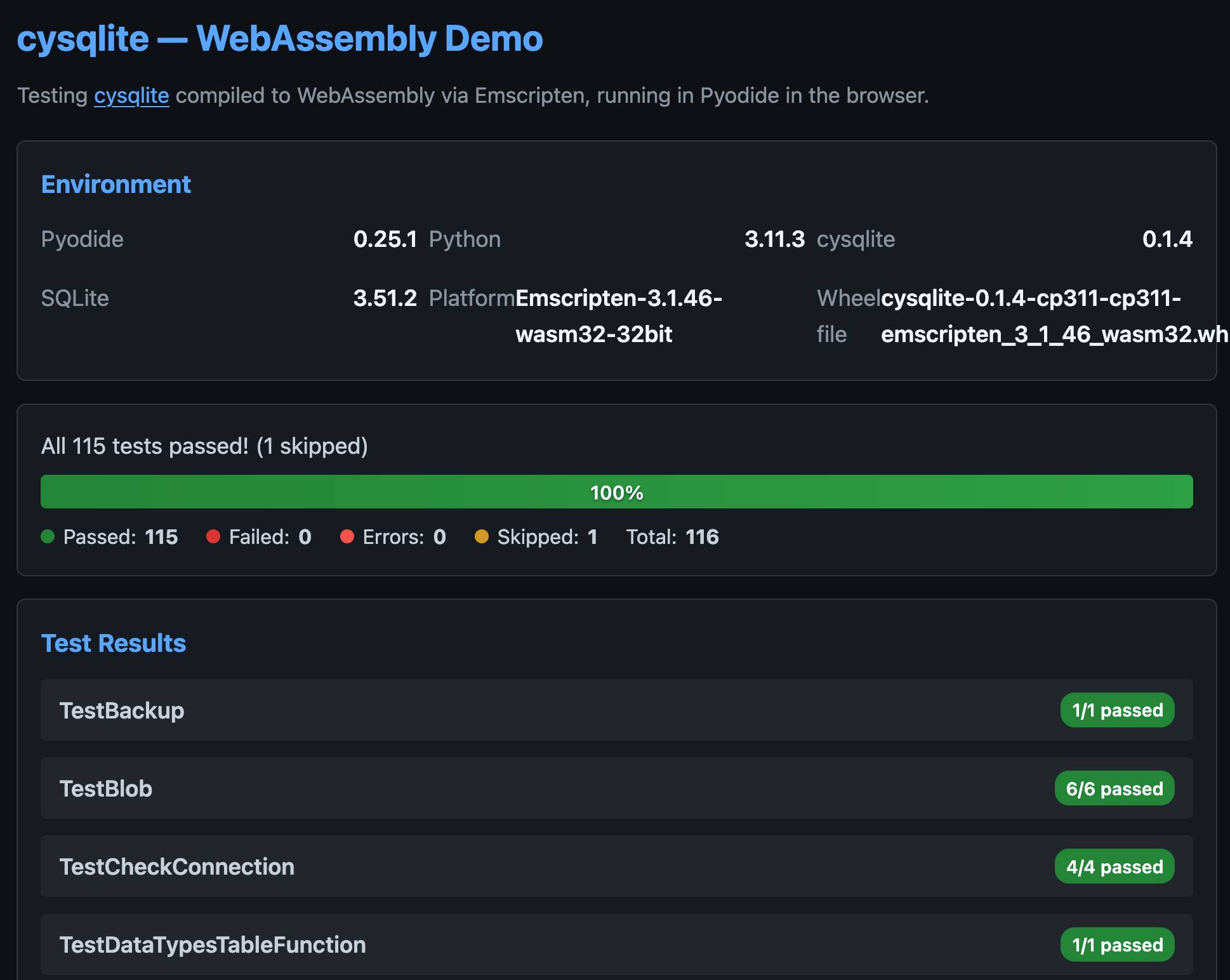
cysqlite provides a Python extension compiled from C, which means it normally wouldn't be available in Pyodide. I set Claude Code on it (here's the prompt) and it built me cysqlite-0.1.4-cp311-cp311-emscripten_3_1_46_wasm32.whl, a 688KB wheel file with a WASM build of the library that can be loaded into Pyodide like this:
import micropip await micropip.install( "https://simonw.github.io/research/cysqlite-wasm-wheel/cysqlite-0.1.4-cp311-cp311-emscripten_3_1_46_wasm32.whl" ) import cysqlite print(cysqlite.connect(":memory:").execute( "select sqlite_version()" ).fetchone())
(I also learned that wheels like this have to be built for the emscripten version used by that edition of Pyodide - my experimental wheel loads in Pyodide 0.25.1 but fails in 0.27.5 with a Wheel was built with Emscripten v3.1.46 but Pyodide was built with Emscripten v3.1.58 error.)
You can try my wheel in this new Pyodide REPL i had Claude build as a mobile-friendly alternative to Pyodide's own hosted console.
I also had Claude build this demo page that executes the original test suite in the browser and displays the results:
Distributing Go binaries like sqlite-scanner through PyPI using go-to-wheel
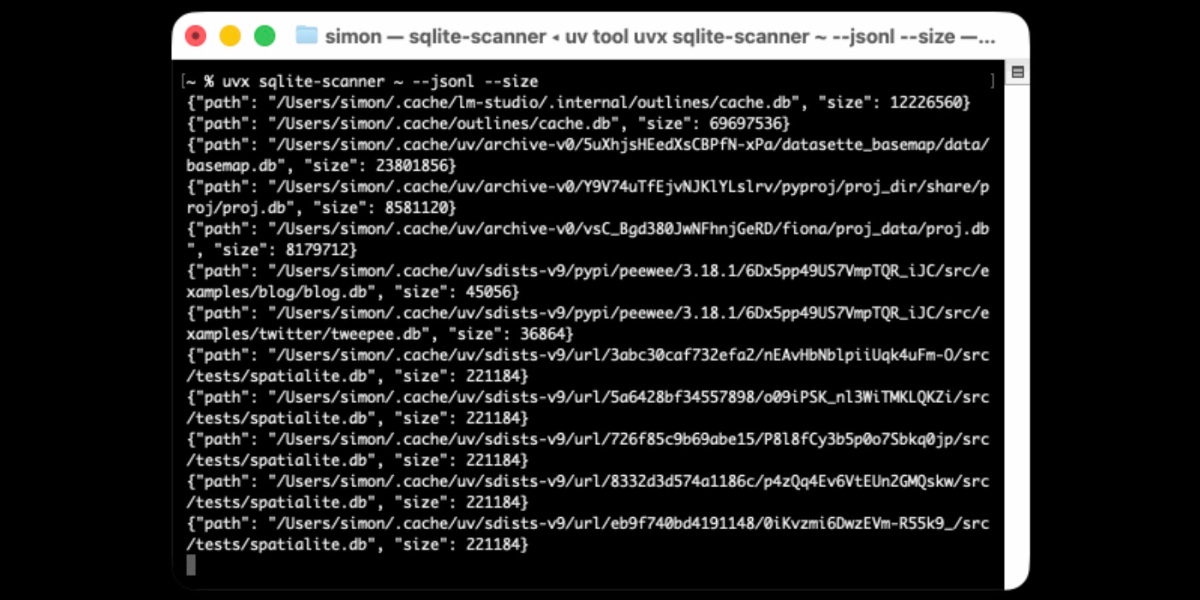
I’ve been exploring Go for building small, fast and self-contained binary applications recently. I’m enjoying how there’s generally one obvious way to do things and the resulting code is boring and readable—and something that LLMs are very competent at writing. The one catch is distribution, but it turns out publishing Go binaries to PyPI means any Go binary can be just a uvx package-name call away.
Introducing the Codex app. OpenAI just released a new macOS app for their Codex coding agent. I've had a few days of preview access - it's a solid app that provides a nice UI over the capabilities of the Codex CLI agent and adds some interesting new features, most notably first-class support for Skills, and Automations for running scheduled tasks.
The app is built with Electron and Node.js. Automations track their state in a SQLite database - here's what that looks like if you explore it with uvx datasette ~/.codex/sqlite/codex-dev.db:

Here’s an interactive copy of that database in Datasette Lite.
The announcement gives us a hint at some usage numbers for Codex overall - the holiday spike is notable:
Since the launch of GPT‑5.2-Codex in mid-December, overall Codex usage has doubled, and in the past month, more than a million developers have used Codex.
Automations are currently restricted in that they can only run when your laptop is powered on. OpenAI promise that cloud-based automations are coming soon, which will resolve this limitation.
They chose Electron so they could target other operating systems in the future, with Windows “coming very soon”. OpenAI’s Alexander Embiricos noted on the Hacker News thread that:
it's taking us some time to get really solid sandboxing working on Windows, where there are fewer OS-level primitives for it.
Like Claude Code, Codex is really a general agent harness disguised as a tool for programmers. OpenAI acknowledge that here:
Codex is built on a simple premise: everything is controlled by code. The better an agent is at reasoning about and producing code, the more capable it becomes across all forms of technical and knowledge work. [...] We’ve focused on making Codex the best coding agent, which has also laid the foundation for it to become a strong agent for a broad range of knowledge work tasks that extend beyond writing code.
Claude Code had to rebrand to Cowork to better cover the general knowledge work case. OpenAI can probably get away with keeping the Codex name for both.
OpenAI have made Codex available to free and Go plans for "a limited time" (update: Sam Altman says two months) during which they are also doubling the rate limits for paying users.
I wanted a Python library that could parse SQLite SELECT statements, so I vibe coded this one up based on a specification I reverse-engineered from SQLite's own parser behavior.
There's an interactive playground here for trying it out in the browser (via Pyodide).
The Design & Implementation of Sprites (via) I wrote about Sprites last week. Here's Thomas Ptacek from Fly with the insider details on how they work under the hood.
I like this framing of them as "disposable computers":
Sprites are ball-point disposable computers. Whatever mark you mean to make, we’ve rigged it so you’re never more than a second or two away from having a Sprite to do it with.
I've noticed that new Fly Machines can take a while (up to around a minute) to provision. Sprites solve that by keeping warm pools of unused machines in multiple regions, which is enabled by them all using the same container:
Now, today, under the hood, Sprites are still Fly Machines. But they all run from a standard container. Every physical worker knows exactly what container the next Sprite is going to start with, so it’s easy for us to keep pools of “empty” Sprites standing by. The result: a Sprite create doesn’t have any heavy lifting to do; it’s basically just doing the stuff we do when we start a Fly Machine.
The most interesting detail is how the persistence layer works. Sprites only charge you for data you have written that differs from the base image and provide ~300ms checkpointing and restores - it turns out that's power by a custom filesystem on top of S3-compatible storage coordinated by Litestream-replicated local SQLite metadata:
We still exploit NVMe, but not as the root of storage. Instead, it’s a read-through cache for a blob on object storage. S3-compatible object stores are the most trustworthy storage technology we have. I can feel my blood pressure dropping just typing the words “Sprites are backed by object storage.” [...]
The Sprite storage stack is organized around the JuiceFS model (in fact, we currently use a very hacked-up JuiceFS, with a rewritten SQLite metadata backend). It works by splitting storage into data (“chunks”) and metadata (a map of where the “chunks” are). Data chunks live on object stores; metadata lives in fast local storage. In our case, that metadata store is kept durable with Litestream. Nothing depends on local storage.
The most popular blogs of Hacker News in 2025 (via) Michael Lynch maintains HN Popularity Contest, a site that tracks personal blogs on Hacker News and scores them based on how well they perform on that platform.
The engine behind the project is the domain-meta.csv CSV on GiHub, a hand-curated list of known personal blogs with author and bio and tag metadata, which Michael uses to separate out personal blog posts from other types of content.
I came top of the rankings in 2023, 2024 and 2025 but I'm listed in third place for all time behind Paul Graham and Brian Krebs.
I dug around in the browser inspector and was delighted to find that the data powering the site is served with open CORS headers, which means you can easily explore it with external services like Datasette Lite.
Here's a convoluted window function query Claude Opus 4.5 wrote for me which, for a given domain, shows where that domain ranked for each year since it first appeared in the dataset:
with yearly_scores as ( select domain, strftime('%Y', date) as year, sum(score) as total_score, count(distinct date) as days_mentioned from "hn-data" group by domain, strftime('%Y', date) ), ranked as ( select domain, year, total_score, days_mentioned, rank() over (partition by year order by total_score desc) as rank from yearly_scores ) select r.year, r.total_score, r.rank, r.days_mentioned from ranked r where r.domain = :domain and r.year >= ( select min(strftime('%Y', date)) from "hn-data" where domain = :domain ) order by r.year desc
(I just noticed that the last and r.year >= ( clause isn't actually needed here.)
My simonwillison.net results show me ranked 3rd in 2022, 30th in 2021 and 85th back in 2007 - though I expect there are many personal blogs from that year which haven't yet been manually added to Michael's list.
Also useful is that every domain gets its own CORS-enabled CSV file with details of the actual Hacker News submitted from that domain, e.g. https://hn-popularity.cdn.refactoringenglish.com/domains/simonwillison.net.csv. Here's that one in Datasette Lite.
2025
But once we got that and got this aviation grade testing in place, the number of bugs just dropped to a trickle. Now we still do have bugs but the aviation grade testing allows us to move fast, which is important because in this business you either move fast or you're disrupted. So, we're able to make major changes to the structure of the code that we deliver and be confident that we're not breaking things because we had these intense tests. Probably half the time we spend is actually writing new tests, we're constantly writing new tests. And over the 17-year history, we have amassed a huge suite of tests which we run constantly.
Other database engines don't do this; don't have this level of testing. But they're still high quality, I mean, I noticed in particular, PostgreSQL is a very high-quality database engine, they don't have many bugs. I went to the PostgreSQL and ask them “how do you prevent the bugs”? We talked about this for a while. What I came away with was they've got a very elaborate peer review process, and if they've got code that has worked for 10 years they just don't mess with it, leave it alone, it works. Whereas we change our code fearlessly, and we have a much smaller team and we don't have the peer review process.
— D. Richard Hipp, ACM SIGMOD Record, June 2019 (PDF)
Copyright Release for Contributions To SQLite. D. Richard Hipp called me out for spreading misinformation on Hacker News that SQLite refuses outside contributions:
No, Simon, we don't "refuse". We are just very selective and there is a lot of paperwork involved to confirm the contribution is in the public domain and does not contaminate the SQLite core with licensed code.
I deeply regret this error! I'm linking to the copyright release document here - it looks like SQLite's public domain nature makes this kind of clause extremely important:
[...] To the best of my knowledge and belief, the changes and enhancements that I have contributed to SQLite are either originally written by me or are derived from prior works which I have verified are also in the public domain and are not subject to claims of copyright by other parties.
Out of curiosity I decided to see how many people have contributed to SQLite outside of the core team of Richard, Dan and Joe. I ran that query using Fossil, SQLite's own SQLite-based version control system, like this:
brew install fossil
fossil clone https://www.sqlite.org/src sqlite.fossil
fossil sql -R sqlite.fossil "
SELECT user, COUNT(*) as commits
FROM event WHERE type='ci'
GROUP BY user ORDER BY commits DESC
"
I got back 38 rows, though I think danielk1977 and dan may be duplicates.
Update: The SQLite team have clarified this on their SQLite is Public Domain page. It used to read "In order to keep SQLite completely free and unencumbered by copyright, the project does not accept patches." - it now reads:
In order to keep SQLite completely free and unencumbered by copyright, the project does not accept patches from random people on the internet. There is a process to get a patch accepted, but that process is involved and for smaller changes is not normally worth the effort.
Under the hood of Canada Spends with Brendan Samek

I talked to Brendan Samek about Canada Spends, a project from Build Canada that makes Canadian government financial data accessible and explorable using a combination of Datasette, a neat custom frontend, Ruby ingestion scripts, sqlite-utils and pieces of LLM-powered PDF extraction.
[... 561 words]sqlite-utils 3.39.
I got a report of a bug in sqlite-utils concerning plugin installation - if you installed the package using uv tool install further attempts to install plugins with sqlite-utils install X would fail, because uv doesn't bundle pip by default. I had the same bug with Datasette a while ago, turns out I forgot to apply the fix to sqlite-utils.
Since I was pushing a new dot-release I decided to integrate some of the non-breaking changes from the 4.0 alpha I released last night.
I tried to have Claude Code do the backporting for me:
create a new branch called 3.x starting with the 3.38 tag, then consult https://github.com/simonw/sqlite-utils/issues/688 and cherry-pick the commits it lists in the second comment, then review each of the links in the first comment and cherry-pick those as well. After each cherry-pick run the command "just test" to confirm the tests pass and fix them if they don't. Look through the commit history on main since the 3.38 tag to help you with this task.
This worked reasonably well - here's the terminal transcript. It successfully argued me out of two of the larger changes which would have added more complexity than I want in a small dot-release like this.
I still had to do a bunch of manual work to get everything up to scratch, which I carried out in this PR - including adding comments there and then telling Claude Code:
Apply changes from the review on this PR https://github.com/simonw/sqlite-utils/pull/689
Here's the transcript from that.
The release is now out with the following release notes:
- Fixed a bug with
sqlite-utils installwhen the tool had been installed usinguv. (#687)- The
--functionsargument now optionally accepts a path to a Python file as an alternative to a string full of code, and can be specified multiple times - see Defining custom SQL functions. (#659)sqlite-utilsnow requires on Python 3.10 or higher.
sqlite-utils 4.0a1 has several (minor) backwards incompatible changes
I released a new alpha version of sqlite-utils last night—the 128th release of that package since I started building it back in 2018.
[... 1,049 words]How I automate my Substack newsletter with content from my blog

I sent out my weekly-ish Substack newsletter this morning and took the opportunity to record a YouTube video demonstrating my process and describing the different components that make it work. There’s a lot of digital duct tape involved, taking the content from Django+Heroku+PostgreSQL to GitHub Actions to SQLite+Datasette+Fly.io to JavaScript+Observable and finally to Substack.
[... 1,345 words]