1,264 posts tagged “python”
The Python programming language.
2026
I finally found a cache-friendly recipe for using uvx tool-name in GitHub Actions workflows that I like.
The trick is setting a UV_EXCLUDE_NEWER: "2026-07-12" environment variable at the start of the workflow and then using that as part of the GitHub Actions cache key. This means any uvx tool-name commands will resolve to the most recent version as-of that date, and you can bust the cache and upgrade the tools by bumping the date in the future.
My goal here is to use Python tools in GitHub Actions without every run of the workflow hitting PyPI to download a fresh copy of the tool and its dependencies.
Update: Here's an existing issue against the astral-sh/setup-uv repository requesting that they switch the default to cache rather than purge wheels from PyPI.
The first dot-release since 4.0 a few days ago, introducing a number of minor new features.
sqlite-utils insertandsqlite-utils upsertnow accept a--codeoption for providing a block of Python code (or a path to a.pyfile) that defines arows()function orrowsiterable of rows to insert, as an alternative to importing from a file. (#684)
sqlite-utils already had features that allow you to pass blocks of Python code as CLI arguments, for example this one for the sqlite-utils convert command:
sqlite-utils convert content.db articles headline ' def convert(value): return value.upper()'
Allowing blocks of code to generate new rows directly was on obvious extension of that pattern:
sqlite-utils insert data.db creatures --code ' def rows(): yield {"id": 1, "name": "Cleo"} yield {"id": 2, "name": "Suna"} ' --pk id
sqlite-utils insertandsqlite-utils upsertnow accept--type column-name typeto override the type automatically chosen when the table is created. This is useful for CSV or TSV columns such as ZIP codes that look like integers but should be stored asTEXTto preserve leading zeros. (#131)
A long-standing feature request which turned out to be a simple implementation.
- New
table.drop_index(name)method andsqlite-utils drop-indexcommand for dropping an index by name. Both acceptignore=True/--ignoreto ignore a missing index. (#626)sqlite-utils querycan now read the SQL query from standard input by passing-in place of the query, for exampleecho "select * from dogs" | sqlite-utils query dogs.db -. (#765)
Two more small features. I had Codex review all open issues and highlight the easiest ones!
sqlite-utils upsertcan now infer the primary key of an existing table, so--pkcan be omitted when upserting into a table that already has a primary key.
Another Codex suggestion, an obvious missing CLI feature from a Python library improvement that shipped in the 4.0 release.
table.transform()andtable.transform_sql()now acceptstrict=Trueorstrict=Falseto change a table’s SQLite strict mode. Omitting the option preserves the existing mode. (#787)- The
sqlite-utils transformcommand now accepts--strictand--no-strictto change a table’s strict mode. (#787)
These two were inspired by Prefer STRICT tables in SQLite by Evan Hahn, which did the rounds on Hacker News today. Evan pointed out that:
Unfortunately, I don’t think there’s a way to ALTER a table to make it strict. I think you have to copy the data out of the non-strict table into the strict one.
That's exactly what the sqlite-utils transform mechanism does, so I extended it to add the ability to switch tables from strict to non-strict and vice-versa.
Here's the GPT-5.6 Sol xhigh Codex transcript I used to implement those new strict table features. One of the most useful prompts I ran was this one:
use uv run python -c and manually exercise the new .transform(strict=) option, see if you can find any edge-cases or bugs
Effectively telling the model to manually test its work, outside of the automated tests it had already written. This turned up two minor issues that we then fixed.
Have your agent record video demos of its work with shot-scraper video
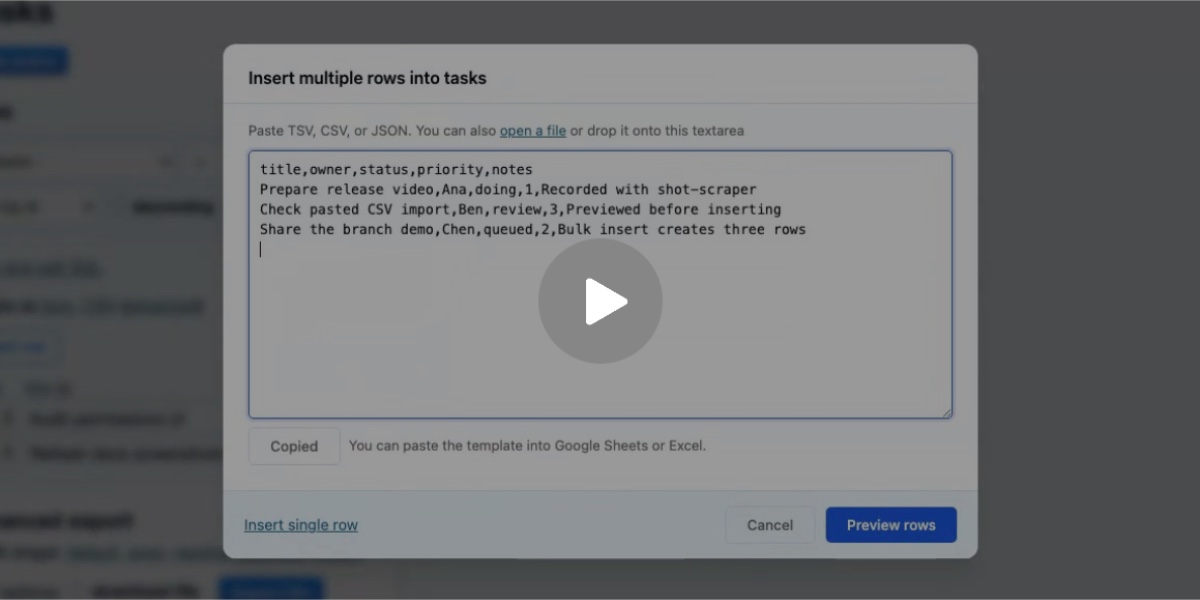
shot-scraper video is a new command introduced in today’s shot-scraper 1.10 release which accepts a storyboard.yml file defining a routine to run against a web application and uses Playwright to record a video of that routine. I’ve written before about the importance of having coding agents produce demos of their work; this is my latest attempt at enabling them to do that.
Publishing WASM wheels to PyPI for use with Pyodide
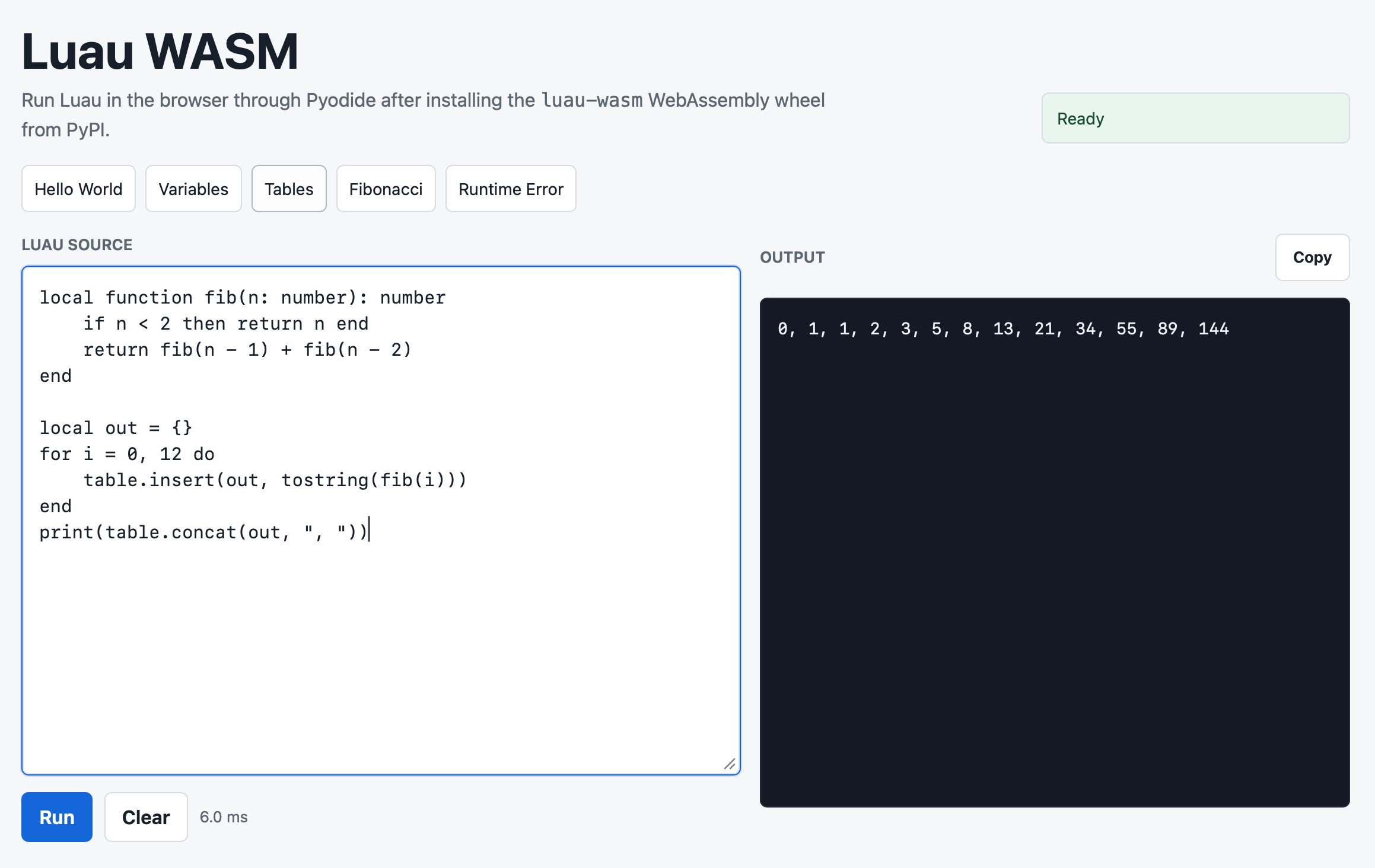
The Pyodide 314.0 release announcement (via Hacker News) includes news I’ve been looking forward to for a long time:
[... 757 words]It would be neat if arbitrary SQL queries in Datasette could be rendered with additional information based on which columns from which tables were included in the results.
To build that, we would need to be able to look at a SQL query like select users.name, orders.total from users join orders on orders.user_id = users.id and programmatically identify the table.column for each result - navigating not just joins but also more complex syntax like CTEs.
I decided to set Claude Code (Opus 4.8, since Fable is currently banned by the US government) on the problem. It found several promising solutions - one using apsw, another that uses ctypes to access the SQLite sqlite3_column_table_name() C function (which is not otherwise exposed to Python), and one using clever interrogation of the output of EXPLAIN.
I built this utility library to support an asyncio dependency injection pattern a few years ago. I was using it with Datasette and Claude Fable 5 spotted some bugs in the dependency which it then fixed for me. It's a very proactive model!
I added a CLI to micropython-wasm (issue #7), inspired by the first draft of the blog entry when I realized it would be a great way to illustrate the Try it yourself section.
Running Python code in a sandbox with MicroPython and WASM
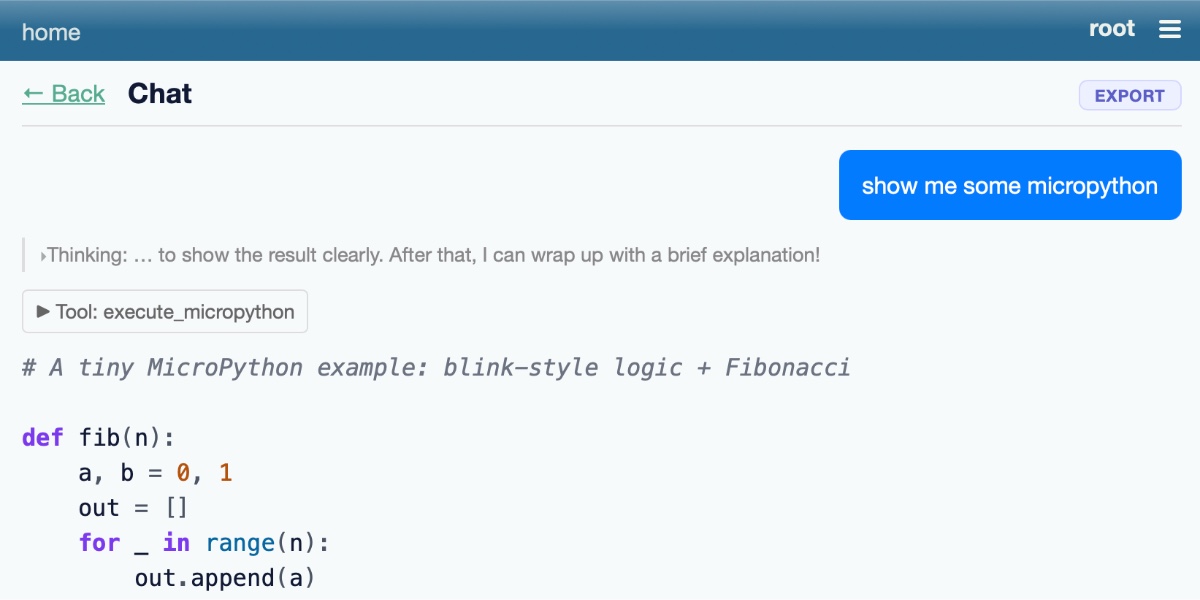
I’ve been experimenting with different approaches to running code in a sandbox for several years now, but my latest attempt feels like it might finally have all of the characteristics I’ve been looking for. I’ve released it as an alpha package called micropython-wasm, and I’m using it for a code execution sandbox plugin for Datasette Agent called datasette-agent-micropython.
[... 2,024 words]I want Datasette Agent to be able to generate and execute Python code safely. This alpha is looking promising so far. GPT-5.5 has so far failed to break out of the sandbox!
Fixes for some limitations that emerged while I was trying to use this to build datasette-agent-micropython.
My latest sandboxing experiment: This alpha package bundles a lightly customized WASM build of MicroPython with a wrapper to execute code in it via wasmtime.
Datasette Lite is my version of Datasette that runs entirely in the browser using Pyodide in WebAssembly.
When I first built it four years ago I used Web Workers and code that intercepts navigation operations and fetches the generated HTML by running the Python app.
This worked, but had the disadvantage that any JavaScript in <script> tags would not be executed - breaking some Datasette functionality and a whole lot of Datasette plugins.
This morning I set Claude Opus 4.8 the task (in Claude Code for web) of figuring out how to run Python ASGI apps in Pyodide using Service Workers instead, and it seems to work! Here's a basic ASGI FastCGI demo and here's a demo that runs Datasette 1.0a31.
I'm still getting my head around exactly how it works, but once I've done that I plan to upgrade Datasette Lite itself.
It's been a few months since I last poked at Monty, the sandboxed subset of Python implemented in Rust. I had Claude Code look at the most recent release.
Importantly the max_duration_secs, max_memory, max_allocations, and max_recursion_depth settings all appear to work as advertised.
If it's good enough for antirez to add to Redis I figured Ville Laurikari's TRE regular expression engine was worth exploring in a little more detail.
I had Claude Code build an experimental Python binding (it used ctypes) and try some malicious regular expression attacks against the library. TRE handles those much better than Python's standard library implementation, thanks mainly to the lack of support for backtracking.
LLM 0.32a0 is a major backwards-compatible refactor
I just released LLM 0.32a0, an alpha release of my LLM Python library and CLI tool for accessing LLMs, with some consequential changes that I’ve been working towards for quite a while.
[... 1,874 words]What’s new in pip 26.1—lockfiles and dependency cooldowns!
(via)
Richard Si describes an excellent set of upgrades to Python's default pip tool for installing dependencies.
This version drops support for Python 3.9 - fair enough, since it's been EOL since October. macOS still ships with python3 as a default Python 3.9, so I tried out the new Python version against Python 3.14 like this:
uv python install 3.14
mkdir /tmp/experiment
cd /tmp/experiment
python3.14 -m venv venv
source venv/bin/activate
pip install -U pip
pip --version
This confirmed I had pip 26.1 - then I tried out the new lock files:
pip lock datasette llm
This installs Datasette and LLM and all of their dependencies and writes the whole lot to a 519 line pylock.toml file - here's the result.
The new release also supports dependency cooldowns, discussed here previously, via the new --uploaded-prior-to PXD option where X is a number of days. The format is P-number-of-days-D, following ISO duration format but only supporting days.
I shipped a new release of LLM, version 0.31, three days ago. Here's how to use the new --uploaded-prior-to P4D option to ask for a version that is at least 4 days old.
pip install llm --uploaded-prior-to P4D
venv/bin/llm --version
This gave me version 0.30.
microsoft/VibeVoice. VibeVoice is Microsoft's Whisper-style audio model for speech-to-text, MIT licensed and with speaker diarization built into the model.
Microsoft released it on January 21st, 2026 but I hadn't tried it until today. Here's a one-liner to run it on a Mac with uv, mlx-audio (by Prince Canuma) and the 5.71GB mlx-community/VibeVoice-ASR-4bit MLX conversion of the 17.3GB VibeVoice-ASR model, in this case against a downloaded copy of my recent podcast appearance with Lenny Rachitsky:
uv run --with mlx-audio mlx_audio.stt.generate \
--model mlx-community/VibeVoice-ASR-4bit \
--audio lenny.mp3 --output-path lenny \
--format json --verbose --max-tokens 32768
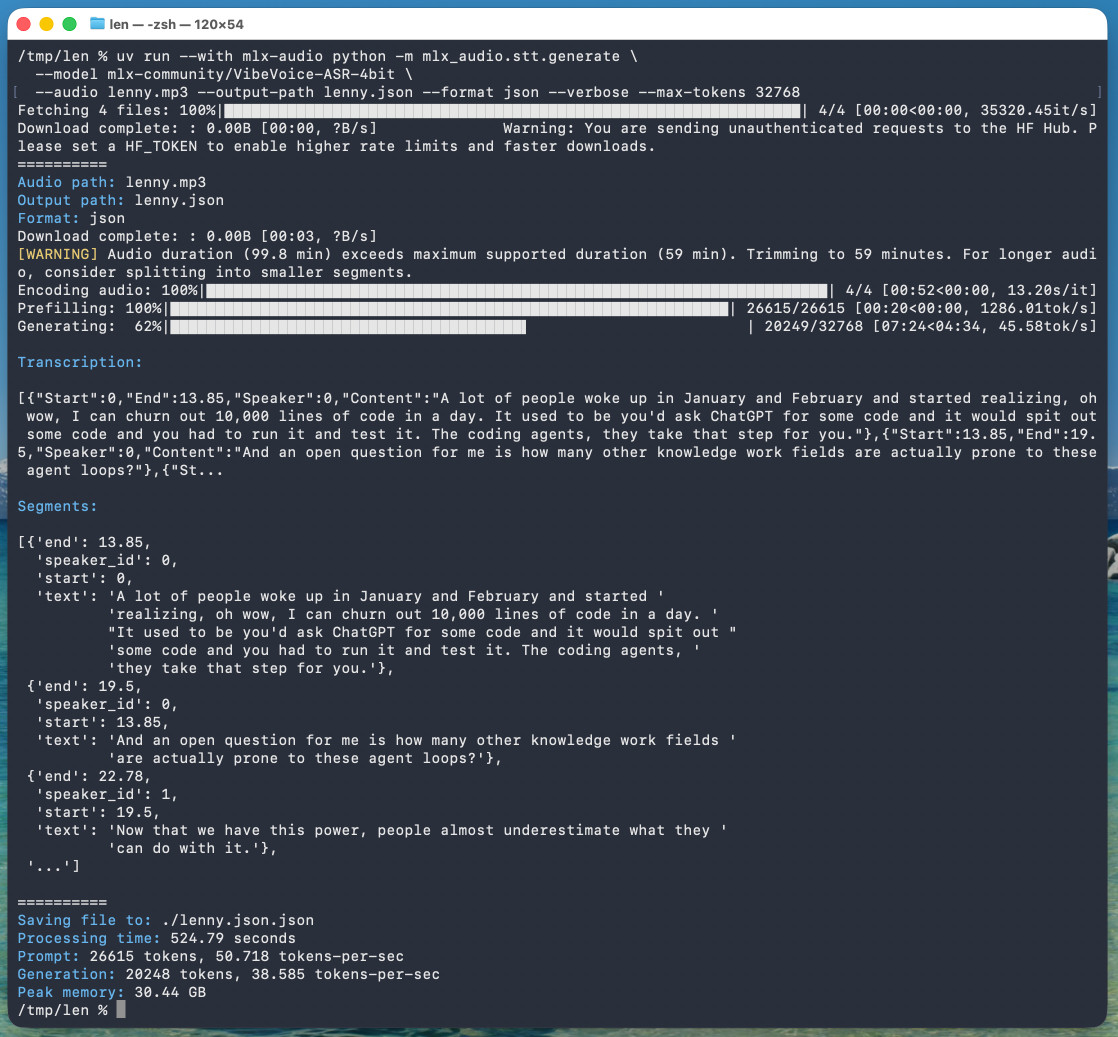
The tool reported back:
Processing time: 524.79 seconds
Prompt: 26615 tokens, 50.718 tokens-per-sec
Generation: 20248 tokens, 38.585 tokens-per-sec
Peak memory: 30.44 GB
So that's 8 minutes 45 seconds for an hour of audio (running on a 128GB M5 Max MacBook Pro).
I've tested it against .wav and .mp3 files and they both worked fine.
If you omit --max-tokens it defaults to 8192, which is enough for about 25 minutes of audio. I discovered that through trial-and-error and quadrupled it to guarantee I'd get the full hour.
That command reported using 30.44GB of RAM at peak, but in Activity Monitor I observed 61.5GB of usage during the prefill stage and around 18GB during the generating phase.
Here's the resulting JSON. The key structure looks like this:
{
"text": "And an open question for me is how many other knowledge work fields are actually prone to these agent loops?",
"start": 13.85,
"end": 19.5,
"duration": 5.65,
"speaker_id": 0
},
{
"text": "Now that we have this power, people almost underestimate what they can do with it.",
"start": 19.5,
"end": 22.78,
"duration": 3.280000000000001,
"speaker_id": 1
},
{
"text": "Today, probably 95% of the code that I produce, I didn't type it myself. I write so much of my code on my phone. It's wild.",
"start": 22.78,
"end": 30.0,
"duration": 7.219999999999999,
"speaker_id": 0
}
Since that's an array of objects we can open it in Datasette Lite, making it easier to browse.
Amusingly that Datasette Lite view shows three speakers - it identified Lenny and me for the conversation, and then a separate Lenny for the voice he used for the additional intro and the sponsor reads!
VibeVoice can only handle up to an hour of audio, so running the above command transcribed just the first hour of the podcast. To transcribe more than that you'd need to split the audio, ideally with a minute or so of overlap so you can avoid errors from partially transcribed words at the split point. You'd also need to then line up the identified speaker IDs across the multiple segments.
Join us at PyCon US 2026 in Long Beach—we have new AI and security tracks this year

This year’s PyCon US is coming up next month from May 13th to May 19th, with the core conference talks from Friday 15th to Sunday 17th and tutorial and sprint days either side. It’s in Long Beach, California this year, the first time PyCon US has come to the West Coast since Portland, Oregon in 2017 and the first time in California since Santa Clara in 2013.
[... 606 words]Two major changes in this new Datasette alpha. I covered the first of those in detail yesterday - Datasette no longer uses Django-style CSRF form tokens, instead using modern browser headers as described by Filippo Valsorda.
The second big change is that Datasette now fires a new RenameTableEvent any time a table is renamed during a SQLite transaction. This is useful because some plugins (like datasette-comments) attach additional data to table records by name, so a renamed table requires them to react in appropriate ways.
Here are the rest of the changes in the alpha:
- New actor= parameter for
datasette.clientmethods, allowing internal requests to be made as a specific actor. This is particularly useful for writing automated tests. (#2688)- New
Database(is_temp_disk=True)option, used internally for the internal database. This helps resolve intermittent database locked errors caused by the internal database being in-memory as opposed to on-disk. (#2683) (#2684)- The
/<database>/<table>/-/upsertAPI (docs) now rejects rows withnullprimary key values. (#1936)- Improved example in the API explorer for the
/-/upsertendpoint (docs). (#1936)- The
/<database>.jsonendpoint now includes an"ok": truekey, for consistency with other JSON API responses.- call_with_supported_arguments() is now documented as a supported public API. (#2678)
Thanks to a tip from Rahim Nathwani, here's a uv run recipe for transcribing an audio file on macOS using the 10.28 GB Gemma 4 E2B model with MLX and mlx-vlm:
uv run --python 3.13 --with mlx_vlm --with torchvision --with gradio \
mlx_vlm.generate \
--model google/gemma-4-e2b-it \
--audio file.wav \
--prompt "Transcribe this audio" \
--max-tokens 500 \
--temperature 1.0
I tried it on this 14 second .wav file and it output the following:
This front here is a quick voice memo. I want to try it out with MLX VLM. Just going to see if it can be transcribed by Gemma and how that works.
(That was supposed to be "This right here..." and "... how well that works" but I can hear why it misinterpreted that as "front" and "how that works".)
I ran into trouble deploying a new feature using SSE to a production Datasette instance, and it turned out that instance was using datasette-gzip which uses asgi-gzip which was incorrectly compressing event/text-stream responses.
asgi-gzip was extracted from Starlette, and has a GitHub Actions scheduled workflow to check Starlette for updates that need to be ported to the library... but that action had stopped running and hence had missed Starlette's own fix for this issue.
I ran the workflow and integrated the new fix, and now datasette-gzip and asgi-gzip both correctly handle text/event-stream in SSE responses.
LLM plugins can define new models in both sync and async varieties. The async variants are most common for API-backed models - sync variants tend to be things that run the model directly within the plugin.
My llm-mrchatterbox plugin is sync only. I wanted to try it out with various Datasette LLM features (specifically datasette-enrichments-llm) but Datasette can only use async models.
So... I had Claude spin up this plugin that turns sync models into async models using a thread pool. This ended up needing an extra plugin hook mechanism in LLM itself, which I shipped just now in LLM 0.30.
LiteLLM Hack: Were You One of the 47,000? (via) Daniel Hnyk used the BigQuery PyPI dataset to determine how many downloads there were of the exploited LiteLLM packages during the 46 minute period they were live on PyPI. The answer was 46,996 across the two compromised release versions (1.82.7 and 1.82.8).
They also identified 2,337 packages that depended on LiteLLM - 88% of which did not pin versions in a way that would have avoided the exploited version.
Package Managers Need to Cool Down. Today's LiteLLM supply chain attack inspired me to revisit the idea of dependency cooldowns, the practice of only installing updated dependencies once they've been out in the wild for a few days to give the community a chance to spot if they've been subverted in some way.
This recent piece (March 4th) piece by Andrew Nesbitt reviews the current state of dependency cooldown mechanisms across different packaging tools. It's surprisingly well supported! There's been a flurry of activity across major packaging tools, including:
- pnpm 10.16 (September 2025) —
minimumReleaseAgewithminimumReleaseAgeExcludefor trusted packages - Yarn 4.10.0 (September 2025) —
npmMinimalAgeGate(in minutes) withnpmPreapprovedPackagesfor exemptions - Bun 1.3 (October 2025) —
minimumReleaseAgeviabunfig.toml - Deno 2.6 (December 2025) —
--minimum-dependency-agefordeno updateanddeno outdated - uv 0.9.17 (December 2025) — added relative duration support to existing
--exclude-newer, plus per-package overrides viaexclude-newer-package - pip 26.0 (January 2026) —
--uploaded-prior-to(absolute timestamps only; relative duration support requested, update: and added in pip 26.1 in April) - npm 11.10.0 (February 2026) —
min-release-age
pip currently only supports absolute rather than relative dates but Seth Larson has a workaround for that using a scheduled cron to update the absolute date in the pip.conf config file.
Malicious litellm_init.pth in litellm 1.82.8 — credential stealer.
The LiteLLM v1.82.8 package published to PyPI was compromised with a particularly nasty credential stealer hidden in base64 in a litellm_init.pth file, which means installing the package is enough to trigger it even without running import litellm.
(1.82.7 had the exploit as well but it was in the proxy/proxy_server.py file so the package had to be imported for it to take effect.)
This issue has a very detailed description of what the credential stealer does. There's more information about the timeline of the exploit over here.
PyPI has already quarantined the litellm package so the window for compromise was just a few hours, but if you DID install the package it would have hoovered up a bewildering array of secrets, including ~/.ssh/, ~/.gitconfig, ~/.git-credentials, ~/.aws/, ~/.kube/, ~/.config/, ~/.azure/, ~/.docker/, ~/.npmrc, ~/.vault-token, ~/.netrc, ~/.lftprc, ~/.msmtprc, ~/.my.cnf, ~/.pgpass, ~/.mongorc.js, ~/.bash_history, ~/.zsh_history, ~/.sh_history, ~/.mysql_history, ~/.psql_history, ~/.rediscli_history, ~/.bitcoin/, ~/.litecoin/, ~/.dogecoin/, ~/.zcash/, ~/.dashcore/, ~/.ripple/, ~/.bitmonero/, ~/.ethereum/, ~/.cardano/.
It looks like this supply chain attack started with the recent exploit against Trivy, ironically a security scanner tool that was used in CI by LiteLLM. The Trivy exploit likely resulted in stolen PyPI credentials which were then used to directly publish the vulnerable packages.
Experimenting with Starlette 1.0 with Claude skills
Starlette 1.0 is out! This is a really big deal. I think Starlette may be the Python framework with the most usage compared to its relatively low brand recognition because Starlette is the foundation of FastAPI, which has attracted a huge amount of buzz that seems to have overshadowed Starlette itself.
[... 1,194 words]Thoughts on OpenAI acquiring Astral and uv/ruff/ty
The big news this morning: Astral to join OpenAI (on the Astral blog) and OpenAI to acquire Astral (the OpenAI announcement). Astral are the company behind uv, ruff, and ty—three increasingly load-bearing open source projects in the Python ecosystem. I have thoughts!
[... 1,378 words]Great news—we’ve hit our (very modest) performance goals for the CPython JIT over a year early for macOS AArch64, and a few months early for x86_64 Linux. The 3.15 alpha JIT is about 11-12% faster on macOS AArch64 than the tail calling interpreter, and 5-6%faster than the standard interpreter on x86_64 Linux.
— Ken Jin, Python 3.15’s JIT is now back on track
Coding agents for data analysis. Here's the handout I prepared for my NICAR 2026 workshop "Coding agents for data analysis" - a three hour session aimed at data journalists demonstrating ways that tools like Claude Code and OpenAI Codex can be used to explore, analyze and clean data.
Here's the table of contents:
I ran the workshop using GitHub Codespaces and OpenAI Codex, since it was easy (and inexpensive) to distribute a budget-restricted API key for Codex that attendees could use during the class. Participants ended up burning $23 of Codex tokens.
The exercises all used Python and SQLite and some of them used Datasette.
One highlight of the workshop was when we started running Datasette such that it served static content from a viz/ folder, then had Claude Code start vibe coding new interactive visualizations directly in that folder. Here's a heat map it created for my trees database using Leaflet and Leaflet.heat, source code here.

I designed the handout to also be useful for people who weren't able to attend the session in person. As is usually the case, material aimed at data journalists is equally applicable to anyone else with data to explore.