68 posts tagged “machine-learning”
2025
I counted all of the yurts in Mongolia using machine learning (via) Fascinating, detailed account by Monroe Clinton of a geospatial machine learning project. Monroe wanted to count visible yurts in Mongolia using Google Maps satellite view. The resulting project incorporates mercantile for tile calculations, Label Studio for help label the first 10,000 examples, a model trained on top of YOLO11 and a bunch of clever custom Python code to co-ordinate a brute force search across 120 CPU workers running the model.
Career Update: Google DeepMind -> Anthropic. Nicholas Carlini (previously) on joining Anthropic, driven partly by his frustration at friction he encountered publishing his research at Google DeepMind after their merge with Google Brain. His area of expertise is adversarial machine learning.
The recent advances in machine learning and language modeling are going to be transformative [d] But in order to realize this potential future in a way that doesn't put everyone's safety and security at risk, we're going to need to make a lot of progress---and soon. We need to make so much progress that no one organization will be able to figure everything out by themselves; we need to work together, we need to talk about what we're doing, and we need to start doing this now.
Manual inspection of data has probably the highest value-to-prestige ratio of any activity in machine learning.
— Greg Brockman, OpenAI, Feb 2023
2024
Bridging Language Gaps in Multilingual Embeddings via Contrastive Learning (via) Most text embeddings models suffer from a "language gap", where phrases in different languages with the same semantic meaning end up with embedding vectors that aren't clustered together.
Jina claim their new jina-embeddings-v3 (CC BY-NC 4.0, which means you need to license it for commercial use if you're not using their API) is much better on this front, thanks to a training technique called "contrastive learning".
There are 30 languages represented in our contrastive learning dataset, but 97% of pairs and triplets are in just one language, with only 3% involving cross-language pairs or triplets. But this 3% is enough to produce a dramatic result: Embeddings show very little language clustering and semantically similar texts produce close embeddings regardless of their language

The problem that you face is that it's relatively easy to take a model and make it look like it's aligned. You ask GPT-4, “how do I end all of humans?” And the model says, “I can't possibly help you with that”. But there are a million and one ways to take the exact same question - pick your favorite - and you can make the model still answer the question even though initially it would have refused. And the question this reminds me a lot of coming from adversarial machine learning. We have a very simple objective: Classify the image correctly according to the original label. And yet, despite the fact that it was essentially trivial to find all of the bugs in principle, the community had a very hard time coming up with actually effective defenses. We wrote like over 9,000 papers in ten years, and have made very very very limited progress on this one small problem. You all have a harder problem and maybe less time.
State-of-the-art music scanning by Soundslice. It's been a while since I checked in on Soundslice, Adrian Holovaty's beautiful web application focused on music education.
The latest feature is spectacular. The Soundslice music editor - already one of the most impressive web applications I've ever experienced - can now import notation directly from scans or photos of sheet music.
The attention to detail is immaculate. The custom machine learning model can handle a wide variety of notation details, and the system asks the user to verify or correct details that it couldn't perfectly determine using a neatly designed flow.
Free accounts can scan two single page documents a month, and paid plans get a much higher allowance. I tried it out just now on a low resolution image I found on Wikipedia and it did a fantastic job, even allowing me to listen to a simulated piano rendition of the music once it had finished processing.
It's worth spending some time with the release notes for the feature to appreciate how much work they've out into improving it since the initial release.
If you're new to Soundslice, here's an example of their core player interface which syncs the display of music notation to an accompanying video.
Adrian wrote up some detailed notes on the machine learning behind the feature when they first launched it in beta back in November 2022.
OMR [Optical Music Recognition] is an inherently hard problem, significantly more difficult than text OCR. For one, music symbols have complex spatial relationships, and mistakes have a tendency to cascade. A single misdetected key signature might result in multiple incorrect note pitches. And there’s a wide diversity of symbols, each with its own behavior and semantics — meaning the problems and subproblems aren’t just hard, there are many of them.
One consideration is that such a deep ML system could well be developed outside of Google-- at Microsoft, Baidu, Yandex, Amazon, Apple, or even a startup. My impression is that the Translate team experienced this. Deep ML reset the translation game; past advantages were sort of wiped out. Fortunately, Google's huge investment in deep ML largely paid off, and we excelled in this new game. Nevertheless, our new ML-based translator was still beaten on benchmarks by a small startup. The risk that Google could similarly be beaten in relevance by another company is highlighted by a startling conclusion from BERT: huge amounts of user feedback can be largely replaced by unsupervised learning from raw text. That could have heavy implications for Google.
— Eric Lehman, internal Google email in 2018
You likely have a TinyML system in your pocket right now: every cellphone has a low power DSP chip running a deep learning model for keyword spotting, so you can say "Hey Google" or "Hey Siri" and have it wake up on-demand without draining your battery. It’s an increasingly pervasive technology. [...]
It’s astonishing what is possible today: real time computer vision on microcontrollers, on-device speech transcription, denoising and upscaling of digital signals. Generative AI is happening, too, assuming you can find a way to squeeze your models down to size. We are an unsexy field compared to our hype-fueled neighbors, but the entire world is already filling up with this stuff and it’s only the very beginning. Edge AI is being rapidly deployed in a ton of fields: medical sensing, wearables, manufacturing, supply chain, health and safety, wildlife conservation, sports, energy, built environment—we see new applications every day.
Daniel Situnayake explains TinyML in a Hacker News comment. Daniel worked on TensorFlow Lite at Google and co-wrote the TinyML O’Reilly book. He just posted a multi-paragraph comment on Hacker News explaining the term and describing some of the recent innovations in that space.
“TinyML means running machine learning on low power embedded devices, like microcontrollers, with constrained compute and memory.”
2023
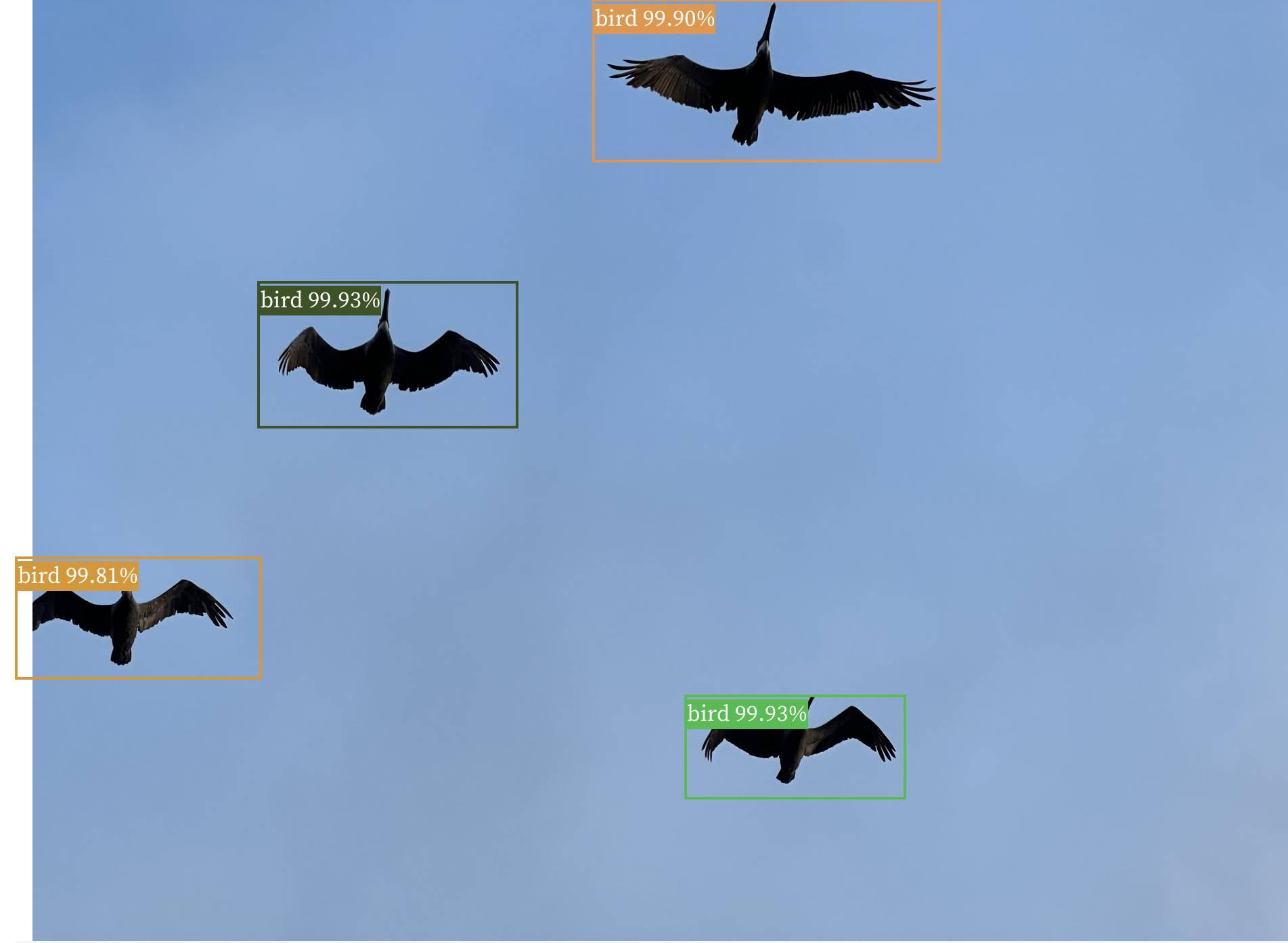
Observable notebook: Detect objects in images (via) I built an Observable notebook that uses Transformers.js and the Xenova/detra-resnet-50 model to detect objects in images, entirely running within your browser. You can select an image using a file picker and it will show you that image with bounding boxes and labels drawn around items within it. I have a demo image showing some pelicans flying ahead, but it works with any image you give it - all without uploading that image to a server.
All models on Hugging Face, sorted by downloads (via) I realized this morning that “sort by downloads” against the list of all of the models on Hugging Face can work as a reasonably good proxy for “which of these models are easiest to get running on your own computer”.
AI photo sorter (via) Really interesting implementation of machine learning photo classification by Alexander Visheratin. This tool lets you select as many photos as you like from your own machine, then provides a web interface for classifying them into labels that you provide. It loads a 102MB quantized CLIP model and executes it in the browser using WebAssembly. Once classified, a “Generate script” button produces a copyable list of shell commands for moving your images into corresponding folders on your own machine. Your photos never get uploaded to a server—everything happens directly in your browser.
Transformers.js. Hugging Face Transformers is a library of Transformer machine learning models plus a Python package for loading and running them. Transformers.js provides a JavaScript alternative interface which runs in your browser, thanks to a set of precompiled WebAssembly binaries for a selection of models. This interactive demo is incredible: in particular, try running the Image classification with google/vit-base-patch16-224 (91MB) model against any photo to get back labels representing that photo. Dropping one of these models onto a page is as easy as linking to a hosted CDN script and running a few lines of JavaScript.
As an NLP researcher I'm kind of worried about this field after 10-20 years. Feels like these oversized LLMs are going to eat up this field and I'm sitting in my chair thinking, "What's the point of my research when GPT-4 can do it better?"
Online gradient descent written in SQL (via) Max Halford trains an online gradient descent model against two years of AAPL stock data using just a single advanced SQL query. He built this against DuckDB—I tried to replicate his query in SQLite and it almost worked, but it gave me a “recursive reference in a subquery” error that I was unable to resolve.
You will not use the Software for any act that may undermine China's national security and national unity, harm the public interest of society, or infringe upon the rights and interests of human beings.
2022
These kinds of biases aren’t so much a technical problem as a sociotechnical one; ML models try to approximate biases in their underlying datasets and, for some groups of people, some of these biases are offensive or harmful. That means in the coming years there will be endless political battles about what the ‘correct’ biases are for different models to display (or not display), and we can ultimately expect there to be as many approaches as there are distinct ideologies on the planet. I expect to move into a fractal ecosystem of models, and I expect model providers will ‘shapeshift’ a single model to display different biases depending on the market it is being deployed into. This will be extraordinarily messy.
Semantic text search using embeddings. Example Python notebook from OpenAI demonstrating how to build a search engine using embeddings rather than straight up token matching. This is a fascinating way of implementing search, providing results that match the intent of the search (“delicious beans” for example) even if none of the keywords are actually present in the text.
Is the AI spell-casting metaphor harmful or helpful?
For a few weeks now I’ve been promoting spell-casting as a metaphor for prompt design against generative AI systems such as GPT-3 and Stable Diffusion.
[... 990 words]konstantint/SKompiler (via) A tool for compiling trained SKLearn models into other representations —including SQL queries and Excel formulas. I’ve been pondering the most light-weight way to package a simple machine learning model as part of a larger application without needing to bundle heavy dependencies, this set of techniques looks ideal!
Exploring 10m scraped Shutterstock videos used to train Meta’s Make-A-Video text-to-video model
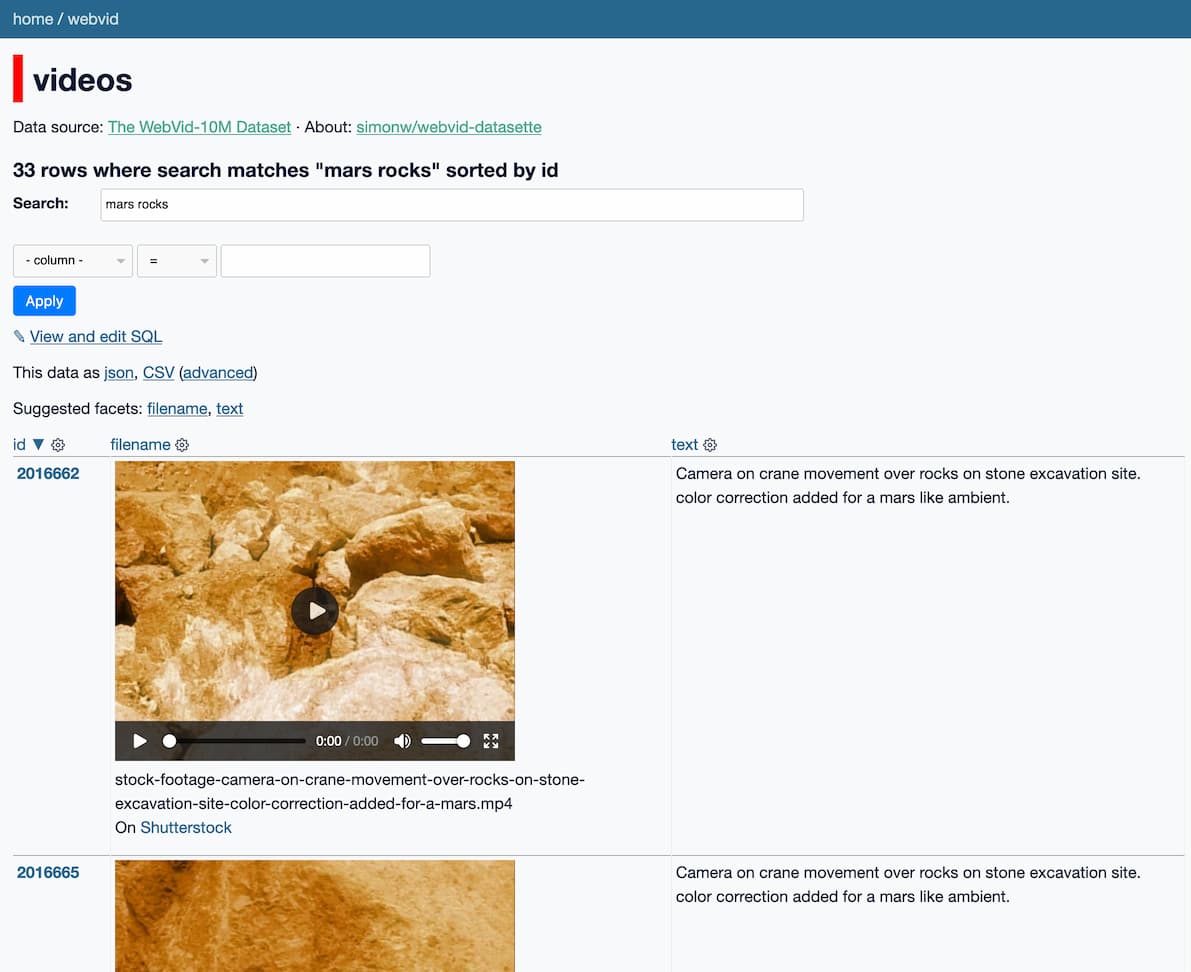
Make-A-Video is a new “state-of-the-art AI system that generates videos from text” from Meta AI. It looks incredible—it really is DALL-E / Stable Diffusion for video. And it appears to have been trained on 10m video preview clips scraped from Shutterstock.
[... 923 words]Running training jobs across multiple nodes scales really well. A common assumption is that scale inevitably means slowdowns: more GPUs means more synchronization overhead, especially with multiple nodes communicating across a network. But we observed that the performance penalty isn’t as harsh as what you might think. Instead, we found near-linear strong scaling: fixing the global batch size and training on more GPUs led to proportional increases in training throughput. On a 1.3B parameter model, 4 nodes means a 3.9x gain over one node. On 16 nodes, it’s 14.4x. This is largely thanks to the super fast interconnects that major cloud providers have built in: @awscloud EC2 P4d instances provide 400 Gbps networking bandwidth, @Azure provides 1600 Gbps, and @OraclePaaS provides 800 Gbps.
I Resurrected “Ugly Sonic” with Stable Diffusion Textual Inversion (via) “I trained an Ugly Sonic object concept on 5 image crops from the movie trailer, with 6,000 steps [...] (on a T4 GPU, this took about 1.5 hours and cost about $0.21 on a GCP Spot instance)”
An introduction to XGBoost regression. I hadn’t realized what a wealth of high quality tutorial material could be found in Kaggle notebooks. Here Carl McBride Ellis provides a very approachable and practical introduction to XGBoost, one of the leading techniques for building machine learning models against tabular data.
In a previous iteration of the machine learning paradigm, researchers were obsessed with cleaning their datasets and ensuring that every data point seen by their models is pristine, gold-standard, and does not disturb the fragile learning process of billions of parameters finding their home in model space. Many began to realize that data scale trumps most other priorities in the deep learning world; utilizing general methods that allow models to scale in tandem with the complexity of the data is a superior approach. Now, in the era of LLMs, researchers tend to dump whole mountains of barely filtered, mostly unedited scrapes of the internet into the eager maw of a hungry model.
— roon
karpathy/minGPT (via) A “minimal PyTorch re-implementation” of the OpenAI GPT training and inference model, by Andrej Karpathy. It’s only a few hundred lines of code and includes extensive comments, plus notebook demos.
r/MachineLearning: What is the SOTA explanation for why deep learning works? The thing I find fascinating about this Reddit conversation is that it makes it clear that the machine learning research community has very little agreement on WHY the state of the art techniques that are being used today actually work as well as they do.
Run Stable Diffusion on your M1 Mac’s GPU. Ben Firshman provides detailed instructions for getting Stable Diffusion running on an M1 Mac.
Exploring 12 Million of the 2.3 Billion Images Used to Train Stable Diffusion’s Image Generator. Andy Baio and I collaborated on an investigation into the training set used for Stable Diffusion. I built a Datasette instance with 12m image records sourced from the LAION-Aesthetics v2 6+ aesthetic score data used as part of the training process, and built a tool so people could run searches and explore the data. Andy did some extensive analysis of things like the domains scraped for the images and names of celebrities and artists represented in the data. His write-up here explains our project in detail and some of the patterns we’ve uncovered so far.
Stable Diffusion is a really big deal
If you haven’t been paying attention to what’s going on with Stable Diffusion, you really should be.
[... 1,443 words]