Exploring 10m scraped Shutterstock videos used to train Meta’s Make-A-Video text-to-video model
29th September 2022
Make-A-Video is a new “state-of-the-art AI system that generates videos from text” from Meta AI. It looks incredible—it really is DALL-E / Stable Diffusion for video. And it appears to have been trained on 10m video preview clips scraped from Shutterstock.
I built a new search engine to explore those ten million clips:
https://webvid.datasette.io/webvid/videos
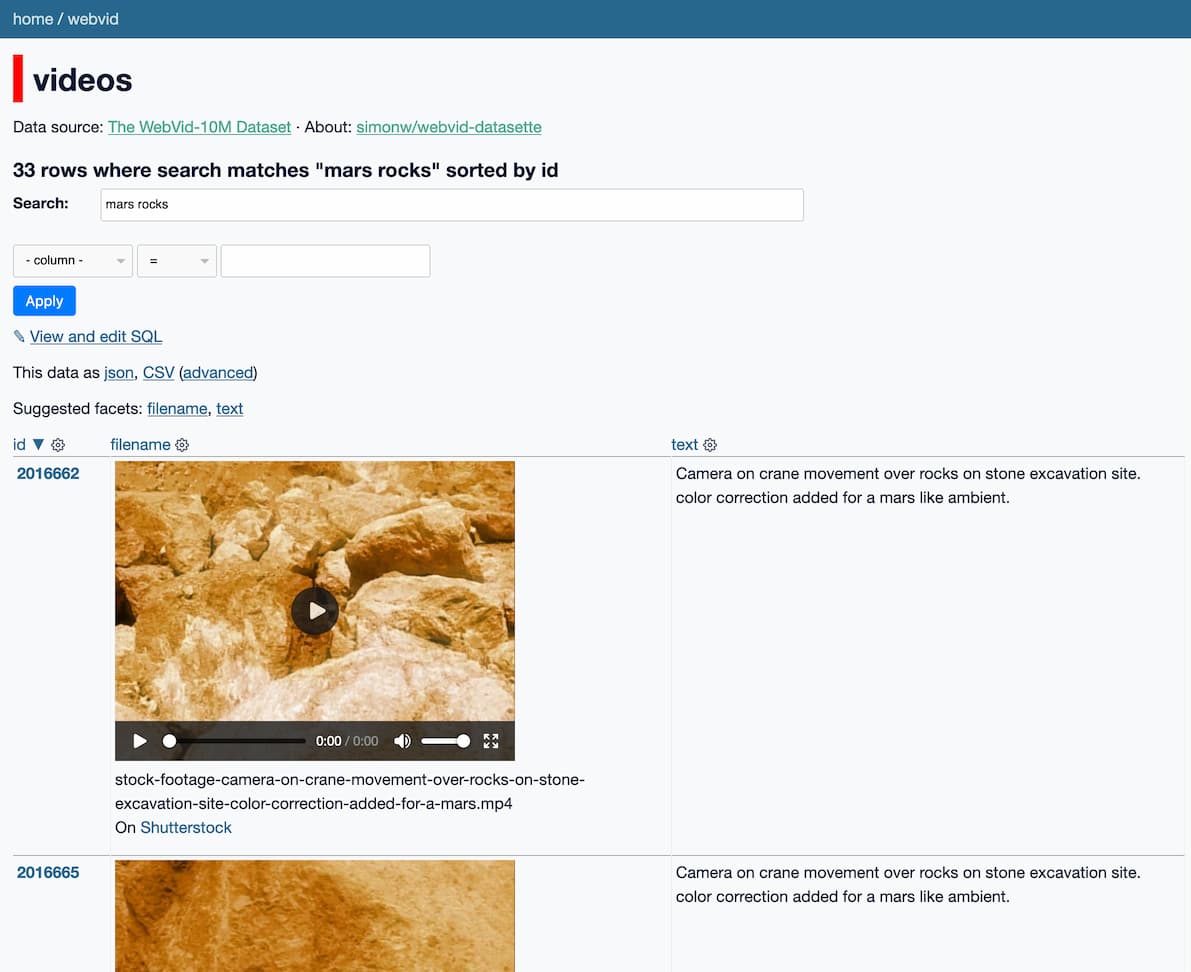
This is similar to the system I built with Andy Baio a few weeks ago to explore the LAION data used to train Stable Diffusion.
Make-A-Video training data
Meta AI’s paper describing the model includes this section about the training data:
Datasets. To train the image models, we use a 2.3B subset of the dataset from (Schuhmann et al.) where the text is English. We filter out sample pairs with NSFW images 2, toxic words in the text, or images with a watermark probability larger than 0.5.
We use WebVid-10M (Bain et al., 2021) and a 10M subset from HD-VILA-100M (Xue et al., 2022) 3 to train our video generation models. Note that only the videos (no aligned text) are used.
The decoder Dt and the interpolation model is trained on WebVid-10M. SRt l is trained on both WebVid-10M and HD-VILA-10M. While prior work (Hong et al., 2022; Ho et al., 2022) have collected private text-video pairs for T2V generation, we use only public datasets (and no paired text for videos). We conduct automatic evaluation on UCF-101 (Soomro et al., 2012) and MSR-VTT (Xu et al., 2016) in a zero-shot setting.
That 2.3B subset of images is the same LAION data I explored previously.
HD-VILA-100M was collected by Microsoft Research Asia—Andy Baio notes that these were scraped from YouTube.
I decided to take a look at the WebVid-10M data.
WebVid-10M
The WebVid-10M site describes the data like this:
WebVid-10M is a large-scale dataset of short videos with textual descriptions sourced from the web. The videos are diverse and rich in their content.
The accompanying paper provides a little bit more detail:
We scrape the web for a new dataset of videos with textual description annotations, called WebVid-2M. Our dataset consists of 2.5M video-text pairs, which is an order of magnitude larger than existing video captioning datasets (see Table 1).
The data was scraped from the web following a similar procedure to Google Conceptual Captions [55] (CC3M). We note that more than 10% of CC3M images are in fact thumbnails from videos, which motivates us to use such video sources to scrape a total of 2.5M text-video pairs. The use of data collected for this study is authorised via the Intellectual Property Office’s Exceptions to Copyright for Non-Commercial Research and Private Study.
I’m presuming that Web-10M is a larger version of the WebVid-2M dataset described in the paper.
Most importantly though, the website includes a link to a 2.7GB CSV file—results_10M_train.csv—containing the full WebVid-10M dataset. The CSV file looks like this:
videoid,contentUrl,duration,page_dir,name
21179416,https://ak.picdn.net/shutterstock/videos/21179416/preview/stock-footage-aerial-shot-winter-forest.mp4,PT00H00M11S,006001_006050,Aerial shot winter forest
5629184,https://ak.picdn.net/shutterstock/videos/5629184/preview/stock-footage-senior-couple-looking-through-binoculars-on-sailboat-together-shot-on-red-epic-for-high-quality-k.mp4,PT00H00M29S,071501_071550,"Senior couple looking through binoculars on sailboat together. shot on red epic for high quality 4k, uhd, ultra hd resolution."
I loaded it into SQLite and started digging around.
It’s all from Shutterstock!
The big surprise for me when I started exploring the data was this: every single one of the 10,727,582 videos linked in the Datasette started with the same URL prefix:
https://ak.picdn.net/shutterstock/videos/
They’re all from Shutterstock. The paper talks about “scraping the web”, but it turns out there was only one scraped website involved.
Here’s that first row from the CSV file on Shutterstock itself:
https://www.shutterstock.com/video/clip-21179416-aerial-shot-winter-forest
As far as I can tell, the training set used here isn’t even full Shutterstock videos: it’s the free, watermarked preview clips that Shutterstock makes available.
I guess Shutterstock have really high quality captions for their videos, perfect for training a model on.
Implementation notes
My simonw/webvid-datasette repository contains the code I used to build the Datasette instance.
I built a SQLite database with full-text search enabled using sqlite-utils. I deployed it directly to Fly by building a Docker image that bundled the 2.5G SQLite database, taking advantage of the Baked Data architectural pattern.
The most interesting custom piece of implementation is the plugin I wrote to add a video player to each result. Here’s the implementation of that plugin:
from datasette import hookimpl from markupsafe import Markup TEMPLATE = """ <video controls width="400" preload="none" poster="{poster}"> <source src="{url}" type="video/mp4"> </video> <p>{filename}<br>On <a href="https://www.shutterstock.com/video/clip-{id}">Shutterstock</a></p> """.strip() VIDEO_URL = "https://ak.picdn.net/shutterstock/videos/{id}/preview/{filename}" POSTER_URL = "https://ak.picdn.net/shutterstock/videos/{id}/thumb/1.jpg?ip=x480" @hookimpl def render_cell(row, column, value): if column != "filename": return id = row["id"] url = VIDEO_URL.format(id=id, filename=value) poster = POSTER_URL.format(id=id) return Markup(TEMPLATE.format(url=url, poster=poster, filename=value, id=id))
I’m using the new render_cell(row) argument added in Datasette 0.62.
The plugin outputs a <video> element with preload="none" to avoid the browser downloading the video until the user clicks play (see this TIL). I set the poster attribute to a thumbnail image from Shutterstock.
More recent articles
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026
- The new GPT-5.6 family: Luna, Terra, Sol - 9th July 2026