Series: How it's trained
Investigating the training data behind different machine learning models.
Exploring the training data behind Stable Diffusion
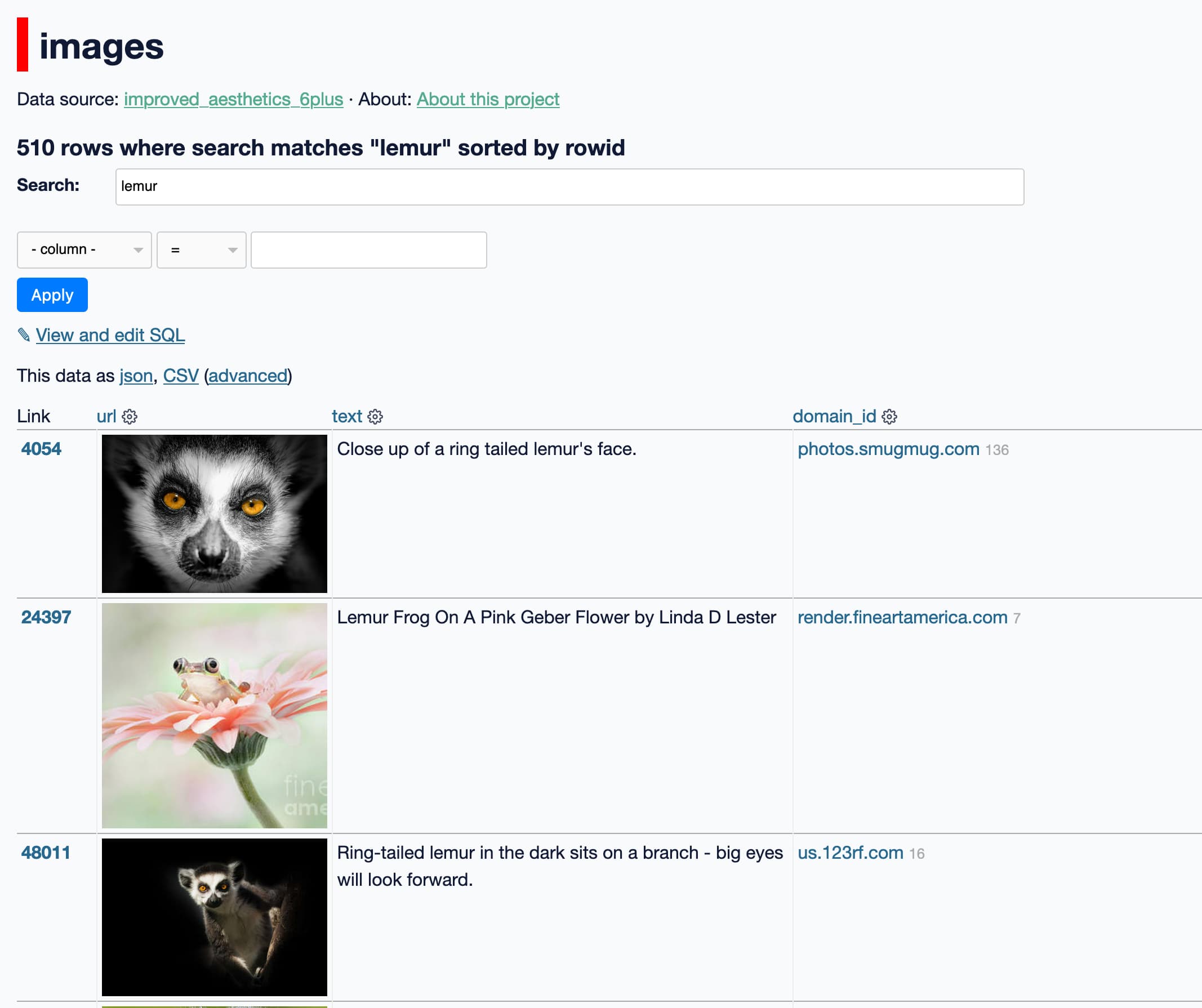
Two weeks ago, the Stable Diffusion image generation model was released to the public. I wrote about this last week, in Stable Diffusion is a really big deal—a post which has since become one of the top ten results for “stable diffusion” on Google and shown up in all sorts of different places online.
[... 2,897 words]Exploring 10m scraped Shutterstock videos used to train Meta’s Make-A-Video text-to-video model
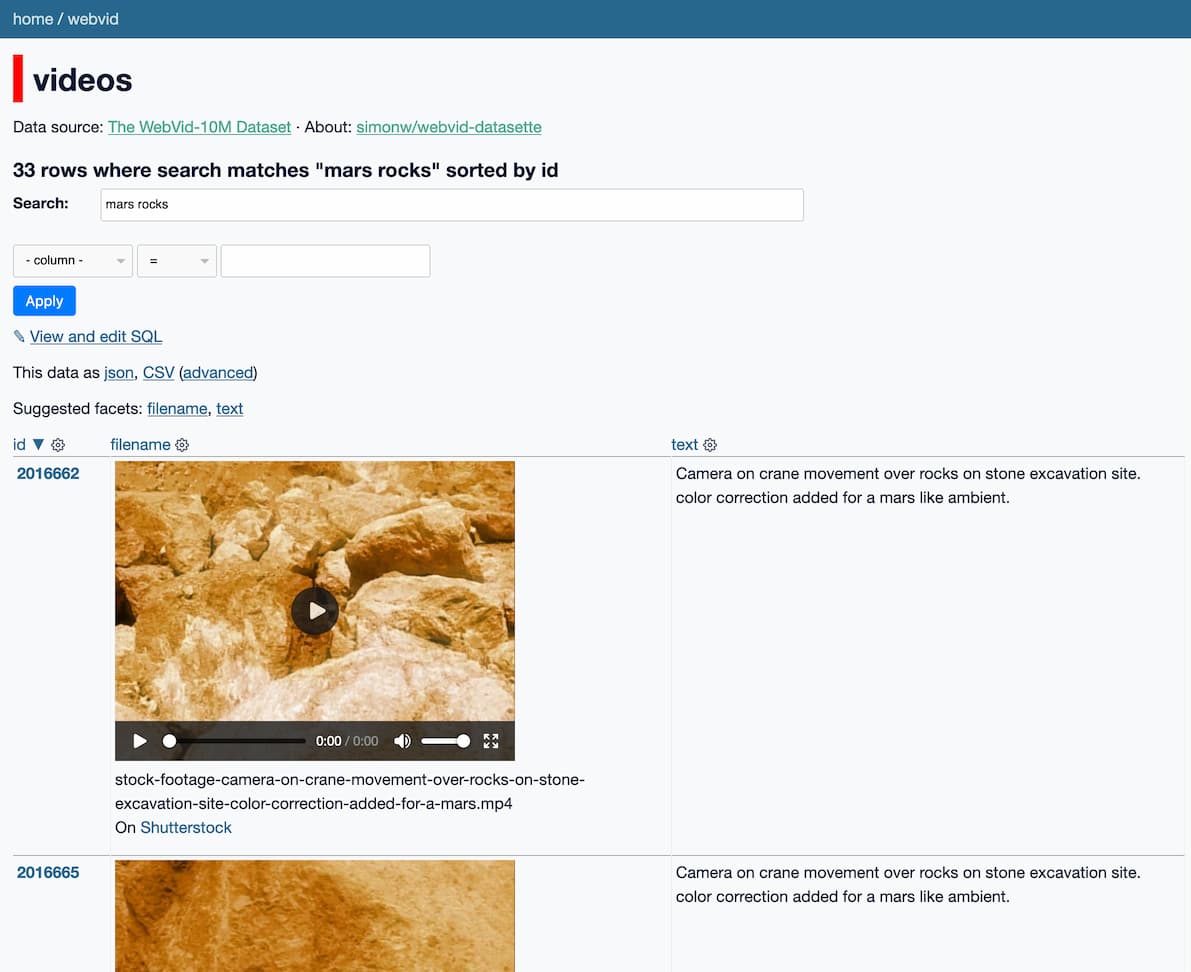
Make-A-Video is a new “state-of-the-art AI system that generates videos from text” from Meta AI. It looks incredible—it really is DALL-E / Stable Diffusion for video. And it appears to have been trained on 10m video preview clips scraped from Shutterstock.
[... 923 words]Exploring MusicCaps, the evaluation data released to accompany Google’s MusicLM text-to-music model
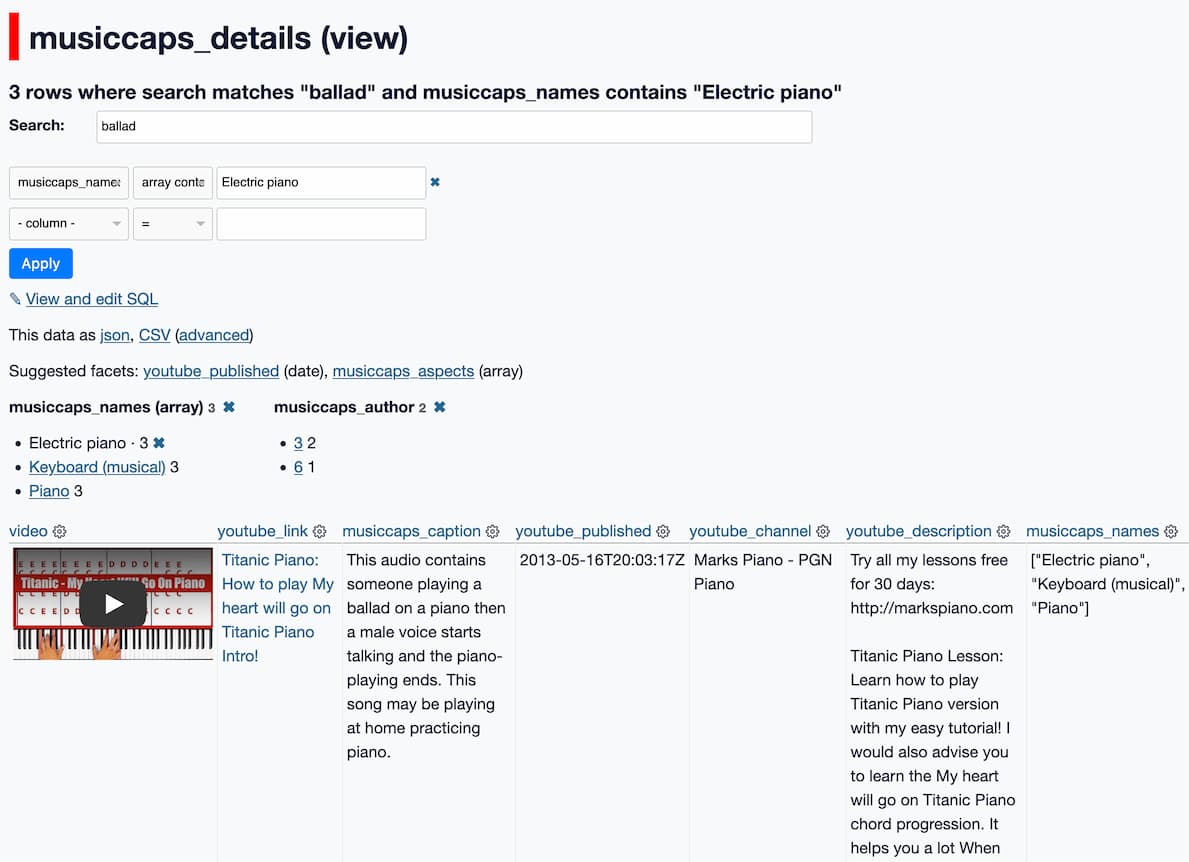
Google Research just released MusicLM: Generating Music From Text. It’s a new generative AI model that takes a descriptive prompt and produces a “high-fidelity” music track. Here’s the paper (and a more readable version using arXiv Vanity).
[... 1,323 words]What’s in the RedPajama-Data-1T LLM training set
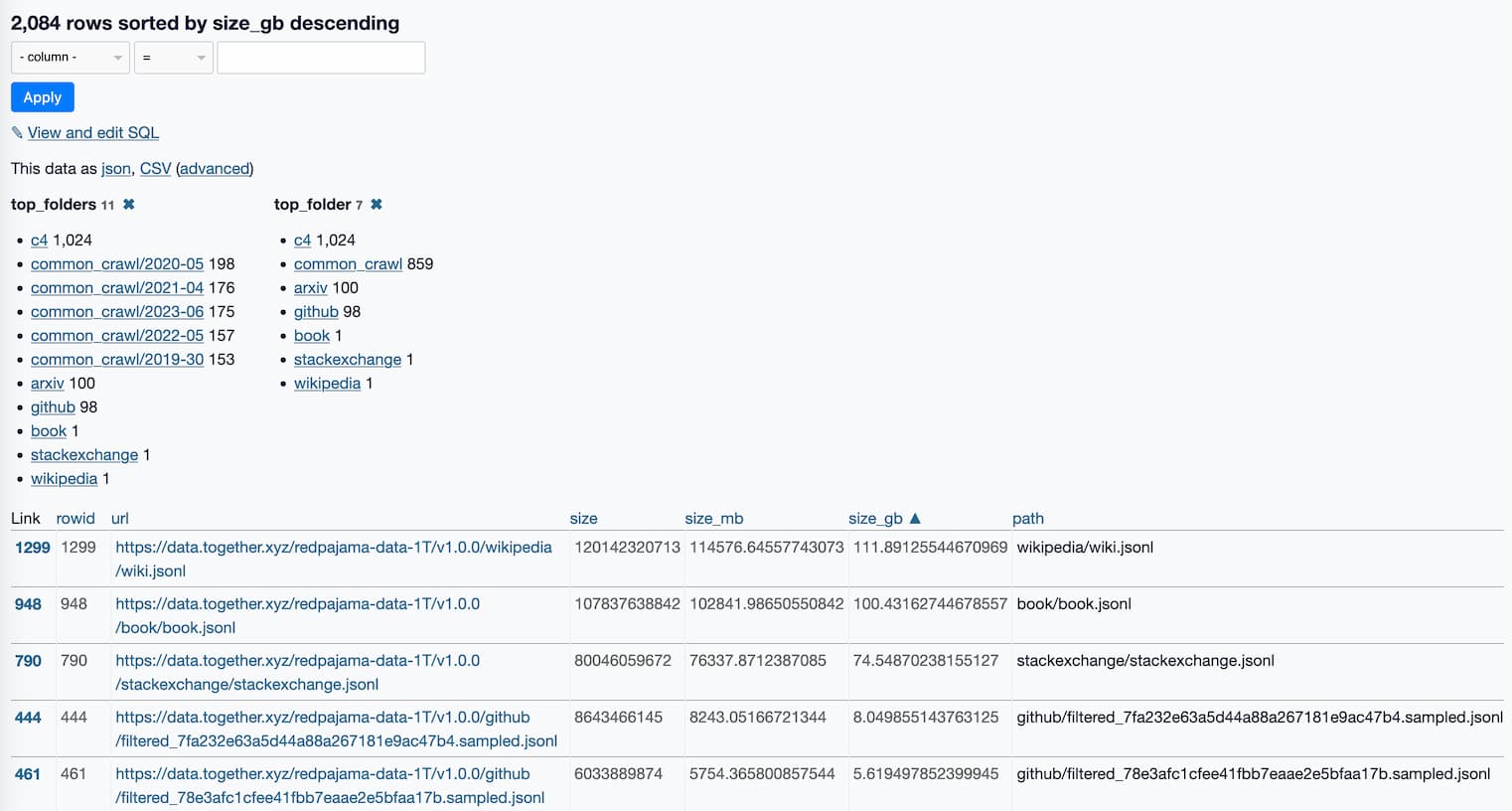
RedPajama is “a project to create leading open-source models, starts by reproducing LLaMA training dataset of over 1.2 trillion tokens”. It’s a collaboration between Together, Ontocord.ai, ETH DS3Lab, Stanford CRFM, Hazy Research, and MILA Québec AI Institute.
[... 1,077 words]