What’s in the RedPajama-Data-1T LLM training set
17th April 2023
RedPajama is “a project to create leading open-source models, starts by reproducing LLaMA training dataset of over 1.2 trillion tokens”. It’s a collaboration between Together, Ontocord.ai, ETH DS3Lab, Stanford CRFM, Hazy Research, and MILA Québec AI Institute.
They just announced their first release: RedPajama-Data-1T, a 1.2 trillion token dataset modelled on the training data described in the original LLaMA paper.
The full dataset is 2.67TB, so I decided not to try and download the whole thing! Here’s what I’ve figured out about it so far.
How to download it
The data is split across 2,084 different files. These are listed in a plain text file here:
https://data.together.xyz/redpajama-data-1T/v1.0.0/urls.txt
The dataset card suggests you could download them all like this—assuming you have 2.67TB of disk space and bandwith to spare:
wget -i https://data.together.xyz/redpajama-data-1T/v1.0.0/urls.txt
I prompted GPT-4 a few times to write a quick Python script to run a HEAD request against each URL in that file instead, in order to collect the Content-Length and calculate the total size of the data. My script is at the bottom of this post.
I then processed the size data into a format suitable for loading into Datasette Lite.
Exploring the size data
Here’s a link to a Datasette Lite page showing all 2,084 files, sorted by size and with some useful facets.
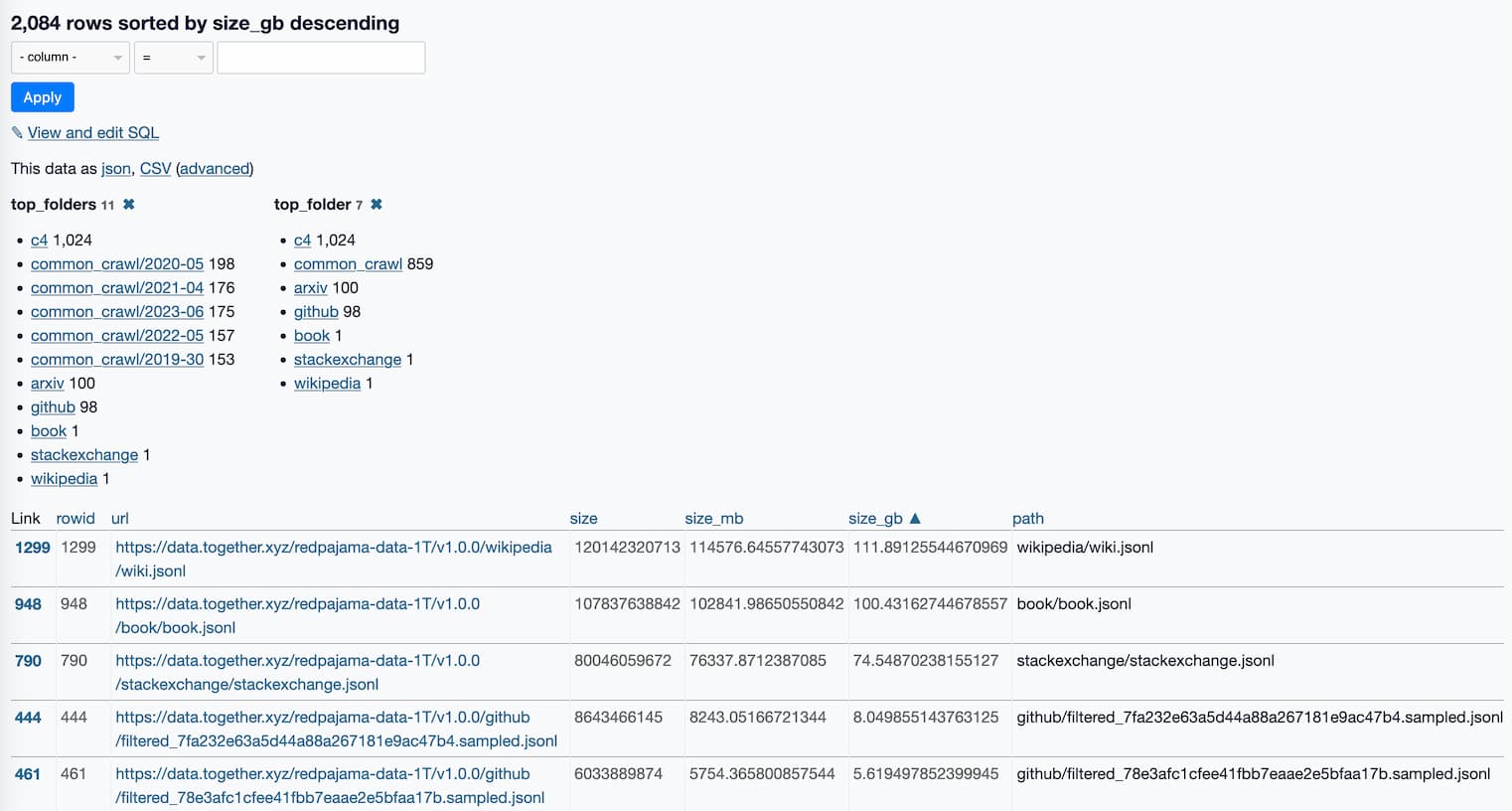
This is already revealing a lot about the data.
The top_folders facet inspired me to run this SQL query:
select
top_folders,
cast (sum(size_gb) as integer) as total_gb,
count(*) as num_files
from raw
group by top_folders
order by sum(size_gb) descHere are the results:
| top_folders | total_gb | num_files |
|---|---|---|
| c4 | 806 | 1024 |
| common_crawl/2023-06 | 288 | 175 |
| common_crawl/2020-05 | 286 | 198 |
| common_crawl/2021-04 | 276 | 176 |
| common_crawl/2022-05 | 251 | 157 |
| common_crawl/2019-30 | 237 | 153 |
| github | 212 | 98 |
| wikipedia | 111 | 1 |
| book | 100 | 1 |
| arxiv | 87 | 100 |
| stackexchange | 74 | 1 |
There’s a lot of Common Crawl data in there!
The RedPajama announcement says:
- CommonCrawl: Five dumps of CommonCrawl, processed using the CCNet pipeline, and filtered via several quality filters including a linear classifier that selects for Wikipedia-like pages.
- C4: Standard C4 dataset
It looks like they used CommonCrawl from 5 different dates, from 2019-30 (30? That’s not a valid month—looks like it’s a week number) to 2022-05. I wonder if they de-duplicated content within those different crawls?
C4 is “a colossal, cleaned version of Common Crawl’s web crawl corpus”—so yet another copy of Common Crawl, cleaned in a different way.
I downloaded the first 100MB of that 100GB book.jsonl file—the first 300 rows in it are all full-text books from Project Gutenberg, starting with The Bible Both Testaments King James Version from 1611.
The data all appears to be in JSONL format—newline-delimited JSON. Different files I looked at had different shapes, though a common pattern was a "text" key containing the text and a "meta" key containing a dictionary of metadata.
For example, the first line of books.jsonl looks like this (after pretty-printing using jq):
{
"meta": {
"short_book_title": "The Bible Both Testaments King James Version",
"publication_date": 1611,
"url": "http://www.gutenberg.org/ebooks/10"
},
"text": "\n\nThe Old Testament of the King James Version of the Bible\n..."
}There are more details on the composition of the dataset in the dataset card.
My Python script
I wrote a quick Python script to do the next best thing: run a HEAD request against each URL to figure out the total size of the data.
I prompted GPT-4 a few times, and came up with this:
import httpx from tqdm import tqdm async def get_sizes(urls): sizes = {} async def fetch_size(url): try: response = await client.head(url) content_length = response.headers.get('Content-Length') if content_length is not None: return url, int(content_length) except Exception as e: print(f"Error while processing URL '{url}': {e}") return url, 0 async with httpx.AsyncClient() as client: # Create a progress bar using tqdm with tqdm(total=len(urls), desc="Fetching sizes", unit="url") as pbar: # Use asyncio.as_completed to process results as they arrive coros = [fetch_size(url) for url in urls] for coro in asyncio.as_completed(coros): url, size = await coro sizes[url] = size # Update the progress bar pbar.update(1) return sizes
I pasted this into python3 -m asyncio—the -m asyncio flag ensures the await statement can be used in the interactive interpreter—and ran the following:
>>> urls = httpx.get("https://data.together.xyz/redpajama-data-1T/v1.0.0/urls.txt").text.splitlines()
>>> sizes = await get_sizes(urls)
Fetching sizes: 100%|██████████████████████████████████████| 2084/2084 [00:08<00:00, 256.60url/s]
>>> sum(sizes.values())
2936454998167Then I added the following to turn the data into something that would work with Datasette Lite:
output = [] for url, size in sizes.items(): path = url.split('/redpajama-data-1T/v1.0.0/')[1] output.append({ "url": url, "size": size, "size_mb": size / 1024 / 1024, "size_gb": size / 1024 / 1024 / 1024, "path": path, "top_folder": path.split("/")[0], "top_folders": path.rsplit("/", 1)[0], }) open("/tmp/sizes.json", "w").write(json.dumps(output, indent=2))
I pasted the result into a Gist.