4 posts tagged “redpajama”
2023
MLC: Bringing Open Large Language Models to Consumer Devices (via) “We bring RedPajama, a permissive open language model to WebGPU, iOS, GPUs, and various other platforms.” I managed to get this running on my Mac (see via link) with a few tweaks to their official instructions.
OpenLLaMA. The first openly licensed model I’ve seen trained on the RedPajama dataset. This initial release is a 7B model trained on 200 billion tokens, but the team behind it are promising a full 1 trillion token model in the near future. I haven’t found a live demo of this one running anywhere yet.
What’s in the RedPajama-Data-1T LLM training set
RedPajama is “a project to create leading open-source models, starts by reproducing LLaMA training dataset of over 1.2 trillion tokens”. It’s a collaboration between Together, Ontocord.ai, ETH DS3Lab, Stanford CRFM, Hazy Research, and MILA Québec AI Institute.
[... 1,077 words]RedPajama, a project to create leading open-source models, starts by reproducing LLaMA training dataset of over 1.2 trillion tokens. With the amount of projects that have used LLaMA as a foundation model since its release two months ago—despite its non-commercial license—it’s clear that there is a strong desire for a fully openly licensed alternative.
RedPajama is a collaboration between Together, Ontocord.ai, ETH DS3Lab, Stanford CRFM, Hazy Research, and MILA Québec AI Institute aiming to build exactly that.
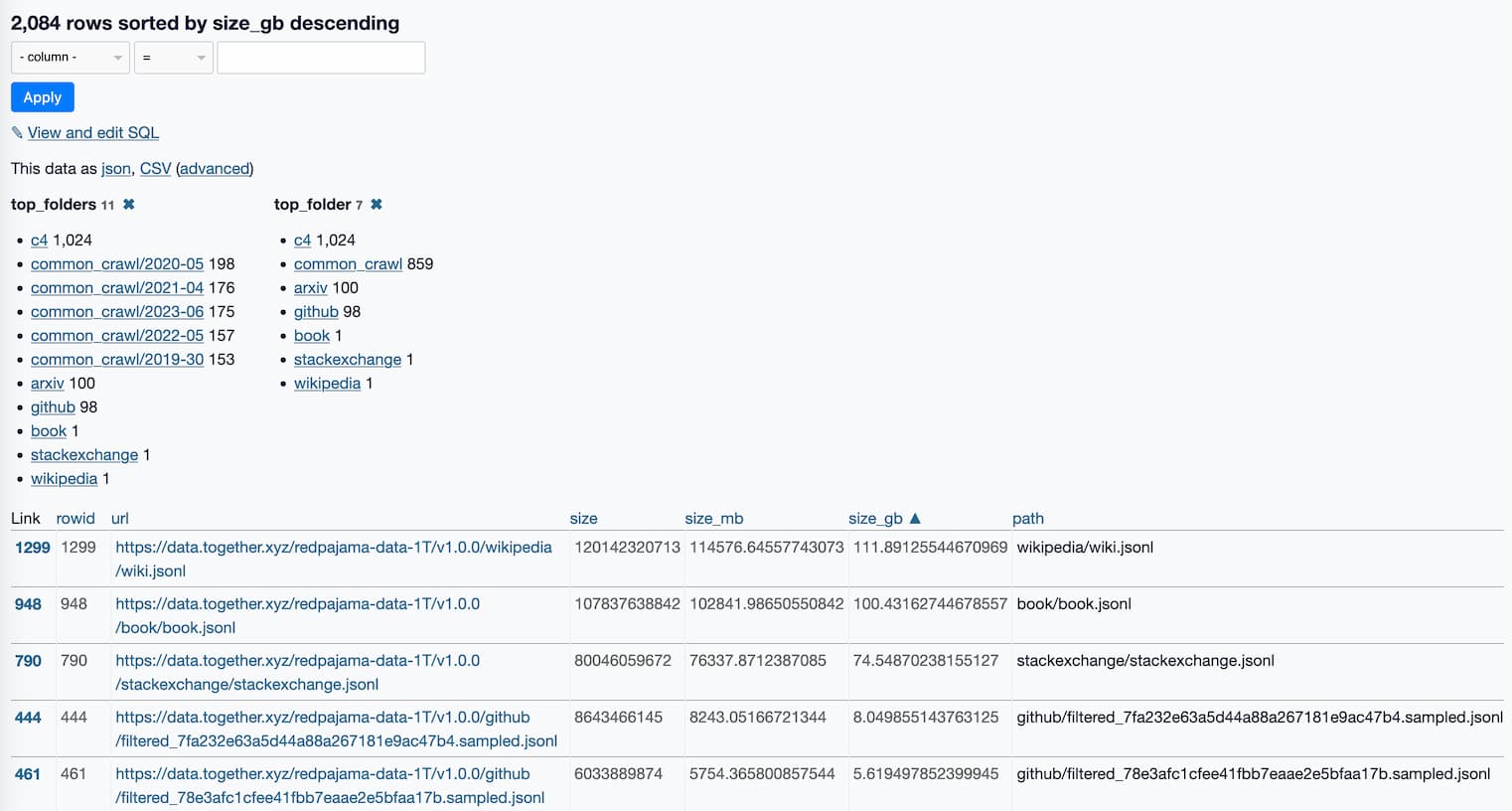
Step one is gathering the training data: the LLaMA paper described a 1.2 trillion token training set gathered from sources that included Wikipedia, Common Crawl, GitHub, arXiv, Stack Exchange and more.
RedPajama-Data-1T is an attempt at recreating that training set. It’s now available to download, as 2,084 separate multi-GB jsonl files—2.67TB total.
Even without a trained model, this is a hugely influential contribution to the world of open source LLMs. Any team looking to build their own LLaMA from scratch can now jump straight to the next stage, training the model.