400 posts tagged “ai-assisted-programming”
Using AI tools such as Large Language Models to help write code. Vibe coding is the less responsible subset of this. See Here’s how I use LLMs to help me write code for a description of my process.
2026
I keep hearing anecdotes from people who used coding agents to reverse-engineer and automate devices in their homes.
I think this is an interesting illustration of the impact of the reduced cost of writing code.
Prior to agents, it was entirely possible to reverse-engineer home devices. The problem was the ROI - was it really worth all of that effort? More importantly, any experienced programmer knows that undocumented, unstable APIs like that may well change or break in the future. Is that initial work worth the effort if you're committing yourself to a frustrating cycle of maintenance in the future?
Coding agents change that equation entirely. The effort to get a simple automation working has dropped, as has the cost of trying and failing to get it to work. Since the code is so cheap, the idea of having to maintain it in the future - or throw it away and start again - carries way less psychological baggage.
Firefox in WebAssembly (via) This is absurdly cool: Puter compiled Firefox to WebAssembly such that the whole browser runs in another browser.
Here's my blog, running in Firefox, running in WebAssembly, running in Chrome:
They chose Firefox/Gecko because it has strong single-process support. The project used an estimated $25,000 worth of Claude Opus and Fable tokens, but took advantage of a Claude Max subscription plan so cost much less in actual dollars.
The demo funnels all traffic over a WebSocket protocol (using the Wisp protocol) through Puter's server - a requirement to get this kind of thing to work because code running in browsers can't open arbitrary network connections.
(That proxying sounds expensive! The team had to scale the servers up to handle the traffic during the Hacker News conversation about the project.)
Puter claim this supports end-to-end encryption and that looks to be true - I inspected the WebSocket messages and traffic to my own HTTPS site was encrypted whereas requests and responses to http://www.example.com/ were in cleartext.
Here's the repo for firefox-wasm. theogbob/WebkitWasm is a similar project that compiles WebKit to WASM, but that one doesn't currently have an accessible online demo.
The shared language of a software project is not English or Python but it is the common understanding of what its concepts mean, where the boundaries are, which invariants matter, who owns what, and why the system has the shape it does. This language is rarely written down in one place. It lives partly in documentation and code, but also in code review, conversations, arguments, and the experience of having to explain a change to somebody else.
Before agents, some of this shared understanding was maintained by friction. If I wanted to change your storage layer, I usually had to read your code, ask you questions, and perhaps coordinate with another team whose service depended on it. This was slow, and much of that slowness was waste but not all of it was. Some of it was the process by which your understanding became mine, and by which both of us discovered whether we still agreed about how the system worked. This friction synchronizes people.
— Armin Ronacher, The Tower Keeps Rising
DOOMQL (via) Peter Gostev built this using GPT-5.6 Sol. This is a lot of fun:
DOOMQL started with a deliberately unreasonable question: what if SQLite were the game engine, not merely the place where a game stores data?
The result is a small, original Doom-like game in which SQL owns movement, collision, enemies, combat, progression and every RGB pixel on screen.
It's implemented as a Python terminal script - I tried it out like this:
cd /tmp
git clone https://github.com/petergpt/doomql
cd doomql
uv run host/doomql.py
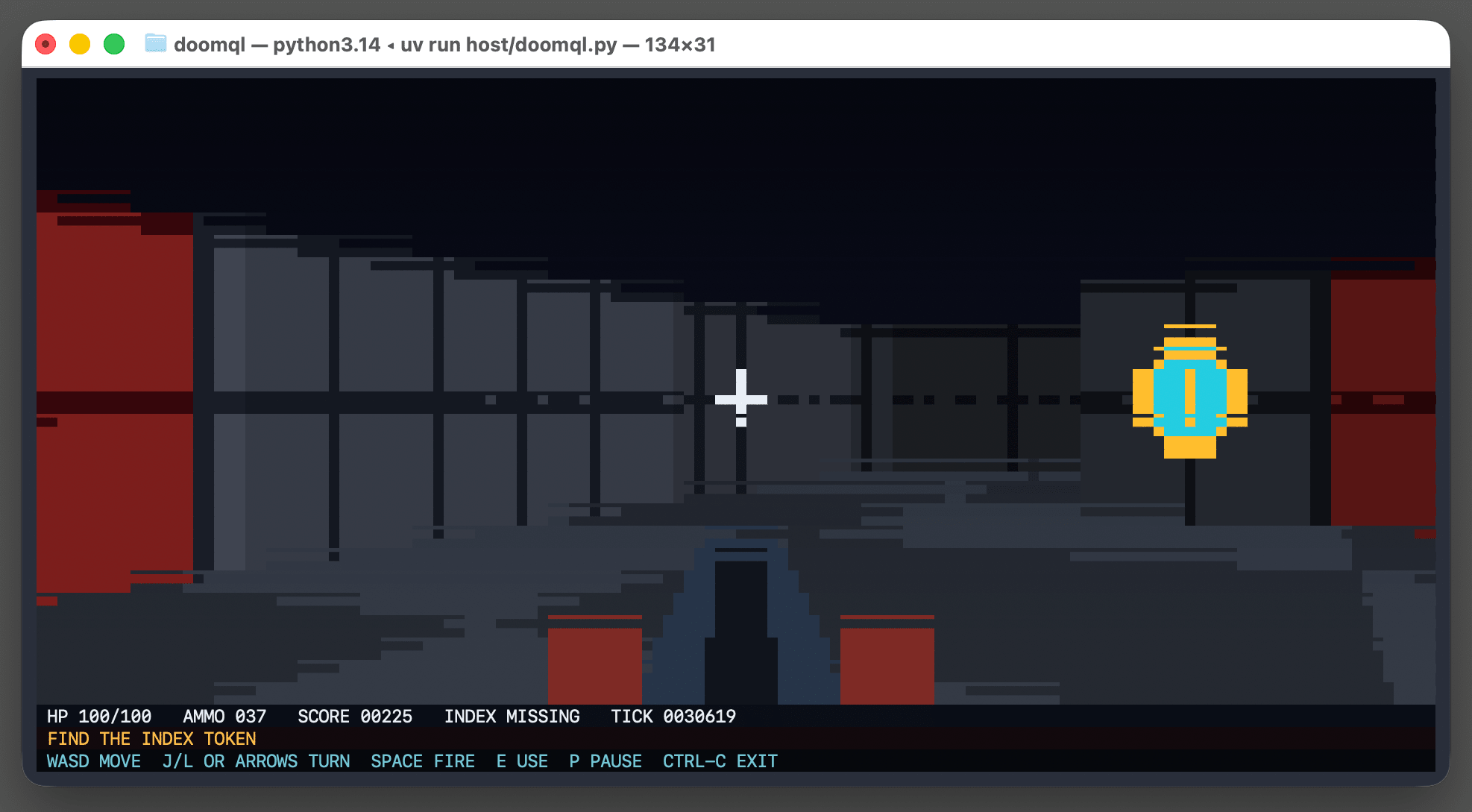
Here's the huge SQL query that implements a full ray tracer in SQLite using a recursive CTE.
Running the above script creates a /tmp/doomql/.doomql/doomql.sqlite SQLite database, which you can explore using Datasette like this:
uvx --prerelease=allow --with datasette-apps datasette \
/tmp/doomql/.doomql/doomql.sqlite \
-p 4444 --root --secret 1 --internal internal.db
The --with datasette-apps option installs the new Datasette Apps plugin, which supports creating custom HTML+JavaScript apps that can run SQL queries directly within the Datasette interface.
I created a new app, pasted the copy-paste prompt into Claude chat (Fable 5) and told it:
Build an app that displays the current state of the screen using the frame_pixels view with its x, y, r, g, b columns. have it refresh once a second.
This got me a working HTML+JavaScript app inside Datasette that could reflect the current state while I played the game in my terminal. Then I added:
add a minimap
And now my Datasette App looks like this:
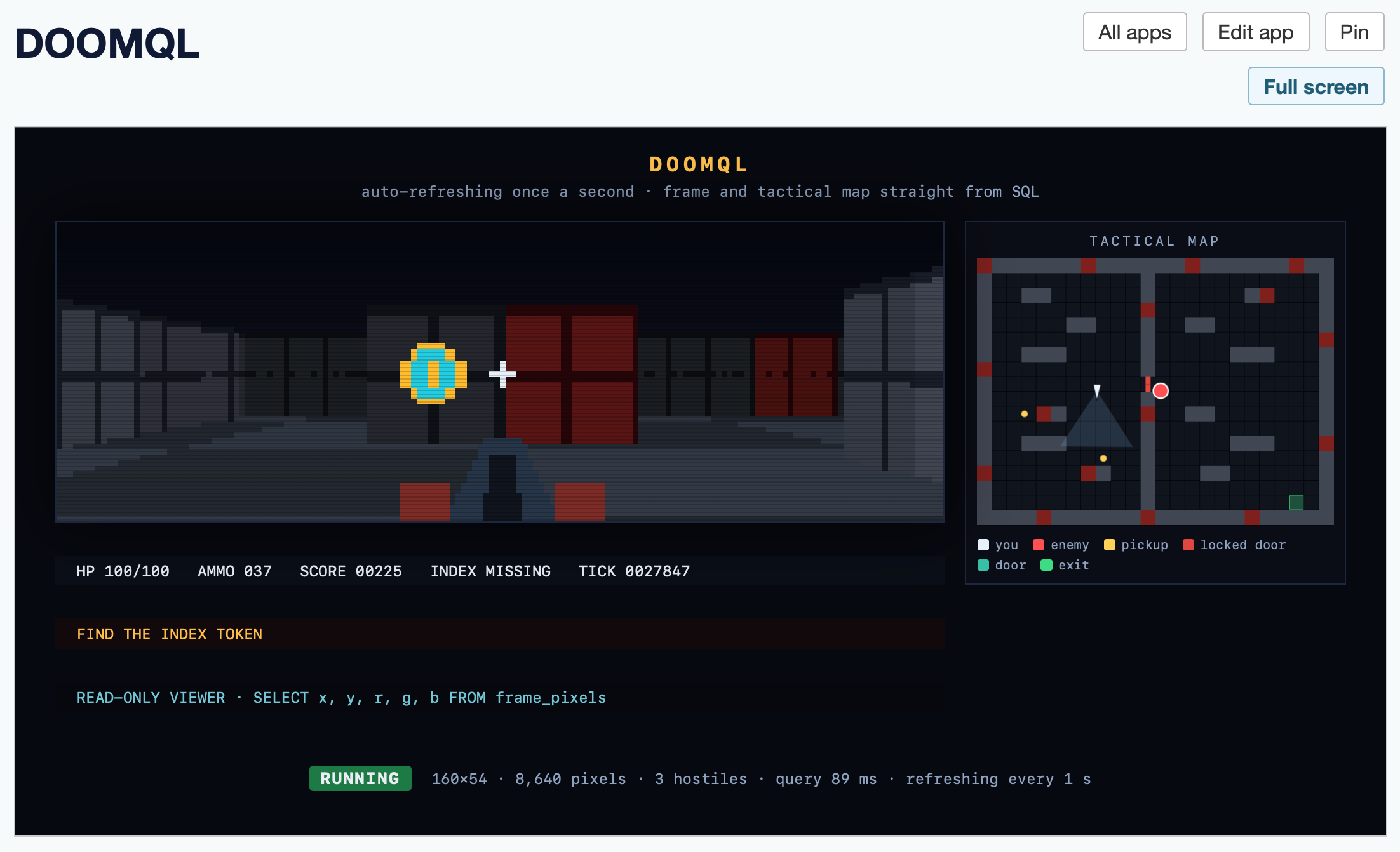
Here's the HTML app code - paste that into your own Datasette instance (using the uvx --with datasette-apps recipe from above) to try it yourself.
datasette code-frequency chart on GitHub. Out of curiosity I decided to see if I could find a useful illustration of the impact of coding agents and Opus 4.5 class models on my own output. The best I've found so far is this GitHub chart of frequency of code changes to my Datasette open source project:
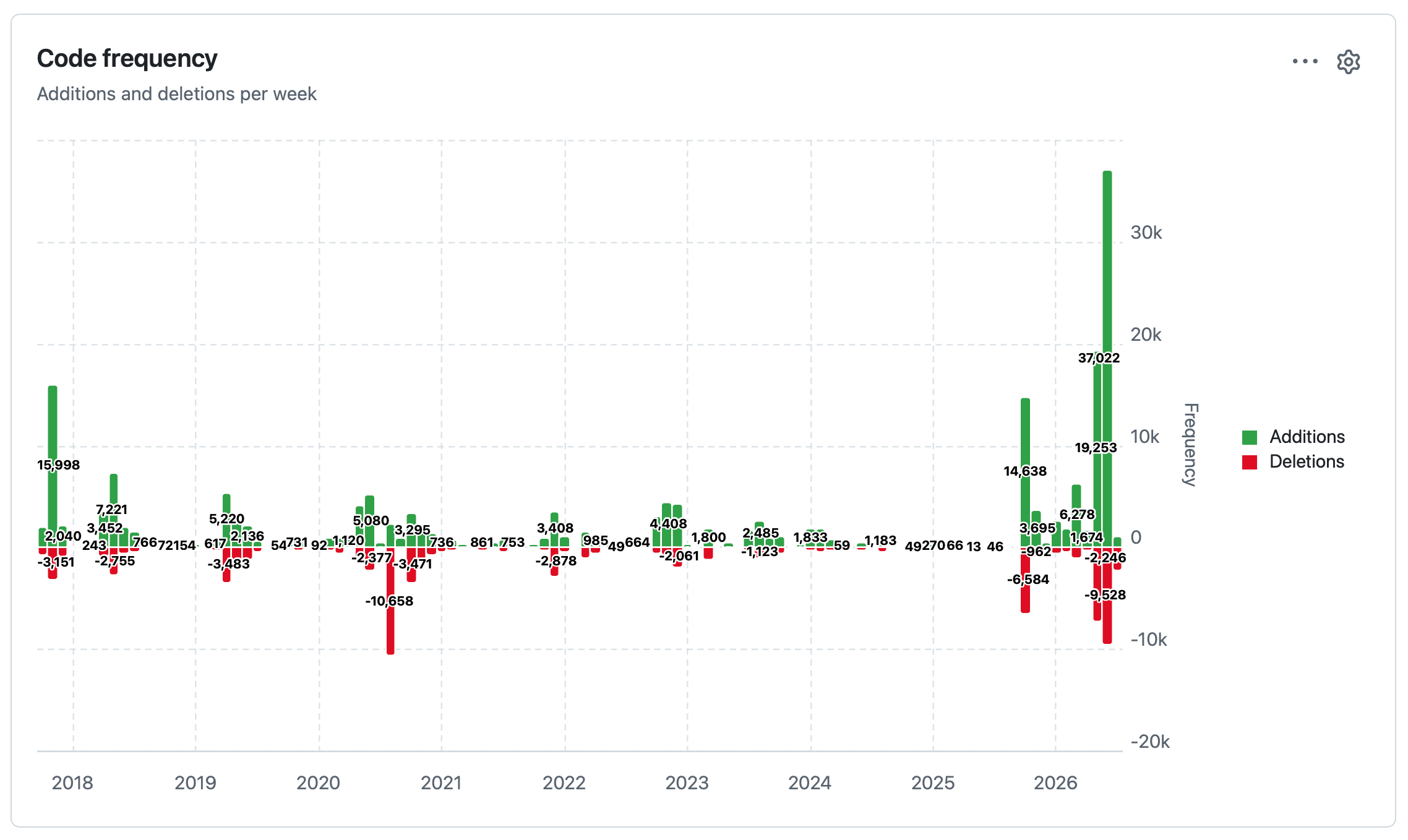
The big spike in activity at the end aligns with Opus 4.8, GPT-5.5, Fable 5 and GPT-5.6 Sol.
The first dot-release since 4.0 a few days ago, introducing a number of minor new features.
sqlite-utils insertandsqlite-utils upsertnow accept a--codeoption for providing a block of Python code (or a path to a.pyfile) that defines arows()function orrowsiterable of rows to insert, as an alternative to importing from a file. (#684)
sqlite-utils already had features that allow you to pass blocks of Python code as CLI arguments, for example this one for the sqlite-utils convert command:
sqlite-utils convert content.db articles headline ' def convert(value): return value.upper()'
Allowing blocks of code to generate new rows directly was on obvious extension of that pattern:
sqlite-utils insert data.db creatures --code ' def rows(): yield {"id": 1, "name": "Cleo"} yield {"id": 2, "name": "Suna"} ' --pk id
sqlite-utils insertandsqlite-utils upsertnow accept--type column-name typeto override the type automatically chosen when the table is created. This is useful for CSV or TSV columns such as ZIP codes that look like integers but should be stored asTEXTto preserve leading zeros. (#131)
A long-standing feature request which turned out to be a simple implementation.
- New
table.drop_index(name)method andsqlite-utils drop-indexcommand for dropping an index by name. Both acceptignore=True/--ignoreto ignore a missing index. (#626)sqlite-utils querycan now read the SQL query from standard input by passing-in place of the query, for exampleecho "select * from dogs" | sqlite-utils query dogs.db -. (#765)
Two more small features. I had Codex review all open issues and highlight the easiest ones!
sqlite-utils upsertcan now infer the primary key of an existing table, so--pkcan be omitted when upserting into a table that already has a primary key.
Another Codex suggestion, an obvious missing CLI feature from a Python library improvement that shipped in the 4.0 release.
table.transform()andtable.transform_sql()now acceptstrict=Trueorstrict=Falseto change a table’s SQLite strict mode. Omitting the option preserves the existing mode. (#787)- The
sqlite-utils transformcommand now accepts--strictand--no-strictto change a table’s strict mode. (#787)
These two were inspired by Prefer STRICT tables in SQLite by Evan Hahn, which did the rounds on Hacker News today. Evan pointed out that:
Unfortunately, I don’t think there’s a way to ALTER a table to make it strict. I think you have to copy the data out of the non-strict table into the strict one.
That's exactly what the sqlite-utils transform mechanism does, so I extended it to add the ability to switch tables from strict to non-strict and vice-versa.
Here's the GPT-5.6 Sol xhigh Codex transcript I used to implement those new strict table features. One of the most useful prompts I ran was this one:
use uv run python -c and manually exercise the new .transform(strict=) option, see if you can find any edge-cases or bugs
Effectively telling the model to manually test its work, outside of the automated tests it had already written. This turned up two minor issues that we then fixed.
Rewriting Bun in Rust (via) Jarred Sumner has been promising this blog post (since May 9th) about his Zig to Rust rewrite of Bun for significantly longer than it took him to finish the rewrite.
Honestly, it was worth the wait. This is a detailed description of an extremely sophisticated piece of agentic engineering, featuring dynamic workflows, trial runs, adversarial review and all sorts of other interesting tricks.
Jarred spends the first half of the post praising Zig for getting Bun this far. Then we get to a core idea in the piece, emphasis mine:
Our bugfix list felt bad and I was tired of going to sleep worrying about crashes in Bun. I don't blame Zig for that - other users of Zig don't have the bugs we had, and mixing GC with manually-managed memory is an uncommon enough thing for software to need that no language really designs for it. We wouldn't have gotten this far if not for Zig, and I'll always be grateful. Until very recently, programming language choice was a one-way decision for a project like Bun.
Everyone knows you should never stop the world and rewrite a large piece of software from the ground up. Joel Spolsky highlighted that in Things You Should Never Do, Part I back in April 2000!
Coding agents powered by today's frontier models change that equation.
Why pick Rust? It all came down to those challenges with memory management:
A large percentage of bugs from that list are use-after-free, double-free, and "forgot to free" in an error path. In safe Rust, these are compiler errors and RAII-like automatic cleanup with
Drop.
A crucial enabling factor for the rewrite was that the Bun test suite was written in TypeScript, which meant it could act as a conformance suite. This allowed an agent harness to automate much of the initial port from Bun to Rust, initially as an experiment to try out an earlier version of the model we now have access to as Mythos/Fable.
At first, I didn't expect it to work. A few days in, a high % of the test suite started passing and I saw how much the new Rust code matched up with the original Zig codebase. My opinion went from "this is worth trying" to "I'm going to merge this". [...]
For most of those 11 days (and after), I monitored workflows - manually reading the outputs to check for issues and bugs, and prompting Claude to edit the loop to fix things.
How do you review a PR with +1 million lines added? How do you start to build the confidence needed to responsibly merge large quantities of LLM-authored code?
A language-independent test suite with a million assertions, adversarial code review and when something does go wrong, fixing the process that generates the code instead of hand-fixing the code.
The new implementation of Bun has been live in Claude Code for nearly a month now:
Claude Code v2.1.181 (released June 17th) and later use the Rust port of Bun. Startup got 10% faster on Linux but otherwise, barely anyone noticed. Boring is good.
A perk of working at Anthropic is that you don't have to pay for your tokens - handy when the estimated cost is $165,000!
Pre-merge, this took 5.9 billion uncached input tokens, 690 million output tokens, and 72 billion cached input token reads — around $165,000 at API pricing.
This whole thing is a fascinating case study in taking on wildly ambitious projects with the help of coordinated parallel agents.
I just declared a moratorium against AI-written change descriptions (e.g. PR and commit messages, also issues/tickets) from my team.
AI was writing change descriptions that were worse than useless to me as I tried to review PRs: outlining details of the code that could easily be seen by looking at the code, but omitting the higher-level framing needed to understand broadly what the code is doing.
sqlite-utils 4.0, now with database schema migrations
This morning I released sqlite-utils 4.0, the 124th release of that project and the first major version bump since 3.0 in November 2020. In addition to some small but significant breaking changes (described in this upgrade guide), this version introduces three major features: database migrations, nested transactions (via a new db.atomic() method), and support for compound foreign keys.
simonw/browser-compat-db. Inspired by Mozilla's new MDN MCP service - source code here - I decided to try converting their comprehensive mdn/browser-compat-data repository full of browser compatibility data into a SQLite database.
This new GitHub repo includes a Claude Code for web (Opus 4.8) generated script for doing that using sqlite-utils.
I wanted the resulting ~66MB SQLite database to be available via the GitHub CDN with open CORS headers. GitHub releases don't have those, but any file stored in a regular GitHub repository does - so I had Codex Desktop (GPT-5.5) build a GitHub Actions workflow that builds the database and then force-pushes it to a db "orphan" branch.
You can download the resulting database from here, and since it's hosted with open CORS headers you can also explore it with Datasette Lite.
Datasette Apps: Host custom HTML applications inside Datasette
Today we launched a new plugin for Datasette, datasette-apps, with this launch announcement post on the Datasette project blog. That post has the what, but I’m going to expand on that a little bit here to provide the why.
[... 2,301 words]What happened in 2025 was this: the economics of code production were turned upside down. Instead of being very hard, time-consuming, and expensive to generate code, it became effectively free and instant. Lines of code went from being treasured, reused, cared for and carefully curated, to being disposable and regenerable, practically overnight.
— Charity Majors, AI demands more engineering discipline. Not less
I can 100% attest to the fact that Qwen3.6-27B is a very capable local model for coding tasks. Over the last month and a half I've been using it almost daily, either on my M2 Ultra or on my RTX 5090 box. I use it for small mundane tasks at ggml-org - nothing really impressive, but definitely a helpful tool for a maintainer. I think I would be using it much more, if I didn't have to spend a lot of my time on reviewing PRs. Currently, I have a very lightweight harness - the pi agent with everything stripped (
pi -nc --offline) and a short system prompt to align it a bit with my style.
— Georgi Gerganov, Hacker News comment on Running local models is good now by Boykis
Claude Fable is relentlessly proactive
After two days of experience with Claude Fable 5 I think the best way to describe it is relentlessly proactive. It knows a whole lot of tricks and it will deploy pretty much any of them to get to its goal.
[... 1,939 words]This alpha is a significant step on the road to a stable 1.0, finally extending the ?_extra= pattern I introduced in Datasette 1.0a3 to cover queries and rows in addition to tables. That pattern is also now documented!
I wrote a whole lot more about the new release on the Datasette project blog: Datasette 1.0a33 with JSON extras in the API.
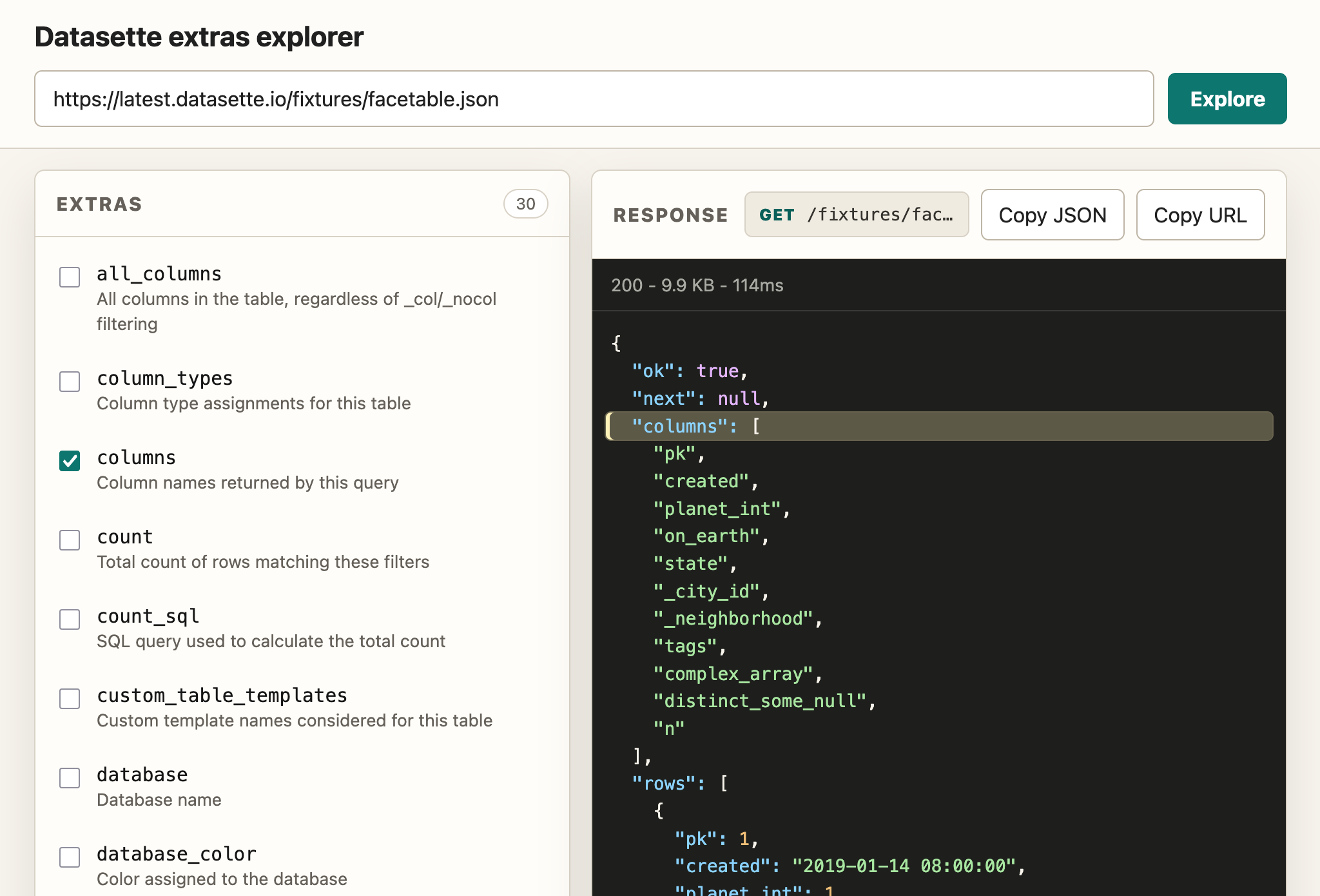
Because API explorer tools are almost free to build now I had Claude Fable 5 in Claude Code (for the plan) and GPT-5.5 xhigh in Codex Desktop (for the implementation) build me this custom extras API explorer to help demonstrate the feature:
Running Python code in a sandbox with MicroPython and WASM
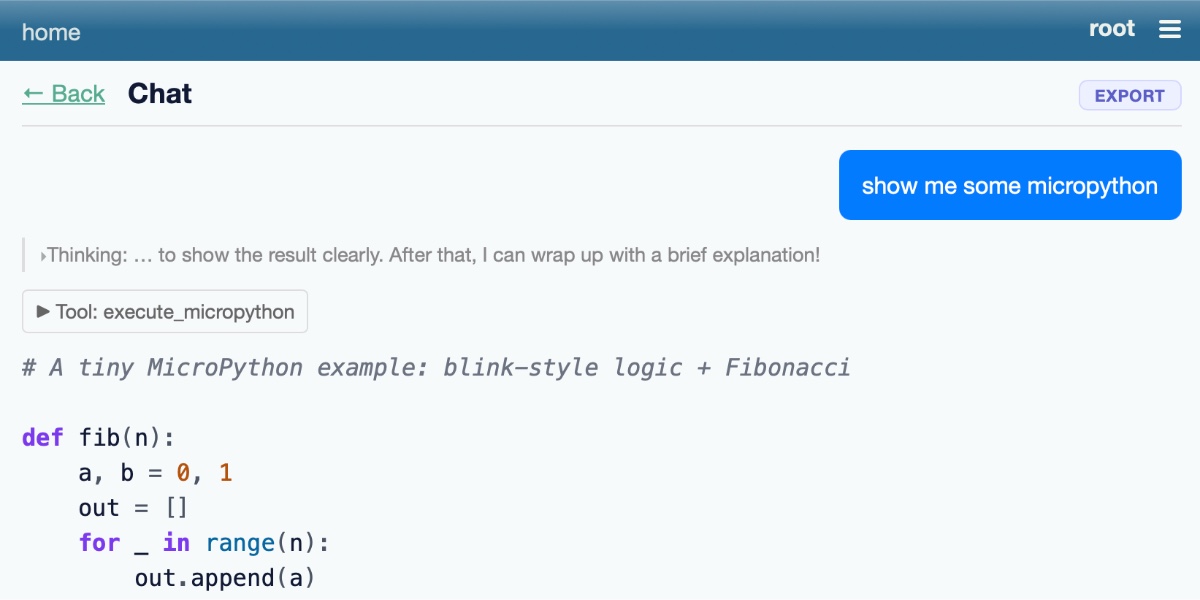
I’ve been experimenting with different approaches to running code in a sandbox for several years now, but my latest attempt feels like it might finally have all of the characteristics I’ve been looking for. I’ve released it as an alpha package called micropython-wasm, and I’m using it for a code execution sandbox plugin for Datasette Agent called datasette-agent-micropython.
[... 2,024 words]I really like how you can paste a large volume of text into claude.ai (or the Claude desktop/mobile apps) and it will detect it as a large paste and turn it into a file attachment instead.
I decided to have Codex desktop build me a version of that as a prototype.
You can also open files directly - including images which will be shown as thumbnails - or drag files onto the textarea.
This Mitchell Hashimoto quote about Bun migrating from Zig to Rust reminded me of a similar conversation I had at a conference last week.
I was talking to someone who worked for a medium sized technology company with a pair of legacy/legendary iPhone and Android apps.
They told me they had just completed a coding-agent driven rewrite of both apps to React Native.
I asked why they chose that, given that coding agents presumably drive down the cost of maintaining separate iPhone and Android apps.
They said that React Native has improved a lot over the past few years and covered everything their apps needed to do.
And... if it turned out to be the wrong decision, they could just port back to native in the future.
Like Mitchell said:
Programming languages used to be LOCK IN, and they're increasingly not so.
Welcome to the Datasette blog. We have a bunch of neat Datasette announcements in the pipeline so we decided it was time the project grew an official blog.
I built this using OpenAI Codex desktop, which turns out to have the Markdown session transcript export feature I've always wanted. Here's the session that built the blog. See also issue 179.
Your AI coding agent, the one you use to write code, needs to reduce your maintenance costs. Not by a little bit, either. You write code twice as quick now? Better hope you’ve halved your maintenance costs. Three times as productive? One third the maintenance costs. Otherwise, you’re screwed. You’re trading a temporary speed boost for permanent indenture. [...]
The math only works if the LLM decreases your maintenance costs, and by exactly the inverse of the rate it adds code. If you double your output and your cost of maintaining that output, two times two means you’ve quadrupled your maintenance costs. If you double your output and hold your maintenance costs steady, two times one means you’ve still doubled your maintenance costs.
— James Shore, You Need AI That Reduces Maintenance Costs
/elsewhere/sightings/. I have a new camera (a Canon R6 Mark II) so I'm taking a lot more photos of birds. I share my best wildlife photos on iNaturalist, and based on yesterday's successful prototype I decided to add those to my blog.
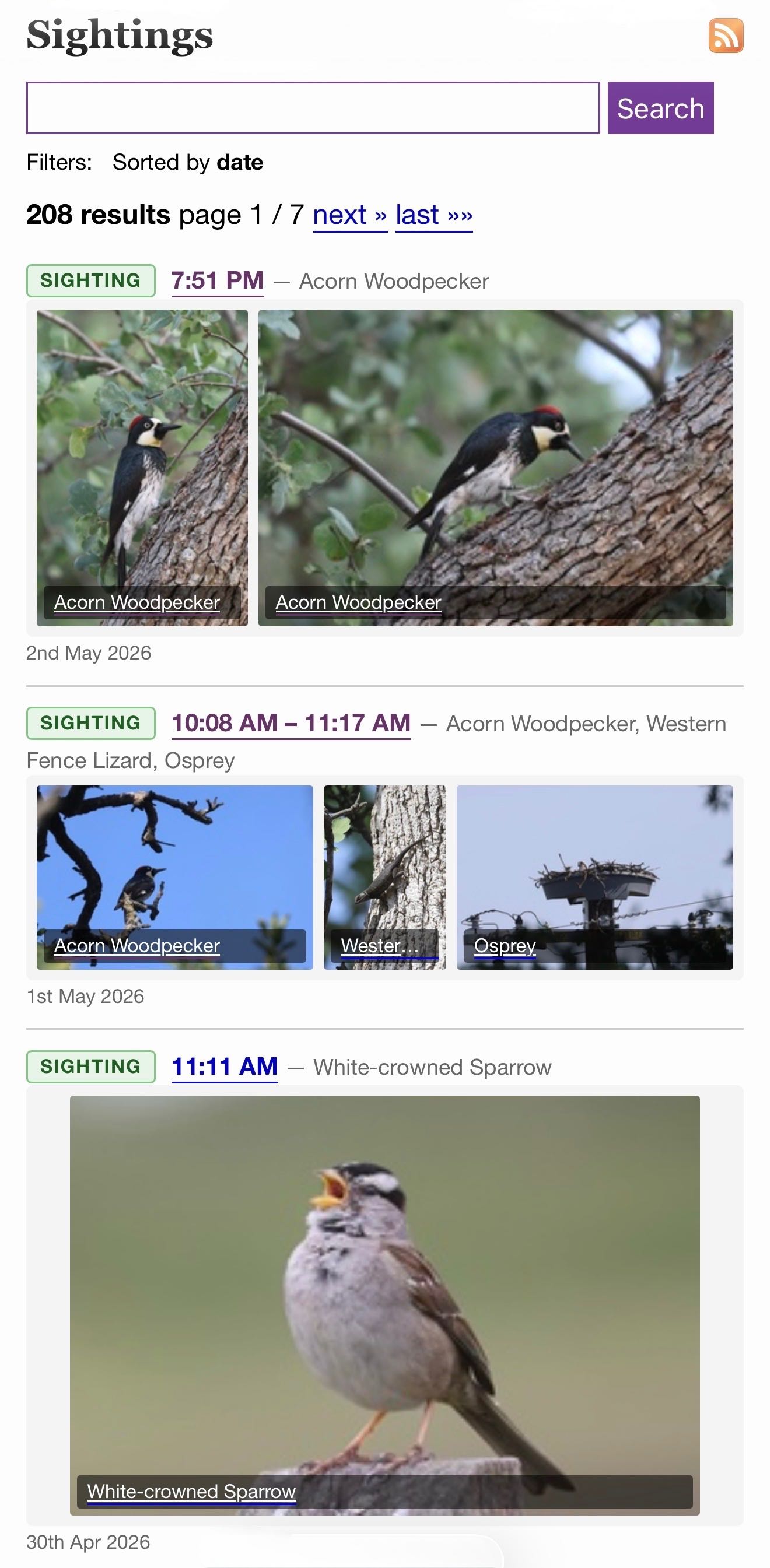
I built this feature on my phone using Claude Code for web, as an extension of my beats system for syndicating external content. Here's the PR and prompt.
As with my other forms of incoming syndicated content sightings show up on the homepage, the date archive pages, and in site search results.
I back-populated over a decade of iNaturalist sightings, which means you that if you search for lemur you'll see my lemur photos from Madagascar in 2019!
Zig has one of the most stringent anti-LLM policies of any major open source project:
No LLMs for issues.
No LLMs for pull requests.
No LLMs for comments on the bug tracker, including translation. English is encouraged, but not required. You are welcome to post in your native language and rely on others to have their own translation tools of choice to interpret your words.
The most prominent project written in Zig may be the Bun JavaScript runtime, which was acquired by Anthropic in December 2025 and, unsurprisingly, makes heavy use of AI assistance.
Bun operates its own fork of Zig, and recently achieved a 4x performance improvement on Bun compile after adding "parallel semantic analysis and multiple codegen units to the llvm backend". Here's that code. But @bunjavascript says:
We do not currently plan to upstream this, as Zig has a strict ban on LLM-authored contributions.
(Update: here's a Zig core contributor providing details on why they wouldn't accept that particular patch independent of the LLM issue - parallel semantic analysis is a long planned feature but has implications "for the Zig language itself".)
In Contributor Poker and Zig's AI Ban (via Lobste.rs) Zig Software Foundation VP of Community Loris Cro explains the rationale for this strict ban. It's the best articulation I've seen yet for a blanket ban on LLM-assisted contributions:
In successful open source projects you eventually reach a point where you start getting more PRs than what you’re capable of processing. Given what I mentioned so far, it would make sense to stop accepting imperfect PRs in order to maximize ROI from your work, but that’s not what we do in the Zig project. Instead, we try our best to help new contributors to get their work in, even if they need some help getting there. We don’t do this just because it’s the “right” thing to do, but also because it’s the smart thing to do.
Zig values contributors over their contributions. Each contributor represents an investment by the Zig core team - the primary goal of reviewing and accepting PRs isn't to land new code, it's to help grow new contributors who can become trusted and prolific over time.
LLM assistance breaks that completely. It doesn't matter if the LLM helps you submit a perfect PR to Zig - the time the Zig team spends reviewing your work does nothing to help them add new, confident, trustworthy contributors to their overall project.
Loris explains the name here:
The reason I call it “contributor poker” is because, just like people say about the actual card game, “you play the person, not the cards”. In contributor poker, you bet on the contributor, not on the contents of their first PR.
This makes a lot of sense to me. It relates to an idea I've seen circulating elsewhere: if a PR was mostly written by an LLM, why should a project maintainer spend time reviewing and discussing that PR as opposed to firing up their own LLM to solve the same problem?
Five months in, I think I've decided that I don't want to vibecode — I want professionally managed software companies to use AI coding assistance to make more/better/cheaper software products that they sell to me for money.
— Matthew Yglesias, in a now-deleted Tweet
Adding a new content type to my blog-to-newsletter tool
Here's an example of a deceptively short prompt that got a quite a lot of work done in a single shot.
First, some background. I send out a free Substack newsletter around once a week containing content copied-and-pasted from my blog. I'm effectively using Substack as a lightweight way to allow people to subscribe to my blog via email.
I generate the newsletter with my blog-to-newsletter tool - an HTML and JavaScript app that fetches my latest content from this Datasette instance and formats it as rich text HTML, which I can then copy to my clipboard and paste into the Substack editor. Here's a detailed explanation of how that works. [... 902 words]
datasette PR #2689: Replace token-based CSRF with Sec-Fetch-Site header protection.
Datasette has long protected against CSRF attacks using CSRF tokens, implemented using my asgi-csrf Python library. These are something of a pain to work with - you need to scatter forms in templates with <input type="hidden" name="csrftoken" value="{{ csrftoken() }}"> lines and then selectively disable CSRF protection for APIs that are intended to be called from outside the browser.
I've been following Filippo Valsorda's research here with interest, described in this detailed essay from August 2025 and shipped as part of Go 1.25 that same month.
I've now landed the same change in Datasette. Here's the PR description - Claude Code did much of the work (across 10 commits, closely guided by me and cross-reviewed by GPT-5.4) but I've decided to start writing these PR descriptions by hand, partly to make them more concise and also as an exercise in keeping myself honest.
- New CSRF protection middleware inspired by Go 1.25 and this research by Filippo Valsorda. This replaces the old CSRF token based protection.
- Removes all instances of
<input type="hidden" name="csrftoken" value="{{ csrftoken() }}">in the templates - they are no longer needed.- Removes the
def skip_csrf(datasette, scope):plugin hook defined indatasette/hookspecs.pyand its documentation and tests.- Updated CSRF protection documentation to describe the new approach.
- Upgrade guide now describes the CSRF change.
The problem is that LLMs inherently lack the virtue of laziness. Work costs nothing to an LLM. LLMs do not feel a need to optimize for their own (or anyone's) future time, and will happily dump more and more onto a layercake of garbage. Left unchecked, LLMs will make systems larger, not better — appealing to perverse vanity metrics, perhaps, but at the cost of everything that matters.
As such, LLMs highlight how essential our human laziness is: our finite time forces us to develop crisp abstractions in part because we don't want to waste our (human!) time on the consequences of clunky ones.
— Bryan Cantrill, The peril of laziness lost
Eight years of wanting, three months of building with AI (via) Lalit Maganti provides one of my favorite pieces of long-form writing on agentic engineering I've seen in ages.
They spent eight years thinking about and then three months building syntaqlite, which they describe as "high-fidelity devtools that SQLite deserves".
The goal was to provide fast, robust and comprehensive linting and verifying tools for SQLite, suitable for use in language servers and other development tools - a parser, formatter, and verifier for SQLite queries. I've found myself wanting this kind of thing in the past myself, hence my (far less production-ready) sqlite-ast project from a few months ago.
Lalit had been procrastinating on this project for years, because of the inevitable tedium of needing to work through 400+ grammar rules to help build a parser. That's exactly the kind of tedious work that coding agents excel at!
Claude Code helped get over that initial hump and build the first prototype:
AI basically let me put aside all my doubts on technical calls, my uncertainty of building the right thing and my reluctance to get started by giving me very concrete problems to work on. Instead of “I need to understand how SQLite’s parsing works”, it was “I need to get AI to suggest an approach for me so I can tear it up and build something better". I work so much better with concrete prototypes to play with and code to look at than endlessly thinking about designs in my head, and AI lets me get to that point at a pace I could not have dreamed about before. Once I took the first step, every step after that was so much easier.
That first vibe-coded prototype worked great as a proof of concept, but they eventually made the decision to throw it away and start again from scratch. AI worked great for the low level details but did not produce a coherent high-level architecture:
I found that AI made me procrastinate on key design decisions. Because refactoring was cheap, I could always say “I’ll deal with this later.” And because AI could refactor at the same industrial scale it generated code, the cost of deferring felt low. But it wasn’t: deferring decisions corroded my ability to think clearly because the codebase stayed confusing in the meantime.
The second attempt took a lot longer and involved a great deal more human-in-the-loop decision making, but the result is a robust library that can stand the test of time.
It's worth setting aside some time to read this whole thing - it's full of non-obvious downsides to working heavily with AI, as well as a detailed explanation of how they overcame those hurdles.
The key idea I took away from this concerns AI's weakness in terms of design and architecture:
When I was working on something where I didn’t even know what I wanted, AI was somewhere between unhelpful and harmful. The architecture of the project was the clearest case: I spent weeks in the early days following AI down dead ends, exploring designs that felt productive in the moment but collapsed under scrutiny. In hindsight, I have to wonder if it would have been faster just thinking it through without AI in the loop at all.
But expertise alone isn’t enough. Even when I understood a problem deeply, AI still struggled if the task had no objectively checkable answer. Implementation has a right answer, at least at a local level: the code compiles, the tests pass, the output matches what you asked for. Design doesn’t. We’re still arguing about OOP decades after it first took off.
Lalit Maganti's syntaqlite is currently being discussed on Hacker News thanks to Eight years of wanting, three months of building with AI, a deep dive into how it was built.
This inspired me to revisit a research project I ran when Lalit first released it a couple of weeks ago, where I tried it out and then compiled it to a WebAssembly wheel so it could run in Pyodide in a browser (the library itself uses C and Rust).
This new playground loads up the Python library and provides a UI for trying out its different features: formating, parsing into an AST, validating, and tokenizing SQLite SQL queries.
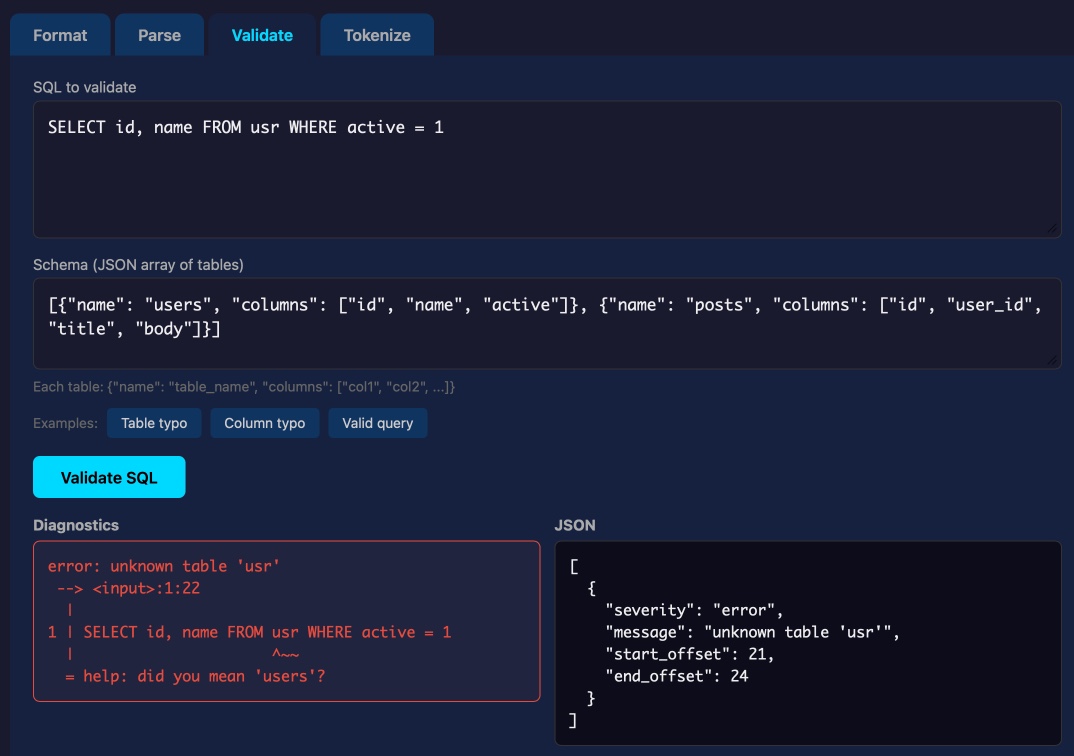
Update: not sure how I missed this but syntaqlite has its own WebAssembly playground linked to from the README.
I like publishing transcripts of local Claude Code sessions using my claude-code-transcripts tool but I'm often paranoid that one of my API keys or similar secrets might inadvertently be revealed in the detailed log files.
I built this new Python scanning tool to help reassure me. You can feed it secrets and have it scan for them in a specified directory:
uvx scan-for-secrets $OPENAI_API_KEY -d logs-to-publish/
If you leave off the -d it defaults to the current directory.
It doesn't just scan for the literal secrets - it also scans for common encodings of those secrets e.g. backslash or JSON escaping, as described in the README.
If you have a set of secrets you always want to protect you can list commands to echo them in a ~/.scan-for-secrets.conf.sh file. Mine looks like this:
llm keys get openai
llm keys get anthropic
llm keys get gemini
llm keys get mistral
awk -F= '/aws_secret_access_key/{print $2}' ~/.aws/credentials | xargs
I built this tool using README-driven-development: I carefully constructed the README describing exactly how the tool should work, then dumped it into Claude Code and told it to build the actual tool (using red/green TDD, naturally.)
I want to argue that AI models will write good code because of economic incentives. Good code is cheaper to generate and maintain. Competition is high between the AI models right now, and the ones that win will help developers ship reliable features fastest, which requires simple, maintainable code. Good code will prevail, not only because we want it to (though we do!), but because economic forces demand it. Markets will not reward slop in coding, in the long-term.
— Soohoon Choi, Slop Is Not Necessarily The Future