87 posts tagged “llm-pricing”
Posts about the pricing of various LLMs. See also my pricing calculator.
2026
Advancing the price-performance frontier with GPT‑5.6 (via) Huge price drop from OpenAI today: GPT-5.6 Terra got a 20% reduction, and GPT-5.6 Luna got a massive 80% drop.
OpenAI credit 5.6 Sol with enabling this: in How GPT‑5.6 fuses frontier intelligence with frontier efficiency they describe using 5.6 Sol to optimize load balancing, and more impressively to optimize inference itself:
We also used GPT‑5.6 Sol to optimize the model’s forward pass: the computation that transforms inputs into next-token predictions. Even when individual operations are fast, excess memory movement, synchronization, and inefficient data layouts can leave GPUs idle. To avoid this, GPT‑5.6 Sol found work that could be precomputed, avoided, or parallelized. With Codex, GPT‑5.6 Sol autonomously rewrote and optimized our production kernels, the core code that executes the mathematical operations that make up the model. This worked in part because we’ve trained GPT‑5.6 to be effective at writing and improving kernels in Tritonand Gluon, two open-source GPU programming languages maintained by OpenAI. These efforts, combined with broader kernel advancements from GPT‑5.6 Sol, reduced end-to-end serving costs by 20%.
That Luna price drop completely changes the landscape with respect to lower priced models. At $0.20/million tokens for input and $1.20/million for output Luna is now cheaper than Google's Gemini 3.1 Flash-Lite ($.025/$1.50).
Anthropic's cheapest current model is Claude Haiku 4.5, and that's $1/$5 - Luna is now 1/5th of that for input, previously it cost the same.
My agent.datasette.io demo site was running on Gemini 3.1 Flash-Lite. I've switched it over to Luna.
moonshotai/Kimi-K3. As promised earlier this month, Moonshot have released the weights for their excellent 2.8 trillion parameter Kimi K3. They're a hefty 1.56TB on Hugging Face.
Kimi introduced their own janky modified version of the MIT license with K2 back in July 2025. That license just added this paragraph requiring attribution beyond a certain size of commercial entity:
Our only modification part is that, if the Software (or any derivative works thereof) is used for any of your commercial products or services that have more than 100 million monthly active users, or more than 20 million US dollars (or equivalent in other currencies) in monthly revenue, you shall prominently display "Kimi K2" on the user interface of such product or service.
The K3 license no longer calls itself "modified MIT" and goes further, requiring a separate agreement with Moonshot for large "Model as a Service" businesses:
If the Licensee or any of its affiliates operates a Model as a Service business, and the aggregate revenue of the Licensee and its affiliates exceeds 20 million US dollars (or the equivalent in other currencies) in total over any consecutive 12 months, the Licensee must enter into a separate agreement with Moonshot AI before using the Software or its derivative works for any commercial purpose.
To Kimi's credit, they make no attempt to describe this as an "open source" license in their own materials, consistently using the term "open weight" in its place.
OpenRouter is already offering K3 from 7 providers, most of which are at the same $3/million input and $15/million output as Moonshot AI themselves.
An Inside Look at the Relay Market Powering Token Resellers and Fraud (via) Fascinating investigation by Matt Lenhard into the market that has grown up around reselling LLM tokens at a discount by pooling API keys from various sources.
This looks to be mostly a thing in China. Resellers sell access to an LLM proxy that offers significant discounts on regular API pricing, which they achieve by abusing free trials, proxying through unprotected support bots, or sometimes through stolen credit cards or chargeback attacks.
The software they are using for these proxies is open source - mostly one-api and its more actively developed fork new-api, both legitimate API proxy products which can be used to load. balance requests across a pool of API credentials.
The buyers are seeking cheap tokens, avoiding geo-restrictions, and in some cases collecting data for model distillation.
I've been cautious about exposing my own LLM-driven applications publicly out of fear of abuse leading to big token bills. The existence of this marketplace makes me even more cautious: there's now an entire ecosystem that can profit from finding a new unprotected endpoint to exploit.
LLM vendors really need to get better at offering strict caps for their API keys. I want my LLM apps to stop working the moment they hit a dollar threshold I've set for a period of time.
Here's the (Chinese language) forum thread that served as the principal source for Matt's article.
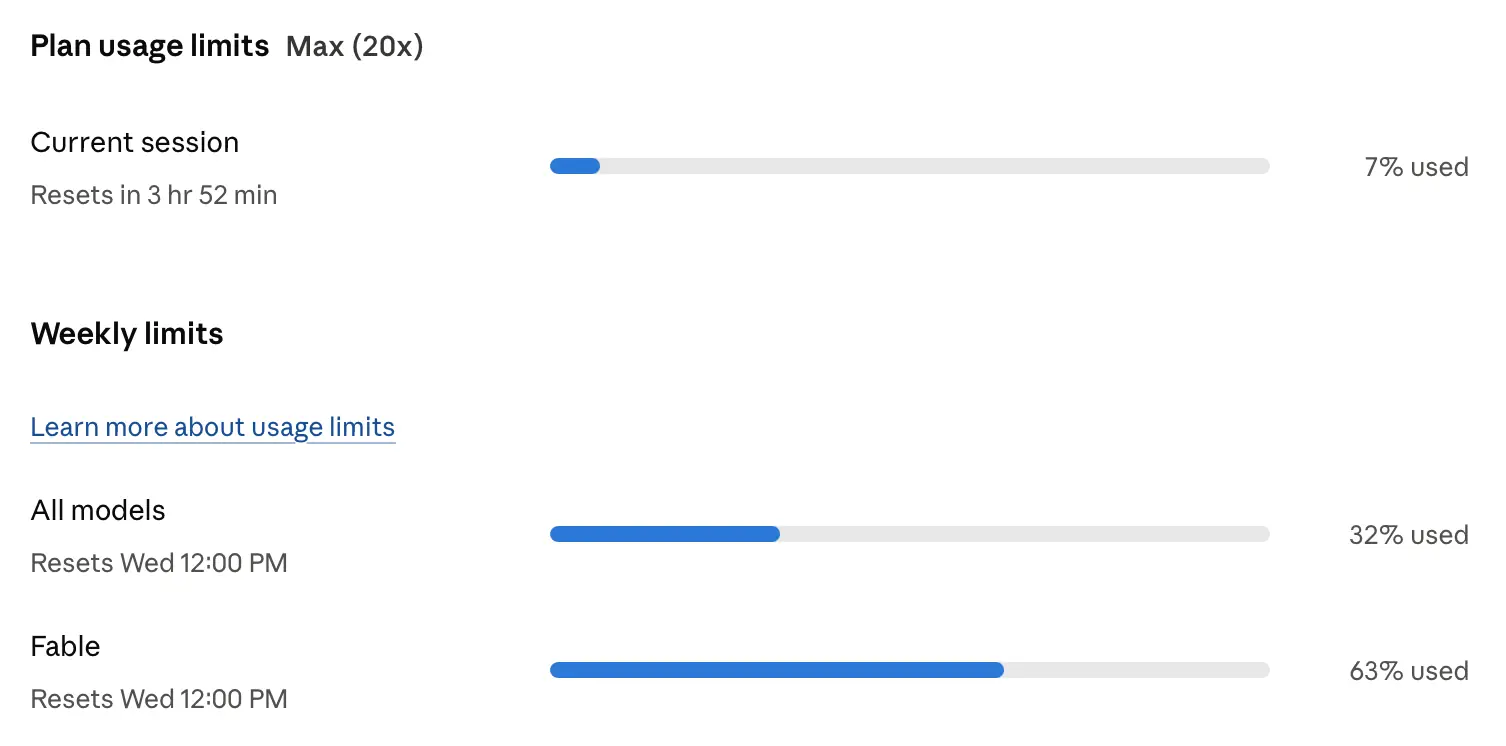
Claude make Fable 5 permanent.
An update from the @claudeai account on Twitter:
Beginning July 20, Claude Fable 5 will be included in all Max and Team Premium plans, at 50% of limits.
Pro and Team Standard users will continue to have access to Fable via usage credits, and will receive a one-time $100 credit.
As I was saying last week, the competition from GPT-5.6 Sol (and maybe to a lesser extent Kimi 3) made untenable Anthropic's plan to remove Fable 5 from their subscription accounts and make it available exclusively through API pricing.
Why pay $100 or $200/month for a subscription plan that doesn't include Anthropic's best model?
Their original plan was driven by concerns over compute capacity. I wonder if they'll have to dial back their training efforts in order to make more GPUs available to help serve the model.
A lot of people were losing sleep over trying to make the most of Fable 5 before subscriber access was withdrawn. It's nice not to have to worry about the Fablepocalypse any more.
Update: Important to note that users on the $20/month plan will still not have access to Fable 5 on that subscription. The Max plans are $100 and $200/month.
Kimi K3, and what we can still learn from the pelican benchmark

Chinese AI lab Moonshot AI announced Kimi K3 this morning, describing it as their “most capable model to date, with 2.8 trillion parameters”. It’s currently available via their website and API, but an open weight release is promised “by July 27, 2026”.
[... 1,113 words]One of the consequences of GPT-5.6 Sol being clearly a Fable/Mythos class model is that Anthropic have, once again, bumped the date that Fable stops being available in their Claude Max plans:
We're extending Claude Fable 5 access on all paid plans, as well as keeping Claude Code’s weekly rate limits 50% higher, through July 19.
As before, you can use up to half of your weekly usage limit on Fable 5. After that, you can continue using Fable 5 with usage credits, or switch to another model to keep working within your remaining limits.
Anthropic's original rationale for this was compute constraints - they wanted a better idea of both demand and compute availability before committing to keeping the new model cheap for subscribers.
OpenAI appear confident that they won't need to restrict access to GPT-5.6 in the same way. Here's Thibault Sottiaux this morning:
The last 48 hours of Codex and ChatGPT Work have been intense! Three important updates:
- Temporarily removing the 5 hour usage limit restriction for all Plus, Business and Pro plans
- Rolling out changes that will make GPT 5.6 Sol more efficient across the board and that will be reflected in less usage being used so that it can take you further. Exact impact to be quantified and shared
- We hit 6M active users, and are landing a usage reset in the next hour
At this point I think Anthropic should change track and keep Fable permanently available on those plans. OpenAI are winning users simply due to the uncertainty that surrounds Fable access.
The new GPT-5.6 family: Luna, Terra, Sol

OpenAI’s latest flagship model hit general availability this morning, and comes in three sizes: Luna, Terra, and Sol (from smallest to largest).
[... 661 words]sqlite-utils 4.0rc2, mostly written by Claude Fable (for about $149.25)
I wrote about the sqlite-utils 4.0rc1 release a couple of weeks ago. Since we only have Claude Fable on our Max subscriptions for a few more days, I decided to see if it could help me get to a 4.0 stable release that I felt truly comfortable about, since I try to keep to SemVer and like my incompatible major versions to be as rare as possible.
[... 2,427 words]What’s new in Claude Sonnet 5 (via) Claude Sonnet 5 came out this morning. I always head straight for the "what's new" developer docs because they tend to have more actionable information than the official announcement post.
Anthropic say of Sonnet 5 that "its performance is close to that of Opus 4.8, but at lower prices". The system card helps explain how they were able to release the model without being blocked by the US government:
Sonnet 5 is significantly less capable at cyber tasks than Mythos 5: its safeguards are thus similar to those we apply to Opus 4.7 and Opus 4.8 (models that are more capable than Sonnet 5 but much less capable than Mythos 5).
Of note from the "what's new" API changes:
- Sampling parameters
temperature,top_p,top_kare no longer supported. - It has a 1 million token context window and 128,000 maximum output tokens.
- It features "the same set of tools and platform features as Claude Sonnet 4.6"
- Adaptive thinking is on by default, unless you specify
"thinking": {type: "disabled"}. - The pricing is the same as Sonnet 4.6: $3/million input, $15/million input, with an introductory discount to $2/$10 until 31st August. But...
- The model has a new tokenizer, where "The same input text produces approximately 30% more tokens than on Claude Sonnet 4.6." - effectively a 30% price increase.
I used my Claude Token Counter tool to try out the new tokenizer. Here are my results for several larger documents:
| Document | Sonnet 4.6 | Opus 4.7 | Sonnet 5 |
|---|---|---|---|
| Universal Declaration of Human Rights (English) | 2,356 | 3,347 1.42x |
3,341 1.42x |
| Universal Declaration of Human Rights (Spanish) | 3,572 | 4,753 1.33x |
4,747 1.33x |
| Universal Declaration of Human Rights (Chinese, Mandarin Simplified) | 3,334 | 3,366 1.01x |
3,360 1.01x |
| sqlite_utils/db.py (4,279 lines of Python) | 44,014 | 56,118 1.28x |
56,113 1.27x |
So the new token is roughly 1.4x times more expensive for English, 1.33x for Spanish, 1.28x for Python code and effectively the same cost for Simplified Mandarin.
Here's the pelican. It's nothing to write home about. Sonnet 5 thinks it looks like a goose.

We're beginning a limited preview of the GPT‑5.6 series: Sol, our flagship model; Terra, a balanced model for everyday work; and Luna, a fast and affordable model. Terra has competitive performance to GPT‑5.5 while being 2x cheaper and Luna brings strong capability at our lowest cost. [...]
We believe in broad access, and we plan to make GPT‑5.6 Sol, Terra, and Luna generally available in the coming weeks. As part of our ongoing engagement with the U.S. government, we previewed our plans and the models’ capabilities ahead of today’s launch. At their request, we are starting with a limited preview for a small group of trusted partners whose participation has been shared with the government, before releasing more broadly. [...]
GPT‑5.6 is priced per 1M tokens across three model sizes: Sol is $5 input / $30 output; Terra is $2.50 input / $15 output; and Luna is $1 input / $6 output. GPT‑5.6 also introduces more predictable prompt caching, including support for explicit cache breakpoints and a 30-minute minimum cache life. For GPT‑5.6 and later models, cache writes are billed at 1.25x the model’s uncached input rate, while cache reads continue to receive the 90% cached-input discount.
— OpenAI, Previewing GPT‑5.6 Sol: a next-generation model
Initial impressions of Claude Fable 5

I didn’t have early access to today’s Claude Fable 5 release, but I’ve spent the past ~5.5 hours putting it through its paces. My initial impressions are that this is something of a beast. It’s slow, expensive and has been quite happily churning through everything I’ve thrown at it so far. As is frequently the case with current frontier models the challenge is finding tasks that it can’t do.
[... 2,404 words]
I've been really enjoying AgentsView by Wes McKinney as a tool for exploring my token usage across different coding agents running on my laptop.
Claude Fable 5 came out today and wasn't yet included in the pricing database AgentsView uses. I used Fable to reverse-engineer AgentsView and figured out this recipe for setting custom prices.
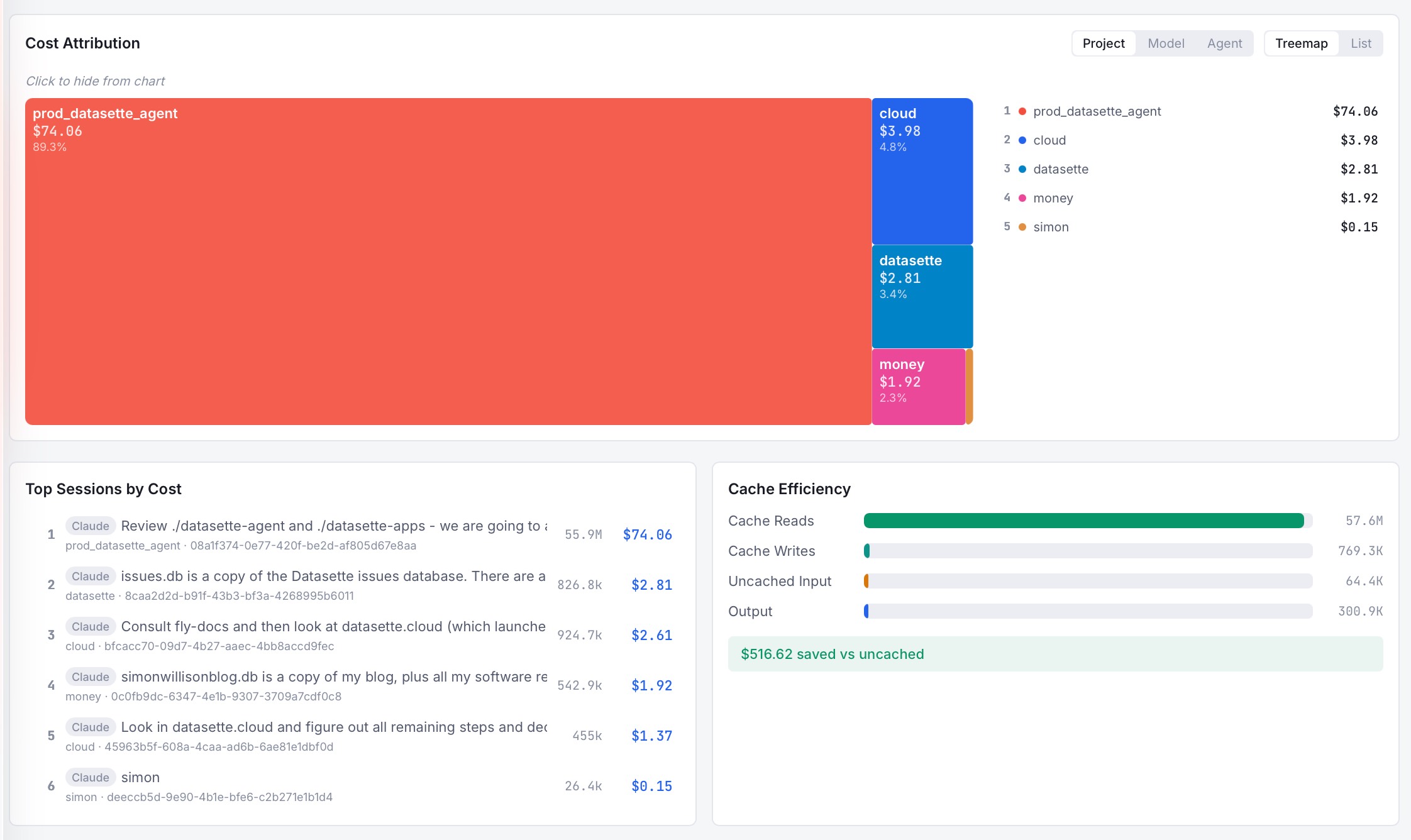
Here's my Claude Fable 5 usage for today so far, plotted by AgentsView as a treemap across my different local projects:
Uber Caps Usage of AI Tools Like Claude Code to Manage Costs. I wrote the other day about Uber blowing its 2026 AI budget in four months, and how that wasn't particularly surprising given they would have set that budget in 2025, before anyone could have predicted how popular token-burning coding agents were about to become. Natalie Lung for Bloomberg:
The rideshare giant is limiting all employees to $1,500 in monthly token spending per AI coding tool, an Uber spokesperson said in response to a Bloomberg News inquiry. That means spending on one tool doesn’t have a bearing on the budget for another. The limits, which have been instituted in recent months, only apply to agentic coding software such as Cursor or Anthropic PBC’s Claude Code.
A $1,500 monthly limit per tool strikes me as a rational policy response to over-spending, and much more sensible than those tokenmaxxing leaderboards encouraging employees to compete for as much AI usage as possible.
It's also interesting in that it hints at a real dollar value for what Uber is getting out of these tools. If we assume two actively used tools per engineer that's $3,000 * 12 = $36,000 cap per engineer per year. Levels.fyi lists the median yearly compensation package for Uber software engineers in the USA at $330,000.
That means each employee's AI spending cap is ~11% of that median compensation package.
I noted that my own token usage comes to about $1,000/month against each of Anthropic and OpenAI - which currently costs me just $100 per provider thanks to their generous subsidized plans for individual subscribers. Those plans are no longer available to larger companies like Uber.
Their new policy means if I were working at Uber I'd still have ~$500/month of tokens to spare for each of those tools, given my current usage patterns.
I think Anthropic and OpenAI have found product-market fit
Anthropic are strongly rumored to be about to have their first profitable quarter. Stories are circulating of companies surprised at how expensive their LLM bills are becoming from usage by their staff. I think this is because OpenAI and Anthropic have both found product-market fit.
[... 1,931 words]Gemini 3.5 Flash: more expensive, but Google plan to use it for everything

Today at Google I/O, Google released Gemini 3.5 Flash. This one skipped the -preview modifier and went straight to general availability, and Google appear to be using it for a whole lot of their key products:
DeepSeek V4—almost on the frontier, a fraction of the price

Chinese AI lab DeepSeek’s last model release was V3.2 (and V3.2 Speciale) last December. They just dropped the first of their hotly anticipated V4 series in the shape of two preview models, DeepSeek-V4-Pro and DeepSeek-V4-Flash.
[... 703 words]A pelican for GPT-5.5 via the semi-official Codex backdoor API

GPT-5.5 is out. It’s available in OpenAI Codex and is rolling out to paid ChatGPT subscribers. I’ve had some preview access and found it to be a fast, effective and highly capable model. As is usually the case these days, it’s hard to put into words what’s good about it—I ask it to build things and it builds exactly what I ask for!
[... 884 words]Changes to GitHub Copilot Individual plans (via) On the same day as Claude Code's temporary will-they-won't-they $100/month kerfuffle (for the moment, they won't), here's the latest on GitHub Copilot pricing.
Unlike Anthropic, GitHub put up an official announcement about their changes, which include tightening usage limits, pausing signups for individual plans (!), restricting Claude Opus 4.7 to the more expensive $39/month "Pro+" plan, and dropping the previous Opus models entirely.
The key paragraph:
Agentic workflows have fundamentally changed Copilot’s compute demands. Long-running, parallelized sessions now regularly consume far more resources than the original plan structure was built to support. As Copilot’s agentic capabilities have expanded rapidly, agents are doing more work, and more customers are hitting usage limits designed to maintain service reliability.
It's easy to forget that just six months ago heavy LLM users were burning an order of magnitude less tokens. Coding agents consume a lot of compute.
Copilot was also unique (I believe) among agents in charging per-request, not per-token. (Correction: Windsurf also operated a credit system like this which they abandoned last month.) This means that single agentic requests which burn more tokens cut directly into their margins. The most recent pricing scheme addresses that with token-based usage limits on a per-session and weekly basis.
My one problem with this announcement is that it doesn't clearly clarify which product called "GitHub Copilot" is affected by these changes. Last month in How many products does Microsoft have named 'Copilot'? I mapped every one Tey Bannerman identified 75 products that share the Copilot brand, 15 of which have "GitHub Copilot" in the title.
Judging by the linked GitHub Copilot plans page this covers Copilot CLI, Copilot cloud agent and code review (features on GitHub.com itself), and the Copilot IDE features available in VS Code, Zed, JetBrains and more.
Is Claude Code going to cost $100/month? Probably not—it’s all very confusing
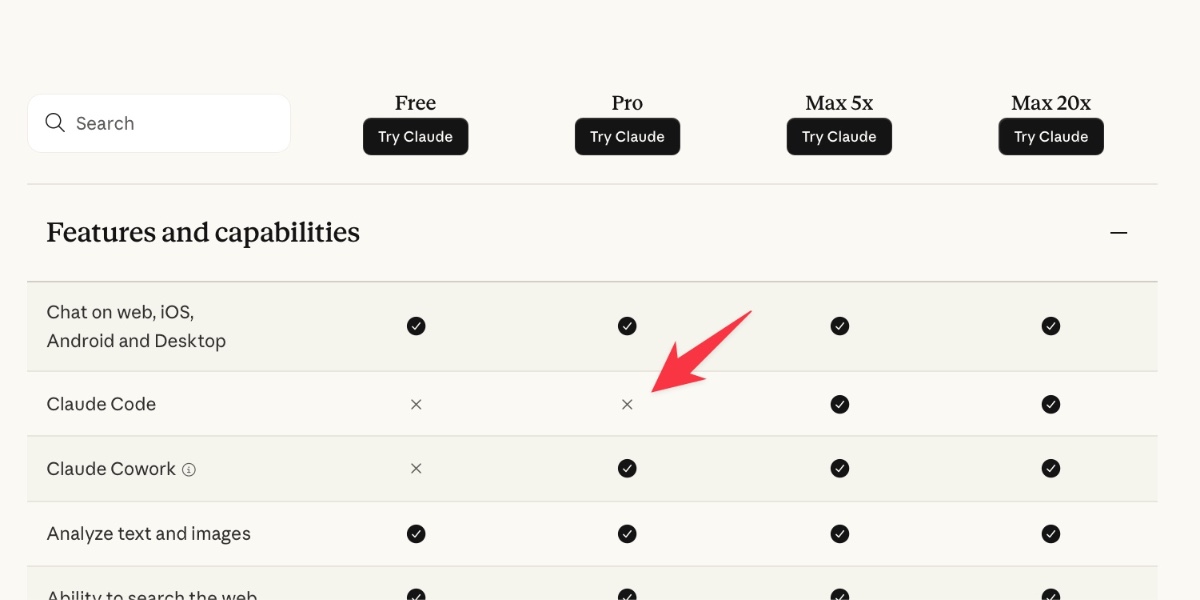
Anthropic today quietly (as in silently, no announcement anywhere at all) updated their claude.com/pricing page (but not their Choosing a Claude plan page, which shows up first for me on Google) to add this tiny but significant detail (arrow is mine, and it’s already reverted):
[... 1,202 words]Claude Token Counter, now with model comparisons. I upgraded my Claude Token Counter tool to add the ability to run the same count against different models in order to compare them.
As far as I can tell Claude Opus 4.7 is the first model to change the tokenizer, so it's only worth running comparisons between 4.7 and 4.6. The Claude token counting API accepts any Claude model ID though so I've included options for all four of the notable current models (Opus 4.7 and 4.6, Sonnet 4.6, and Haiku 4.5).
In the Opus 4.7 announcement Anthropic said:
Opus 4.7 uses an updated tokenizer that improves how the model processes text. The tradeoff is that the same input can map to more tokens—roughly 1.0–1.35× depending on the content type.
I pasted the Opus 4.7 system prompt into the token counting tool and found that the Opus 4.7 tokenizer used 1.46x the number of tokens as Opus 4.6.
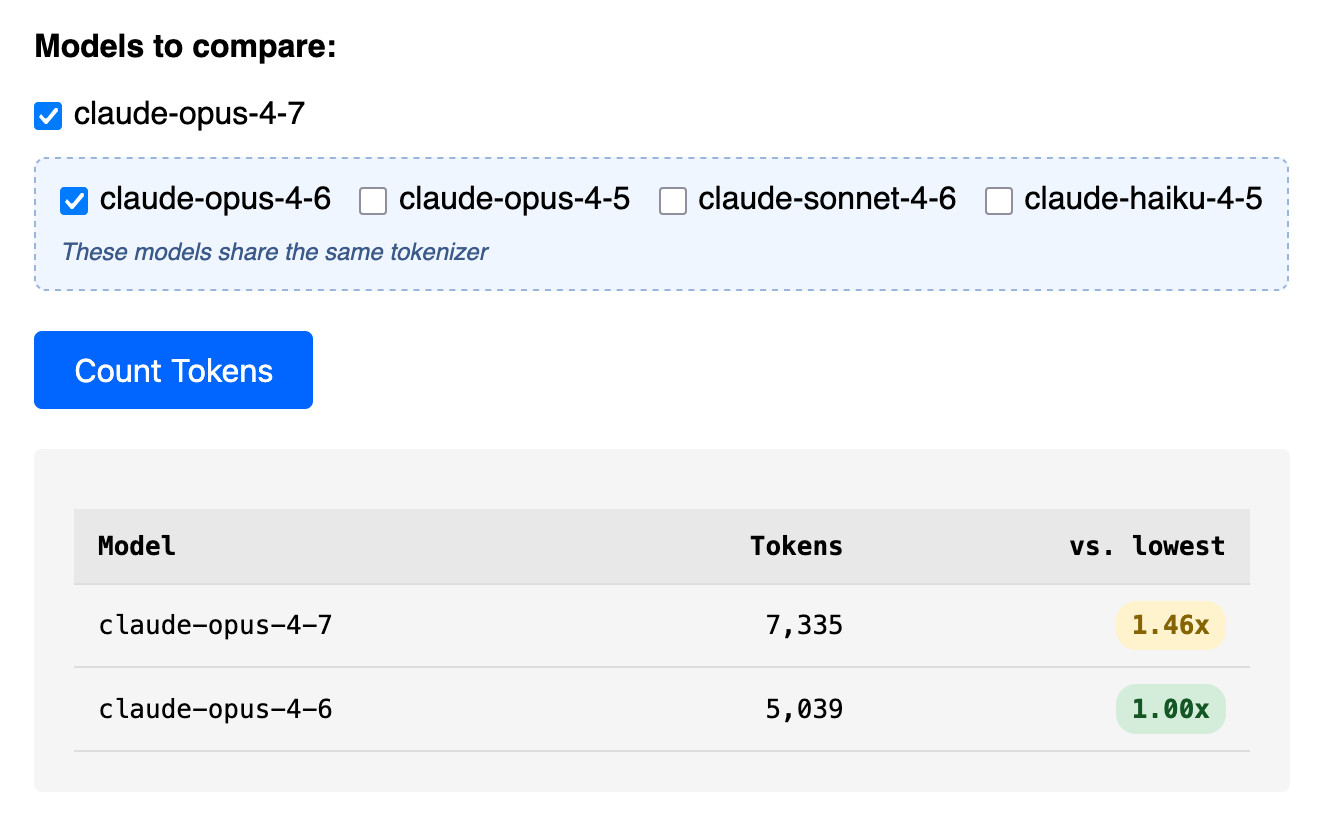
Opus 4.7 uses the same pricing is Opus 4.6 - $5 per million input tokens and $25 per million output tokens - but this token inflation means we can expect it to be around 40% more expensive.
The token counter tool also accepts images. Opus 4.7 has improved image support, described like this:
Opus 4.7 has better vision for high-resolution images: it can accept images up to 2,576 pixels on the long edge (~3.75 megapixels), more than three times as many as prior Claude models.
I tried counting tokens for a 3456x2234 pixel 3.7MB PNG and got an even bigger increase in token counts - 3.01x times the number of tokens for 4.7 compared to 4.6:
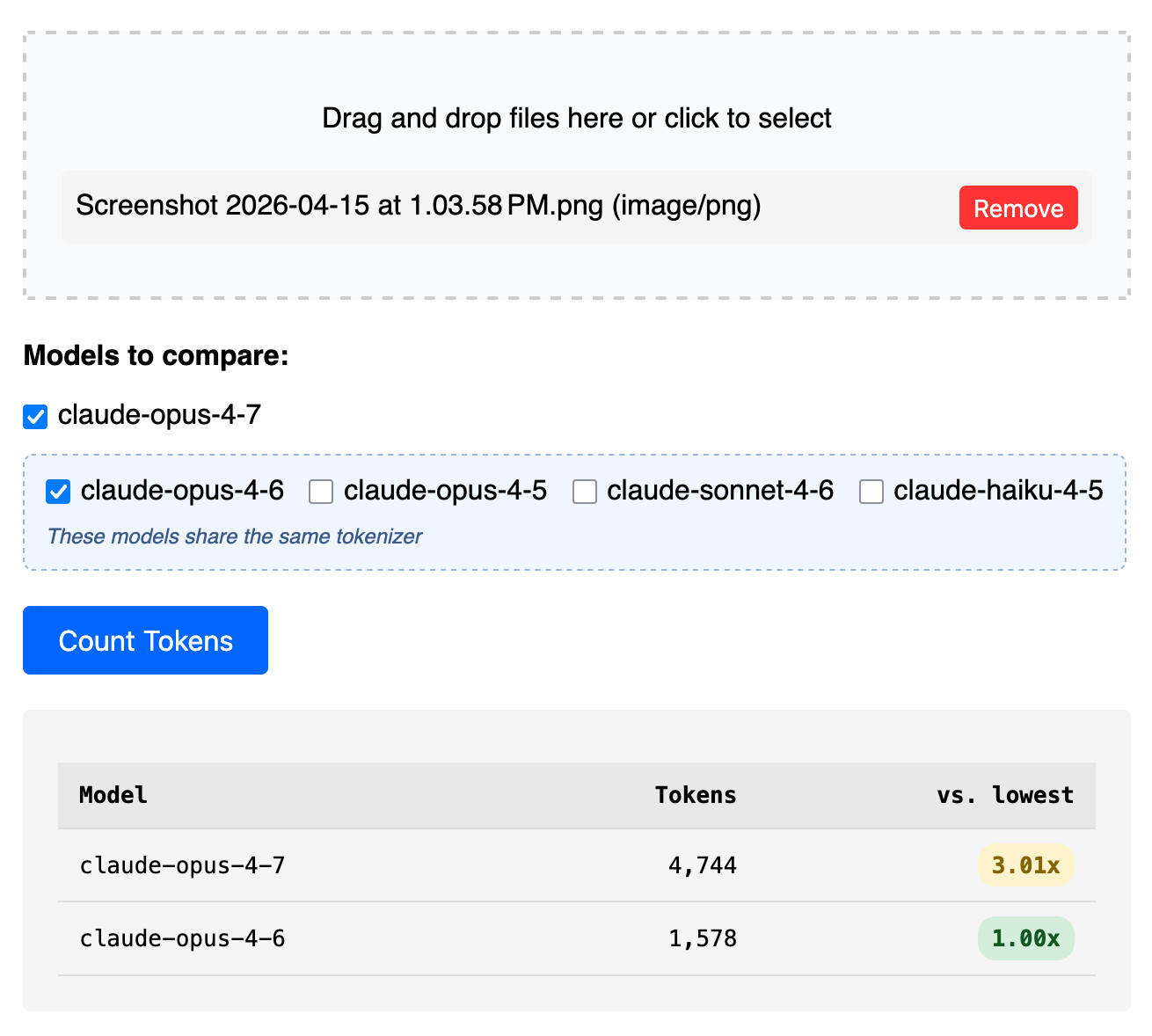
Update: That 3x increase for images is entirely due to Opus 4.7 being able to handle higher resolutions. I tried that again with a 682x318 pixel image and it took 314 tokens with Opus 4.7 and 310 with Opus 4.6, so effectively the same cost.
Update 2: I tried a 15MB, 30 page text-heavy PDF and Opus 4.7 reported 60,934 tokens while 4.6 reported 56,482 - that's a 1.08x multiplier, significantly lower than the multiplier I got for raw text.
GPT-5.4 mini and GPT-5.4 nano, which can describe 76,000 photos for $52
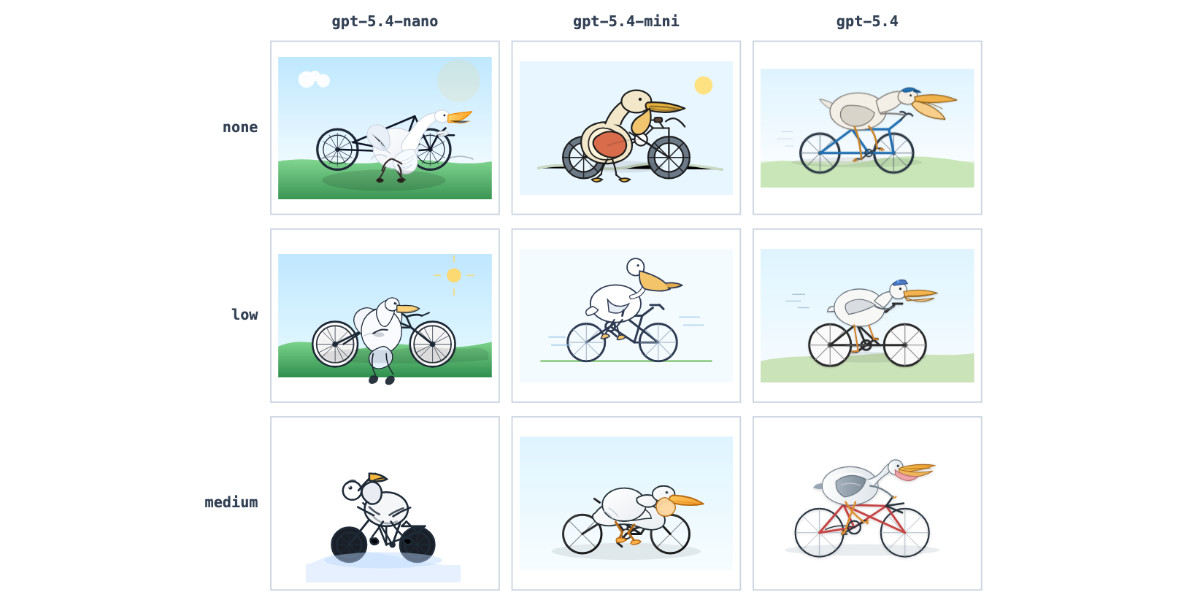
OpenAI today: Introducing GPT‑5.4 mini and nano. These models join GPT-5.4 which was released two weeks ago.
[... 719 words]1M context is now generally available for Opus 4.6 and Sonnet 4.6. Here's what surprised me:
Standard pricing now applies across the full 1M window for both models, with no long-context premium.
OpenAI and Gemini both charge more for prompts where the token count goes above a certain point - 200,000 for Gemini 3.1 Pro and 272,000 for GPT-5.4.
Gemini 3.1 Flash-Lite. Google's latest model is an update to their inexpensive Flash-Lite family. At $0.25/million tokens of input and $1.5/million output this is 1/8th the price of Gemini 3.1 Pro.
It supports four different thinking levels, so I had it output four different pelicans:

minimal

low

medium
high
Introducing Claude Sonnet 4.6 (via) Sonnet 4.6 is out today, and Anthropic claim it offers similar performance to November's Opus 4.5 while maintaining the Sonnet pricing of $3/million input and $15/million output tokens (the Opus models are $5/$25). Here's the system card PDF.
Sonnet 4.6 has a "reliable knowledge cutoff" of August 2025, compared to Opus 4.6's May 2025 and Haiku 4.5's February 2025. Both Opus and Sonnet default to 200,000 max input tokens but can stretch to 1 million in beta and at a higher cost.
I just released llm-anthropic 0.24 with support for both Sonnet 4.6 and Opus 4.6. Claude Code did most of the work - the new models had a fiddly amount of extra details around adaptive thinking and no longer supporting prefixes, as described in Anthropic's migration guide.
Here's what I got from:
uvx --with llm-anthropic llm 'Generate an SVG of a pelican riding a bicycle' -m claude-sonnet-4.6

The SVG comments include:
<!-- Hat (fun accessory) -->
I tried a second time and also got a top hat. Sonnet 4.6 apparently loves top hats!
For comparison, here's the pelican Opus 4.5 drew me in November:

And here's Anthropic's current best pelican, drawn by Opus 4.6 on February 5th:

Opus 4.6 produces the best pelican beak/pouch. I do think the top hat from Sonnet 4.6 is a nice touch though.
Claude: Speed up responses with fast mode.
New "research preview" from Anthropic today: you can now access a faster version of their frontier model Claude Opus 4.6 by typing /fast in Claude Code... but at a cost that's 6x the normal price.
Opus is usually $5/million input and $25/million output. The new fast mode is $30/million input and $150/million output!
There's a 50% discount until the end of February 16th, so only a 3x multiple (!) before then.
How much faster is it? The linked documentation doesn't say, but on Twitter Claude say:
Our teams have been building with a 2.5x-faster version of Claude Opus 4.6.
We’re now making it available as an early experiment via Claude Code and our API.
Claude Opus 4.5 had a context limit of 200,000 tokens. 4.6 has an option to increase that to 1,000,000 at 2x the input price ($10/m) and 1.5x the output price ($37.50/m) once your input exceeds 200,000 tokens. These multiples hold for fast mode too, so after Feb 16th you'll be able to pay a hefty $60/m input and $225/m output for Anthropic's fastest best model.
2025
Gemini 3 Flash

It continues to be a busy December, if not quite as busy as last year. Today’s big news is Gemini 3 Flash, the latest in Google’s “Flash” line of faster and less expensive models.
[... 1,271 words]Claude Opus 4.5, and why evaluating new LLMs is increasingly difficult

Anthropic released Claude Opus 4.5 this morning, which they call “best model in the world for coding, agents, and computer use”. This is their attempt to retake the crown for best coding model after significant challenges from OpenAI’s GPT-5.1-Codex-Max and Google’s Gemini 3, both released within the past week!
[... 1,120 words]Trying out Gemini 3 Pro with audio transcription and a new pelican benchmark

Google released Gemini 3 Pro today. Here’s the announcement from Sundar Pichai, Demis Hassabis, and Koray Kavukcuoglu, their developer blog announcement from Logan Kilpatrick, the Gemini 3 Pro Model Card, and their collection of 11 more articles. It’s a big release!
[... 2,476 words]MiniMax M2 & Agent: Ingenious in Simplicity. MiniMax M2 was released on Monday 27th October by MiniMax, a Chinese AI lab founded in December 2021.
It's a very promising model. Their self-reported benchmark scores show it as comparable to Claude Sonnet 4, and Artificial Analysis are ranking it as the best currently available open weight model according to their intelligence score:
MiniMax’s M2 achieves a new all-time-high Intelligence Index score for an open weights model and offers impressive efficiency with only 10B active parameters (200B total). [...]
The model’s strengths include tool use and instruction following (as shown by Tau2 Bench and IFBench). As such, while M2 likely excels at agentic use cases it may underperform other open weights leaders such as DeepSeek V3.2 and Qwen3 235B at some generalist tasks. This is in line with a number of recent open weights model releases from Chinese AI labs which focus on agentic capabilities, likely pointing to a heavy post-training emphasis on RL.
The size is particularly significant: the model weights are 230GB on Hugging Face, significantly smaller than other high performing open weight models. That's small enough to run on a 256GB Mac Studio, and the MLX community have that working already.
MiniMax offer their own API, and recommend using their Anthropic-compatible endpoint and the official Anthropic SDKs to access it. MiniMax Head of Engineering Skyler Miao provided some background on that:
M2 is a agentic thinking model, it do interleaved thinking like sonnet 4.5, which means every response will contain its thought content. Its very important for M2 to keep the chain of thought. So we must make sure the history thought passed back to the model. Anthropic API support it for sure, as sonnet needs it as well. OpenAI only support it in their new Response API, no support for in ChatCompletion.
MiniMax are offering the new model via their API for free until November 7th, after which the cost will be $0.30/million input tokens and $1.20/million output tokens - similar in price to Gemini 2.5 Flash and GPT-5 Mini, see price comparison here on my llm-prices.com site.
I released a new plugin for LLM called llm-minimax providing support for M2 via the MiniMax API:
llm install llm-minimax
llm keys set minimax
# Paste key here
llm -m m2 -o max_tokens 10000 "Generate an SVG of a pelican riding a bicycle"
Here's the result:

51 input, 4,017 output. At $0.30/m input and $1.20/m output that pelican would cost 0.4836 cents - less than half a cent.
This is the first plugin I've written for an Anthropic-API-compatible model. I released llm-anthropic 0.21 first adding the ability to customize the base_url parameter when using that model class. This meant the new plugin was less than 30 lines of Python.
Introducing Claude Haiku 4.5 (via) Anthropic released Claude Haiku 4.5 today, the cheapest member of the Claude 4.5 family that started with Sonnet 4.5 a couple of weeks ago.
It's priced at $1/million input tokens and $5/million output tokens, slightly more expensive than Haiku 3.5 ($0.80/$4) and a lot more expensive than the original Claude 3 Haiku ($0.25/$1.25), both of which remain available at those prices.
It's a third of the price of Sonnet 4 and Sonnet 4.5 (both $3/$15) which is notable because Anthropic's benchmarks put it in a similar space to that older Sonnet 4 model. As they put it:
What was recently at the frontier is now cheaper and faster. Five months ago, Claude Sonnet 4 was a state-of-the-art model. Today, Claude Haiku 4.5 gives you similar levels of coding performance but at one-third the cost and more than twice the speed.
I've been hoping to see Anthropic release a fast, inexpensive model that's price competitive with the cheapest models from OpenAI and Gemini, currently $0.05/$0.40 (GPT-5-Nano) and $0.075/$0.30 (Gemini 2.0 Flash Lite). Haiku 4.5 certainly isn't that, it looks like they're continuing to focus squarely on the "great at code" part of the market.
The new Haiku is the first Haiku model to support reasoning. It sports a 200,000 token context window, 64,000 maximum output (up from just 8,192 for Haiku 3.5) and a "reliable knowledge cutoff" of February 2025, one month later than the January 2025 date for Sonnet 4 and 4.5 and Opus 4 and 4.1.
Something that caught my eye in the accompanying system card was this note about context length:
For Claude Haiku 4.5, we trained the model to be explicitly context-aware, with precise information about how much context-window has been used. This has two effects: the model learns when and how to wrap up its answer when the limit is approaching, and the model learns to continue reasoning more persistently when the limit is further away. We found this intervention—along with others—to be effective at limiting agentic “laziness” (the phenomenon where models stop working on a problem prematurely, give incomplete answers, or cut corners on tasks).
I've added the new price to llm-prices.com, released llm-anthropic 0.20 with the new model and updated my Haiku-from-your-webcam demo (source) to use Haiku 4.5 as well.
Here's llm -m claude-haiku-4.5 'Generate an SVG of a pelican riding a bicycle' (transcript).

18 input tokens and 1513 output tokens = 0.7583 cents.