77 posts tagged “llm-pricing”
Posts about the pricing of various LLMs. See also my pricing calculator.
2025
Two interesting examples of inference speed as a flagship feature of LLM services today.
First, Cerebras announced two new monthly plans for their extremely high speed hosted model service: Cerebras Code Pro ($50/month, 1,000 messages a day) and Cerebras Code Max ($200/month, 5,000/day). The model they are selling here is Qwen's Qwen3-Coder-480B-A35B-Instruct, likely the best available open weights coding model right now and one that was released just ten days ago. Ten days from model release to third-party subscription service feels like some kind of record.
Cerebras claim they can serve the model at an astonishing 2,000 tokens per second - four times the speed of Claude Sonnet 4 in their demo video.
Also today, Moonshot announced a new hosted version of their trillion parameter Kimi K2 model called kimi-k2-turbo-preview:
🆕 Say hello to kimi-k2-turbo-preview Same model. Same context. NOW 4× FASTER.
⚡️ From 10 tok/s to 40 tok/s.
💰 Limited-Time Launch Price (50% off until Sept 1)
- $0.30 / million input tokens (cache hit)
- $1.20 / million input tokens (cache miss)
- $5.00 / million output tokens
👉 Explore more: platform.moonshot.ai
This is twice the price of their regular model for 4x the speed (increasing to 4x the price in September). No details yet on how they achieved the speed-up.
I am interested to see how much market demand there is for faster performance like this. I've experimented with Cerebras in the past and found that the speed really does make iterating on code with live previews feel a whole lot more interactive.
We’re rolling out new weekly rate limits for Claude Pro and Max in late August. We estimate they’ll apply to less than 5% of subscribers based on current usage. [...]
Some of the biggest Claude Code fans are running it continuously in the background, 24/7.
These uses are remarkable and we want to enable them. But a few outlying cases are very costly to support. For example, one user consumed tens of thousands in model usage on a $200 plan.
Qwen3-Coder: Agentic Coding in the World (via) It turns out that as I was typing up my notes on Qwen3-235B-A22B-Instruct-2507 the Qwen team were unleashing something much bigger:
Today, we’re announcing Qwen3-Coder, our most agentic code model to date. Qwen3-Coder is available in multiple sizes, but we’re excited to introduce its most powerful variant first: Qwen3-Coder-480B-A35B-Instruct — a 480B-parameter Mixture-of-Experts model with 35B active parameters which supports the context length of 256K tokens natively and 1M tokens with extrapolation methods, offering exceptional performance in both coding and agentic tasks.
This is another Apache 2.0 licensed open weights model, available as Qwen3-Coder-480B-A35B-Instruct and Qwen3-Coder-480B-A35B-Instruct-FP8 on Hugging Face.
I used qwen3-coder-480b-a35b-instruct on the Hyperbolic playground to run my "Generate an SVG of a pelican riding a bicycle" test prompt:

I actually slightly prefer the one I got from qwen3-235b-a22b-07-25.
It's also available as qwen3-coder on OpenRouter.
In addition to the new model, Qwen released their own take on an agentic terminal coding assistant called qwen-code, which they describe in their blog post as being "Forked from Gemini Code" (they mean gemini-cli) - which is Apache 2.0 so a fork is in keeping with the license.
They focused really hard on code performance for this release, including generating synthetic data tested using 20,000 parallel environments on Alibaba Cloud:
In the post-training phase of Qwen3-Coder, we introduced long-horizon RL (Agent RL) to encourage the model to solve real-world tasks through multi-turn interactions using tools. The key challenge of Agent RL lies in environment scaling. To address this, we built a scalable system capable of running 20,000 independent environments in parallel, leveraging Alibaba Cloud’s infrastructure. The infrastructure provides the necessary feedback for large-scale reinforcement learning and supports evaluation at scale. As a result, Qwen3-Coder achieves state-of-the-art performance among open-source models on SWE-Bench Verified without test-time scaling.
To further burnish their coding credentials, the announcement includes instructions for running their new model using both Claude Code and Cline using custom API base URLs that point to Qwen's own compatibility proxies.
Pricing for Qwen's own hosted models (through Alibaba Cloud) looks competitive. This is the first model I've seen that sets different prices for four different sizes of input:
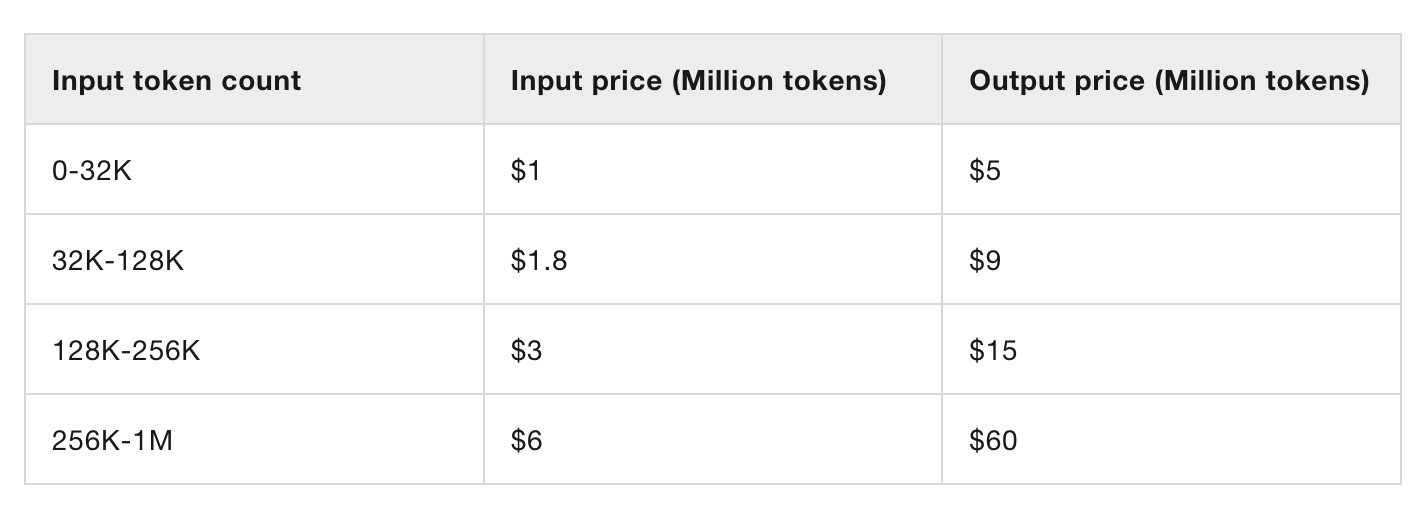
This kind of pricing reflects how inference against longer inputs is more expensive to process. Gemini 2.5 Pro has two different prices for above or below 200,00 tokens.
Awni Hannun reports running a 4-bit quantized MLX version on a 512GB M3 Ultra Mac Studio at 24 tokens/second using 272GB of RAM, getting great results for "write a python script for a bouncing yellow ball within a square, make sure to handle collision detection properly. make the square slowly rotate. implement it in python. make sure ball stays within the square".
Gemini 2.5 Flash-Lite is now stable and generally available. The last remaining member of the Gemini 2.5 trio joins Pro and Flash in General Availability today.
Gemini 2.5 Flash-Lite is the cheapest of the 2.5 family, at $0.10/million input tokens and $0.40/million output tokens. This puts it equal to GPT-4.1 Nano on my llm-prices.com comparison table.
The preview version of that model had the same pricing for text tokens, but is now cheaper for audio:
We have also reduced audio input pricing by 40% from the preview launch.
I released llm-gemini 0.24 with support for the new model alias:
llm install -U llm-gemini
llm -m gemini-2.5-flash-lite \
-a https://static.simonwillison.net/static/2024/pelican-joke-request.mp3
I wrote more about the Gemini 2.5 Flash-Lite preview model last month.
Grok 4. Released last night, Grok 4 is now available via both API and a paid subscription for end-users.
Update: If you ask it about controversial topics it will sometimes search X for tweets "from:elonmusk"!
Key characteristics: image and text input, text output. 256,000 context length (twice that of Grok 3). It's a reasoning model where you can't see the reasoning tokens or turn off reasoning mode.
xAI released results showing Grok 4 beating other models on most of the significant benchmarks. I haven't been able to find their own written version of these (the launch was a livestream video) but here's a TechCrunch report that includes those scores. It's not clear to me if these benchmark results are for Grok 4 or Grok 4 Heavy.
I ran my own benchmark using Grok 4 via OpenRouter (since I have API keys there already).
llm -m openrouter/x-ai/grok-4 "Generate an SVG of a pelican riding a bicycle" \
-o max_tokens 10000

I then asked Grok to describe the image it had just created:
llm -m openrouter/x-ai/grok-4 -o max_tokens 10000 \
-a https://static.simonwillison.net/static/2025/grok4-pelican.png \
'describe this image'
Here's the result. It described it as a "cute, bird-like creature (resembling a duck, chick, or stylized bird)".
The most interesting independent analysis I've seen so far is this one from Artificial Analysis:
We have run our full suite of benchmarks and Grok 4 achieves an Artificial Analysis Intelligence Index of 73, ahead of OpenAI o3 at 70, Google Gemini 2.5 Pro at 70, Anthropic Claude 4 Opus at 64 and DeepSeek R1 0528 at 68.
The timing of the release is somewhat unfortunate, given that Grok 3 made headlines just this week after a clumsy system prompt update - presumably another attempt to make Grok "less woke" - caused it to start firing off antisemitic tropes and referring to itself as MechaHitler.
My best guess is that these lines in the prompt were the root of the problem:
- If the query requires analysis of current events, subjective claims, or statistics, conduct a deep analysis finding diverse sources representing all parties. Assume subjective viewpoints sourced from the media are biased. No need to repeat this to the user.
- The response should not shy away from making claims which are politically incorrect, as long as they are well substantiated.
If xAI expect developers to start building applications on top of Grok they need to do a lot better than this. Absurd self-inflicted mistakes like this do not build developer trust!
As it stands, Grok 4 isn't even accompanied by a model card.
Update: Ian Bicking makes an astute point:
It feels very credulous to ascribe what happened to a system prompt update. Other models can't be pushed into racism, Nazism, and ideating rape with a system prompt tweak.
Even if that system prompt change was responsible for unlocking this behavior, the fact that it was able to speaks to a much looser approach to model safety by xAI compared to other providers.
Update 12th July 2025: Grok posted a postmortem blaming the behavior on a different set of prompts, including "you are not afraid to offend people who are politically correct", that were not included in the system prompts they had published to their GitHub repository.
Grok 4 is competitively priced. It's $3/million for input tokens and $15/million for output tokens - the same price as Claude Sonnet 4. Once you go above 128,000 input tokens the price doubles to $6/$30 (Gemini 2.5 Pro has a similar price increase for longer inputs). I've added these prices to llm-prices.com.
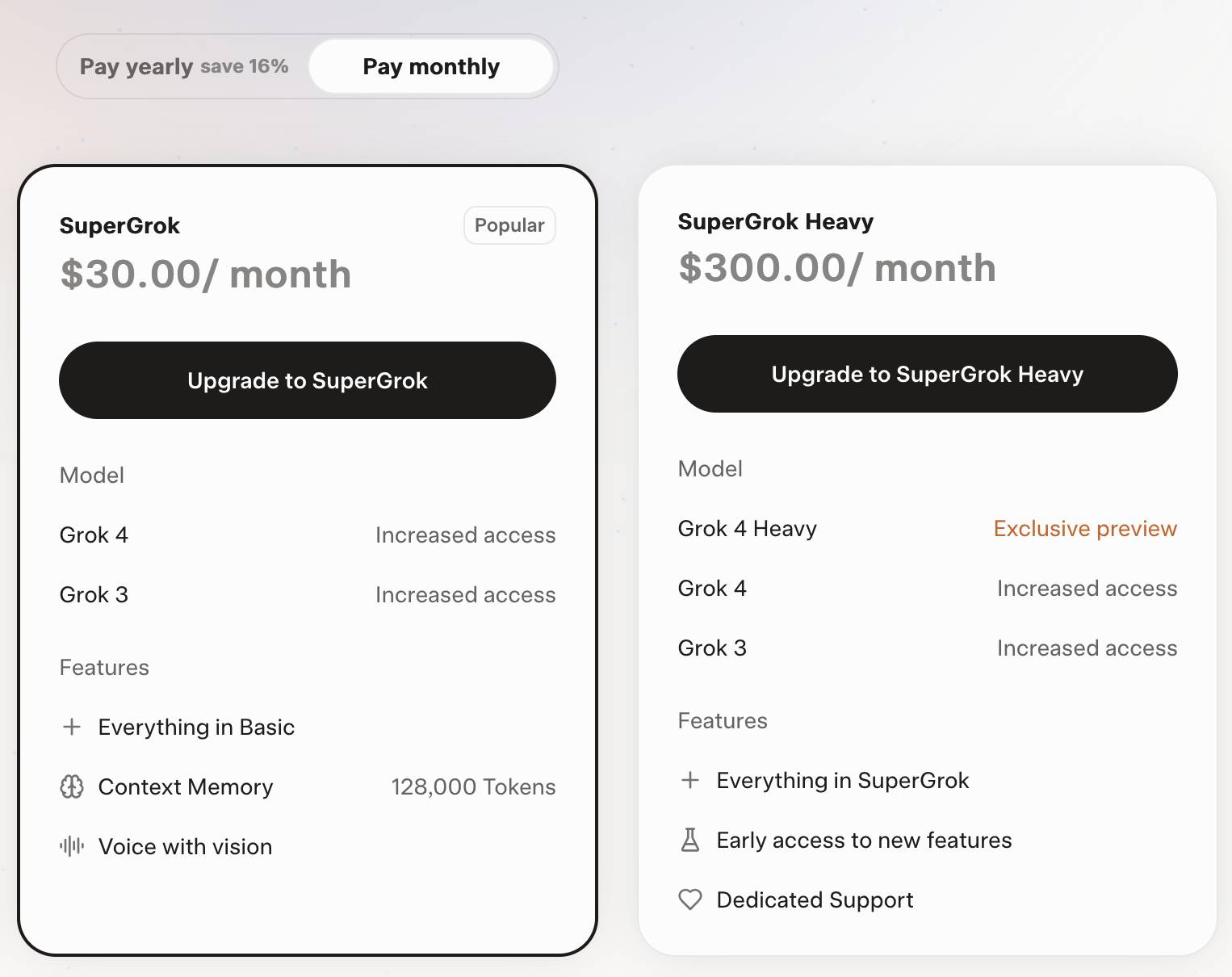
Consumers can access Grok 4 via a new $30/month or $300/year "SuperGrok" plan - or a $300/month or $3,000/year "SuperGrok Heavy" plan providing access to Grok 4 Heavy.
Cursor: Clarifying Our Pricing. Cursor changed their pricing plan on June 16th, introducing a new $200/month Ultra plan with "20x more usage than Pro" and switching their $20/month Pro plan from "request limits to compute limits".
This confused a lot of people. Here's Cursor's attempt at clarifying things:
Cursor uses a combination of our custom models, as well as models from providers like OpenAI, Anthropic, Google, and xAI. For external models, we previously charged based on the number of requests made. There was a limit of 500 requests per month, with Sonnet models costing two requests.
New models can spend more tokens per request on longer-horizon tasks. Though most users' costs have stayed fairly constant, the hardest requests cost an order of magnitude more than simple ones. API-based pricing is the best way to reflect that.
I think I understand what they're saying there. They used to allow you 500 requests per month, but those requests could be made against any model and, crucially, a single request could trigger a variable amount of token spend.
Modern LLMs can have dramatically different prices, so one of those 500 requests with a large context query against an expensive model could cost a great deal more than a single request with a shorter context against something less expensive.
I imagine they were losing money on some of their more savvy users, who may have been using prompting techniques that sent a larger volume of tokens through each one of those precious 500 requests.
The new billing switched to passing on the expense of those tokens directly, with a $20 included budget followed by overage charges for tokens beyond that.
It sounds like a lot of people, used to the previous model where their access would be cut off after 500 requests, got caught out by this and racked up a substantial bill!
To cursor's credit, they're offering usage refunds to "those with unexpected usage between June 16 and July 4."
I think this highlights a few interesting trends.
Firstly, the era of VC-subsidized tokens may be coming to an end, especially for products like Cursor which are way past demonstrating product-market fit.
Secondly, that $200/month plan for 20x the usage of the $20/month plan is an emerging pattern: Anthropic offers the exact same deal for Claude Code, with the same 10x price for 20x usage multiplier.
Professional software engineers may be able to justify one $200/month subscription, but I expect most will be unable to justify two. The pricing here becomes a significant form of lock-in - once you've picked your $200/month coding assistant you are less likely to evaluate the alternatives.
Trying out the new Gemini 2.5 model family

After many months of previews, Gemini 2.5 Pro and Flash have reached general availability with new, memorable model IDs: gemini-2.5-pro and gemini-2.5-flash. They are joined by a new preview model with an unmemorable name: gemini-2.5-flash-lite-preview-06-17 is a new Gemini 2.5 Flash Lite model that offers lower prices and much faster inference times.
o3-pro. OpenAI released o3-pro today, which they describe as a "version of o3 with more compute for better responses".
It's only available via the newer Responses API. I've added it to my llm-openai-plugin plugin which uses that new API, so you can try it out like this:
llm install -U llm-openai-plugin
llm -m openai/o3-pro "Generate an SVG of a pelican riding a bicycle"

It's slow - generating this pelican took 124 seconds! OpenAI suggest using their background mode for o3 prompts, which I haven't tried myself yet.
o3-pro is priced at $20/million input tokens and $80/million output tokens - 10x the price of regular o3 after its 80% price drop this morning.
Ben Hylak had early access and published his notes so far in God is hungry for Context: First thoughts on o3 pro. It sounds like this model needs to be applied very thoughtfully. It comparison to o3:
It's smarter. much smarter.
But in order to see that, you need to give it a lot more context. and I'm running out of context. [...]
My co-founder Alexis and I took the the time to assemble a history of all of our past planning meetings at Raindrop, all of our goals, even record voice memos: and then asked o3-pro to come up with a plan.
We were blown away; it spit out the exact kind of concrete plan and analysis I've always wanted an LLM to create --- complete with target metrics, timelines, what to prioritize, and strict instructions on what to absolutely cut.
The plan o3 gave us was plausible, reasonable; but the plan o3 Pro gave us was specific and rooted enough that it actually changed how we are thinking about our future.
This is hard to capture in an eval.
It sounds to me like o3-pro works best when combined with tools. I don't have tool support in llm-openai-plugin yet, here's the relevant issue.
OpenAI just dropped the price of their o3 model by 80% - from $10/million input tokens and $40/million output tokens to just $2/million and $8/million for the very same model. This is in advance of the release of o3-pro which apparently is coming later today (update: here it is).
This is a pretty huge shake-up in LLM pricing. o3 is now priced the same as GPT 4.1, and slightly less than GPT-4o ($2.50/$10). It’s also less than Anthropic’s Claude Sonnet 4 ($3/$15) and Opus 4 ($15/$75) and sits in between Google’s Gemini 2.5 Pro for >200,00 tokens ($2.50/$15) and 2.5 Pro for <200,000 ($1.25/$10).
I’ve updated my llm-prices.com pricing calculator with the new rate.
How have they dropped the price so much? OpenAI's Adam Groth credits ongoing optimization work:
thanks to the engineers optimizing inferencing.
Magistral — the first reasoning model by Mistral AI. Mistral's first reasoning model is out today, in two sizes. There's a 24B Apache 2 licensed open-weights model called Magistral Small (actually Magistral-Small-2506), and a larger API-only model called Magistral Medium.
Magistral Small is available as mistralai/Magistral-Small-2506 on Hugging Face. From that model card:
Context Window: A 128k context window, but performance might degrade past 40k. Hence we recommend setting the maximum model length to 40k.
Mistral also released an official GGUF version, Magistral-Small-2506_gguf, which I ran successfully using Ollama like this:
ollama pull hf.co/mistralai/Magistral-Small-2506_gguf:Q8_0
That fetched a 25GB file. I ran prompts using a chat session with llm-ollama like this:
llm chat -m hf.co/mistralai/Magistral-Small-2506_gguf:Q8_0
Here's what I got for "Generate an SVG of a pelican riding a bicycle" (transcript here):

It's disappointing that the GGUF doesn't support function calling yet - hopefully a community variant can add that, it's one of the best ways I know of to unlock the potential of these reasoning models.
I just noticed that Ollama have their own Magistral model too, which can be accessed using:
ollama pull magistral:latest
That gets you a 14GB q4_K_M quantization - other options can be found in the full list of Ollama magistral tags.
One thing that caught my eye in the Magistral announcement:
Legal, finance, healthcare, and government professionals get traceable reasoning that meets compliance requirements. Every conclusion can be traced back through its logical steps, providing auditability for high-stakes environments with domain-specialized AI.
I guess this means the reasoning traces are fully visible and not redacted in any way - interesting to see Mistral trying to turn that into a feature that's attractive to the business clients they are most interested in appealing to.
Also from that announcement:
Our early tests indicated that Magistral is an excellent creative companion. We highly recommend it for creative writing and storytelling, with the model capable of producing coherent or — if needed — delightfully eccentric copy.
I haven't seen a reasoning model promoted for creative writing in this way before.
You can try out Magistral Medium by selecting the new "Thinking" option in Mistral's Le Chat.
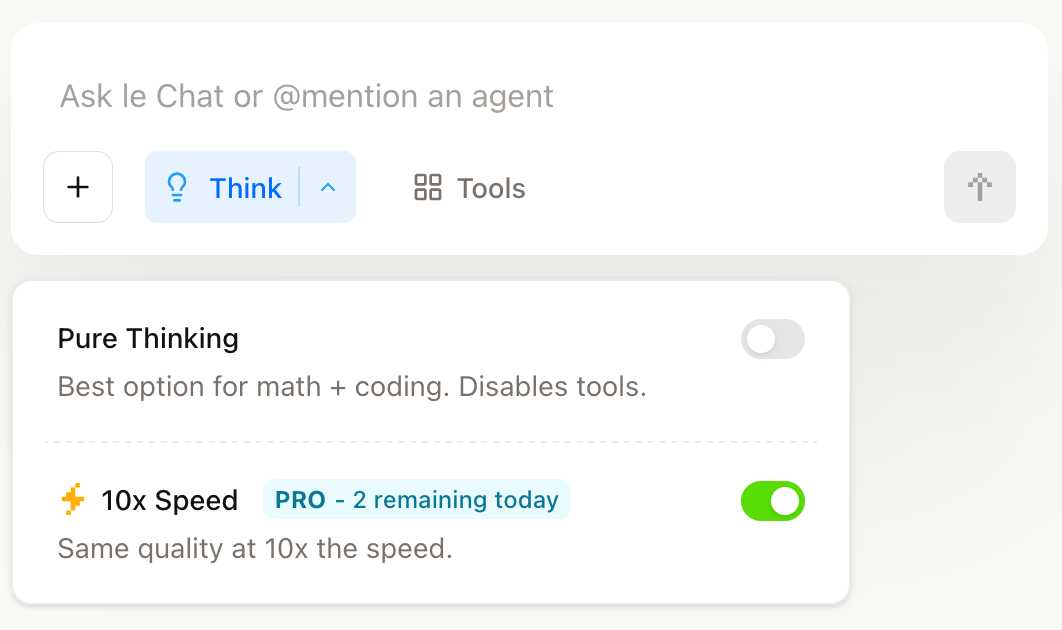
They have options for "Pure Thinking" and a separate option for "10x speed", which runs Magistral Medium at 10x the speed using Cerebras.
The new models are also available through the Mistral API. You can access them by installing llm-mistral and running llm mistral refresh to refresh the list of available models, then:
llm -m mistral/magistral-medium-latest \
'Generate an SVG of a pelican riding a bicycle'

Here's that transcript. At 13 input and 1,236 output tokens that cost me 0.62 cents - just over half a cent.
Here's a quick demo of the kind of casual things I use LLMs for on a daily basis.
I just found out that Perplexity offer their Deep Research feature via their API, through a model called Sonar Deep Research.
Their documentation includes an example response, which included this usage data in the JSON:
{"prompt_tokens": 19, "completion_tokens": 498, "total_tokens": 517, "citation_tokens": 10175, "num_search_queries": 48, "reasoning_tokens": 95305}
But how much would that actually cost?
Their pricing page lists the price for that model. I snapped this screenshot of the prices:

I could break out a calculator at this point, but I'm not quite curious enough to go through the extra effort.
So I pasted that screenshot into Claude along with the JSON and prompted:
{"prompt_tokens": 19, "completion_tokens": 498, "total_tokens": 517, "citation_tokens": 10175, "num_search_queries": 48, "reasoning_tokens": 95305}Calculate price, use javascript
I wanted to make sure Claude would use its JavaScript analysis tool, since LLMs can't do maths.
I watched Claude Sonnet 4 write 61 lines of JavaScript - keeping an eye on it to check it didn't do anything obviously wrong. The code spat out this output:
=== COST CALCULATIONS ===
Input tokens cost: 19 tokens × $2/million = $0.000038
Output tokens cost: 498 tokens × $8/million = $0.003984
Search queries cost: 48 queries × $5/1000 = $0.240000
Reasoning tokens cost: 95305 tokens × $3/million = $0.285915
=== COST SUMMARY ===
Input tokens: $0.000038
Output tokens: $0.003984
Search queries: $0.240000
Reasoning tokens: $0.285915
─────────────────────────
TOTAL COST: $0.529937
TOTAL COST: $0.5299 (rounded to 4 decimal places)
So that Deep Research API call would cost 53 cents! Curiosity satisfied in less than a minute.
Updated Anthropic model comparison table. A few details in here about Claude 4 that I hadn't spotted elsewhere:
- The training cut-off date for Claude Opus 4 and Claude Sonnet 4 is March 2025! That's the most recent cut-off for any of the current popular models, really impressive.
- Opus 4 has a max output of 32,000 tokens, Sonnet 4 has a max output of 64,000 tokens. Claude 3.7 Sonnet is 64,000 tokens too, so this is a small regression for Opus.
- The input limit for both of the Claude 4 models is still stuck at 200,000. I'm disjointed by this, I was hoping for a leap to a million to catch up with GPT 4.1 and the Gemini Pro series.
- Claude 3 Haiku is still in that table - it remains Anthropic's cheapest model, priced slightly lower than Claude 3.5 Haiku.
For pricing: Sonnet 4 is the same price as Sonnet 3.7 ($3/million input, $15/million output). Opus 4 matches the pricing of the older Opus 3 - $15/million for input and $75/million for output. I've updated llm-prices.com with the new models.
I spotted a few more interesting details in Anthropic's Migrating to Claude 4 documentation:
Claude 4 models introduce a new
refusalstop reason for content that the model declines to generate for safety reasons, due to the increased intelligence of Claude 4 models.
Plus this note on the new summarized thinking feature:
With extended thinking enabled, the Messages API for Claude 4 models returns a summary of Claude’s full thinking process. Summarized thinking provides the full intelligence benefits of extended thinking, while preventing misuse.
While the API is consistent across Claude 3.7 and 4 models, streaming responses for extended thinking might return in a “chunky” delivery pattern, with possible delays between streaming events.
Summarization is processed by a different model than the one you target in your requests. The thinking model does not see the summarized output.
There's a new beta header, interleaved-thinking-2025-05-14, which turns on the "interleaved thinking" feature where tools can be called as part of the chain-of-thought. More details on that in the interleaved thinking documentation.
This is a frustrating note:
- You’re charged for the full thinking tokens generated by the original request, not the summary tokens.
- The billed output token count will not match the count of tokens you see in the response.
I initially misread that second bullet as meaning we would no longer be able to estimate costs based on the return token counts, but it's just warning us that we might see an output token integer that doesn't exactly match the visible tokens that were returned in the API.
Gemini 2.5: Our most intelligent models are getting even better. A bunch of new Gemini 2.5 announcements at Google I/O today.
2.5 Flash and 2.5 Pro are both getting audio output (previously previewed in Gemini 2.0) and 2.5 Pro is getting an enhanced reasoning mode called "Deep Think" - not yet available via the API.
Available today is the latest Gemini 2.5 Flash model, gemini-2.5-flash-preview-05-20. I added support to that in llm-gemini 0.20 (and, if you're using the LLM tool-use alpha, llm-gemini 0.20a2).
I tried it out on my personal benchmark, as seen in the Google I/O keynote!
llm -m gemini-2.5-flash-preview-05-20 'Generate an SVG of a pelican riding a bicycle'
Here's what I got from the default model, with its thinking mode enabled:
Full transcript. 11 input tokens, 2,619 output tokens, 10,391 thinking tokens = 4.5537 cents.
I ran the same thing again with -o thinking_budget 0 to turn off thinking mode entirely, and got this:

Full transcript. 11 input, 1,243 output = 0.0747 cents.
The non-thinking model is priced differently - still $0.15/million for input but $0.60/million for output as opposed to $3.50/million for thinking+output. The pelican it drew was 61x cheaper!
Finally, inspired by the keynote I ran this follow-up prompt to animate the more expensive pelican:
llm --cid 01jvqjqz9aha979yemcp7a4885 'Now animate it'
This one is pretty great!

Building software on top of Large Language Models

I presented a three hour workshop at PyCon US yesterday titled Building software on top of Large Language Models. The goal of the workshop was to give participants everything they needed to get started writing code that makes use of LLMs.
[... 3,726 words]Gemini 2.5 Models now support implicit caching.
I just spotted a cacheTokensDetails key in the token usage JSON while running a long chain of prompts against Gemini 2.5 Flash - despite not configuring caching myself:
{"cachedContentTokenCount": 200658, "promptTokensDetails": [{"modality": "TEXT", "tokenCount": 204082}], "cacheTokensDetails": [{"modality": "TEXT", "tokenCount": 200658}], "thoughtsTokenCount": 2326}
I went searching and it turns out Gemini had a massive upgrade to their prompt caching earlier today:
Implicit caching directly passes cache cost savings to developers without the need to create an explicit cache. Now, when you send a request to one of the Gemini 2.5 models, if the request shares a common prefix as one of previous requests, then it’s eligible for a cache hit. We will dynamically pass cost savings back to you, providing the same 75% token discount. [...]
To make more requests eligible for cache hits, we reduced the minimum request size for 2.5 Flash to 1024 tokens and 2.5 Pro to 2048 tokens.
Previously you needed to both explicitly configure the cache and pay a per-hour charge to keep that cache warm.
This new mechanism is so much more convenient! It imitates how both DeepSeek and OpenAI implement prompt caching, leaving Anthropic as the remaining large provider who require you to manually configure prompt caching to get it to work.
Gemini's explicit caching mechanism is still available. The documentation says:
Explicit caching is useful in cases where you want to guarantee cost savings, but with some added developer work.
With implicit caching the cost savings aren't possible to predict in advance, especially since the cache timeout within which a prefix will be discounted isn't described and presumably varies based on load and other circumstances outside of the developer's control.
Update: DeepMind's Philipp Schmid:
There is no fixed time, but it's should be a few minutes.
llm-gemini 0.19.1.
Bugfix release for my llm-gemini plugin, which was recording the number of output tokens (needed to calculate the price of a response) incorrectly for the Gemini "thinking" models. Those models turn out to return candidatesTokenCount and thoughtsTokenCount as two separate values which need to be added together to get the total billed output token count. Full details in this issue.
I spotted this potential bug in this response log this morning, and my concerns were confirmed when Paul Gauthier wrote about a similar fix in Aider in Gemini 2.5 Pro Preview 03-25 benchmark cost, where he noted that the $6.32 cost recorded to benchmark Gemini 2.5 Pro Preview 03-25 was incorrect. Since that model is no longer available (despite the date-based model alias persisting) Paul is not able to accurately calculate the new cost, but it's likely a lot more since the Gemini 2.5 Pro Preview 05-06 benchmark cost $37.
I've gone through my gemini tag and attempted to update my previous posts with new calculations - this mostly involved increases in the order of 12.336 cents to 16.316 cents (as seen here).
Medium is the new large. New model release from Mistral - this time closed source/proprietary. Mistral Medium claims strong benchmark scores similar to GPT-4o and Claude 3.7 Sonnet, but is priced at $0.40/million input and $2/million output - about the same price as GPT 4.1 Mini. For comparison, GPT-4o is $2.50/$10 and Claude 3.7 Sonnet is $3/$15.
The model is a vision LLM, accepting both images and text.
More interesting than the price is the deployment model. Mistral Medium may not be open weights but it is very much available for self-hosting:
Mistral Medium 3 can also be deployed on any cloud, including self-hosted environments of four GPUs and above.
Mistral's other announcement today is Le Chat Enterprise. This is a suite of tools that can integrate with your company's internal data and provide "agents" (these look similar to Claude Projects or OpenAI GPTs), again with the option to self-host.
Is there a new open weights model coming soon? This note tucked away at the bottom of the Mistral Medium 3 announcement seems to hint at that:
With the launches of Mistral Small in March and Mistral Medium today, it's no secret that we're working on something 'large' over the next few weeks. With even our medium-sized model being resoundingly better than flagship open source models such as Llama 4 Maverick, we're excited to 'open' up what's to come :)
I released llm-mistral 0.12 adding support for the new model.
llm-prices.com.
I've been maintaining a simple LLM pricing calculator since October last year. I finally decided to split it out to its own domain name (previously it was hosted at tools.simonwillison.net/llm-prices), running on Cloudflare Pages.
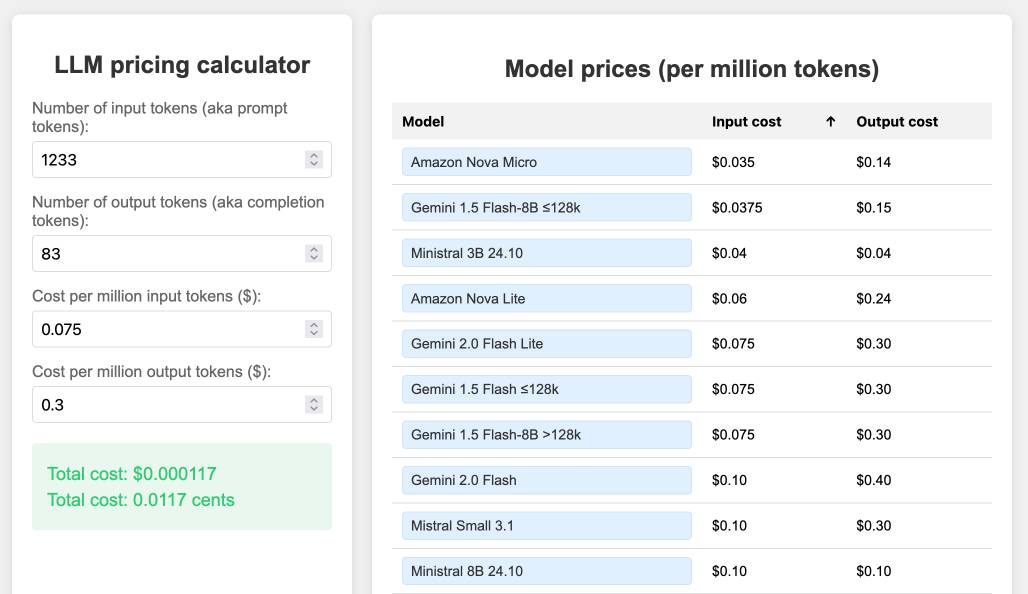
The site runs out of my simonw/llm-prices GitHub repository. I ported the history of the old llm-prices.html file using a vibe-coded bash script that I forgot to save anywhere.
I rarely use AI-generated imagery in my own projects, but for this one I found an excellent reason to use GPT-4o image outputs... to generate the favicon! I dropped a screenshot of the site into ChatGPT (o4-mini-high in this case) and asked for the following:
design a bunch of options for favicons for this site in a single image, white background

I liked the top right one, so I cropped it into Pixelmator and made a 32x32 version. Here's what it looks like in my browser:
I added a new feature just now: the state of the calculator is now reflected in the #fragment-hash URL of the page, which means you can link to your previous calculations.
I implemented that feature using the new gemini-2.5-pro-preview-05-06, since that model boasts improved front-end coding abilities. It did a pretty great job - here's how I prompted it:
llm -m gemini-2.5-pro-preview-05-06 -f https://www.llm-prices.com/ -s 'modify this code so that the state of the page is reflected in the fragmenth hash URL - I want to capture the values filling out the form fields and also the current sort order of the table. These should be respected when the page first loads too. Update them using replaceHistory, no need to enable the back button.'
Here's the transcript and the commit updating the tool, plus an example link showing the new feature in action (and calculating the cost for that Gemini 2.5 Pro prompt at 16.8224 cents, after fixing the calculation.)
Image segmentation using Gemini 2.5

Max Woolf pointed out this new feature of the Gemini 2.5 series (here’s my coverage of 2.5 Pro and 2.5 Flash) in a comment on Hacker News:
[... 1,428 words]Start building with Gemini 2.5 Flash
(via)
Google Gemini's latest model is Gemini 2.5 Flash, available in (paid) preview as gemini-2.5-flash-preview-04-17.
Building upon the popular foundation of 2.0 Flash, this new version delivers a major upgrade in reasoning capabilities, while still prioritizing speed and cost. Gemini 2.5 Flash is our first fully hybrid reasoning model, giving developers the ability to turn thinking on or off. The model also allows developers to set thinking budgets to find the right tradeoff between quality, cost, and latency.
Gemini AI Studio product lead Logan Kilpatrick says:
This is an early version of 2.5 Flash, but it already shows huge gains over 2.0 Flash.
You can fully turn off thinking if needed and use this model as a drop in replacement for 2.0 Flash.
I added support to the new model in llm-gemini 0.18. Here's how to try it out:
llm install -U llm-gemini
llm -m gemini-2.5-flash-preview-04-17 'Generate an SVG of a pelican riding a bicycle'
Here's that first pelican, using the default setting where Gemini Flash 2.5 makes its own decision in terms of how much "thinking" effort to apply:

Here's the transcript. This one used 11 input tokens, 4,266 output tokens and 2,702 "thinking" tokens.
I asked the model to "describe" that image and it could tell it was meant to be a pelican:
A simple illustration on a white background shows a stylized pelican riding a bicycle. The pelican is predominantly grey with a black eye and a prominent pink beak pouch. It is positioned on a black line-drawn bicycle with two wheels, a frame, handlebars, and pedals.
The way the model is priced is a little complicated. If you have thinking enabled, you get charged $0.15/million tokens for input and $3.50/million for output. With thinking disabled those output tokens drop to $0.60/million. I've added these to my pricing calculator.
For comparison, Gemini 2.0 Flash is $0.10/million input and $0.40/million for output.
So my first prompt - 11 input and 4,266+2,702 =6,968 output (with thinking enabled), cost 2.439 cents.
Let's try 2.5 Flash again with thinking disabled:
llm -m gemini-2.5-flash-preview-04-17 'Generate an SVG of a pelican riding a bicycle' -o thinking_budget 0

11 input, 1705 output. That's 0.1025 cents. Transcript here - it still shows 25 thinking tokens even though I set the thinking budget to 0 - Logan confirms that this will still be billed at the lower rate:
In some rare cases, the model still thinks a little even with thinking budget = 0, we are hoping to fix this before we make this model stable and you won't be billed for thinking. The thinking budget = 0 is what triggers the billing switch.
Here's Gemini 2.5 Flash's self-description of that image:
A minimalist illustration shows a bright yellow bird riding a bicycle. The bird has a simple round body, small wings, a black eye, and an open orange beak. It sits atop a simple black bicycle frame with two large circular black wheels. The bicycle also has black handlebars and black and yellow pedals. The scene is set against a solid light blue background with a thick green stripe along the bottom, suggesting grass or ground.
And finally, let's ramp the thinking budget up to the maximum:
llm -m gemini-2.5-flash-preview-04-17 'Generate an SVG of a pelican riding a bicycle' -o thinking_budget 24576
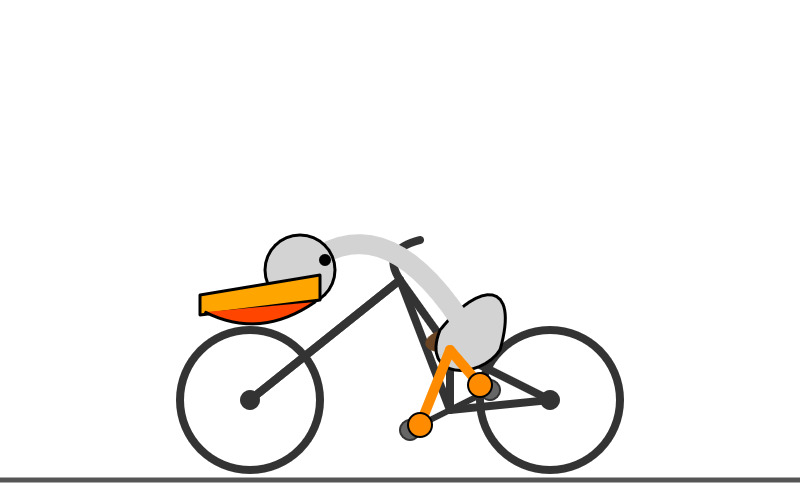
I think it over-thought this one. Transcript - 5,174 output tokens and 3,023 thinking tokens. A hefty 2.8691 cents!
A simple, cartoon-style drawing shows a bird-like figure riding a bicycle. The figure has a round gray head with a black eye and a large, flat orange beak with a yellow stripe on top. Its body is represented by a curved light gray shape extending from the head to a smaller gray shape representing the torso or rear. It has simple orange stick legs with round feet or connections at the pedals. The figure is bent forward over the handlebars in a cycling position. The bicycle is drawn with thick black outlines and has two large wheels, a frame, and pedals connected to the orange legs. The background is plain white, with a dark gray line at the bottom representing the ground.
One thing I really appreciate about Gemini 2.5 Flash's approach to SVGs is that it shows very good taste in CSS, comments and general SVG class structure. Here's a truncated extract - I run a lot of these SVG tests against different models and this one has a coding style that I particularly enjoy. (Gemini 2.5 Pro does this too).
<svg width="800" height="500" viewBox="0 0 800 500" xmlns="http://www.w3.org/2000/svg"> <style> .bike-frame { fill: none; stroke: #333; stroke-width: 8; stroke-linecap: round; stroke-linejoin: round; } .wheel-rim { fill: none; stroke: #333; stroke-width: 8; } .wheel-hub { fill: #333; } /* ... */ .pelican-body { fill: #d3d3d3; stroke: black; stroke-width: 3; } .pelican-head { fill: #d3d3d3; stroke: black; stroke-width: 3; } /* ... */ </style> <!-- Ground Line --> <line x1="0" y1="480" x2="800" y2="480" stroke="#555" stroke-width="5"/> <!-- Bicycle --> <g id="bicycle"> <!-- Wheels --> <circle class="wheel-rim" cx="250" cy="400" r="70"/> <circle class="wheel-hub" cx="250" cy="400" r="10"/> <circle class="wheel-rim" cx="550" cy="400" r="70"/> <circle class="wheel-hub" cx="550" cy="400" r="10"/> <!-- ... --> </g> <!-- Pelican --> <g id="pelican"> <!-- Body --> <path class="pelican-body" d="M 440 330 C 480 280 520 280 500 350 C 480 380 420 380 440 330 Z"/> <!-- Neck --> <path class="pelican-neck" d="M 460 320 Q 380 200 300 270"/> <!-- Head --> <circle class="pelican-head" cx="300" cy="270" r="35"/> <!-- ... -->
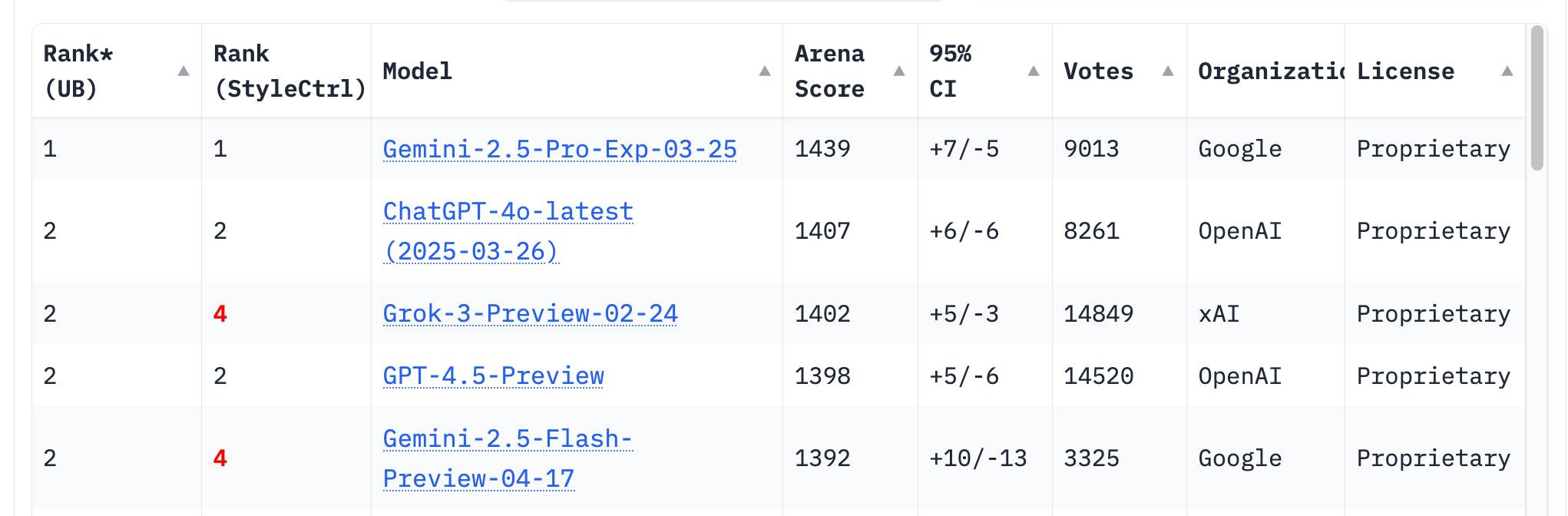
The LM Arena leaderboard now has Gemini 2.5 Flash in joint second place, just behind Gemini 2.5 Pro and tied with ChatGPT-4o-latest, Grok-3 and GPT-4.5 Preview.
Introducing OpenAI o3 and o4-mini. OpenAI are really emphasizing tool use with these:
For the first time, our reasoning models can agentically use and combine every tool within ChatGPT—this includes searching the web, analyzing uploaded files and other data with Python, reasoning deeply about visual inputs, and even generating images. Critically, these models are trained to reason about when and how to use tools to produce detailed and thoughtful answers in the right output formats, typically in under a minute, to solve more complex problems.
I released llm-openai-plugin 0.3 adding support for the two new models:
llm install -U llm-openai-plugin
llm -m openai/o3 "say hi in five languages"
llm -m openai/o4-mini "say hi in five languages"
Here are the pelicans riding bicycles (prompt: Generate an SVG of a pelican riding a bicycle).
o3:
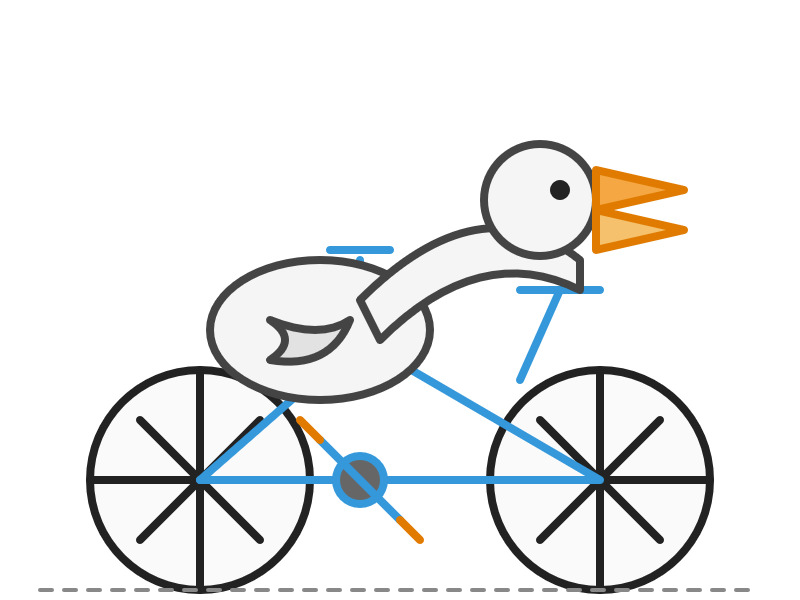
o4-mini:

Here are the full OpenAI model listings: o3 is $10/million input and $40/million for output, with a 75% discount on cached input tokens, 200,000 token context window, 100,000 max output tokens and a May 31st 2024 training cut-off (same as the GPT-4.1 models). It's a bit cheaper than o1 ($15/$60) and a lot cheaper than o1-pro ($150/$600).
o4-mini is priced the same as o3-mini: $1.10/million for input and $4.40/million for output, also with a 75% input caching discount. The size limits and training cut-off are the same as o3.
You can compare these prices with other models using the table on my updated LLM pricing calculator.
A new capability released today is that the OpenAI API can now optionally return reasoning summary text. I've been exploring that in this issue. I believe you have to verify your organization (which may involve a photo ID) in order to use this option - once you have access the easiest way to see the new tokens is using curl like this:
curl https://api.openai.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(llm keys get openai)" \
-d '{
"model": "o3",
"input": "why is the sky blue?",
"reasoning": {"summary": "auto"},
"stream": true
}'
This produces a stream of events that includes this new event type:
event: response.reasoning_summary_text.delta
data: {"type": "response.reasoning_summary_text.delta","item_id": "rs_68004320496081918e1e75ddb550d56e0e9a94ce520f0206","output_index": 0,"summary_index": 0,"delta": "**Expl"}
Omit the "stream": true and the response is easier to read and contains this:
{
"output": [
{
"id": "rs_68004edd2150819183789a867a9de671069bc0c439268c95",
"type": "reasoning",
"summary": [
{
"type": "summary_text",
"text": "**Explaining the blue sky**\n\nThe user asks a classic question about why the sky is blue. I'll talk about Rayleigh scattering, where shorter wavelengths of light scatter more than longer ones. This explains how we see blue light spread across the sky! I wonder if the user wants a more scientific or simpler everyday explanation. I'll aim for a straightforward response while keeping it engaging and informative. So, let's break it down!"
}
]
},
{
"id": "msg_68004edf9f5c819188a71a2c40fb9265069bc0c439268c95",
"type": "message",
"status": "completed",
"content": [
{
"type": "output_text",
"annotations": [],
"text": "The short answer ..."
}
]
}
]
}
GPT-4.1: Three new million token input models from OpenAI, including their cheapest model yet

OpenAI introduced three new models this morning: GPT-4.1, GPT-4.1 mini and GPT-4.1 nano. These are API-only models right now, not available through the ChatGPT interface (though you can try them out in OpenAI’s API playground). All three models can handle 1,047,576 tokens of input and 32,768 tokens of output, and all three have a May 31, 2024 cut-off date (their previous models were mostly September 2023).
[... 1,124 words]LLM pricing calculator (updated). I updated my LLM pricing calculator this morning (Claude transcript) to show the prices of various hosted models in a sorted table, defaulting to lowest price first.
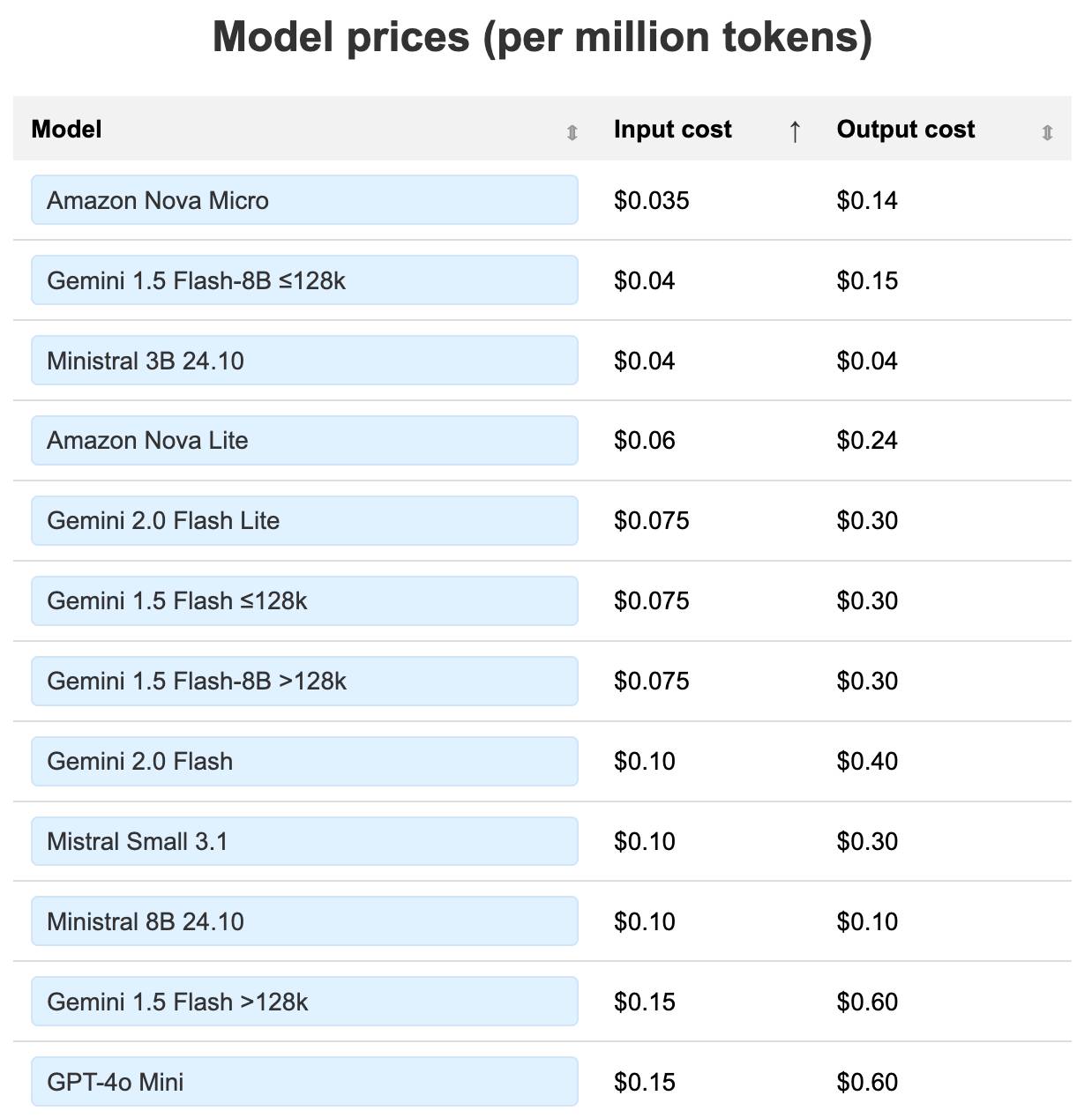
Amazon Nova and Google Gemini continue to dominate the lower end of the table. The most expensive models currently are still OpenAI's o1-Pro ($150/$600 and GPT-4.5 ($75/$150).
Gemini 2.5 Pro Preview pricing (via) Google's Gemini 2.5 Pro is currently the top model on LM Arena and, from my own testing, a superb model for OCR, audio transcription and long-context coding.
You can now pay for it!
The new gemini-2.5-pro-preview-03-25 model ID is priced like this:
- Prompts less than 200,00 tokens: $1.25/million tokens for input, $10/million for output
- Prompts more than 200,000 tokens (up to the 1,048,576 max): $2.50/million for input, $15/million for output
This is priced at around the same level as Gemini 1.5 Pro ($1.25/$5 for input/output below 128,000 tokens, $2.50/$10 above 128,000 tokens), is cheaper than GPT-4o for shorter prompts ($2.50/$10) and is cheaper than Claude 3.7 Sonnet ($3/$15).
Gemini 2.5 Pro is a reasoning model, and invisible reasoning tokens are included in the output token count. I just tried prompting "hi" and it charged me 2 tokens for input and 623 for output, of which 613 were "thinking" tokens. That still adds up to just 0.6232 cents (less than a cent) using my LLM pricing calculator which I updated to support the new model just now.
I released llm-gemini 0.17 this morning adding support for the new model:
llm install -U llm-gemini
llm -m gemini-2.5-pro-preview-03-25 hi
Note that the model continues to be available for free under the previous gemini-2.5-pro-exp-03-25 model ID:
llm -m gemini-2.5-pro-exp-03-25 hi
The free tier is "used to improve our products", the paid tier is not.
Rate limits for the paid model vary by tier - from 150/minute and 1,000/day for tier 1 (billing configured), 1,000/minute and 50,000/day for Tier 2 ($250 total spend) and 2,000/minute and unlimited/day for Tier 3 ($1,000 total spend). Meanwhile the free tier continues to limit you to 5 requests per minute and 25 per day.
Google are retiring the Gemini 2.0 Pro preview entirely in favour of 2.5.
OpenAI platform: o1-pro. OpenAI have a new most-expensive model: o1-pro can now be accessed through their API at a hefty $150/million tokens for input and $600/million tokens for output. That's 10x the price of their o1 and o1-preview models and a full 1,000x times more expensive than their cheapest model, gpt-4o-mini!
Aside from that it has mostly the same features as o1: a 200,000 token context window, 100,000 max output tokens, Sep 30 2023 knowledge cut-off date and it supports function calling, structured outputs and image inputs.
o1-pro doesn't support streaming, and most significantly for developers is the first OpenAI model to only be available via their new Responses API. This means tools that are built against their Chat Completions API (like my own LLM) have to do a whole lot more work to support the new model - my issue for that is here.
Since LLM doesn't support this new model yet I had to make do with curl:
curl https://api.openai.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(llm keys get openai)" \
-d '{
"model": "o1-pro",
"input": "Generate an SVG of a pelican riding a bicycle"
}'
Here's the full JSON I got back - 81 input tokens and 1552 output tokens for a total cost of 94.335 cents.

I took a risk and added "reasoning": {"effort": "high"} to see if I could get a better pelican with more reasoning:
curl https://api.openai.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(llm keys get openai)" \
-d '{
"model": "o1-pro",
"input": "Generate an SVG of a pelican riding a bicycle",
"reasoning": {"effort": "high"}
}'
Surprisingly that used less output tokens - 1459 compared to 1552 earlier (cost: 88.755 cents) - producing this JSON which rendered as a slightly better pelican:

It was cheaper because while it spent 960 reasoning tokens as opposed to 704 for the previous pelican it omitted the explanatory text around the SVG, saving on total output.
Gemini 2.0 Flash and Flash-Lite (via) Gemini 2.0 Flash-Lite is now generally available - previously it was available just as a preview - and has announced pricing. The model is $0.075/million input tokens and $0.030/million output - the same price as Gemini 1.5 Flash.
Google call this "simplified pricing" because 1.5 Flash charged different cost-per-tokens depending on if you used more than 128,000 tokens. 2.0 Flash-Lite (and 2.0 Flash) are both priced the same no matter how many tokens you use.
I released llm-gemini 0.12 with support for the new gemini-2.0-flash-lite model ID. I've also updated my LLM pricing calculator with the new prices.
The cost to use a given level of AI falls about 10x every 12 months, and lower prices lead to much more use. You can see this in the token cost from GPT-4 in early 2023 to GPT-4o in mid-2024, where the price per token dropped about 150x in that time period. Moore’s law changed the world at 2x every 18 months; this is unbelievably stronger.
— Sam Altman, Three Observations
Gemini 2.0 is now available to everyone. Big new Gemini 2.0 releases today:
- Gemini 2.0 Pro (Experimental) is Google's "best model yet for coding performance and complex prompts" - currently available as a free preview.
- Gemini 2.0 Flash is now generally available.
-
Gemini 2.0 Flash-Lite looks particularly interesting:
We’ve gotten a lot of positive feedback on the price and speed of 1.5 Flash. We wanted to keep improving quality, while still maintaining cost and speed. So today, we’re introducing 2.0 Flash-Lite, a new model that has better quality than 1.5 Flash, at the same speed and cost. It outperforms 1.5 Flash on the majority of benchmarks.
That means Gemini 2.0 Flash-Lite is priced at 7.5c/million input tokens and 30c/million output tokens - half the price of OpenAI's GPT-4o mini (15c/60c).
Gemini 2.0 Flash isn't much more expensive: 10c/million for text/image input, 70c/million for audio input, 40c/million for output. Again, cheaper than GPT-4o mini.
I pushed a new LLM plugin release, llm-gemini 0.10, adding support for the three new models:
llm install -U llm-gemini
llm keys set gemini
# paste API key here
llm -m gemini-2.0-flash "impress me"
llm -m gemini-2.0-flash-lite-preview-02-05 "impress me"
llm -m gemini-2.0-pro-exp-02-05 "impress me"
Here's the output for those three prompts.
I ran Generate an SVG of a pelican riding a bicycle through the three new models. Here are the results, cheapest to most expensive:
gemini-2.0-flash-lite-preview-02-05

gemini-2.0-flash

gemini-2.0-pro-exp-02-05

I also ran the same prompt I tried with o3-mini the other day:
cd /tmp
git clone https://github.com/simonw/datasette
cd datasette
files-to-prompt datasette -e py -c | \
llm -m gemini-2.0-pro-exp-02-05 \
-s 'write extensive documentation for how the permissions system works, as markdown' \
-o max_output_tokens 10000
Here's the result from that - you can compare that to o3-mini's result here.
OpenAI o3-mini, now available in LLM
OpenAI’s o3-mini is out today. As with other o-series models it’s a slightly difficult one to evaluate—we now need to decide if a prompt is best run using GPT-4o, o1, o3-mini or (if we have access) o1 Pro.
[... 748 words]Mistral Small 3 (via) First model release of 2025 for French AI lab Mistral, who describe Mistral Small 3 as "a latency-optimized 24B-parameter model released under the Apache 2.0 license."
More notably, they claim the following:
Mistral Small 3 is competitive with larger models such as Llama 3.3 70B or Qwen 32B, and is an excellent open replacement for opaque proprietary models like GPT4o-mini. Mistral Small 3 is on par with Llama 3.3 70B instruct, while being more than 3x faster on the same hardware.
Llama 3.3 70B and Qwen 32B are two of my favourite models to run on my laptop - that ~20GB size turns out to be a great trade-off between memory usage and model utility. It's exciting to see a new entrant into that weight class.
The license is important: previous Mistral Small models used their Mistral Research License, which prohibited commercial deployments unless you negotiate a commercial license with them. They appear to be moving away from that, at least for their core models:
We’re renewing our commitment to using Apache 2.0 license for our general purpose models, as we progressively move away from MRL-licensed models. As with Mistral Small 3, model weights will be available to download and deploy locally, and free to modify and use in any capacity. […] Enterprises and developers that need specialized capabilities (increased speed and context, domain specific knowledge, task-specific models like code completion) can count on additional commercial models complementing what we contribute to the community.
Despite being called Mistral Small 3, this appears to be the fourth release of a model under that label. The Mistral API calls this one mistral-small-2501 - previous model IDs were mistral-small-2312, mistral-small-2402 and mistral-small-2409.
I've updated the llm-mistral plugin for talking directly to Mistral's La Plateforme API:
llm install -U llm-mistral
llm keys set mistral
# Paste key here
llm -m mistral/mistral-small-latest "tell me a joke about a badger and a puffin"
Sure, here's a light-hearted joke for you:
Why did the badger bring a puffin to the party?
Because he heard puffins make great party 'Puffins'!
(That's a play on the word "puffins" and the phrase "party people.")
API pricing is $0.10/million tokens of input, $0.30/million tokens of output - half the price of the previous Mistral Small API model ($0.20/$0.60). for comparison, GPT-4o mini is $0.15/$0.60.
Mistral also ensured that the new model was available on Ollama in time for their release announcement.
You can pull the model like this (fetching 14GB):
ollama run mistral-small:24b
The llm-ollama plugin will then let you prompt it like so:
llm install llm-ollama
llm -m mistral-small:24b "say hi"