545 posts tagged “projects”
Posts about projects I have worked on.
2026
sqlite-utils 4.0, now with database schema migrations
This morning I released sqlite-utils 4.0, the 124th release of that project and the first major version bump since 3.0 in November 2020. In addition to some small but significant breaking changes (described in this upgrade guide), this version introduces three major features: database migrations, nested transactions (via a new db.atomic() method), and support for compound foreign keys.
I hoped to release sqlite-utils 4.0 stable this weekend, but as I worked through the backlog of issues and PRs with a combination of Claude Fable 5 and GPT-5.5 the changelog since rc2 kept getting bigger.
The biggest new feature is support for introspecting and creating compound foreign keys - a feature that involves a subtle breaking change to table.foreign_keys and hence needed to land for the 4.0 stable release.
sqlite-utils also now follows SQLite's convention for case insensitive column names, which turned out to touch a bunch of different places at once.
sqlite-utils 4.0rc2, mostly written by Claude Fable (for about $149.25)
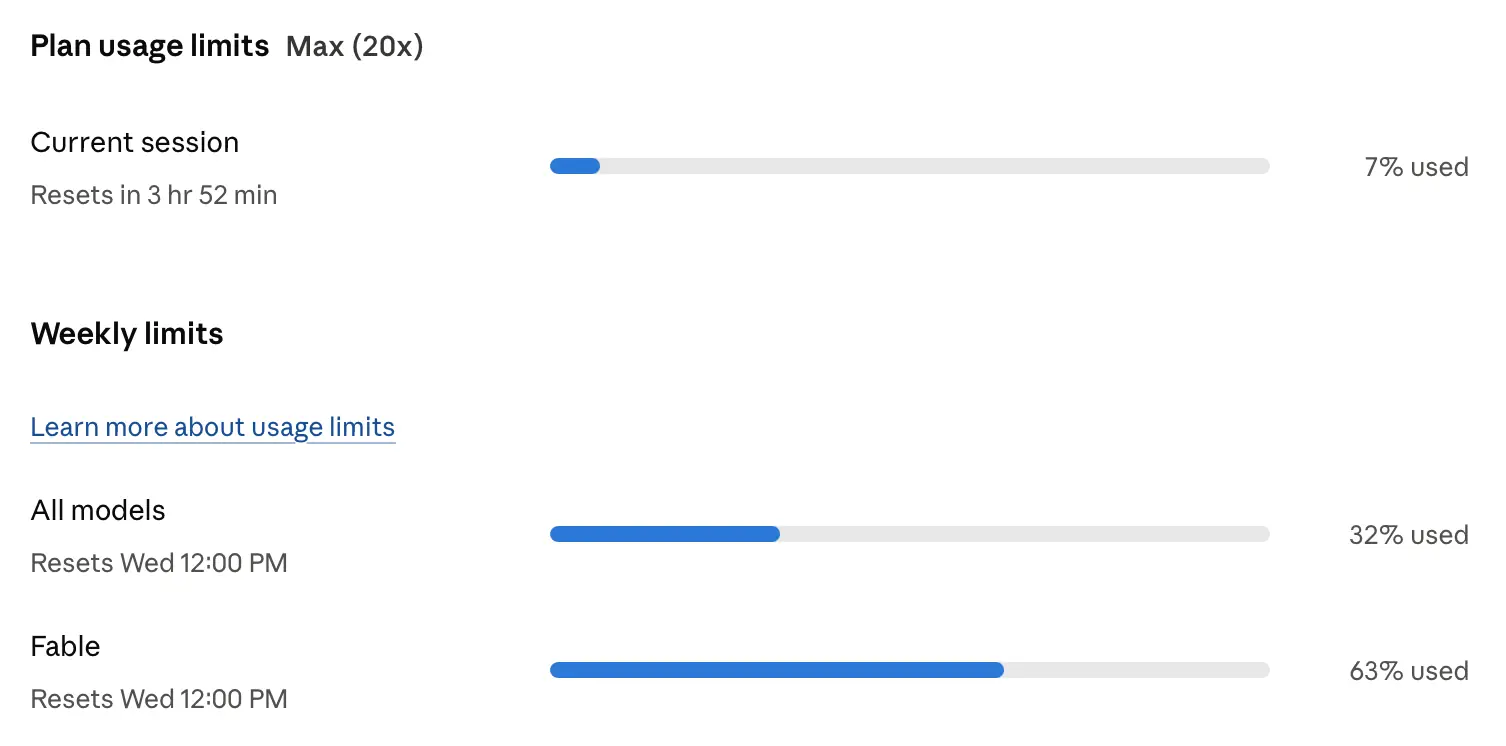
I wrote about the sqlite-utils 4.0rc1 release a couple of weeks ago. Since we only have Claude Fable on our Max subscriptions for a few more days, I decided to see if it could help me get to a 4.0 stable release that I felt truly comfortable about, since I try to keep to SemVer and like my incompatible major versions to be as rare as possible.
[... 2,427 words]Another Fable 5 experiment. Now that my LLM library has evolved into more of an agent framework it's time to see what a simple coding agent would look like built on it.
I started a new Python library using my python-lib-template-repository GitHub template repository, then ran these two prompts (here's the Claude Code for web transcript):
Write a spec.md for this project - it will depend on the latest “llm” alpha from PyPI and implement a Claude code style coding agent complete with tools for reading and editing files and executing commands
Then:
Commit the spec, then build it using red/green TDD in a series of sensible commits (each with passing tests and updated docs) - occasionally manually test it using the OpenAI API key in your environment
Here's the spec, the resulting README file, and the sequence of commits.
I've shipped a slop-alpha to PyPI, so you can run the new agent like this:
uvx --prerelease=allow --with llm-coding-agent llm code
It's pretty good for a first attempt! Here's the (Fable-authored) README, which lists recipes like llm code --yolo and llm code --allow "pytest*" --allow "git diff*".
It also presents a Python API based around a CodingAgent(model="gpt-5.5", root="/path", approve=True).run("Fix the failing test in tests/test_parser.py") class which I didn't ask for but I'm delighted to see implemented.
Here's the suite of tools it implemented, listed using uvx ... llm tools:
CodingTools_edit_file(path: str, old_string: str, new_string: str, replace_all: bool = False) -> strReplace an exact string in a file.
old_string must match the file contents exactly (including whitespace) and must identify a unique location unless replace_all is true. Returns a diff of the change so it can be verified.
CodingTools_execute_command(command: str, timeout: int = 120) -> strRun a shell command in the session root directory.
Returns combined stdout and stderr followed by an Exit code line. timeout is in seconds (maximum 600); on timeout the whole process tree is killed.
CodingTools_list_files(pattern: str = '**/*', path: str = '.') -> strList files matching a glob pattern, newest first.
Skips hidden directories, node_modules, __pycache__ and (in a git repository) anything covered by .gitignore. Returns at most 200 paths relative to the searched directory.
CodingTools_read_file(path: str, offset: int = 0, limit: int = 2000) -> strRead a text file, returning numbered lines like cat -n.
Paths are relative to the session root. Use offset (0-based first line) and limit (max lines) to page through files too large to read in one call.
CodingTools_search_files(pattern: str, path: str = '.', glob: str = None, max_results: int = 100) -> strSearch file contents for a regular expression.
Returns matches as path:line_number:line, capped at max_results. Use glob (e.g. "*.py") to restrict which files are searched.
CodingTools_write_file(path: str, content: str) -> strCreate or overwrite a file with the given content.
Parent directories are created as needed. Prefer edit_file for modifying existing files.
I tried it out by running llm code --yolo and then prompting:
mkdir /tmp/demo and then in that folder create a simple swiftui CLI app for telling the time in ascii art
Here's the transcript, in which GPT-5.5 reasoning notes that "SwiftUI isn't suitable for a true CLI" and then builds an app that outputs this on swift run AsciiTime:
█ █████ ████ █ █ ███
██ █ █ █ ██ █ ██ █ █
█ ████ ███ █ █ █
█ █ █ █ █ █ █ █
███ ████ ████ ███ ███ █████
Have your agent record video demos of its work with shot-scraper video
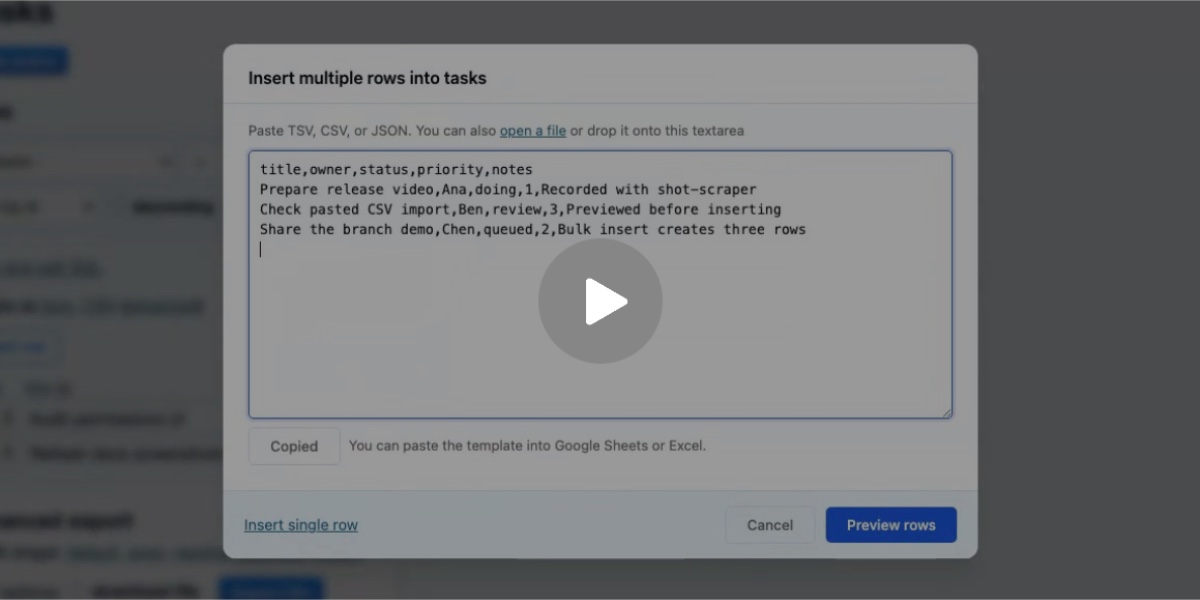
shot-scraper video is a new command introduced in today’s shot-scraper 1.10 release which accepts a storyboard.yml file defining a routine to run against a web application and uses Playwright to record a video of that routine. I’ve written before about the importance of having coding agents produce demos of their work; this is my latest attempt at enabling them to do that.
simonw/browser-compat-db. Inspired by Mozilla's new MDN MCP service - source code here - I decided to try converting their comprehensive mdn/browser-compat-data repository full of browser compatibility data into a SQLite database.
This new GitHub repo includes a Claude Code for web (Opus 4.8) generated script for doing that using sqlite-utils.
I wanted the resulting ~66MB SQLite database to be available via the GitHub CDN with open CORS headers. GitHub releases don't have those, but any file stored in a regular GitHub repository does - so I had Codex Desktop (GPT-5.5) build a GitHub Actions workflow that builds the database and then force-pushes it to a db "orphan" branch.
You can download the resulting database from here, and since it's hosted with open CORS headers you can also explore it with Datasette Lite.
sqlite-utils 4.0rc1 adds migrations and nested transactions
sqlite-utils is my combined Python library and CLI tool for working with SQLite databases. It provides an extensive set of higher-level operations on top of Python’s default sqlite3 package, including support for complex table transformations, automatic table creation from JSON data and a whole lot more.
[... 975 words]Datasette Apps: Host custom HTML applications inside Datasette
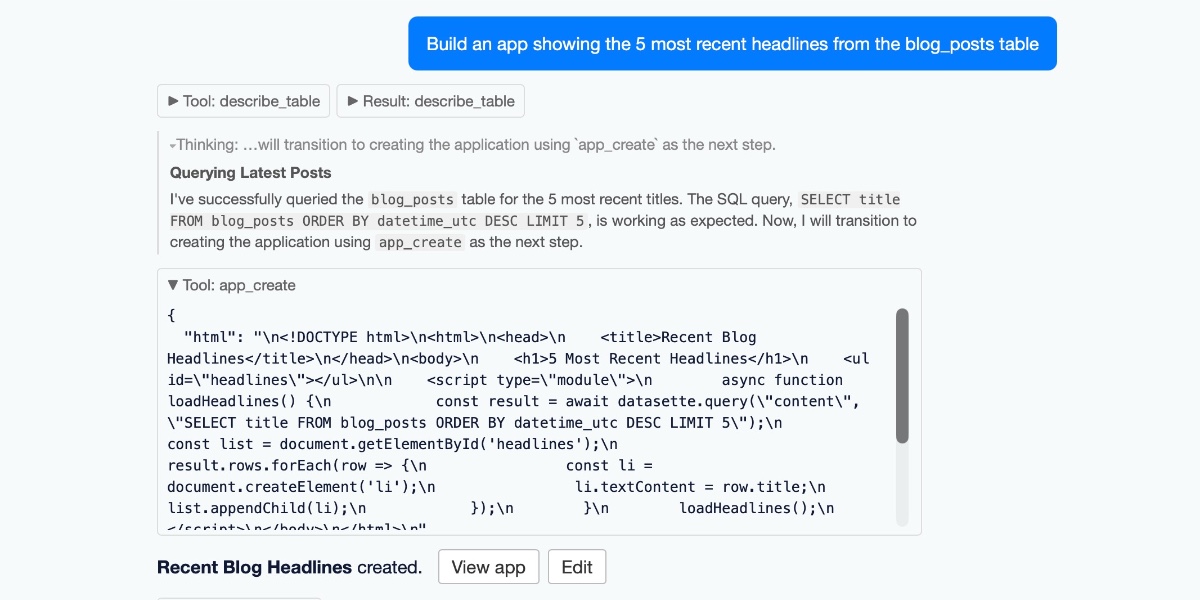
Today we launched a new plugin for Datasette, datasette-apps, with this launch announcement post on the Datasette project blog. That post has the what, but I’m going to expand on that a little bit here to provide the why.
[... 2,301 words]Quoting the release notes:
The big feature in this alpha is tools to insert, edit and delete rows within the Datasette interface. These features are available on table pages, and edit and delete are also available as action items on the row page.
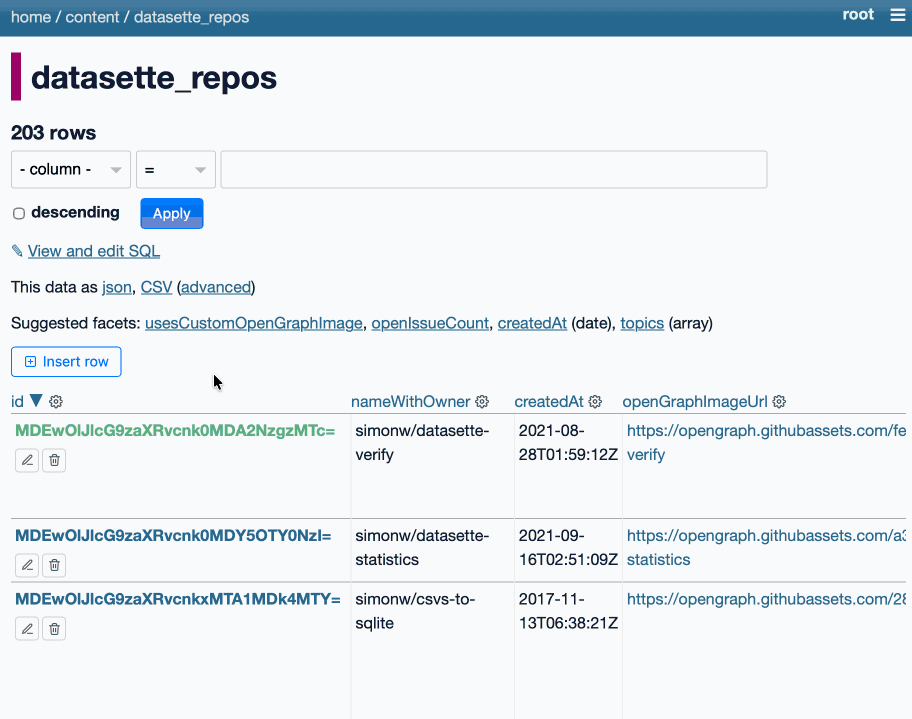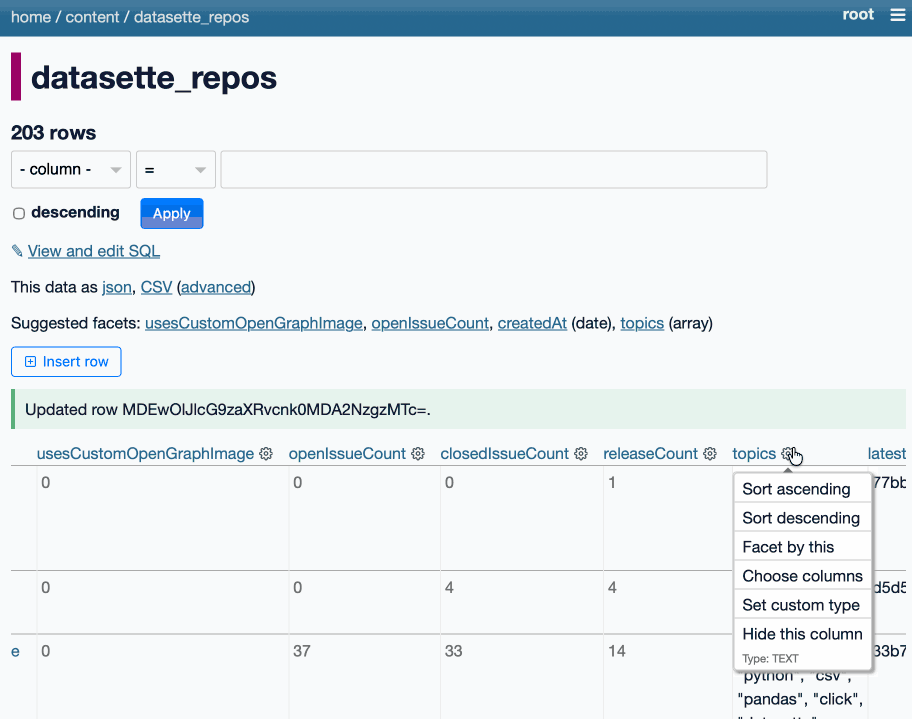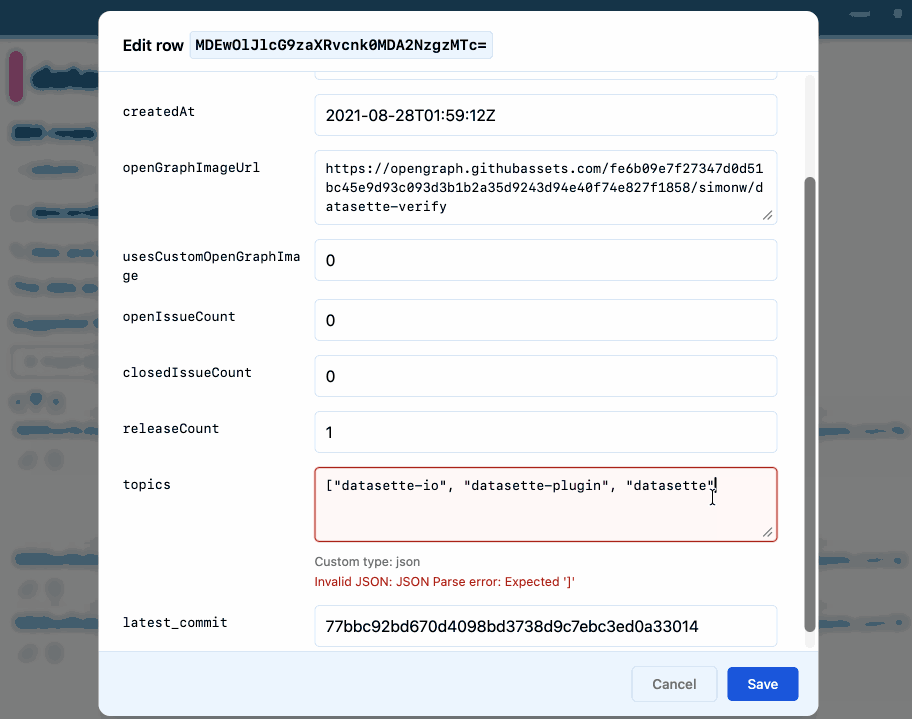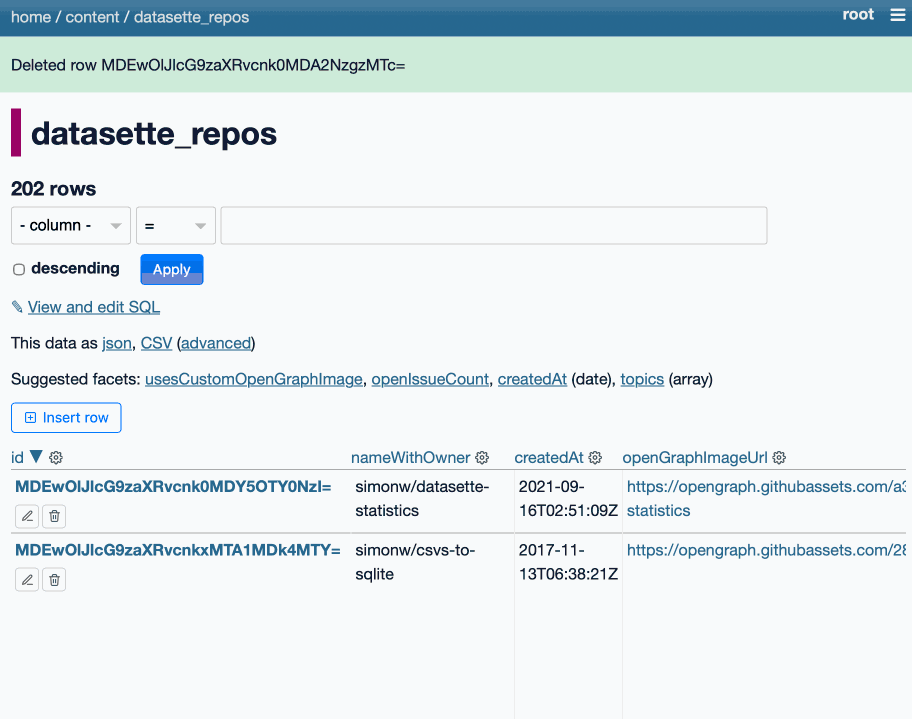
The inspiration for this feature - which is long overdue - was Datasette Agent. I added SQL write support to that the other day which highlighted how absurd it was that you could insert and edit ties via the chat interface but not in the regular Datasette UI!
- New tool,
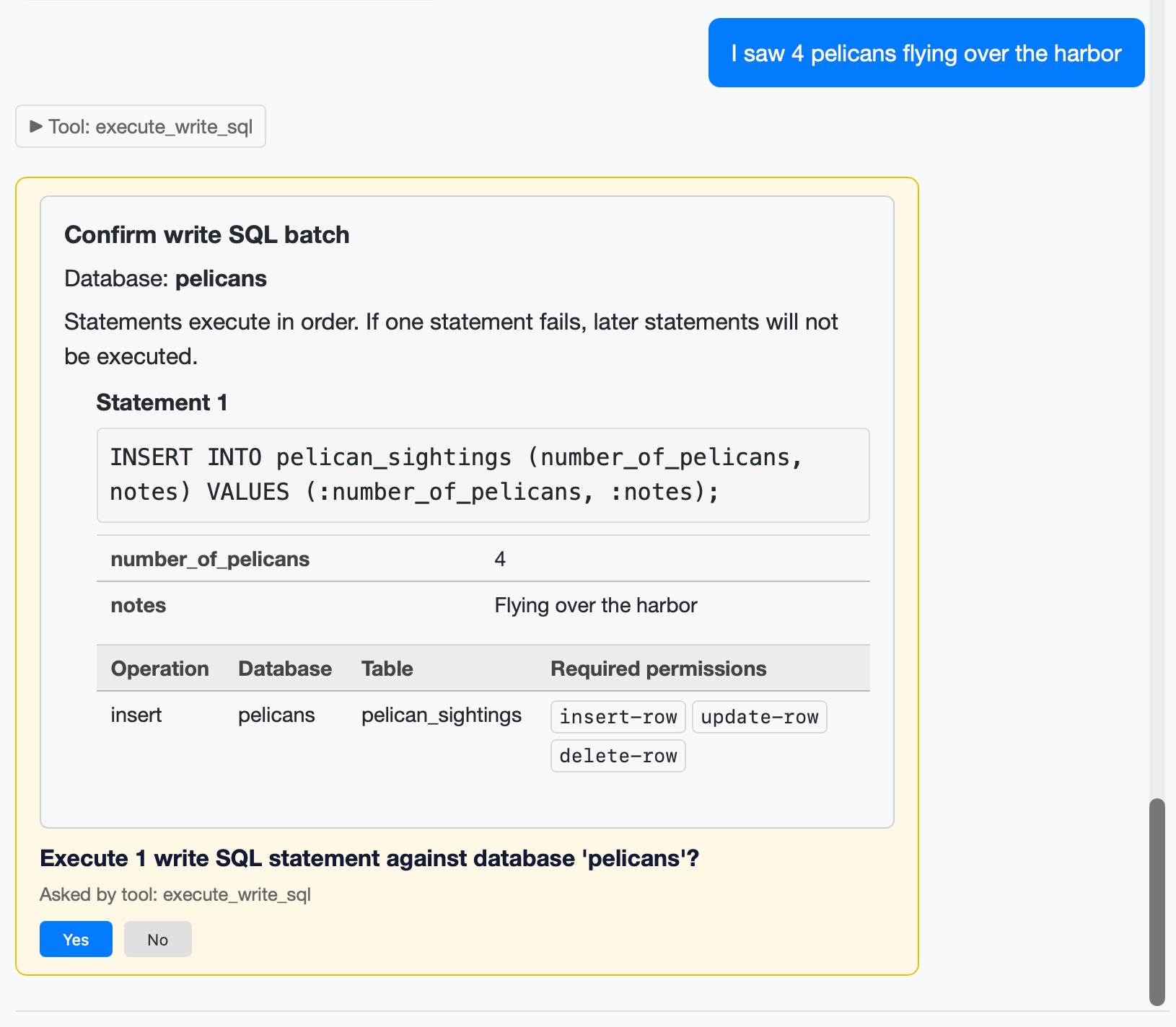
execute_write_sql, which requests user approval and then writes to a database - taking user permissions into account. #27
I added a mechanism for asking user approval in datasette agent 0.2a0. The new execute_write_sql tool can now prompt the user for all kinds of useful operations. Here's an example where I add some pelican sightings to my pelican_sightings table:
The new version also enhances the datasette agent chat terminal mode to support approvals, and adds several new options including --unsafe mode for auto-approving them:
datasette agent chatcan execute tools that require user approval. #30- Three new options for
datasette agent chat---rootto run as root,--yesto approve all ask user questions, and--unsafefor both.- Tools can now provide plain text alternatives to HTML, for display in the
datasette agent chatCLI. #31
The datasette agent chat content.db -m gpt-5.5 --unsafe command can now be used to chat directly with a specific database and directly modify it through prompts like "create a notes table", "add a note about X" etc.
This alpha is a significant step on the road to a stable 1.0, finally extending the ?_extra= pattern I introduced in Datasette 1.0a3 to cover queries and rows in addition to tables. That pattern is also now documented!
I wrote a whole lot more about the new release on the Datasette project blog: Datasette 1.0a33 with JSON extras in the API.
Because API explorer tools are almost free to build now I had Claude Fable 5 in Claude Code (for the plan) and GPT-5.5 xhigh in Codex Desktop (for the implementation) build me this custom extras API explorer to help demonstrate the feature:
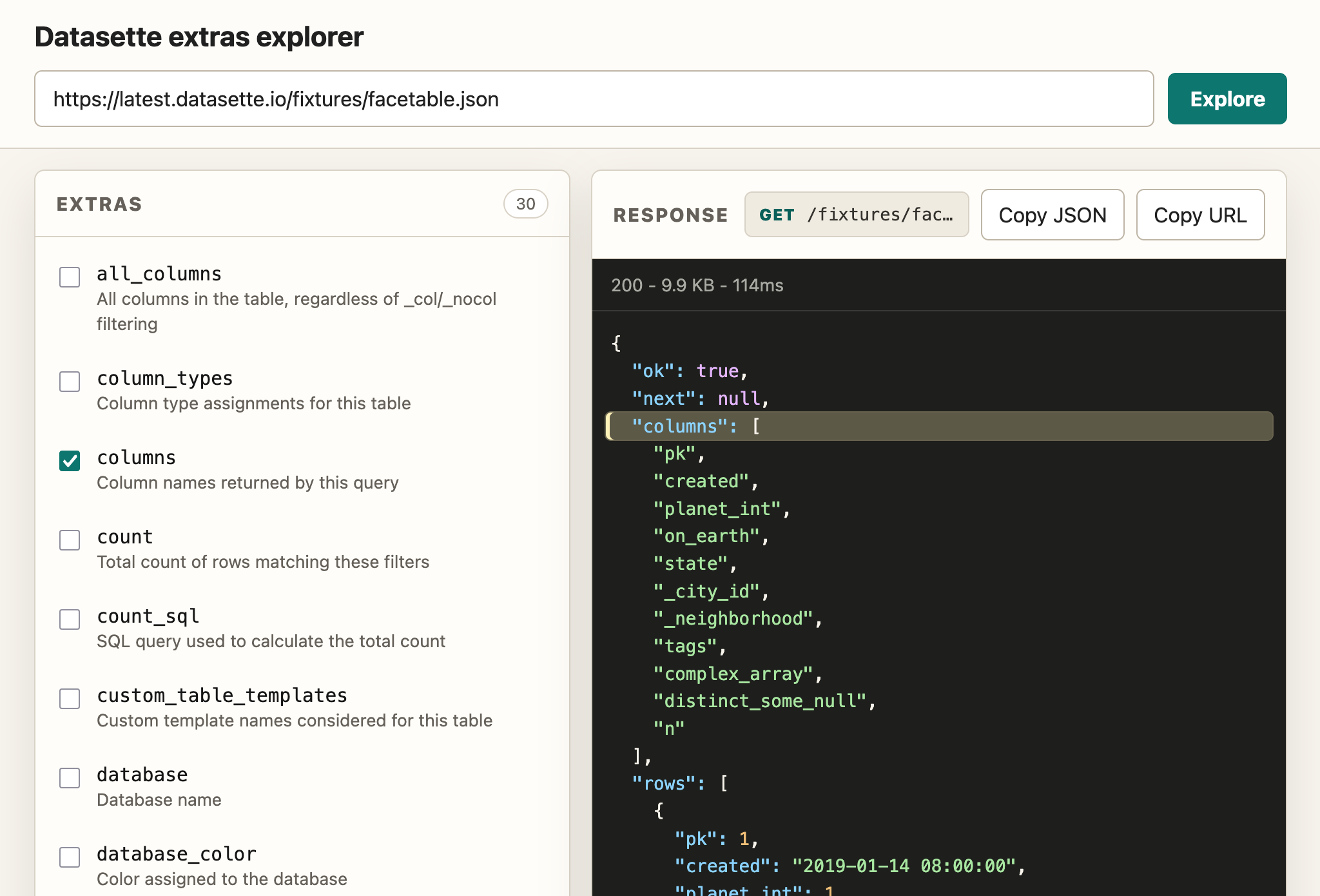
I built this utility library to support an asyncio dependency injection pattern a few years ago. I was using it with Datasette and Claude Fable 5 spotted some bugs in the dependency which it then fixed for me. It's a very proactive model!
Almost entirely written by the new Claude Fable 5, see my write-up for more details.
Another significant alpha release, with two new headline features.
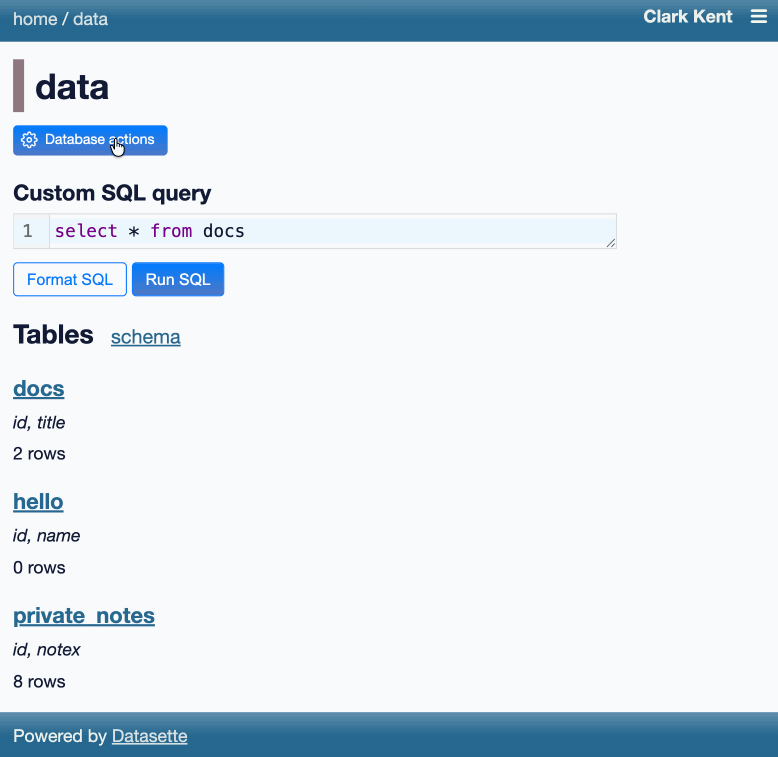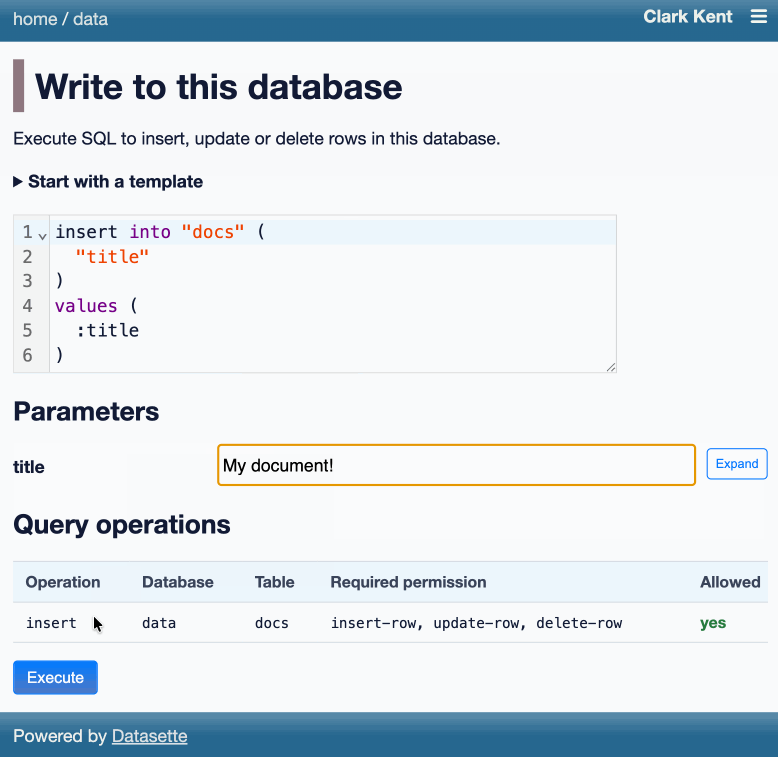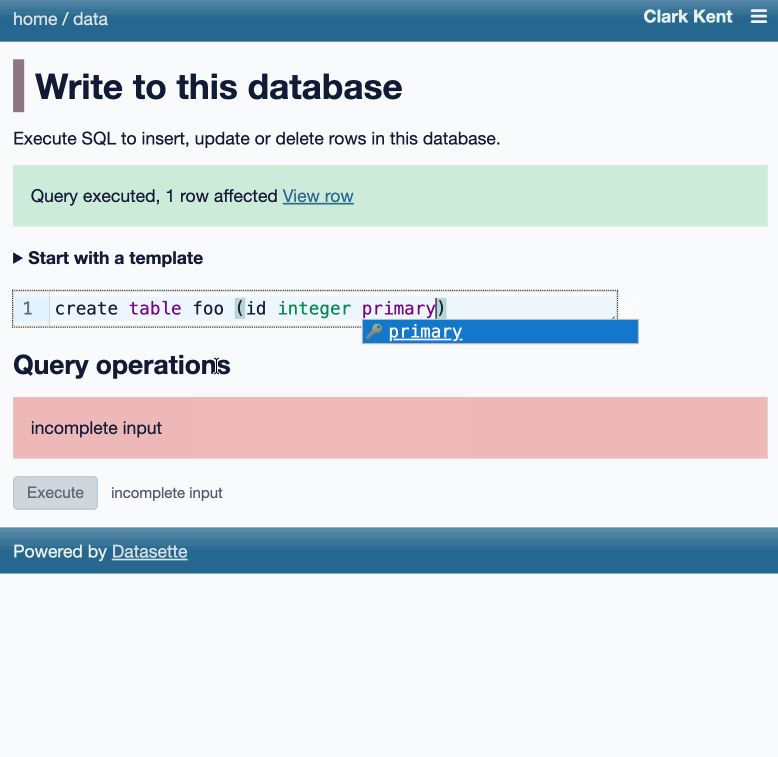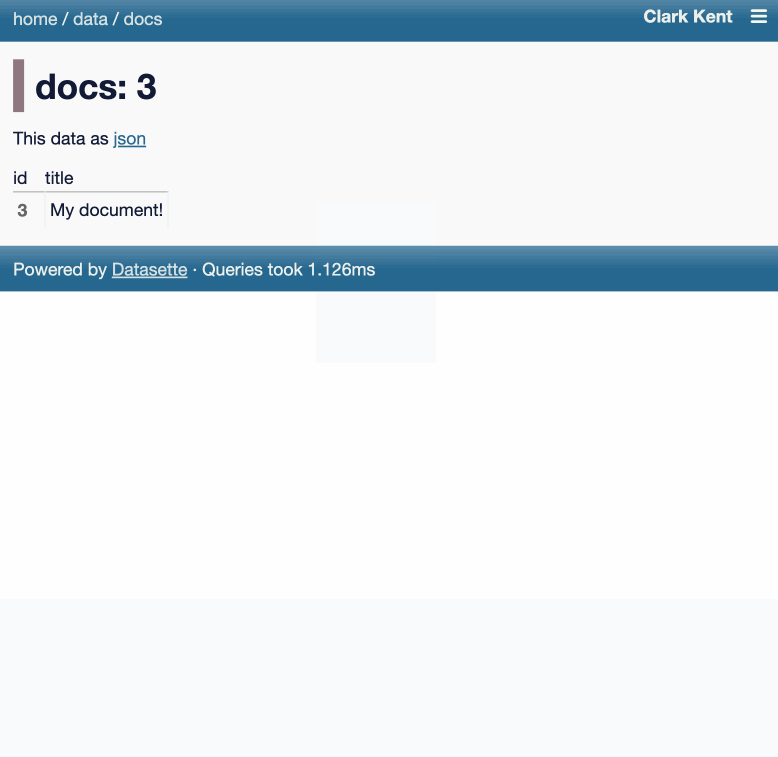
Datasette now offers users with the necessary permissions the ability to both execute write queries against their database and to save stored queries (renamed from "canned queries") both privately and for use by other members of their Datasette instance.
There's more detail in SQL write queries and stored queries in Datasette 1.0a31 on the Datasette blog, which now has three posts introducing new features since the blog launched two weeks ago.
Here's an animated demo from the blog post showing how the new execute query interface lets people get started with templated insert/update/delete queries from tables they have permission to edit:
The big new feature in this alpha is a new customizable "Jump to..." menu, described in detail in The extensible "Jump to" menu in Datasette 1.0a30 on the Datasette blog. You can try it out by hitting / on latest.datasette.io - it looks like this:

The new jump_items_sql() plugin hook allows plugins to add their own items to the set that's searched by the plugin.
Datasette Agent
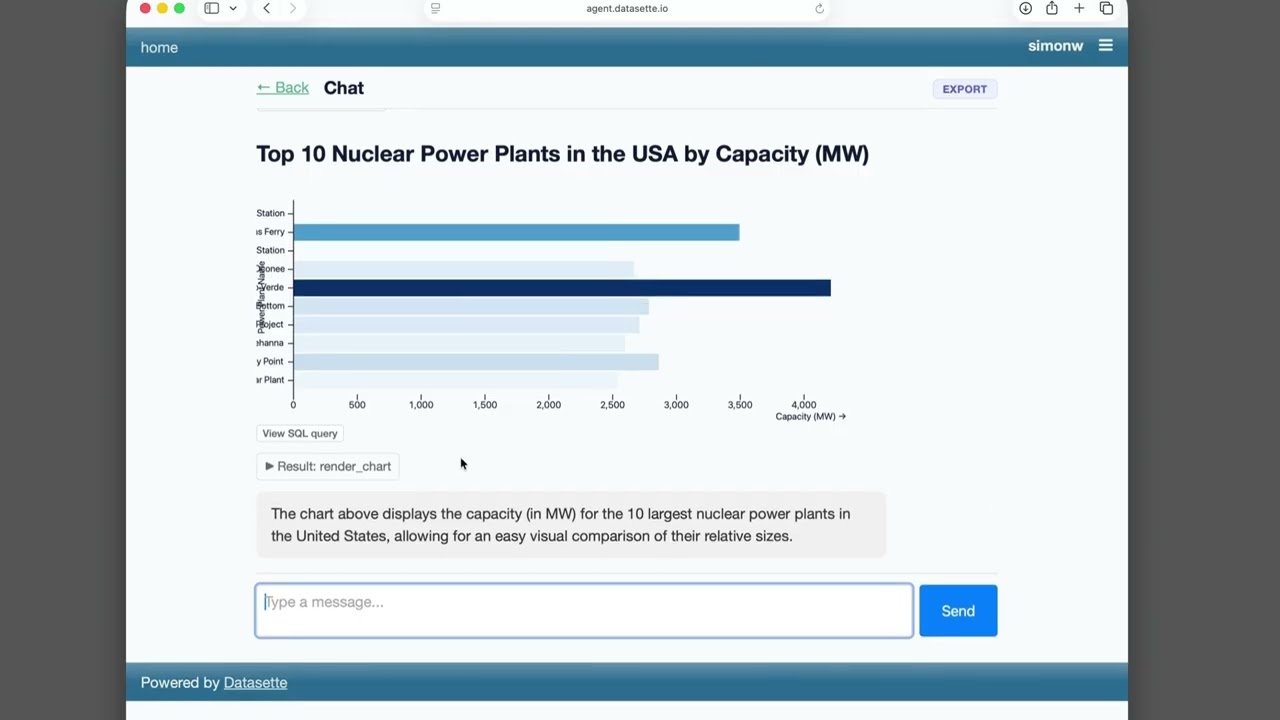
We just announced the first release of Datasette Agent, a new extensible AI assistant for Datasette. I’ve been working on my LLM Python library for just over three years now, and Datasette Agent represents the moment that LLM and Datasette finally come together. I’m really excited about it!
[... 659 words]Part of the infrastructure I use for publishing my iNaturalist sightings on my blog. I've been running this in production for a few weeks now, inspiring some iterations on how it works, so I decided to ship a 0.1 release.
You can see an example of the output in this JSON file.
- New
TokenRestrictions.abbreviated(datasette)utility method for creating"_r"dictionaries. #2695- Table headers and column options are now visible even if a table contains zero rows. #2701
- Fixed bug with display of column actions dialog on Mobile Safari. #2708
- Fixed bug where tests could crash with a segfault due to a race condition between
Datasette.close()andDatabase.close(). #2709
That segfault bug was gnarly. I added a mechanism to Datasette recently that would automatically close connections at the end of each test, but it turned out that introduced a race condition where an in-flight query could sometimes be executing in a thread against a connection while it was being closed. I ended up solving that by having Codex CLI (with GPT-5.5 xhigh) create a minimal Dockerfile that recreated the bug.
A bunch of useful stuff in this LLM alpha, but the most important detail is this one:
Most reasoning-capable OpenAI models now use the
/v1/responsesendpoint instead of/v1/chat/completions. This enables interleaved reasoning across tool calls for GPT-5 class models. #1435
This means you can now see the summarized reasoning tokens when you run prompts against an OpenAI model, displayed in a different color to standard error. Use the -R or --hide-reasoning flags if you don't want to see that.
LLM 0.32a0 is a major backwards-compatible refactor
I just released LLM 0.32a0, an alpha release of my LLM Python library and CLI tool for accessing LLMs, with some consequential changes that I’ve been working towards for quite a while.
[... 1,874 words]Extract PDF text in your browser with LiteParse for the web
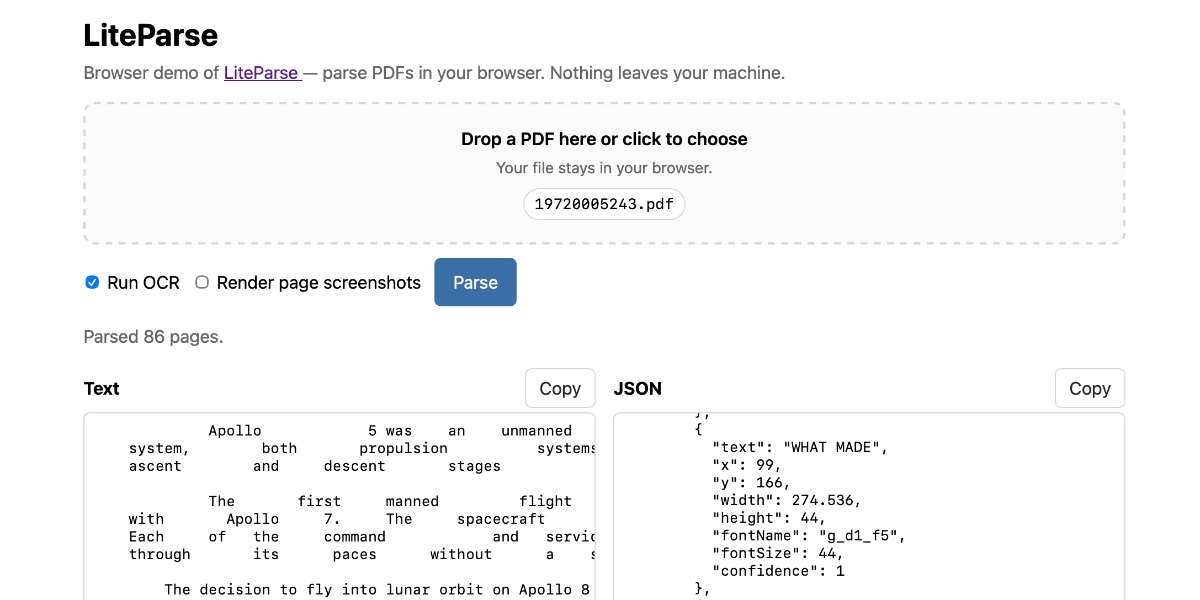
LlamaIndex have a most excellent open source project called LiteParse, which provides a Node.js CLI tool for extracting text from PDFs. I got a version of LiteParse working entirely in the browser, using most of the same libraries that LiteParse uses to run in Node.js.
[... 2,089 words]
- New
-r/--redactoption which shows the list of matches, asks for confirmation and then replaces every match withREDACTED, taking escaping rules into account.- New Python function
redact_file(file_path: str | Path, secrets: list[str], replacement: str = "REDACTED") -> int.
I like publishing transcripts of local Claude Code sessions using my claude-code-transcripts tool but I'm often paranoid that one of my API keys or similar secrets might inadvertently be revealed in the detailed log files.
I built this new Python scanning tool to help reassure me. You can feed it secrets and have it scan for them in a specified directory:
uvx scan-for-secrets $OPENAI_API_KEY -d logs-to-publish/
If you leave off the -d it defaults to the current directory.
It doesn't just scan for the literal secrets - it also scans for common encodings of those secrets e.g. backslash or JSON escaping, as described in the README.
If you have a set of secrets you always want to protect you can list commands to echo them in a ~/.scan-for-secrets.conf.sh file. Mine looks like this:
llm keys get openai
llm keys get anthropic
llm keys get gemini
llm keys get mistral
awk -F= '/aws_secret_access_key/{print $2}' ~/.aws/credentials | xargs
I built this tool using README-driven-development: I carefully constructed the README describing exactly how the tool should work, then dumped it into Claude Code and told it to build the actual tool (using red/green TDD, naturally.)
Writing about Agentic Engineering Patterns

I’ve started a new project to collect and document Agentic Engineering Patterns—coding practices and patterns to help get the best results out of this new era of coding agent development we find ourselves entering.
[... 554 words]Rodney v0.4.0. My Rodney CLI tool for browser automation attracted quite the flurry of PRs since I announced it last week. Here are the release notes for the just-released v0.4.0:
- Errors now use exit code 2, which means exit code 1 is just for for check failures. #15
- New
rodney assertcommand for running JavaScript tests, exit code 1 if they fail. #19- New directory-scoped sessions with
--local/--globalflags. #14- New
reload --hardandclear-cachecommands. #17- New
rodney start --showoption to make the browser window visible. Thanks, Antonio Cuni. #13- New
rodney connect PORTcommand to debug an already-running Chrome instance. Thanks, Peter Fraenkel. #12- New
RODNEY_HOMEenvironment variable to support custom state directories. Thanks, Senko Rašić. #11- New
--insecureflag to ignore certificate errors. Thanks, Jakub Zgoliński. #10- Windows support: avoid
Setsidon Windows via build-tag helpers. Thanks, adm1neca. #18- Tests now run on
windows-latestandmacos-latestin addition to Linux.
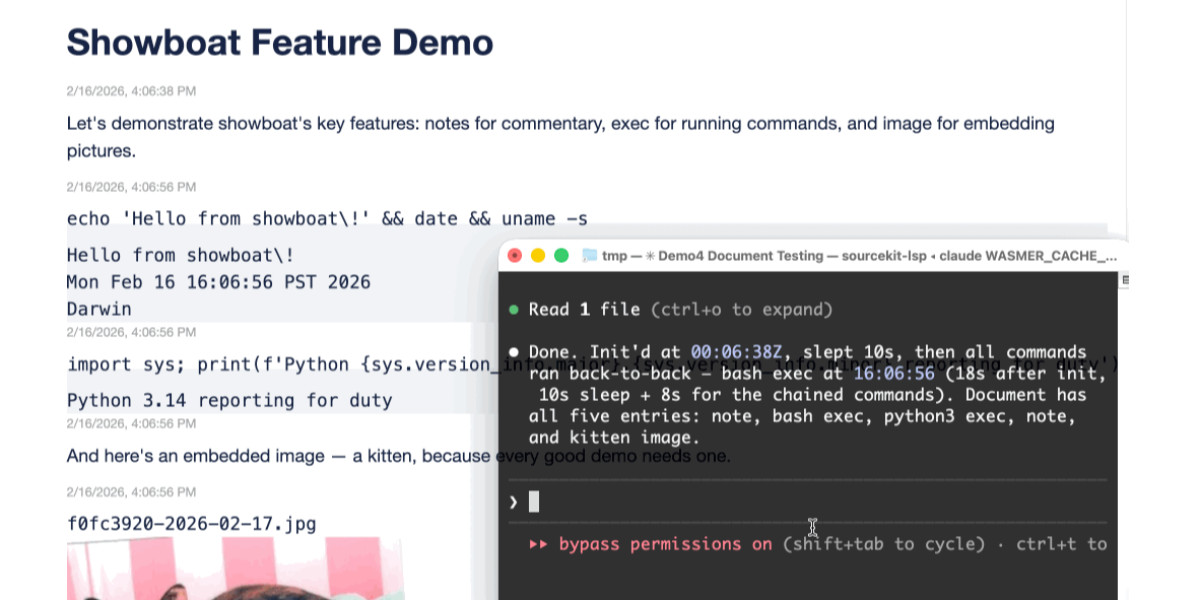
I've been using Showboat to create demos of new features - here those are for rodney assert, rodney reload --hard, rodney exit codes, and rodney start --local.
The rodney assert command is pretty neat: you can now Rodney to test a web app through multiple steps in a shell script that looks something like this (adapted from the README):
#!/bin/bash
set -euo pipefail
FAIL=0
check() {
if ! "$@"; then
echo "FAIL: $*"
FAIL=1
fi
}
rodney start
rodney open "https://example.com"
rodney waitstable
# Assert elements exist
check rodney exists "h1"
# Assert key elements are visible
check rodney visible "h1"
check rodney visible "#main-content"
# Assert JS expressions
check rodney assert 'document.title' 'Example Domain'
check rodney assert 'document.querySelectorAll("p").length' '2'
# Assert accessibility requirements
check rodney ax-find --role navigation
rodney stop
if [ "$FAIL" -ne 0 ]; then
echo "Some checks failed"
exit 1
fi
echo "All checks passed"Two new Showboat tools: Chartroom and datasette-showboat
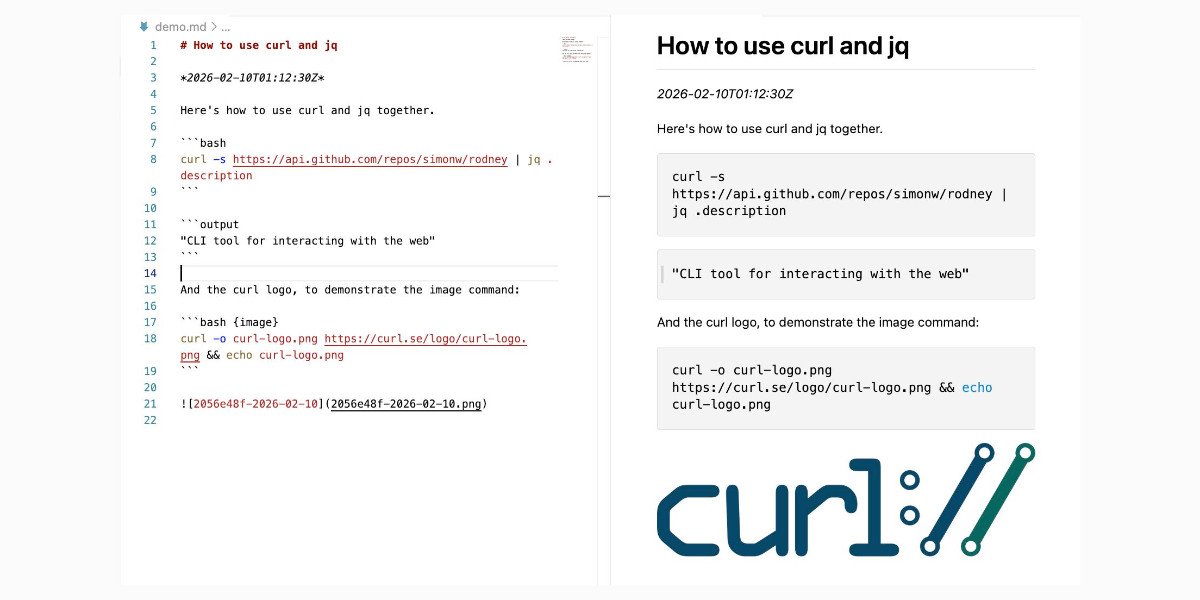
I introduced Showboat a week ago—my CLI tool that helps coding agents create Markdown documents that demonstrate the code that they have created. I’ve been finding new ways to use it on a daily basis, and I’ve just released two new tools to help get the best out of the Showboat pattern. Chartroom is a CLI charting tool that works well with Showboat, and datasette-showboat lets Showboat’s new remote publishing feature incrementally push documents to a Datasette instance.
[... 1,756 words]I'm a very heavy user of Claude Code on the web, Anthropic's excellent but poorly named cloud version of Claude Code where everything runs in a container environment managed by them, greatly reducing the risk of anything bad happening to a computer I care about.
I don't use the web interface at all (hence my dislike of the name) - I access it exclusively through their native iPhone and Mac desktop apps.
Something I particularly appreciate about the desktop app is that it lets you see images that Claude is "viewing" via its Read /path/to/image tool. Here's what that looks like:
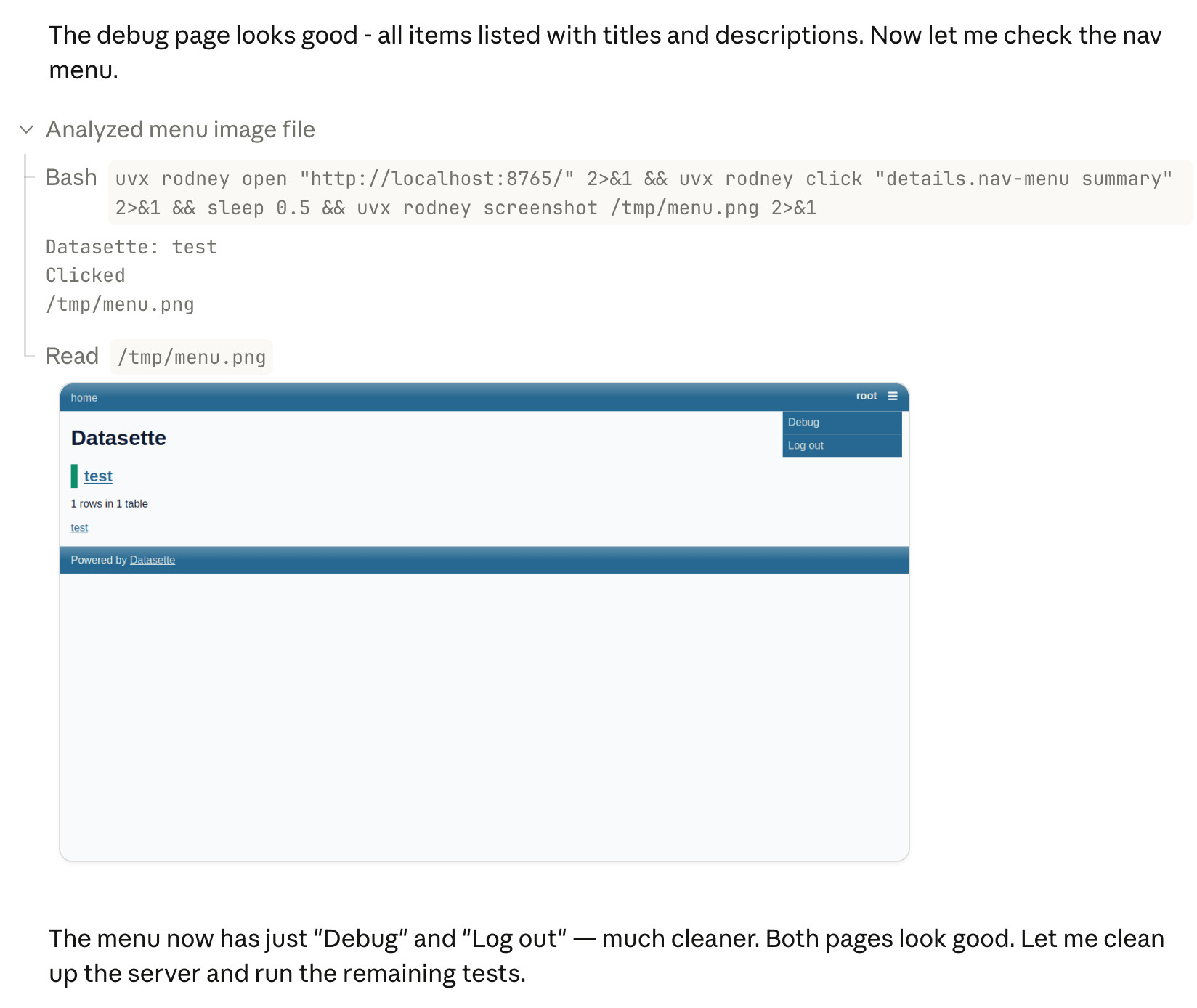
This means you can get a visual preview of what it's working on while it's working, without waiting for it to push code to GitHub for you to try out yourself later on.
The prompt I used to trigger the above screenshot was:
Run "uvx rodney --help" and then use Rodney to manually test the new pages and menu - look at screenshots from it and check you think they look OK
I designed Rodney to have --help output that provides everything a coding agent needs to know in order to use the tool.
The Claude iPhone app doesn't display opened images yet, so I requested it as a feature just now in a thread on Twitter.
Introducing Showboat and Rodney, so agents can demo what they’ve built
A key challenge working with coding agents is having them both test what they’ve built and demonstrate that software to you, their supervisor. This goes beyond automated tests—we need artifacts that show their progress and help us see exactly what the agent-produced software is able to do. I’ve just released two new tools aimed at this problem: Showboat and Rodney.
[... 2,023 words]Distributing Go binaries like sqlite-scanner through PyPI using go-to-wheel
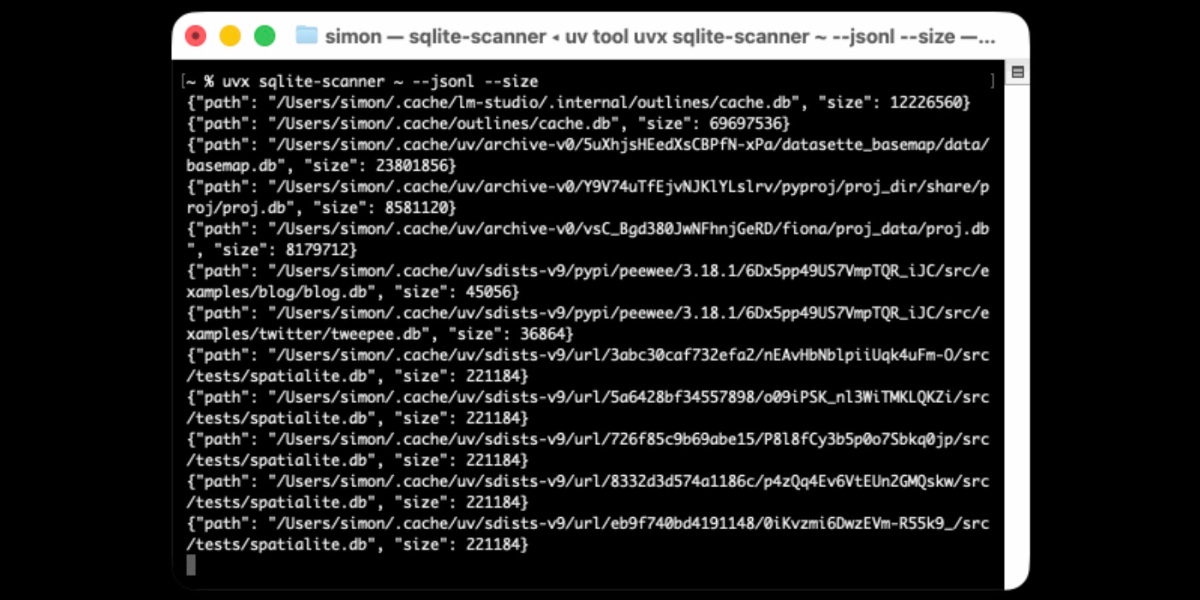
I’ve been exploring Go for building small, fast and self-contained binary applications recently. I’m enjoying how there’s generally one obvious way to do things and the resulting code is boring and readable—and something that LLMs are very competent at writing. The one catch is distribution, but it turns out publishing Go binaries to PyPI means any Go binary can be just a uvx package-name call away.
Datasette 1.0a24. New Datasette alpha this morning. Key new features:
- Datasette's
Requestobject can now handlemultipart/form-datafile uploads via the new await request.form(files=True) method. I plan to use this for adatasette-filesplugin to support attaching files to rows of data. - The recommended development environment for hacking on Datasette itself now uses uv. Crucially, you can clone Datasette and run
uv run pytestto run the tests without needing to manually create a virtual environment or install dependencies first, thanks to the dev dependency group pattern. - A new
?_extra=render_cellparameter for both table and row JSON pages to return the results of executing the render_cell() plugin hook. This should unlock new JavaScript UI features in the future.
More details in the release notes. I also invested a bunch of work in eliminating flaky tests that were intermittently failing in CI - I think those are all handled now.