11 posts tagged “structured-extraction”
Using LLMs to extract structured data from unstructured text and images.
2025
How OpenElections Uses LLMs (via) The OpenElections project collects detailed election data for the USA, all the way down to the precinct level. This is a surprisingly hard problem: while county and state-level results are widely available, precinct-level results are published in thousands of different ad-hoc ways and rarely aggregated once the election result has been announced.
A lot of those precinct results are published as image-filled PDFs.
Derek Willis has recently started leaning on Gemini to help parse those PDFs into CSV data:
For parsing image PDFs into CSV files, Google’s Gemini is my model of choice, for two main reasons. First, the results are usually very, very accurate (with a few caveats I’ll detail below), and second, Gemini’s large context window means it’s possible to work with PDF files that can be multiple MBs in size.
Is this piece he shares the process and prompts for a real-world expert level data entry project, assisted by Gemini.
This example from Limestone County, Texas is a great illustration of how tricky this problem can get. Getting traditional OCR software to correctly interpret multi-column layouts like this always requires some level of manual intervention:
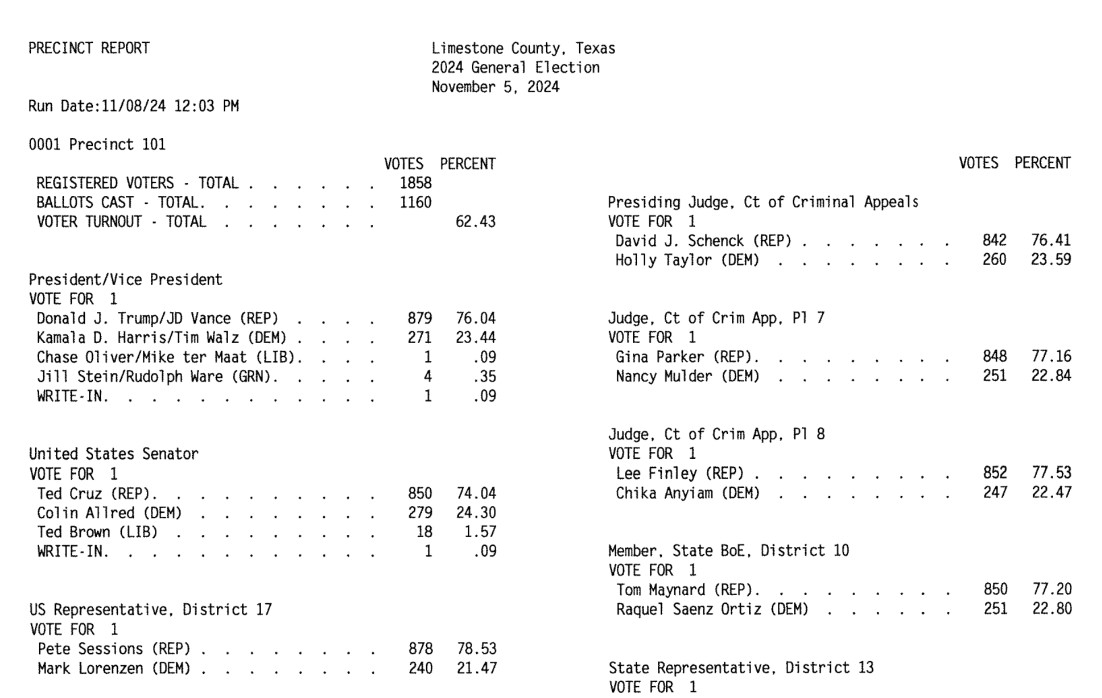
Derek's prompt against Gemini 2.5 Pro throws in an example, some special instructions and a note about the two column format:
Produce a CSV file from the attached PDF based on this example:
county,precinct,office,district,party,candidate,votes,absentee,early_voting,election_day
Limestone,Precinct 101,Registered Voters,,,,1858,,,
Limestone,Precinct 101,Ballots Cast,,,,1160,,,
Limestone,Precinct 101,President,,REP,Donald J. Trump,879,,,
Limestone,Precinct 101,President,,DEM,Kamala D. Harris,271,,,
Limestone,Precinct 101,President,,LIB,Chase Oliver,1,,,
Limestone,Precinct 101,President,,GRN,Jill Stein,4,,,
Limestone,Precinct 101,President,,,Write-ins,1,,,
Skip Write-ins with candidate names and rows with "Cast Votes", "Not Assigned", "Rejected write-in votes", "Unresolved write-in votes" or "Contest Totals". Do not extract any values that end in "%"
Use the following offices:
President/Vice President -> President
United States Senator -> U.S. Senate
US Representative -> U.S. House
State Senator -> State Senate
Quote all office and candidate values. The results are split into two columns on each page; parse the left column first and then the right column.
A spot-check and a few manual tweaks and the result against a 42 page PDF was exactly what was needed.
How about something harder? The results for Cameron County came as more than 600 pages and looked like this - note the hole-punch holes that obscure some of the text!
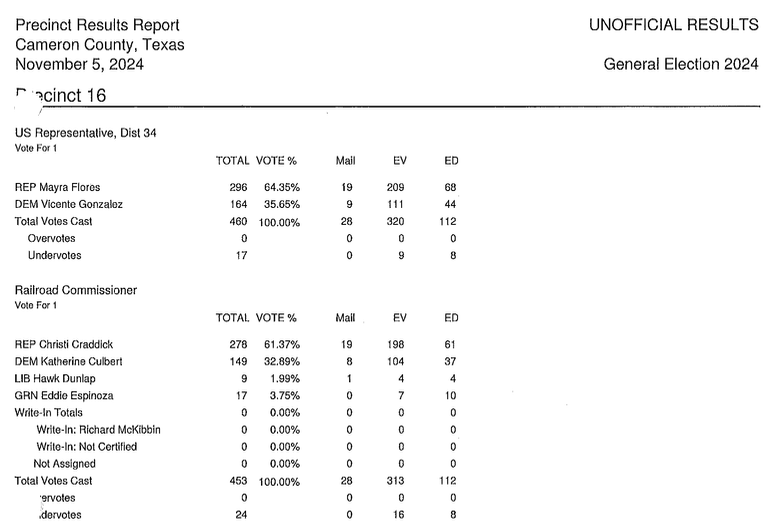
This file had to be split into chunks of 100 pages each, and the entire process still took a full hour of work - but the resulting table matched up with the official vote totals.
I love how realistic this example is. AI data entry like this isn't a silver bullet - there's still a bunch of work needed to verify the results and creative thinking needed to work through limitations - but it represents a very real improvement in how small teams can take on projects of this scale.
In the six weeks since we started working on Texas precinct results, we’ve been able to convert them for more than half of the state’s 254 counties, including many image PDFs like the ones on display here. That pace simply wouldn’t be possible with data entry or traditional OCR software.
Introducing Datasette for Newsrooms. We're introducing a new product suite today called Datasette for Newsrooms - a bundled collection of Datasette Cloud features built specifically for investigative journalists and data teams. We're describing it as an all-in-one data store, search engine, and collaboration platform designed to make working with data in a newsroom easier, faster, and more transparent.
If your newsroom could benefit from a managed version of Datasette we would love to hear from you. We're offering it to nonprofit newsrooms for free for the first year (they can pay us in feedback), and we have a two month trial for everyone else.
Get in touch at hello@datasette.cloud if you'd like to try it out.
One crucial detail: we will help you get started - we'll load data into your instance for you (you get some free data engineering!) and walk you through how to use it, and we will eagerly consume any feedback you have for us and prioritize shipping anything that helps you use the tool. Our unofficial goal: we want someone to win a Pulitzer for investigative reporting where our tool played a tiny part in their reporting process.
Here's an animated GIF demo (taken from our new Newsrooms landing page) of my favorite recent feature: the ability to extract structured data into a table starting with an unstructured PDF, using the latest version of the datasette-extract plugin.

How ProPublica Uses AI Responsibly in Its Investigations. Charles Ornstein describes how ProPublica used an LLM to help analyze data for their recent story A Study of Mint Plants. A Device to Stop Bleeding. This Is the Scientific Research Ted Cruz Calls “Woke.” by Agnel Philip and Lisa Song.
They ran ~3,400 grant descriptions through a prompt that included the following:
As an investigative journalist, I am looking for the following information
--
woke_description: A short description (at maximum a paragraph) on why this grant is being singled out for promoting "woke" ideology, Diversity, Equity, and Inclusion (DEI) or advanced neo-Marxist class warfare propaganda. Leave this blank if it's unclear.
why_flagged: Look at the "STATUS", "SOCIAL JUSTICE CATEGORY", "RACE CATEGORY", "GENDER CATEGORY" and "ENVIRONMENTAL JUSTICE CATEGORY" fields. If it's filled out, it means that the author of this document believed the grant was promoting DEI ideology in that way. Analyze the "AWARD DESCRIPTIONS" field and see if you can figure out why the author may have flagged it in this way. Write it in a way that is thorough and easy to understand with only one description per type and award.
citation_for_flag: Extract a very concise text quoting the passage of "AWARDS DESCRIPTIONS" that backs up the "why_flagged" data.
This was only the first step in the analysis of the data:
Of course, members of our staff reviewed and confirmed every detail before we published our story, and we called all the named people and agencies seeking comment, which remains a must-do even in the world of AI.
I think journalists are particularly well positioned to take advantage of LLMs in this way, because a big part of journalism is about deriving the truth from multiple unreliable sources of information. Journalists are deeply familiar with fact-checking, which is a critical skill if you're going to report with the assistance of these powerful but unreliable models.
Agnel Philip:
The tech holds a ton of promise in lead generation and pointing us in the right direction. But in my experience, it still needs a lot of human supervision and vetting. If used correctly, it can both really speed up the process of understanding large sets of information, and if you’re creative with your prompts and critically read the output, it can help uncover things that you may not have thought of.
Introducing Command A: Max performance, minimal compute (via) New LLM release from Cohere. It's interesting to see which aspects of the model they're highlighting, as an indicator of what their commercial customers value the most (highlights mine):
Command A delivers maximum performance with minimal hardware costs when compared to leading proprietary and open-weights models, such as GPT-4o and DeepSeek-V3. For private deployments, Command A excels on business-critical agentic and multilingual tasks, while being deployable on just two GPUs, compared to other models that typically require as many as 32. [...]
With a serving footprint of just two A100s or H100s, it requires far less compute than other comparable models on the market. This is especially important for private deployments. [...]
Its 256k context length (2x most leading models) can handle much longer enterprise documents. Other key features include Cohere’s advanced retrieval-augmented generation (RAG) with verifiable citations, agentic tool use, enterprise-grade security, and strong multilingual performance.
It's open weights but very much not open source - the license is Creative Commons Attribution Non-Commercial and also requires adhering to their Acceptable Use Policy.
Cohere offer it for commercial use via "contact us" pricing or through their API. I released llm-command-r 0.3 adding support for this new model, plus their smaller and faster Command R7B (released in December) and support for structured outputs via LLM schemas.
(I found a weird bug with their schema support where schemas that end in an integer output a seemingly limitless integer - in my experiments it affected Command R and the new Command A but not Command R7B.)
Structured data extraction from unstructured content using LLM schemas
LLM 0.23 is out today, and the signature feature is support for schemas—a new way of providing structured output from a model that matches a specification provided by the user. I’ve also upgraded both the llm-anthropic and llm-gemini plugins to add support for schemas.
[... 2,601 words]2024
Structured Generation w/ SmolLM2 running in browser & WebGPU (via) Extraordinary demo by Vaibhav Srivastav (VB). Here's Hugging Face's SmolLM2-1.7B-Instruct running directly in a web browser (using WebGPU, so requires Chrome for the moment) demonstrating structured text extraction, converting a text description of an image into a structured GitHub issue defined using JSON schema.
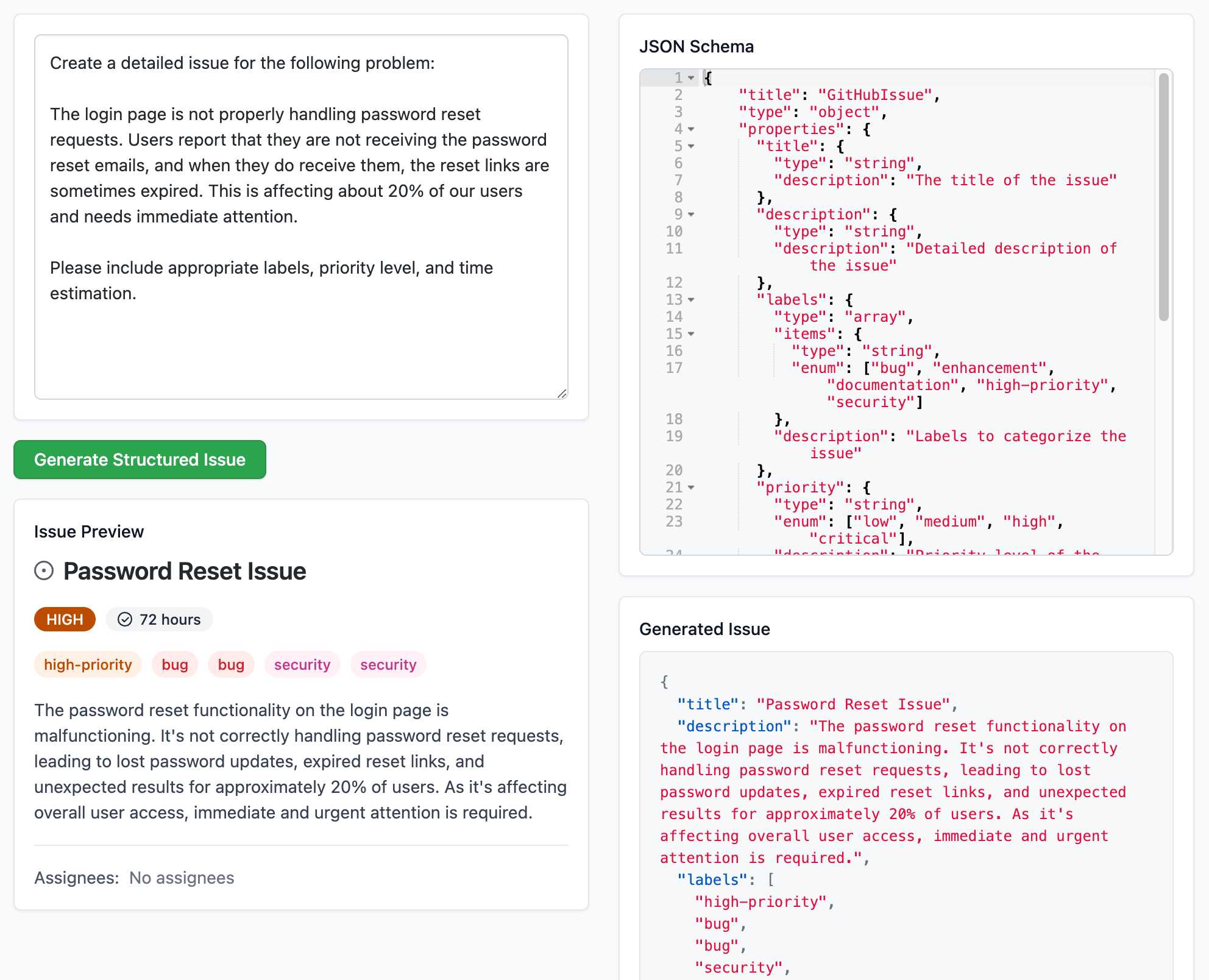
The page loads 924.8MB of model data (according to this script to sum up files in window.caches) and performs everything in-browser. I did not know a model this small could produce such useful results.
Here's the source code for the demo. It's around 200 lines of code, 50 of which are the JSON schema describing the data to be extracted.
The real secret sauce here is web-llm by MLC. This library has made loading and executing prompts through LLMs in the browser shockingly easy, and recently incorporated support for MLC's XGrammar library (also available in Python) which implements both JSON schema and EBNF-based structured output guidance.
NuExtract 1.5. Structured extraction - where an LLM helps turn unstructured text (or image content) into structured data - remains one of the most directly useful applications of LLMs.
NuExtract is a family of small models directly trained for this purpose (though text only at the moment) and released under the MIT license.
It comes in a variety of shapes and sizes:
- NuExtract-v1.5 is a 3.8B parameter model fine-tuned on Phi-3.5-mini instruct. You can try this one out in this playground.
- NuExtract-tiny-v1.5 is 494M parameters, fine-tuned on Qwen2.5-0.5B.
- NuExtract-1.5-smol is 1.7B parameters, fine-tuned on SmolLM2-1.7B.
All three models were fine-tuned on NuMind's "private high-quality dataset". It's interesting to see a model family that uses one fine-tuning set against three completely different base models.
Useful tip from Steffen Röcker:
Make sure to use it with low temperature, I've uploaded NuExtract-tiny-v1.5 to Ollama and set it to 0. With the Ollama default of 0.7 it started repeating the input text. It works really well despite being so smol.
Braggoscope Prompts. Matt Webb's Braggoscope (previously) is an alternative way to browse the archive's of the BBC's long-running radio series In Our Time, including the ability to browse by Dewey Decimal library classification, view related episodes and more.
Matt used an LLM to generate the structured data for the site, based on the episode synopsis on the BBC's episode pages like this one.
The prompts he used for this are now described on this new page on the site.
Of particular interest is the way the Dewey Decimal classifications are derived. Quoting an extract from the prompt:
- Provide a Dewey Decimal Classification code, label, and reason for the classification.
- Reason: summarise your deduction process for the Dewey code, for example considering the topic and era of history by referencing lines in the episode description. Bias towards the main topic of the episode which is at the beginning of the description.
- Code: be as specific as possible with the code, aiming to give a second level code (e.g. "510") or even lower level (e.g. "510.1"). If you cannot be more specific than the first level (e.g. "500"), then use that.
Return valid JSON conforming to the following Typescript type definition:{ "dewey_decimal": {"reason": string, "code": string, "label": string} }
That "reason" key is essential, even though it's not actually used in the resulting project. Matt explains why:
It gives the AI a chance to generate tokens to narrow down the possibility space of the code and label that follow (the reasoning has to appear before the Dewey code itself is generated).
Here's a relevant note from OpenAI's new structured outputs documentation:
When using Structured Outputs, outputs will be produced in the same order as the ordering of keys in the schema.
That's despite JSON usually treating key order as undefined. I think OpenAI designed the feature to work this way precisely to support the kind of trick Matt is using for his Dewey Decimal extraction process.
OpenAI: Introducing Structured Outputs in the API.
OpenAI have offered structured outputs for a while now: you could specify "response_format": {"type": "json_object"}} to request a valid JSON object, or you could use the function calling mechanism to request responses that match a specific schema.
Neither of these modes were guaranteed to return valid JSON! In my experience they usually did, but there was always a chance that something could go wrong and the returned code could not match the schema, or even not be valid JSON at all.
Outside of OpenAI techniques like jsonformer and llama.cpp grammars could provide those guarantees against open weights models, by interacting directly with the next-token logic to ensure that only tokens that matched the required schema were selected.
OpenAI credit that work in this announcement, so they're presumably using the same trick. They've provided two new ways to guarantee valid outputs. The first a new "strict": true option for function definitions. The second is a new feature: a "type": "json_schema" option for the "response_format" field which lets you then pass a JSON schema (and another "strict": true flag) to specify your required output.
I've been using the existing "tools" mechanism for exactly this already in my datasette-extract plugin - defining a function that I have no intention of executing just to get structured data out of the API in the shape that I want.
Why isn't "strict": true by default? Here's OpenAI's Ted Sanders:
We didn't cover this in the announcement post, but there are a few reasons:
- The first request with each JSON schema will be slow, as we need to preprocess the JSON schema into a context-free grammar. If you don't want that latency hit (e.g., you're prototyping, or have a use case that uses variable one-off schemas), then you might prefer "strict": false
- You might have a schema that isn't covered by our subset of JSON schema. (To keep performance fast, we don't support some more complex/long-tail features.)
- In JSON mode and Structured Outputs, failures are rarer but more catastrophic. If the model gets too confused, it can get stuck in loops where it just prints technically valid output forever without ever closing the object. In these cases, you can end up waiting a minute for the request to hit the max_token limit, and you also have to pay for all those useless tokens. So if you have a really tricky schema, and you'd rather get frequent failures back quickly instead of infrequent failures back slowly, you might also want
"strict": falseBut in 99% of cases, you'll want
"strict": true.
More from Ted on how the new mode differs from function calling:
Under the hood, it's quite similar to function calling. A few differences:
- Structured Outputs is a bit more straightforward. e.g., you don't have to pretend you're writing a function where the second arg could be a two-page report to the user, and then pretend the "function" was called successfully by returning
{"success": true}- Having two interfaces lets us teach the model different default behaviors and styles, depending on which you use
- Another difference is that our current implementation of function calling can return both a text reply plus a function call (e.g., "Let me look up that flight for you"), whereas Structured Outputs will only return the JSON
The official openai-python library also added structured output support this morning, based on Pydantic and looking very similar to the Instructor library (also credited as providing inspiration in their announcement).
There are some key limitations on the new structured output mode, described in the documentation. Only a subset of JSON schema is supported, and most notably the "additionalProperties": false property must be set on all objects and all object keys must be listed in "required" - no optional keys are allowed.
Another interesting new feature: if the model denies a request on safety grounds a new refusal message will be returned:
{
"message": {
"role": "assistant",
"refusal": "I'm sorry, I cannot assist with that request."
}
}
Finally, tucked away at the bottom of this announcement is a significant new model release with a major price cut:
By switching to the new
gpt-4o-2024-08-06, developers save 50% on inputs ($2.50/1M input tokens) and 33% on outputs ($10.00/1M output tokens) compared togpt-4o-2024-05-13.
This new model also supports 16,384 output tokens, up from 4,096.
The price change is particularly notable because GPT-4o-mini, the much cheaper alternative to GPT-4o, prices image inputs at the same price as GPT-4o. This new model cuts that by half (confirmed here), making gpt-4o-2024-08-06 the new cheapest model from OpenAI for handling image inputs.
AI for Data Journalism: demonstrating what we can do with this stuff right now
I gave a talk last month at the Story Discovery at Scale data journalism conference hosted at Stanford by Big Local News. My brief was to go deep into the things we can use Large Language Models for right now, illustrated by a flurry of demos to help provide starting points for further conversations at the conference.
[... 6,081 words]Extracting data from unstructured text and images with Datasette and GPT-4 Turbo. Datasette Extract is a new Datasette plugin that uses GPT-4 Turbo (released to general availability today) and GPT-4 Vision to extract structured data from unstructured text and images.
I put together a video demo of the plugin in action today, and posted it to the Datasette Cloud blog along with screenshots and a tutorial describing how to use it.