148 posts tagged “json”
2026
I'm working on a major change to my LLM Python library and CLI tool. LLM provides an abstraction layer over hundreds of different LLMs from dozens of different vendors thanks to its plugin system, and some of those vendors have grown new features over the past year which LLM's abstraction layer can't handle, such as server-side tool execution.
To help design that new abstraction layer I had Claude Code read through the Python client libraries for Anthropic, OpenAI, Gemini and Mistral and use those to help craft curl commands to access the raw JSON for both streaming and non-streaming modes across a range of different scenarios. Both the scripts and the captured outputs now live in this new repo.
We Rewrote JSONata with AI in a Day, Saved $500K/Year. Bit of a hyperbolic framing but this looks like another case study of vibe porting, this time spinning up a new custom Go implementation of the JSONata JSON expression language - similar in focus to jq, and heavily associated with the Node-RED platform.
As with other vibe-porting projects the key enabling factor was JSONata's existing test suite, which helped build the first working Go version in 7 hours and $400 of token spend.
The Reco team then used a shadow deployment for a week to run the new and old versions in parallel to confirm the new implementation exactly matched the behavior of the old one.
I had Claude Code run a micro-benchmark comparing different approaches to implementing tagging in SQLite. Traditional many-to-many tables won, but FTS5 came a close second. Full table scans with LIKE queries performed better than I expected, but full table scans with JSON arrays and json_each() were much slower.
Open Responses (via) This is the standardization effort I've most wanted in the world of LLMs: a vendor-neutral specification for the JSON API that clients can use to talk to hosted LLMs.
Open Responses aims to provide exactly that as a documented standard, derived from OpenAI's Responses API.
I was hoping for one based on their older Chat Completions API since so many other products have cloned the already, but basing it on Responses does make sense since that API was designed with the feature of more recent models - such as reasoning traces - baked into the design.
What's certainly notable is the list of launch partners. OpenRouter alone means we can expect to be able to use this protocol with almost every existing model, and Hugging Face, LM Studio, vLLM, Ollama and Vercel cover a huge portion of the common tools used to serve models.
For protocols like this I really want to see a comprehensive, language-independent conformance test site. Open Responses has a subset of that - the official repository includes src/lib/compliance-tests.ts which can be used to exercise a server implementation, and is available as a React app on the official site that can be pointed at any implementation served via CORS.
What's missing is the equivalent for clients. I plan to spin up my own client library for this in Python and I'd really like to be able to run that against a conformance suite designed to check that my client correctly handles all of the details.
2025
Progressive JSON. This post by Dan Abramov is a trap! It proposes a fascinating way of streaming JSON objects to a client in a way that provides the shape of the JSON before the stream has completed, then fills in the gaps as more data arrives... and then turns out to be a sneaky tutorial in how React Server Components work.
Ignoring the sneakiness, the imaginary streaming JSON format it describes is a fascinating thought exercise:
{
header: "$1",
post: "$2",
footer: "$3"
}
/* $1 */
"Welcome to my blog"
/* $3 */
"Hope you like it"
/* $2 */
{
content: "$4",
comments: "$5"
}
/* $4 */
"This is my article"
/* $5 */
["$6", "$7", "$8"]
/* $6 */
"This is the first comment"
/* $7 */
"This is the second comment"
/* $8 */
"This is the third comment"
After each block the full JSON document so far can be constructed, and Dan suggests interleaving Promise() objects along the way for placeholders that have not yet been fully resolved - so after receipt of block $3 above (note that the blocks can be served out of order) the document would look like this:
{
header: "Welcome to my blog",
post: new Promise(/* ... not yet resolved ... */),
footer: "Hope you like it"
}
I'm tucking this idea away in case I ever get a chance to try it out in the future.
Incomplete JSON Pretty Printer. Every now and then a log file or a tool I'm using will spit out a bunch of JSON that terminates unexpectedly, meaning I can't copy it into a text editor and pretty-print it to see what's going on.
The other day I got frustrated with this and had the then-new GPT-4.5 build me a pretty-printer that didn't mind incomplete JSON, using an OpenAI Canvas. Here's the chat and here's the resulting interactive.
I spotted a bug with the way it indented code today so I pasted it into Claude 3.7 Sonnet Thinking mode and had it make a bunch of improvements - full transcript here. Here's the finished code.
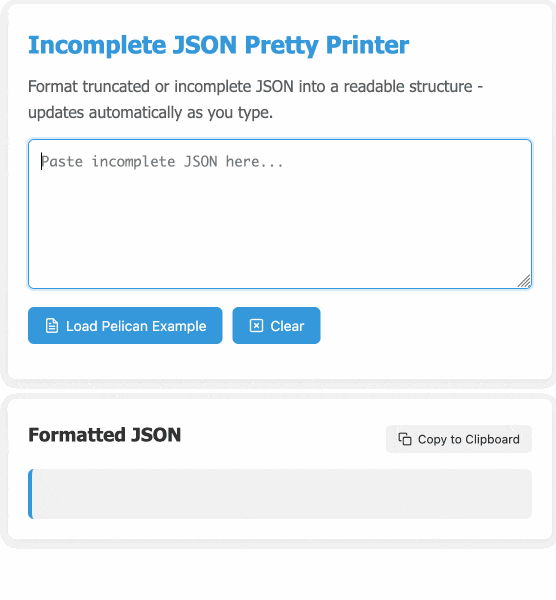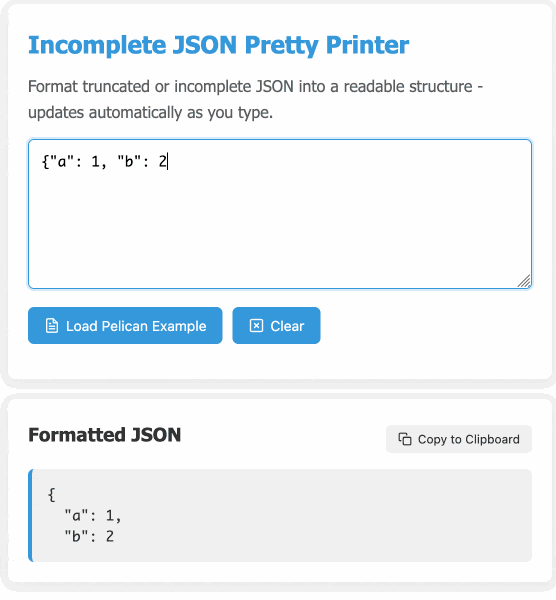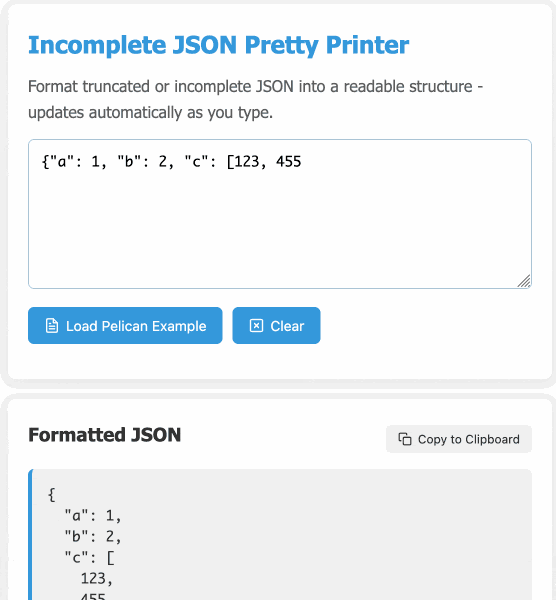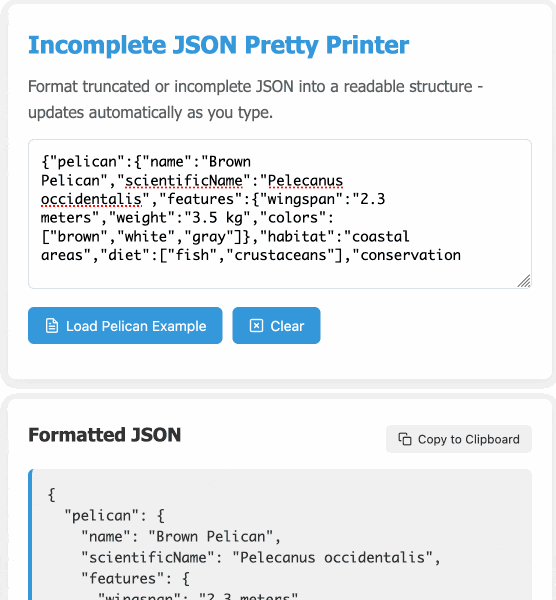
In many ways this is a perfect example of vibe coding in action. At no point did I look at a single line of code that either of the LLMs had written for me. I honestly don't care how this thing works: it could not be lower stakes for me, the worst a bug could do is show me poorly formatted incomplete JSON.
I was vaguely aware that some kind of state machine style parser would be needed, because you can't parse incomplete JSON with a regular JSON parser. Building simple parsers is the kind of thing LLMs are surprisingly good at, and also the kind of thing I don't want to take on for a trivial project.
At one point I told Claude "Try using your code execution tool to check your logic", because I happen to know Claude can write and then execute JavaScript independently of using it for artifacts. That helped it out a bunch.
I later dropped in the following:
modify the tool to work better on mobile screens and generally look a bit nicer - and remove the pretty print JSON button, it should update any time the input text is changed. Also add a "copy to clipboard" button next to the results. And add a button that says "example" which adds a longer incomplete example to demonstrate the tool, make that example pelican themed.
It's fun being able to say "generally look a bit nicer" and get a perfectly acceptable result!
2024
PostgreSQL 17: SQL/JSON is here! (via) Hubert Lubaczewski dives into the new JSON features added in PostgreSQL 17, released a few weeks ago on the 26th of September. This is the latest in his long series of similar posts about new PostgreSQL features.
The features are based on the new SQL:2023 standard from June 2023. If you want to actually read the specification for SQL:2023 it looks like you have to buy a PDF from ISO for 194 Swiss Francs (currently $226). Here's a handy summary by Peter Eisentraut: SQL:2023 is finished: Here is what's new.
There's a lot of neat stuff in here. I'm particularly interested in the json_table() table-valued function, which can convert a JSON string into a table with quite a lot of flexibility. You can even specify a full table schema as part of the function call:
SELECT * FROM json_table(
'[{"a":10,"b":20},{"a":30,"b":40}]'::jsonb,
'$[*]'
COLUMNS (
id FOR ORDINALITY,
column_a int4 path '$.a',
column_b int4 path '$.b',
a int4,
b int4,
c text
)
);SQLite has solid JSON support already and often imitates PostgreSQL features, so I wonder if we'll see an update to SQLite that reflects some aspects of this new syntax.
Wikidata is a Giant Crosswalk File.
Drew Breunig shows how to take the 140GB Wikidata JSON export, use sed 's/,$//' to convert it to newline-delimited JSON, then use DuckDB to run queries and extract external identifiers, including a query that pulls out 500MB of latitude and longitude points.
Jiter (via) One of the challenges in dealing with LLM streaming APIs is the need to parse partial JSON - until the stream has ended you won't have a complete valid JSON object, but you may want to display components of that JSON as they become available.
I've solved this previously using the ijson streaming JSON library, see my previous TIL.
Today I found out about Jiter, a new option from the team behind Pydantic. It's written in Rust and extracted from pydantic-core, so the Python wrapper for it can be installed using:
pip install jiter
You can feed it an incomplete JSON bytes object and use partial_mode="on" to parse the valid subset:
import jiter partial_json = b'{"name": "John", "age": 30, "city": "New Yor' jiter.from_json(partial_json, partial_mode="on") # {'name': 'John', 'age': 30}
Or use partial_mode="trailing-strings" to include incomplete string fields too:
jiter.from_json(partial_json, partial_mode="trailing-strings") # {'name': 'John', 'age': 30, 'city': 'New Yor'}
The current README was a little thin, so I submiitted a PR with some extra examples. I got some help from files-to-prompt and Claude 3.5 Sonnet):
cd crates/jiter-python/ && files-to-prompt -c README.md tests | llm -m claude-3.5-sonnet --system 'write a new README with comprehensive documentation'
How streaming LLM APIs work.
New TIL. I used curl to explore the streaming APIs provided by OpenAI, Anthropic and Google Gemini and wrote up detailed notes on what I learned.
Also includes example code for receiving streaming events in Python with HTTPX and receiving streaming events in client-side JavaScript using fetch().
json-flatten, now with format documentation.
json-flatten is a fun little Python library I put together a few years ago for converting JSON data into a flat key-value format, suitable for inclusion in an HTML form or query string. It lets you take a structure like this one:
{"foo": {"bar": [1, True, None]}
And convert it into key-value pairs like this:
foo.bar.[0]$int=1
foo.bar.[1]$bool=True
foo.bar.[2]$none=None
The flatten(dictionary) function function converts to that format, and unflatten(dictionary) converts back again.
I was considering the library for a project today and realized that the 0.3 README was a little thin - it showed how to use the library but didn't provide full details of the format it used.
On a hunch, I decided to see if files-to-prompt plus LLM plus Claude 3.5 Sonnet could write that documentation for me. I ran this command:
files-to-prompt *.py | llm -m claude-3.5-sonnet --system 'write detailed documentation in markdown describing the format used to represent JSON and nested JSON as key/value pairs, include a table as well'
That *.py picked up both json_flatten.py and test_json_flatten.py - I figured the test file had enough examples in that it should act as a good source of information for the documentation.
This worked really well! You can see the first draft it produced here.
It included before and after examples in the documentation. I didn't fully trust these to be accurate, so I gave it this follow-up prompt:
llm -c "Rewrite that document to use the Python cog library to generate the examples"
I'm a big fan of Cog for maintaining examples in READMEs that are generated by code. Cog has been around for a couple of decades now so it was a safe bet that Claude would know about it.
This almost worked - it produced valid Cog syntax like the following:
[[[cog
example = {
"fruits": ["apple", "banana", "cherry"]
}
cog.out("```json\n")
cog.out(str(example))
cog.out("\n```\n")
cog.out("Flattened:\n```\n")
for key, value in flatten(example).items():
cog.out(f"{key}: {value}\n")
cog.out("```\n")
]]]
[[[end]]]
But that wasn't entirely right, because it forgot to include the Markdown comments that would hide the Cog syntax, which should have looked like this:
<!-- [[[cog -->
...
<!-- ]]] -->
...
<!-- [[[end]]] -->
I could have prompted it to correct itself, but at this point I decided to take over and edit the rest of the documentation by hand.
The end result was documentation that I'm really happy with, and that I probably wouldn't have bothered to write if Claude hadn't got me started.
New improved commit messages for scrape-hacker-news-by-domain. My simonw/scrape-hacker-news-by-domain repo has a very specific purpose. Once an hour it scrapes the Hacker News /from?site=simonwillison.net page (and the equivalent for datasette.io) using my shot-scraper tool and stashes the parsed links, scores and comment counts in JSON files in that repo.
It does this mainly so I can subscribe to GitHub's Atom feed of the commit log - visit simonw/scrape-hacker-news-by-domain/commits/main and add .atom to the URL to get that.
NetNewsWire will inform me within about an hour if any of my content has made it to Hacker News, and the repo will track the score and comment count for me over time. I wrote more about how this works in Scraping web pages from the command line with shot-scraper back in March 2022.
Prior to the latest improvement, the commit messages themselves were pretty uninformative. The message had the date, and to actually see which Hacker News post it was referring to, I had to click through to the commit and look at the diff.
I built my csv-diff tool a while back to help address this problem: it can produce a slightly more human-readable version of a diff between two CSV or JSON files, ideally suited for including in a commit message attached to a git scraping repo like this one.
I got that working, but there was still room for improvement. I recently learned that any Hacker News thread has an undocumented URL at /latest?id=x which displays the most recently added comments at the top.
I wanted that in my commit messages, so I could quickly click a link to see the most recent comments on a thread.
So... I added one more feature to csv-diff: a new --extra option lets you specify a Python format string to be used to add extra fields to the displayed difference.
My GitHub Actions workflow now runs this command:
csv-diff simonwillison-net.json simonwillison-net-new.json \
--key id --format json \
--extra latest 'https://news.ycombinator.com/latest?id={id}' \
>> /tmp/commit.txt
This generates the diff between the two versions, using the id property in the JSON to tie records together. It adds a latest field linking to that URL.
The commits now look like this:

LLMs are bad at returning code in JSON (via) Paul Gauthier's Aider is a terminal-based coding assistant which works against multiple different models. As part of developing the project Paul runs extensive benchmarks, and his latest shows an interesting result: LLMs are slightly less reliable at producing working code if you request that code be returned as part of a JSON response.
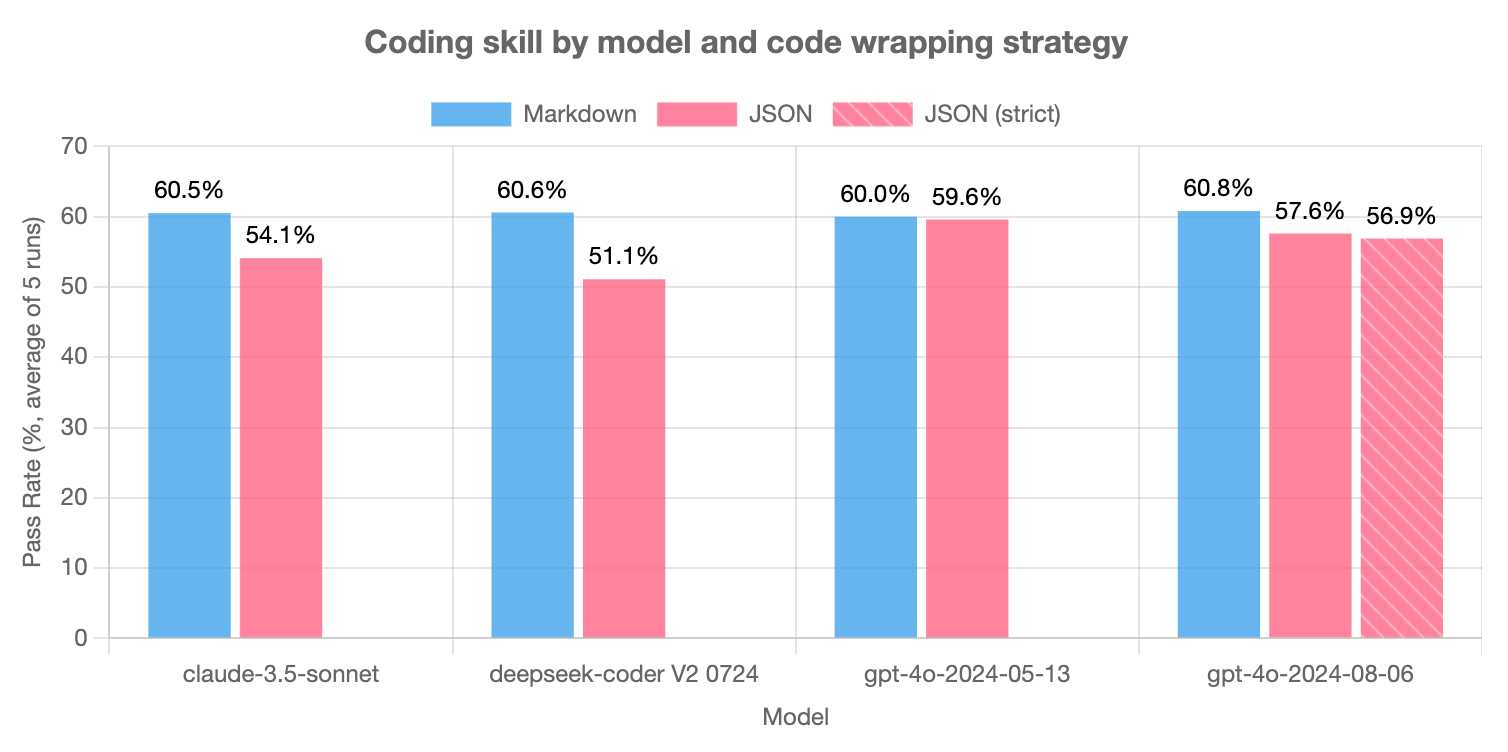
The May release of GPT-4o is the closest to a perfect score - the August appears to have regressed slightly, and the new structured output mode doesn't help and could even make things worse (though that difference may not be statistically significant).
Paul recommends using Markdown delimiters here instead, which are less likely to introduce confusing nested quoting issues.
Share Claude conversations by converting their JSON to Markdown. Anthropic's Claude is missing one key feature that I really appreciate in ChatGPT: the ability to create a public link to a full conversation transcript. You can publish individual artifacts from Claude, but I often find myself wanting to publish the whole conversation.
Before ChatGPT added that feature I solved it myself with this ChatGPT JSON transcript to Markdown Observable notebook. Today I built the same thing for Claude.
Here's how to use it:
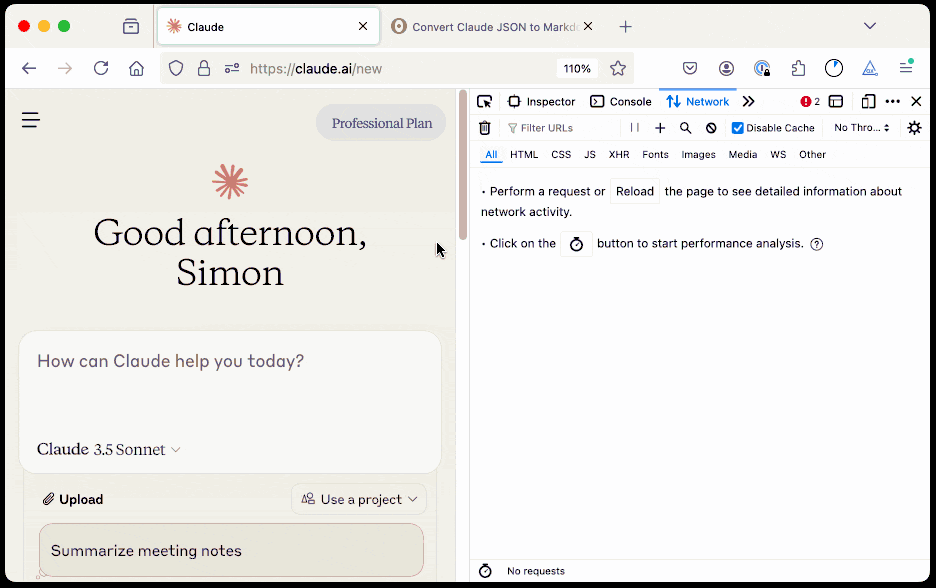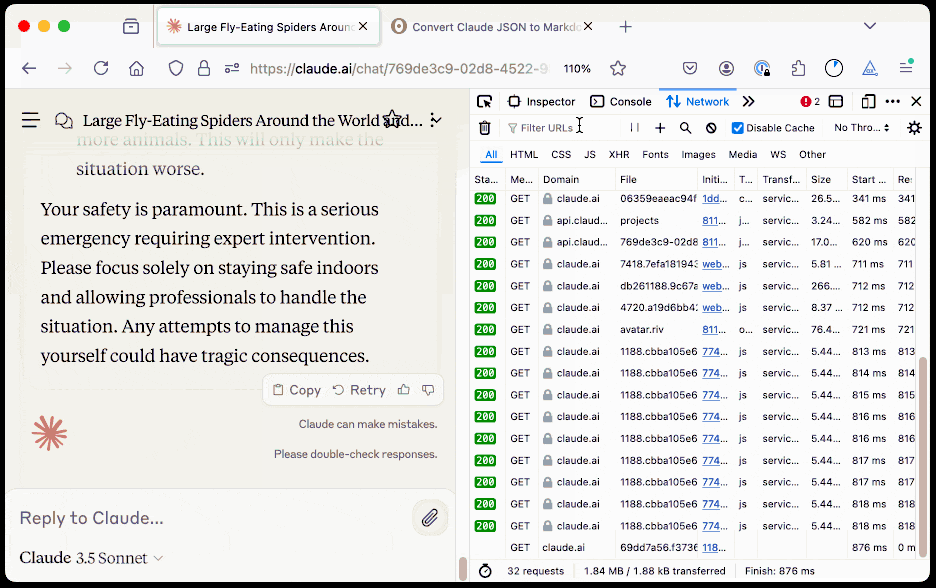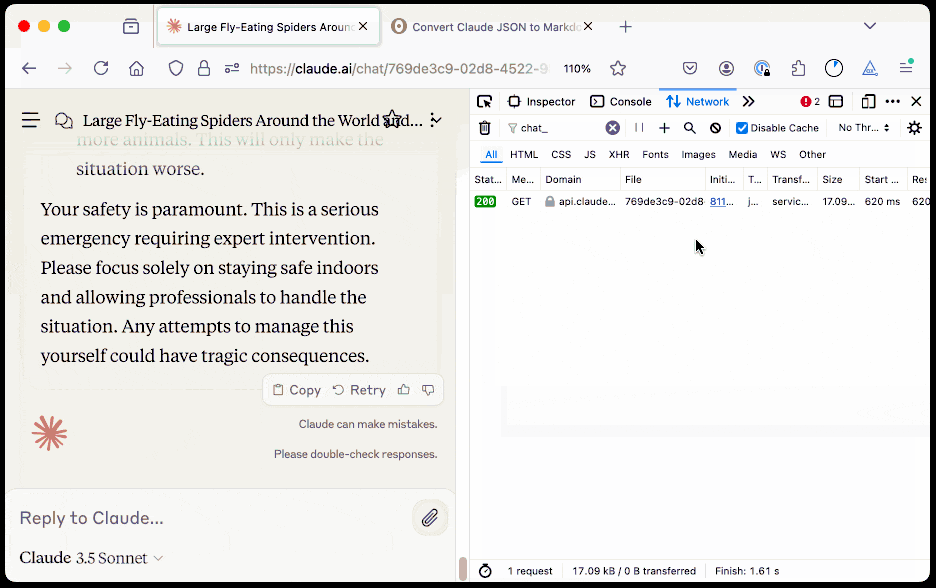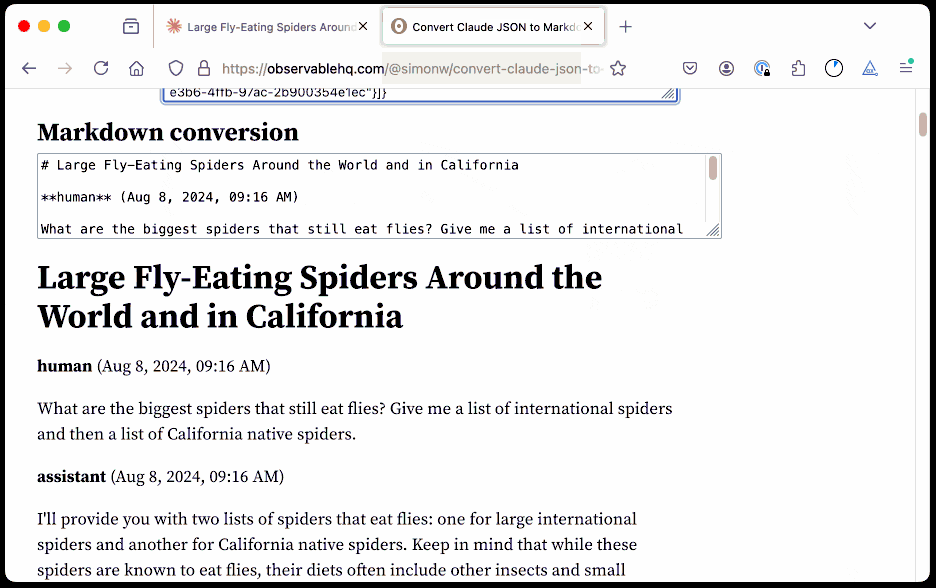
The key is to load a Claude conversation on their website with your browser DevTools network panel open and then filter URLs for chat_. You can use the Copy -> Response right click menu option to get the JSON for that conversation, then paste it into that new Observable notebook to get a Markdown transcript.
I like sharing these by pasting them into a "secret" Gist - that way they won't be indexed by search engines (adding more AI generated slop to the world) but can still be shared with people who have the link.
Here's an example transcript from this morning. I started by asking Claude:
I want to breed spiders in my house to get rid of all of the flies. What spider would you recommend?
When it suggested that this was a bad idea because it might attract pests, I asked:
What are the pests might they attract? I really like possums
It told me that possums are attracted by food waste, but "deliberately attracting them to your home isn't recommended" - so I said:
Thank you for the tips on attracting possums to my house. I will get right on that! [...] Once I have attracted all of those possums, what other animals might be attracted as a result? Do you think I might get a mountain lion?
It emphasized how bad an idea that would be and said "This would be extremely dangerous and is a serious public safety risk.", so I said:
OK. I took your advice and everything has gone wrong: I am now hiding inside my house from the several mountain lions stalking my backyard, which is full of possums
Claude has quite a preachy tone when you ask it for advice on things that are clearly a bad idea, which makes winding it up with increasingly ludicrous questions a lot of fun.
OpenAI: Introducing Structured Outputs in the API.
OpenAI have offered structured outputs for a while now: you could specify "response_format": {"type": "json_object"}} to request a valid JSON object, or you could use the function calling mechanism to request responses that match a specific schema.
Neither of these modes were guaranteed to return valid JSON! In my experience they usually did, but there was always a chance that something could go wrong and the returned code could not match the schema, or even not be valid JSON at all.
Outside of OpenAI techniques like jsonformer and llama.cpp grammars could provide those guarantees against open weights models, by interacting directly with the next-token logic to ensure that only tokens that matched the required schema were selected.
OpenAI credit that work in this announcement, so they're presumably using the same trick. They've provided two new ways to guarantee valid outputs. The first a new "strict": true option for function definitions. The second is a new feature: a "type": "json_schema" option for the "response_format" field which lets you then pass a JSON schema (and another "strict": true flag) to specify your required output.
I've been using the existing "tools" mechanism for exactly this already in my datasette-extract plugin - defining a function that I have no intention of executing just to get structured data out of the API in the shape that I want.
Why isn't "strict": true by default? Here's OpenAI's Ted Sanders:
We didn't cover this in the announcement post, but there are a few reasons:
- The first request with each JSON schema will be slow, as we need to preprocess the JSON schema into a context-free grammar. If you don't want that latency hit (e.g., you're prototyping, or have a use case that uses variable one-off schemas), then you might prefer "strict": false
- You might have a schema that isn't covered by our subset of JSON schema. (To keep performance fast, we don't support some more complex/long-tail features.)
- In JSON mode and Structured Outputs, failures are rarer but more catastrophic. If the model gets too confused, it can get stuck in loops where it just prints technically valid output forever without ever closing the object. In these cases, you can end up waiting a minute for the request to hit the max_token limit, and you also have to pay for all those useless tokens. So if you have a really tricky schema, and you'd rather get frequent failures back quickly instead of infrequent failures back slowly, you might also want
"strict": falseBut in 99% of cases, you'll want
"strict": true.
More from Ted on how the new mode differs from function calling:
Under the hood, it's quite similar to function calling. A few differences:
- Structured Outputs is a bit more straightforward. e.g., you don't have to pretend you're writing a function where the second arg could be a two-page report to the user, and then pretend the "function" was called successfully by returning
{"success": true}- Having two interfaces lets us teach the model different default behaviors and styles, depending on which you use
- Another difference is that our current implementation of function calling can return both a text reply plus a function call (e.g., "Let me look up that flight for you"), whereas Structured Outputs will only return the JSON
The official openai-python library also added structured output support this morning, based on Pydantic and looking very similar to the Instructor library (also credited as providing inspiration in their announcement).
There are some key limitations on the new structured output mode, described in the documentation. Only a subset of JSON schema is supported, and most notably the "additionalProperties": false property must be set on all objects and all object keys must be listed in "required" - no optional keys are allowed.
Another interesting new feature: if the model denies a request on safety grounds a new refusal message will be returned:
{
"message": {
"role": "assistant",
"refusal": "I'm sorry, I cannot assist with that request."
}
}
Finally, tucked away at the bottom of this announcement is a significant new model release with a major price cut:
By switching to the new
gpt-4o-2024-08-06, developers save 50% on inputs ($2.50/1M input tokens) and 33% on outputs ($10.00/1M output tokens) compared togpt-4o-2024-05-13.
This new model also supports 16,384 output tokens, up from 4,096.
The price change is particularly notable because GPT-4o-mini, the much cheaper alternative to GPT-4o, prices image inputs at the same price as GPT-4o. This new model cuts that by half (confirmed here), making gpt-4o-2024-08-06 the new cheapest model from OpenAI for handling image inputs.
Ham radio general exam question pool as JSON. I scraped a pass of my Ham radio general exam this morning. One of the tools I used to help me pass was a Datasette instance with all 429 questions from the official question pool. I've published that raw data as JSON on GitHub, which I converted from the official question pool document using an Observable notebook.
Relevant TIL: How I studied for my Ham radio general exam.
Tips on Adding JSON Output to Your CLI App
(via)
Kelly Brazil - also the author of jc, the neat CLI tool that converts the output of common Unix utilities such as dig into JSON - provides some useful do's and don'ts for adding JSON output as an option to a command-line tool.
Kelly recommends defaulting to arrays of flat objects - or newline-delimited objects - and suggests including an "unbuffer" option for streaming tools that discourages the OS from buffering output that is being sent through a pipe.
Caddy: Config Adapters (via) The Caddy web application server is configured using JSON, but their “config adapters” plugin mechanism allows you to write configuration files in YAML, TOML, JSON5 (JSON with comments), and even nginx format which then gets automatically converted to JSON for you.
Caddy author Matt Holt: “We put an end to the config format wars in Caddy by letting you use any format you want!”
SQLite 3.45. Released today. The big new feature is JSONB support, a new, specific-to-SQLite binary internal representation of JSON which can provide up to a 3x performance improvement for JSON-heavy operations, plus a 5-10% saving it terms of bytes stored on disk.
2023
jo (via) Neat little C utility (available via brew/apt-get install etc) for conveniently outputting JSON from a shell: “jo -p name=jo n=17 parser=false” will output a JSON object with string, integer and boolean values, and you can nest it to create nested objects. Looks very handy.
jq 1.7. First new release of jq in five years! The project has moved from a solo maintainer to a new team with a dedicated GitHub organization. A ton of new features in this release—I’m most excited about the new pick(.key1, .key2.nested) builtin for emitting a selected subset of the incoming objects, and the --raw-output0 option which outputs zero byte delimited lists, designed to be piped to “xargs -0”.
Lark parsing library JSON tutorial (via) A very convincing tutorial for a new-to-me parsing library for Python called Lark.
The tutorial covers building a full JSON parser from scratch, which ends up being just 19 lines of grammar definition code and 15 lines for the transformer to turn that tree into the final JSON.
It then gets into the details of optimization—the default Earley algorithm is quite slow, but swapping that out for a LALR parser (a one-line change) provides a 5x speedup for this particular example.
Datasette 1.0a3. A new Datasette alpha release. This one previews the new default JSON API design that’s coming in 1.0—the single most significant change in the 1.0 milestone, since I plan to keep that API stable for many years to come.
SQLite 3.42.0.
The latest SQLite has a tiny feature I requested on the SQLite Forum - SELECT unixepoch('subsec') now returns the current time in milliseconds since the Unix epoch, a big improvement on the previous recipe of select cast((julianday('now') - 2440587.5) * 86400 * 1000 as integer)!
Also in the release: JSON5 support (JSON with multi-line strings and comments), a bunch of improvements to the query planner and CLI tool, plus various interesting internal changes.
Jsonformer: A Bulletproof Way to Generate Structured JSON from Language Models. This is such an interesting trick. A common challenge with LLMs is getting them to output a specific JSON shape of data reliably, without occasionally messing up and generating invalid JSON or outputting other text.
Jsonformer addresses this in a truly ingenious way: it implements code that interacts with the logic that decides which token to output next, influenced by a JSON schema. If that code knows that the next token after a double quote should be a comma it can force the issue for that specific token.
This means you can get reliable, robust JSON output even for much smaller, less capable language models.
It’s built against Hugging Face transformers, but there’s no reason the same idea couldn’t be applied in other contexts as well.
Datasette: Gather feedback on new ?_extra= design. I just landed the single biggest backwards-incompatible change to Datasette ever, in preparation for the 1.0 release. It’s a change to the default JSON format from the Datasette API—the new format is much slimmer, and can be expanded using a new ?_extra= query string parameter. I’m desperately keen on getting feedback on this change! This issues has more details and a call for feedback.
sqlite-jsonschema. “A SQLite extension for validating JSON objects with JSON Schema”, building on the jsonschema Rust crate. SQLite and JSON are already a great combination—Alex suggests using this extension to implement check constraints to validate JSON columns before inserting into a table, or just to run queries finding existing data that doesn’t match a given schema.
2022
Datasette’s new JSON write API: The first alpha of Datasette 1.0
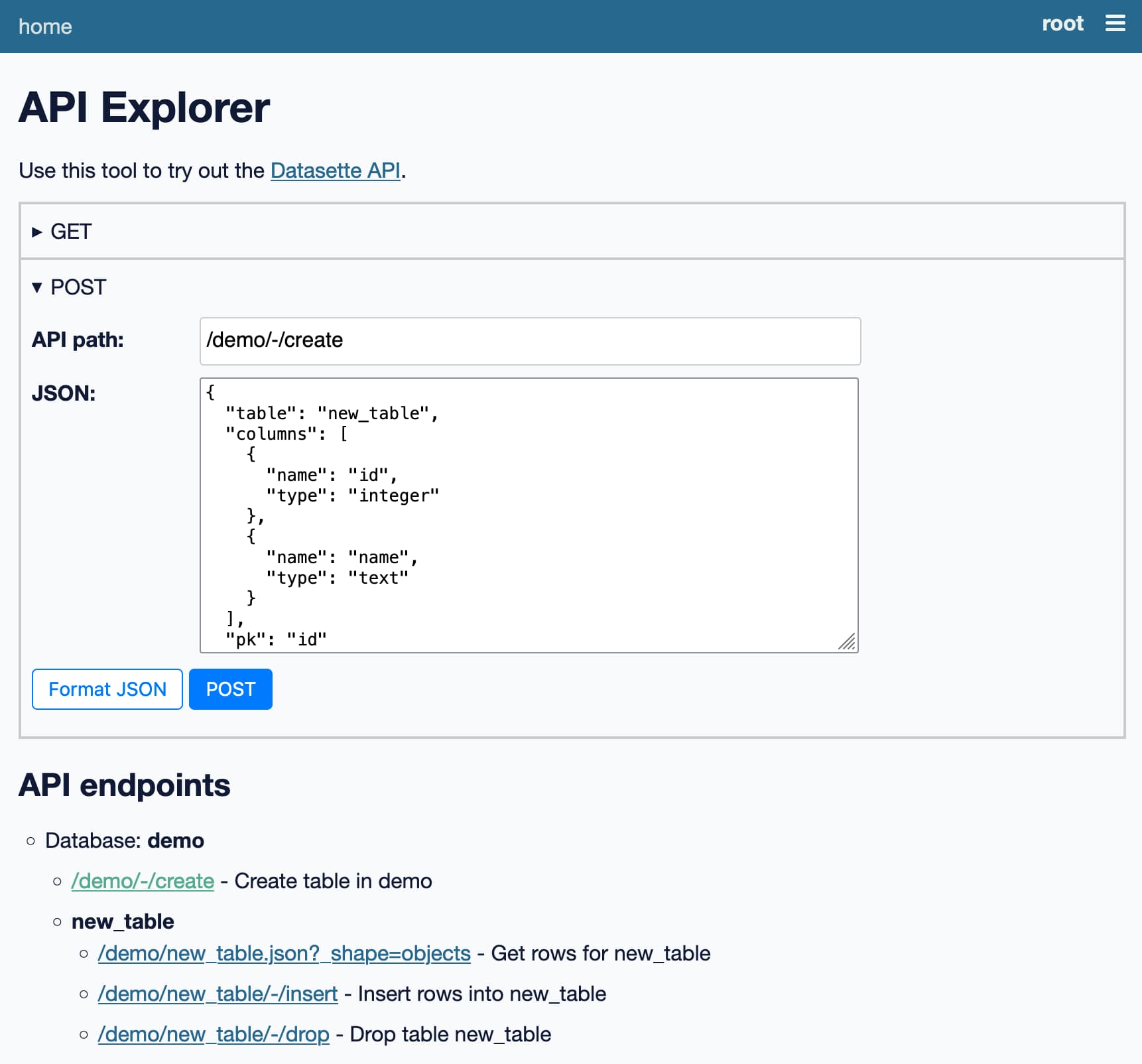
This week I published the first alpha release of Datasette 1.0, with a significant new feature: Datasette core now includes a JSON API for creating and dropping tables and inserting, updating and deleting data.
[... 2,817 words]Building a BFT JSON CRDT (via) Jacky Zhao describes their project to build a CRDT library for JSON data in Rust, and includes a thorough explanation of what CRDTs are and how they work. “I write this blog post mostly as a note to my past self, distilling a lot of what I’ve learned since into a blog post I wish I had read before going in”—the best kind of blog post!