124 posts tagged “http”
2026
The OpenStreetMap tiles on the Datasette global-power-plants demo weren't displaying correctly. This turned out to be caused by two bugs.
The first is that the CAPTCHA I added to that site a few weeks ago was triggering for the .json fetch requests used by the map plugin, and since those weren't HTML the user was not being asked to solve them. Here's the fix.
The second was that OpenStreetMap quite reasonably block tile requests from sites that use a Referrer-Policy: no-referrer header.
Datasette does this by default, and I didn't want to change that default on people without warning - so I had Codex + GPT-5.5 build me a new plugin to help set that header to another value.
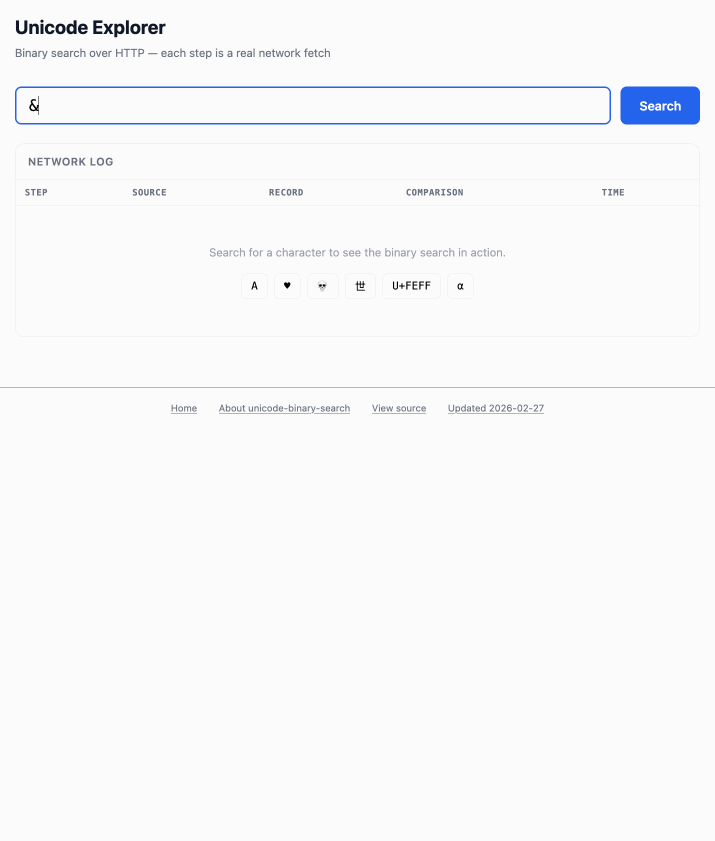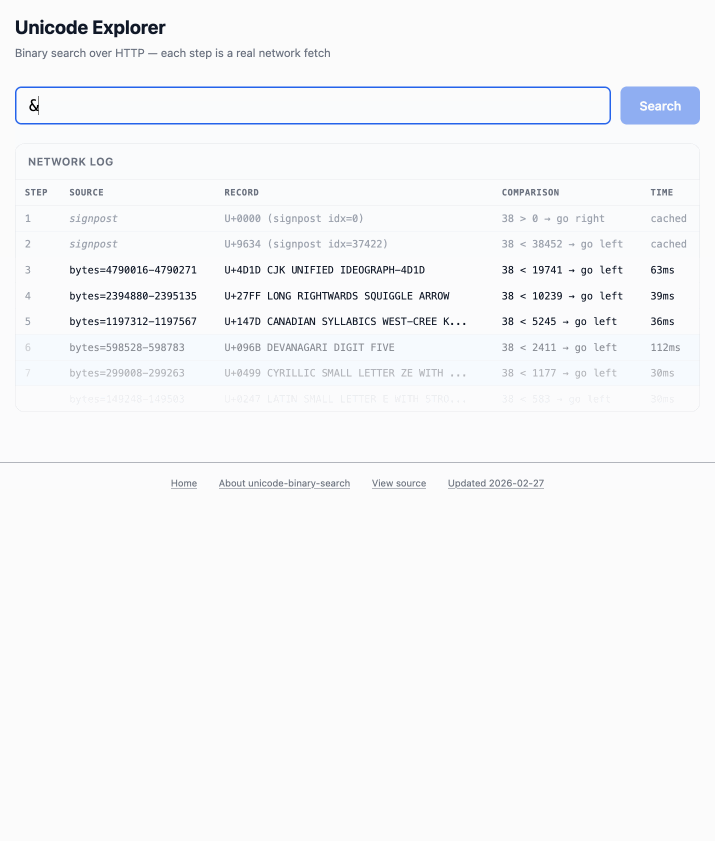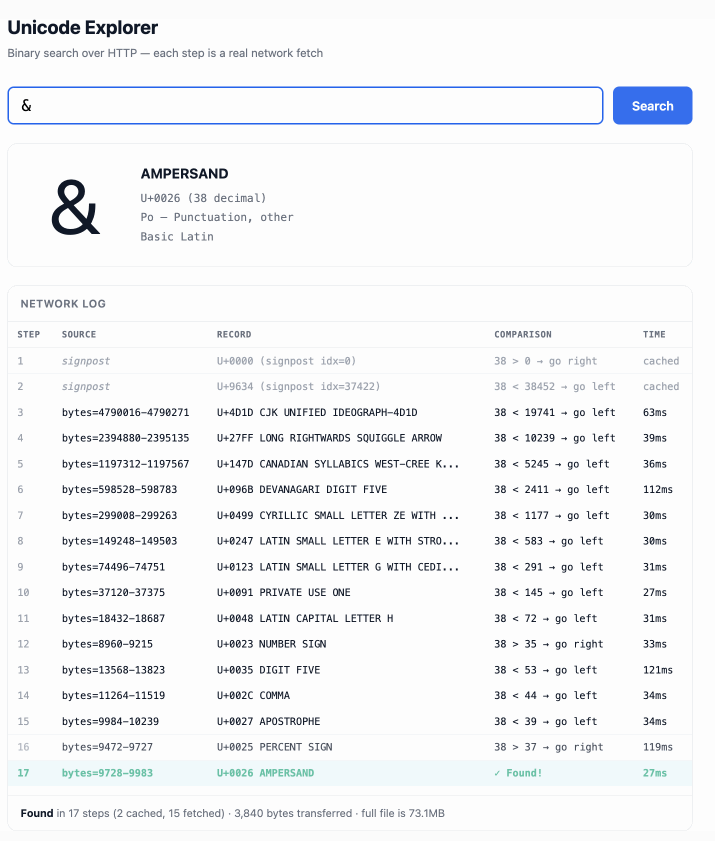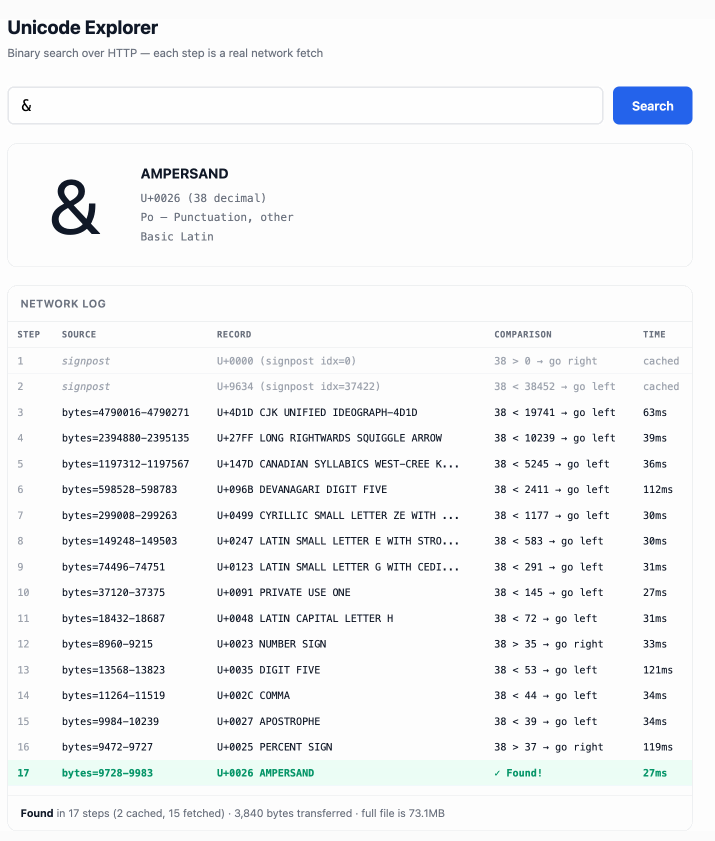
Unicode Explorer using binary search over fetch() HTTP range requests. Here's a little prototype I built this morning from my phone as an experiment in HTTP range requests, and a general example of using LLMs to satisfy curiosity.
I've been collecting HTTP range tricks for a while now, and I decided it would be fun to build something with them myself that used binary search against a large file to do something useful.
So I brainstormed with Claude. The challenge was coming up with a use case for binary search where the data could be naturally sorted in a way that would benefit from binary search.
One of Claude's suggestions was looking up information about unicode codepoints, which means searching through many MBs of metadata.
I had Claude write me a spec to feed to Claude Code - visible here - then kicked off an asynchronous research project with Claude Code for web against my simonw/research repo to turn that into working code.
Here's the resulting report and code. One interesting thing I learned is that Range request tricks aren't compatible with HTTP compression because they mess with the byte offset calculations. I added 'Accept-Encoding': 'identity' to the fetch() calls but this isn't actually necessary because Cloudflare and other CDNs automatically skip compression if a content-range header is present.
I deployed the result to my tools.simonwillison.net site, after first tweaking it to query the data via range requests against a CORS-enabled 76.6MB file in an S3 bucket fronted by Cloudflare.
The demo is fun to play with - type in a single character like ø or a hexadecimal codepoint indicator like 1F99C and it will binary search its way through the large file and show you the steps it takes along the way:
Introducing gisthost.github.io
I am a huge fan of gistpreview.github.io, the site by Leon Huang that lets you append ?GIST_id to see a browser-rendered version of an HTML page that you have saved to a Gist. The last commit was ten years ago and I needed a couple of small changes so I’ve forked it and deployed an updated version at gisthost.github.io.
2025
YouTube embeds fail with a 153 error. I just fixed this bug on my blog. I was getting an annoying "Error 153: Video player configuration error" on some of the YouTube video embeds (like this one) on this site. After some digging it turns out the culprit was this HTTP header, which Django's SecurityMiddleware was sending by default:
Referrer-Policy: same-origin
YouTube's embedded player terms documentation explains why this broke:
API Clients that use the YouTube embedded player (including the YouTube IFrame Player API) must provide identification through the
HTTP Refererrequest header. In some environments, the browser will automatically setHTTP Referer, and API Clients need only ensure they are not setting theReferrer-Policyin a way that suppresses theReferervalue. YouTube recommends usingstrict-origin-when-cross-originReferrer-Policy, which is already the default in many browsers.
The fix, which I outsourced to GitHub Copilot agent since I was on my phone, was to add this to my settings.py:
SECURE_REFERRER_POLICY = "strict-origin-when-cross-origin"
This explainer on the Chrome blog describes what the header means:
strict-origin-when-cross-originoffers more privacy. With this policy, only the origin is sent in the Referer header of cross-origin requests.This prevents leaks of private data that may be accessible from other parts of the full URL such as the path and query string.
Effectively it means that any time you follow a link from my site to somewhere else they'll see this in the incoming HTTP headers even if you followed the link from a page other than my homepage:
Referer: https://simonwillison.net/
The previous header, same-origin, is explained by MDN here:
Send the origin, path, and query string for same-origin requests. Don't send the
Refererheader for cross-origin requests.
This meant that previously traffic from my site wasn't sending any HTTP referer at all!
httpjail
(via)
Here's a promising new (experimental) project in the sandboxing space from Ammar Bandukwala at Coder. httpjail provides a Rust CLI tool for running an individual process against a custom configured HTTP proxy.
The initial goal is to help run coding agents like Claude Code and Codex CLI with extra rules governing how they interact with outside services. From Ammar's blog post that introduces the new tool, Fine-grained HTTP filtering for Claude Code:
httpjailimplements an HTTP(S) interceptor alongside process-level network isolation. Under default configuration, all DNS (udp:53) is permitted and all other non-HTTP(S) traffic is blocked.
httpjailrules are either JavaScript expressions or custom programs. This approach makes them far more flexible than traditional rule-oriented firewalls and avoids the learning curve of a DSL.Block all HTTP requests other than the LLM API traffic itself:
$ httpjail --js "r.host === 'api.anthropic.com'" -- claude "build something great"
I tried it out using OpenAI's Codex CLI instead and found this recipe worked:
brew upgrade rust
cargo install httpjail # Drops it in `~/.cargo/bin`
httpjail --js "r.host === 'chatgpt.com'" -- codex
Within that Codex instance the model ran fine but any attempts to access other URLs (e.g. telling it "Use curl to fetch simonwillison.net)" failed at the proxy layer.
This is still at a really early stage but there's a lot I like about this project. Being able to use JavaScript to filter requests via the --js option is neat (it's using V8 under the hood), and there's also a --sh shellscript option which instead runs a shell program passing environment variables that can be used to determine if the request should be allowed.
At a basic level it works by running a proxy server and setting HTTP_PROXY and HTTPS_PROXY environment variables so well-behaving software knows how to route requests.
It can also add a bunch of other layers. On Linux it sets up nftables rules to explicitly deny additional network access. There's also a --docker-run option which can launch a Docker container with the specified image but first locks that container down to only have network access to the httpjail proxy server.
It can intercept, filter and log HTTPS requests too by generating its own certificate and making that available to the underlying process.
I'm always interested in new approaches to sandboxing, and fine-grained network access is a particularly tricky problem to solve. This looks like a very promising step in that direction - I'm looking forward to seeing how this project continues to evolve.
tidwall/pogocache
(via)
New project from Josh Baker, author of the excellent tg C geospatial libarry (covered previously) and various other interesting projects:
Pogocache is fast caching software built from scratch with a focus on low latency and cpu efficency.
Faster: Pogocache is faster than Memcache, Valkey, Redis, Dragonfly, and Garnet. It has the lowest latency per request, providing the quickest response times. It's optimized to scale from one to many cores, giving you the best single-threaded and multithreaded performance.
Faster than Memcache and Redis is a big claim! The README includes a design details section that explains how the system achieves that performance, using a sharded hashmap inspired by Josh's shardmap project and clever application of threads.
Performance aside, the most interesting thing about Pogocache is the server interface it provides: it emulates the APIs for Redis and Memcached, provides a simple HTTP API and lets you talk to it over the PostgreSQL wire protocol as well!
psql -h localhost -p 9401
=> SET first Tom;
=> SET last Anderson;
=> SET age 37;
$ curl http://localhost:9401/last
Anderson
2024
Some Go web dev notes. Julia Evans on writing small, self-contained web applications in Go:
In general everything about it feels like it makes projects easy to work on for 5 days, abandon for 2 years, and then get back into writing code without a lot of problems.
Go 1.22 introduced HTTP routing in February of this year, making it even more practical to build a web application using just the Go standard library.
How streaming LLM APIs work.
New TIL. I used curl to explore the streaming APIs provided by OpenAI, Anthropic and Google Gemini and wrote up detailed notes on what I learned.
Also includes example code for receiving streaming events in Python with HTTPX and receiving streaming events in client-side JavaScript using fetch().
SQL Injection Isn’t Dead: Smuggling Queries at the Protocol Level (via) PDF slides from a presentation by Paul Gerste at DEF CON 32. It turns out some databases have vulnerabilities in their binary protocols that can be exploited by carefully crafted SQL queries.
Paul demonstrates an attack against PostgreSQL (which works in some but not all of the PostgreSQL client libraries) which uses a message size overflow, by embedding a string longer than 4GB (2**32 bytes) which overflows the maximum length of a string in the underlying protocol and writes data to the subsequent value. He then shows a similar attack against MongoDB.
The current way to protect against these attacks is to ensure a size limit on incoming requests. This can be more difficult than you may expect - Paul points out that alternative paths such as WebSockets might bypass limits that are in place for regular HTTP requests, plus some servers may apply limits before decompression, allowing an attacker to send a compressed payload that is larger than the configured limit.

django-http-debug, a new Django app mostly written by Claude
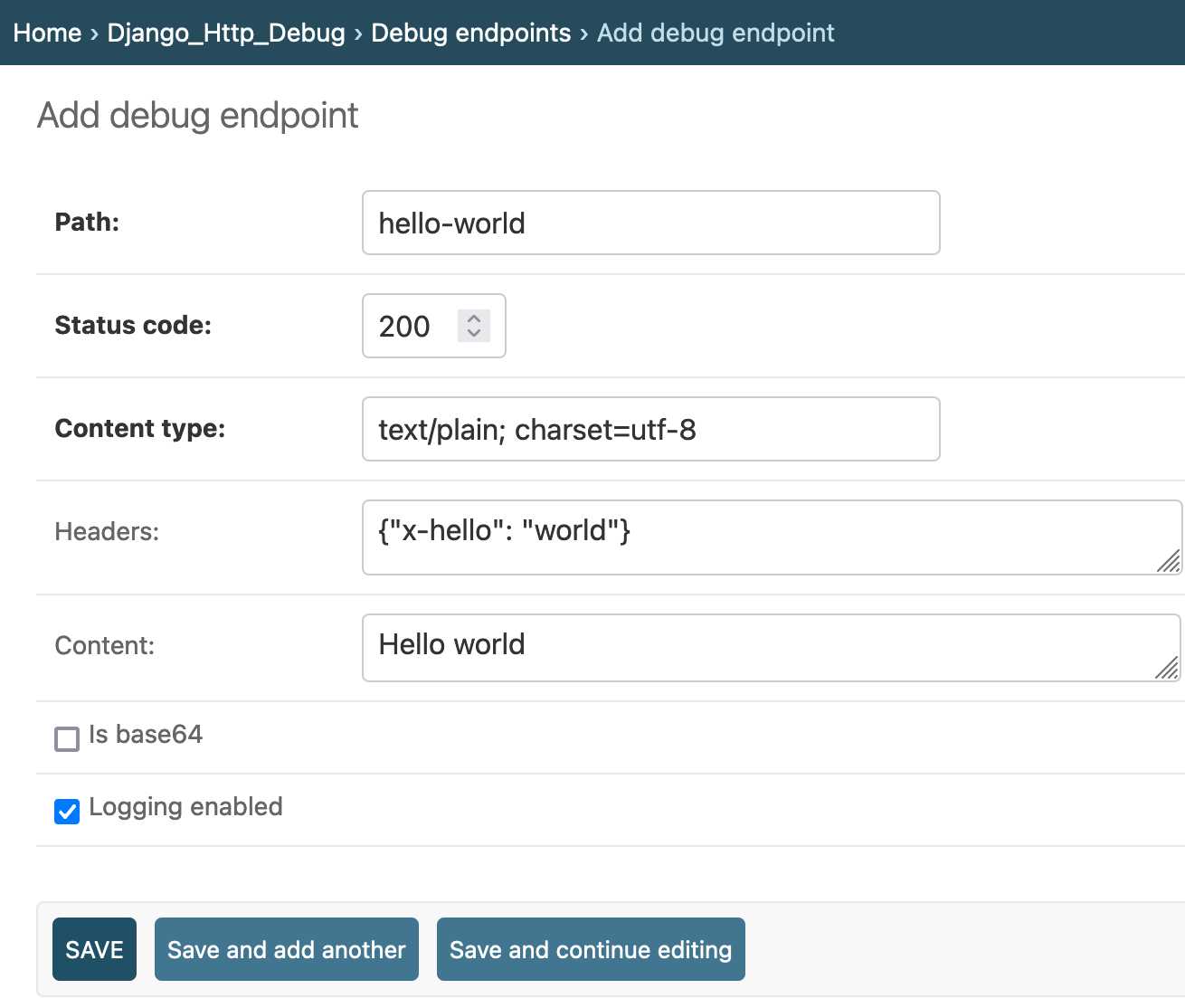
Yesterday I finally developed something I’ve been casually thinking about building for a long time: django-http-debug. It’s a reusable Django app—something you can pip install into any Django project—which provides tools for quickly setting up a URL that returns a canned HTTP response and logs the full details of any incoming request to a database table.
How I write HTTP services in Go after 13 years (via) Useful set of current best practices for deploying HTTP servers written in Go. I guess Go counts as boring technology these days, which is high praise in my book.
2023
Cloudflare does not consider vary values in caching decisions. Here’s the spot in Cloudflare’s documentation where they hide a crucially important detail:
“Cloudflare does not consider vary values in caching decisions. Nevertheless, vary values are respected when Vary for images is configured and when the vary header is vary: accept-encoding.”
This means you can’t deploy an application that uses content negotiation via the Accept header behind the Cloudflare CDN—for example serving JSON or HTML for the same URL depending on the incoming Accept header. If you do, Cloudflare may serve cached JSON to an HTML client or vice-versa.
There’s an exception for image files, which Cloudflare added support for in September 2021 (for Pro accounts only) in order to support formats such as WebP which may not have full support across all browsers.
See this page fetch itself, byte by byte, over TLS (via) George MacKerron built a TLS 1.3 library in TypeScript and used it to construct this amazing educational demo, which performs a full HTTPS request for its own source code over a WebSocket and displays an annotated byte-by-byte representation of the entire exchange. This is the most useful illustration of how HTTPS actually works that I’ve ever seen.
urllib3 v2.0.0 is now generally available. urllib3 is 12 years old now, and is a common low-level dependency for packages like requests and httpx. The biggest new feature in v2 is a higher-level API: resp = urllib3.request(“GET”, “https://example.com”)—a very welcome addition to the library.
2022
RFC 7807: Problem Details for HTTP APIs (via) This RFC has been brewing for quite a while, and is currently in last call (ends 2022-11-03). I’m designing the JSON error messages for Datasette at the moment so this could not be more relevant for me.
Introducing sqlite-http: A SQLite extension for making HTTP requests (via) Characteristically thoughtful SQLite extension from Alex, following his sqlite-html extension from a few days ago. sqlite-http lets you make HTTP requests from SQLite—both as a SQL function that returns a string, and as a table-valued SQL function that lets you independently access the body, headers and even the timing data for the request.
This write-up is excellent: it provides interactive demos but also shows how additional SQLite extensions such as the new-to-me “define” extension can be combined with sqlite-http to create custom functions for parsing and processing HTML.

curlconverter.com (via) This is pretty magic: paste in a “curl” command (including the ones you get from browser devtools using copy-as-curl) and this will convert that into code for making the same HTTP request... using Python, JavaScript, PHP, R, Go, Rust, Elixir, Java, MATLAB, Ansible URI, Strest, Dart or JSON.
2021
Hurl (via) Hurl is “a command line tool that runs HTTP requests defined in a simple plain text format”—written in Rust on top of curl, it lets you run HTTP requests and then execute assertions against the response, defined using JSONPath or XPath for HTML. It can even assert that responses were returned within a specified duration.
New HTTP standards for caching on the modern web (via) Cache-Status is a new HTTP header (RFC from August 2021) designed to provide better debugging information about which caches were involved in serving a request—“Cache-Status: Nginx; hit, Cloudflare; fwd=stale; fwd-status=304; collapsed; ttl=300” for example indicates that Nginx served a cache hit, then Cloudflare had a stale cached version so it revalidated from Nginx, got a 304 not modified, collapsed multiple requests (dogpile prevention) and plans to serve the new cached value for the next five minutes. Also described is $Target-Cache-Control: which allows different CDNs to respond to different headers and is already supported by Cloudflare and Akamai (Cloudflare-CDN-Cache-Control: and Akamai-Cache-Control:).
Notes on streaming large API responses
I started a Twitter conversation last week about API endpoints that stream large amounts of data as an alternative to APIs that return 100 results at a time and require clients to paginate through all of the pages in order to retrieve all of the data:
[... 1,692 words]2020
Weeknotes: Archiving coronavirus.data.gov.uk, custom pages and directory configuration in Datasette, photos-to-sqlite
I mainly made progress on three projects this week: Datasette, photos-to-sqlite and a cleaner way of archiving data to a git repository.
[... 1,132 words]Async Support—HTTPX
(via)
HTTPX is the new async-friendly HTTP library for Python spearheaded by Tom Christie. It works in both async and non-async mode with an API very similar to requests. The async support is particularly interesting - it's a really clean API, and now that Jupyter supports top-level await you can run (await httpx.AsyncClient().get(url)).text directly in a cell and get back the response. Most excitingly the library lets you pass an ASGI app directly to the client and then perform requests against it - ideal for unit tests.
2018
Usage of ARIA attributes via HTTP Archive. A neat example of a Google BigQuery query you can run against the HTTP Archive public dataset (a crawl of the “top” websites run periodically by the Internet Archive, which captures the full details of every resource fetched) to see which ARIA attributes are used the most often. Linking to this because I used it successfully today as the basis for my own custom query—I love that it’s possible to analyze a huge representative sample of the modern web in this way.
Cookies-over-HTTP Bad (via) Mike West from the Chrome security team proposes a way for browsers to start discouraging the use of tracking cookies sent over HTTP—which represent a significant threat to user privacy from network attackers. It’s a clever piece of thinking: browsers would slowly ramp up the forced expiry deadline for non-HTTPS cookies, further encouraging sites to switch to HTTPS cookies while giving them ample time to adapt.