148 posts tagged “scaling”
2026
Serving the For You feed. One of Bluesky's most interesting features is that anyone can run their own custom "feed" implementation and make it available to other users - effectively enabling custom algorithms that can use any mechanism they like to recommend posts.
spacecowboy runs the For You Feed, used by around 72,000 people. This guest post on the AT Protocol blog explains how it works.
The architecture is fascinating. The feed is served by a single Go process using SQLite on a "gaming" PC in spacecowboy's living room - 16 cores, 96GB of RAM and 4TB of attached NVMe storage.
Recommendations are based on likes: what else are the people who like the same things as you liking on the platform?
That Go server consumes the Bluesky firehose and stores the relevant details in SQLite, keeping the last 90 days of relevant data, which currently uses around 419GB of SQLite storage.
Public internet traffic is handled by a $7/month VPS on OVH, which talks to the living room server via Tailscale.
Total cost is now $30/month: $20 in electricity, $7 in VPS and $3 for the two domain names. spacecowboy estimates that the existing system could handle all ~1 million daily active Bluesky users if they were to switch to the cheapest algorithm they have found to work.
2025
Cloudflare's network began experiencing significant failures to deliver core network traffic [...] triggered by a change to one of our database systems' permissions which caused the database to output multiple entries into a “feature file” used by our Bot Management system. That feature file, in turn, doubled in size. The larger-than-expected feature file was then propagated to all the machines that make up our network. [...] The software had a limit on the size of the feature file that was below its doubled size. That caused the software to fail. [...]
This resulted in the following panic which in turn resulted in a 5xx error:
thread fl2_worker_thread panicked: called Result::unwrap() on an Err value
— Matthew Prince, Cloudflare outage on November 18, 2025, see also this comment
The case against pgvector (via) I wasn't keen on the title of this piece but the content is great: Alex Jacobs talks through lessons learned trying to run the popular pgvector PostgreSQL vector indexing extension at scale, in particular the challenges involved in maintaining a large index with close-to-realtime updates using the IVFFlat or HNSW index types.
The section on pre-v.s.-post filtering is particularly useful:
Okay but let's say you solve your index and insert problems. Now you have a document search system with millions of vectors. Documents have metadata---maybe they're marked as
draft,published, orarchived. A user searches for something, and you only want to return published documents.[...] should Postgres filter on status first (pre-filter) or do the vector search first and then filter (post-filter)?
This seems like an implementation detail. It’s not. It’s the difference between queries that take 50ms and queries that take 5 seconds. It’s also the difference between returning the most relevant results and… not.
The Hacker News thread for this article attracted a robust discussion, including some fascinating comments by Discourse developer Rafael dos Santos Silva (xfalcox) about how they are using pgvector at scale:
We [run pgvector in production] at Discourse, in thousands of databases, and it's leveraged in most of the billions of page views we serve. [...]
Also worth mentioning that we use quantization extensively:
- halfvec (16bit float) for storage - bit (binary vectors) for indexes
Which makes the storage cost and on-going performance good enough that we could enable this in all our hosting. [...]
In Discourse embeddings power:
- Related Topics, a list of topics to read next, which uses embeddings of the current topic as the key to search for similar ones
- Suggesting tags and categories when composing a new topic
- Augmented search
- RAG for uploaded files
For resiliency, the DNS Enactor operates redundantly and fully independently in three different Availability Zones (AZs). [...] When the second Enactor (applying the newest plan) completed its endpoint updates, it then invoked the plan clean-up process, which identifies plans that are significantly older than the one it just applied and deletes them. At the same time that this clean-up process was invoked, the first Enactor (which had been unusually delayed) applied its much older plan to the regional DDB endpoint, overwriting the newer plan. [...] The second Enactor's clean-up process then deleted this older plan because it was many generations older than the plan it had just applied. As this plan was deleted, all IP addresses for the regional endpoint were immediately removed.
— AWS, Amazon DynamoDB Service Disruption in Northern Virginia (US-EAST-1) Region (14.5 hours long!)
In Python 3.14, I have implemented several changes to fix thread safety of
asyncioand enable it to scale effectively on the free-threaded build of CPython. It is now implemented using lock-free data structures and per-thread state, allowing for highly efficient task management and execution across multiple threads. In the general case of multiple event loops running in parallel, there is no lock contention and performance scales linearly with the number of threads. [...]For a deeper dive into the implementation, check out the internal docs for asyncio.
— Kumar Aditya, Scaling asyncio on Free-Threaded Python
Announcing PlanetScale for Postgres. PlanetScale formed in 2018 to build a commercial offering on top of the Vitess MySQL sharding open source project, which was originally released by YouTube in 2012. The PlanetScale founders were the co-creators and maintainers of Vitess.
Today PlanetScale are announcing a private preview of their new horizontally sharded PostgreSQL solution, due to "overwhelming" demand.
Notably, it doesn't use Vitess under the hood:
Vitess is one of PlanetScale’s greatest strengths [...] We have made explicit sharding accessible to hundreds of thousands of users and it is time to bring this power to Postgres. We will not however be using Vitess to do this.
Vitess’ achievements are enabled by leveraging MySQL’s strengths and engineering around its weaknesses. To achieve Vitess’ power for Postgres we are architecting from first principles.
Meanwhile, on June 10th Supabase announced that they had hired Vitess co-creator Sugu Sougoumarane to help them build "Multigres: Vitess for Postgres". Sugu said:
For some time, I've been considering a Vitess adaptation for Postgres, and this feeling had been gradually intensifying. The recent explosion in the popularity of Postgres has fueled this into a full-blown obsession. [...]
The project to address this problem must begin now, and I'm convinced that Vitess provides the most promising foundation.
I remember when MySQL was an order of magnitude more popular than PostgreSQL, and Heroku's decision to only offer PostgreSQL back in 2007 was a surprising move. The vibes have certainly shifted.
GitHub Issues search now supports nested queries and boolean operators: Here’s how we (re)built it. GitHub Issues got a significant search upgrade back in January. Deborah Digges provides some behind the scene details about how it works and how they rolled it out.
The signature new feature is complex boolean logic: you can now search for things like is:issue state:open author:rileybroughten (type:Bug OR type:Epic), up to five levels of nesting deep.
Queries are parsed into an AST using the Ruby parslet PEG grammar library. The AST is then compiled into a nested Elasticsearch bool JSON query.
GitHub Issues search deals with around 2,000 queries a second so robust testing is extremely important! The team rolled it out invisibly to 1% of live traffic, running the new implementation via a queue and competing the number of results returned to try and spot any degradations compared to the old production code.
Building, launching, and scaling ChatGPT Images (via) Gergely Orosz landed a fantastic deep dive interview with OpenAI's Sulman Choudhry (head of engineering, ChatGPT) and Srinivas Narayanan (VP of engineering, OpenAI) to talk about the launch back in March of ChatGPT images - their new image generation mode built on top of multi-modal GPT-4o.
The feature kept on having new viral spikes, including one that added one million new users in a single hour. They signed up 100 million new users in the first week after the feature's launch.
When this vertical growth spike started, most of our engineering teams didn't believe it. They assumed there must be something wrong with the metrics.
Under the hood the infrastructure is mostly Python and FastAPI! I hope they're sponsoring those projects (and Starlette, which is used by FastAPI under the hood.)
They're also using some C, and Temporal as a workflow engine. They addressed the early scaling challenge by adding an asynchronous queue to defer the load for their free users (resulting in longer generation times) at peak demand.
There are plenty more details tucked away behind the firewall, including an exclusive I've not been able to find anywhere else: OpenAI's core engineering principles.
- Ship relentlessly - move quickly and continuously improve, without waiting for perfect conditions
- Own the outcome - take full responsibility for products, end-to-end
- Follow through - finish what is started and ensure the work lands fully
I tried getting o4-mini-high to track down a copy of those principles online and was delighted to see it either leak or hallucinate the URL to OpenAI's internal engineering handbook!
Gergely has a whole series of posts like this called Real World Engineering Challenges, including another one on ChatGPT a year ago.
Merklemap runs a 16TB PostgreSQL. Interesting thread on Hacker News where Pierre Barre describes the database architecture behind Merklemap, a certificate transparency search engine.
I run a 100 billion+ rows Postgres database [0], that is around 16TB, it's pretty painless!
There are a few tricks that make it run well (PostgreSQL compiled with a non-standard block size, ZFS, careful VACUUM planning). But nothing too out of the ordinary.
ATM, I insert about 150,000 rows a second, run 40,000 transactions a second, and read 4 million rows a second.
[...]
It's self-hosted on bare metal, with standby replication, normal settings, nothing "weird" there.
6 NVMe drives in raidz-1, 1024GB of memory, a 96 core AMD EPYC cpu.
[...]
About 28K euros of hardware per replica [one-time cost] IIRC + [ongoing] colo costs.
2024
[On Reddit] we had to look up every single comment on the page to see if you had voted on it [...]
But with a bloom filter, we could very quickly look up all the comments and get back a list of all the ones you voted on (with a couple of false positives in there). Then we could go to the cache and see if your actual vote was there (and if it was an upvote or a downvote). It was only after a failed cache hit did we have to actually go to the database.
But that bloom filter saved us from doing sometimes 1000s of cache lookups.
DSQL Vignette: Reads and Compute. Marc Brooker is one of the engineers behind AWS's new Aurora DSQL horizontally scalable database. Here he shares all sorts of interesting details about how it works under the hood.
The system is built around the principle of separating storage from compute: storage uses S3, while compute runs in Firecracker:
Each transaction inside DSQL runs in a customized Postgres engine inside a Firecracker MicroVM, dedicated to your database. When you connect to DSQL, we make sure there are enough of these MicroVMs to serve your load, and scale up dynamically if needed. We add MicroVMs in the AZs and regions your connections are coming from, keeping your SQL query processor engine as close to your client as possible to optimize for latency.
We opted to use PostgreSQL here because of its pedigree, modularity, extensibility, and performance. We’re not using any of the storage or transaction processing parts of PostgreSQL, but are using the SQL engine, an adapted version of the planner and optimizer, and the client protocol implementation.
The system then provides strong repeatable-read transaction isolation using MVCC and EC2's high precision clocks, enabling reads "as of time X" including against nearby read replicas.
The storage layer supports index scans, which means the compute layer can push down some operations allowing it to load a subset of the rows it needs, reducing round-trips that are affected by speed-of-light latency.
The overall approach here is disaggregation: we’ve taken each of the critical components of an OLTP database and made it a dedicated service. Each of those services is independently horizontally scalable, most of them are shared-nothing, and each can make the design choices that is most optimal in its domain.
Most people don’t have an intuition about what current hardware can and can’t do. There is a simple math that can help you with that: “you can process about 500MB in one second on a single machine”. I know it’s not a universal truth and there are a lot of details that can change that but believe me, this estimation is a pretty good tool to have under your belt.
Amazon S3 adds new functionality for conditional writes (via)
Amazon S3 can now perform conditional writes that evaluate if an object is unmodified before updating it. This helps you coordinate simultaneous writes to the same object and prevents multiple concurrent writers from unintentionally overwriting the object without knowing the state of its content. You can use this capability by providing the ETag of an object [...]
This new conditional header can help improve the efficiency of your large-scale analytics, distributed machine learning, and other highly parallelized workloads by reliably offloading compare and swap operations to S3.
(Both Azure Blob Storage and Google Cloud have this feature already.)
When AWS added conditional write support just for if an object with that key exists or not back in August I wrote about Gunnar Morling's trick for Leader Election With S3 Conditional Writes. This new capability opens up a whole set of new patterns for implementing distributed locking systems along those lines.
Here's a useful illustrative example by lxgr on Hacker News:
As a (horribly inefficient, in case of non-trivial write contention) toy example, you could use S3 as a lock-free concurrent SQLite storage backend: Reads work as expected by fetching the entire database and satisfying the operation locally; writes work like this:
- Download the current database copy
- Perform your write locally
- Upload it back using "Put-If-Match" and the pre-edit copy as the matched object.
- If you get success, consider the transaction successful.
- If you get failure, go back to step 1 and try again.
AWS also just added the ability to enforce conditional writes in bucket policies:
To enforce conditional write operations, you can now use s3:if-none-match or s3:if-match condition keys to write a bucket policy that mandates the use of HTTP if-none-match or HTTP if-match conditional headers in S3 PutObject and CompleteMultipartUpload API requests. With this bucket policy in place, any attempt to write an object to your bucket without the required conditional header will be rejected.
Amazon S3 Express One Zone now supports the ability to append data to an object. This is a first for Amazon S3: it is now possible to append data to an existing object in a bucket, where previously the only supported operation was to atomically replace the object with an updated version.
This is only available for S3 Express One Zone, a bucket class introduced a year ago which provides storage in just a single availability zone, providing significantly lower latency at the cost of reduced redundancy and a much higher price (16c/GB/month compared to 2.3c for S3 standard tier).
The fact that appends have never been supported for multi-availability zone S3 provides an interesting clue as to the underlying architecture. Guaranteeing that every copy of an object has received and applied an append is significantly harder than doing a distributed atomic swap to a new version.
More details from the documentation:
There is no minimum size requirement for the data you can append to an object. However, the maximum size of the data that you can append to an object in a single request is 5GB. This is the same limit as the largest request size when uploading data using any Amazon S3 API.
With each successful append operation, you create a part of the object and each object can have up to 10,000 parts. This means you can append data to an object up to 10,000 times. If an object is created using S3 multipart upload, each uploaded part is counted towards the total maximum of 10,000 parts. For example, you can append up to 9,000 times to an object created by multipart upload comprising of 1,000 parts.
That 10,000 limit means this won't quite work for constantly appending to a log file in a bucket.
Presumably it will be possible to "tail" an object that is receiving appended updates using the HTTP Range header.
Using Rust in non-Rust servers to improve performance (via) Deep dive into different strategies for optimizing part of a web server application - in this case written in Node.js, but the same strategies should work for Python as well - by integrating with Rust in different ways.
The example app renders QR codes, initially using the pure JavaScript qrcode package. That ran at 1,464 req/sec, but switching it to calling a tiny Rust CLI wrapper around the qrcode crate using Node.js spawn() increased that to 2,572 req/sec.
This is yet another reminder to me that I need to get over my cgi-bin era bias that says that shelling out to another process during a web request is a bad idea. It turns out modern computers can quite happily spawn and terminate 2,500+ processes a second!
The article optimizes further first through a Rust library compiled to WebAssembly (2,978 req/sec) and then through a Rust function exposed to Node.js as a native library (5,490 req/sec), then finishes with a full Rust rewrite of the server that replaces Node.js entirely, running at 7,212 req/sec.
Full source code to accompany the article is available in the using-rust-in-non-rust-servers repository.
Supercharge the One Person Framework with SQLite: Rails World 2024 (via) Stephen Margheim shares an annotated transcript of the YouTube video of his recent talk at this year's Rails World conference in Toronto.
The Rails community is leaning hard into SQLite right now. Stephen's talk is some of the most effective evangelism I've seen anywhere for SQLite as a production database for web applications, highlighting several new changes in Rails 8:
... there are two additions coming with Rails 8 that merit closer consideration. Because these changes make Rails 8 the first version of Rails (and, as far as I know, the first version of any web framework) that provides a fully production-ready SQLite experience out-of-the-box.
Those changes: Ensure SQLite transaction default to IMMEDIATE mode to avoid "database is locked" errors when a deferred transaction attempts to upgrade itself with a write lock (discussed here previously, and added to Datasette 1.0a14 in August) and SQLite non-GVL-blocking, fair retry interval busy handler - a lower-level change that ensures SQLite's busy handler doesn't hold Ruby's Global VM Lock (the Ruby version of Python's GIL) while a thread is waiting on a SQLite lock.
The rest of the talk makes a passionate and convincing case for SQLite as an option for production deployments, in line with the Rails goal of being a One Person Framework - "a toolkit so powerful that it allows a single individual to create modern applications upon which they might build a competitive business".

Back in April Stephen published SQLite on Rails: The how and why of optimal performance describing some of these challenges in more detail (including the best explanation I've seen anywhere of BEGIN IMMEDIATE TRANSACTION) and promising:
Unfortunately, running SQLite on Rails out-of-the-box isn’t viable today. But, with a bit of tweaking and fine-tuning, you can ship a very performant, resilient Rails application with SQLite. And my personal goal for Rails 8 is to make the out-of-the-box experience fully production-ready.
It looks like he achieved that goal!
Zero-latency SQLite storage in every Durable Object (via) Kenton Varda introduces the next iteration of Cloudflare's Durable Object platform, which recently upgraded from a key/value store to a full relational system based on SQLite.
For useful background on the first version of Durable Objects take a look at Cloudflare's durable multiplayer moat by Paul Butler, who digs into its popularity for building WebSocket-based realtime collaborative applications.
The new SQLite-backed Durable Objects is a fascinating piece of distributed system design, which advocates for a really interesting way to architect a large scale application.
The key idea behind Durable Objects is to colocate application logic with the data it operates on. A Durable Object comprises code that executes on the same physical host as the SQLite database that it uses, resulting in blazingly fast read and write performance.
How could this work at scale?
A single object is inherently limited in throughput since it runs on a single thread of a single machine. To handle more traffic, you create more objects. This is easiest when different objects can handle different logical units of state (like different documents, different users, or different "shards" of a database), where each unit of state has low enough traffic to be handled by a single object
Kenton presents the example of a flight booking system, where each flight can map to a dedicated Durable Object with its own SQLite database - thousands of fresh databases per airline per day.
Each DO has a unique name, and Cloudflare's network then handles routing requests to that object wherever it might live on their global network.
The technical details are fascinating. Inspired by Litestream, each DO constantly streams a sequence of WAL entries to object storage - batched every 16MB or every ten seconds. This also enables point-in-time recovery for up to 30 days through replaying those logged transactions.
To ensure durability within that ten second window, writes are also forwarded to five replicas in separate nearby data centers as soon as they commit, and the write is only acknowledged once three of them have confirmed it.
The JavaScript API design is interesting too: it's blocking rather than async, because the whole point of the design is to provide fast single threaded persistence operations:
let docs = sql.exec(`
SELECT title, authorId FROM documents
ORDER BY lastModified DESC
LIMIT 100
`).toArray();
for (let doc of docs) {
doc.authorName = sql.exec(
"SELECT name FROM users WHERE id = ?",
doc.authorId).one().name;
}This one of their examples deliberately exhibits the N+1 query pattern, because that's something SQLite is uniquely well suited to handling.
The system underlying Durable Objects is called Storage Relay Service, and it's been powering Cloudflare's existing-but-different D1 SQLite system for over a year.
I was curious as to where the objects are created. According to this (via Hacker News):
Durable Objects do not currently change locations after they are created. By default, a Durable Object is instantiated in a data center close to where the initial
get()request is made. [...] To manually create Durable Objects in another location, provide an optionallocationHintparameter toget().
And in a footnote:
Dynamic relocation of existing Durable Objects is planned for the future.
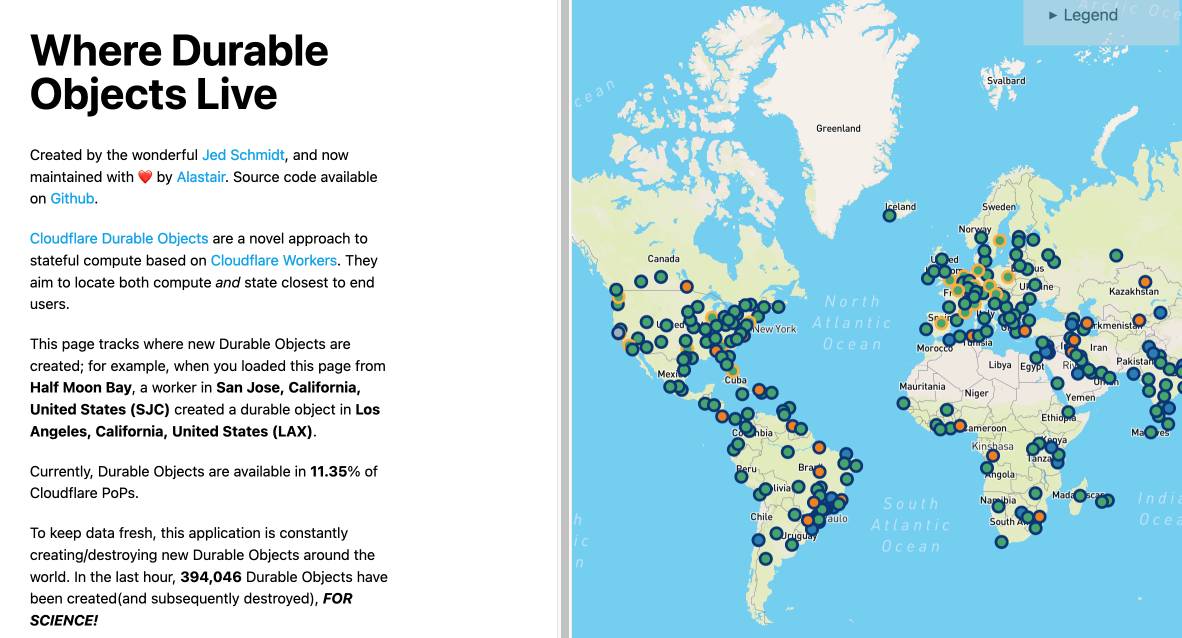
where.durableobjects.live is a neat site that tracks where in the Cloudflare network DOs are created - I just visited it and it said:
This page tracks where new Durable Objects are created; for example, when you loaded this page from Half Moon Bay, a worker in San Jose, California, United States (SJC) created a durable object in San Jose, California, United States (SJC).
Serving a billion web requests with boring code (via) Bill Mill provides a deep retrospective from his work helping build a relaunch of the medicare.gov/plan-compare site.
It's a fascinating case study of the choose boring technology mantra put into action. The "boring" choices here were PostgreSQL, Go and React, all three of which are so widely used and understood at this point that you're very unlikely to stumble into surprises with them.
Key goals for the site were accessibility, in terms of users, devices and performance. Despite best efforts:
The result fell prey after a few years to a common failure mode of react apps, and became quite heavy and loaded somewhat slowly.
I've seen this pattern myself many times over, and I'd love to understand why. React itself isn't a particularly large dependency but somehow it always seems to lead to architectural bloat over time. Maybe that's more of an SPA thing than something that's specific to React.
Loads of other interesting details in here. The ETL details - where brand new read-only RDS databases were spun up every morning after a four hour build process - are particularly notable.
[...] by default Heroku will spin up multiple dynos in different availability zones. It also has multiple routers in different zones so if one zone should go completely offline, having a second dyno will mean that your app can still serve traffic.
How Figma’s databases team lived to tell the scale (via) The best kind of scaling war story:
"Figma’s database stack has grown almost 100x since 2020. [...] In 2020, we were running a single Postgres database hosted on AWS’s largest physical instance, and by the end of 2022, we had built out a distributed architecture with caching, read replicas, and a dozen vertically partitioned databases."
I like the concept of "colos", their internal name for sharded groups of related tables arranged such that those tables can be queried using joins.
Also smart: separating the migration into "logical sharding" - where queries all still run against a single database, even though they are logically routed as if the database was already sharded - followed by "physical sharding" where the data is actually copied to and served from the new database servers.
Logical sharding was implemented using PostgreSQL views, which can accept both reads and writes:
CREATE VIEW table_shard1 AS SELECT * FROM table
WHERE hash(shard_key) >= min_shard_range AND hash(shard_key) < max_shard_range)
The final piece of the puzzle was DBProxy, a custom PostgreSQL query proxy written in Go that can parse the query to an AST and use that to decide which shard the query should be sent to. Impressively it also has a scatter-gather mechanism, so select * from table can be sent to all shards at once and the results combined back together again.
The power of two random choices, visualized. Grant Slatton shares a visualization illustrating “a favorite load balancing technique at AWS”: pick two nodes at random and then send the task to whichever of those two has the lowest current load score.
Why just two nodes? “The function grows logarithmically, so it’s a big jump from 1 to 2 and then tapers off *real* quick.”
2023
Database “sharding” came from UO? (via) Raph Koster coined the term “shard” back in 1996 in a design document proposing a way of scaling Ultima Online: “[...] we realized we would need to run multiple whole copies of Ultima Online for users to connect to, we needed to come up with a fiction for it. [...] the evil wizard Mondain had attempted to gain control over Sosaria by trapping its essence in a crystal. When the Stranger at the end of Ultima I defeated Mondain and shattered the crystal, the crystal shards each held a refracted copy of Sosaria.”
How Discord Stores Trillions of Messages (via) This is a really interesting case-study. Discord migrated from MongoDB to Cassandra back in 2016 to handle billions of messages. Today they're handling trillions, and they completed a migration from Cassandra to Scylla, a Cassandra-like data store written in C++ (as opposed to Cassandra's Java) to help avoid problems like GC pauses. In addition to being a really good scaling war story this has some interesting details about their increased usage of Rust. As a fan of request coalescing (which I've previously referred to as dogpile prevention) I particularly liked this bit:
Our data services sit between the API and our ScyllaDB clusters. They contain roughly one gRPC endpoint per database query and intentionally contain no business logic. The big feature our data services provide is request coalescing. If multiple users are requesting the same row at the same time, we’ll only query the database once. The first user that makes a request causes a worker task to spin up in the service. Subsequent requests will check for the existence of that task and subscribe to it. That worker task will query the database and return the row to all subscribers.
2022
Scaling Mastodon: The Compendium (via) Hazel Weakly’s collection of notes on scaling Mastodon, covering PostgreSQL, Sidekiq, Redis, object storage and more.
2021
Transactionally Staged Job Drains in Postgres. Any time I see people argue that relational databases shouldn’t be used to implement job queues I think of this post by Brandur from 2017. If you write to a queue before committing a transaction you run the risk of a queue consumer trying to read from the database before the new row becomes visible. If you write to the queue after the transaction there’s a risk an error might result in your message never being written. So: write to a relational staging table as part of the transaction, then have a separate process read from that table and write to the queue.
Centrifuge: a reliable system for delivering billions of events per day (via) From 2018, a write-up from Segment explaining how they solved the problem of delivering webhooks from thousands of different producers to hundreds of potentially unreliable endpoints. They started with Kafka and ended up on a custom system written in Go against RDS MySQL that was specifically tuned to their write-heavy requirements.
How Discord Stores Billions of Messages (via) Fascinating article from 2017 describing how Discord migrated their primary message store to Cassandra (from MongoDB, but I could easily see them making the same decision if they had started with PostgreSQL or MySQL).
The trick with scalable NoSQL databases like Cassandra is that you need to have a very deep understanding of the kinds of queries you will need to answer - and Discord had exactly that.
In the article they talk about their desire to eventually migrate to Scylla (a compatible Cassandra alternative written in C++) - in the Hacker News comments they confirm that in 2021 they are using Scylla for a few things but they still have their core messages in Cassandra.
Notes on streaming large API responses
I started a Twitter conversation last week about API endpoints that stream large amounts of data as an alternative to APIs that return 100 results at a time and require clients to paginate through all of the pages in order to retrieve all of the data:
[... 1,692 words]Multi-region PostgreSQL on Fly (via) Really interesting piece of architectural design from Fly here. Fly can run your application (as a Docker container run using Firecracker) in multiple regions around the world, and they’ve now quietly added PostgreSQL multi-region support. The way it works is that all-but-one region can have a read-only replica, and requests sent to application servers can perform read-only queries against their local region’s replica. If a request needs to execute a SQL update your application code can return a “fly-replay: region=scl” HTTP header and the Fly CDN will transparently replay the request against the region containing the leader database. This also means you can implement tricks like setting a 10s expiring cookie every time the user performs a write, such that their requests in the next 10s will go straight to the leader and avoid them experiencing any replication lag that hasn’t caught up with their latest update.
Why I Built Litestream. Litestream is a really exciting new piece of technology by Ben Johnson, who previously built BoltDB, the key-value store written in Go that is used by etcd. It adds replication to SQLite by running a process that converts the SQLite WAL log into a stream that can be saved to another folder or pushed to S3. The S3 option is particularly exciting—Ben estimates that keeping a full point-in-time recovery log of a high write SQLite database should cost in the order of a few dollars a month. I think this could greatly expand the set of use-cases for which SQLite is sensible choice.