29 posts tagged “nosql”
2025
Using S3 triggers to maintain a list of files in DynamoDB. I built an experimental prototype this morning of a system for efficiently tracking files that have been added to a large S3 bucket by maintaining a parallel DynamoDB table using S3 triggers and AWS lambda.
I got 80% of the way there with this single prompt (complete with typos) to my custom Claude Project:
Python CLI app using boto3 with commands for creating a new S3 bucket which it also configures to have S3 lambada event triggers which moantian a dynamodb table containing metadata about all of the files in that bucket. Include these commands
create_bucket - create a bucket and sets up the associated triggers and dynamo tableslist_files - shows me a list of files based purely on querying dynamo
ChatGPT then took me to the 95% point. The code Claude produced included an obvious bug, so I pasted the code into o3-mini-high on the basis that "reasoning" is often a great way to fix those kinds of errors:
Identify, explain and then fix any bugs in this code:code from Claude pasted here
... and aside from adding a couple of time.sleep() calls to work around timing errors with IAM policy distribution, everything worked!
Getting from a rough idea to a working proof of concept of something like this with less than 15 minutes of prompting is extraordinarily valuable.
This is exactly the kind of project I've avoided in the past because of my almost irrational intolerance of the frustration involved in figuring out the individual details of each call to S3, IAM, AWS Lambda and DynamoDB.
(Update: I just found out about the new S3 Metadata system which launched a few weeks ago and might solve this exact problem!)
2023
How Discord Stores Trillions of Messages (via) This is a really interesting case-study. Discord migrated from MongoDB to Cassandra back in 2016 to handle billions of messages. Today they're handling trillions, and they completed a migration from Cassandra to Scylla, a Cassandra-like data store written in C++ (as opposed to Cassandra's Java) to help avoid problems like GC pauses. In addition to being a really good scaling war story this has some interesting details about their increased usage of Rust. As a fan of request coalescing (which I've previously referred to as dogpile prevention) I particularly liked this bit:
Our data services sit between the API and our ScyllaDB clusters. They contain roughly one gRPC endpoint per database query and intentionally contain no business logic. The big feature our data services provide is request coalescing. If multiple users are requesting the same row at the same time, we’ll only query the database once. The first user that makes a request causes a worker task to spin up in the service. Subsequent requests will check for the existence of that task and subscribe to it. That worker task will query the database and return the row to all subscribers.
2021
How Discord Stores Billions of Messages (via) Fascinating article from 2017 describing how Discord migrated their primary message store to Cassandra (from MongoDB, but I could easily see them making the same decision if they had started with PostgreSQL or MySQL).
The trick with scalable NoSQL databases like Cassandra is that you need to have a very deep understanding of the kinds of queries you will need to answer - and Discord had exactly that.
In the article they talk about their desire to eventually migrate to Scylla (a compatible Cassandra alternative written in C++) - in the Hacker News comments they confirm that in 2021 they are using Scylla for a few things but they still have their core messages in Cassandra.
2013
NoSQL: What is the “best” solution for storing high volumes of structured data?
On the right setup, PostgreSQL can handle petabytes. There are also commercial vendors such as Greenplum that offer data warehouse solutions built on a modified version of PostgreSQL.
[... 80 words]How was FriendFeed’s schema less db faster than pure MySQL?
The principle reason they switched to a schemaless DB was to work around the challenges of having to make schemes changes in MySQL, which can lock the table and take hours if bit days to complete in large tables.
[... 115 words]How could we using couchbase with binary document as value?
There’s a system called cbfs that acts as a distributed blobstore on top of Couchbase server—https://github.com/couchbaselabs...—it looks like it is currently under active development.
[... 45 words]2012
Any source available to download sample data (in 10+ GB) for testing?
Wikipedia has some pretty interesting dumps, in both XML and SQL format: http://meta.wikimedia.org/wiki/I...
[... 100 words]NoSQL: Whats the simplest on disk key-value storage?
Surprisingly there doesn’t seem to be an obvious answer to this. Here are a few options:
[... 164 words]What is the best NoSQL database to store unstructured data?
Any of the document stores are worth a look—I’d suggest investigating MongoDB, Riak and CouchDB.
[... 33 words]NoSQL: On a shared server, what are the alternatives to using SQL?
You could probably run Redis on a shared server—it doesn’t need to be installed as root, but it does require a process to run all the time which shared hosts may not allow.
[... 138 words]Benchmarks for scalability in NoSQL systems?
NoSQL systems are enormously varied which makes it hard (and not particularly constructive) to benchmark them against each other. How would you compare the performance of Redis, an in-memory data structure server, with Cassandra, a distributed redundant column store?
[... 78 words]2011
What are the best blogs about NoSQL?
myNoSQL is excellent: http://nosql.mypopescu.com/
[... 18 words]What are the pros and cons of switching from MySQL to one of the NoSQL databases?
Pro: If your own benchmarks tell you you need to switch to a specific NoSQL solution, you’ll know exactly what the pro is.
[... 227 words]2010
What are the advantages and disadvantages of using MongoDB vs CouchDB vs Cassandra vs Redis?
I see Redis as a different category from the other three—kind of like you wouldn’t say “what are the advantages of MySQL v.s. Memcached”. Redis makes an excellent complement to pretty much any other persistent storage mechanism. I expanded on this here: http://simonwillison.net/2009/Oc...
[... 67 words]Using MySQL as a NoSQL—A story for exceeding 750,000 qps on a commodity server. Very interesting approach: much of the speed difference between MySQL/InnoDB and memcached is due to the overhead involved in parsing and processing SQL, so the team at DeNA wrote their own MySQL plugin, HandlerSocket, which exposes a NoSQL-style network protocol for directly calling the low level MySQL storage engine APIs—resulting in a 7.5x performance increase.
Will Redis support per-database persistence configuration?
I don’t know if that’s on the roadmap (you’d need to ask antirez on the mailing list or Twitter), but it should be easy enough to run multiple Redis instances with different settings—especially on a multi core machine.
[... 52 words]What is the largest production deployment of CouchDB for online use?
The BBC have a pretty big CouchDB cluster, which they use mostly as a replicated key-value store. It’s used by their new identity platform which includes customisation features for iPlayer.
[... 47 words]reddit’s May 2010 “State of the Servers” report. An interesting Cassandra war story: Cassandra scales up, but it doesn’t scale down very well: running with just three nodes can make recovery from problems a lot more tricky.
Comprehensive notes from my three hour Redis tutorial

Last week I presented two talks at the inaugural NoSQL Europe conference in London. The first was presented with Matthew Wall and covered the ways in which we have been exploring NoSQL at the Guardian. The second was a three hour workshop on Redis, my favourite piece of software to have the NoSQL label applied to it.
[... 263 words]Redis weekly update #3—Pub/Sub and more. Redis is now a publish/subscribe server—and it ended up only taking 150 lines of C code since Redis internals were already based on that paradigm.
VMware: the new Redis home. Redis creator Salvatore Sanfilippo is joining VMWare to work on Redis full time. Sounds like a good match.
Redis weekly update #1—Hashes and... many more! Hashes were the big missing data type in Redis—support is only partial at the moment (no ability to list all keys in a hash or delete a specific key) but at the rate Redis is developed I expect that to be fixed within a week or two.
A Collection Of Redis Use Cases. Lots of interesting case studies here, collated by Mathias Meyer. Redis clearly shines for anything involving statistics or high volumes of small writes.
FleetDB (via) Yet Another Key-Value Store: Schema-free, JSON protocol, everything cached in RAM, append-only log for durability, multi-record transactions... but what’s really interesting about this one is that it’s written in Clojure and takes full advantage of that language’s concurrency primitives. The prefix operators used by the select API hint at its Lisp heritage.
2009
New Redis ZINCRBY command (via) Just added to Redis, a command which increments the “score” for an item in a sorted set and reorders the set to reflect the new scores. Looks ideally suited to real time stats, and I’m sure there are plenty of other exciting uses for it.
Crowdsourced document analysis and MP expenses
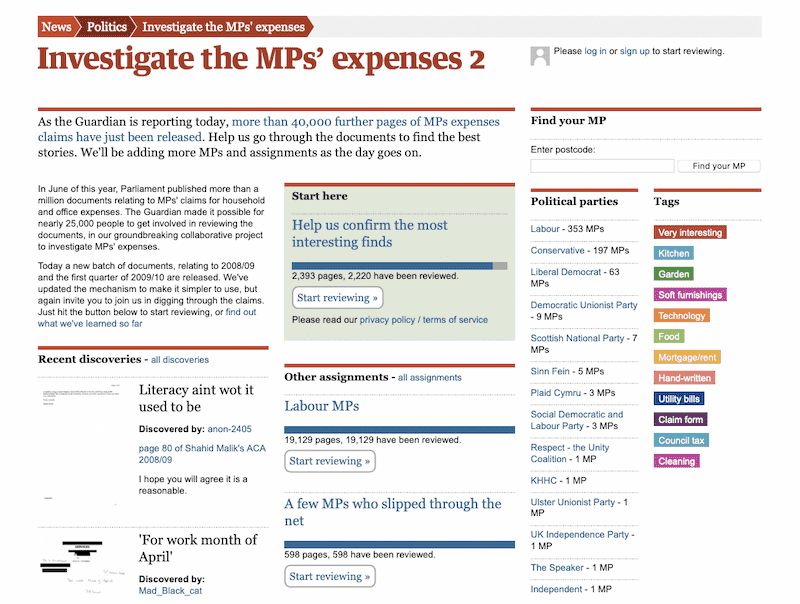
As you may have heard, the UK government released a fresh batch of MP expenses documents a week ago on Thursday. I spent that week working with a small team at Guardian HQ to prepare for the release. Here’s what we built:
[... 2,081 words]Node.js is genuinely exciting
I gave a talk on Friday at Full Frontal, a new one day JavaScript conference in my home town of Brighton. I ended up throwing away my intended topic (JSONP, APIs and cross-domain security) three days before the event in favour of a technology which first crossed my radar less than two weeks ago.
[... 2,025 words]When I worked at Amazon.com we had a deeply-ingrained hatred for all of the SQL databases in our systems. Now, we knew perfectly well how to scale them through partitioning and other means. But making them highly available was another matter. Replication and failover give you basic reliability, but it's very limited and inflexible compared to a real distributed datastore with master-master replication, partition tolerance, consensus and/or eventual consistency, or other availability-oriented features.
Looking to the future with Cassandra. Digg are now using Cassandra for their “green badge” (one of your friends have dugg this story) feature—the resulting denormalised dataset weighs in at 3 TB and 76 billion columns.