21 posts tagged “duckdb”
2025
Spatial Joins in DuckDB (via) Extremely detailed overview by Max Gabrielsson of DuckDB's new spatial join optimizations.
Consider the following query, which counts the number of NYC Citi Bike Trips for each of the neighborhoods defined by the NYC Neighborhood Tabulation Areas polygons and returns the top three:
SELECT neighborhood, count(*) AS num_rides FROM rides JOIN hoods ON ST_Intersects( rides.start_geom, hoods.geom ) GROUP BY neighborhood ORDER BY num_rides DESC LIMIT 3;
The rides table contains 58,033,724 rows. The hoods table has polygons for 310 neighborhoods.
Without an optimized spatial joins this query requires a nested loop join, executing that expensive ST_Intersects() operation 58m * 310 ~= 18 billion times. This took around 30 minutes on the 36GB MacBook M3 Pro used for the benchmark.
The first optimization described - implemented from DuckDB 1.2.0 onwards - uses a "piecewise merge join". This takes advantage of the fact that a bounding box intersection is a whole lot faster to calculate, especially if you pre-cache the bounding box (aka the minimum bounding rectangle or MBR) in the stored binary GEOMETRY representation.
Rewriting the query to use a fast bounding box intersection and then only running the more expensive ST_Intersects() filters on those matches drops the runtime from 1800 seconds to 107 seconds.
The second optimization, added in DuckDB 1.3.0 in May 2025 using the new SPATIAL_JOIN operator, is significantly more sophisticated.
DuckDB can now identify when a spatial join is working against large volumes of data and automatically build an in-memory R-Tree of bounding boxes for the larger of the two tables being joined.
This new R-Tree further accelerates the bounding box intersection part of the join, and drops the runtime down to just 30 seconds.
DuckDB is Probably the Most Important Geospatial Software of the Last Decade. Drew Breunig argues that the ease of installation of DuckDB is opening up geospatial analysis to a whole new set of developers.
This inspired a comment on Hacker News from DuckDB Labs geospatial engineer Max Gabrielsson which helps explain why the drop in friction introduced by DuckDB is so significant:
I think a big part is that duckdbs spatial extension provides a SQL interface to a whole suite of standard foss gis packages by statically bundling everything (including inlining the default PROJ database of coordinate projection systems into the binary) and providing it for multiple platforms (including WASM). I.E there are no transitive dependencies except libc.
[...] the fact that you can e.g. convert too and from a myriad of different geospatial formats by utilizing GDAL, transforming through SQL, or pulling down the latest overture dump without having the whole workflow break just cause you updated QGIS has probably been the main killer feature for a lot of the early adopters.
I've lost count of the time I've spent fiddling with dependencies like GDAL trying to get various geospatial tools to work in the past. Bundling difficult dependencies statically is an under-appreciated trick!
If the bold claim in the headline inspires you to provide a counter-example, bear in mind that a decade ago is 2015, and most of the key technologies In the modern geospatial stack - QGIS, PostGIS, geopandas, SpatiaLite - predate that by quite a bit.
Abusing DuckDB-WASM by making SQL draw 3D graphics (Sort Of) (via) Brilliant hack by Patrick Trainer who got an ASCII-art Doom clone running in the browser using convoluted SQL queries running against the WebAssembly build of DuckDB. Here’s the live demo, and the code on GitHub.

The SQL is so much fun. Here’s a snippet that implements ray tracing as part of a SQL view:
CREATE OR REPLACE VIEW render_3d_frame AS WITH RECURSIVE -- ... rays AS ( SELECT c.col, (p.dir - s.fov/2.0 + s.fov * (c.col*1.0 / (s.view_w - 1))) AS angle FROM cols c, s, p ), raytrace(col, step_count, fx, fy, angle) AS ( SELECT r.col, 1, p.x + COS(r.angle)*s.step, p.y + SIN(r.angle)*s.step, r.angle FROM rays r, p, s UNION ALL SELECT rt.col, rt.step_count + 1, rt.fx + COS(rt.angle)*s.step, rt.fy + SIN(rt.angle)*s.step, rt.angle FROM raytrace rt, s WHERE rt.step_count < s.max_steps AND NOT EXISTS ( SELECT 1 FROM map m WHERE m.x = CAST(rt.fx AS INT) AND m.y = CAST(rt.fy AS INT) AND m.tile = '#' ) ), -- ...
OpenTimes (via) Spectacular new open geospatial project by Dan Snow:
OpenTimes is a database of pre-computed, point-to-point travel times between United States Census geographies. It lets you download bulk travel time data for free and with no limits.
Here's what I get for travel times by car from El Granada, California:
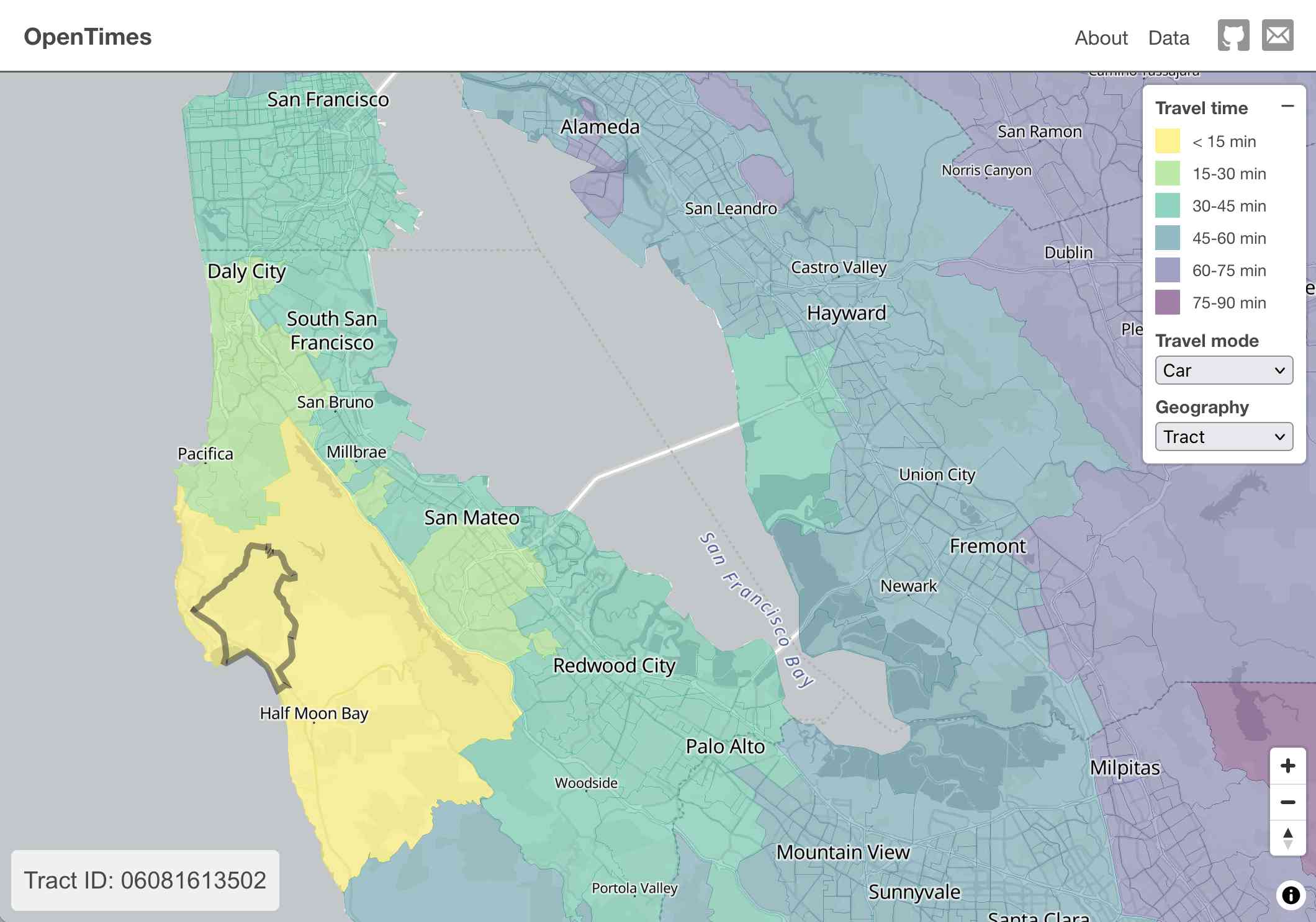
The technical details are fascinating:
- The entire OpenTimes backend is just static Parquet files on Cloudflare's R2. There's no RDBMS or running service, just files and a CDN. The whole thing costs about $10/month to host and costs nothing to serve. In my opinion, this is a great way to serve infrequently updated, large public datasets at low cost (as long as you partition the files correctly).
Sure enough, R2 pricing charges "based on the total volume of data stored" - $0.015 / GB-month for standard storage, then $0.36 / million requests for "Class B" operations which include reads. They charge nothing for outbound bandwidth.
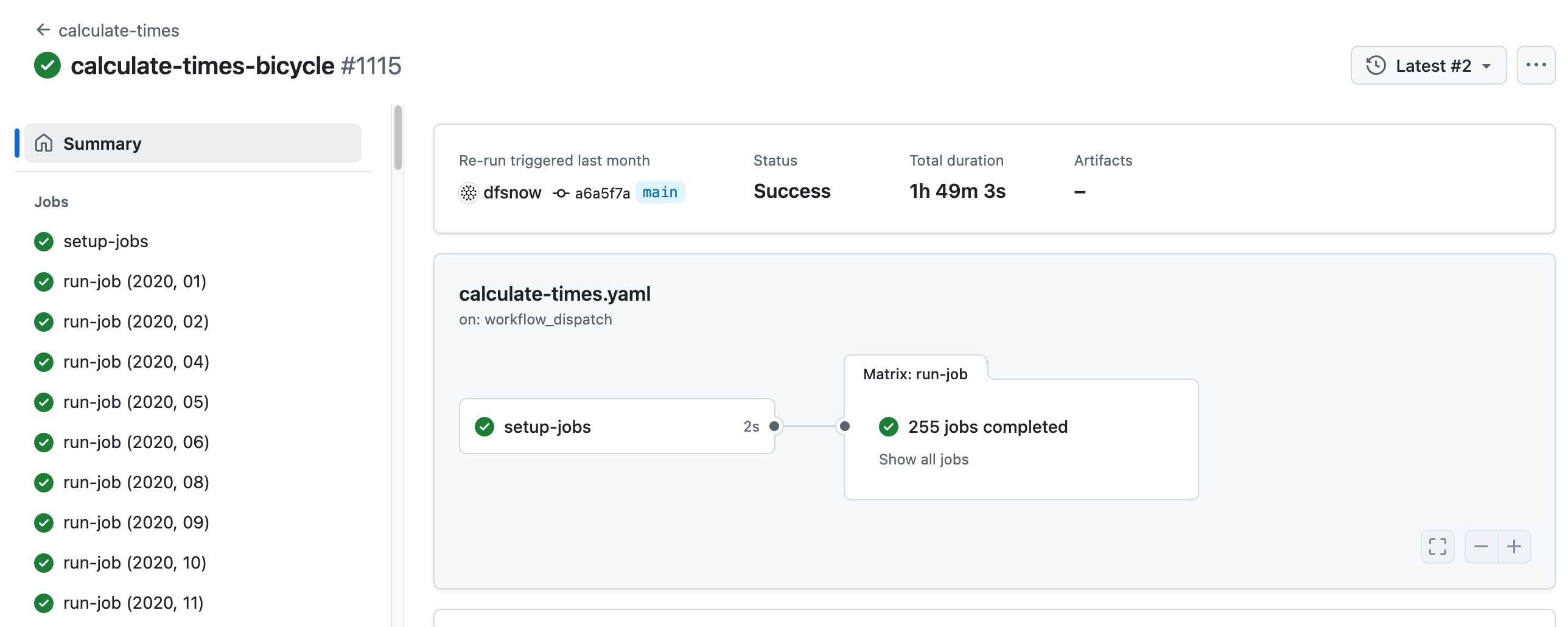
- All travel times were calculated by pre-building the inputs (OSM, OSRM networks) and then distributing the compute over hundreds of GitHub Actions jobs. This worked shockingly well for this specific workload (and was also completely free).
Here's a GitHub Actions run of the calculate-times.yaml workflow which uses a matrix to run 255 jobs!
Relevant YAML:
matrix:
year: ${{ fromJSON(needs.setup-jobs.outputs.years) }}
state: ${{ fromJSON(needs.setup-jobs.outputs.states) }}
Where those JSON files were created by the previous step, which reads in the year and state values from this params.yaml file.
- The query layer uses a single DuckDB database file with views that point to static Parquet files via HTTP. This lets you query a table with hundreds of billions of records after downloading just the ~5MB pointer file.
This is a really creative use of DuckDB's feature that lets you run queries against large data from a laptop using HTTP range queries to avoid downloading the whole thing.
The README shows how to use that from R and Python - I got this working in the duckdb client (brew install duckdb):
INSTALL httpfs;
LOAD httpfs;
ATTACH 'https://data.opentimes.org/databases/0.0.1.duckdb' AS opentimes;
SELECT origin_id, destination_id, duration_sec
FROM opentimes.public.times
WHERE version = '0.0.1'
AND mode = 'car'
AND year = '2024'
AND geography = 'tract'
AND state = '17'
AND origin_id LIKE '17031%' limit 10;
In answer to a question about adding public transit times Dan said:
In the next year or so maybe. The biggest obstacles to adding public transit are:
- Collecting all the necessary scheduling data (e.g. GTFS feeds) for every transit system in the county. Not insurmountable since there are services that do this currently.
- Finding a routing engine that can compute nation-scale travel time matrices quickly. Currently, the two fastest open-source engines I've tried (OSRM and Valhalla) don't support public transit for matrix calculations and the engines that do support public transit (R5, OpenTripPlanner, etc.) are too slow.
GTFS is a popular CSV-based format for sharing transit schedules - here's an official list of available feed directories.
This whole project feels to me like a great example of the baked data architectural pattern in action.
S1: The $6 R1 Competitor? Tim Kellogg shares his notes on a new paper, s1: Simple test-time scaling, which describes an inference-scaling model fine-tuned on top of Qwen2.5-32B-Instruct for just $6 - the cost for 26 minutes on 16 NVIDIA H100 GPUs.
Tim highlight the most exciting result:
After sifting their dataset of 56K examples down to just the best 1K, they found that the core 1K is all that's needed to achieve o1-preview performance on a 32B model.
The paper describes a technique called "Budget forcing":
To enforce a minimum, we suppress the generation of the end-of-thinking token delimiter and optionally append the string “Wait” to the model’s current reasoning trace to encourage the model to reflect on its current generation
That's the same trick Theia Vogel described a few weeks ago.
Here's the s1-32B model on Hugging Face. I found a GGUF version of it at brittlewis12/s1-32B-GGUF, which I ran using Ollama like so:
ollama run hf.co/brittlewis12/s1-32B-GGUF:Q4_0
I also found those 1,000 samples on Hugging Face in the simplescaling/s1K data repository there.
I used DuckDB to convert the parquet file to CSV (and turn one VARCHAR[] column into JSON):
COPY (
SELECT
solution,
question,
cot_type,
source_type,
metadata,
cot,
json_array(thinking_trajectories) as thinking_trajectories,
attempt
FROM 's1k-00001.parquet'
) TO 'output.csv' (HEADER, DELIMITER ',');
Then I loaded that CSV into sqlite-utils so I could use the convert command to turn a Python data structure into JSON using json.dumps() and eval():
# Load into SQLite
sqlite-utils insert s1k.db s1k output.csv --csv
# Fix that column
sqlite-utils convert s1k.db s1u metadata 'json.dumps(eval(value))' --import json
# Dump that back out to CSV
sqlite-utils rows s1k.db s1k --csv > s1k.csv
Here's that CSV in a Gist, which means I can load it into Datasette Lite.
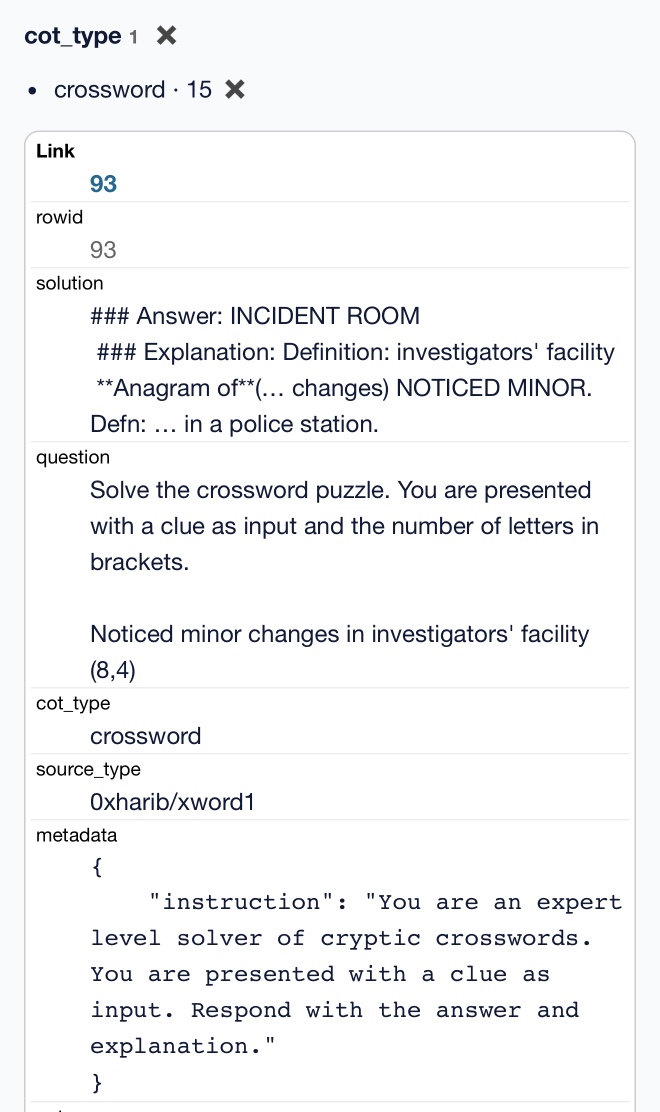
It really is a tiny amount of training data. It's mostly math and science, but there are also 15 cryptic crossword examples.
2024
Turning Your Root URL Into a DuckDB Remote Database. Fun idea from Drew Breunig: DuckDB supports attaching existing databases that are accessible over HTTP using their URL. Drew suggests creating vanity URLs using your root domain, detecting the DuckDB user-agent and serving the database file directly - allowing tricks like this one:
ATTACH 'https://steplist.app/' AS steplist;
SELECT * FROM steplist.lists;
Foursquare Open Source Places: A new foundational dataset for the geospatial community (via) I did not expect this!
[...] we are announcing today the general availability of a foundational open data set, Foursquare Open Source Places ("FSQ OS Places"). This base layer of 100mm+ global places of interest ("POI") includes 22 core attributes (see schema here) that will be updated monthly and available for commercial use under the Apache 2.0 license framework.
The data is available as Parquet files hosted on Amazon S3.
Here's how to list the available files:
aws s3 ls s3://fsq-os-places-us-east-1/release/dt=2024-11-19/places/parquet/
I got back places-00000.snappy.parquet through places-00024.snappy.parquet, each file around 455MB for a total of 10.6GB of data.
I ran duckdb and then used DuckDB's ability to remotely query Parquet on S3 to explore the data a bit more without downloading it to my laptop first:
select count(*) from 's3://fsq-os-places-us-east-1/release/dt=2024-11-19/places/parquet/places-00000.snappy.parquet';
This got back 4,180,424 - that number is similar for each file, suggesting around 104,000,000 records total.
Update: DuckDB can use wildcards in S3 paths (thanks, Paul) so this query provides an exact count:
select count(*) from 's3://fsq-os-places-us-east-1/release/dt=2024-11-19/places/parquet/places-*.snappy.parquet';
That returned 104,511,073 - and Activity Monitor on my Mac confirmed that DuckDB only needed to fetch 1.2MB of data to answer that query.
I ran this query to retrieve 1,000 places from that first file as newline-delimited JSON:
copy (
select * from 's3://fsq-os-places-us-east-1/release/dt=2024-11-19/places/parquet/places-00000.snappy.parquet'
limit 1000
) to '/tmp/places.json';
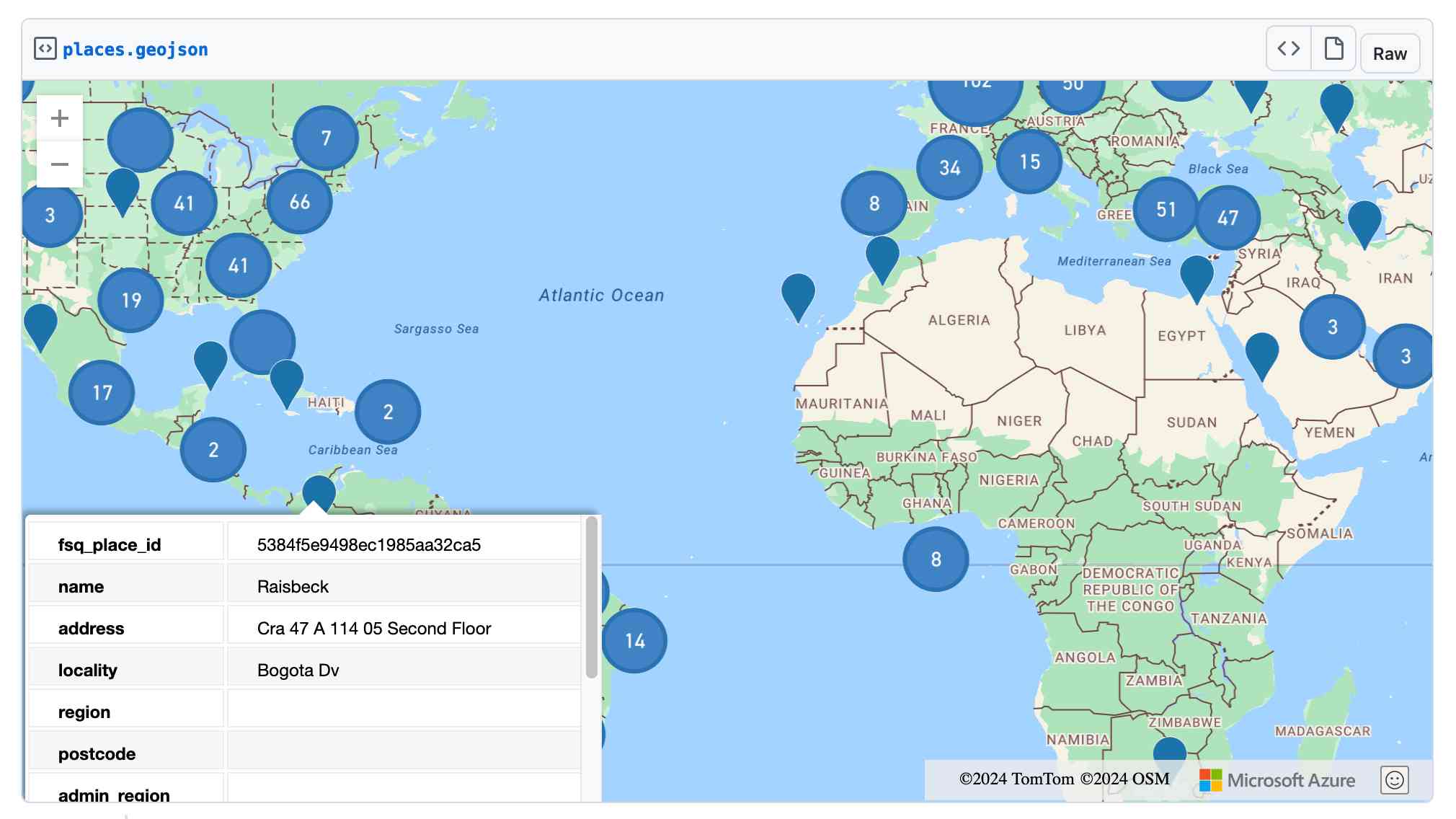
Here's that places.json file, and here it is imported into Datasette Lite.
Finally, I got ChatGPT Code Interpreter to convert that file to GeoJSON and pasted the result into this Gist, giving me a map of those thousand places (because Gists automatically render GeoJSON):
Wikidata is a Giant Crosswalk File.
Drew Breunig shows how to take the 140GB Wikidata JSON export, use sed 's/,$//' to convert it to newline-delimited JSON, then use DuckDB to run queries and extract external identifiers, including a query that pulls out 500MB of latitude and longitude points.
Conflating Overture Places Using DuckDB, Ollama, Embeddings, and More.
Drew Breunig's detailed tutorial on "conflation" - combining different geospatial data sources by de-duplicating address strings such as RESTAURANT LOS ARCOS,3359 FOOTHILL BLVD,OAKLAND,94601 and LOS ARCOS TAQUERIA,3359 FOOTHILL BLVD,OAKLAND,94601.
Drew uses an entirely offline stack based around Python, DuckDB and Ollama and finds that a combination of H3 geospatial tiles and mxbai-embed-large embeddings (though other embedding models should work equally well) gets really good results.
An example running DuckDB in ChatGPT Code Interpreter
(via)
I confirmed today that DuckDB can indeed be run inside ChatGPT Code Interpreter (aka "data analysis"), provided you upload the correct wheel file for it to install. The wheel file it needs is currently duckdb-1.0.0-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl from the PyPI releases page - I asked ChatGPT to identify its platform, and it said that it needs manylinux2014_x86_64.whl wheels.
Once the wheel in installed ChatGPT already knows enough of the DuckDB API to start performing useful operations with it - and any brand new features in 1.0 will work if you tell it how to use them.
Using DuckDB for Embeddings and Vector Search (via) Sören Brunk's comprehensive tutorial combining DuckDB 1.0, a subset of German Wikipedia from Hugging Face (loaded using Parquet), the BGE M3 embedding model and DuckDB's new vss extension for implementing an HNSW vector index.
DuckDB 1.0 (via) Six years in the making. The most significant feature in this milestone is stability of the file format: previous releases often required files to be upgraded to work with the new version.
This release also aspires to provide stability for both the SQL dialect and the C API, though these may still change with sufficient warning in the future.
DuckDB as the New jq (via) The DuckDB CLI tool can query JSON files directly, making it a surprisingly effective replacement for jq. Paul Gross demonstrates the following query:
select license->>'key' as license, count(*) from 'repos.json' group by 1
repos.json contains an array of {"license": {"key": "apache-2.0"}..} objects. This example query shows counts for each of those licenses.
Announcing DuckDB 0.10.0.
Somewhat buried in this announcement: DuckDB has Fixed-Length Arrays now, along with array_cross_product(a1, a2), array_cosine_similarity(a1, a2) and array_inner_product(a1, a2) functions.
This means you can now use DuckDB to find related content (and other tricks) using vector embeddings!
Also notable:
DuckDB can now attach MySQL, Postgres, and SQLite databases in addition to databases stored in its own format. This allows data to be read into DuckDB and moved between these systems in a convenient manner, as attached databases are fully functional, appear just as regular tables, and can be updated in a safe, transactional manner.
Fastest Way to Read Excel in Python (via) Haki Benita produced a meticulously researched and written exploration of the options for reading a large Excel spreadsheet into Python. He explored Pandas, Tablib, Openpyxl, shelling out to LibreOffice, DuckDB and python-calamine (a Python wrapper of a Rust library). Calamine was the winner, taking 3.58s to read 500,00 rows—compared to Pandas in last place at 32.98s.
2023
Online gradient descent written in SQL (via) Max Halford trains an online gradient descent model against two years of AAPL stock data using just a single advanced SQL query. He built this against DuckDB—I tried to replicate his query in SQLite and it almost worked, but it gave me a “recursive reference in a subquery” error that I was unable to resolve.
2022
Querying Postgres Tables Directly From DuckDB (via) I learned a lot of interesting PostgreSQL tricks from this write-up of the new DuckDB feature that allows it to run queries against PostgreSQL servers directly. It works using COPY (SELECT ...) TO STDOUT (FORMAT binary) which writes rows to the protocol stream in efficient binary format, but splits the table being read into parallel fetches against page ranges and uses SET TRANSACTION SNAPSHOT ... in those parallel queries to ensure they see the same transactional snapshot of the database.
Notes on the SQLite DuckDB paper
SQLite: Past, Present, and Future is a newly published paper authored by Kevin P. Gaffney, Martin Prammer and Jignesh M. Patel from the University of Wisconsin-Madison and D. Richard Hipp, Larry Brasfield and Dan Kennedy from the core SQLite engineering team.
[... 1,021 words]2021
DuckDB-Wasm: Efficient Analytical SQL in the Browser (via) First SQLite, now DuckDB: options for running database engines in the browser using WebAssembly keep on growing. DuckDB means browsers now have a fast, intuitive mechanism for querying Parquet files too. This also supports the same HTTP Range header trick as the SQLite demo from a while back, meaning it can query large databases loaded over HTTP without downloading the whole file.
Querying Parquet using DuckDB (via) DuckDB is a relatively new SQLite-style database (released as an embeddable library) with a focus on analytical queries. This tutorial really made the benefits click for me: it ships with support for the Parquet columnar data format, and you can use it to execute SQL queries directly against Parquet files—e.g. “SELECT COUNT(*) FROM ’taxi_2019_04.parquet’”. Performance against large files is fantastic, and the whole thing can be installed just using “pip install duckdb”. I wonder if faceting-style group/count queries (pretty expensive with regular RDBMSs) could be sped up with this?
2020
DuckDB (via) This is a really interesting, relatively new database. It’s kind of a weird hybrid between SQLite and PostgreSQL: it uses the PostgreSQL parser but models itself after SQLite in that databases are a single file and the code is designed for use as an embedded library, distributed in a single amalgamation C++ file (SQLite uses a C amalgamation). It features a “columnar-vectorized query execution engine” inspired by MonetDB (also by the DuckDB authors) and is hence designed to run analytical queries really quickly. You can install it using “pip install duckdb”—the resulting module feels similar to Python’s sqlite3, and follows roughly the same DBAPI pattern.