Wednesday, 20th November 2024
Bluesky WebSocket Firehose. Very quick (10 seconds of Claude hacking) prototype of a web page that attaches to the public Bluesky WebSocket firehose and displays the results directly in your browser.
Here's the code - there's very little to it, it's basically opening a connection to wss://jetstream2.us-east.bsky.network/subscribe?wantedCollections=app.bsky.feed.post and logging out the results to a <textarea readonly> element.

Bluesky's Jetstream isn't their main atproto firehose - that's a more complicated protocol involving CBOR data and CAR files. Jetstream is a new Go proxy (source code here) that provides a subset of that firehose over WebSocket.
Jetstream was built by Bluesky developer Jaz, initially as a side-project, in response to the surge of traffic they received back in September when Brazil banned Twitter. See Jetstream: Shrinking the AT Proto Firehose by >99% for their description of the project when it first launched.
The API scene growing around Bluesky is really exciting right now. Twitter's API is so expensive it may as well not exist, and Mastodon's community have pushed back against many potential uses of the Mastodon API as incompatible with that community's value system.
Hacking on Bluesky feels reminiscent of the massive diversity of innovation we saw around Twitter back in the late 2000s and early 2010s.
Here's a much more fun Bluesky demo by Theo Sanderson: firehose3d.theo.io (source code here) which displays the firehose from that same WebSocket endpoint in the style of a Windows XP screensaver.
Foursquare Open Source Places: A new foundational dataset for the geospatial community (via) I did not expect this!
[...] we are announcing today the general availability of a foundational open data set, Foursquare Open Source Places ("FSQ OS Places"). This base layer of 100mm+ global places of interest ("POI") includes 22 core attributes (see schema here) that will be updated monthly and available for commercial use under the Apache 2.0 license framework.
The data is available as Parquet files hosted on Amazon S3.
Here's how to list the available files:
aws s3 ls s3://fsq-os-places-us-east-1/release/dt=2024-11-19/places/parquet/
I got back places-00000.snappy.parquet through places-00024.snappy.parquet, each file around 455MB for a total of 10.6GB of data.
I ran duckdb and then used DuckDB's ability to remotely query Parquet on S3 to explore the data a bit more without downloading it to my laptop first:
select count(*) from 's3://fsq-os-places-us-east-1/release/dt=2024-11-19/places/parquet/places-00000.snappy.parquet';
This got back 4,180,424 - that number is similar for each file, suggesting around 104,000,000 records total.
Update: DuckDB can use wildcards in S3 paths (thanks, Paul) so this query provides an exact count:
select count(*) from 's3://fsq-os-places-us-east-1/release/dt=2024-11-19/places/parquet/places-*.snappy.parquet';
That returned 104,511,073 - and Activity Monitor on my Mac confirmed that DuckDB only needed to fetch 1.2MB of data to answer that query.
I ran this query to retrieve 1,000 places from that first file as newline-delimited JSON:
copy (
select * from 's3://fsq-os-places-us-east-1/release/dt=2024-11-19/places/parquet/places-00000.snappy.parquet'
limit 1000
) to '/tmp/places.json';
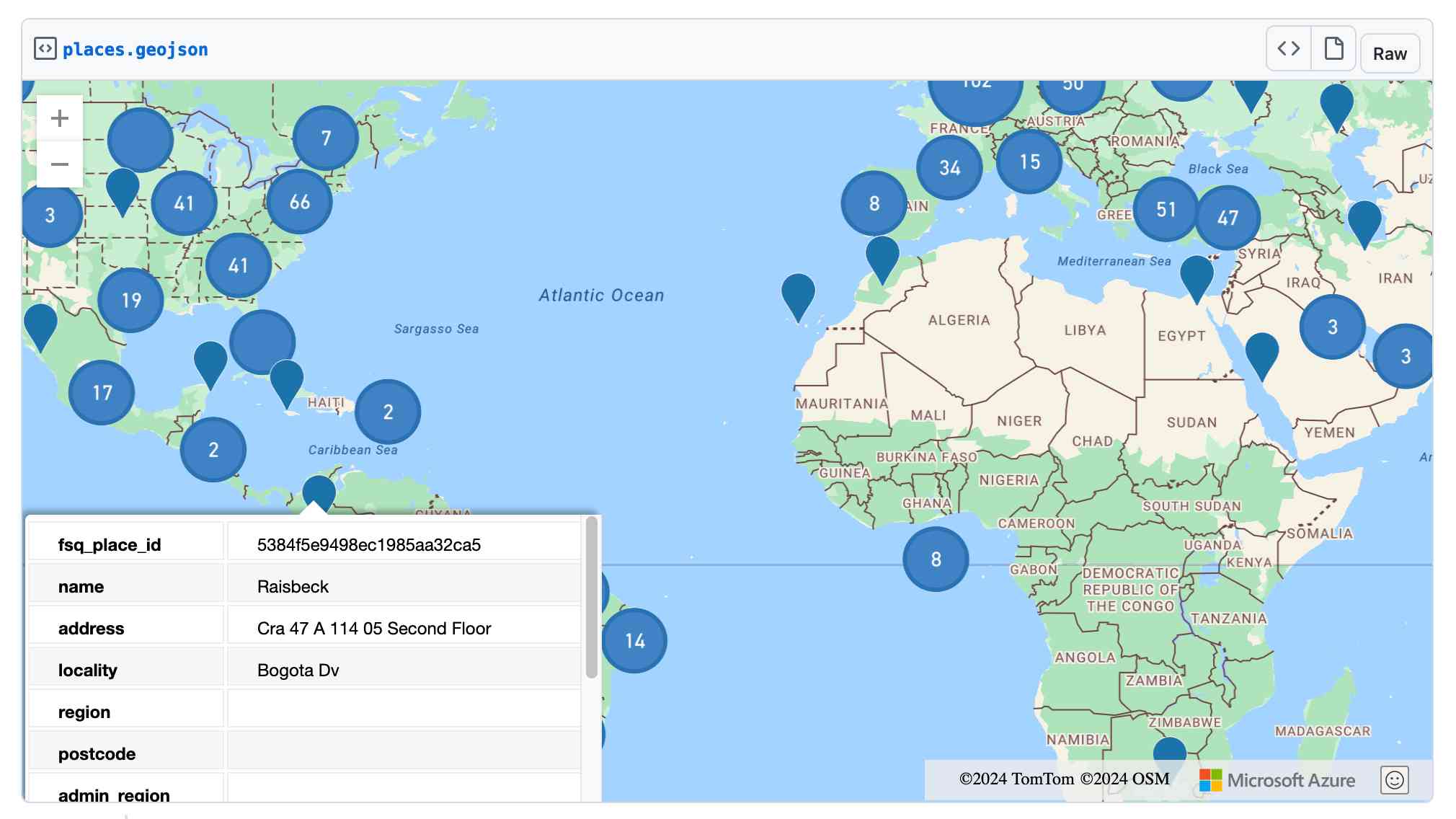
Here's that places.json file, and here it is imported into Datasette Lite.
Finally, I got ChatGPT Code Interpreter to convert that file to GeoJSON and pasted the result into this Gist, giving me a map of those thousand places (because Gists automatically render GeoJSON):