Friday, 22nd November 2024
Amazon S3 Express One Zone now supports the ability to append data to an object. This is a first for Amazon S3: it is now possible to append data to an existing object in a bucket, where previously the only supported operation was to atomically replace the object with an updated version.
This is only available for S3 Express One Zone, a bucket class introduced a year ago which provides storage in just a single availability zone, providing significantly lower latency at the cost of reduced redundancy and a much higher price (16c/GB/month compared to 2.3c for S3 standard tier).
The fact that appends have never been supported for multi-availability zone S3 provides an interesting clue as to the underlying architecture. Guaranteeing that every copy of an object has received and applied an append is significantly harder than doing a distributed atomic swap to a new version.
More details from the documentation:
There is no minimum size requirement for the data you can append to an object. However, the maximum size of the data that you can append to an object in a single request is 5GB. This is the same limit as the largest request size when uploading data using any Amazon S3 API.
With each successful append operation, you create a part of the object and each object can have up to 10,000 parts. This means you can append data to an object up to 10,000 times. If an object is created using S3 multipart upload, each uploaded part is counted towards the total maximum of 10,000 parts. For example, you can append up to 9,000 times to an object created by multipart upload comprising of 1,000 parts.
That 10,000 limit means this won't quite work for constantly appending to a log file in a bucket.
Presumably it will be possible to "tail" an object that is receiving appended updates using the HTTP Range header.
Say hello to gemini-exp-1121. Google Gemini's Logan Kilpatrick on Twitter:
Say hello to gemini-exp-1121! Our latest experimental gemini model, with:
- significant gains on coding performance
- stronger reasoning capabilities
- improved visual understanding
Available on Google AI Studio and the Gemini API right now
The 1121 in the name is a release date of the 21st November. This comes fast on the heels of last week's gemini-exp-1114.
Both of these new experimental Gemini models have seen moments at the top of the Chatbot Arena. gemini-exp-1114 took the top spot a few days ago, and then lost it to a new OpenAI model called "ChatGPT-4o-latest (2024-11-20)"... only for the new gemini-exp-1121 to hold the top spot right now.
(These model names are all so, so bad.)
I released llm-gemini 0.4.2 with support for the new model - this should have been 0.5 but I already have a 0.5a0 alpha that depends on an unreleased feature in LLM core.
I tried my pelican benchmark:
llm -m gemini-exp-1121 'Generate an SVG of a pelican riding a bicycle'

Since Gemini is a multi-modal vision model, I had it describe the image it had created back to me (by feeding it a PNG render):
llm -m gemini-exp-1121 describe -a pelican.png
And got this description, which is pretty great:
The image shows a simple, stylized drawing of an insect, possibly a bee or an ant, on a vehicle. The insect is composed of a large yellow circle for the body and a smaller yellow circle for the head. It has a black dot for an eye, a small orange oval for a beak or mouth, and thin black lines for antennae and legs. The insect is positioned on top of a simple black and white vehicle with two black wheels. The drawing is abstract and geometric, using basic shapes and a limited color palette of black, white, yellow, and orange.
Update: Logan confirmed on Twitter that these models currently only have a 32,000 token input, significantly less than the rest of the Gemini family.
It's okay to complain and vent, I just ask you be able to back it up. Saying, "Python packaging sucks", but then admit you actually haven't used it in so long you don't remember why it sucked isn't fair. Things do improve, so it's better to say "it did suck" and acknowledge you might be out-of-date.
Private School Labeler on Bluesky. I am utterly delighted by this subversive use of Bluesky's labels feature, which allows you to subscribe to a custom application that then adds visible labels to profiles.
The feature was designed for moderation, but this labeler subverts it by displaying labels on accounts belonging to British public figures showing which expensive private school they went to and what the current fees are for that school.
Here's what it looks like on an account - tapping the label brings up the information about the fees:
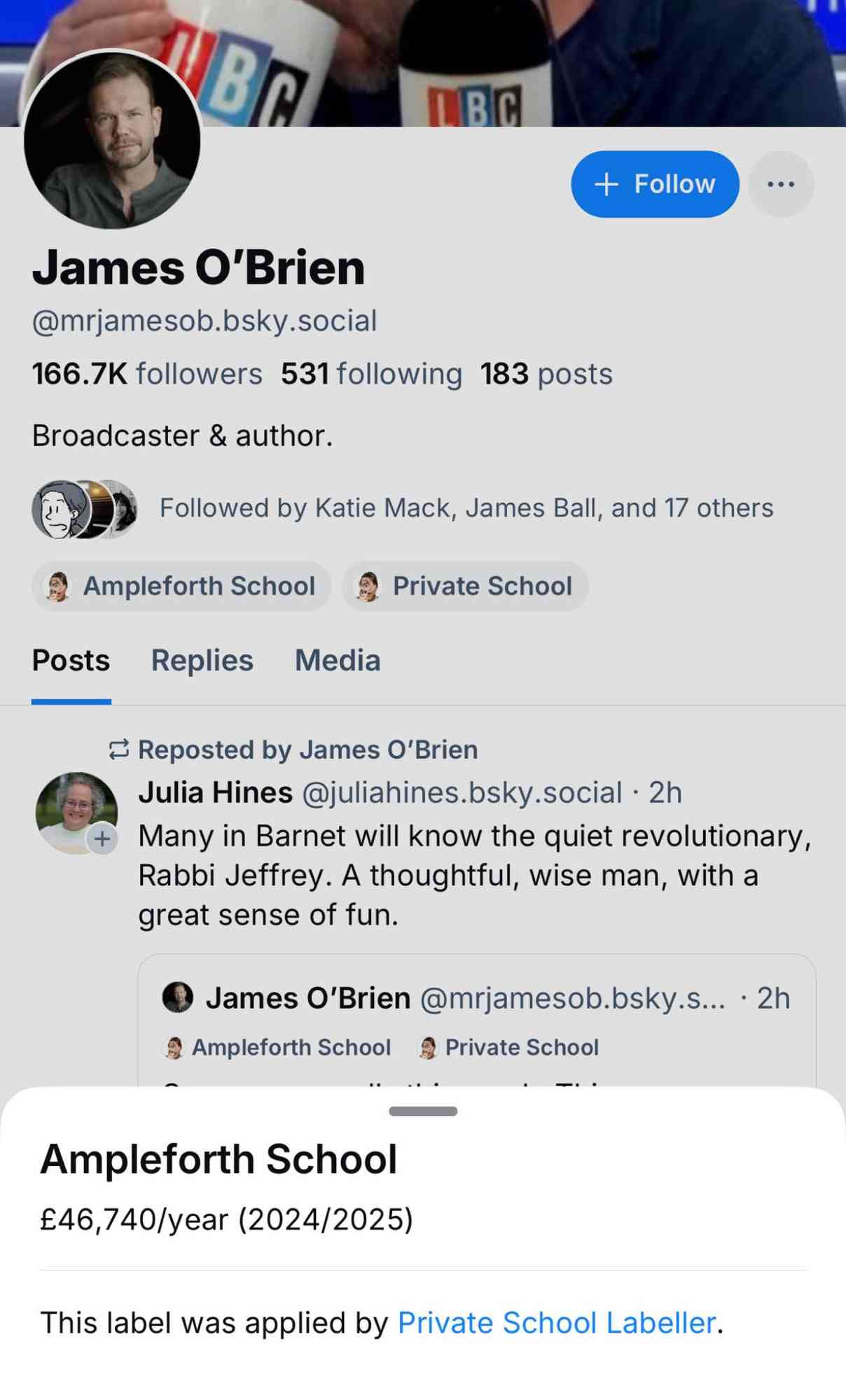
These labels are only visible to users who have deliberately subscribed to the labeler. Unsurprisingly, some of those labeled aren't too happy about it!
In response to a comment about attending on a scholarship, the label creator said:
I'm explicit with the labeller that scholarship pupils, grant pupils, etc, are still included - because it's the later effects that are useful context - students from these schools get a leg up and a degree of privilege, which contributes eg to the overrepresentation in British media/politics
On the one hand, there are clearly opportunities for abuse here. But given the opt-in nature of the labelers, this doesn't feel hugely different to someone creating a separate webpage full of information about Bluesky profiles.
I'm intrigued by the possibilities of labelers. There's a list of others on bluesky-labelers.io, including another brilliant hack: Bookmarks, which lets you "report" a post to the labeler and then displays those reported posts in a custom feed - providing a private bookmarks feature that Bluesky itself currently lacks.
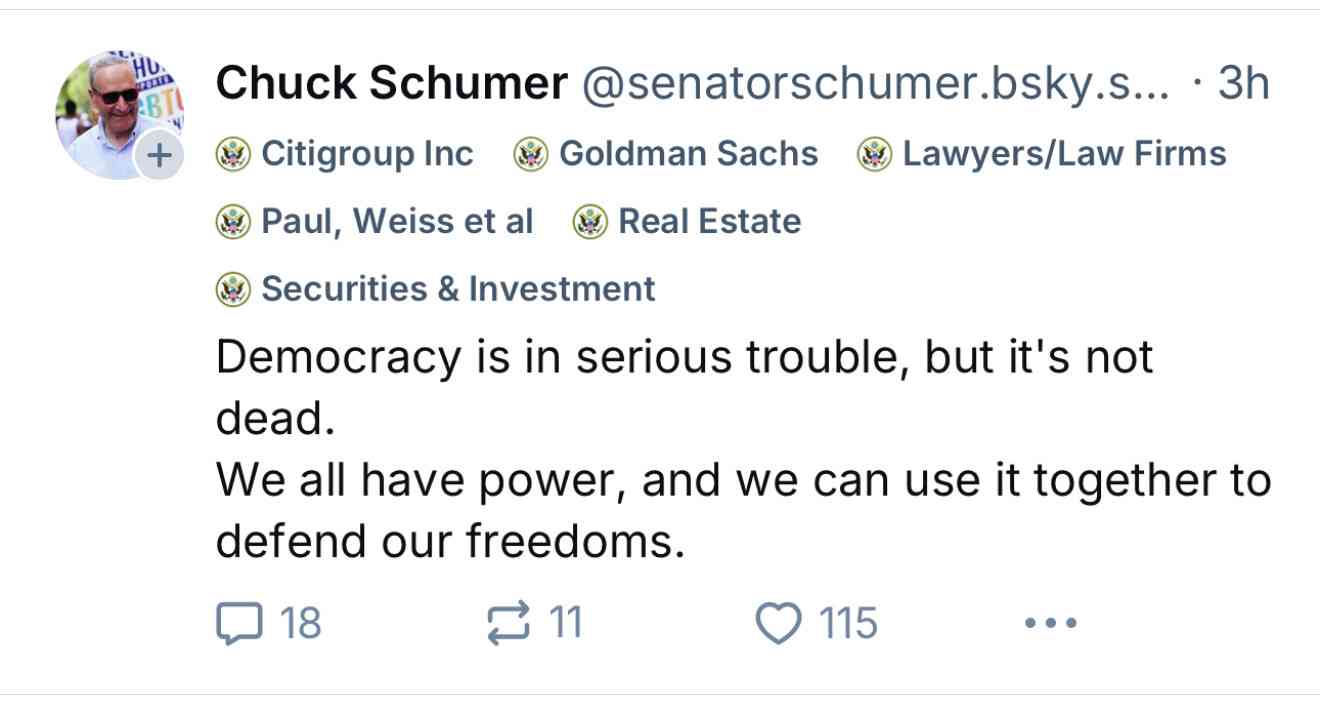
Update: @us-gov-funding.bsky.social is the inevitable labeler for US politicians showing which companies and industries are their top donors, built by Andrew Lisowski (source code here) using data sourced from OpenScrets. Here's what it looks like on this post:
How decentralized is Bluesky really? (via) Lots of technical depth in this comparison of the Bluesky (ATProto) and Fediverse/Mastodon/ActivityPub approach to decentralization, from ActivityPub spec author Christine Lemmer-Webber.
One key theme: many of the features of Bluesky that aren't present in the rest of the Fediverse are the result of centralization: Bluesky follows a "shared heap" architecture where participating nodes are expected to maintain a full copy of the entire network - more than 5TB of data already. ActivityPub instead uses a "message passing" architecture where only a subset of the overall network data - messages from accounts followed by that node's users - are imported into the node.
This enables features like comprehensive search and the ability to browse all messages in a conversation even if some come from accounts that are not followed by any of the current node's users (a problem I've faced in the past).
This is also part of the "credible exit" mechanism where users can theoretically switch to a different host while keeping all of their existing content - though that also takes advantage of content addressed storage, a feature that could be added to ActivityPub.
Also of note: direct messages on Bluesky are currently entirely dependent on the single central node run by Bluesky themselves, and are not end-to-end encrypted. Furthermore, signing keys that are used by ATProto are currently held custodially by Bluesky on behalf of their users.
Weeknotes: asynchronous LLMs, synchronous embeddings, and I kind of started a podcast
These past few weeks I’ve been bringing Datasette and LLM together and distracting myself with a new sort-of-podcast crossed with a live streaming experiment.
[... 896 words]