Releases
Filters: Sorted by date
Changes that improve Datasette Apps when created and edited using Datasette Agent:
The app_debug() tool is pretty neat: it works by displaying the app in a opacity: 0 iframe with pointer-events: none (so it can't be seen or interacted with) and then executing agent-provided JavaScript inside that sandboxed iframe. This means the agent can smoke test that the app is working and even do things like measure the dimensions of different elements.
This uses the new context.browser_task() mechanism added in datasette-agent 0.4a0.
- New
await context.browser_task()mechanism allowing agent tools to run code directly in the user's browser. #33
This is an exciting new capability: it makes it easy for Datasette Agent plugins to provide tools that execute custom JavaScript in the user's browser.
I used this to add a debug loop to Datasette Apps in datasette-apps 0.2a0.
Hot on the heels of RC1, this fixes a dependency issue and also adds two neat new features:
- The default model for users who have not set their own default is now GPT-5.6 Luna. It was previously GPT-4o mini. Luna is a much better and more recent model, albeit slightly more expensive - $0.20 per million input tokens and $1.20 per million output tokens, compared to $0.15/$0.60 for 4o mini. You can switch back to 4o mini using
llm models default gpt-4o-mini, or switch to GPT-5 nano, an even cheaper default model ($0.05/$0.40), usingllm models default gpt-5-nano. #1576- New llm openai endpoint command for running prompts, chats and model listings against arbitrary OpenAI-compatible endpoints without first configuring a model. These calls are not logged. #1565
The llm openai endpoint command is really cool. I got frustrated at the lack of an obvious CLI tool for trying out prompts against arbitrary OpenAI Chat Completions imitation endpoints, so I decided to add that to LLM itself.
You don't even have to install LLM to use this. Here's a uvx one-liner for running a prompt - with tools - against an LM Studio local model:
uvx --pre llm openai endpoint http://127.0.0.1:1234/v1 \
T llm_version -T llm_time --td \
-m google/gemma-4-31b 'what is the current LLM version? And the time?'
A key goal of the new content-addressable logs in LLM 0.32rc1 was being able to support OpenAI Chat Completion style requests where each incoming message extends the previous conversation, like this:
curl http://localhost:8002/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{
"model": "qwen3.5-4b",
"messages": [
{"role": "user", "content": "Capital of France?"},
{"role": "assistant", "content": "Paris."},
{"role": "user", "content": "Germany?"}
]
}'
Here the conversation state is tracked by the client, so each of these requests gets longer and longer. The new schema design in LLM is designed to de-duplicate these using hashes of the individual message parts.
To test that out, I built this plugin:
uv tool install llm --pre
llm install llm-chat-completions-server
llm chat-completions-server -p 9001
Running this starts a localhost server on port 9001 that exposes your full collection of LLM models (from any plugins you have installed) using a ChatGPT Completions compatible endpoint.
GPT-5.6 Sol wrote the whole thing - it turns out it knows the OpenAI Chat Completions API shape really well.
This RC for LLM 0.32 finishes the work that started in LLM 0.32a0 - it adds a new schema design that does a much better job of capturing the details of the prompts and responses returned by the latest model families.
The most important change is the use of content-addressable hash IDs for stored messages. This allows de-duplication in the database, and means that LLM can now represent trees of messages for forked conversations.
Since it involves a significant schema change - new tables only, and old data should not be affected at all - it's worth running a backup of your existing logs.db before upgrading to the RC:
llm logs backup logs-backup.db
The RC also adds support for gpt-5.6-sol, gpt-5.6-terra, and gpt-5.6-luna.
I back-ported a fix for table.delete_where() that shipped in version 4.
A minor release. Performance and documentation improvements to the permissions system, plus I reverted a cosmetic API change which caused almost every existing plugin test suite to break.
Some minor improvements, mainly around command option consistency and making the server: mechanism used by both shot-scraper video and shot-scraper multi work if the server takes longer than a second to start serving traffic.
server:processes used byshot-scraper multiandshot-scraper videonow wait up to 30 seconds for the target URL to accept connections, polling for port availability and replacing the previous fixed one-second delay. #197- The
shot-scraper,html,accessibilityandharcommands now have a--js-fileoption for loading JavaScript from a local file, standard input orgh:username/script, as an alternative to--javascriptwhich accepts the string of JavaScript directly as an argument. #192shot-scraper multisupports the equivalentjs_file:YAML key.- The
shot-scraper javascriptandshot-scraper htmlcommands now have a--timeoutoption for consistency with other commands. #118
Mainly a fix for an edge case that regular Claude chat spotted while experimenting with the 4.1 release to answer a question about ON DELETE.
table.transform()now raises aTransactionErrorif called while a transaction is open withPRAGMA foreign_keysenabled and the table is referenced by foreign keys with destructiveON DELETEactions -CASCADE,SET NULLorSET DEFAULT. The pragma cannot be changed inside a transaction, so previously dropping the old table as part of the transform could fire those actions and silently delete or modify referencing rows. See Foreign keys and transactions for details and workarounds. (#794)- The CLI and Python API documentation now cross-reference each other: CLI sections link to the equivalent Python API functionality and Python API sections link back to the corresponding CLI command. (#791)
The first dot-release since 4.0 a few days ago, introducing a number of minor new features.
sqlite-utils insertandsqlite-utils upsertnow accept a--codeoption for providing a block of Python code (or a path to a.pyfile) that defines arows()function orrowsiterable of rows to insert, as an alternative to importing from a file. (#684)
sqlite-utils already had features that allow you to pass blocks of Python code as CLI arguments, for example this one for the sqlite-utils convert command:
sqlite-utils convert content.db articles headline ' def convert(value): return value.upper()'
Allowing blocks of code to generate new rows directly was on obvious extension of that pattern:
sqlite-utils insert data.db creatures --code ' def rows(): yield {"id": 1, "name": "Cleo"} yield {"id": 2, "name": "Suna"} ' --pk id
sqlite-utils insertandsqlite-utils upsertnow accept--type column-name typeto override the type automatically chosen when the table is created. This is useful for CSV or TSV columns such as ZIP codes that look like integers but should be stored asTEXTto preserve leading zeros. (#131)
A long-standing feature request which turned out to be a simple implementation.
- New
table.drop_index(name)method andsqlite-utils drop-indexcommand for dropping an index by name. Both acceptignore=True/--ignoreto ignore a missing index. (#626)sqlite-utils querycan now read the SQL query from standard input by passing-in place of the query, for exampleecho "select * from dogs" | sqlite-utils query dogs.db -. (#765)
Two more small features. I had Codex review all open issues and highlight the easiest ones!
sqlite-utils upsertcan now infer the primary key of an existing table, so--pkcan be omitted when upserting into a table that already has a primary key.
Another Codex suggestion, an obvious missing CLI feature from a Python library improvement that shipped in the 4.0 release.
table.transform()andtable.transform_sql()now acceptstrict=Trueorstrict=Falseto change a table’s SQLite strict mode. Omitting the option preserves the existing mode. (#787)- The
sqlite-utils transformcommand now accepts--strictand--no-strictto change a table’s strict mode. (#787)
These two were inspired by Prefer STRICT tables in SQLite by Evan Hahn, which did the rounds on Hacker News today. Evan pointed out that:
Unfortunately, I don’t think there’s a way to ALTER a table to make it strict. I think you have to copy the data out of the non-strict table into the strict one.
That's exactly what the sqlite-utils transform mechanism does, so I extended it to add the ability to switch tables from strict to non-strict and vice-versa.
Here's the GPT-5.6 Sol xhigh Codex transcript I used to implement those new strict table features. One of the most useful prompts I ran was this one:
use uv run python -c and manually exercise the new .transform(strict=) option, see if you can find any edge-cases or bugs
Effectively telling the model to manually test its work, outside of the automated tests it had already written. This turned up two minor issues that we then fixed.
Let's LLM run prompts against the new muse-spark-1.1 model.
- Fix for a bug with OpenAI Chat Completion endpoints where a tool call with empty arguments could result in a JSON error from some providers. #1521
This bug came up when I was testing llm-meta-ai.
The signature features of this alpha are new UIs for inserting multiple rows at once (from TSV, CSV or JSON) and for creating a table from rows, plus a large number of small JSON API consistency fixes in preparation for a 1.0 stable release.
The version that retires the library, instead implementing a compatibility shim against the new sqlite-utils 4.0 dependency.
See sqlite-utils 4.0, now with database schema migrations for details.
The last RC before the 4.0 stable release. Mainly implements feedback from a detailed review by Claude Fable 5.
I hoped to release sqlite-utils 4.0 stable this weekend, but as I worked through the backlog of issues and PRs with a combination of Claude Fable 5 and GPT-5.5 the changelog since rc2 kept getting bigger.
The biggest new feature is support for introspecting and creating compound foreign keys - a feature that involves a subtle breaking change to table.foreign_keys and hence needed to land for the 4.0 stable release.
sqlite-utils also now follows SQLite's convention for case insensitive column names, which turned out to touch a bunch of different places at once.
Another Fable 5 experiment. Now that my LLM library has evolved into more of an agent framework it's time to see what a simple coding agent would look like built on it.
I started a new Python library using my python-lib-template-repository GitHub template repository, then ran these two prompts (here's the Claude Code for web transcript):
Write a spec.md for this project - it will depend on the latest “llm” alpha from PyPI and implement a Claude code style coding agent complete with tools for reading and editing files and executing commands
Then:
Commit the spec, then build it using red/green TDD in a series of sensible commits (each with passing tests and updated docs) - occasionally manually test it using the OpenAI API key in your environment
Here's the spec, the resulting README file, and the sequence of commits.
I've shipped a slop-alpha to PyPI, so you can run the new agent like this:
uvx --prerelease=allow --with llm-coding-agent llm code
It's pretty good for a first attempt! Here's the (Fable-authored) README, which lists recipes like llm code --yolo and llm code --allow "pytest*" --allow "git diff*".
It also presents a Python API based around a CodingAgent(model="gpt-5.5", root="/path", approve=True).run("Fix the failing test in tests/test_parser.py") class which I didn't ask for but I'm delighted to see implemented.
Here's the suite of tools it implemented, listed using uvx ... llm tools:
CodingTools_edit_file(path: str, old_string: str, new_string: str, replace_all: bool = False) -> strReplace an exact string in a file.
old_string must match the file contents exactly (including whitespace) and must identify a unique location unless replace_all is true. Returns a diff of the change so it can be verified.
CodingTools_execute_command(command: str, timeout: int = 120) -> strRun a shell command in the session root directory.
Returns combined stdout and stderr followed by an Exit code line. timeout is in seconds (maximum 600); on timeout the whole process tree is killed.
CodingTools_list_files(pattern: str = '**/*', path: str = '.') -> strList files matching a glob pattern, newest first.
Skips hidden directories, node_modules, __pycache__ and (in a git repository) anything covered by .gitignore. Returns at most 200 paths relative to the searched directory.
CodingTools_read_file(path: str, offset: int = 0, limit: int = 2000) -> strRead a text file, returning numbered lines like cat -n.
Paths are relative to the session root. Use offset (0-based first line) and limit (max lines) to page through files too large to read in one call.
CodingTools_search_files(pattern: str, path: str = '.', glob: str = None, max_results: int = 100) -> strSearch file contents for a regular expression.
Returns matches as path:line_number:line, capped at max_results. Use glob (e.g. "*.py") to restrict which files are searched.
CodingTools_write_file(path: str, content: str) -> strCreate or overwrite a file with the given content.
Parent directories are created as needed. Prefer edit_file for modifying existing files.
I tried it out by running llm code --yolo and then prompting:
mkdir /tmp/demo and then in that folder create a simple swiftui CLI app for telling the time in ascii art
Here's the transcript, in which GPT-5.5 reasoning notes that "SwiftUI isn't suitable for a true CLI" and then builds an app that outputs this on swift run AsciiTime:
█ █████ ████ █ █ ███
██ █ █ █ ██ █ ██ █ █
█ ████ ███ █ █ █
█ █ █ █ █ █ █ █
███ ████ ████ ███ ███ █████
The big new feature is shot-scraper video storyboard.yml, described in detail in Have your agent record video demos of its work with shot-scraper video.
An embarrassingly tiny release. The pyproject.toml had pinned to datasette==1.0a27, inadvertently making this plugin incompatible with all other Datasette versions. It's now datasette>=1.0a27 instead.
I'll write more about this one soon, but it's a big release. Three highlights from the release notes:
- New "Create table" interface in the database actions menu, backed by the
/<database>/-/createJSON API. It can define columns, primary keys, custom column types,NOT NULLconstraints, literal defaults, expression defaults and single-column foreign keys. (#2787)- New "Alter table" table action and
/<database>/<table>/-/alterJSON API for changing existing tables: add, rename, reorder and drop columns; change column types, defaults,NOT NULLconstraints, primary keys and foreign keys; and rename the table. The alter table dialog also includes a "Drop table" button. (#2788)- New Template context documentation listing the variables available to custom templates for Datasette's core pages. Variables documented there are treated as a stable API for custom templates until Datasette 2.0. The documentation is generated from dataclass definitions next to the view code, with tests that compare the documented fields against the actual contexts rendered by the database, table, query and row pages. (#1510, #2127, #1477, #2803)
Here's a rough video demo I made of the new create/alter table feature as part of reviewing the PR:
This release expands
datasette-aclfrom table-only permissions toward a general resource-sharing system.
Alex Garcia did most of the work for this release - we're fleshing out the plugin that will allow multi-user Datasette instances finely grained control over who can access which resources within Datasette.
Quoting the release notes:
The big feature in this alpha is tools to insert, edit and delete rows within the Datasette interface. These features are available on table pages, and edit and delete are also available as action items on the row page.
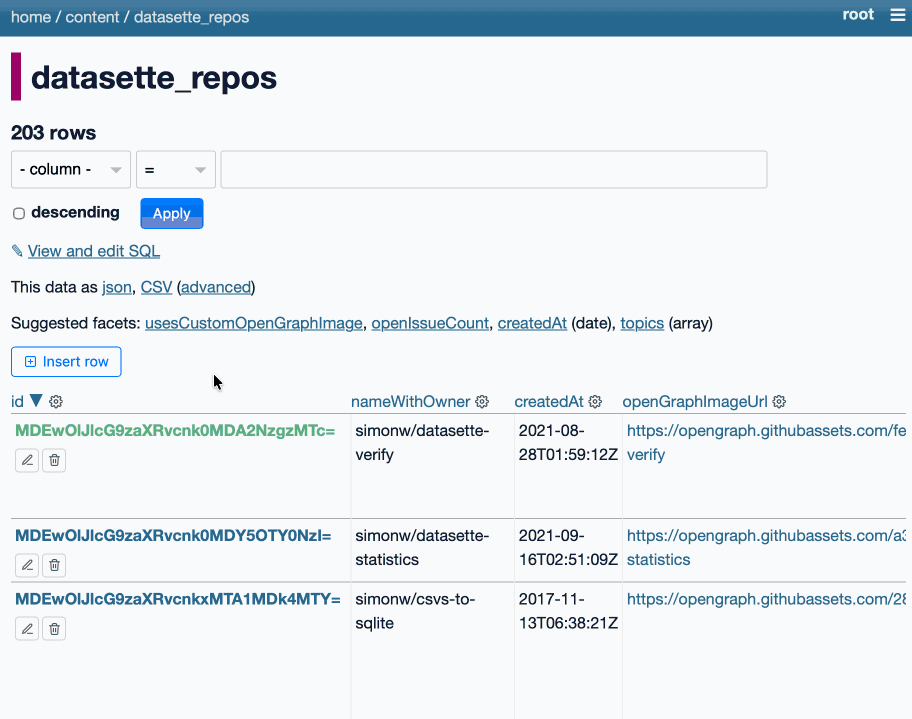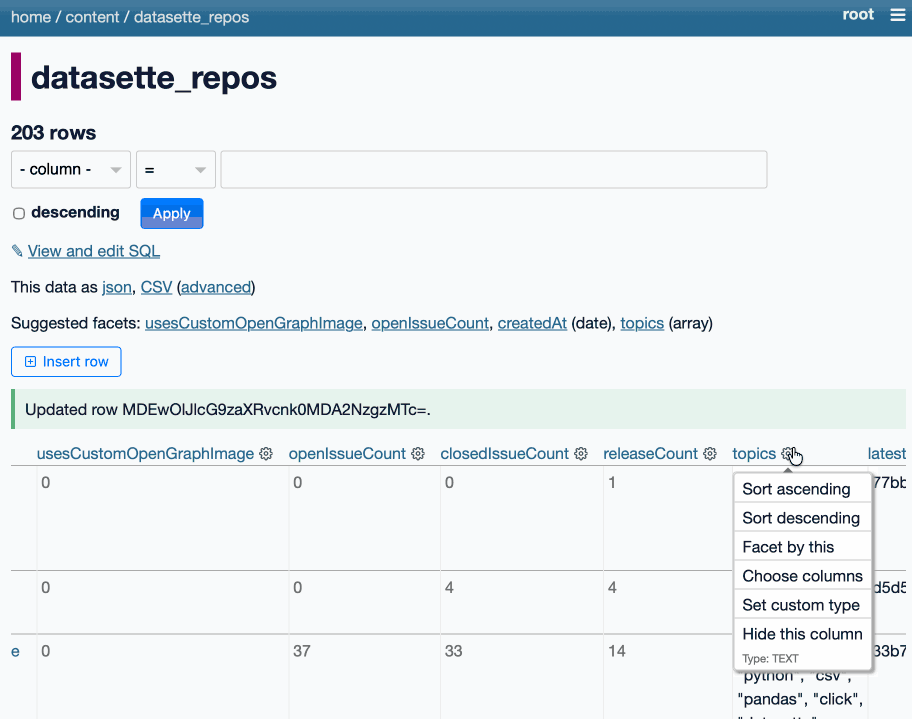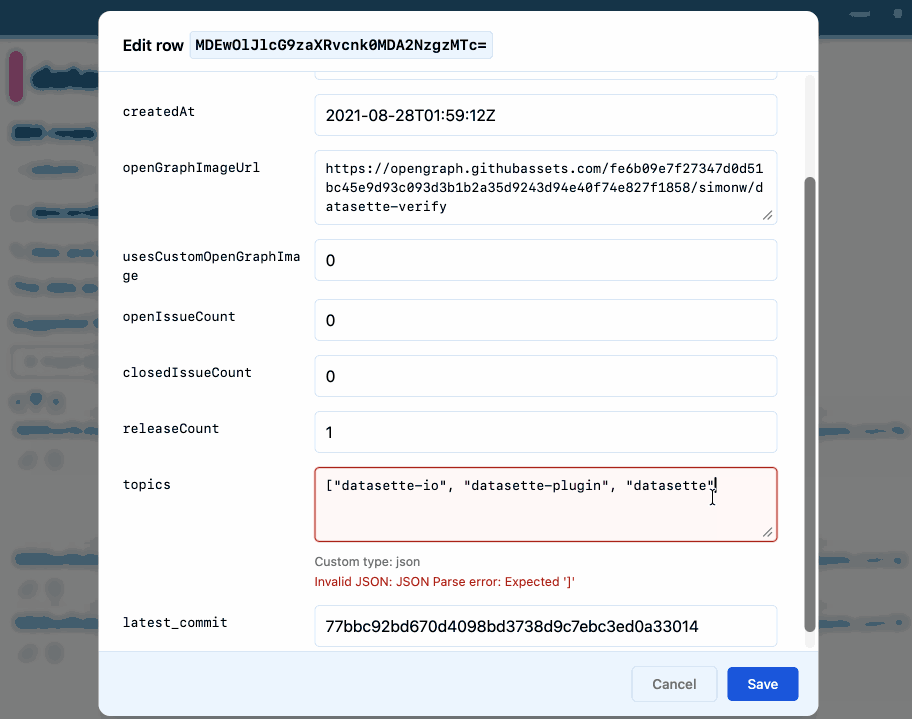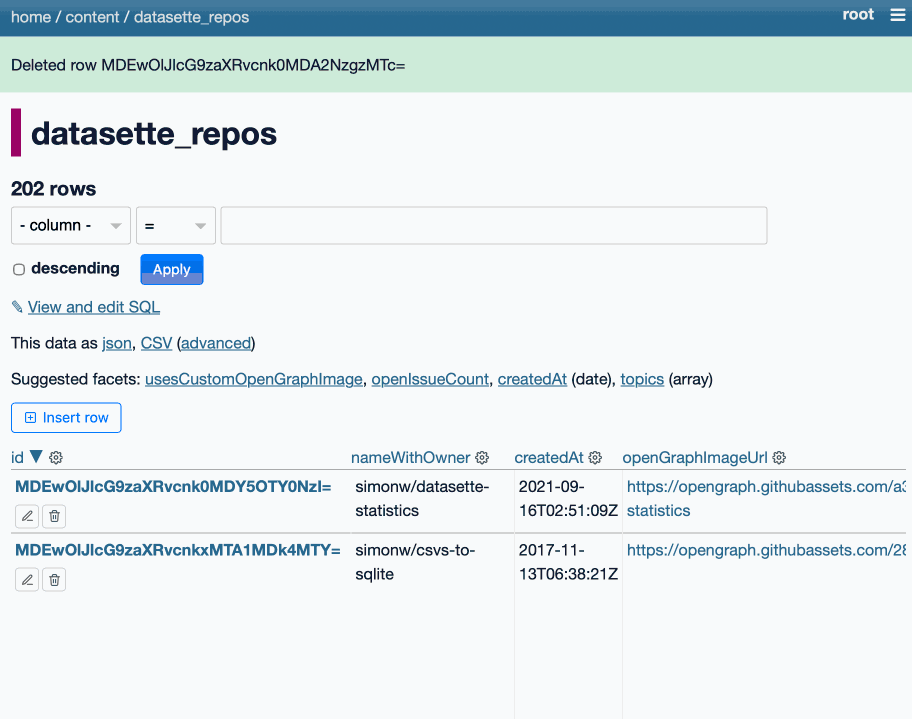
The inspiration for this feature - which is long overdue - was Datasette Agent. I added SQL write support to that the other day which highlighted how absurd it was that you could insert and edit ties via the chat interface but not in the regular Datasette UI!
A very experimental alpha plugin which lets you do this:
datasette tailscale mydata.db \
--ts-authkey tskey-auth-xxxx --ts-hostname datasette-preview
This starts a localhost Datasette server with a Tailscale sidecar that connects it to your Tailnet, such that http://datasette-preview/ serves Datasette.
It's using the Python bindings for the experimental tailscale-rs library. I filed an issue asking if there's a cleaner way of setting up the proxy mechanism.
- Fixed a bug where users without the
create-apppermission could still create apps. #27- Fixed a bug where it was impossible to grant permission to edit an app to users who were not the app's owner. The rules for edit/delete are now the same as view: if the app is private only the owner can modify it, otherwise permission is controlled by Datasette's regular permission system. #29