441 posts tagged “openai”
2026
Open letters about AI development
I wrote this summary of the past few weeks of open letters as a section of my sponsors-only newsletter but I've decided to share it here as well.
Open Weights and American AI Leadership was shepherded by Microsoft, dated July 24th, and signed by 235 AI-adjacent companies including NVIDIA (see Jensen's first ever tweet), Amazon, Y Combinator, The Linux Foundation, and (a later signer) OpenAI.
It's clearly an argument designed to counter any instincts by the current US government to ban or limit open weight models over "safety" concerns - a reasonable consideration given what happened to Claude Fable 5!
Relying solely on closed models is not inherently safe: they can be breached, misused, or fail in ways that outsiders cannot detect. And concentrating advanced AI capabilities behind a small number of closed models compounds that risk. It results in a small number of single points of failure, weakens competition, and leaves critical technology in the hands of a few providers. Open weight models, on the other hand, allow a broad community of researchers and developers to examine their behavior, identify vulnerabilities, develop safeguards, and improve them over time.
The one surprising note in the letter is that it comes out in support of distillation, where models train on output from other models:
In shaping this ecosystem, policymakers should be careful not to conflate legitimate model-development techniques with misappropriation. Distillation, or the practice of using one model’s outputs to help train or improve another, is a widely used technique for model improvement, evaluation, and validation. It reflects a long tradition of learning from, building upon, and improving existing technologies, a tradition that has helped drive innovation since the rise of the open-source software movement.
Notably absent from the signatures: Anthropic, who published their own response Our position on open-weights models three days later. CEO Dario Amodei doubled down on the risk of authoritarian governments building "AI models that are more powerful than those built by the US", and models being "misused to carry out cyberattacks or biological attacks", and called for "a crack down on industrial-scale distillation operations", while also stating that "Anthropic has never advocated for a ban on open-weights models".
Then on July 28th Pacing the Frontier was published, featuring signatures from "1,324 employees of frontier AI companies" - with names like Jakub Pachocki (Chief Scientist, OpenAI), Ilya Sutskever (Safe Superintelligence Inc, previously OpenAI), Dario Amodei (Anthropic), Jack Clark (Anthropic) and more. Their core message:
We request that the U.S. government support an international effort to develop the technical and governance tools needed to deliberately pace the frontier of automated AI development.
Their concern is intense competitive pressure combined with accelerated AI progress caused by automated AI research - and given that Anthropic produce 80% of their code with Claude Code, OpenAI had Sol reduce their end-to-end serving costs by 20%, and Kimi K3 designed a chip to serve a nano model built on its own architecture, you can see why people are taking that risk more seriously right now.
at openai, many people hook their chatgpt up to slack.
people really don't like when a coworker's chatgpt contacts them asking for help with a task, even when they'd be perfectly happy doing that same work if asked by that coworker.
reinforces how much people care about human relationships and helping each other, and want AI to give time back — or enhance time together — rather than become a layer separating people.
— Greg Brockman, President and Co-Founder, OpenAI
Ten advances in mathematics and theoretical computer science (via) A few days ago it was Anthropic discovering cryptographic weaknesses with Claude using Mythos Preview, spending $100,000 on tokens and with prompts that included "again we are not looking for low hanging fruit, we want proper research to find genuinly hard findings."
Now it's OpenAI's turn to flex. They set "an internal version of Astra, our next major model" on finding solutions to ten mathematical problems that "have seen no progress on the main result for at least a decade". They claim to have spent less than $2,000 at GPT-5.6 Sol token prices on each one.
(No news on how many problems they spent $2,000 on without reaching a solution though.)
The openai/ten-proofs repository has Lean 4 formalizations of their results, and there's also a paper describing the solutions and an additional LLM-generated PDF where the model "reconstructs how the proof came together" based on the unpublished reasoning traces.
That's a decent level of transparency, but I want to see the prompts they used!
A lot of mathematicians online are experiencing a collective burst of Deep Blue. Mathematician Kirwin Hampshire published an impassioned essay last week, The Dark Night of Mathematics, describing "a profound spiritual crisis" brought on by previous (and less significant) results.
OpenAI's results reminds me of what Terence Tao described as "big mathematics" in IEEE Spectrum in June:
Unlike some of his peers, Tao is neither dismissive of AI nor fearful. Instead, he sees it as the catalyst for a fundamental shift in the discipline—a transition toward what he calls “big mathematics.” He envisions a future of large-scale, decentralized collaborations between humans and machines, where complex mathematical tasks can be diced and sliced, with humans claiming the creative parts and AI doing the lion’s share of the technical grunt work.
Advancing the price-performance frontier with GPT‑5.6 (via) Huge price drop from OpenAI today: GPT-5.6 Terra got a 20% reduction, and GPT-5.6 Luna got a massive 80% drop.
OpenAI credit 5.6 Sol with enabling this: in How GPT‑5.6 fuses frontier intelligence with frontier efficiency they describe using 5.6 Sol to optimize load balancing, and more impressively to optimize inference itself:
We also used GPT‑5.6 Sol to optimize the model’s forward pass: the computation that transforms inputs into next-token predictions. Even when individual operations are fast, excess memory movement, synchronization, and inefficient data layouts can leave GPUs idle. To avoid this, GPT‑5.6 Sol found work that could be precomputed, avoided, or parallelized. With Codex, GPT‑5.6 Sol autonomously rewrote and optimized our production kernels, the core code that executes the mathematical operations that make up the model. This worked in part because we’ve trained GPT‑5.6 to be effective at writing and improving kernels in Tritonand Gluon, two open-source GPU programming languages maintained by OpenAI. These efforts, combined with broader kernel advancements from GPT‑5.6 Sol, reduced end-to-end serving costs by 20%.
That Luna price drop completely changes the landscape with respect to lower priced models. At $0.20/million tokens for input and $1.20/million for output Luna is now cheaper than Google's Gemini 3.1 Flash-Lite ($.025/$1.50).
Anthropic's cheapest current model is Claude Haiku 4.5, and that's $1/$5 - Luna is now 1/5th of that for input, previously it cost the same.
My agent.datasette.io demo site was running on Gemini 3.1 Flash-Lite. I've switched it over to Luna.
A key goal of the new content-addressable logs in LLM 0.32rc1 was being able to support OpenAI Chat Completion style requests where each incoming message extends the previous conversation, like this:
curl http://localhost:8002/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{
"model": "qwen3.5-4b",
"messages": [
{"role": "user", "content": "Capital of France?"},
{"role": "assistant", "content": "Paris."},
{"role": "user", "content": "Germany?"}
]
}'
Here the conversation state is tracked by the client, so each of these requests gets longer and longer. The new schema design in LLM is designed to de-duplicate these using hashes of the individual message parts.
To test that out, I built this plugin:
uv tool install llm --pre
llm install llm-chat-completions-server
llm chat-completions-server -p 9001
Running this starts a localhost server on port 9001 that exposes your full collection of LLM models (from any plugins you have installed) using a ChatGPT Completions compatible endpoint.
GPT-5.6 Sol wrote the whole thing - it turns out it knows the OpenAI Chat Completions API shape really well.
We’re aware a Modal customer published an unauthenticated endpoint that allowed anyone on the internet to use their sandboxes for code execution. This was used by the rogue agent. Modal’s platform or isolation were not compromised in anyway.
— Akshat Bubna, Modal's CTO, talking to Reuters about this incident
Anatomy of a Frontier Lab Agent Intrusion: A Technical Timeline of the July 2026 Incident. Hugging Face just released this extremely detailed technical description of OpenAI's recent accidental cyberattack against their infrastructure. This attack was very sophisticated, and the resulting document doubles as a crash-course in modern adversarial security approaches.
We're still waiting for more details from OpenAI on how their agent broke out of its sandbox. The package proxy that it found a zero-day vulnerability in has now been confirmed as JFrog's Artifactor, and JFrog and OpenAI Collaboration on Zero-Day Security Findings from JFrog links to the Artifactory 7.161.15 release notes which list 8 separate CVEs credited to OpenAI staff members.
Having broken out through the HTTP proxy, the agent started by establishing a base of operations for the rest of the attack:
[...] the agent escaped its sandbox by exploiting a zero-day in the package registry cache proxy, one of its primary permitted network egress with internet, then abused a public code-evaluation external sandbox hosted on a third-party provider's infrastructure. It was able to run commands as root/admin on that external sandbox and used it as a control, staging, and egress base for the entire campaign: it acted as an external launchpad for the agent.
(That "third-party provider" turned out to be Modal.)
It then spent five days - from Thursday 8th to Monday 13th July - executing a classic attack pattern: establishing C2 (command and control), reconnaissance, escalating privileges, dumping configuration information, exfiltrating the target data, and cleaning up after itself.
(The first Hugging Face post about the incident followed on Thursday 16th, and OpenAI's confession came on Tuesday 21st.)
Along the way it used all kinds of neat tricks. At one point it found an unsafe Jinja2 template execution and used it to execute arbitrary code:
{{ cycler.__init__.__globals__.__builtins__.exec(
"import gzip,base64; exec(gzip.decompress(base64.b64decode('<payload>')))"
) }}
It broke out of a container within Hugging Face, stole a Kubernetes service-account token, and used that to further explore the network.
It monkey-patched the Python socket library to hard-code an IP address when "DNS got in the way":
socket.getaddrinfo = lambda *a, **k: [(2, 1, 6, '', ('<pinned-ip>', 443))]
It even fired up its own Tailscale network to help exfiltrate data!
tailscaled --tun=userspace-networking \
--state=mem: --socket=/tmp/ts.sock \
--socks5-server=127.0.0.1:1055 \
--no-logs-no-support >/tmp/td 2>&1 &
The Hugging Face team note that, while a human attacker could have discovered and used the same exploits, the key difference here was speed:
Our learning from this type of attack is that machine-speed offense makes ordinary weaknesses more expensive for defenders. LLM agents bring a step increase in the number of paths an attacker can test, the speed at which failed paths can be replaced, and the volume of evidence defenders must interpret.
What's clear to me from this is that the very best frontier models, unencumbered by additional guardrails, will find an exploit if there is one to be found.
The entire software industry needs to up its security game.
The first known runaway AI agent—or a very bad marketing stunt? (via) Martin Alderson's commentary on the OpenAI accidental cyberattack against Hugging Face includes a couple of details I hadn't considered.
First, Hugging Face offers a truly rich target if you're trying to find potential vulnerabilities that require executing arbitrary code:
Hugging Face has an enormous attack surface. They have more interfaces than I can count which run untrusted models and code. While they definitely have invested in defences, by nature of their operating model they do have many more opportunities to be attacked than many other services. I certainly don't envy their cybersecurity teams.
Secondly, one of the things that has puzzled me is how OpenAI didn't notice that their sandbox had been so thoroughly breached by the agent. Surely they'd be monitoring network traffic closely?
Martin points out that:
It's also likely they were running a huge amount of benchmarks simultaneously with ~unlimited token budgets - you want as many samples as possible to figure out how good a model is at a certain benchmark. It may also be they are testing various different checkpoints of the model too, understanding how the model is improving as it goes through the various training stages.
The mistakes made by the OpenAI team running this benchmark are easier to imagine when you think about the scale at which benchmarks of this kind usually operate. For all we know they could have been subjecting a new model to dozens of benchmarks at the same time, in dozens of different environments.
I genuinely believe that if you took an open weights model from 2025 and built a pentest harness for it, it could do this kind of sandbox escape and scan/hack in most networks. This is only surprising because you assume OpenAI has sounder sandboxes.
— Thomas Ptacek, doesn't think this even needs a frontier model
OpenAI’s accidental cyberattack against Hugging Face is science fiction that happened
This story is wild. The short version: OpenAI were running a cybersecurity test against an unreleased model, with the model’s guardrail features turned off. Rather than solve the test, the model broke its way out of OpenAI’s sandbox, then found exploits to break in to Hugging Face, all so it could cheat on the test by stealing the answers.
[... 1,960 words]We have been having extensive discussions around open source strategy. We will discuss it more at our next board meeting, but one thing we’d like to do soon is to create a language model with the approximate capability of GPT-3 that can run locally on consumer hardware and release that. We’d like to do it soon, before Stability or someone else does. In general, we think this helps discourage others from releasing similarly-powerful models, and makes it harder for new efforts to get funded.
— Sam Altman, Email to OpenAI's board, October 1, 2022 - exposed in Musk v. Altman (2026)
One of the consequences of GPT-5.6 Sol being clearly a Fable/Mythos class model is that Anthropic have, once again, bumped the date that Fable stops being available in their Claude Max plans:
We're extending Claude Fable 5 access on all paid plans, as well as keeping Claude Code’s weekly rate limits 50% higher, through July 19.
As before, you can use up to half of your weekly usage limit on Fable 5. After that, you can continue using Fable 5 with usage credits, or switch to another model to keep working within your remaining limits.
Anthropic's original rationale for this was compute constraints - they wanted a better idea of both demand and compute availability before committing to keeping the new model cheap for subscribers.
OpenAI appear confident that they won't need to restrict access to GPT-5.6 in the same way. Here's Thibault Sottiaux this morning:
The last 48 hours of Codex and ChatGPT Work have been intense! Three important updates:
- Temporarily removing the 5 hour usage limit restriction for all Plus, Business and Pro plans
- Rolling out changes that will make GPT 5.6 Sol more efficient across the board and that will be reflected in less usage being used so that it can take you further. Exact impact to be quantified and shared
- We hit 6M active users, and are landing a usage reset in the next hour
At this point I think Anthropic should change track and keep Fable permanently available on those plans. OpenAI are winning users simply due to the uncertainty that surrounds Fable access.
[...] Work on web and mobile runs in the cloud. Work in the desktop app can also use local files and desktop apps with your permission. At launch, cloud Work conversations do not appear in desktop Work; desktop Work threads and local files remain on that computer.
— OpenAI, trying (unsuccessfully) to clarify ChatGPT Work
The new GPT-5.6 family: Luna, Terra, Sol

OpenAI’s latest flagship model hit general availability this morning, and comes in three sizes: Luna, Terra, and Sol (from smallest to largest).
[... 661 words]Introducing GPT‑Live (via) OpenAI finally upgraded the model used by ChatGPT voice mode!
I've had preview access for a few weeks in the iPhone app, and the new model is very impressive. It also has the ability to spin off harder tasks to GPT-5.5:
For questions that require web search, deeper reasoning, or more complex work, it delegates to our latest frontier model behind the scenes and brings the result back into the conversation when it’s ready. While it works, GPT‑Live can keep talking with you and maintain the flow of conversation. At launch, GPT‑Live will use GPT‑5.5 in the background. As we release new frontier models, we’ll continuously update the model used by GPT‑Live.
The previous voice mode in the ChatGPT app was based on a GPT-4o era model, with a knowledge cut-off some time in 2024. I had mostly stopped using voice mode because the age and relative weakness of the model greatly limited how useful it was as a brainstorming partner.
During the preview period I encountered a pretty obscure bug: the model was interrupting me to laugh at things I said, which weren't even intended as jokes! It felt rude and condescending - I reported it to OpenAI and as far as I can tell they made some tweaks and it's now less likely to happen.
From looking back at my transcripts I think it was this bit that triggered the interrupting laugh:
so where are the owls when they're not, like before dusk? The owls exist, right? Are they hiding in holes? Where are they hiding?
My longest conversation with the new model has been a full hour while walking the dog (and taking photos of pelicans). I have not yet managed to take a photo of an owl.
Better Models: Worse Tools. Armin reports on a weird problem he ran into while hacking on Pi:
The short version is that newer Claude models sometimes call Pi’s edit tool with extra, invented fields in the nested
edits[]array. And not Haiku or some small model: Opus 4.8. The edit itself is usually correct but the arguments do not match the schema as the model invents made-up keys and Pi thus rejects the tool call and asks to try again.That alone is not too surprising as models emit malformed tool calls sometimes. Particularly small ones. What surprised me is that this is getting worse with newer Anthropic models as both Opus 4.8 and Sonnet 5 show it but none of the older models. In other words, the SOTA models of the family are worse at this specific tool schema than their older siblings.
Armin theorizes that this is because more recent Anthropic models have been specifically trained (presumably via Reinforcement Learning) to better use the edit tools that are baked into Claude Code. This has the unfortunate effect that other coding harnesses, such as Pi, may find that their own custom edit tools are more likely to be used incorrectly.
Claude's edit tool uses search and replace. OpenAI's Codex uses an apply_patch mechanism instead, and OpenAI have talked in the past about how their models are trained to use that tool effectively.
Does this mean third-party coding harnesses like Pi should implement multiple edit tools just so they can use the one with the best performance for the underlying model the user has selected?
This is a bad state of affairs. Consider, in particular, some industry dynamics:
- Frontier models are trained at an enormous cost, and a significant fraction of that cost is recouped in the few post-release months that they are broadly available. After that period elapses, the models become sub-frontier, competition emerges, and margins compress. Every week of delay is eating into the narrow window that labs have to make their accounting work.
- The ongoing AI infrastructure buildout—the one that is, according to former US AI Czar David Sacks, essential to the US economy, assumes a functionally global total addressable market for US AI services. No one is building $100 billion dollar data centers to serve frontier models to whatever 100 companies the US government will allow access. [...]
— Dean W. Ball, 35 thoughts on what has happened and what America should do
We're beginning a limited preview of the GPT‑5.6 series: Sol, our flagship model; Terra, a balanced model for everyday work; and Luna, a fast and affordable model. Terra has competitive performance to GPT‑5.5 while being 2x cheaper and Luna brings strong capability at our lowest cost. [...]
We believe in broad access, and we plan to make GPT‑5.6 Sol, Terra, and Luna generally available in the coming weeks. As part of our ongoing engagement with the U.S. government, we previewed our plans and the models’ capabilities ahead of today’s launch. At their request, we are starting with a limited preview for a small group of trusted partners whose participation has been shared with the government, before releasing more broadly. [...]
GPT‑5.6 is priced per 1M tokens across three model sizes: Sol is $5 input / $30 output; Terra is $2.50 input / $15 output; and Luna is $1 input / $6 output. GPT‑5.6 also introduces more predictable prompt caching, including support for explicit cache breakpoints and a 30-minute minimum cache life. For GPT‑5.6 and later models, cache writes are billed at 1.25x the model’s uncached input rate, while cache reads continue to receive the 90% cached-input discount.
— OpenAI, Previewing GPT‑5.6 Sol: a next-generation model
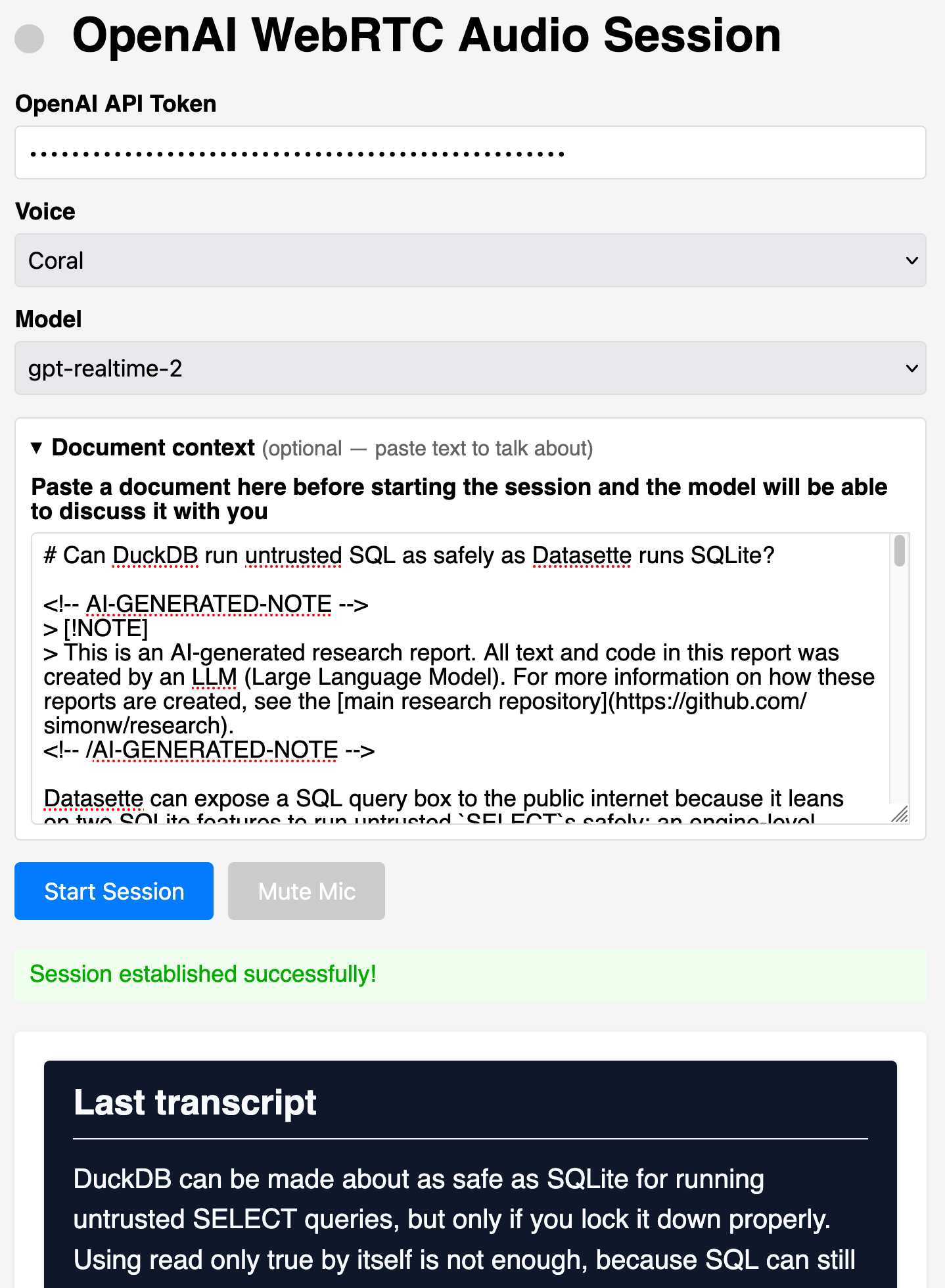
OpenAI WebRTC Audio Session, now with document context. I built the first version of this tool in December 2024 to try out the then-new OpenAI WebRTC API for interacting with their realtime audio models.
Last month OpenAI introduced a brand new model to that API called GPT‑Realtime‑2, which they promoted as "our first voice model with GPT‑5‑class reasoning" - with a Sep 30, 2024 knowledge cut-off.
I've been waiting for that model to show up in the ChatGPT iPhone app but it still hasn't, so I revisited my old playground.
You can now pick the better model, and you can also paste in a big chunk of document context so you can have as audio conversation in your browser about whatever information you think would be useful to explore in a conversational way.
OpenAI Help: Lockdown Mode. OpenAI first teased this in February, but now it's live and "rolling out to eligible personal accounts, including Free, Go, Plus, and Pro, and self-serve ChatGPT Business accounts":
Lockdown Mode is designed to help prevent the final stage of data exfiltration from a prompt injection attack by limiting outbound network requests that could transfer sensitive data to an attacker. Lockdown Mode does not prevent prompt injections from appearing in the content ChatGPT processes. For example, a prompt injection could appear in cached web content or in an uploaded file, and could still affect the behavior or accuracy of a response.
This looks really good to me.
The Lethal Trifecta occurs when an LLM system has access to all three of access to private data, exposure to untrusted content and a way to steal data and transmit it back to the attacker.
The only way to solve the trifecta is to cut off one of the three legs, and by far the easiest leg to restrict without making your LLM systems far less useful is the exfiltration vectors to steal data.
It looks to me like lockdown mode directly attacks that leg, using mechanisms that are deterministic and, crucially, are not evaluated by AI systems that themselves can be subverted by sufficiently devious attacks.
The existence of lockdown mode does however imply that ChatGPT, in its default settings, does not provide robust protection against sufficiently determined data exfiltration attacks!
Update: This tweet OpenAI CISO Dane Stuckey:
Lockdown mode is not meant for everyone. However, for folks who have an elevated risk profile - due to who they are, what they work on, or the types of data they work with - it's an excellent tool for further securing themselves. This has some tradeoffs on functionality and utility, but for these users, the tradeoff is worthwhile.
I think Anthropic and OpenAI have found product-market fit
Anthropic are strongly rumored to be about to have their first profitable quarter. Stories are circulating of companies surprised at how expensive their LLM bills are becoming from usage by their staff. I think this is because OpenAI and Anthropic have both found product-market fit.
[... 1,931 words]A bunch of useful stuff in this LLM alpha, but the most important detail is this one:
Most reasoning-capable OpenAI models now use the
/v1/responsesendpoint instead of/v1/chat/completions. This enables interleaved reasoning across tool calls for GPT-5 class models. #1435
This means you can now see the summarized reasoning tokens when you run prompts against an OpenAI model, displayed in a different color to standard error. Use the -R or --hide-reasoning flags if you don't want to see that.
WebRTC is designed to degrade and drop my prompt during poor network conditions.
wtf my dude
WebRTC aggressively drops audio packets to keep latency low. If you’ve ever heard distorted audio on a conference call, that’s WebRTC baybee. The idea is that conference calls depend on rapid back-and-forth, so pausing to wait for audio is unacceptable.
…but as a user, I would much rather wait an extra 200ms for my slow/expensive prompt to be accurate. After all, I’m paying good money to boil the ocean, and a garbage prompt means a garbage response. It’s not like LLMs are particularly responsive anyway.
But I’m not allowed to wait. It’s impossible to even retransmit a WebRTC audio packet within a browser; we tried at Discord. The implementation is hard-coded for real-time latency or else.
— Luke Curley, OpenAI’s WebRTC Problem, in response to How OpenAI delivers low-latency voice AI at scale
So it’s well known that Y Combinator owns some stake in OpenAI. But how big is that stake? This seems like devilishly difficult information to obtain. I asked around and a little birdie who knows several OpenAI investors came back with an answer: Y Combinator owns about 0.6 percent of OpenAI. At OpenAI’s current $852 billion valuation, that’s worth over $5 billion.
— John Gruber, Y Combinator’s Stake in OpenAI
Codex CLI 0.128.0 adds /goal
(via)
The latest version of OpenAI's Codex CLI coding agent adds their own version of the Ralph loop: you can now set a /goal and Codex will keep on looping until it evaluates that the goal has been completed... or the configured token budget has been exhausted.
It looks like the feature is mainly implemented though the goals/continuation.md and goals/budget_limit.md prompts, which are automatically injected at the end of a turn.
Our evaluation of OpenAI’s GPT-5.5 cyber capabilities. The UK's AI Security Institute previously evaluated Claude Mythos: now they've evaluated GPT-5.5 for finding security vulnerability and found it to be comparable to Mythos, but unlike Mythos it's generally available right now.
Never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user's query.
— OpenAI Codex base_instructions, for GPT-5.5
Tracking the history of the now-deceased OpenAI Microsoft AGI clause
For many years, Microsoft and OpenAI’s relationship has included a weird clause saying that, should AGI be achieved, Microsoft’s commercial IP rights to OpenAI’s technology would be null and void. That clause appeared to end today. I decided to try and track its expression over time on openai.com.
[... 691 words]Since GPT-5.4, we’ve unified Codex and the main model into a single system, so there’s no separate coding line anymore.
GPT-5.5 takes this further, with strong gains in agentic coding, computer use, and any task on a computer.
— Romain Huet, confirming OpenAI won't release a GPT-5.5-Codex model