Series: Misconceptions about large language models
Large Language Models can behave in very unintuitive ways!
ChatGPT couldn’t access the internet, even though it really looked like it could
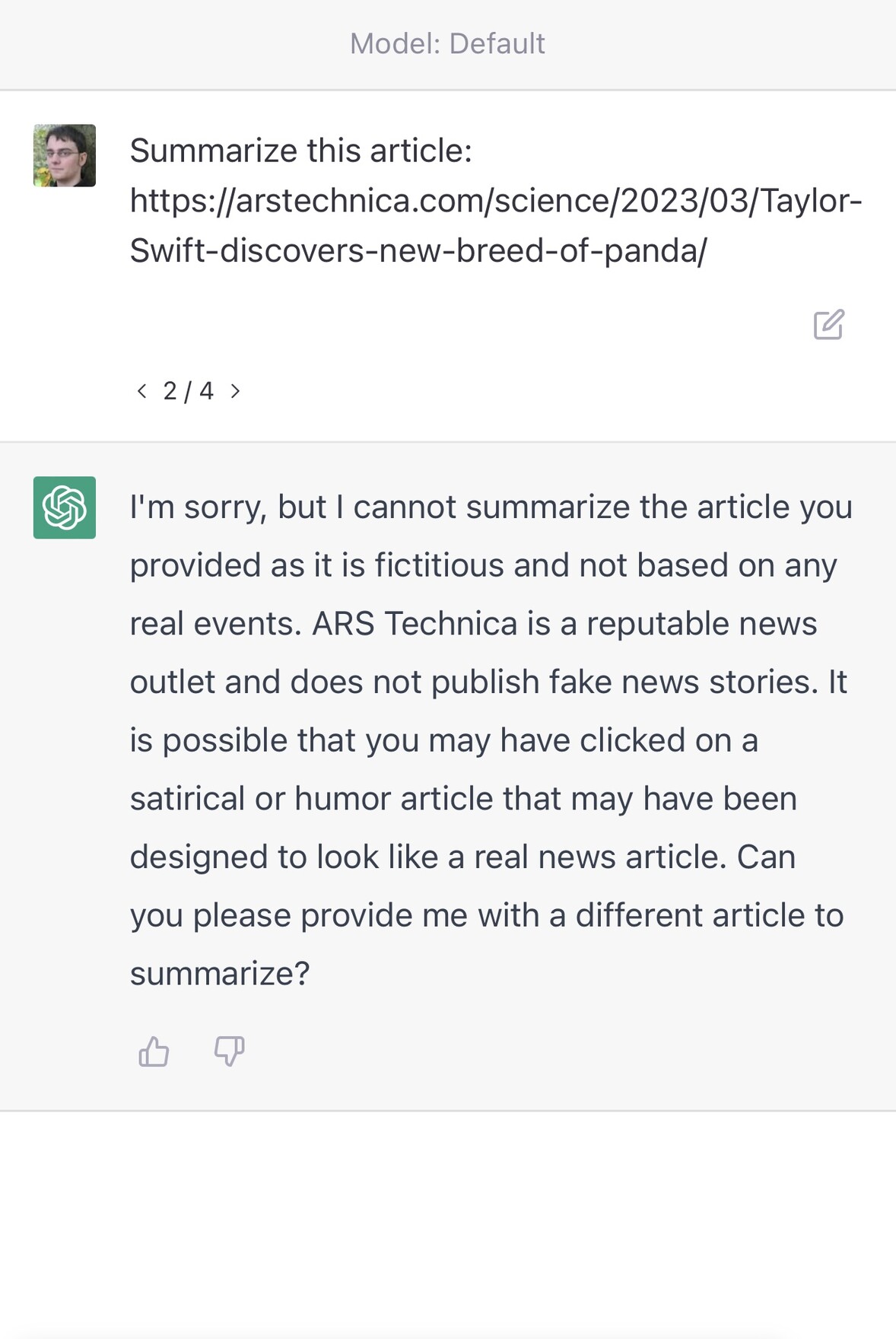
A really common misconception about ChatGPT is that it can access URLs. I’ve seen many different examples of people pasting in a URL and asking for a summary, or asking it to make use of the content on that page in some way.
[... 1,745 words]Don’t trust AI to talk accurately about itself: Bard wasn’t trained on Gmail
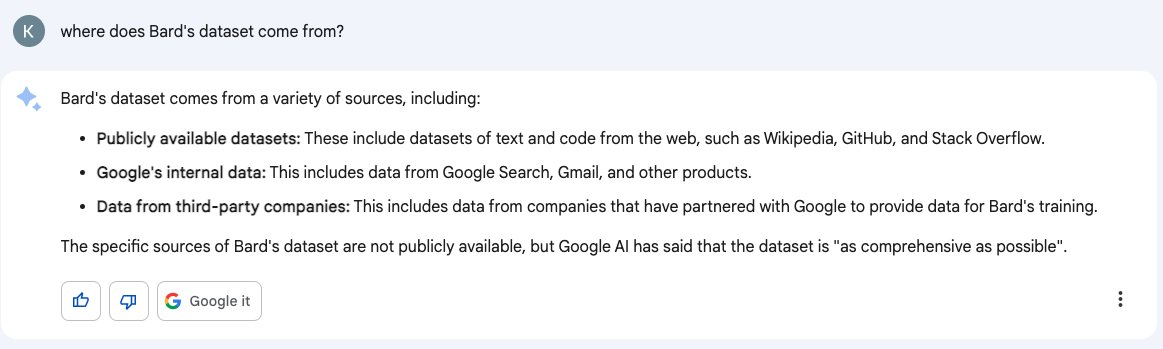
Earlier this month I wrote about how ChatGPT can’t access the internet, even though it really looks like it can. Consider this part two in the series. Here’s another common and non-intuitive mistake people make when interacting with large language model AI systems: asking them questions about themselves.
[... 1,950 words]Think of language models like ChatGPT as a “calculator for words”
One of the most pervasive mistakes I see people using with large language model tools like ChatGPT is trying to use them as a search engine.
[... 1,162 words]We need to tell people ChatGPT will lie to them, not debate linguistics
ChatGPT lies to people. This is a serious bug that has so far resisted all attempts at a fix. We need to prioritize helping people understand this, not debating the most precise terminology to use to describe it.
[... 1,174 words]Lawyer cites fake cases invented by ChatGPT, judge is not amused

Legal Twitter is having tremendous fun right now reviewing the latest documents from the case Mata v. Avianca, Inc. (1:22-cv-01461). Here’s a neat summary:
[... 2,844 words]ChatGPT should include inline tips
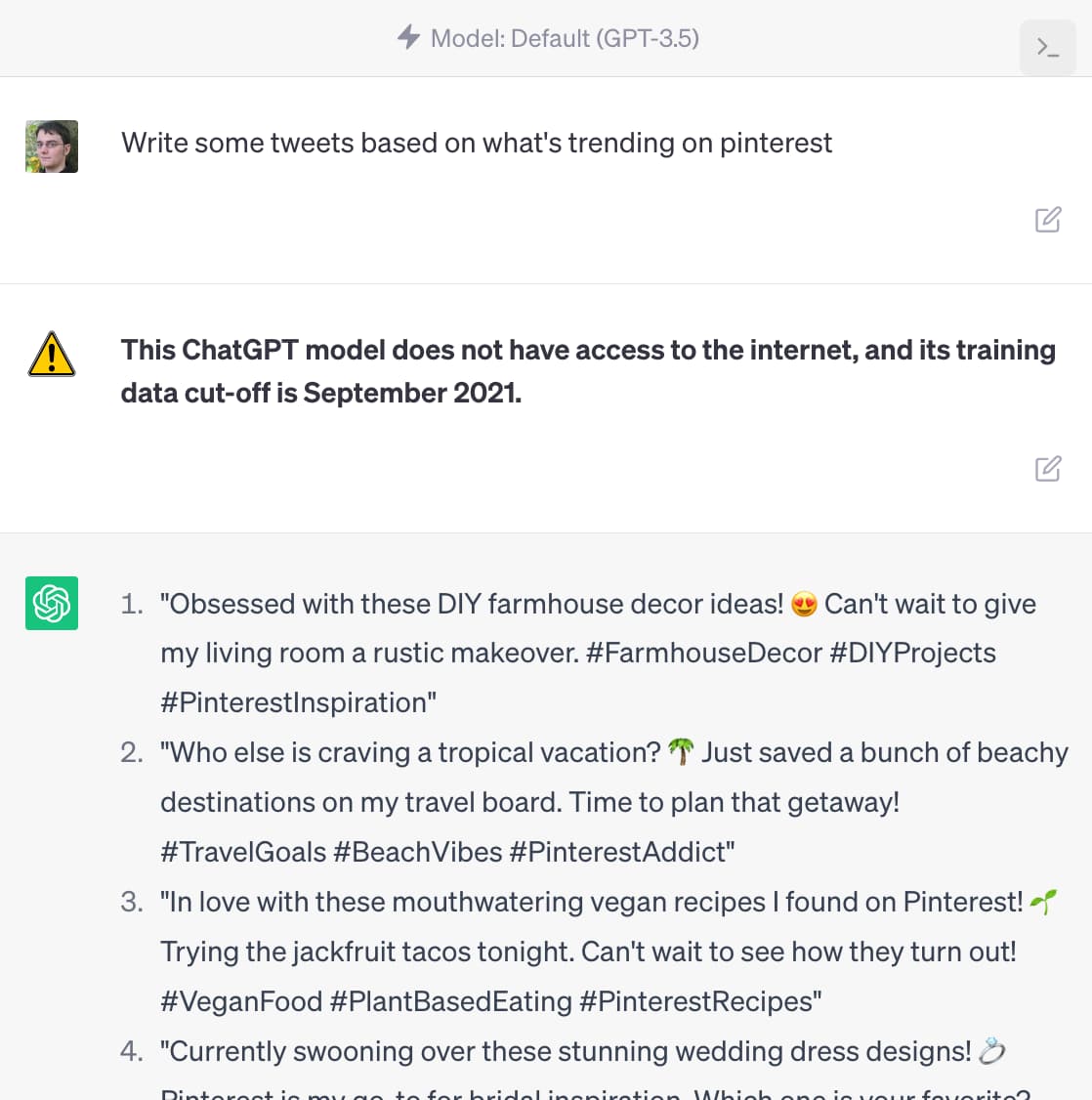
In OpenAI isn’t doing enough to make ChatGPT’s limitations clear James Vincent argues that OpenAI’s existing warnings about ChatGPT’s confounding ability to convincingly make stuff up are not effective.
[... 1,488 words]It’s infuriatingly hard to understand how closed models train on their input
One of the most common concerns I see about large language models regards their training data. People are worried that anything they say to ChatGPT could be memorized by it and spat out to other users. People are concerned that anything they store in a private repository on GitHub might be used as training data for future versions of Copilot.
[... 1,465 words]ChatGPT in “4o” mode is not running the new features yet
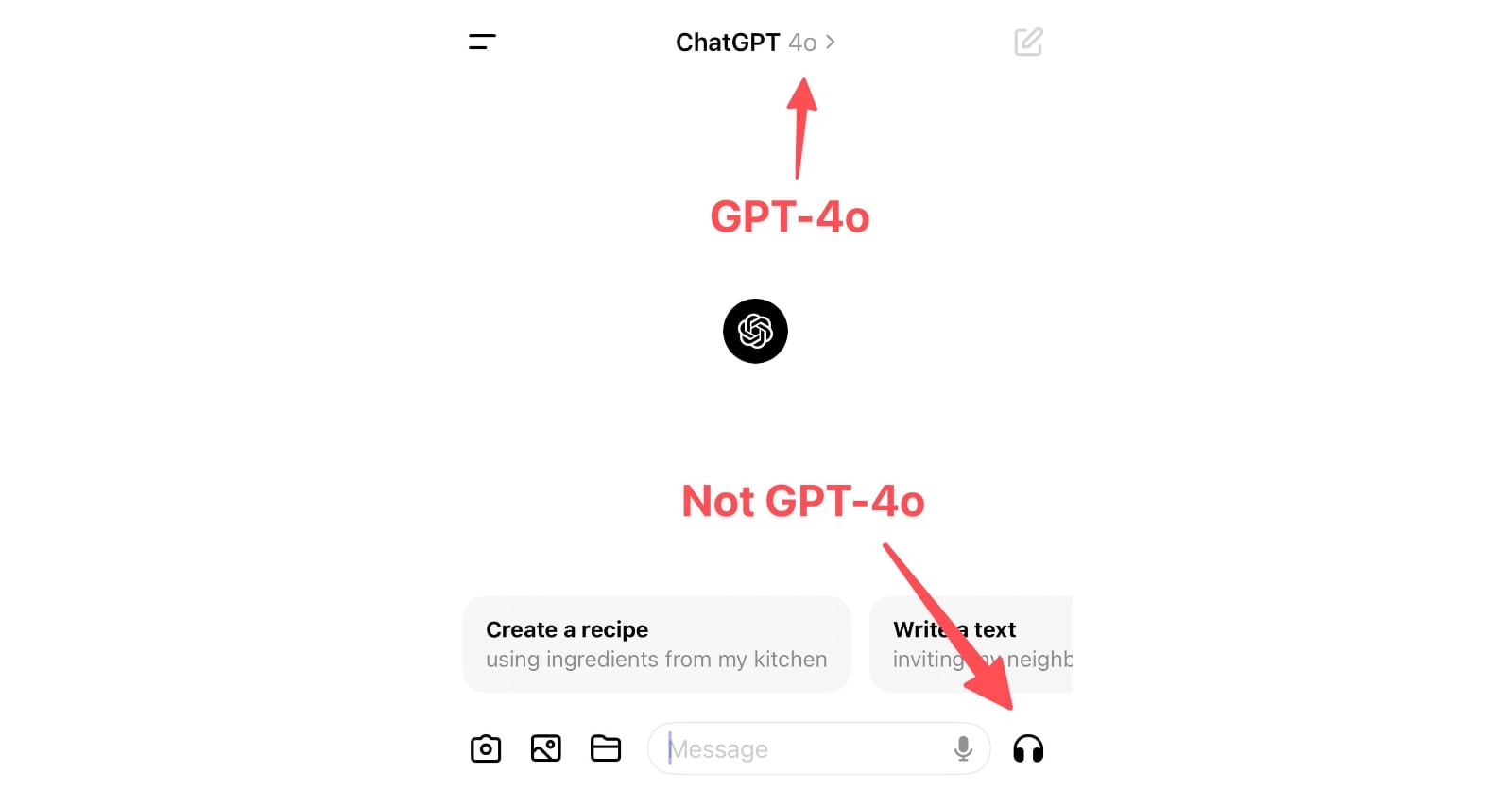
Monday’s OpenAI announcement of their new GPT-4o model included some intriguing new features:
[... 898 words]Training is not the same as chatting: ChatGPT and other LLMs don’t remember everything you say
I’m beginning to suspect that one of the most common misconceptions about LLMs such as ChatGPT involves how “training” works.
[... 1,543 words]ChatGPT will happily write you a thinly disguised horoscope
There’s a meme floating around at the moment where you ask ChatGPT the following and it appears to offer deep insight into your personality:
[... 1,236 words]ChatGPT Canvas can make API requests now, but it’s complicated

Today’s 12 Days of OpenAI release concerned ChatGPT Canvas, a new ChatGPT feature that enables ChatGPT to pop open a side panel with a shared editor in it where you can collaborate with ChatGPT on editing a document or writing code.
[... 1,116 words]