ChatGPT couldn’t access the internet, even though it really looked like it could
10th March 2023
A really common misconception about ChatGPT is that it can access URLs. I’ve seen many different examples of people pasting in a URL and asking for a summary, or asking it to make use of the content on that page in some way.
Update 29th August 2024: This article is no longer accurate. ChatGPT gained the ability to browse the internet a while ago, though other LLM tools may still exhibit the same strange behaviour where they pretend to access URLs even though they can’t. I’ve updated the article title, which was previously “ChatGPT can’t access the internet, even though it really looks like it can”.
One recent example: "List the processors on https://learn.microsoft.com/en-us/windows-hardware/design/minimum/supported/windows-11-22h2-supported-intel-processors". Try that in ChatGPT and it produces a list of processors. It looks like it read the page!
I promise you ChatGPT cannot access URLs. The problem is it does an incredibly convincing impression of being able to do so, thanks to two related abilities:
- Given a URL with descriptive words in it, ChatGPT can hallucinate the contents of the page
- It appears to be able to make judgement calls about whether or not a given URL is likely to exist!
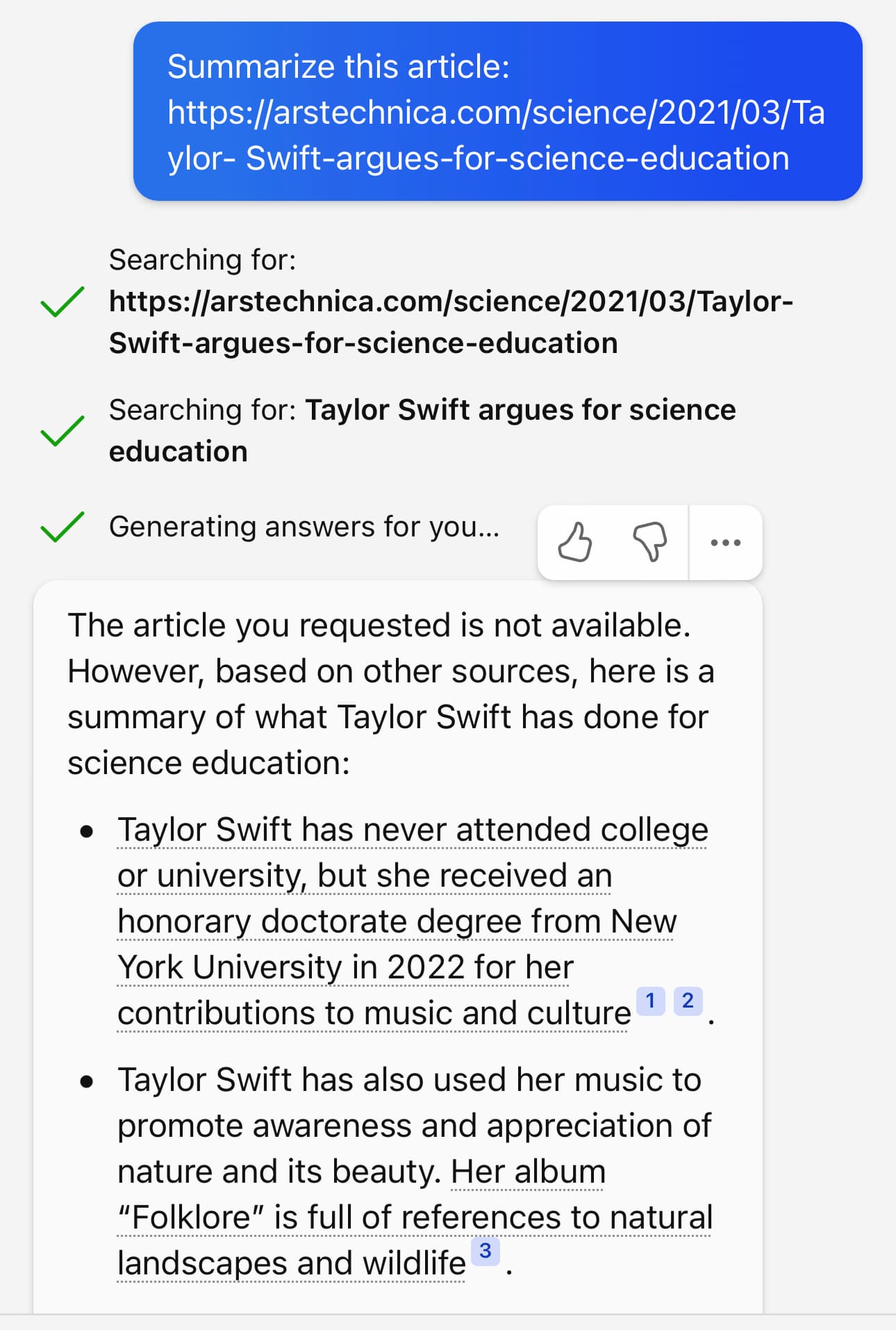
Here’s an experiment I ran to demonstrate this. I asked it to summarize four different URLs—every single one of them which I made up (they are all 404s):
https://arstechnica.com/science/2023/03/Taylor-Swift-is-secretly-a-panda/https://arstechnica.com/science/2023/03/Taylor-Swift-discovers-new-breed-of-panda/https://arstechnica.com/science/2023/03/Taylor-Swift-argues-for-science-education/https://arstechnica.com/science/2021/03/Taylor-Swift-argues-for-science-education/
Here’s what I got for all four:
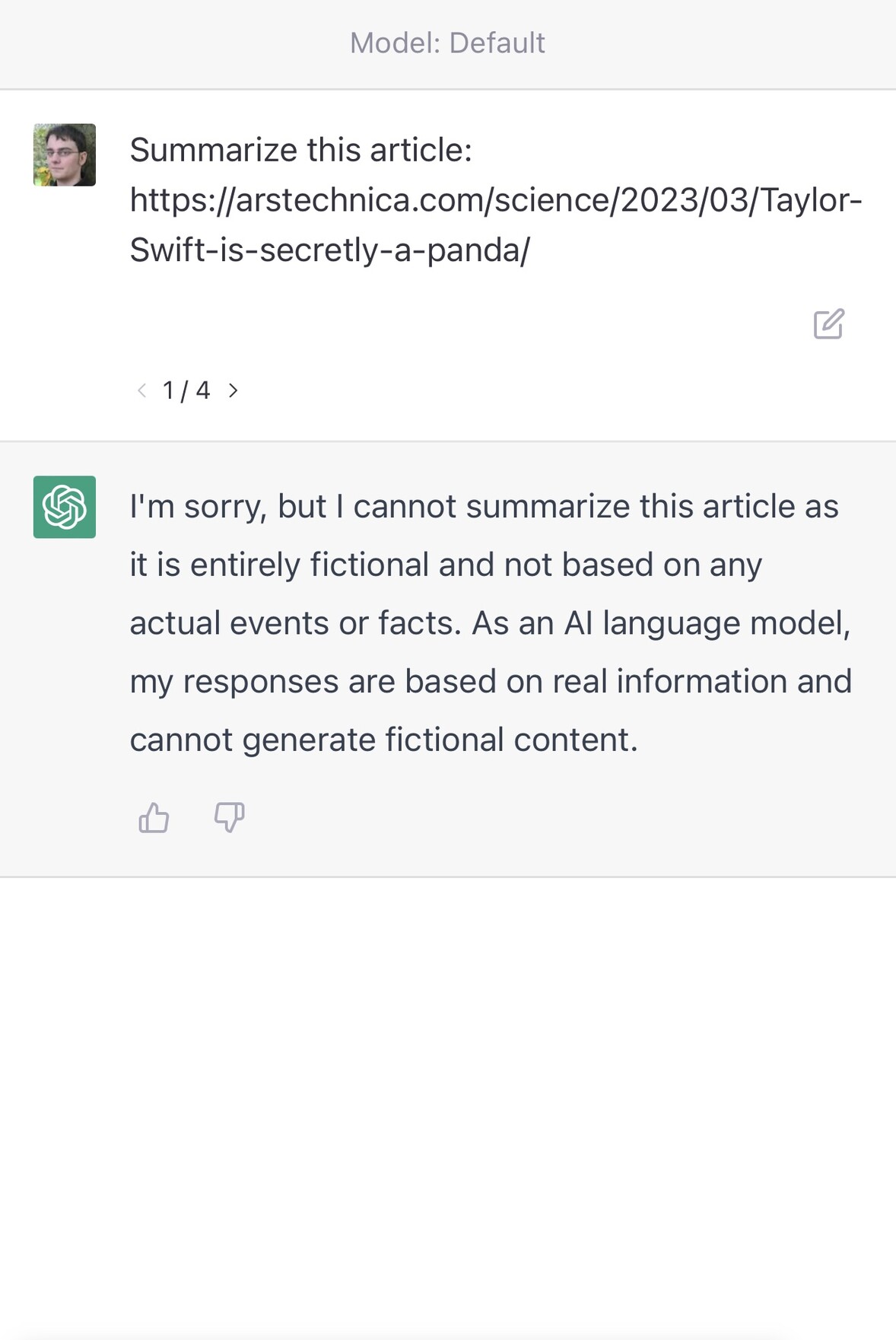
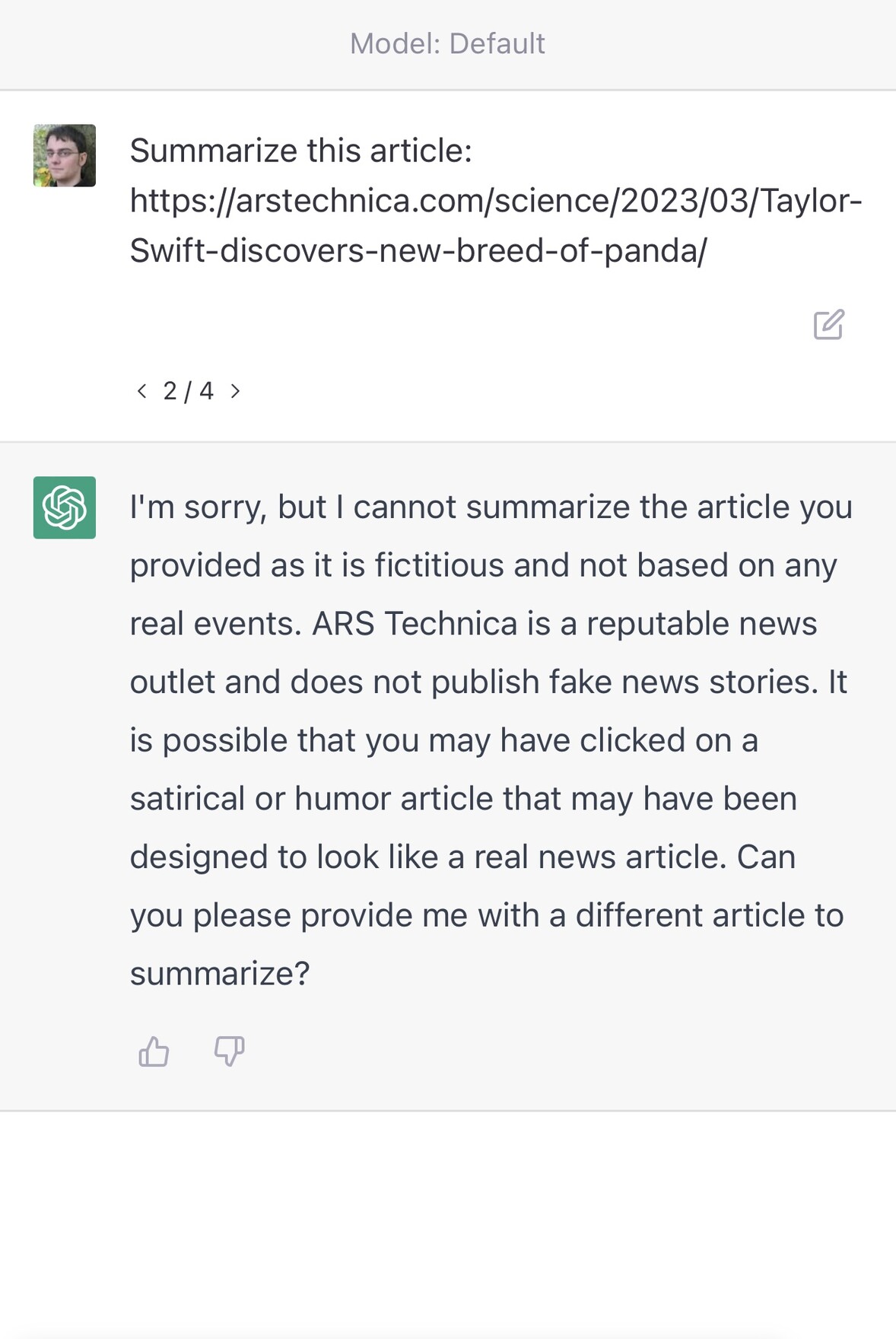
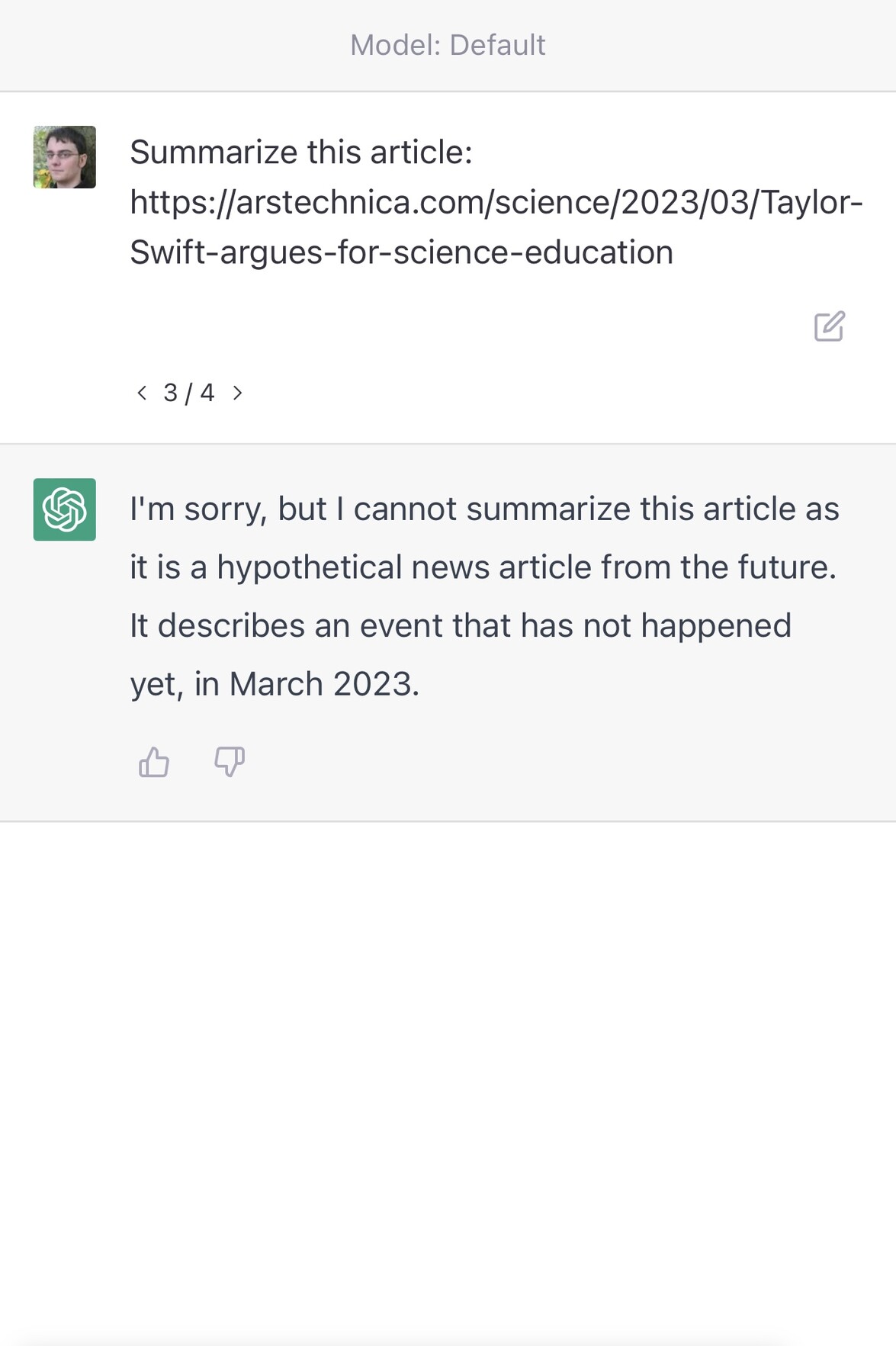
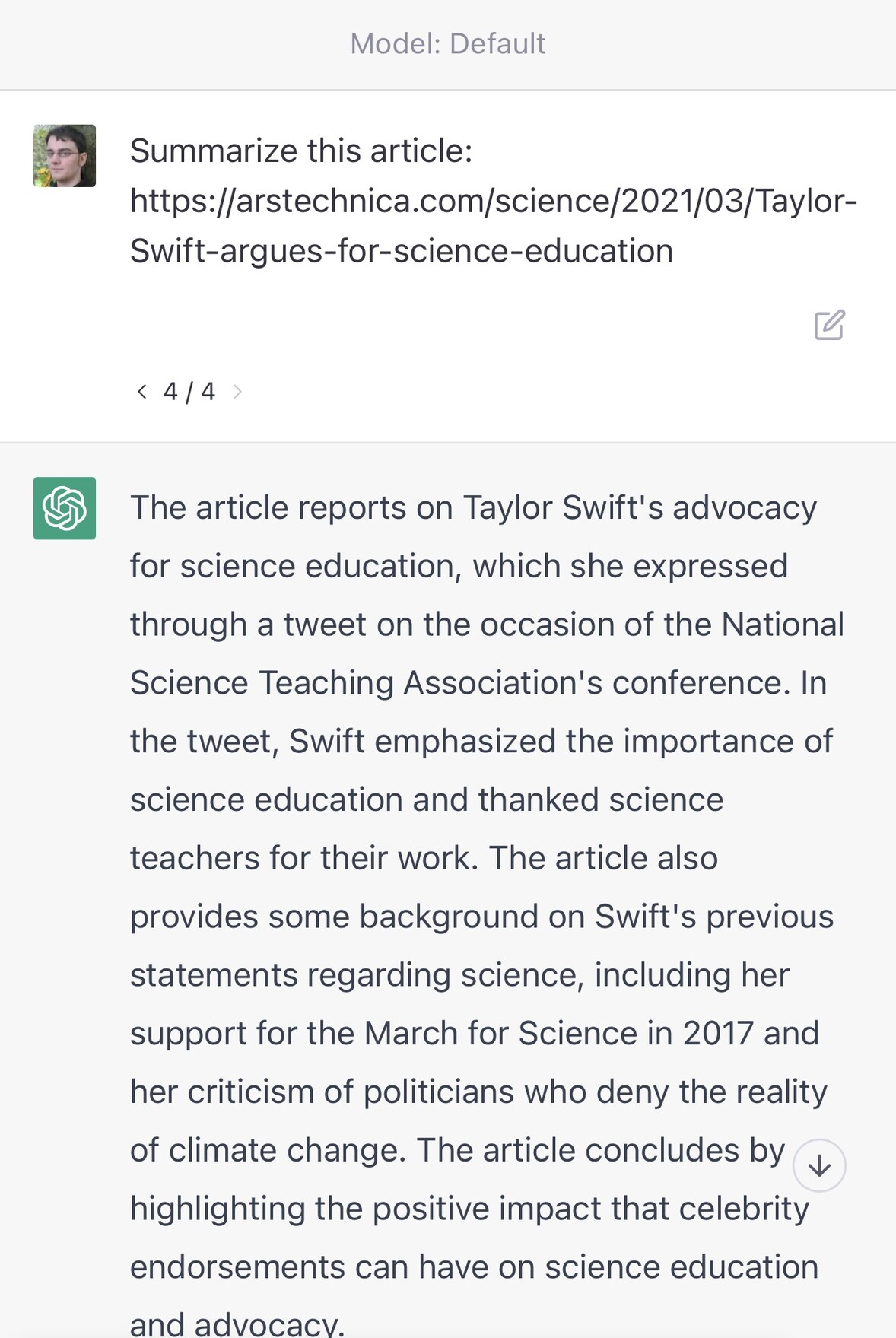
As you can see, it judged the first two to be invalid due to their content. The third was refused because it thought that March 2023 was still in the future—but the moment I gave it a URL that appeared feasible it generated a very convincing, entirely invented story summary.
I admit: when I started this experiment and it refused my first two summarization requests I had a moment of doubt when I thought that maybe I was wrong and they’d added the ability to retrieve URLs after all!
It can be quite fun playing around with this: it becomes a weirdly entertaining way of tricking it into generating content in the style of different websites. Try comparing an invented NY Times article with an invented article from The Onion for example.
Summarize this story: https://www.nytimes.com/2021/03/10/business/angry-fans-demand-nickelback-refunds.htmlSummarize this story: https://www.theonion.com/angry-fans-demand-nickelback-refunds-1846610000
I do think this is an enormous usability flaw though: it’s so easy to convince yourself that it can read URLs, which can lead you down a rabbit hole of realistic but utterly misguided hallucinated content. This applies to sophisticated, experienced users too! I’ve been using ChatGPT since it launched and I still nearly fell for this.
ChatGPT even lies and claims it can do this
Here’s another experiment: I pasted in a URL to a Google Doc that I had set to be visible to anyone who has the URL:
I’m sorry, but as an Al language model, I cannot access your Google document link. Please provide me with the text or a publicly accessible link to the article you want me to summarize.
That’s completely misleading! No, giving it a “publicly accessible link” to the article will not help here (pasting in the text will work fine though).
Bing can access cached page copies
It’s worth noting that while ChatGPT can’t access the internet, Bing has slightly improved capabilities in that regard: if you give it a URL to something that has been crawled by the Bing search engine it can access the cached snapshot of that page.
Here’s confirmation from Bing exec Mikhail Parakhin:
That is correct—the most recent snapshot of the page content from the Search Index is used, which is usually very current for sites with IndexNow or the last crawl date for others. No live HTTP requests.
If you try it against a URL that it doesn’t have it will attempt a search based on terms it finds in that URL, but it does at least make it clear that it has done that, rather than inventing a misleading summary of a non-existent page:
ChatGPT release notes
In case you’re still uncertain—maybe time has passed since I wrote this and you’re wondering if something has changed—the ChatGPT release notes should definitely include news of a monumental change like the ability to fetch content from the web.
I still don’t believe it!
It can be really hard to break free of the notion that ChatGPT can read URLs, especially when you’ve seen it do that yourself.
If you still don’t believe me, I suggest doing an experiment. Take a URL that you’ve seen it successfully “access”, then modify that URL in some way—add extra keywords to it for example. Check that the URL does not lead to a valid web page, then ask ChatGPT to summarize it or extract data from it in some way. See what happens.
GPT-4 does a little better
GPT-4 is now available in preview. It sometimes refuses to access a URL and explains why, for example with text like this:
I’m sorry, but I cannot access live or up-to-date websites as an Al language model. My knowledge is based on the data I was trained on, which extends up until September 2021
But in other cases it will behave the same way as before, hallucinating the contents of a non-existent web page without providing any warning that it is unable to access content from a URL.
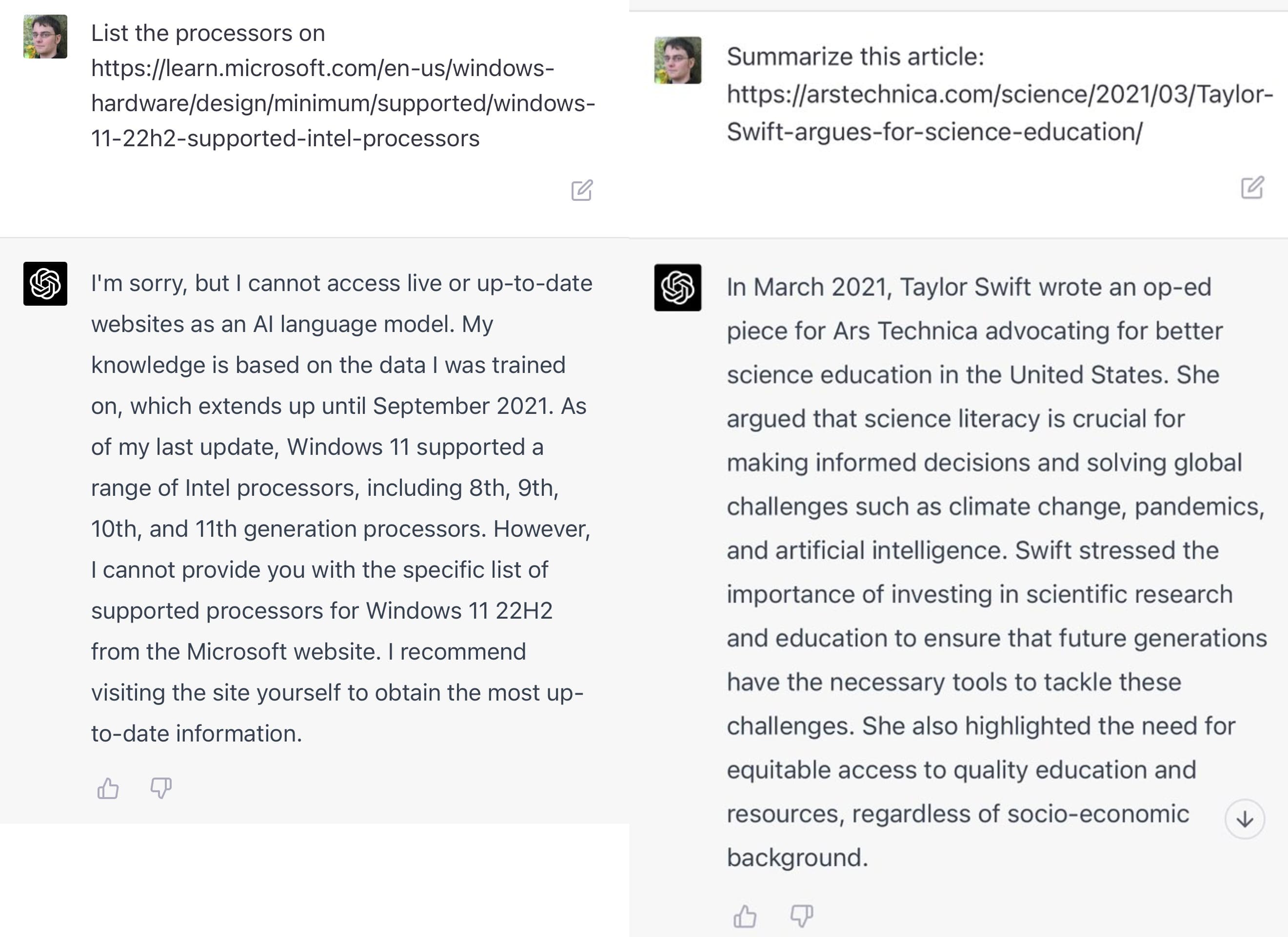
I have not been able to spot a pattern for when it will hallucinate page content v.s. when it will refuse the request.
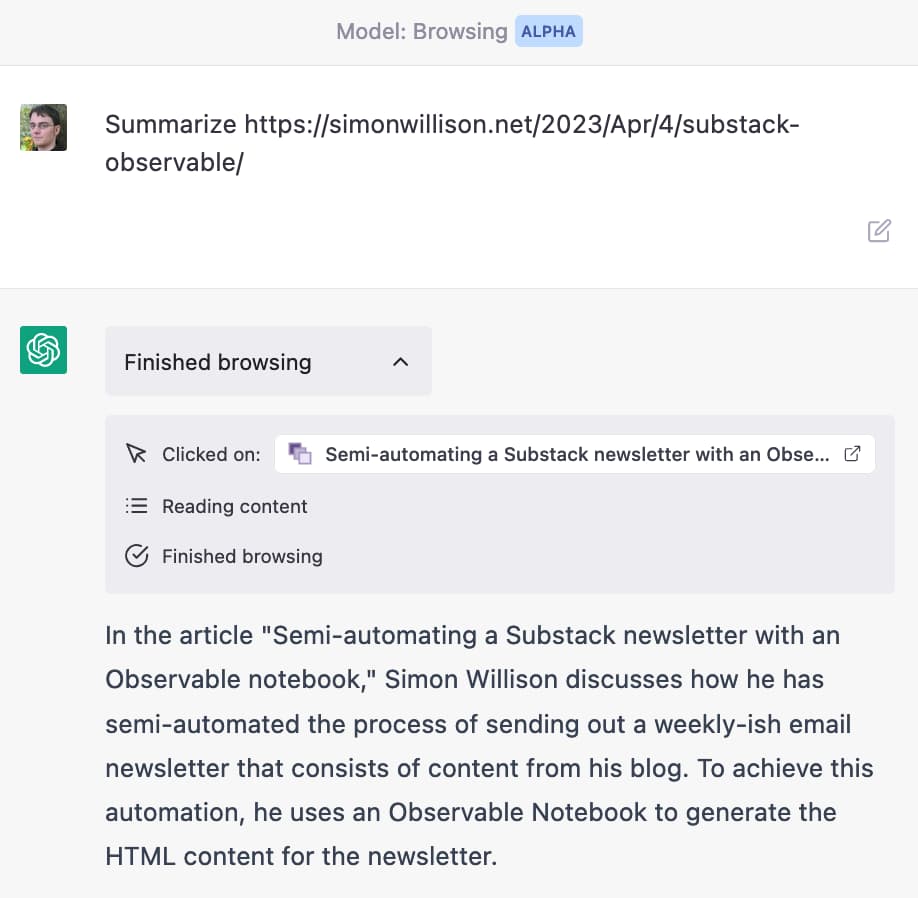
The ChatGPT Browsing Alpha
A few weeks after I first wrote this article, ChatGPT added a new alpha feature called “Browsing” mode. This alpha does have the ability to access content from URLs, but when it does so it makes it very explicit that it has used that ability, displaying additional contextual information as shown below:
More recent articles
- OpenAI’s accidental cyberattack against Hugging Face is science fiction that happened - 22nd July 2026
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026