Large language models are having their Stable Diffusion moment
11th March 2023
The open release of the Stable Diffusion image generation model back in August 2022 was a key moment. I wrote how Stable Diffusion is a really big deal at the time.
People could now generate images from text on their own hardware!
More importantly, developers could mess around with the guts of what was going on.
The resulting explosion in innovation is still going on today. Most recently, ControlNet appears to have leapt Stable Diffusion ahead of Midjourney and DALL-E in terms of its capabilities.
It feels to me like that Stable Diffusion moment back in August kick-started the entire new wave of interest in generative AI—which was then pushed into over-drive by the release of ChatGPT at the end of November.
That Stable Diffusion moment is happening again right now, for large language models—the technology behind ChatGPT itself.
This morning I ran a GPT-3 class language model on my own personal laptop for the first time!
AI stuff was weird already. It’s about to get a whole lot weirder.
LLaMA
Somewhat surprisingly, language models like GPT-3 that power tools like ChatGPT are a lot larger and more expensive to build and operate than image generation models.
The best of these models have mostly been built by private organizations such as OpenAI, and have been kept tightly controlled—accessible via their API and web interfaces, but not released for anyone to run on their own machines.
These models are also BIG. Even if you could obtain the GPT-3 model you would not be able to run it on commodity hardware—these things usually require several A100-class GPUs, each of which retail for $8,000+.
This technology is clearly too important to be entirely controlled by a small group of companies.
There have been dozens of open large language models released over the past few years, but none of them have quite hit the sweet spot for me in terms of the following:
- Easy to run on my own hardware
- Large enough to be useful—ideally equivalent in capabilities to GPT-3
- Open source enough that they can be tinkered with
This all changed yesterday, thanks to the combination of Facebook’s LLaMA model and llama.cpp by Georgi Gerganov.
Here’s the abstract from the LLaMA paper:
We introduce LLaMA, a collection of foundation language models ranging from 7B to 65B parameters. We train our models on trillions of tokens, and show that it is possible to train state-of-the-art models using publicly available datasets exclusively, without resorting to proprietary and inaccessible datasets. In particular, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla-70B and PaLM-540B. We release all our models to the research community.
It’s important to note that LLaMA isn’t fully “open”. You have to agree to some strict terms to access the model. It’s intended as a research preview, and isn’t something which can be used for commercial purposes.
In a totally cyberpunk move, within a few days of the release, someone submitted this PR to the LLaMA repository linking to an unofficial BitTorrent download link for the model files!
So they’re in the wild now. You may not be legally able to build a commercial product on them, but the genie is out of the bottle. That furious typing sound you can hear is thousands of hackers around the world starting to dig in and figure out what life is like when you can run a GPT-3 class model on your own hardware.
llama.cpp
LLaMA on its own isn’t much good if it’s still too hard to run it on a personal laptop.
Enter Georgi Gerganov.
Georgi is an open source developer based in Sofia, Bulgaria (according to his GitHub profile). He previously released whisper.cpp, a port of OpenAI’s Whisper automatic speech recognition model to C++. That project made Whisper applicable to a huge range of new use cases.
He’s just done the same thing with LLaMA.
Georgi’s llama.cpp project had its initial release yesterday. From the README:
The main goal is to run the model using 4-bit quantization on a MacBook.
4-bit quantization is a technique for reducing the size of models so they can run on less powerful hardware. It also reduces the model sizes on disk—to 4GB for the 7B model and just under 8GB for the 13B one.
It totally works!
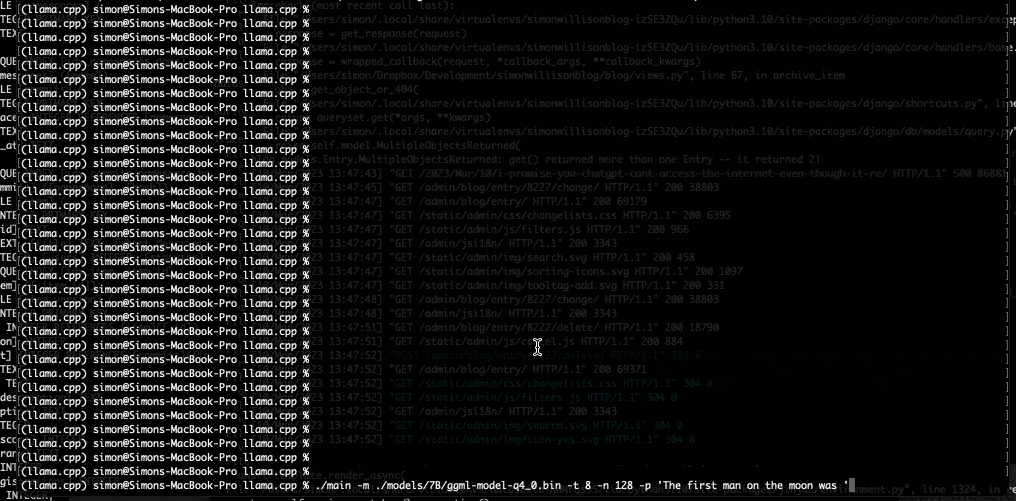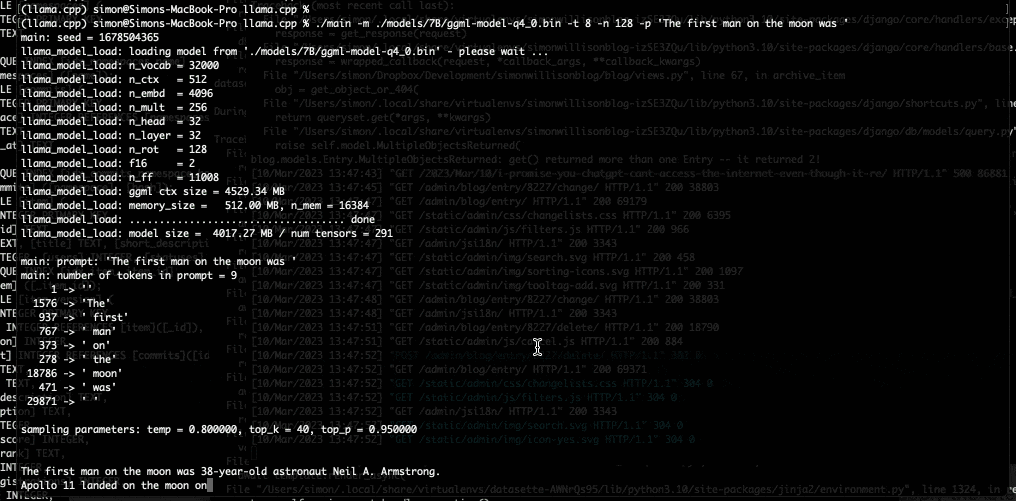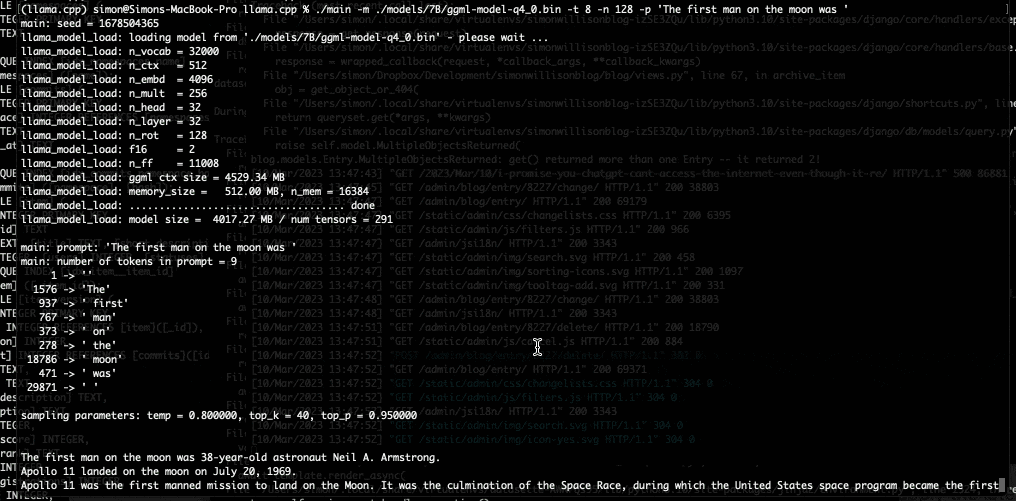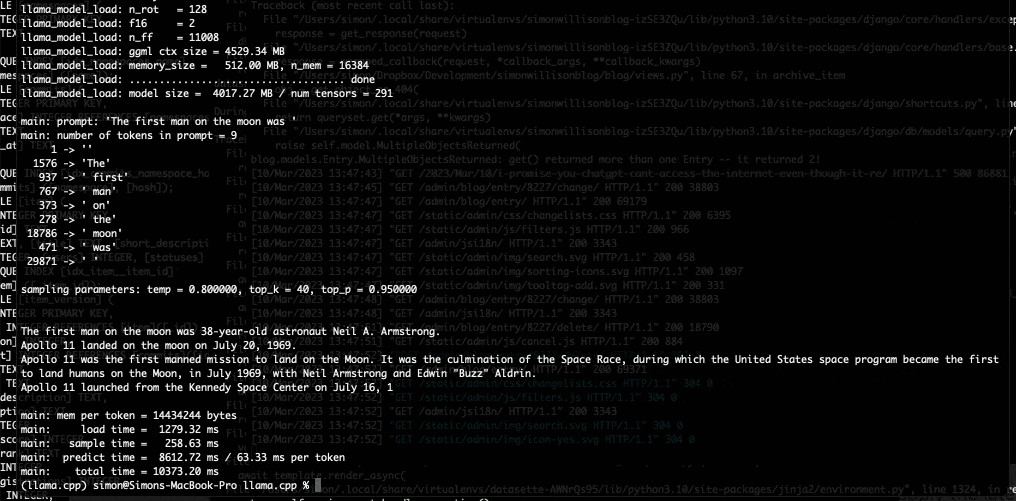
I used it to run the 7B LLaMA model on my laptop last night, and then this morning upgraded to the 13B model—the one that Facebook claim is competitive with GPT-3.
Here are my detailed notes on how I did that—most of the information I needed was already there in the README.
As my laptop started to spit out text at me I genuinely had a feeling that the world was about to change, again.
I thought it would be a few more years before I could run a GPT-3 class model on hardware that I owned. I was wrong: that future is here already.
Is this the worst thing that ever happened?
I’m not worried about the science fiction scenarios here. The language model running on my laptop is not an AGI that’s going to break free and take over the world.
But there are a ton of very real ways in which this technology can be used for harm. Just a few:
- Generating spam
- Automated romance scams
- Trolling and hate speech
- Fake news and disinformation
- Automated radicalization (I worry about this one a lot)
Not to mention that this technology makes things up exactly as easily as it parrots factual information, and provides no way to tell the difference.
Prior to this moment, a thin layer of defence existed in terms of companies like OpenAI having a limited ability to control how people interacted with those models.
Now that we can run these on our own hardware, even those controls are gone.
How do we use this for good?
I think this is going to have a huge impact on society. My priority is trying to direct that impact in a positive direction.
It’s easy to fall into a cynical trap of thinking there’s nothing good here at all, and everything generative AI is either actively harmful or a waste of time.
I’m personally using generative AI tools on a daily basis now for a variety of different purposes. They’ve given me a material productivity boost, but more importantly they have expanded my ambitions in terms of projects that I take on.
I used ChatGPT to learn enough AppleScript to ship a new project in less than an hour just last week!
I’m going to continue exploring and sharing genuinely positive applications of this technology. It’s not going to be un-invented, so I think our priority should be figuring out the most constructive possible ways to use it.
What to look for next
Assuming Facebook don’t relax the licensing terms, LLaMA will likely end up more a proof-of-concept that local language models are feasible on consumer hardware than a new foundation model that people use going forward.
The race is on to release the first fully open language model that gives people ChatGPT-like capabilities on their own devices.
Quoting Stable Diffusion backer Emad Mostaque:
Wouldn’t be nice if there was a fully open version eh
It’s happening already...
I published this article on Saturday 11th March 2023. On Sunday, Artem Andreenko got it running on a RaspberryPi with 4GB of RAM:
I’ve sucefully runned LLaMA 7B model on my 4GB RAM Raspberry Pi 4. It’s super slow about 10sec/token. But it looks we can run powerful cognitive pipelines on a cheap hardware. pic.twitter.com/XDbvM2U5GY
- Artem Andreenko 🇺🇦 (@miolini) March 12, 2023
Then on Monday, Anish Thite got it working on a Pixel 6 phone (at 26s/token):
@ggerganov’s LLaMA works on a Pixel 6!
- anishmaxxing (@thiteanish) March 13, 2023
LLaMAs been waiting for this, and so have I pic.twitter.com/JjEhdzJ2B9
And then a research lab at Stanford released Alpaca—an instruction fine-tuned version of the model. I wrote more about that in a follow-up post: Stanford Alpaca, and the acceleration of on-device large language model development.
Follow my work
Everything I write on my blog goes out in my Atom feed, and I have a very active Mastodon account, plus a Twitter account (@simonw) where I continue to post links to new things I’ve written.
I’m also starting a newsletter at simonw.substack.com. I plan to send out everything from my blog on a weekly basis, so if email is your preferred way to stay up-to-date you can subscribe there.
More stuff I’ve written
My Generative AI tag has everything, but here are some relevant highlights from the past year:
- A Datasette tutorial written by GPT-3—31 May 2022
- How to use the GPT-3 language model—5 Jun 2022
- First impressions of DALL-E, generating images from text—23 Jun 2022
- Using GPT-3 to explain how code works—9 Jul 2022
- Stable Diffusion is a really big deal—29 Aug 2022
- Exploring the training data behind Stable Diffusion—5 Sep 2022
- Prompt injection attacks against GPT-3—12 Sep 2022
- A tool to run caption extraction against online videos using Whisper and GitHub Issues/Actions—30 Sep 2022
- Is the AI spell-casting metaphor harmful or helpful?—5 Oct 2022
- A new AI game: Give me ideas for crimes to do—4 Dec 2022
- AI assisted learning: Learning Rust with ChatGPT, Copilot and Advent of Code—5 Dec 2022
- How to implement Q&A against your documentation with GPT3, embeddings and Datasette—13 Jan 2023
- Bing: “I will not harm you unless you harm me first”—15 Feb 2023
- I talked about Bing and tried to explain language models on live TV!—19 Feb 2023
- In defense of prompt engineering—21 Feb 2023
- Thoughts and impressions of AI-assisted search from Bing—24 Feb 2023
- Weeknotes: NICAR, and an appearance on KQED Forum—7 Mar 2023
- ChatGPT can’t access the internet, even though it really looks like it can—10 Mar 2023
More recent articles
- OpenAI’s accidental cyberattack against Hugging Face is science fiction that happened - 22nd July 2026
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026