Stanford Alpaca, and the acceleration of on-device large language model development
13th March 2023
On Saturday 11th March I wrote about how Large language models are having their Stable Diffusion moment. Today is Monday. Let’s look at what’s happened in the past three days.
- Later on Saturday: Artem Andreenko reports that
llama.cppcan run the 4-bit quantized 7B LLaMA language model model on a 4GB RaspberryPi—at 10 seconds per token, but still hugely impressive. - Sunday 12th March: cocktailpeanut releases Dalai, a “dead simple way to run LLaMA on your computer”:
npx dalai llamaandnpx dalai serve. - 13th March (today): Anish Thite reports
llama.cpprunning on a Pixel 6 phone (26 seconds per token). Update 14th March: Now 1 second per token on an older Pixel 5! - Also today: a team at Stanford released Alpaca: A Strong Open-Source Instruction-Following Model—fine-tuned from the LLaMA 7B model.
When I talked about a “Stable Diffusion moment” this is the kind of thing I meant: the moment this stuff is available for people to experiment with, things accelerate.
I’m going to dive into Alpaca in detail.
Stanford’s Alpaca
Here’s the introduction to the Alpaca announcement:
We introduce Alpaca 7B, a model fine-tuned from the LLaMA 7B model on 52K instruction-following demonstrations. Alpaca behaves similarly to OpenAI’s text-davinci-003, while being surprisingly small and easy/cheap to reproduce (<600$).
The biggest weakness in the LLaMA models released by Meta research last month is their lack of instruction-tuning.
A language model is a sentence completion engine. You give it a sequence of words, “The first man on the moon was”, and it completes that sentence, hopefully with useful content.
One of the great innovations from OpenAI was their application of instruction tuning to GPT-3:
To make our models safer, more helpful, and more aligned, we use an existing technique called reinforcement learning from human feedback (RLHF). On prompts submitted by our customers to the API, our labelers provide demonstrations of the desired model behavior, and rank several outputs from our models. We then use this data to fine-tune GPT-3.
Prior to this, you had to think very carefully about how to construct your prompts. Thanks to instruction tuning you can be a lot more, well, human in the way you interact with the model. “Write me a poem about pandas!” now works as a prompt, instead of “Here is a poem about pandas:”.
The LLaMA models had not been through this process. The LLaMA FAQ acknowledges this:
Keep in mind these models are not finetuned for question answering. As such, they should be prompted so that the expected answer is the natural continuation of the prompt. [...] Overall, always keep in mind that models are very sensitive to prompts (particularly when they have not been finetuned).
This is an enormous usability problem.
One of my open questions about LLaMA was how difficult and expensive it would be to fine-tune it such that it could respond better to instructions.
Thanks to the team at Stanford we now have an answer: 52,000 training samples and $100 of training compute! From their blog post:
Fine-tuning a 7B LLaMA model took 3 hours on 8 80GB A100s, which costs less than $100 on most cloud compute providers.
Something that stuns me about Alpaca is the quality they claim to be able to get from the 7B model—the smallest of the LLaMA models, and the one which has been seen running (albeit glacially slowly) on a RaspberryPi and a mobile phone! Here’s one example from their announcement:
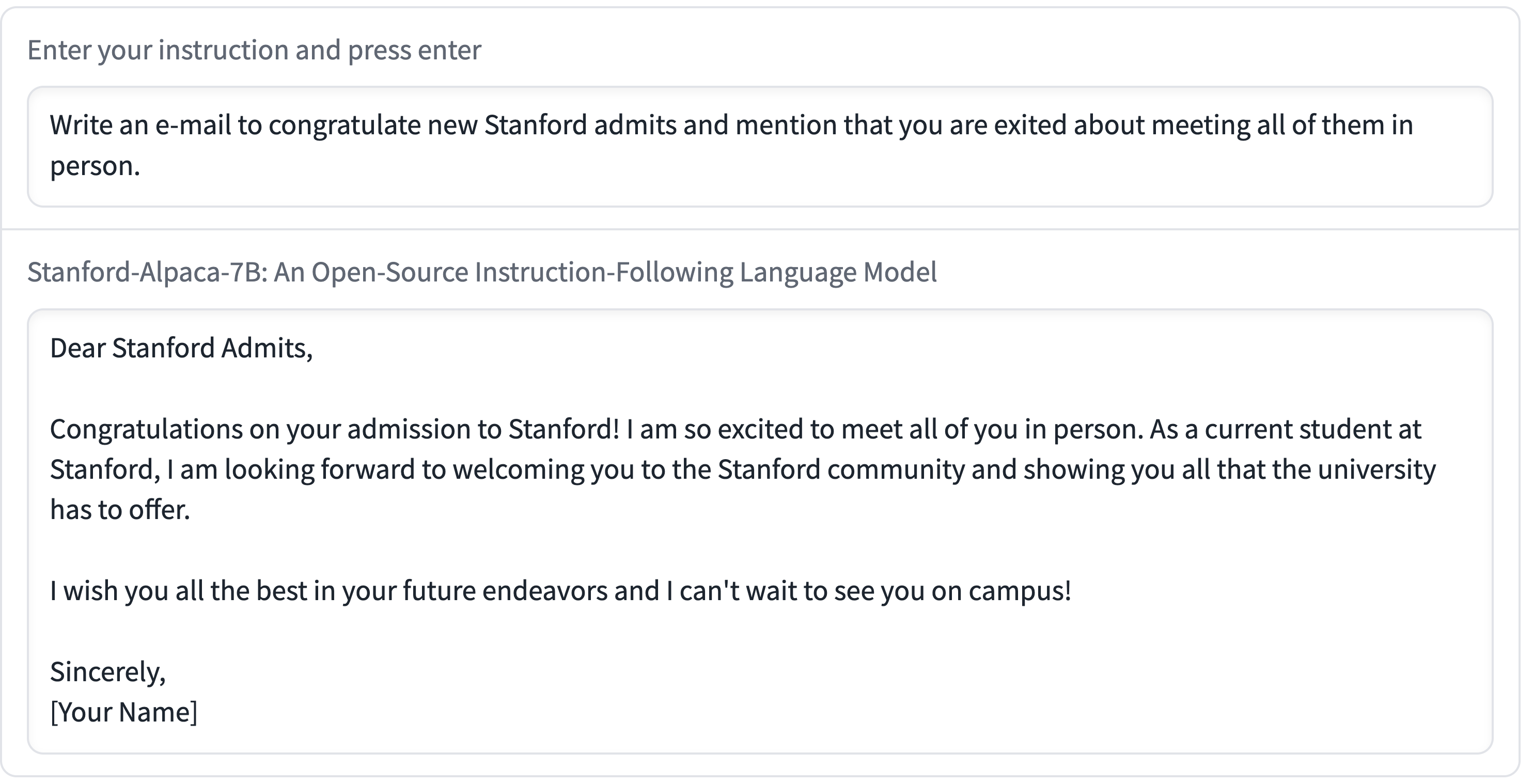
I would be impressed to see this from the 65B (largest) LLaMA model—but getting this from 7B is spectacular.
Still not for commercial usage
I’ll quote the Stanford announcement on this in full:
We emphasize that Alpaca is intended only for academic research and any commercial use is prohibited. There are three factors in this decision: First, Alpaca is based on LLaMA, which has a non-commercial license, so we necessarily inherit this decision. Second, the instruction data is based OpenAI’s text-davinci-003, whose terms of use prohibit developing models that compete with OpenAI. Finally, we have not designed adequate safety measures, so Alpaca is not ready to be deployed for general use.
So it’s still not something we can use to build commercial offerings—but for personal research and tinkering it’s yet another huge leap forwards.
What does this demonstrate?
The license of the LLaMA model doesn’t bother me too much. What’s exciting to me is what this all proves:
- LLaMA itself shows that it’s possible to train a GPT-3 class language model using openly available resources. The LLaMA paper includes details of the training data, which is entirely from publicly available sources (which include CommonCrawl, GitHub, Wikipedia, ArXiv and StackExchange).
- llama.cpp shows that you can then use some tricks to run that language model on consumer hardware—apparently anything with 4GB or more of RAM is enough to at least get it to start spitting out tokens!
- Alpaca shows that you can apply fine-tuning with a feasible sized set of examples (52,000) and cost ($100) such that even the smallest of the LLaMA models—the 7B one, which can compress down to a 4GB file with 4-bit quantization—provides results that compare well to cutting edge
text-davinci-003in initial human evaluation.
One thing that’s worth noting: the Alpaca 7B comparison likely used the full-sized 13.48GB 16bit floating point 7B model, not the 4GB smaller 4bit floating point model used by llama.cpp. I’ve not yet seen a robust comparison of quality between the two.
Exploring the Alpaca training data with Datasette Lite
The Alpaca team released the 52,000 fine-tuning instructions they used as a 21.7MB JSON file in their GitHub repository.
My Datasette Lite tool has the ability to fetch JSON from GitHub and load it into an in-browser SQLite database. Here’s the URL to do that:
This will let you browse the 52,000 examples in your browser.
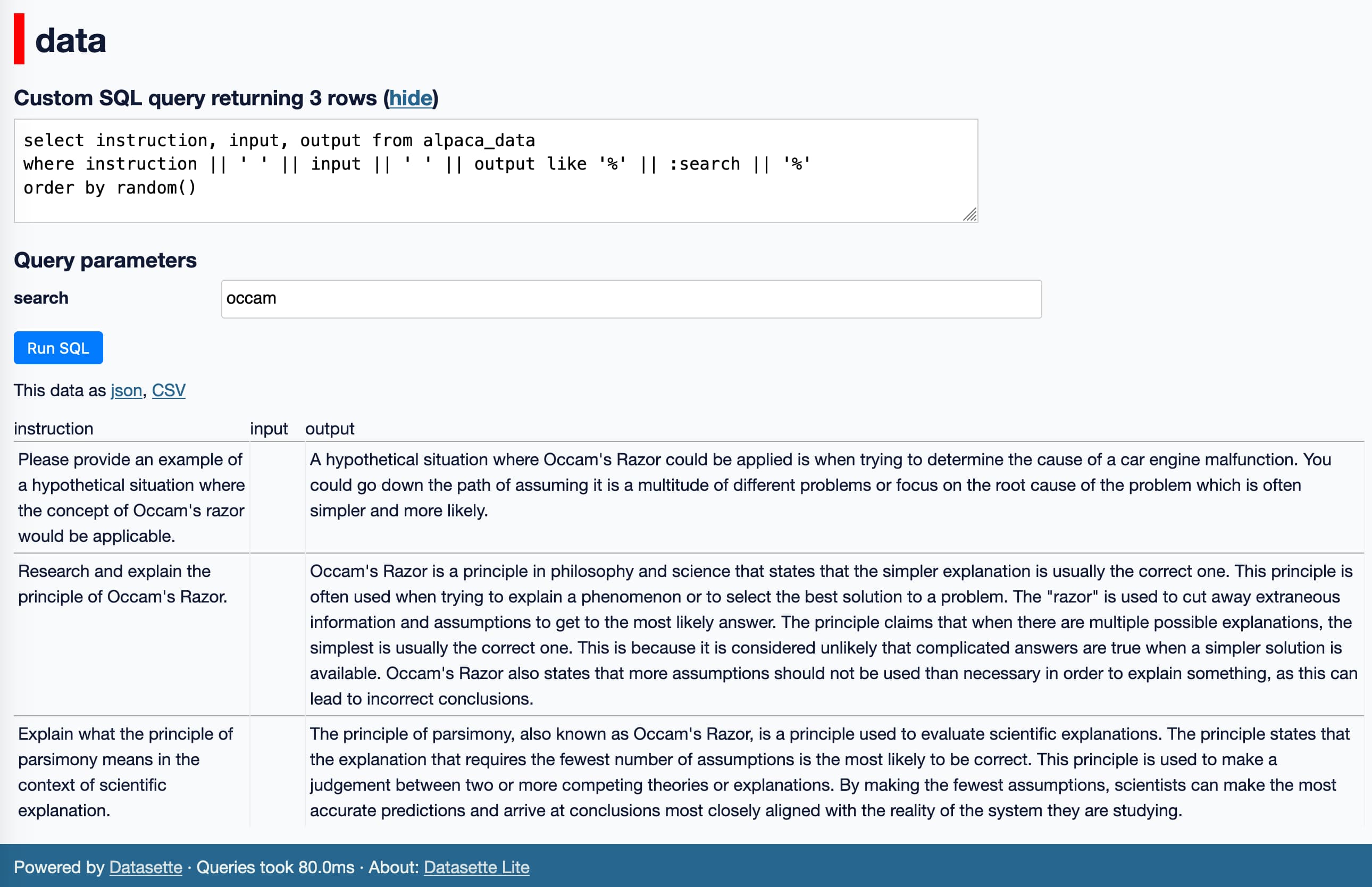
But we can do a step better than that: here’s a SQL query that runs LIKE queries to search through those examples, considering all three text columns:
select instruction, input, output from alpaca_data
where instruction || ' ' || input || ' ' || output like '%' || :search || '%'
order by random()I’m using order by random() because why not? It’s more fun to explore that way.
The following link will both load the JSON file and populate and execute that SQL query, plus allow you to change the search term using a form in your browser:
What’s next?
This week is likely to be wild. OpenAI are rumored to have a big announcement on Tuesday—possibly GPT-4? And I’ve heard rumors of announcements from both Anthropic and Google this week as well.
I’m still more excited about seeing what happens next with LLaMA. Language models on personal devices is happening so much faster than I thought it would.
Bonus: The source of that training data? GPT-3!
Here’s a fascinating detail: Those 52,000 samples they used to fine-tune the model? Those were the result of a prompt they ran against GPT-3 itself! Here’s the prompt they used:
You are asked to come up with a set of 20 diverse task instructions. These task instructions will be given to a GPT model and we will evaluate the GPT model for completing the instructions. Here are the requirements: 1. Try not to repeat the verb for each instruction to maximize diversity. 2. The language used for the instruction also should be diverse. For example, you should combine questions with imperative instrucitons. 3. The type of instructions should be diverse. The list should include diverse types of tasks like open-ended generation, classification, editing, etc. 2. A GPT language model should be able to complete the instruction. For example, do not ask the assistant to create any visual or audio output. For another example, do not ask the assistant to wake you up at 5pm or set a reminder because it cannot perform any action. 3. The instructions should be in English. 4. The instructions should be 1 to 2 sentences long. Either an imperative sentence or a question is permitted. 5. You should generate an appropriate input to the instruction. The input field should contain a specific example provided for the instruction. It should involve realistic data and should not contain simple placeholders. The input should provide substantial content to make the instruction challenging but should ideally not exceed 100 words. 6. Not all instructions require input. For example, when a instruction asks about some general information, "what is the highest peak in the world", it is not necssary to provide a specific context. In this case, we simply put "<noinput>" in the input field. 7. The output should be an appropriate response to the instruction and the input. Make sure the output is less than 100 words. List of 20 tasks:
Then they include three random example instructions from a list of 175 they had prepared by hand. The completed prompt sent to OpenAI would include the above instructions followed by something like this:
### 1. Instruction: Explain the following idiom to me, and try to give me some examples. 1. Input: black sheep 1. Output: Meaning: An outcast. Someone who doesn’t fit in with the rest of the crowd. They take pride in being different. Thinks for themselves and doesn’t care what no one else has to say. They tend to ride their own wave and are usually loners because no one understands them, but its okay because they like it that way. Example: He’s the black sheep of the family. ### 2. Instruction: Generate a haiku using the following word: 2. Input: summer 2. Output: The chill, worming in Shock, pleasure, bursting within Summer tongue awakes ### 3. Instruction: Recommend a movie for me to watch during the weekend and explain the reason. 3. Input: 3. Output: I would recommend the movie "The Shawshank Redemption" because it is an excellent movie that is both moving and inspiring. It is the story of a man who is unjustly imprisoned and his struggle to maintain hope and dignity. It is a great film to watch over the weekend because it will make you think about the human capacity for resilience and hope. ### 4. Instruction:
GPT-3 would then fill in the rest. You can try this in the GPT-3 Playground to see it in action (paste from here).
Here’s the Python script that assembles that all together.
They spent $500 on OpenAI credits to assemble the 52,000 examples they used to fine-tune their model.
As they note in their announcement, generating examples in this way is actually mentioned in the OpenAI terms of use:
You may not [...] (iii) use the Services to develop foundation models or other large scale models that compete with OpenAI
There’s a related concept to this called Model Extraction, where people build new models that emulate the behaviour of others by firing large numbers of examples through the other model and training a new one based on the results.
I don’t think the way Alpaca was trained quite counts as a classic Model Extraction attack, but it certainly echoes one.
More recent articles
- OpenAI’s accidental cyberattack against Hugging Face is science fiction that happened - 22nd July 2026
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026