Monday, 13th March 2023
We introduce Alpaca 7B, a model fine-tuned from the LLaMA 7B model on 52K instruction-following demonstrations. Alpaca behaves similarly to OpenAI’s text-davinci-003, while being surprisingly small and easy/cheap to reproduce (<600$).
Stanford Alpaca, and the acceleration of on-device large language model development
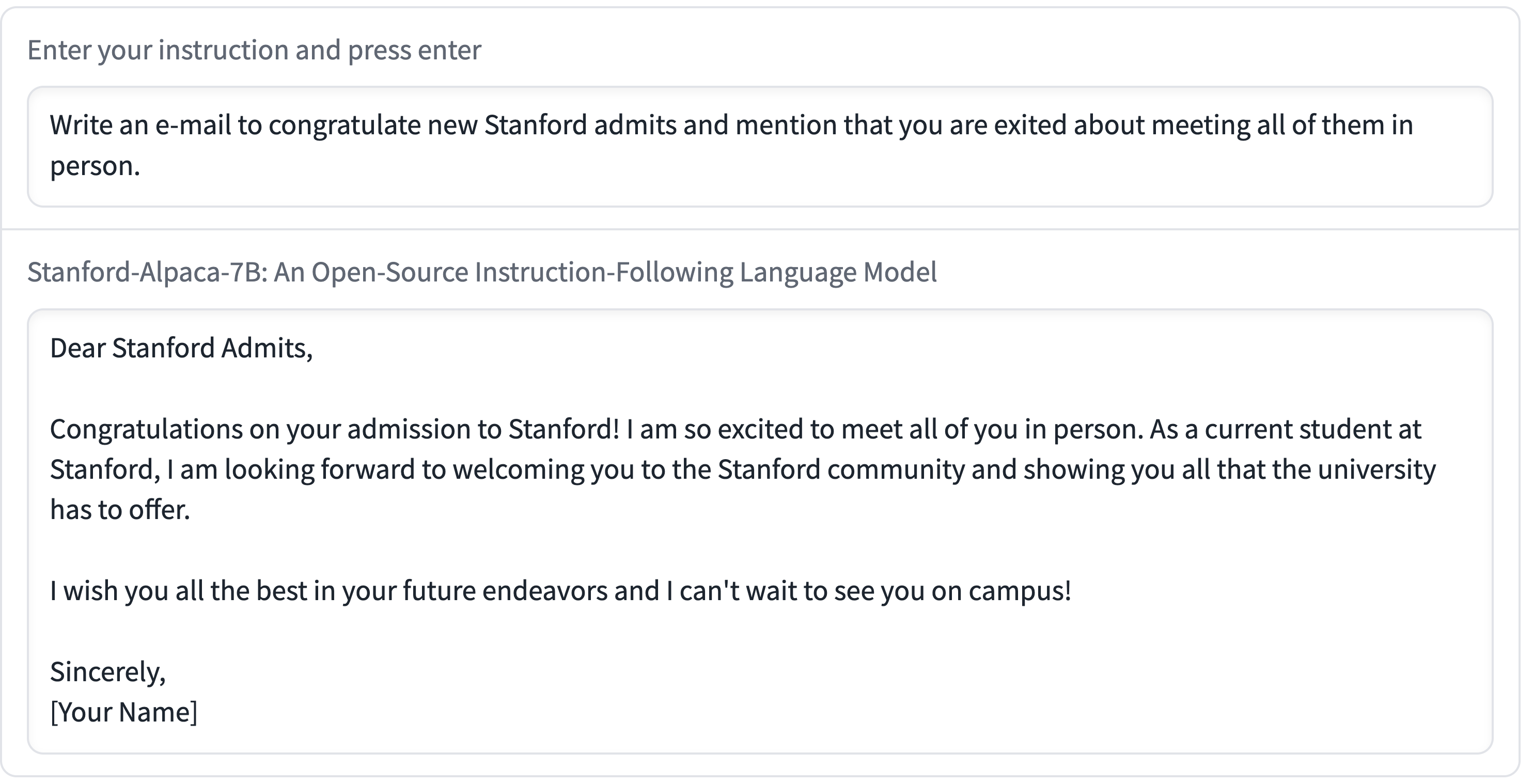
On Saturday 11th March I wrote about how Large language models are having their Stable Diffusion moment. Today is Monday. Let’s look at what’s happened in the past three days.
[... 2,055 words]Int-4 LLaMa is not enough—Int-3 and beyond (via) The Nolano team are experimenting with reducing the size of the LLaMA models even further than the 4bit quantization popularized by llama.cpp.