Exploring the training data behind Stable Diffusion
5th September 2022
Two weeks ago, the Stable Diffusion image generation model was released to the public. I wrote about this last week, in Stable Diffusion is a really big deal—a post which has since become one of the top ten results for “stable diffusion” on Google and shown up in all sorts of different places online.
Andy Baio pinged me a week ago on Friday and asked if I’d be interested in collaborating with him on digging into the training data. The Stable Diffusion Model Card provides a detailed description of how the model was trained—primarily on the LAION 2B-en) dataset (a subset of LAION 5B), with further emphasis given to images with higher calculated aesthetic scores.
We ended up deciding to dig into the improved_aesthetics_6plus subset, which consists of 12 million images with an aesthetics score of 6 or higher.
This isn’t the full training set used for the model, but it’s small enough that it fits comfortably in a SQLite database on inexpensive hosting...
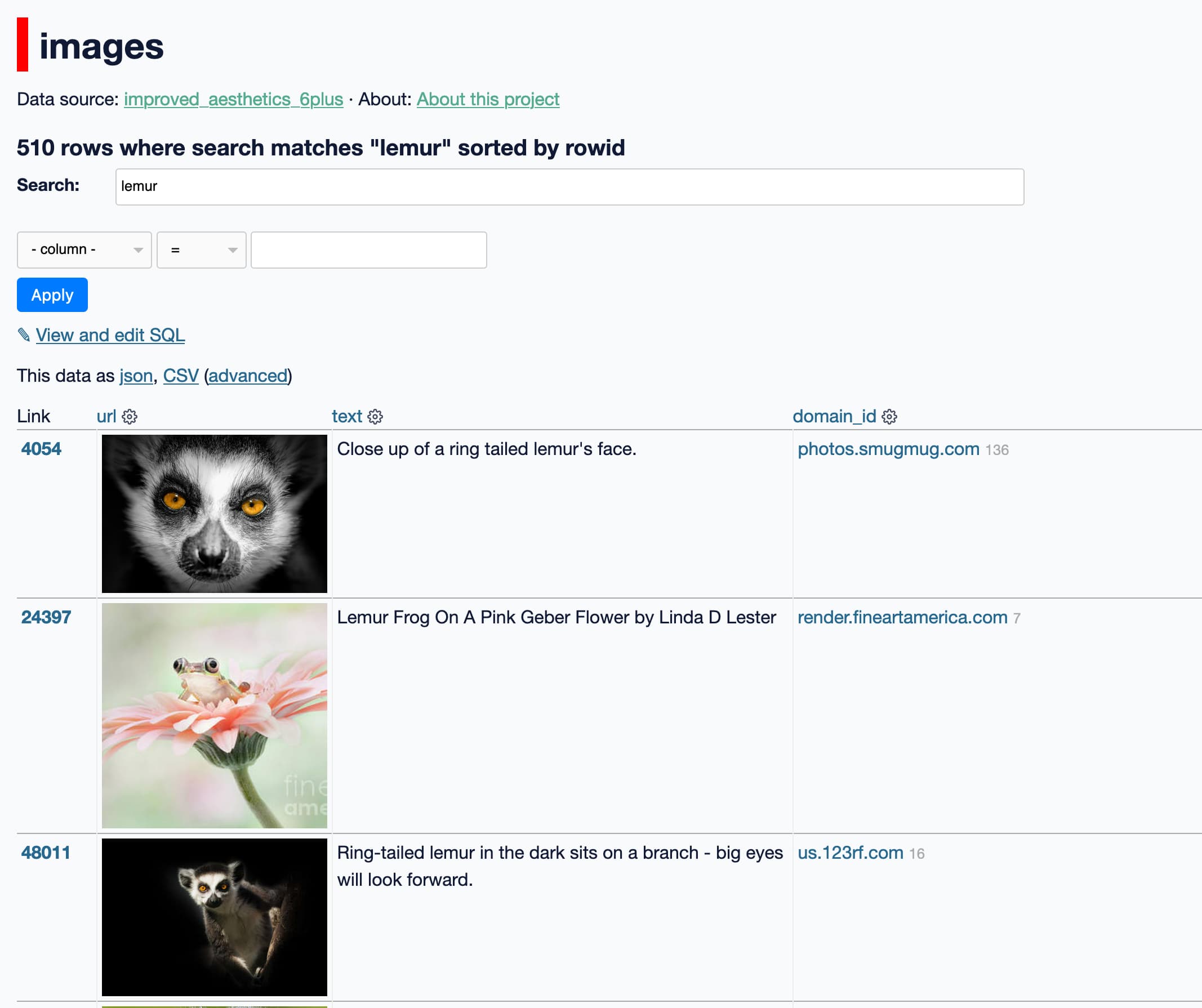
So I built a search engine, powered by Datasette!
Update, 20th December 2023: This search tool is no longer available.
You can search for images by keyword using the following interface:
laion-aesthetic.datasette.io/laion-aesthetic-6pls/images
Or see a breakdown of image counts by the domain they were scraped from on this page.
The search engine provides access to 12,096,835 rows, and uses SQLite full-text search to power search across their text descriptions.
Andy used this Datasette instance to conduct a thorough analysis of the underlying training data, which he wrote about in Exploring 12 Million of the 2.3 Billion Images Used to Train Stable Diffusion’s Image Generator.
This analysis has had a really huge impact! Stories mentioning it made the front page of the websites of both the New York Times and the Washington Post on the same day:
- He used AI art from Midjourney to win a fine-arts prize. Did he cheat?—The Washington Post
- An A.I.-Generated Picture Won an Art Prize. Artists Aren’t Happy.—The New York Times
Further afield, we spotted coverage from publications that included:
- Diese Software macht Sie zum KI-Künstler—Der Spiegel. I get quoted in this one (a translated snippet from my blog at least).
- 23億枚もの画像で構成された画像生成AI「Stable Diffusion」のデータセットのうち1200万枚がどこから入手した画像かを調査した結果が公開される—Gigazine, a long-running (22 years old) Japanese online news magazine.
How I built the database
The code for the Datasette instance can be found in this GitHub repository. The issues in that repo contain a detailed record of the various steps I took to build the database.
The data subset I loaded into the search engine is published on Hugging Face by Christoph Schuhmann. It consists of 7 parquet files, each of which are 325MB and stored in a GitHub repo using Git LFS.
The first step was to fetch that data.
This was my first time running git lfs—I had to install it first using:
brew install git-lfs
git lfs install
Then I cloned the repo and fetched the data like this. Note that to make the actual files available in the directory you need to run both git lfs fetch and git lfs checkout:
git clone https://huggingface.co/datasets/ChristophSchuhmann/improved_aesthetics_6plus
cd improved_aesthetics_6plus
git lfs fetch
git lfs checkoutThe result is 7 parquet files. I wanted to load these into SQLite.
The first solution I found that worked was to use the parquet-tools Python package:
pipx install parquet-tools
I could then convert the parquet data to CSV like this:
parquet-tools csv train-00002-of-00007-709151a2715d894d.parquet
This outputs the contents of the file as CSV.
Since this is a lot of data it made sense to create an empty SQLite table first (with columns with the correct column types) before inserting the data. I did that like so:
sqlite3 laion-aesthetic-6pls.db '
CREATE TABLE IF NOT EXISTS images (
[url] TEXT,
[text] TEXT,
[width] INTEGER,
[height] INTEGER,
[similarity] FLOAT,
[punsafe] FLOAT,
[pwatermark] FLOAT,
[aesthetic] FLOAT,
[hash] TEXT,
[__index_level_0__] INTEGER
);'Then I used a bash loop to insert all of the data:
for filename in *.parquet; do
parquet-tools csv $filename | sqlite3 -csv laion-aesthetic-6pls.db ".import --skip 1 '|cat -' images"
doneThis uses the sqlite3 tool’s .import mechanism, because it’s really fast. The --skip 1 option is necessary to skip the first line, which is the CSV column names. The '|cat -' is the idiom used to tell SQLite to read from standard input.
This did the job! The result was a SQLite database file, about 3.5GB in size.
Enabling search
To enable SQLite full-text search against the images, I used sqlite-utils enable-fts:
sqlite-utils enable-fts laion-aesthetic-6pls.db images text
This took about a minute and a half to run. The resulting database file was around 3.9GB in size—the full text index didn’t add as much to the file size as I had expected.
Best of all, the search was fast! Most search queries took in the order of 20ms to run. My opinion of SQLite FTS keeps improving the more I use it.
Extracting domains with sqlite-utils --functions
We knew we wanted to count how many images had been scraped from each domain—but we currently only had the full image URLs:
https://cdn.idahopotato.com/cache/4075b86c99bc2c46f927f3be5949d161_w310.jpg
While walking Cleo I had an idea: what if sqlite-utils made it really easy to register custom SQL functions and use them from the command-line? Then I could use a Python function to extract the domain names.
This became the impetus for releasing sqlite-utils 3.29 with a brand new feature: sqlite-utils --functions, which lets you do exactly that.
Here’s how I used that to extract the domain names from the URLs:
# First, add an empty 'domain' column to the table
sqlite-utils add-column data.db images domain
# Now populate it using a custom SQL function:
sqlite-utils laion-aesthetic-6pls.db 'update images set domain = domain(url)' \
--functions '
from urllib.parse import urlparse
def domain(url):
return urlparse(url).netloc
'Here we are executing this SQL query against the database:
update images set domain = domain(url)Where that domain(url) function is defined in the Python snippet passed to the --functions option:
from urllib.parse import urlparse def domain(url): return urlparse(url).netloc
sqlite-utils runs eval() against the code in that block, then loops through any callable objects defined by that code (skipping them if their name starts with an underscore) and registers those as custom SQL functions with SQLite.
I’m really excited about this pattern. I think it makes sqlite-utils an even more useful tool for running ad-hoc data cleanup and enrichment tasks.
Populating the domains table
The domain column in the images table was now populated, but it was a bit of a verbose column: it duplicated a chunk of text from the existing url, and was repeated for over 12 million rows.
The sqlite-utils extract command is designed for this exact use-case. It can extract a column from an existing table out into a separate lookup table, reducing the database size by swapping those duplicate text fields for a much smaller integer foreign key column instead.
I ran that like so:
sqlite-utils extract laion-aesthetic-6pls.db images domainThe result was a new domains table, and a domain_id column in the images table that pointed to records there.
One more step: I didn’t want people visiting the site to have to run an expensive group by/count query to see which domains had the most images. So I denormalized that data into the domains table.
First I added a new integer column to it, called image_counts:
sqlite-utils add-column laion-aesthetic-6pls.db domain image_counts integerThen I populated it with a query like this:
sqlite-utils laion-aesthetic-6pls.db '
with counts as (
select domain_id, count(*) as c from images group by domain_id
)
update domain
set image_counts = counts.c
from counts
where id = counts.domain_id
'I first learned to combine CTEs and SQL updates while working with Django migrations—I was delighted to see the same trick works for SQLite as well.
You can see the result of this query in the domain table. The first five rows look like this:
| id | domain | image_counts |
|---|---|---|
| 24 | i.pinimg.com | 1043949 |
| 7 | render.fineartamerica.com | 601106 |
| 16 | us.123rf.com | 497244 |
| 5 | cdn.shopify.com | 241632 |
| 136 | photos.smugmug.com | 225582 |
Doing the same for celebrities, artists, characters
We also wanted to provide pre-calculated counts for searches against a number of celebrities, artists and fictional characters—to help give a sense of the kinds of images that were included in the data.
Andy gathered the ones we wanted to track in this Google Sheet.
I recently learned how to use the /export?format=csv endpoint to export a Google Sheet as CSV. I found out that you can use /export?format=csv&gid=1037423923 to target a specific tab in a multi-tabbed sheet.
So I imported Andy’s data into SQLite using the following:
curl -L 'https://docs.google.com/spreadsheets/d/1JLQQ3U6P0d4vDkAGuB8avmXOPIDPeDUdAEZsWTRYpng/export?format=csv' \
| sqlite-utils insert laion-aesthetic-6pls.db artists - --csv
curl -L 'https://docs.google.com/spreadsheets/d/1JLQQ3U6P0d4vDkAGuB8avmXOPIDPeDUdAEZsWTRYpng/export?format=csv&gid=1037423923' \
| sqlite-utils insert laion-aesthetic-6pls.db celebrities - --csv
curl -L 'https://docs.google.com/spreadsheets/d/1JLQQ3U6P0d4vDkAGuB8avmXOPIDPeDUdAEZsWTRYpng/export?format=csv&gid=480391249' \
| sqlite-utils insert laion-aesthetic-6pls.db characters - --csvThis gave me artists, celebrities and characters tables.
The next challenge was to run a search query for each row in each of those tables and return the count of results. After some experimentation I found that this one worked:
select name, (
select count(*) from images_fts where images_fts match '"' || name || '"'
) as search_count from celebrities order by search_count descNote the match '"' || name || '"' part—this was necessary to ensure the name was correctly quoted in a way that would avoid names like Dwayne 'The Rock' Johnson from breaking the search query.
Now that I had the query I could use that same CTE update trick to populate a counts column in the tables:
sqlite-utils add-column laion-aesthetic-6pls.db celebrities image_counts integer
sqlite-utils laion-aesthetic-6pls.db "$(cat <<EOF
with counts as (
select name,
(
select count(*) from images_fts where images_fts match '"' || name || '"'
) as search_count
from celebrities
)
update celebrities
set image_counts = counts.search_count
from counts
where celebrities.name = counts.name
EOF
)"I’m using the cat <<EOF trick here to avoid having to use shell escaping for the single and double quotes, as described in this TIL: Passing command arguments using heredoc syntax.
Here are the finished tables: characters, celebrities, artists.
Deploying it to Fly
At just under 4GB the resulting SQLite database was an awkward size. I often deploy ~1GB databases to Google Cloud Run, but this was a bit too large for me to feel comfortable with that. Cloud Run can also get expensive for projects that attract a great deal of traffic.
I decided to use Fly instead. Fly includes support for mountable volumes, which means it’s a great fit for these larger database files.
I wrote about Using SQLite and Datasette with Fly Volumes back in February, when I added support to volumes to the datasette-publish-fly Datasette plugin.
This was still the largest database I had ever deployed to Fly, and it took a little bit of work to figure out the best way to handle it.
In the end, I used the following recipe:
datasette publish fly \
--app laion-aesthetic \
--volume-name datasette \
--install datasette-json-html \
--extra-options "-i /data/laion-aesthetic-6pls.db --inspect-file /data/inspect.json --setting sql_time_limit_ms 10000 --setting suggest_facets 0 --setting allow_download 0" \
-m metadata.ymlThe first time I ran this I used --create-volume 20 to create a 20GB volume called datasette. I over-provisioned this so I could run commands like sqlite-utils vacuum, which need twice the amount of space as is taken up by the database file itself.
I uploaded the database file itself using scp, and ran fly ssh console -a laion-aesthetic to SSH in and execute other commands such as datasette inspect laion-aesthetic-6pls.db > inspect.json to create the inspect JSON file.
The --extra-options deserve explanation.
Normally when you run datasette publish the file you pass to the command is automatically deployed using immutable mode. This mode is specifically designed for running read-only databases, and uses optimizations like only counting the rows in the table once on startup (or loading the counts from a pre-prepared inspect.json file).
I wanted those optimizations for this project. But datasette publish fly is currently designed with the assumption that any databases you put in the /data volume are designed to accept writes, and hence shouldn’t be opened in immutable mode.
I ended up coming up with a horrible hack. I add -i /data/laion-aesthetic-6pls.db to the --extra-options command to tell Datasette to open the file in immutable mode.
But this wasn’t enough! datasette publish fly also configures Datasette to automatically open any databases in /data in read-only mode, so that newly saved database files will be served correctly.
This meant my instance was loading the same database twice—once in read-only mode and once in immutable mode.
Rather than fixing the design of datasette-publish-fly, I went for a cheap workaround. I start Datasette with the following metadata.yml configuration (simplified):
databases:
laion-aesthetic-6pls:
tables:
domain:
label_column: domain
laion-aesthetic-6pls_2:
allow: falseThis ensures that the laion-aesthetic-6pls database—the immutable one—is served correctly, and has a label column set for the domain table too.
laion-aesthetic-6pls_2 is the second copy of that database, loaded because Datasette spotted it in the /data directory. Setting allow: false on it uses Datasette’s permissions framework to hide that duplicate database from view.
I’m not proud of these workarounds, and I hope to fix them in the future—but for the moment this is what it took to deploy the project.
Scaling it to meet demand
I launched the first version of the application on Fly’s cheapest instance—256MB of RAM, costing $1.87/month.
This worked fine when it was just me and Andy playing with the site, but it started to struggle as traffic started to increase.
Fly have a “scale app” button which lets you upgrade your instance. I hadn’t actually used it before, but I was delighted to find that it worked exactly as expected: I bumped the RAM up to 4GB (not coincidentally the size of the SQLite database file) and the instance restarted within a few seconds with upgraded capacity.
Fly provide a preconfigured Grafana interface for watching your instances, and it helped me feel confident that the resized instance was happily dealing with the traffic.
I plan to dial back down to a cheaper instance once interest in the project starts to fade.
Got a problem? Throw a search engine at it
This is the third time I’ve used Datasette to build a search engine in the past three weeks! My other two recent projects are:
- scotrail.datasette.io, described in Analyzing ScotRail audio announcements with Datasette—from prototype to production
- archive.sfmicrosociety.org, described in Building a searchable archive for the San Francisco Microscopical Society
The ability to spin up a full search engine for anything that you can stuff into a SQLite database table (which it turns out is almost everything) is a really powerful ability. I plan to write a Datasette tutorial about this in the future.
Releases this week
-
datasette-render-image-tags: 0.1—2022-09-04
Turn any URLs ending in .jpg/.png/.gif into img tags with width 200 -
datasette-sitemap: 1.0—(3 releases total)—2022-08-30
Generate sitemap.xml for Datasette sites -
datasette-block-robots: 1.1—(6 releases total)—2022-08-30
Datasette plugin that blocks robots and crawlers using robots.txt -
sqlite-utils: 3.29—(103 releases total)—2022-08-28
Python CLI utility and library for manipulating SQLite databases