Analyzing ScotRail audio announcements with Datasette—from prototype to production
21st August 2022
Scottish train operator ScotRail released a two-hour long MP3 file containing all of the components of its automated station announcements. Messing around with them is proving to be a huge amount of fun.
I now have a Datasette instance running at scotrail.datasette.io with a table of 2,440 MP3 files of announcement snippets. You can search them, filter them and play them there—either individual clips or as a sequence of clips attached together.
A few examples of things you can do with it:
- Here are all of 421 reasons that a train might be delayed or cancelled.
- A search for bomb turns up four audio clips about a “wartime bomb near the railway”. Searching for theft is fun too.
- Here’s every clip in the Special Train category.
- Here are 100 random clips—hit “Play 100 MP3s on this page” to listen to them all in sequence.
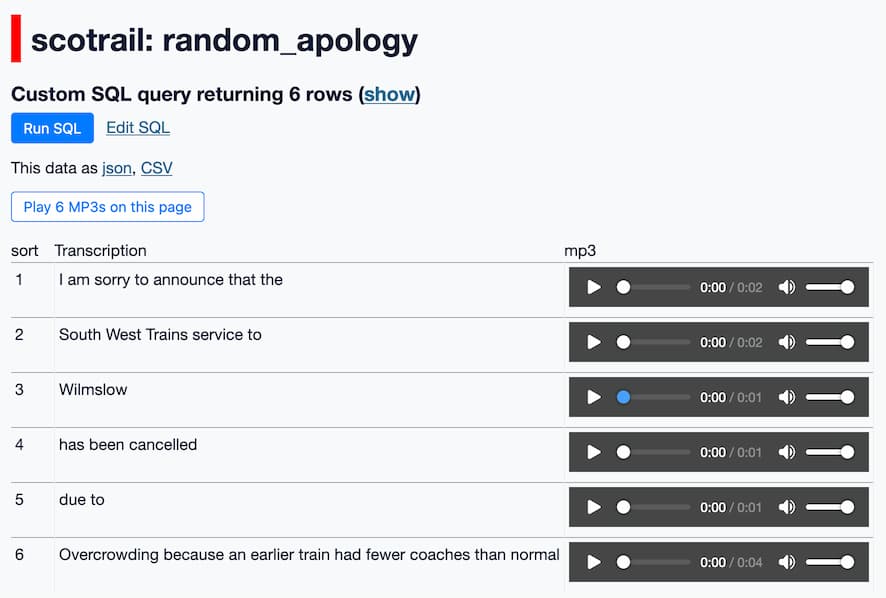
- This page generates a random apology by gluing together six different clips, mad libs style.
The rest of this post is a detailed account of how I built this Datasette instance, from early prototypes on Datasette Lite to a full, customized instance of Datasette running on Vercel and with build and deploy automation powered by GitHub Actions.
Origins of the data
Yesterday, Daily Record journalist Jon Brady tweeted this:
Bizarre FOI find of the day: Scotrail has openly published a two-hour long sound file containing every single element of its automated station announcements https://files.scotrail.co.uk/ScotRail_Station_Announcements_June2022.mp3
An hour and a half later, developer Matt Eason replied:
If anyone needs this split into 2,440 individual mp3s—because why wouldn’t you—I’ve put them here: https://drive.google.com/drive/folders/172W6sXnvlr7UcNLipO8BTw417_KRz9c5?usp=sharing
And if anyone wants to help transcribe all the files, here’s a shared sheet, which has a good chance of descending into chaos:
(Matt later shared notes about how he used WavePad to do this.)
It took two hours for a collective of anonymous volunteers to dive through all of the files and transcribe every single one of them.
I first heard about this all earlier today, when Matt shared his project Ambient Scotrail Beats—an absolutely superb project that overlays random snippets of ScotRail announcement on top of ambient “lofi hip hop radio”—or any YouTube clip you want to enhance in that way.
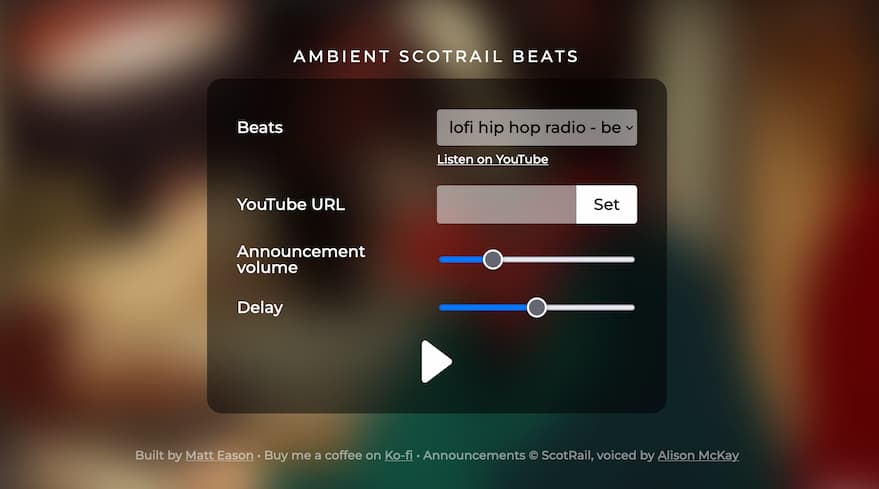
I love how Matt credits Voiceover artist Alison McKay, who originally recorded the announcements for ScotRail, in his work.
I couldn’t resist throwing the data into Datasette to see what kind of things I could do with it.
Starting out with Datasette Lite
My first step to explore the data was to try it out in Datasette Lite, my build of Datasette that runs in WebAssembly entirely in the browser.
The great thing about Datasette Lite is that you don’t need to deploy anything anywhere in order to use it for a new project.
I exported a CSV file from the Google Sheet, pasted it into this GitHub Gist, grabbed the URL to the raw CSV file and pasted that into Datasette Lite.
I ran it through GitHub Gists because Datasette Lite needs data to have open CORS headers in order to load it, and GitHub Gists (and files on GitHub itself) have these headers.
Update: This turns out to be unneccessary: Google Sheets serves these headers too, so given a URL to a Google Sheets CSV export Datasette Lite can open that directly.
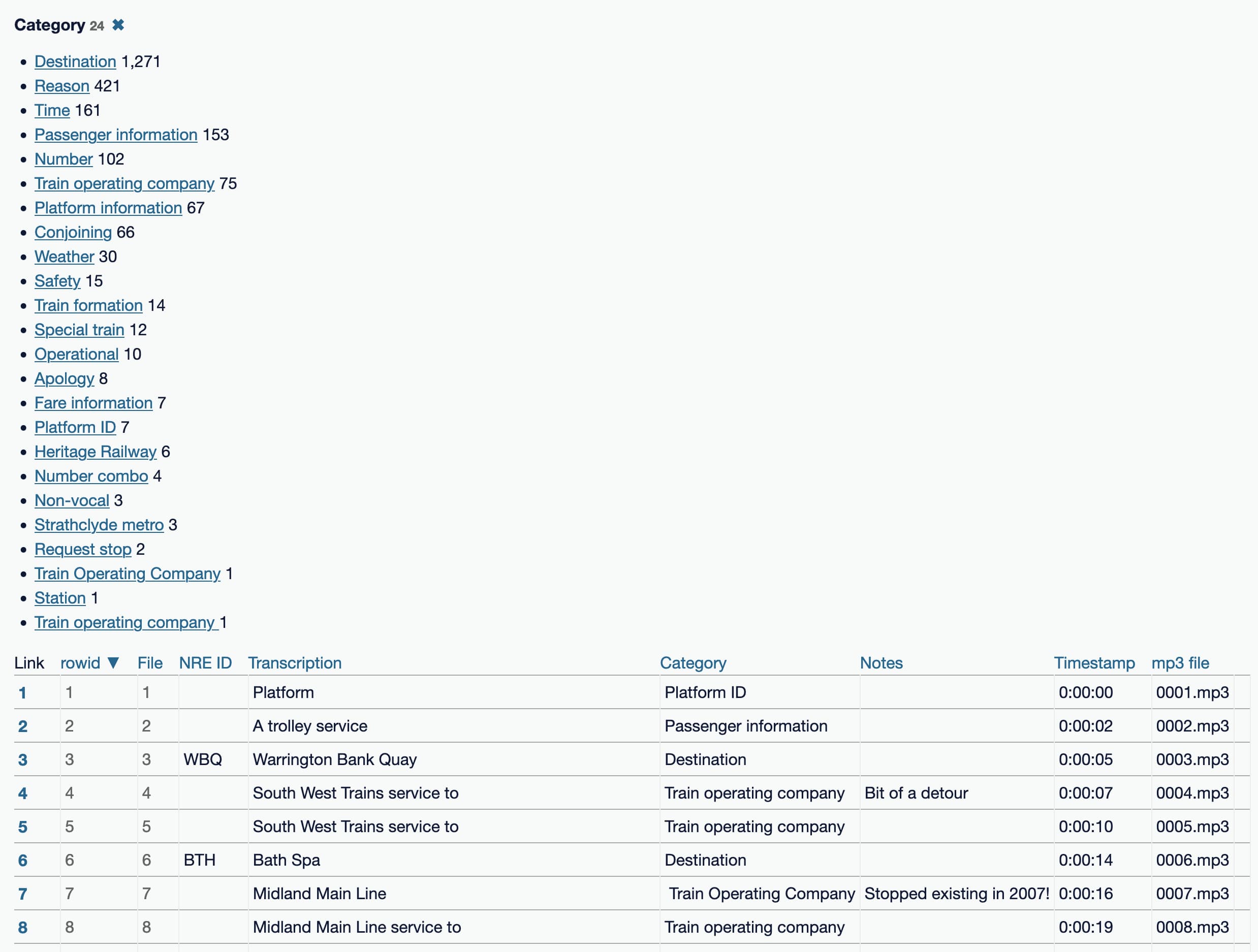
Here’s the result in Datasette Lite. Just being able to facet by Category was already pretty interesting:
I started a Twitter thread sharing my progress so far. This ended up running for the next eight hours as my experiments got increasingly ambitious.
Adding an audio player
Wouldn’t it be neat if you could listen to those MP3 files right there in the Datasette interface?
A few days ago I added plugin support to Datasette Lite—you can now add ?install=name-of-plugin to the URL to install and use a new plugin.
This seemed like the perfect opportunity to put that new capability to good use!
Matt had uploaded all of the individual MP3 files to his scotrail-announcements-june-2022 GitHub repository. This meant that you could get the URL for a snippet called 0008.mp3 by constructing the following URL:
https://github.com/matteason/scotrail-announcements-june-2022/raw/main/announcements/0008.mp3
What I needed was a Datasette plugin that could spot URLs ending in .mp3 and turn them into an interactive audio player.
The easiest way to create a player in modern HTML is like this:
<audio controls src="https://github.com/matteason/scotrail-announcements-june-2022/raw/main/announcements/0008.mp3">
Audio not supported
</audio>Datasette has a render_cell() plugin hook which allows plugins to customize the way individual table cells are rendered.
Here’s the full implementation of a plugin that turns .mp3 URLs into audio elements:
from datasette import hookimpl from markupsafe import Markup, escape @hookimpl def render_cell(value): if not isinstance(value, str): return if value.endswith(".mp3") and ( value.startswith("http://") or value.startswith("https://") or value.startswith("/") ): return Markup( '<audio controls src="{}">Audio not supported</audio>'.format(escape(value)) )
I fired up a new plugin using my datasette-plugin cookiecutter/GitHub repository template called datasette-mp3-audio, dropped in that implementation, added a basic test and shipped it to PyPI.
Now, adding ?install=datasette-mp3-audio to the Datasette Lite URL would install that plugin!
I built a new copy of the CSV file with those full MP3 URLs in it, and loaded that up in Datasette Lite:
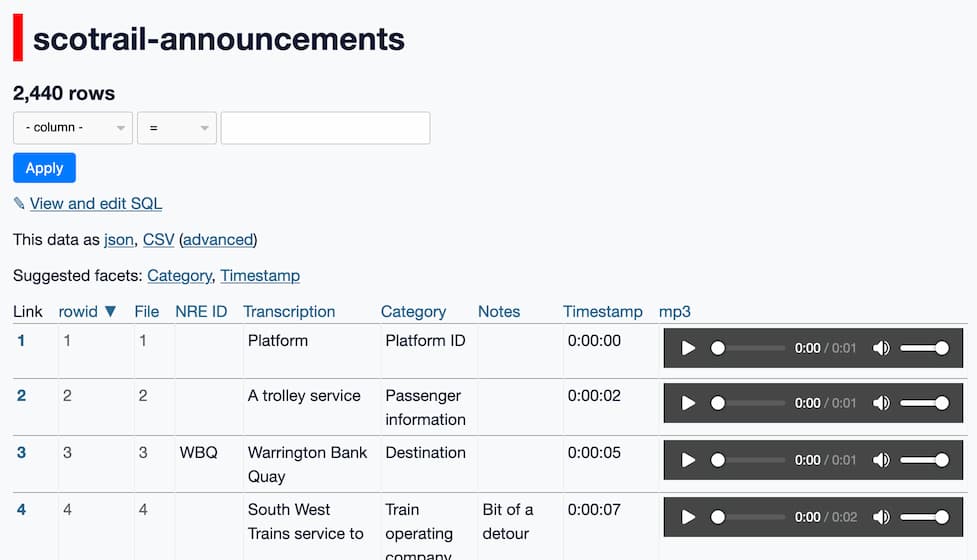
Being able to listen to the clips right there in the Datasette interface made the whole project instantly enormously more fun and interesting.
Upgrading to a full Datasette
Prototyping this on Datasette Lite had been fast and fun, but the long load times were beginning to grate—downloading and running a full copy of Python-compiled-to-WebAssembly every time someone loads the site didn’t make for a great first impression.
I decided to ship a server-side Datasette instance. The database is tiny—just 504KB—so I decided to use Vercel for this. I tend to switch to Cloud Run when my databases grow above about 50MB.
I like to automate my projects as early as possible, so I started a simonw/scotrail-datasette GitHub repository so I could run the deploys using GitHub Actions.
Fetching the CSV with GitHub Actions
First, I wanted a copy of the data in my repository—so that any future changes to the Google Sheet wouldn’t break my project.
I followed my Git scraping pattern and built a quick GitHub Actions workflow to download the Google Sheets data as CSV and stash it in the repository:
name: Fetch CSV from Google Sheets
on:
workflow_dispatch:
permissions:
contents: write
jobs:
fetch-csv:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Python 3.10
uses: actions/setup-python@v3
with:
python-version: "3.10"
cache: "pip"
- name: Install dependencies
run: |
pip install -r requirements.txt
- name: Fetch
run: |
curl -s -L 'https://docs.google.com/spreadsheets/d/1jAtNLBXLYwTraaC_IGAAs53jJWWEQUtFrocS5jW31JM/export?format=csv' | \
sqlite-utils memory stdin:csv \
'select [File], [NRE ID], Transcription, Category, Notes, Timestamp, [mp3 file] from stdin' \
--no-detect-types \
--csv > announcements.csv
- name: Commit and push
run: |-
git config user.name "Automated"
git config user.email "actions@users.noreply.github.com"
git add -A
timestamp=$(date -u)
git commit -m "${timestamp}" || exit 0
git pull --rebase
git pushI was hoping I could just grab the CSV file and save it directly to the repo, but it turned out the raw data had some weirdness to it:
% curl -s -L 'https://docs.google.com/spreadsheets/d/1jAtNLBXLYwTraaC_IGAAs53jJWWEQUtFrocS5jW31JM/export?format=csv' | head -n 5
File,NRE ID,Transcription,Category,Notes,Timestamp,Length,mp3 file,,,,,,,,,,,,,,,,,,,,,,,,
1869,BAI,Blairhill,Destination,,,00:00:00,1869.mp3,,,,,,,,,,,,,,,,,,,,,,,,
1703,BYK,Bentley,Destination,,,00:00:00,1703.mp3,,,,,,,,,,,,,,,,,,,,,,,,
0083,HEX,Hexham,Destination,,,00:00:00,0083.mp3,,,,,,,,,,,,,,,,,,,,,,,,
0004,,South West Trains service to,Train operating company,Bit of a detour,0:00:07,00:00:02,0004.mp3,Progress,#DIV/0!,Progress,#DIV/0!,Progress,#DIV/0!,,,,,,,,,,,,,,,,,,
What’s with all of those ,,,,, blank lines?
It turned out enthusiastic data entry volunteers had scattered some emoji around in the spreadsheet grid to the right of the data, resulting in a whole bunch of extra blank columns in the CSV!
I decided to solve this using by using my sqlite-utils tool to clean up the data—in particular, the sqlite-utils memory mechanism. That’s what this bit does:
curl -s -L 'https://docs.google.com/spreadsheets/d/1jAtNLBXLYwTraaC_IGAAs53jJWWEQUtFrocS5jW31JM/export?format=csv' | \
sqlite-utils memory stdin:csv \
'select [File], [NRE ID], Transcription, Category, Notes, Timestamp, [mp3 file] from stdin' \
--no-detect-types \
--csv > announcements.csv
This fetches the raw CSV data with curl and loads it into an in-memory database, using stdin:csv to hint to sqlite-utils that the data being piped to standard input is in CSV format rather than the default JSON.
Then it runs a SQL query directly against that in-memory database to pull out just the columns I want to keep.
The tool automatically detects types in CSV data. In this particular case filenames such as 0001 were being truncated to the integer 1, which I didn’t want to happen—so I added the --no-detect-types option to turn that off.
Finally, I told it to output --csv and write that to the announcements.csv file.
The workflow ends by writing that new file back to the repository and pushing it, if it has changed.
The workflow is triggered on workflow_dispatch, which means I have to click a button in the GitHub Actions UI to trigger it. I clicked that button, waited a few seconds and GitHub Actions wrote this CSV file back to my repo.
Building the SQLite database
The next step was to write a script that would load that CSV file into a SQLite database. Again, I used sqlite-utils for this. Here’s the build-db.sh script I wrote:
#!/bin/bash
sqlite-utils insert scotrail.db announcements announcements.csv --csv --pk File
sqlite-utils transform scotrail.db announcements \
--rename 'NRE ID' NRE_ID \
--rename 'mp3 file' 'mp3' \
-o File \
-o Transcription \
-o Category \
-o mp3 \
-o Notes \
-o Timestamp \
-o NRE_ID
sqlite-utils scotrail.db "update announcements set mp3 = 'https://github.com/matteason/scotrail-announcements-june-2022/raw/main/announcements/' || mp3"
# Enable search
sqlite-utils enable-fts scotrail.db announcements Transcription --tokenize porterIt took a few iterations to get this exactly right.
The first line imports the CSV data into a table.
The second line does most of the work: it uses sqlite-utils transform to rename a couple of columns, then change the order of the columns in that table to present them in a more useful order in the Datasette UI.
Next the script updates the mp3 column to turn those filenames into full URLs.
Finally, it configures full-text search on the Transcription column, with porter stemming enabled.
Deploying to Vercel
Build script in place, the last step was to automate the process of building the database and then deploying it to Vercel.
I wrote a second workflow for that:
name: Build and deploy
on:
workflow_dispatch:
push:
jobs:
build-and-deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Python 3.10
uses: actions/setup-python@v3
with:
python-version: "3.10"
cache: "pip"
- name: Install dependencies
run: |
pip install -r requirements.txt
- name: Build SQLite database
run: ./build-db.sh
- name: Deploy to Vercel
env:
VERCEL_TOKEN: ${{ secrets.VERCEL_TOKEN }}
run: |-
datasette publish vercel scotrail.db \
--token $VERCEL_TOKEN \
--scope datasette \
--project scotrail \
--install datasette-mp3-audio \
--metadata metadata.ymlThis workflow runs on every push to the repo, but can also be triggered manually.
It installs Python 3.10 and the dependencies I need, then runs the build script to build the database.
The interesting bit is that last block, titled “Deploy to Vercel”.
I created a Vercel API token in their dashboard and saved that as the VERCEL_TOKEN secret in the repository.
The final block uses the datasette-publish-vercel plugin to deploy the site:
datasette publish vercel scotrail.db \
--token $VERCEL_TOKEN \
--scope datasette \
--project scotrail \
--install datasette-mp3-audio \
--metadata metadata.ymlHere we’re deploying the scotrail.db database that was created by our earlier build script. I’m using --scope datasette to specify the Vercel organization that I want to deploy to, and --project scotrail to specify the project.
Vercel will create a new project the first time you use that name, then deploy to that existing project on subsequent runs.
I install the datasette-mp3-audio plugin, described earlier.
Finally, I specify --metadata metadata.yml to upload a metadata file with details to be displayed on the homepage of the site. You can see an early version of that file here.
This worked! I pushed the new workflow, it ran, and Vercel made my new application available at scotrail.vercel.app. I used their dashboard to assign a vanity URL of scotrail.datasette.io.
Adding a “play all” button
I quickly found myself frustrated at having to click the play button on so many different clips!
I decided to see if I could use JavaScript to hit play on everything in succession instead.
I opened up the Firefox DevTools console and started messing around in JavaScript. I eventually found that this recipe did what I wanted:
function playAllAudios() {
let audios = Array.from(document.querySelectorAll('audio'));
function playNext() {
if (!audios.length) {
return;
}
let next = audios.shift();
next.addEventListener('ended', playNext);
next.play();
}
playNext();
}
playAllAudios();I opened an issue to record my prototype.
This was while I was still working with Datasette Lite, which still has some limitations in terms of executing JavaScript from plugins.
Once I’d upgraded to a full Datasette, I revisited the issue.
I figured out an extended version of my JavaScript prototype which would add a “Play 33 MP3s on this page” button to any page with two or more audio elements. Here’s the code. I implemented that in datasette-mp3-audio, shipped a 0.2 release and added that to the site.
The new button is really fun! Here it is on a query that returns 100 random snippets:
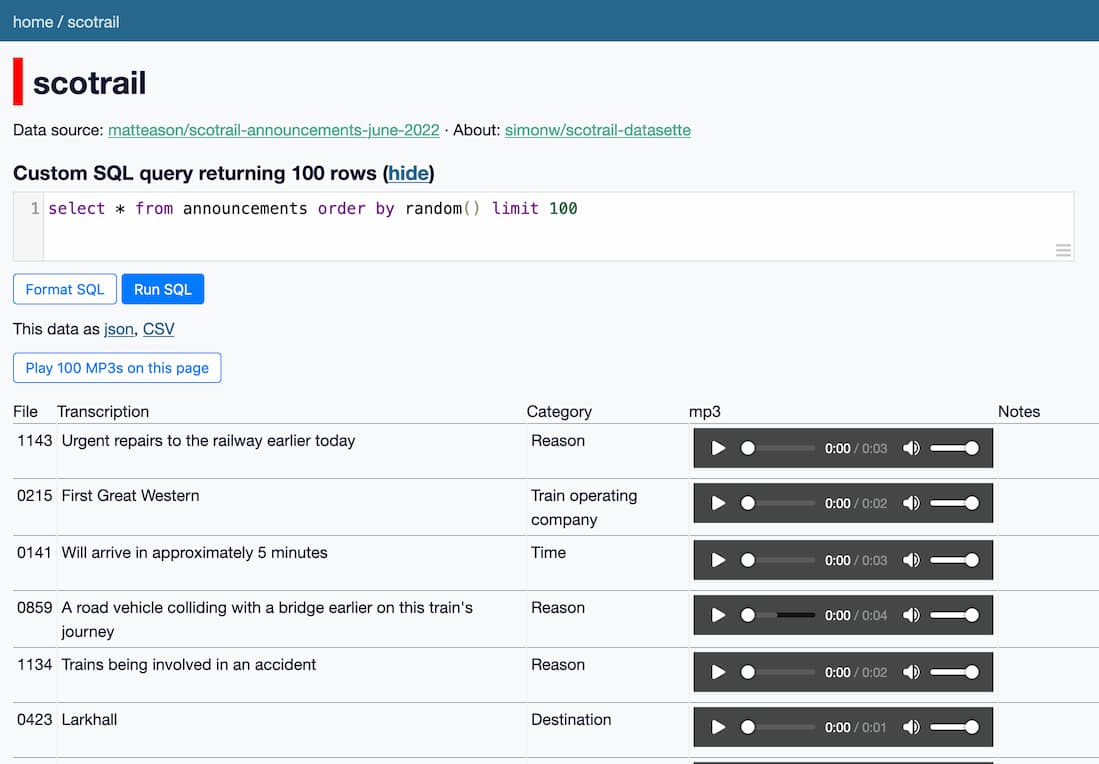
Generating random apologies with a SQL query
To really exercise this new feature, I decided to try and build a mad lib.
I figured out a SQL query that would construct a random apology, stringing together random snippets from a number of different categories.
I used CTEs (common table expressions—the with x as (query) blocks) to pick each of the random components of the final sentence.
Here’s the query I came up with, with some extra inline commentary:
with apology as (
select Transcription, mp3 from announcements where
Category = 'Apology'
order by random() limit 1
),The Apology category only has 8 rows, each along the lines of “I am sorry to announce that the” or “We are sorry to announce that the”.
train_company as (
select Transcription, mp3 from announcements where
Category = 'Train operating company'
and Transcription like '%to%'
order by random() limit 1
),There are 76 Train operating company snippets, in formats that include “Midland Main Line service from” and “Southeastern Trains service to”. I filtered for just the ones with to in the text.
destination as (
select Transcription, mp3 from announcements where
Category = 'Destination'
order by random() limit 1
),There are 1,271 potential destinations—single word names of places, like “Bath Spa” or “Dunfermline Queen Margaret”.
cancelled as (
select Transcription, mp3 from announcements where
Transcription = 'has been cancelled'
limit 1
),
due_to as (
select Transcription, mp3 from announcements where
Transcription = 'due to'
limit 1
),There’s probably a neater way to do this—I just wanted the literal text “has been cancelled due to” in every result.
reason as (
select Transcription, mp3 from announcements where
Category = 'Reason'
order by random() limit 1
),These are the really fun ones. There are 421 snippets marked “Reason”, everything from “bad weather conditions” to “...a burst water main near the railway, yesterday” to “a wartime bomb near the railway earlier today”!
The final piece of the query combined these together into a list, with an artificially added sort column to guarantee the order (which I don’t think is strictly necessary in SQLite, but better safe than sorry):
combined as (
select 1 as sort, * from apology
union select 2, * from train_company
union select 3, * from destination
union select 4, * from cancelled
union select 5, * from due_to
union select 6, * from reason
)
select * from combined order by sortThis totally works!
Since the bookmarked query is a pretty long URL I decided to use Datasette’s canned query mechanism to turn it into a more easily discovered page:
scotrail.datasette.io/scotrail/random_apology
I also chose to hide the SQL query by default, to put the essential “Play 6 MP3s on this page” button above the fold.
I linked to it from the site homepage too, using description_html in the site metadata.yml:
Assembling full sentences from user input
I wanted the ability to stitch together my own custom phrases—specifying a sequence of clips to be played in order.
I decided to do this using an input that was a comma separated list of search terms:
i am sorry, scotrail, from, bath spa, is delayed, due to, bomb
My idea was to split this into search terms and return the first clip for each of those, in order. Then I could hit the “play all” button to listen to them in sequence.
Try this feature out—I built it as another canned query. Click the show link to see the full SQL query.
Here’s that SQL, with additional comments:
with phrases as (
select
key, value
from
json_each('["' || replace(:terms, ',', '","') || '"]')
),This is the trickiest bit. I needed to split that user input of a comma separated string into separate terms, so I could run a search against each one.
The trick I’m using here is to first convert that string into JSON. Here’s a simplified version:
select '["' || replace(:terms, ',', '","') || '"]'Note that users can break this by including double quotes in their input—I’m OK with that, it just means the query will exit with an error.
Once I have a JSON list of terms I can use the SQLite json_each table-valued function. This turns that JSON into a table you can join against other things.
Try select * from json_each(’[“one”, “two”, “three”]’) to see what that table looks like:
| key | value | type | atom | id | parent | fullkey | path |
|---|---|---|---|---|---|---|---|
| 0 | one | text | one | 1 | $[0] | $ | |
| 1 | two | text | two | 2 | $[1] | $ | |
| 2 | three | text | three | 3 | $[2] | $ |
We only need the key column (to maintain the order of the search terms) and the value column (the search term itself).
Back to the next part of that big SQL query:
matches as (select
phrases.key,
phrases.value,
(
select File from announcements
where announcements.Transcription like '%' || trim(phrases.value) || '%'
order by length(announcements.Transcription)
limit 1
) as File
from
phrases
),This is the part that runs a search for each of the phrases from that JSON list.
It’s using a subselect in the select clause to run the actual search.
Try a variant of that subselect to see how it works—it looks for clips that match a like query of %search term%, then orders by length to find the shortest match. This is so that if you type the you’ll get back the word “the” and not the destination “Atherton”.
results as (
select key, announcements.Transcription, announcements.mp3
from announcements join matches on announcements.File = matches.File
order by key
)We only returned the File column from our subselect, because when you put a subselect in a SELECT you can only return a single column.
This next bit joins our matches back against the announcements table to get the other data we need: the transcription text and the mp3 file.
Run a select * from results query to see our results so far.
select
'Combined sentence:' as mp3,
group_concat(Transcription, ' ') as Transcription,
-1 as key
from results
union
select
mp3, Transcription, key
from results
order by keyThis last step is an extra flourish. I decided it would be useful to show the full combined sentence as text, in addition to presenting the individual clips.
I’m using a union for this. The first select query sets the mp3 column to the text “Combined sentence:” and then uses the group_concat() SQLite function to join all of the Transcription values together as a space-separated list. It adds on a -1 as the key so we can sort by that later and have this artificial row show up first.
Then it runs a union against the rows from that results CTE.
The final output looks like this:
| mp3 | Transcription | key |
|---|---|---|
| Combined sentence: | I am sorry to announce that the ScotRail service from Bath Spa is delayed due to A wartime bomb near the railway | -1 |
| .../0031.mp3 | I am sorry to announce that the | 0 |
| .../0032.mp3 | ScotRail | 1 |
| .../1778.mp3 | service from | 2 |
| .../0006.mp3 | Bath Spa | 3 |
| .../1750.mp3 | is delayed | 4 |
| .../1528.mp3 | due to | 5 |
| .../0946.mp3 | A wartime bomb near the railway | 6 |
Make fun stuff with the API
As you can probably tell, I had a ridiculous amount of fun playing with this data.
If you want to build some things with this, you should know that every page on the Datasette instance has an accompanying API. Look for the JSON links on each page—Datasette serves them with CORS headers so you can fetch data from them from any domain on the Web.
I recommend adding ?_shape=objects to the array, since this shape of data is closer to the breaking change I have planned for Datasette 1.0. Here’s an example returning one of those random apologies:
https://scotrail.datasette.io/scotrail/random_apology.json?_shape=objects
I also installed the datasette-graphql plugin, so if you want to use GraphQL instead you can do something like this:
{
announcements(filter: {Category: {eq: "Special train"}}) {
nodes {
File
Transcription
Category
mp3
Notes
Timestamp
NRE_ID
}
}
}That query returns the 12 rows in the Special train category.
Let me know on Twitter if you build something fun!
More recent articles
- OpenAI’s accidental cyberattack against Hugging Face is science fiction that happened - 22nd July 2026
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026