Joining CSV files in your browser using Datasette Lite
20th June 2022
I added a new feature to Datasette Lite—my version of Datasette that runs entirely in your browser using WebAssembly (previously): you can now use it to load one or more CSV files by URL, and then run SQL queries against them—including joins across data from multiple files.
Your CSV file needs to be hosted somewhere with access-control-allow-origin: * CORS headers. Any CSV file hosted on GitHub provides these, if you use the link you get by clicking on the “Raw” version.
Loading CSV data from a URL
Here’s the URL to a CSV file of college fight songs collected by FiveThirtyEight in their data repo as part of the reporting for this story a few years ago:
https://raw.githubusercontent.com/fivethirtyeight/data/master/fight-songs/fight-songs.csv
You can pass this to Datasette Lite in two ways:
- You can load the web app, click the “Load data by URL to a CSV file” button and paste in the URL
- Or you can pass it as a
?csv=parameter to the application, like this: https://lite.datasette.io/?csv=https://raw.githubusercontent.com/fivethirtyeight/data/master/fight-songs/fight-songs.csv
Once Datasette has loaded, a data database will be available with a single table called fight-songs.
As you navigate around in Datasette the URL bar will update to reflect current state—which means you can deep-link to table views with applied filters and facets:
Or even link to the result of a custom SQL query:
Loading multiple files and joining data
You can pass the ?csv= parameter more than once to load data from multiple CSV files into the same virtual data database. Each CSV file will result in a separate table.
For this demo I’ll use two CSV files.
The first is us-counties-recent.csv from the NY Times covid-19-data repository, which lists the most recent numbers for Covid cases for every US county.
The second is us_census_county_populations_2019.csv, a CSV file listing the population of each county according to the 2019 US Census which I extracted from this page on the US Census website.
Both of those tables include a column called fips, representing the FIPS county code for each county. These 4-5 digit codes are ideal for joining the two tables.
Here’s a SQL query which joins the two tables, filters for the data for the most recent date represented (using where date = (select max(date) from [us-counties-recent])) and calculates cases_per_million using the cases and the population:
select
[us-counties-recent].*,
us_census_county_populations_2019.population,
1.0 * [us-counties-recent].cases / us_census_county_populations_2019.population * 1000000 as cases_per_million
from
[us-counties-recent]
join us_census_county_populations_2019 on us_census_county_populations_2019.fips = [us-counties-recent].fips
where
date = (select max(date) from [us-counties-recent])
order by
cases_per_million desc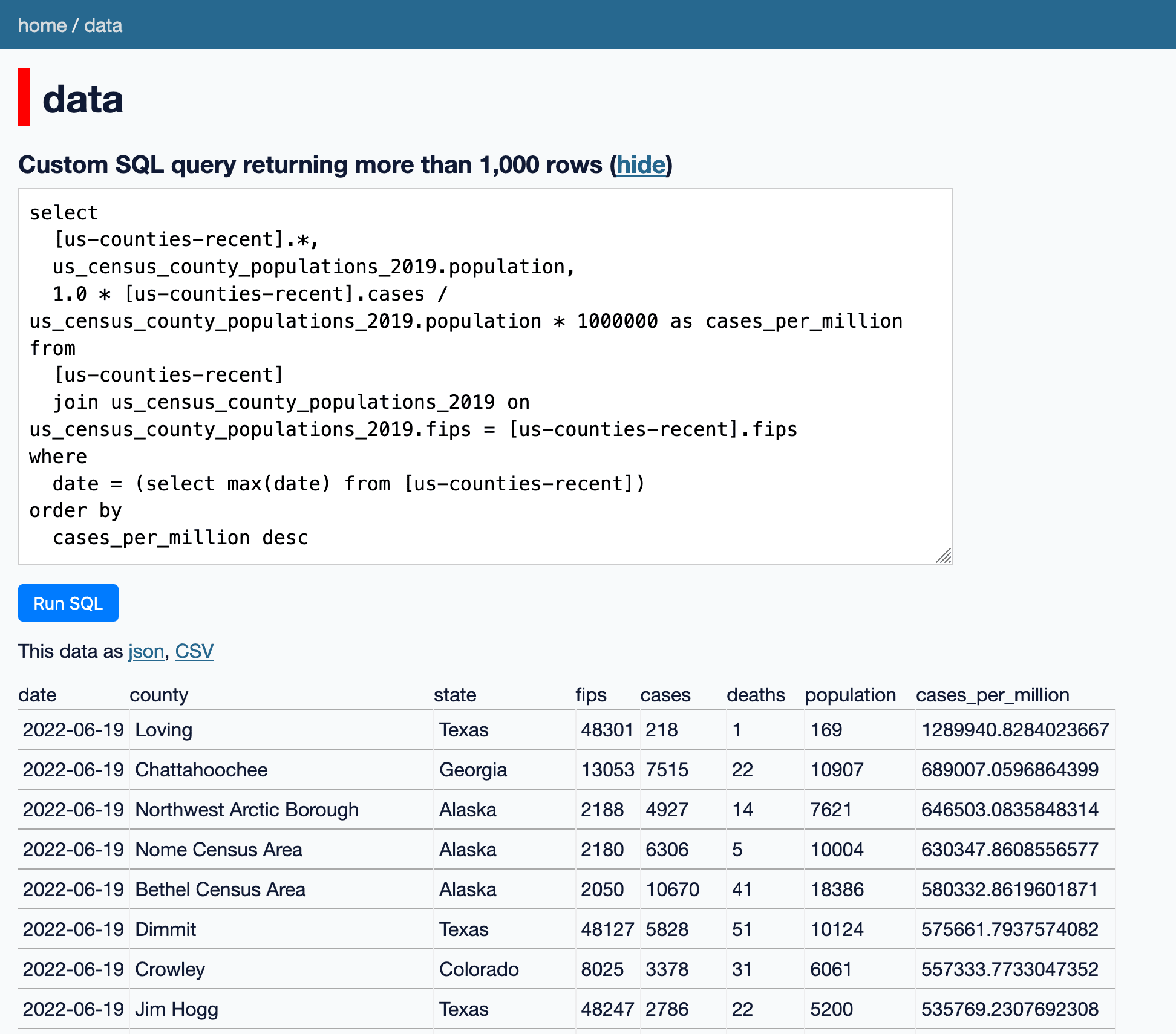
And since everything in Datasette Lite can be bookmarked, here’s the super long URL (clickable version here) that executes that query against those two CSV files:
https://lite.datasette.io/?csv=https://raw.githubusercontent.com/nytimes/covid-19-data/master/us-counties-recent.csv&csv=https://raw.githubusercontent.com/simonw/covid-19-datasette/main/us_census_county_populations_2019.csv#/data?sql=select%0A++%5Bus-counties-recent%5D.*%2C%0A++us_census_county_populations_2019.population%2C%0A++1.0+*+%5Bus-counties-recent%5D.cases+%2F+us_census_county_populations_2019.population+*+1000000+as+cases_per_million%0Afrom%0A++%5Bus-counties-recent%5D%0A++join+us_census_county_populations_2019+on+us_census_county_populations_2019.fips+%3D+%5Bus-counties-recent%5D.fips%0Awhere%0A++date+%3D+%28select+max%28date%29+from+%5Bus-counties-recent%5D%29%0Aorder+by%0A++cases_per_million+desc
More recent articles
- OpenAI’s accidental cyberattack against Hugging Face is science fiction that happened - 22nd July 2026
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026