Git scraping: track changes over time by scraping to a Git repository
9th October 2020
Git scraping is the name I’ve given a scraping technique that I’ve been experimenting with for a few years now. It’s really effective, and more people should use it.
Update 5th March 2021: I presented a version of this post as a five minute lightning talk at NICAR 2021, which includes a live coding demo of building a new git scraper.
Update 5th January 2022: I released a tool called git-history that helps analyze data that has been collected using this technique.
The internet is full of interesting data that changes over time. These changes can sometimes be more interesting than the underlying static data—The @nyt_diff Twitter account tracks changes made to New York Times headlines for example, which offers a fascinating insight into that publication’s editorial process.
We already have a great tool for efficiently tracking changes to text over time: Git. And GitHub Actions (and other CI systems) make it easy to create a scraper that runs every few minutes, records the current state of a resource and records changes to that resource over time in the commit history.
Here’s a recent example. Fires continue to rage in California, and the CAL FIRE website offers an incident map showing the latest fire activity around the state.
Firing up the Firefox Network pane, filtering to requests triggered by XHR and sorting by size, largest first reveals this endpoint:
https://www.fire.ca.gov/umbraco/Api/IncidentApi/GetIncidents
That’s a 241KB JSON endpoints with full details of the various fires around the state.
So... I started running a git scraper against it. My scraper lives in the simonw/ca-fires-history repository on GitHub.
Every 20 minutes it grabs the latest copy of that JSON endpoint, pretty-prints it (for diff readability) using jq and commits it back to the repo if it has changed.
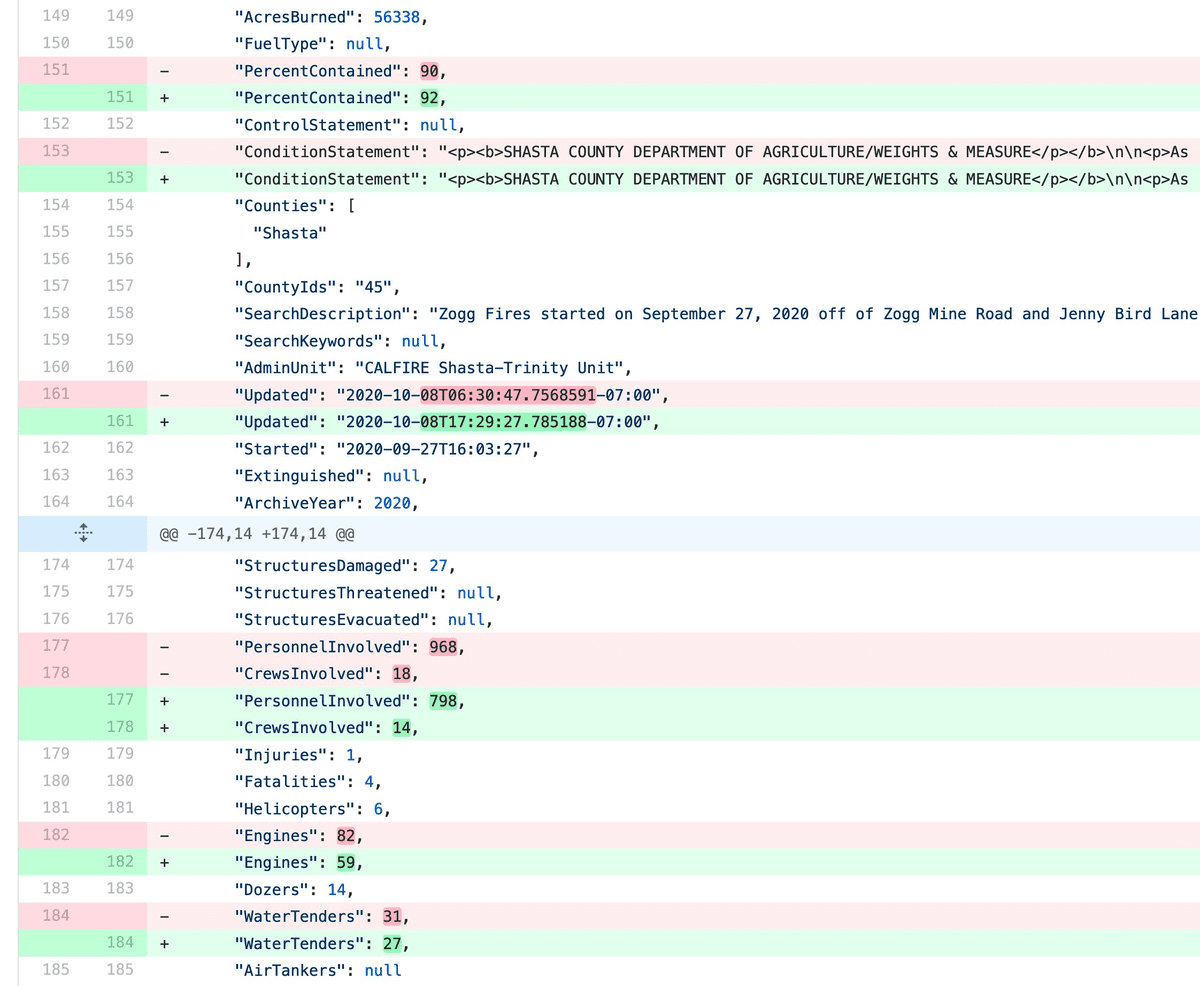
This means I now have a commit log of changes to that information about fires in California. Here’s an example commit showing that last night the Zogg Fires percentage contained increased from 90% to 92%, the number of personnel involved dropped from 968 to 798 and the number of engines responding dropped from 82 to 59.
The implementation of the scraper is entirely contained in a single GitHub Actions workflow. It’s in a file called .github/workflows/scrape.yml which looks like this:
name: Scrape latest data
on:
push:
workflow_dispatch:
schedule:
- cron: '6,26,46 * * * *'
jobs:
scheduled:
runs-on: ubuntu-latest
steps:
- name: Check out this repo
uses: actions/checkout@v2
- name: Fetch latest data
run: |-
curl https://www.fire.ca.gov/umbraco/Api/IncidentApi/GetIncidents | jq . > incidents.json
- name: Commit and push if it changed
run: |-
git config user.name "Automated"
git config user.email "actions@users.noreply.github.com"
git add -A
timestamp=$(date -u)
git commit -m "Latest data: ${timestamp}" || exit 0
git pushThat’s not a lot of code!
It runs on a schedule at 6, 26 and 46 minutes past the hour—I like to offset my cron times like this since I assume that the majority of crons run exactly on the hour, so running not-on-the-hour feels polite.
The scraper itself works by fetching the JSON using curl, piping it through jq . to pretty-print it and saving the result to incidents.json.
The “commit and push if it changed” block uses a pattern that commits and pushes only if the file has changed. I wrote about this pattern in this TIL a few months ago.
I have a whole bunch of repositories running git scrapers now. I’ve been labeling them with the git-scraping topic so they show up in one place on GitHub (other people have started using that topic as well).
I’ve written about some of these in the past:
- Scraping hurricane Irma back in September 2017 is when I first came up with the idea to use a Git repository in this way.
- Changelogs to help understand the fires in the North Bay from October 2017 describes an early attempt at scraping fire-related information.
- Generating a commit log for San Francisco’s official list of trees remains my favourite application of this technique. The City of San Francisco maintains a frequently updated CSV file of 190,000 trees in the city, and I have a commit log of changes to it stretching back over more than a year. This example uses my csv-diff utility to generate human-readable commit messages.
- Tracking PG&E outages by scraping to a git repo documents my attempts to track the impact of PG&E’s outages last year by scraping their outage map. I used the GitPython library to turn the values recorded in the commit history into a database that let me run visualizations of changes over time.
- Tracking FARA by deploying a data API using GitHub Actions and Cloud Run shows how I track new registrations for the US Foreign Agents Registration Act (FARA) in a repository and deploy the latest version of the data using Datasette.
I hope that by giving this technique a name I can encourage more people to add it to their toolbox. It’s an extremely effective way of turning all sorts of interesting data sources into a changelog over time.
Comment thread on this post over on Hacker News.