38 posts tagged “scraping”
2025
Reddit will block the Internet Archive. Well this sucks. Jay Peters for the Verge:
Reddit says that it has caught AI companies scraping its data from the Internet Archive’s Wayback Machine, so it’s going to start blocking the Internet Archive from indexing the vast majority of Reddit. The Wayback Machine will no longer be able to crawl post detail pages, comments, or profiles; instead, it will only be able to index the Reddit.com homepage, which effectively means Internet Archive will only be able to archive insights into which news headlines and posts were most popular on a given day.
Vibe scraping and vibe coding a schedule app for Open Sauce 2025 entirely on my phone
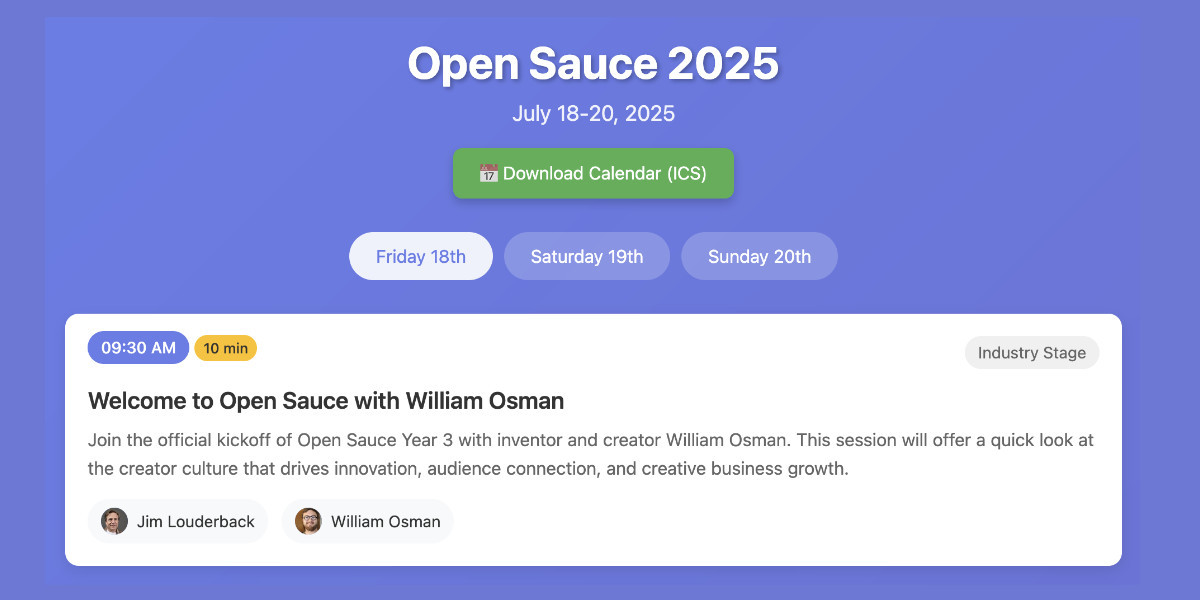
This morning, working entirely on my phone, I scraped a conference website and vibe coded up an alternative UI for interacting with the schedule using a combination of OpenAI Codex and Claude Artifacts.
[... 2,189 words]shot-scraper 1.8. I've added a new feature to shot-scraper that makes it easier to share scripts for other people to use with the shot-scraper javascript command.
shot-scraper javascript lets you load up a web page in an invisible Chrome browser (via Playwright), execute some JavaScript against that page and output the results to your terminal. It's a fun way of running complex screen-scraping routines as part of a terminal session, or even chained together with other commands using pipes.
The -i/--input option lets you load that JavaScript from a file on disk - but now you can also use a gh: prefix to specify loading code from GitHub instead.
To quote the release notes:
shot-scraper javascriptcan now optionally load scripts hosted on GitHub via the newgh:prefix to theshot-scraper javascript -i/--inputoption. #173Scripts can be referenced as
gh:username/repo/path/to/script.jsor, if the GitHub user has created a dedicatedshot-scraper-scriptsrepository and placed scripts in the root of it, usinggh:username/name-of-script.For example, to run this readability.js script against any web page you can use the following:
shot-scraper javascript --input gh:simonw/readability \ https://simonwillison.net/2025/Mar/24/qwen25-vl-32b/
The output from that example starts like this:
{
"title": "Qwen2.5-VL-32B: Smarter and Lighter",
"byline": "Simon Willison",
"dir": null,
"lang": "en-gb",
"content": "<div id=\"readability-page-1\"...My simonw/shot-scraper-scripts repo only has that one file in it so far, but I'm looking forward to growing that collection and hopefully seeing other people create and share their own shot-scraper-scripts repos as well.
This feature is an imitation of a similar feature that's coming in the next release of LLM.
Cutting-edge web scraping techniques at NICAR. Here's the handout for a workshop I presented this morning at NICAR 2025 on web scraping, focusing on lesser know tips and tricks that became possible only with recent developments in LLMs.
For workshops like this I like to work off an extremely detailed handout, so that people can move at their own pace or catch up later if they didn't get everything done.
The workshop consisted of four parts:
- Building a Git scraper - an automated scraper in GitHub Actions that records changes to a resource over time
- Using in-browser JavaScript and then shot-scraper to extract useful information
- Using LLM with both OpenAI and Google Gemini to extract structured data from unstructured websites
- Video scraping using Google AI Studio
I released several new tools in preparation for this workshop (I call this "NICAR Driven Development"):
- git-scraper-template template repository for quickly setting up new Git scrapers, which I wrote about here
- LLM schemas, finally adding structured schema support to my LLM tool
- shot-scraper har for archiving pages as HTML Archive files - though I cut this from the workshop for time
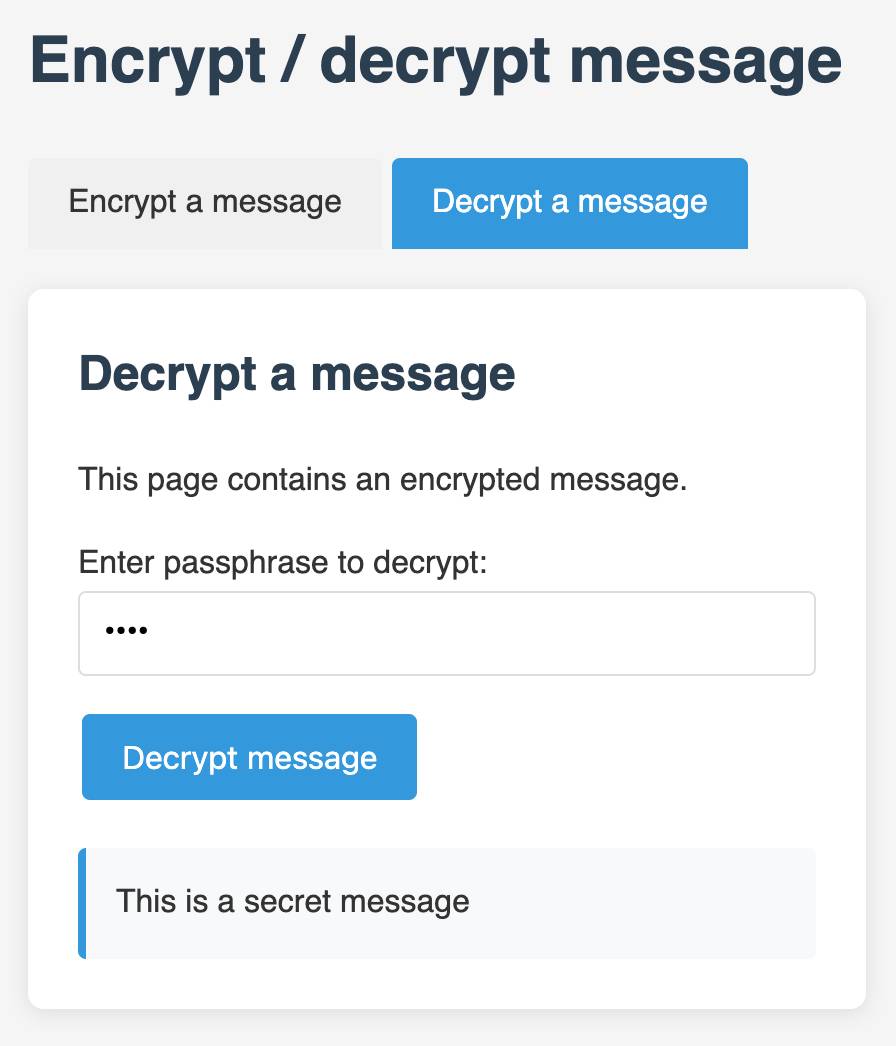
I also came up with a fun way to distribute API keys for workshop participants: I had Claude build me a web page where I can create an encrypted message with a passphrase, then share a URL to that page with users and give them the passphrase to unlock the encrypted message. You can try that at tools.simonwillison.net/encrypt - or use this link and enter the passphrase "demo":
monolith (via) Neat CLI tool built in Rust that can create a single packaged HTML file of a web page plus all of its dependencies.
cargo install monolith # or brew install
monolith https://simonwillison.net/ > simonwillison.html
That command produced this 1.5MB single file result. All of the linked images, CSS and JavaScript assets have had their contents inlined into base64 URIs in their src= and href= attributes.
I was intrigued as to how it works, so I dumped the whole repository into Gemini 2.0 Pro and asked for an architectural summary:
cd /tmp
git clone https://github.com/Y2Z/monolith
cd monolith
files-to-prompt . -c | llm -m gemini-2.0-pro-exp-02-05 \
-s 'architectural overview as markdown'
Here's what I got. Short version: it uses the reqwest, html5ever, markup5ever_rcdom and cssparser crates to fetch and parse HTML and CSS and extract, combine and rewrite the assets. It doesn't currently attempt to run any JavaScript.
simonw/git-scraper-template. I built this new GitHub template repository in preparation for a workshop I'm giving at NICAR (the data journalism conference) next week on Cutting-edge web scraping techniques.
One of the topics I'll be covering is Git scraping - creating a GitHub repository that uses scheduled GitHub Actions workflows to grab copies of websites and data feeds and store their changes over time using Git.
This template repository is designed to be the fastest possible way to get started with a new Git scraper: simple create a new repository from the template and paste the URL you want to scrape into the description field and the repository will be initialized with a custom script that scrapes and stores that URL.
It's modeled after my earlier shot-scraper-template tool which I described in detail in Instantly create a GitHub repository to take screenshots of a web page.
The new git-scraper-template repo took some help from Claude to figure out. It uses a custom script to download the provided URL and derive a filename to use based on the URL and the content type, detected using file --mime-type -b "$file_path" against the downloaded file.
It also detects if the downloaded content is JSON and, if it is, pretty-prints it using jq - I find this is a quick way to generate much more useful diffs when the content changes.
Using a Tailscale exit node with GitHub Actions. New TIL. I started running a git scraper against doge.gov to track changes made to that website over time. The DOGE site runs behind Cloudflare which was blocking requests from the GitHub Actions IP range, but I figured out how to run a Tailscale exit node on my Apple TV and use that to proxy my shot-scraper requests.
The scraper is running in simonw/scrape-doge-gov. It uses the new shot-scraper har command I added in shot-scraper 1.6 (and improved in shot-scraper 1.7).
shot-scraper 1.6 with support for HTTP Archives. New release of my shot-scraper CLI tool for taking screenshots and scraping web pages.
The big new feature is HTTP Archive (HAR) support. The new shot-scraper har command can now create an archive of a page and all of its dependents like this:
shot-scraper har https://datasette.io/
This produces a datasette-io.har file (currently 163KB) which is JSON representing the full set of requests used to render that page. Here's a copy of that file. You can visualize that here using ericduran.github.io/chromeHAR.
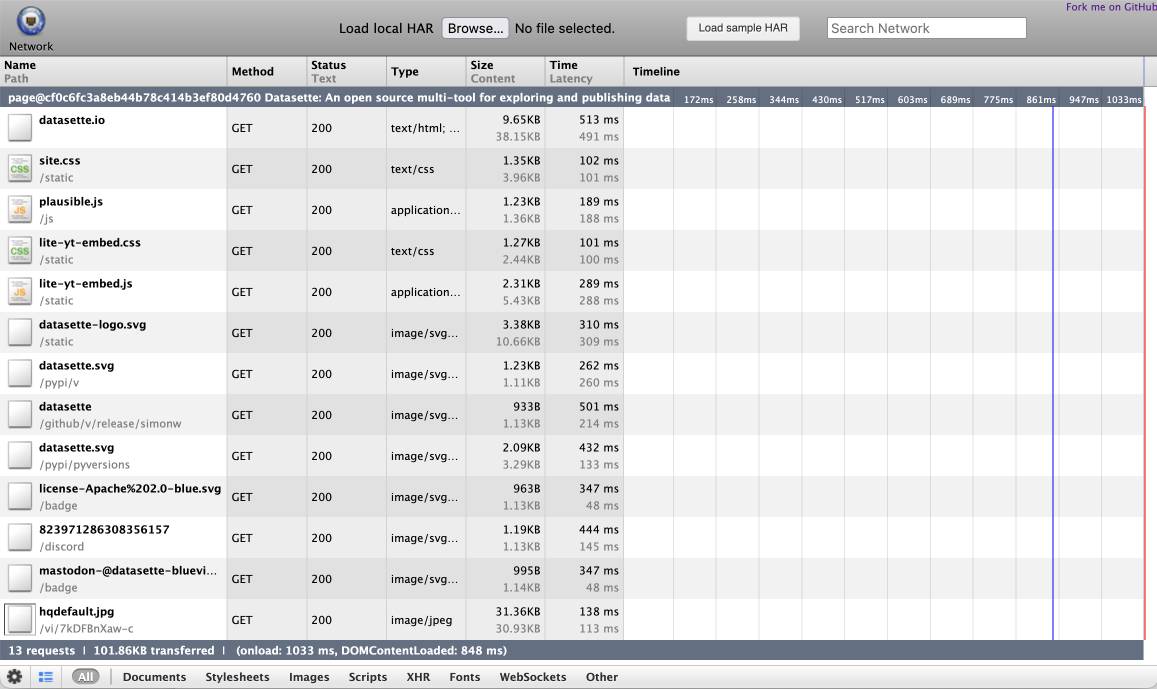
That JSON includes full copies of all of the responses, base64 encoded if they are binary files such as images.
You can add the --zip flag to instead get a datasette-io.har.zip file, containing JSON data in har.har but with the response bodies saved as separate files in that archive.
The shot-scraper multi command lets you run shot-scraper against multiple URLs in sequence, specified using a YAML file. That command now takes a --har option (or --har-zip or --har-file name-of-file), described in the documentation, which will produce a HAR at the same time as taking the screenshots.
Shots are usually defined in YAML that looks like this:
- output: example.com.png
url: http://www.example.com/
- output: w3c.org.png
url: https://www.w3.org/You can now omit the output: keys and generate a HAR file without taking any screenshots at all:
- url: http://www.example.com/
- url: https://www.w3.org/Run like this:
shot-scraper multi shots.yml --har
Which outputs:
Skipping screenshot of 'https://www.example.com/'
Skipping screenshot of 'https://www.w3.org/'
Wrote to HAR file: trace.har
shot-scraper is built on top of Playwright, and the new features use the browser.new_context(record_har_path=...) parameter.
2024
Video scraping: extracting JSON data from a 35 second screen capture for less than 1/10th of a cent
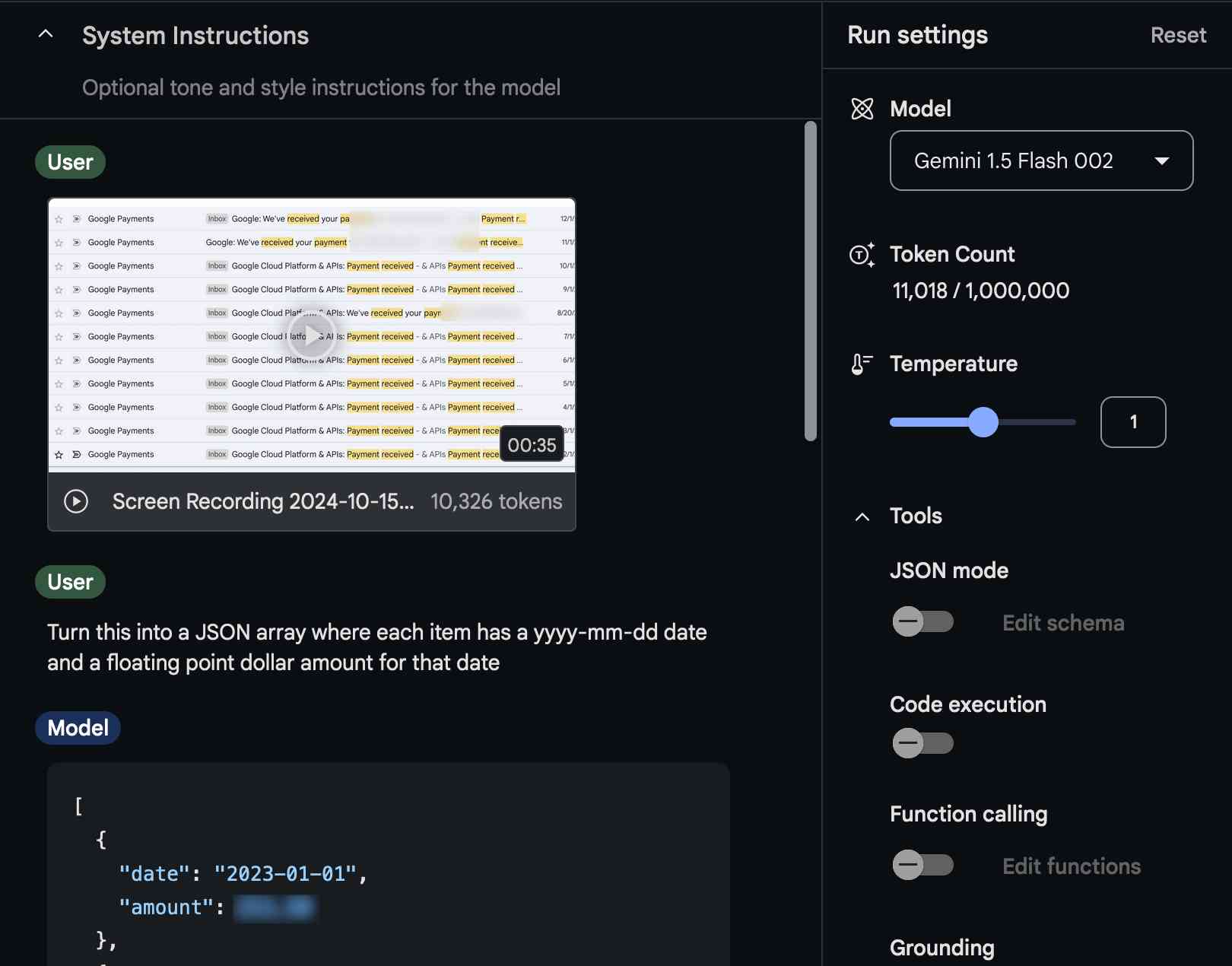
The other day I found myself needing to add up some numeric values that were scattered across twelve different emails.
[... 1,294 words]For the last few years, Meta has had a team of attorneys dedicated to policing unauthorized forms of scraping and data collection on Meta platforms. The decision not to further pursue these claims seems as close to waving the white flag as you can get against these kinds of companies. But why? [...]
In short, I think Meta cares more about access to large volumes of data and AI than it does about outsiders scraping their public data now. My hunch is that they know that any success in anti-scraping cases can be thrown back at them in their own attempts to build AI training databases and LLMs. And they care more about the latter than the former.
2023
scrapeghost (via) Scraping is a really interesting application for large language model tools like GPT3. James Turk’s scrapeghost is a very neatly designed entrant into this space—it’s a Python library and CLI tool that can be pointed at any URL and given a roughly defined schema (using a neat mini schema language) which will then use GPT3 to scrape the page and try to return the results in the supplied format.
I expect GPT-4 will have a LOT of applications in web scraping
The increased 32,000 token limit will be large enough to send it the full DOM of most pages, serialized to HTML - then ask questions to extract data
Or... take a screenshot and use the GPT4 image input mode to ask questions about the visually rendered page instead!
Might need to dust off all of those old semantic web dreams, because the world's information is rapidly becoming fully machine readable
— Me
datasette-scraper walkthrough on YouTube (via) datasette-scraper is Colin Dellow’s new plugin that turns Datasette into a powerful web scraping tool, with a web UI based on plugin-driven customizations to the Datasette interface. It’s really impressive, and this ten minute demo shows quite how much it is capable of: it can crawl sitemaps and fetch pages, caching them (using zstandard with optional custom dictionaries for extra compression) to speed up subsequent crawls... and you can add your own plugins to extract structured data from crawled pages and save it to a separate SQLite table!
2022
curl-impersonate (via) “A special build of curl that can impersonate the four major browsers: Chrome, Edge, Safari & Firefox. curl-impersonate is able to perform TLS and HTTP handshakes that are identical to that of a real browser.”
I hadn’t realized that it’s become increasingly common for sites to use fingerprinting of TLS and HTTP handshakes to block crawlers. curl-impersonate attempts to impersonate browsers much more accurately, using tricks like compiling with Firefox’s nss TLS library and Chrome’s BoringSSL.
Web Scraping via Javascript Runtime Heap Snapshots (via) This is an absolutely brilliant scraping trick. Adrian Cooney figured out a way to use Puppeteer and the Chrome DevTools protocol to take a heap snapshot of all of the JavaScript running on a web page, then recursively crawl through the heap looking for any JavaScript objects that have a specified selection of properties. This allows him to scrape data from arbitrarily complex client-side web applications. He built a JavaScript library and command line tool that implements the pattern.
Scraping web pages from the command line with shot-scraper
I’ve added a powerful new capability to my shot-scraper command line browser automation tool: you can now use it to load a web page in a headless browser, execute JavaScript to extract information and return that information back to the terminal as JSON.
[... 1,277 words]shot-scraper: automated screenshots for documentation, built on Playwright
shot-scraper is a new tool that I’ve built to help automate the process of keeping screenshots up-to-date in my documentation. It also doubles as a scraping tool—hence the name—which I picked as a complement to my git scraping and help scraping techniques.
[... 1,802 words]Help scraping: track changes to CLI tools by recording their --help using Git
I’ve been experimenting with a new variant of Git scraping this week which I’m calling Help scraping. The key idea is to track changes made to CLI tools over time by recording the output of their --help commands in a Git repository.
2021
git-history: a tool for analyzing scraped data collected using Git and SQLite
I described Git scraping last year: a technique for writing scrapers where you periodically snapshot a source of data to a Git repository in order to record changes to that source over time.
[... 2,002 words]Git scraping, the five minute lightning talk
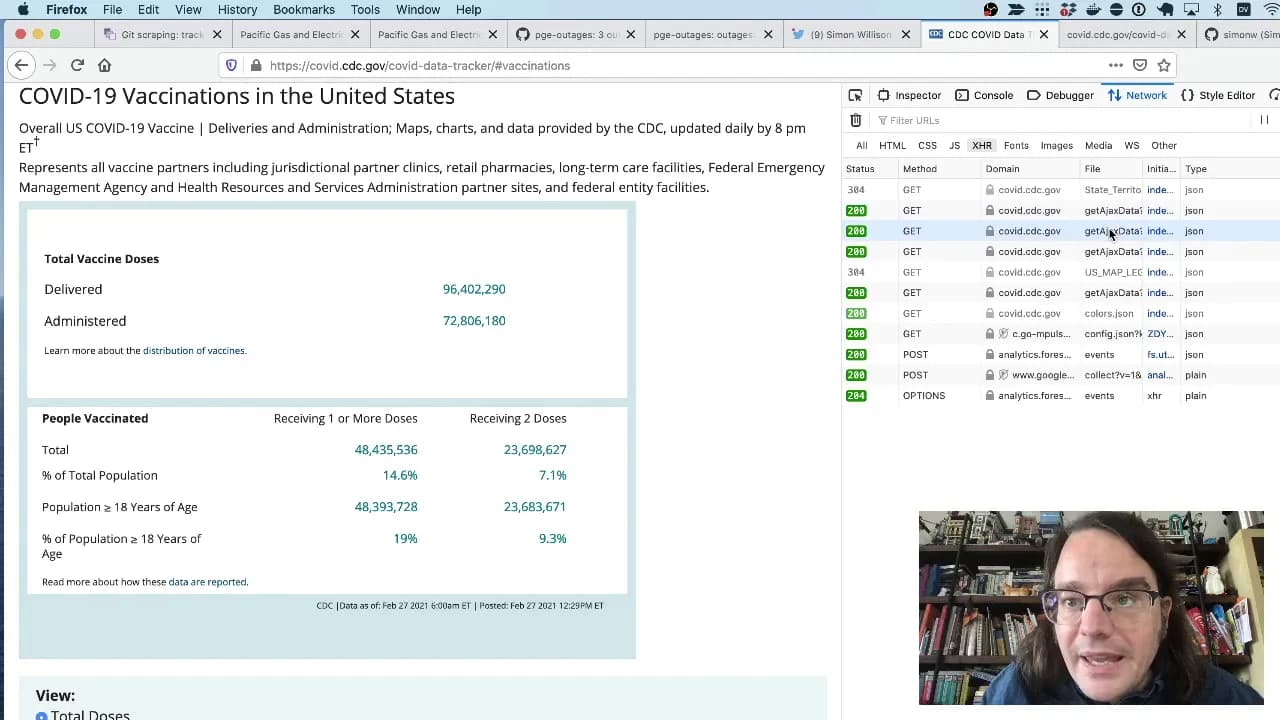
I prepared a lightning talk about Git scraping for the NICAR 2021 data journalism conference. In the talk I explain the idea of running scheduled scrapers in GitHub Actions, show some examples and then live code a new scraper for the CDC’s vaccination data using the GitHub web interface. Here’s the video.
[... 289 words]2020
selenium-wire. Really useful scraping tool: enhances the Python Selenium bindings to run against a proxy which then allows Python scraping code to look at captured requests—great for if a site you are working with triggers Ajax requests and you want to extract data from the raw JSON that came back.
Weeknotes: evernote-to-sqlite, Datasette Weekly, scrapers, csv-diff, sqlite-utils
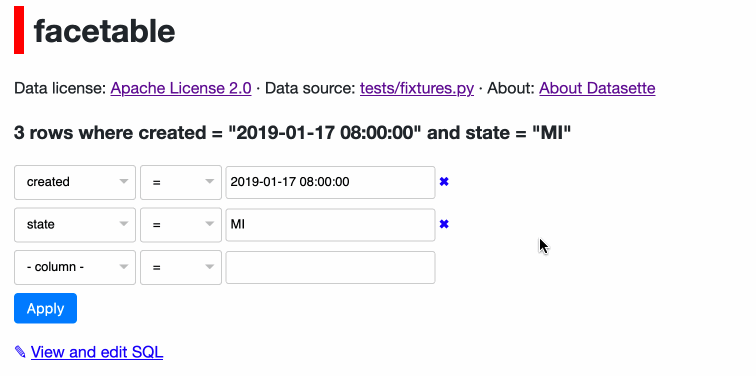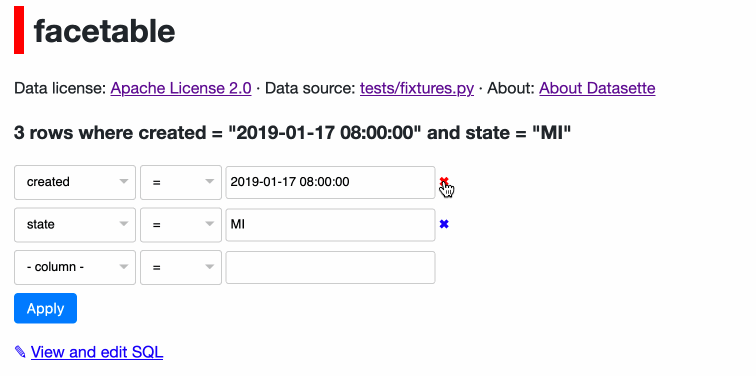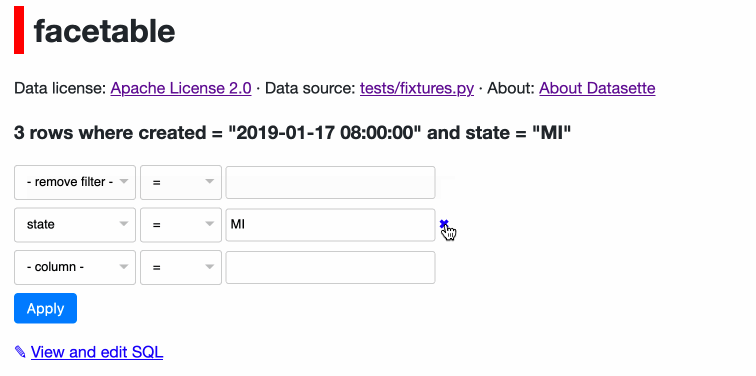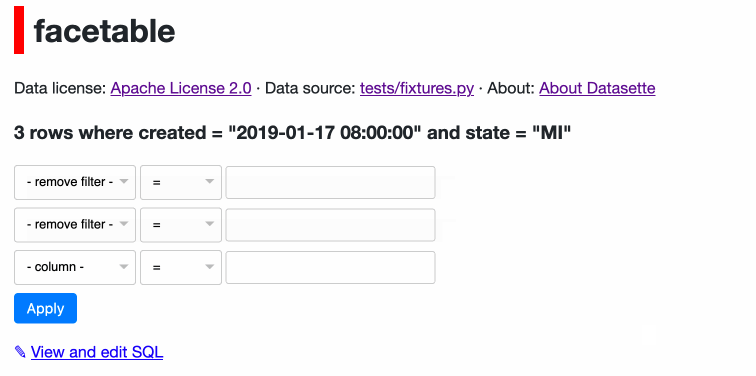
This week I built evernote-to-sqlite (see Building an Evernote to SQLite exporter), launched the Datasette Weekly newsletter, worked on some scrapers and pushed out some small improvements to several other projects.
Git scraping: track changes over time by scraping to a Git repository
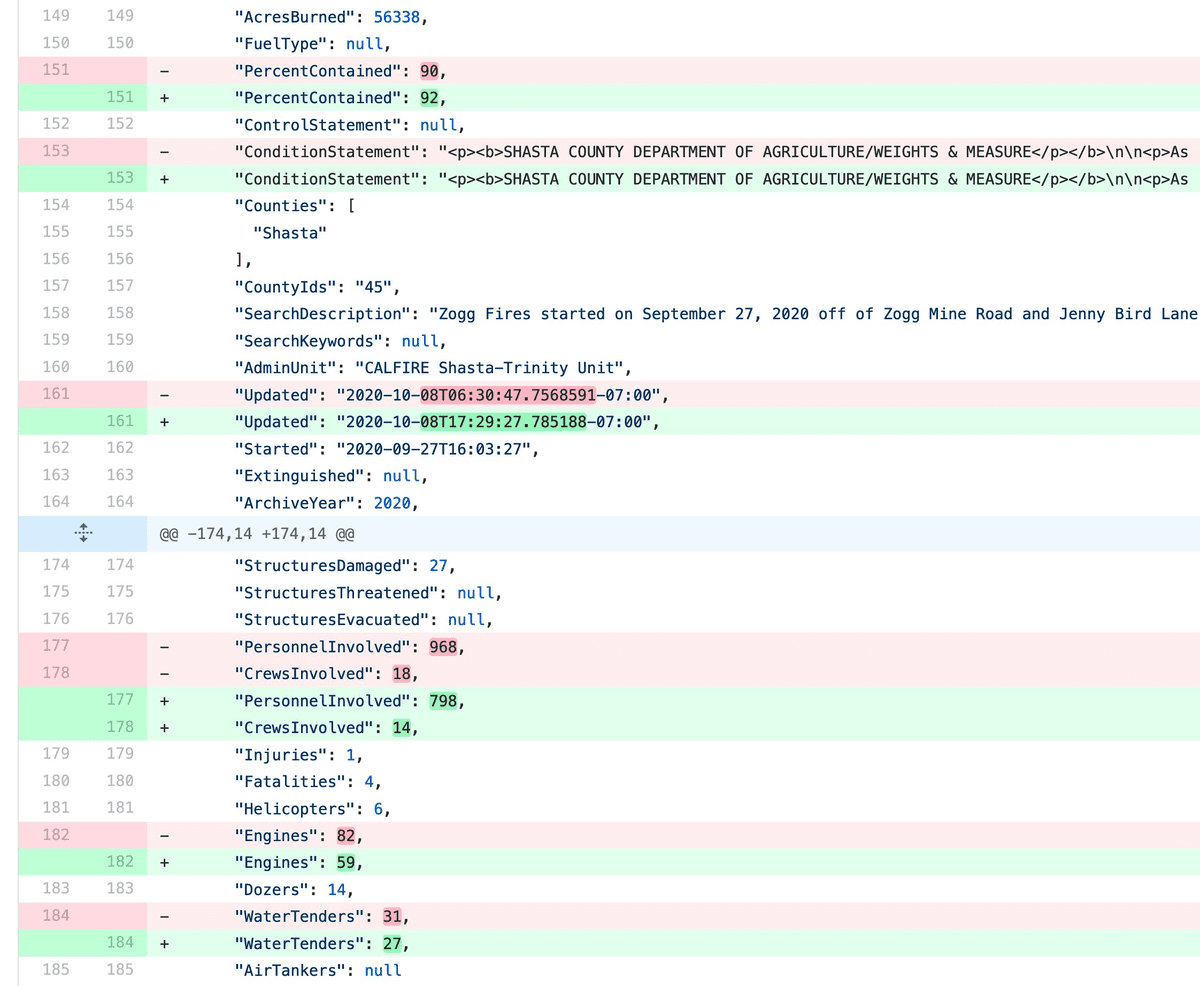
Git scraping is the name I’ve given a scraping technique that I’ve been experimenting with for a few years now. It’s really effective, and more people should use it.
[... 963 words]2019
Tracking PG&E outages by scraping to a git repo
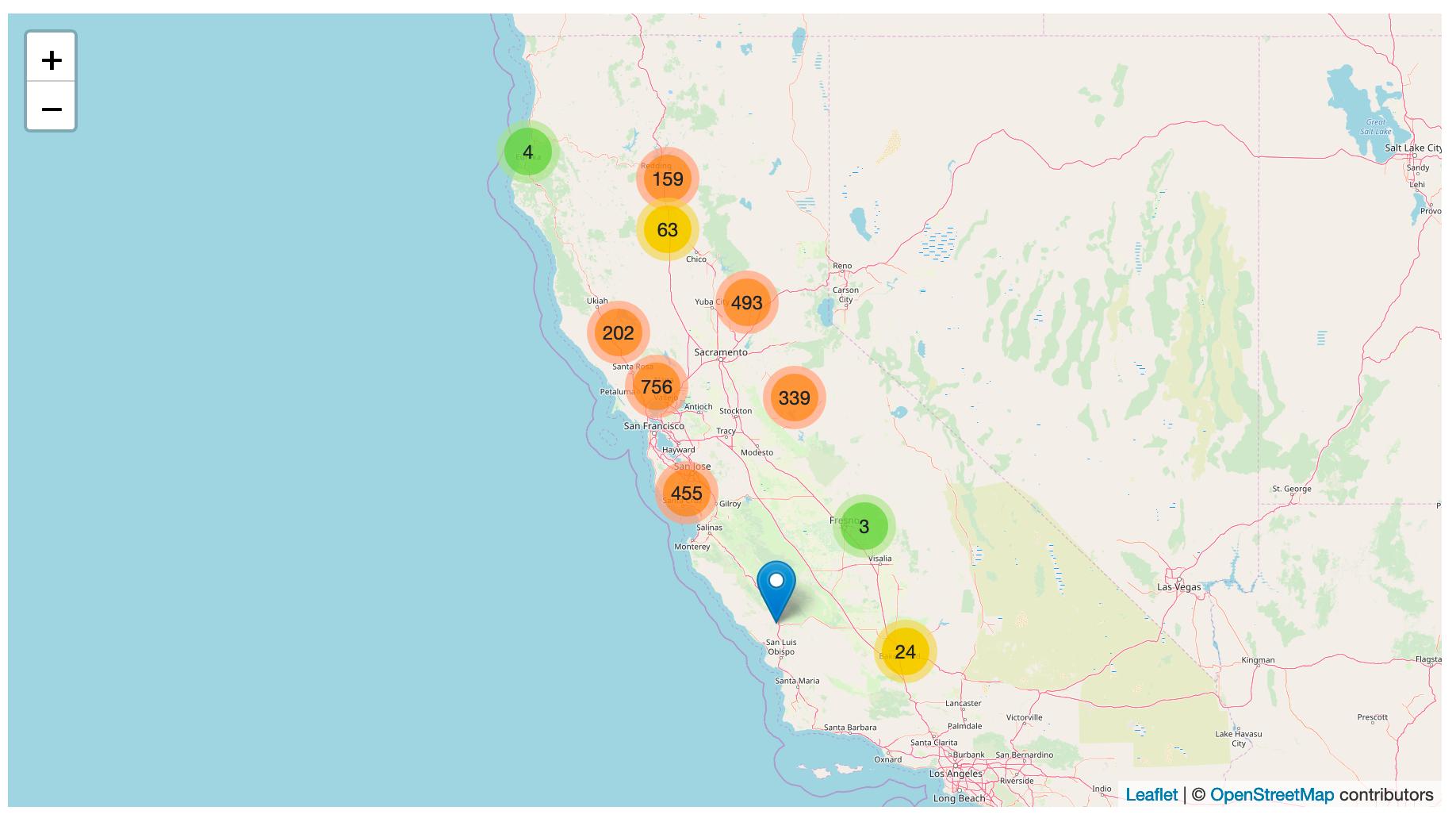
PG&E have cut off power to several million people in northern California, supposedly as a precaution against wildfires.
[... 868 words]2018
scrapely. Neat twist on a screen scraping library: this one lets you “train it” by feeding it examples of URLs paired with a dictionary of the data you would like to have extracted from that URL, then uses an instance based learning earning algorithm to run against new URLs. Slightly confusing name since it’s maintained by the scrapy team but is a totally independent project from the scrapy web crawling framework.
sqlitebiter. Similar to my csvs-to-sqlite tool, but sqlitebiter handles “CSV/Excel/HTML/JSON/LTSV/Markdown/SQLite/SSV/TSV/Google-Sheets”. Most interestingly, it works against HTML pages—run “sqlitebiter -v url ’https://en.wikipedia.org/wiki/Comparison_of_firewalls’” and it will scrape that Wikipedia page and create a SQLite table for each of the HTML tables it finds there.
kennethreitz/requests-html: HTML Parsing for Humans™ (via) Neat and tiny wrapper around requests, lxml and html2text that provides a Kenneth Reitz grade API design for intuitively fetching and scraping web pages. The inclusion of html2text means you can use a CSS selector to select a specific HTML element and then convert that to the equivalent markdown in a one-liner.
2017
Using “import refs” to iteratively import data into Django
I’ve been writing a few scripts to backfill my blog with content I originally posted elsewhere. So far I’ve imported answers I posted on Quora (background), answers I posted on Ask MetaFilter and content I recovered from the Internet Archive.
[... 559 words]Changelogs to help understand the fires in the North Bay
The situation in the counties north of San Francisco is horrifying right now. I’ve repurposed some of the tools I built to for the Irma Response project last month to collect and track some data that might be of use to anyone trying to understand what’s happening up there. I’m sharing these now in the hope that they might prove useful.
[... 383 words]Scraping hurricane Irma
The Irma Response project is a team of volunteers working together to make information available during and after the storm. There is a huge amount of information out there, on many different websites. The Irma API is an attempt to gather key information in one place, verify it and publish it in a reuseable way. It currently powers the irmashelters.org website.
[... 438 words]