98 posts tagged “html”
2026
Yet another in my growing collection of paste-conversion tools. This one accepts pasted rich text from browsers (with embedded HTML tables) and converts every detected table into HTML, Markdown, CSV, TSV, or JSON.
Try it out by selecting everything on the Wikipedia List of cities and towns in the San Francisco Bay Area page and pasting it directly into the tool:
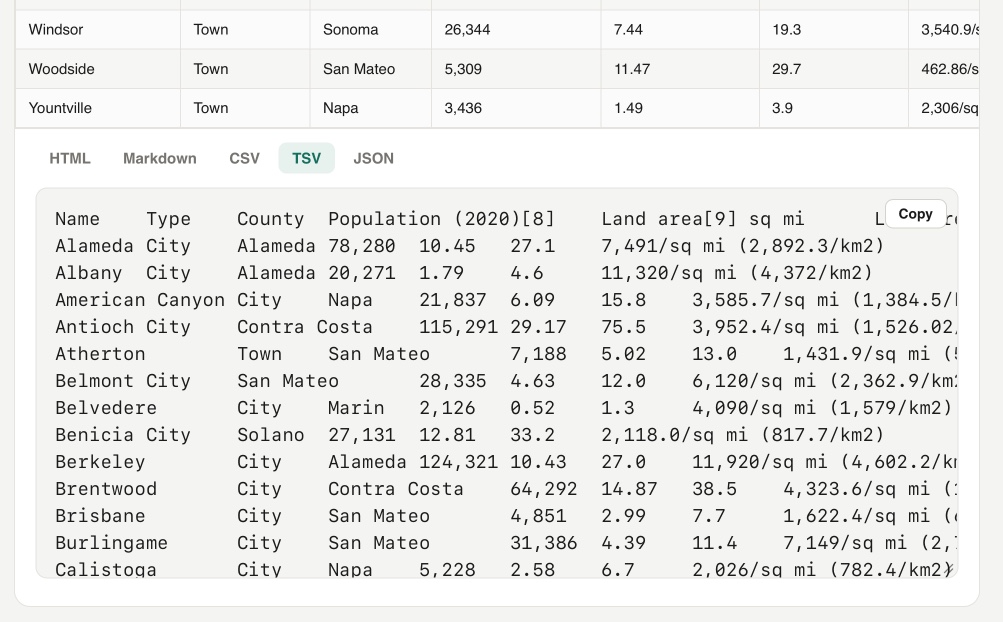
On a similar note, I recently rebuilt my Rich text to markdown tool to add support for tables and generally improve the UI.
Update: It turns out Wikipedia has an open CORS API for retrieving the full rendered HTML content of any page - demo here - so I had Codex add the ability to search Wikipedia for a page and then automatically import and display any tables from that page.
On the <dl>
(via)
I learned a few new-to-me things about the <dl> element from this article by Ben Meyer:
- A
<dt>can be followed by multiple<dd> - You can optionally group the
<dt>and<dd>elements in a<div>for styling - but only a<div>. - You can label them using ARIA.
- They've been called "description lists", not "definition lists", since an HTML5 draft in 2008.
So this is valid:
<h2 id="credits">Credits</h2> <dl aria-labelledby="credits"> <div> <dt>Author</dt> <dd>Jeffrey Zeldman</dd> <dd>Ethan Marcotte</dd> </div> </dl>
Here's a useful note from Adrian Roselli on screen reader support for description lists.
Using Claude Code: The Unreasonable Effectiveness of HTML. Thought-provoking piece by Thariq Shihipar (on the Claude Code team at Anthropic) advocating for HTML over Markdown as an output format to request from Claude.
The article is crammed with interesting examples (collected on this site) and prompt suggestions like this one:
Help me review this PR by creating an HTML artifact that describes it. I'm not very familiar with the streaming/backpressure logic so focus on that. Render the actual diff with inline margin annotations, color-code findings by severity and whatever else might be needed to convey the concept well.
I've been defaulting to asking for most things in Markdown since the GPT-4 days, when the 8,192 token limit meant that Markdown's token-efficiency over HTML was extremely worthwhile.
Thariq's piece here has caused me to reconsider that, especially for output. Asking Claude for an explanation in HTML means it can drop in SVG diagrams, interactive widgets, in-page navigation and all sorts of other neat ways of making the information more pleasant to navigate.
I wrote about Useful patterns for building HTML tools last December, but that was focused very much on interactive utilities like the ones on my tools.simonwillison.net site. I'm excited to start experimenting more with rich HTML explanations in response to ad-hoc prompts.
Trying this out on copy.fail
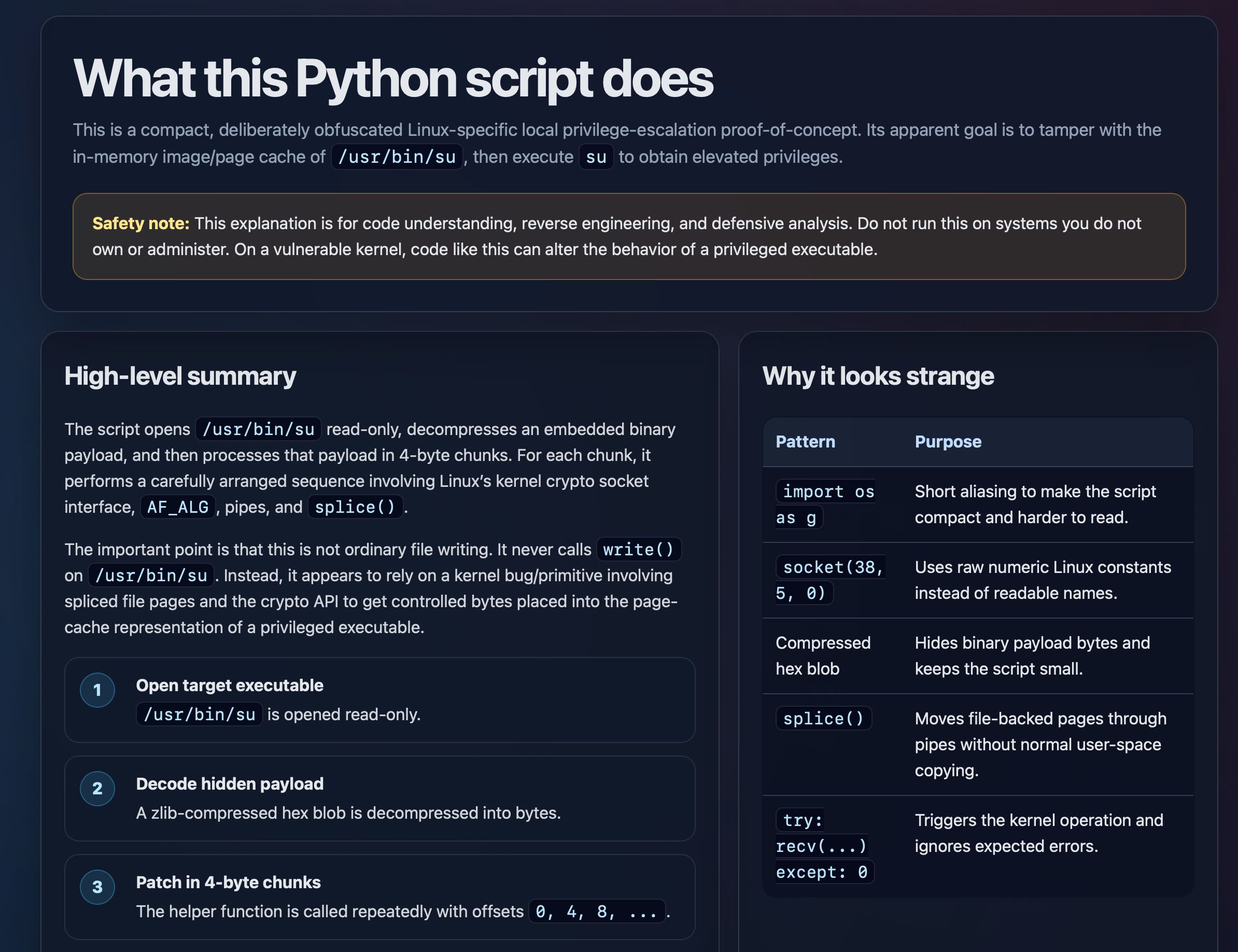
copy.fail describes a recently discovered Linux security exploit, including a proof of concept distributed as obfuscated Python.
I tried having GPT-5.5 create an HTML explanation of the exploit like this:
curl https://copy.fail/exp | llm -m gpt-5.5 -s 'Explain this code in detail. Reformat it, expand out any confusing bits and go deep into what it does and how it works. Output HTML, neatly styled and using capabilities of HTML and CSS and JavaScript to make the explanation rich and interactive and as clear as possible'
Here's the resulting HTML page. It's pretty good, though I should have emphasized explaining the exploit over the Python harness around it.
Gwtar: a static efficient single-file HTML format (via) Fascinating new project from Gwern Branwen and Said Achmiz that targets the challenge of combining large numbers of assets into a single archived HTML file without that file being inconvenient to view in a browser.
The key trick it uses is to fire window.stop() early in the page to prevent the browser from downloading the whole thing, then following that call with inline tar uncompressed content.
It can then make HTTP range requests to fetch content from that tar data on-demand when it is needed by the page.
The JavaScript that has already loaded rewrites asset URLs to point to https://localhost/ purely so that they will fail to load. Then it uses a PerformanceObserver to catch those attempted loads:
let perfObserver = new PerformanceObserver((entryList, observer) => {
resourceURLStringsHandler(entryList.getEntries().map(entry => entry.name));
});
perfObserver.observe({ entryTypes: [ "resource" ] });
That resourceURLStringsHandler callback finds the resource if it is already loaded or fetches it with an HTTP range request otherwise and then inserts the resource in the right place using a blob: URL.
Here's what the window.stop() portion of the document looks like if you view the source:
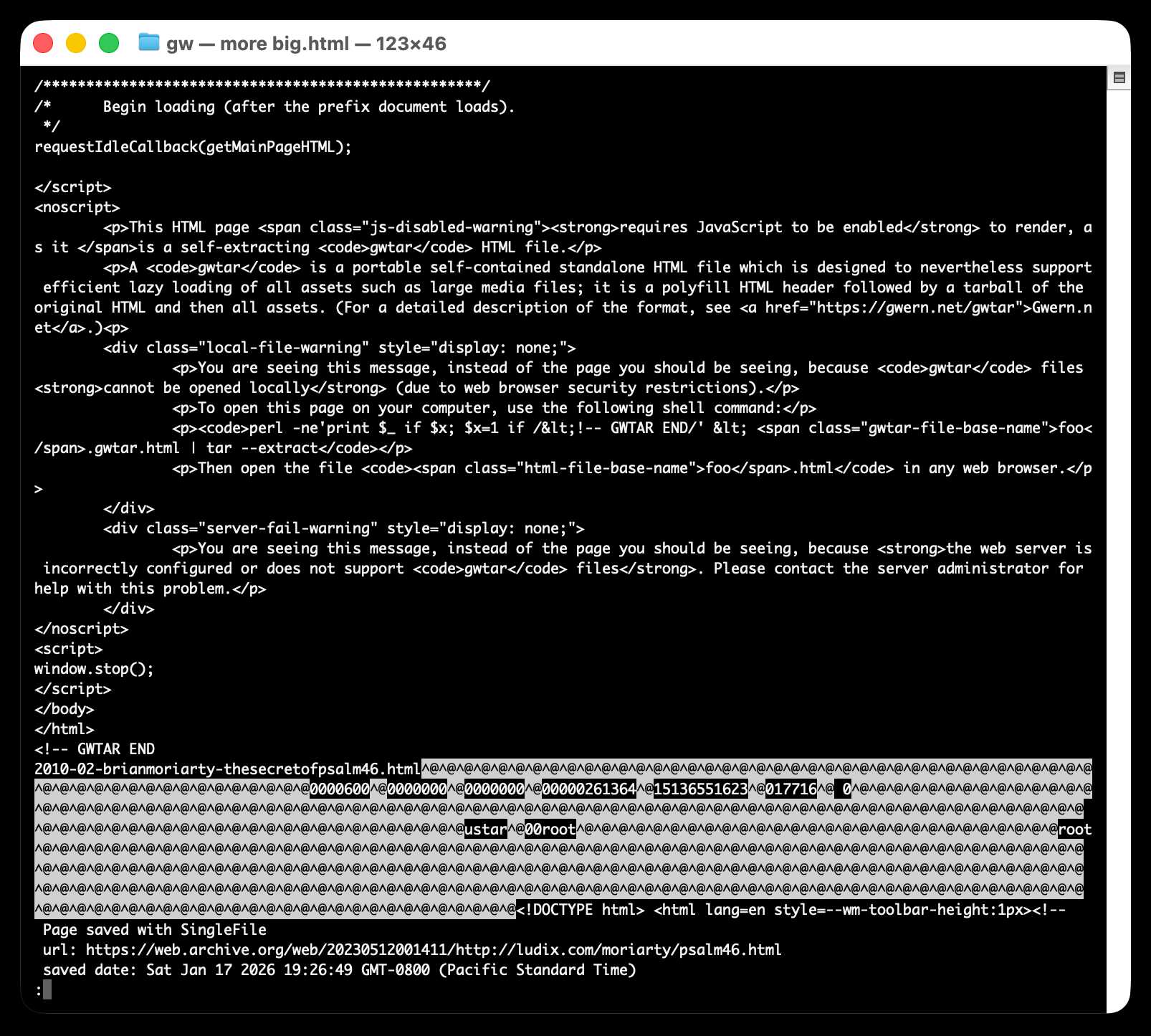
Amusingly for an archive format it doesn't actually work if you open the file directly on your own computer. Here's what you see if you try to do that:
You are seeing this message, instead of the page you should be seeing, because
gwtarfiles cannot be opened locally (due to web browser security restrictions).To open this page on your computer, use the following shell command:
perl -ne'print $_ if $x; $x=1 if /<!-- GWTAR END/' < foo.gwtar.html | tar --extractThen open the file
foo.htmlin any web browser.
2025
I ported JustHTML from Python to JavaScript with Codex CLI and GPT-5.2 in 4.5 hours

I wrote about JustHTML yesterday—Emil Stenström’s project to build a new standards compliant HTML5 parser in pure Python code using coding agents running against the comprehensive html5lib-tests testing library. Last night, purely out of curiosity, I decided to try porting JustHTML from Python to JavaScript with the least amount of effort possible, using Codex CLI and GPT-5.2. It worked beyond my expectations.
[... 1,818 words]JustHTML is a fascinating example of vibe engineering in action
I recently came across JustHTML, a new Python library for parsing HTML released by Emil Stenström. It’s a very interesting piece of software, both as a useful library and as a case study in sophisticated AI-assisted programming.
[... 956 words]Useful patterns for building HTML tools
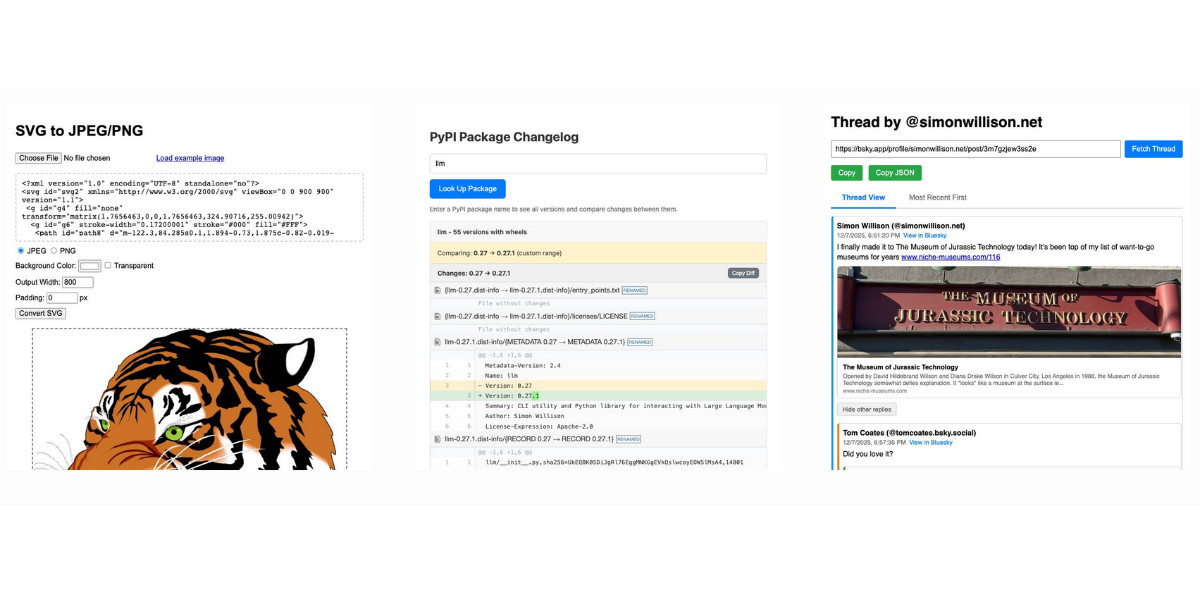
I’ve started using the term HTML tools to refer to HTML applications that I’ve been building which combine HTML, JavaScript, and CSS in a single file and use them to provide useful functionality. I have built over 150 of these in the past two years, almost all of them written by LLMs. This article presents a collection of useful patterns I’ve discovered along the way.
[... 4,231 words]The fetch()ening (via) After several years of stable htmx 2.0 and a promise to never release a backwards-incompatible htmx 3 Carson Gross is technically keeping that promise... by skipping to htmx 4 instead!
The main reason is to replace XMLHttpRequest with fetch() - a change that will have enough knock-on compatibility effects to require a major version bump - so they're using that as an excuse to clean up various other accumulated design warts at the same time.
htmx is a very responsibly run project. Here's their plan for the upgrade:
That said, htmx 2.0 users will face an upgrade project when moving to 4.0 in a way that they did not have to in moving from 1.0 to 2.0.
I am sorry about that, and want to offer three things to address it:
- htmx 2.0 (like htmx 1.0 & intercooler.js 1.0) will be supported in perpetuity, so there is absolutely no pressure to upgrade your application: if htmx 2.0 is satisfying your hypermedia needs, you can stick with it.
- We will create extensions that revert htmx 4 to htmx 2 behaviors as much as is feasible (e.g. Supporting the old implicit attribute inheritance model, at least)
- We will roll htmx 4.0 out slowly, over a multi-year period. As with the htmx 1.0 -> 2.0 upgrade, there will be a long period where htmx 2.x is
latestand htmx 4.x isnext
There are lots of neat details in here about the design changes they plan to make. It's a really great piece of technical writing - I learned a bunch about htmx and picked up some good notes on API design in general from this.
Should form labels be wrapped or separate? (via) James Edwards notes that wrapping a form input in a label event like this has a significant downside:
<label>Name <input type="text"></label>
It turns out both Dragon Naturally Speaking for Windows and Voice Control for macOS and iOS fail to understand this relationship!
You need to use the explicit <label for="element_id"> syntax to ensure those screen readers correctly understand the relationship between label and form field. You can still nest the input inside the label if you like:
<label for="idField">Name
<input id="idField" type="text">
</label>
Today I learned - via a proposal to remove mentions of XSLT from the HTML spec - that congress.gov uses XSLT to serve XML bills as XHTML - here's H. R. 3617 117th CONGRESS 1st Session for example.
View source on that page and it starts like this:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="billres.xsl"?> <!DOCTYPE bill PUBLIC "-//US Congress//DTDs/bill.dtd//EN" "bill.dtd"> <bill bill-stage="Introduced-in-House" dms-id="H5BD50AB7712141319B352D46135AAC2B" public-private="public" key="H" bill-type="olc"> <metadata xmlns:dc="http://purl.org/dc/elements/1.1/"> <dublinCore> <dc:title>117 HR 3617 IH: Marijuana Opportunity Reinvestment and Expungement Act of 2021</dc:title> <dc:publisher>U.S. House of Representatives</dc:publisher> <dc:date>2021-05-28</dc:date> <dc:format>text/xml</dc:format> <dc:language>EN</dc:language> <dc:rights>Pursuant to Title 17 Section 105 of the United States Code, this file is not subject to copyright protection and is in the public domain.</dc:rights> </dublinCore> </metadata> <form> <distribution-code display="yes">I</distribution-code> <congress display="yes">117th CONGRESS</congress><session display="yes">1st Session</session> <legis-num display="yes">H. R. 3617</legis-num> <current-chamber>IN THE HOUSE OF REPRESENTATIVES</current-chamber>
Digging into those XSLT stylesheets leads to billres-details.xsl - gist copy here - which starts with a huge changelog comment with notes dating all the way back to 2004!
If you've found web development frustrating over the past 5-10 years, here's something that has worked worked great for me: give yourself permission to avoid any form of frontend build system (so no npm / React / TypeScript / JSX / Babel / Vite / Tailwind etc) and code in HTML and JavaScript like it's 2009.
The joy came flooding back to me! It turns out browser APIs are really good now.
You don't even need jQuery to paper over the gaps any more - use document.querySelectorAll() and fetch() directly and see how much value you can build with a few dozen lines of code.
CSS Minecraft (via) Incredible project by Benjamin Aster:
There is no JavaScript on this page. All the logic is made 100% with pure HTML & CSS. For the best performance, please close other tabs and running programs.
The page implements a full Minecraft-style world editor: you can place and remove blocks of 7 different types in a 9x9x9 world, and rotate that world in 3D to view it from different angles.
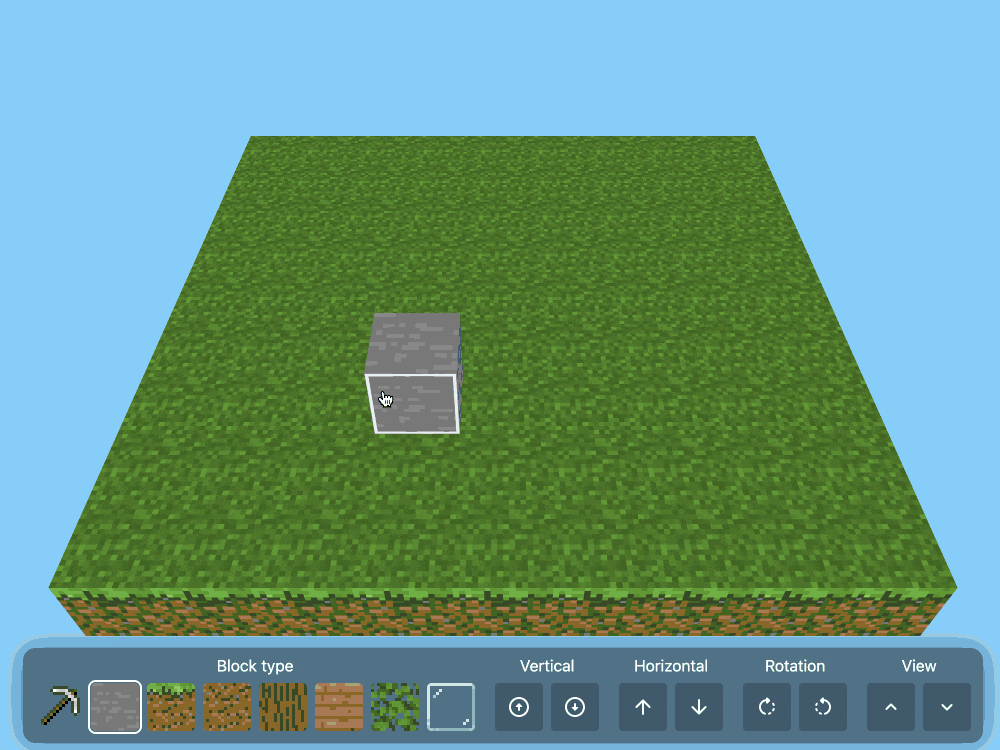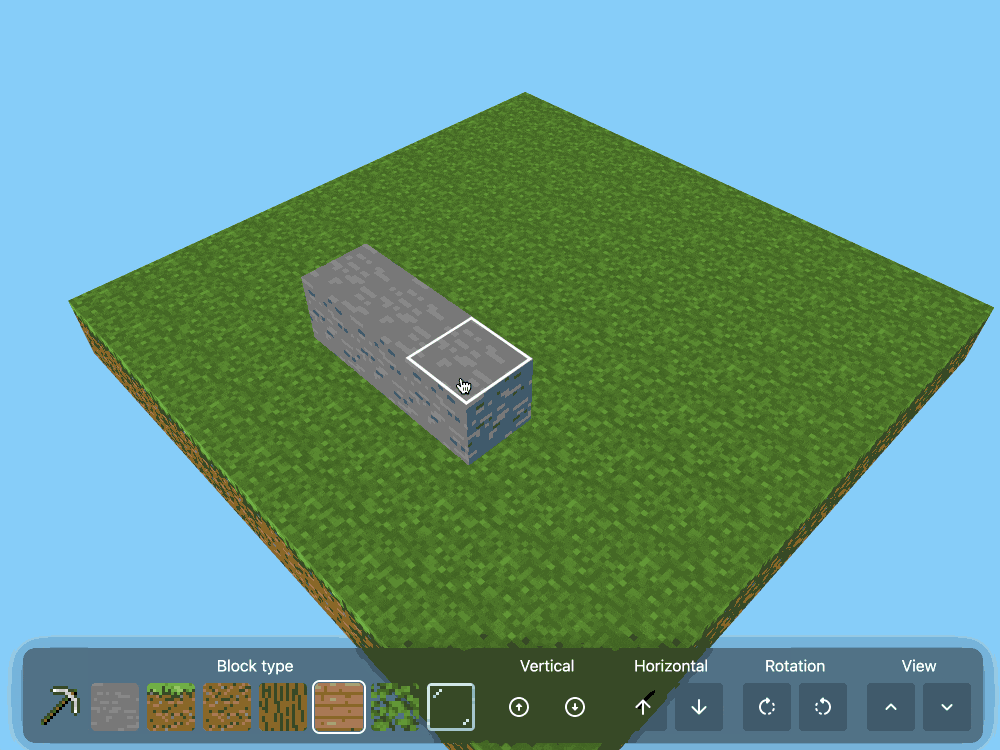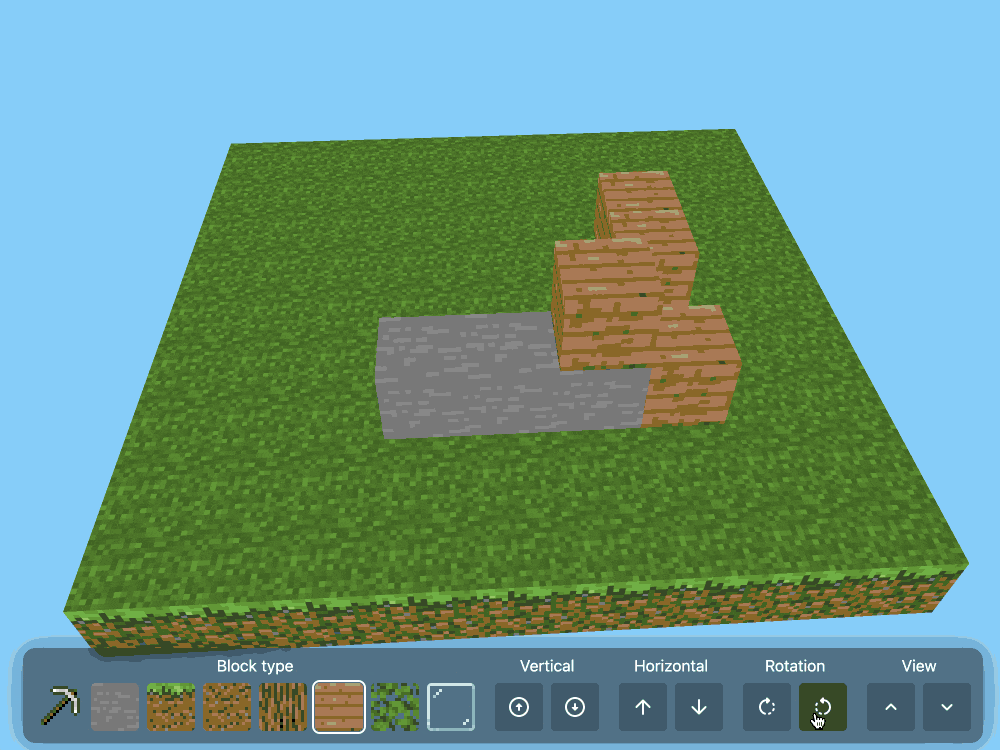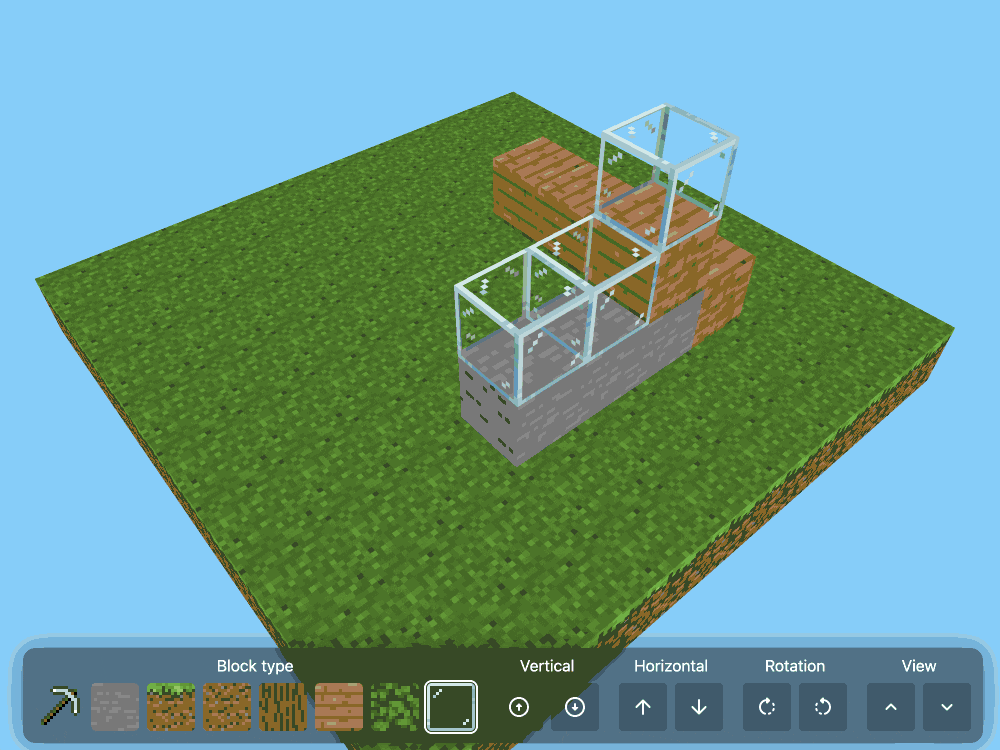
It's implemented in just 480 lines of CSS... and 46,022 lines (3.07MB) of HTML!
The key trick that gets this to work is labels combined with the has() selector. The page has 35,001 <label> elements and 5,840 <input type="radio"> elements - those radio elements are the state storage engine. Clicking on any of the six visible faces of a cube is clicking on a label, and the for="" of that label is the radio box for the neighboring cube in that dimension.
When you switch materials you're actually switching the available visible labels:
.controls:has( > .block-chooser > .stone > input[type=radio]:checked ) ~ main .cubes-container > .cube:not(.stone) { display: none; }
Claude Opus 4 explanation: "When the "stone" radio button is checked, all cube elements except those with the .stone class are hidden (display: none)".
Here's a shortened version of the Pug template (full code here) which illustrates how the HTML structure works:
//- pug index.pug -w - const blocks = ["air", "stone", "grass", "dirt", "log", "wood", "leaves", "glass"]; - const layers = 9; - const rows = 9; - const columns = 9; <html lang="en" style="--layers: #{layers}; --rows: #{rows}; --columns: #{columns}"> <!-- ... --> <div class="blocks"> for _, layer in Array(layers) for _, row in Array(rows) for _, column in Array(columns) <div class="cubes-container" style="--layer: #{layer}; --row: #{row}; --column: #{column}"> - const selectedBlock = layer === layers - 1 ? "grass" : "air"; - const name = `cube-layer-${layer}-row-${row}-column-${column}`; <div class="cube #{blocks[0]}"> - const id = `${name}-${blocks[0]}`; <input type="radio" name="#{name}" id="#{id}" !{selectedBlock === blocks[0] ? "checked" : ""} /> <label for="#{id}" class="front"></label> <label for="#{id}" class="back"></label> <label for="#{id}" class="left"></label> <label for="#{id}" class="right"></label> <label for="#{id}" class="top"></label> <label for="#{id}" class="bottom"></label> </div> each block, index in blocks.slice(1) - const id = `${name}-${block}`; - const checked = index === 0; <div class="cube #{block}"> <input type="radio" name="#{name}" id="#{id}" !{selectedBlock === block ? "checked" : ""} /> <label for="cube-layer-#{layer}-row-#{row + 1}-column-#{column}-#{block}" class="front"></label> <label for="cube-layer-#{layer}-row-#{row - 1}-column-#{column}-#{block}" class="back"></label> <label for="cube-layer-#{layer}-row-#{row}-column-#{column + 1}-#{block}" class="left"></label> <label for="cube-layer-#{layer}-row-#{row}-column-#{column - 1}-#{block}" class="right"></label> <label for="cube-layer-#{layer - 1}-row-#{row}-column-#{column}-#{block}" class="top"></label> <label for="cube-layer-#{layer + 1}-row-#{row}-column-#{column}-#{block}" class="bottom"></label> </div> //- /each </div> //- /for //- /for //- /for </div> <!-- ... -->
So for every one of the 9x9x9 = 729 cubes there is a set of eight radio boxes sharing the same name such as cube-layer-0-row-0-column-3 - which means it can have one of eight values ("air" is clear space, the others are material types). There are six labels, one for each side of the cube - and those label for="" attributes target the next block over of the current selected, visible material type.
The other brilliant technique is the way it implements 3D viewing with controls for rotation and moving the viewport. The trick here relies on CSS animation:
.controls:has(.up:active) ~ main .down { animation-play-state: running; } .controls:has(.down:active) ~ main .up { animation-play-state: running; } .controls:has(.clockwise:active) ~ main .clockwise { animation-play-state: running; } .controls:has(.counterclockwise:active) ~ main .counterclockwise { animation-play-state: running; }
Then later on there are animations defined for each of those different controls:
.content .clockwise { animation: var(--animation-duration) linear 1ms paused rotate-clockwise; } @keyframes rotate-clockwise { from { rotate: y 0turn; } to { rotate: y calc(-1 * var(--max-rotation)); } } .content .counterclockwise { animation: var(--animation-duration) linear 1ms paused rotate-counterclockwise; } @keyframes rotate-counterclockwise { from { rotate: y 0turn; } to { rotate: y calc(var(--max-rotation)); } }
Any time you hold the mouse down on one of the controls you switch the animation state out of paused to running, until you release that button again. As the animation runs it changes the various 3D transform properties applied to the selected element.
It's fiendishly clever, and actually quite elegant and readable once you figure out the core tricks it's using.
If you want to create completely free software for other people to use, the absolute best delivery mechanism right now is static HTML and JavaScript served from a free web host with an established reputation.
Thanks to WebAssembly the set of potential software that can be served in this way is vast and, I think, under appreciated. Pyodide means we can ship client-side Python applications now!
This assumes that you would like your gift to the world to keep working for as long as possible, while granting you the freedom to lose interest and move onto other projects without needing to keep covering expenses far into the future.
Even the cheapest hosting plan requires you to monitor and update billing details every few years. Domains have to be renewed. Anything that runs server-side will inevitably need to be upgraded someday - and the longer you wait between upgrades the harder those become.
My top choice for this kind of thing in 2025 is GitHub, using GitHub Pages. It's free for public repositories and I haven't seen GitHub break a working URL that they have hosted in the 17+ years since they first launched.
A few years ago I'd have recommended Heroku on the basis that their free plan had stayed reliable for more than a decade, but Salesforce took that accumulated goodwill and incinerated it in 2022.
It almost goes without saying that you should release it under an open source license. The license alone is not enough to ensure regular human beings can make use of what you have built though: give people a link to something that works!
Default styles for h1 elements are changing
(via)
Wow, this is a rare occurrence! Firefox are rolling out a change to the default user-agent stylesheet for nested <h1> elements, currently ramping from 5% to 50% of users and with full roll-out planned for Firefox 140 in June 2025. Chrome is showing deprecation warnings and Safari are expected to follow suit in the future.
What's changing? The default sizes of <h1> elements that are nested inside <article>, <aside>, <nav> and <section>.
These are the default styles being removed:
/* where x is :is(article, aside, nav, section) */ x h1 { margin-block: 0.83em; font-size: 1.50em; } x x h1 { margin-block: 1.00em; font-size: 1.17em; } x x x h1 { margin-block: 1.33em; font-size: 1.00em; } x x x x h1 { margin-block: 1.67em; font-size: 0.83em; } x x x x x h1 { margin-block: 2.33em; font-size: 0.67em; }
The short version is that, many years ago, the HTML spec introduced the idea that an <h1> within a nested section should have the same meaning (and hence visual styling) as an <h2>. This never really took off and wasn't reflected by the accessibility tree, and was removed from the HTML spec in 2022. The browsers are now trying to cleanup the legacy default styles.
This advice from that post sounds sensible to me:
- Do not rely on default browser styles for conveying a heading hierarchy. Explicitly define your document hierarchy using
<h2>for second-level headings,<h3>for third-level, etc.- Always define your own
font-sizeandmarginfor<h1>elements.
Backstory on the default styles for the HTML dialog modal. My TIL about Styling an HTML dialog modal to take the full height of the viewport (here's the interactive demo) showed up on Hacker News this morning, and attracted this fascinating comment from Chromium engineer Ian Kilpatrick.
There's quite a bit of history here, but the abbreviated version is that the dialog element was originally added as a replacement for window.alert(), and there were a libraries polyfilling dialog and being surprisingly widely used.
The mechanism which dialog was originally positioned was relatively complex, and slightly hacky (magic values for the insets).
Changing the behaviour basically meant that we had to add "overflow:auto", and some form of "max-height"/"max-width" to ensure that the content within the dialog was actually reachable.
The better solution to this was to add "max-height:stretch", "max-width:stretch". You can see the discussion for this here.
The problem is that no browser had (and still has) shipped the "stretch" keyword. (Blink likely will "soon")
However this was pushed back against as this had to go in a specification - and nobody implemented it ("-webit-fill-available" would have been an acceptable substitute in Blink but other browsers didn't have this working the same yet).
Hence the calc() variant. (Primarily because of "box-sizing:content-box" being the default, and pre-existing border/padding styles on dialog that we didn't want to touch). [...]
I particularly enjoyed this insight into the challenges of evolving the standards that underlie the web, even for something this small:
One thing to keep in mind is that any changes that changes web behaviour is under some time pressure. If you leave something too long, sites will start relying on the previous behaviour - so it would have been arguably worse not to have done anything.
Also from the comments I learned that Firefox DevTools can show you user-agent styles, but that option is turned off by default - notes on that here. Once I turned this option on I saw references to an html.css stylesheet, so I dug around and found that in the Firefox source code. Here's the commit history for that file on the official GitHub mirror, which provides a detailed history of how Firefox default HTML styles have evolved with the standards over time.
And via uallo here are the same default HTML styles for other browsers:
TIL: Styling an HTML dialog modal to take the full height of the viewport.
I spent some time today trying to figure out how to have a modal <dialog> element present as a full height side panel that animates in from the side. The full height bit was hard, until Natalie helped me figure out that browsers apply a default max-height: calc(100% - 6px - 2em); rule which needs to be over-ridden.
Also included: some spelunking through the HTML spec to figure out where that calc() expression was first introduced. The answer was November 2020.
strip-tags 0.6. It's been a while since I updated this tool, but in investigating a tricky mistake in my tutorial for LLM schemas I discovered a bug that I needed to fix.
Those release notes in full:
- Fixed a bug where
strip-tags -t metastill removed<meta>tags from the<head>because the entire<head>element was removed first. #32- Kept
<meta>tags now default to keeping theircontentandpropertyattributes.- The CLI
-m/--minifyoption now also removes any remaining blank lines. #33- A new
strip_tags(remove_blank_lines=True)option can be used to achieve the same thing with the Python library function.
Now I can do this and persist the <meta> tags for the article along with the stripped text content:
curl -s 'https://apnews.com/article/trump-federal-employees-firings-a85d1aaf1088e050d39dcf7e3664bb9f' | \
strip-tags -t meta --minify
Here's the output from that command.
2024
Clay UI library (via) Fascinating project by Nic Barker, who describes Clay like this:
Clay is a flex-box style UI auto layout library in C, with declarative syntax and microsecond performance.
His intro video to the library is outstanding: I learned a ton about how UI layout works from this, and the animated visual explanations are clear, tasteful and really helped land the different concepts:
Clay is a C library delivered in a single ~2000 line clay.h dependency-free header file. It only handles layout calculations: if you want to render the result you need to add an additional rendering layer.
In a fascinating demo of the library, the Clay site itself is rendered using Clay C compiled to WebAssembly! You can even switch between the default HTML renderer and an alternative based on Canvas.
This isn't necessarily a great idea: because the layout is entirely handled using <div> elements positioned using transform: translate(0px, 70px) style CSS attempting to select text across multiple boxes behaves strangely, and it's not clear to me what the accessibility implications are.
Update: Matt Campbell:
The accessibility implications are as serious as you might guess. The links aren't properly labeled, there's no semantic markup such as headings, and since there's a div for every line, continuous reading with a screen reader is choppy, that is, it pauses at the end of every physical line.
It does make for a very compelling demo of what Clay is capable of though, especially when you resize your browser window and the page layout is recalculated in real-time via the Clay WebAssembly bridge.
You can hit "D" on the website and open up a custom Clay debugger showing the hierarchy of layout elements on the page:
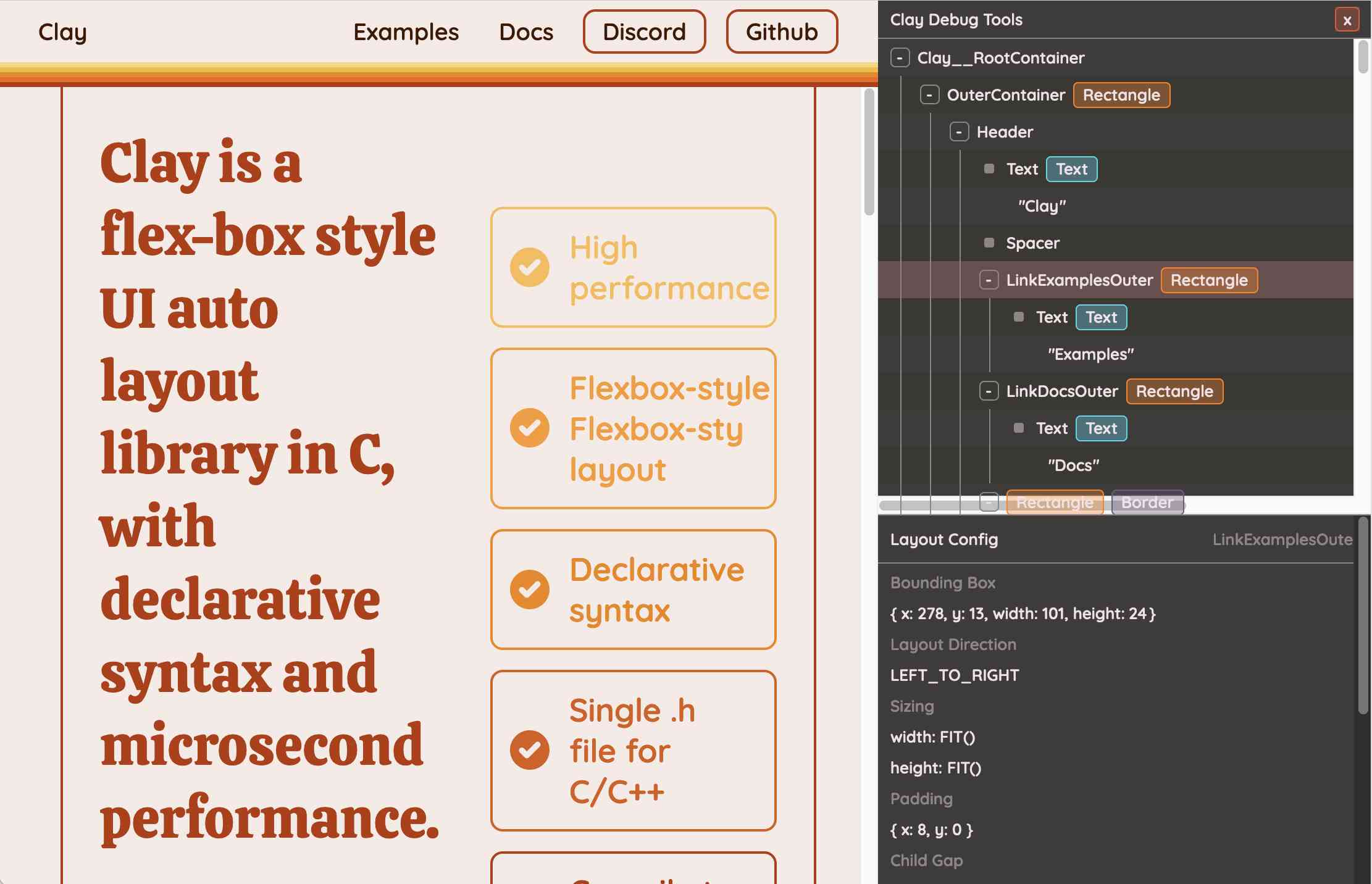
This also means that the entire page is defined using C code! Given that, I find the code itself surprisingly readable
void DeclarativeSyntaxPageDesktop() {
CLAY(CLAY_ID("SyntaxPageDesktop"), CLAY_LAYOUT({ .sizing = { CLAY_SIZING_GROW(), CLAY_SIZING_FIT({ .min = windowHeight - 50 }) }, .childAlignment = {0, CLAY_ALIGN_Y_CENTER}, .padding = {.x = 50} })) {
CLAY(CLAY_ID("SyntaxPage"), CLAY_LAYOUT({ .sizing = { CLAY_SIZING_GROW(), CLAY_SIZING_GROW() }, .childAlignment = { 0, CLAY_ALIGN_Y_CENTER }, .padding = { 32, 32 }, .childGap = 32 }), CLAY_BORDER({ .left = { 2, COLOR_RED }, .right = { 2, COLOR_RED } })) {
CLAY(CLAY_ID("SyntaxPageLeftText"), CLAY_LAYOUT({ .sizing = { CLAY_SIZING_PERCENT(0.5) }, .layoutDirection = CLAY_TOP_TO_BOTTOM, .childGap = 8 })) {
CLAY_TEXT(CLAY_STRING("Declarative Syntax"), CLAY_TEXT_CONFIG({ .fontSize = 52, .fontId = FONT_ID_TITLE_56, .textColor = COLOR_RED }));
CLAY(CLAY_ID("SyntaxSpacer"), CLAY_LAYOUT({ .sizing = { CLAY_SIZING_GROW({ .max = 16 }) } })) {}
CLAY_TEXT(CLAY_STRING("Flexible and readable declarative syntax with nested UI element hierarchies."), CLAY_TEXT_CONFIG({ .fontSize = 28, .fontId = FONT_ID_BODY_36, .textColor = COLOR_RED }));
CLAY_TEXT(CLAY_STRING("Mix elements with standard C code like loops, conditionals and functions."), CLAY_TEXT_CONFIG({ .fontSize = 28, .fontId = FONT_ID_BODY_36, .textColor = COLOR_RED }));
CLAY_TEXT(CLAY_STRING("Create your own library of re-usable components from UI primitives like text, images and rectangles."), CLAY_TEXT_CONFIG({ .fontSize = 28, .fontId = FONT_ID_BODY_36, .textColor = COLOR_RED }));
}
CLAY(CLAY_ID("SyntaxPageRightImage"), CLAY_LAYOUT({ .sizing = { CLAY_SIZING_PERCENT(0.50) }, .childAlignment = {.x = CLAY_ALIGN_X_CENTER} })) {
CLAY(CLAY_ID("SyntaxPageRightImageInner"), CLAY_LAYOUT({ .sizing = { CLAY_SIZING_GROW({ .max = 568 }) } }), CLAY_IMAGE({ .sourceDimensions = {1136, 1194}, .sourceURL = CLAY_STRING("/clay/images/declarative.png") })) {}
}
}
}
}I'm not ready to ditch HTML and CSS for writing my web pages in C compiled to WebAssembly just yet, but as an exercise in understanding layout engines (and a potential tool for building non-web interfaces in the future) this is a really interesting project to dig into.
To clarify here: I don't think the web layout / WebAssembly thing is the key idea behind Clay at all - I think it's a neat demo of the library, but it's not what Clay is for. It's certainly an interesting way to provide a demo of a layout library!
Nic confirms:
You totally nailed it, the fact that you can compile to wasm and run in HTML stemmed entirely from a “wouldn’t it be cool if…” It was designed for my C projects first and foremost!
Using static websites for tiny archives (via) Alex Chan:
Over the last year or so, I’ve been creating static websites to browse my local archives. I’ve done this for a variety of collections, including:
- paperwork I’ve scanned
- documents I’ve created
- screenshots I’ve taken
- web pages I’ve bookmarked
- video and audio files I’ve saved
This is such a neat idea. These tiny little personal archive websites aren't even served through a localhost web server - they exist as folders on disk, and Alex browses them by opening up the index.html file directly in a browser.
HTML for People (via) Blake Watson's brand new HTML tutorial, presented as a free online book (CC BY-NC-SA 4.0, on GitHub). This seems very modern and well thought-out to me. It focuses exclusively on HTML, skipping JavaScript entirely and teaching with Simple.css to avoid needing to dig into CSS while still producing sites that are pleasing to look at. It even touches on Web Components (described as Custom HTML tags) towards the end.
Reckoning. Alex Russell is a self-confessed Cassandra - doomed to speak truth that the wider Web industry stubbornly ignores. With this latest series of posts he is spitting fire.
The series is an "investigation into JavaScript-first frontend culture and how it broke US public services", in four parts.
In Part 2 — Object Lesson Alex profiles BenefitsCal, the California state portal for accessing SNAP food benefits (aka "food stamps"). On a 9Mbps connection, as can be expected in rural parts of California with populations most likely to need these services, the site takes 29.5 seconds to become usefully interactive, fetching more than 20MB of JavaScript (which isn't even correctly compressed) for a giant SPA that incoroprates React, Vue, the AWS JavaScript SDK, six user-agent parsing libraries and a whole lot more.
It doesn't have to be like this! GetCalFresh.org, the Code for America alternative to BenefitsCal, becomes interactive after 4 seconds. Despite not being the "official" site it has driven nearly half of all signups for California benefits.
The fundamental problem here is the Web industry's obsession with SPAs and JavaScript-first development - techniques that make sense for a tiny fraction of applications (Alex calls out document editors, chat and videoconferencing and maps, geospatial, and BI visualisations as apppropriate applications) but massively increase the cost and complexity for the vast majority of sites - especially sites primarily used on mobile and that shouldn't expect lengthy session times or multiple repeat visits.
There's so much great, quotable content in here. Don't miss out on the footnotes, like this one:
The JavaScript community's omertà regarding the consistent failure of frontend frameworks to deliver reasonable results at acceptable cost is likely to be remembered as one of the most shameful aspects of frontend's lost decade.
Had the risks been prominently signposted, dozens of teams I've worked with personally could have avoided months of painful remediation, and hundreds more sites I've traced could have avoided material revenue losses.
Too many engineering leaders have found their teams beached and unproductive for no reason other than the JavaScript community's dedication to a marketing-over-results ethos of toxic positivity.
In Part 4 — The Way Out Alex recommends the gov.uk Service Manual as a guide for building civic Web services that avoid these traps, thanks to the policy described in their Building a resilient frontend using progressive enhancement document.
This month in Servo: parallel tables and more (via) New in Servo:
Parallel table layout is now enabled (@mrobinson, #32477), spreading the work for laying out rows and their columns over all available CPU cores. This change is a great example of the strengths of Rayon and the opportunistic parallelism in Servo's layout engine.
The commit landing the change is quite short, and much of the work is done by refactoring the code to use .par_iter().enumerate().map(...) - par_iter() is the Rayon method that allows parallel iteration over a collection using multiple threads, hence multiple CPU cores.
For some reason, many people still believe that browsers need to include non-standard hacks in HTML parsing to display the web correctly.
In reality, the HTML parsing spec is exhaustively detailed. If you implement it as described, you will have a web-compatible parser.
Streaming HTML out of order without JavaScript (via) A really interesting new browser capability. If you serve the following HTML:
<template shadowrootmode="open">
<slot name="item-1">Loading...</slot>
</template>
Then later in the same page stream an element specifying that slot:
<span slot="item-1">Item number 1</span>
The previous slot will be replaced while the page continues to load.
I tried the demo in the most recent Chrome, Safari and Firefox (and Mobile Safari) and it worked in all of them.
The key feature is shadowrootmode=open, which looks like it was added to Firefox 123 on February 19th 2024 - the other two browsers are listed on caniuse.com as gaining it around March last year.
htmz (via) Astonishingly clever browser platform hack by Lean Rada.
Add this to a page:
<iframe hidden name=htmz onload="setTimeout(() => document.querySelector( this.contentWindow.location.hash || null)?.replaceWith( ...this.contentDocument.body.childNodes ))"></iframe>
Then elsewhere add a link like this:
<a href="/flower.html#my-element" target=htmz>Flower</a>
Clicking that link will fetch content from /flower.html and replace the element with ID of my-element with that content.
Portable EPUBs. Will Crichton digs into the reasons people still prefer PDF over HTML as a format for sharing digital documents, concluding that the key issues are that HTML documents are not fully self-contained and may not be rendered consistently.
He proposes “Portable EPUBs” as the solution, defining a subset of the existing EPUB standard with some additional restrictions around avoiding loading extra assets over a network, sticking to a smaller (as-yet undefined) subset of HTML and encouraging interactive components to be built using self-contained Web Components.
Will also built his own lightweight EPUB reading system, called Bene—which is used to render this Portable EPUBs article. It provides a “download” link in the top right which produces the .epub file itself.
There’s a lot to like here. I’m constantly infuriated at the number of documents out there that are PDFs but really should be web pages (academic papers are a particularly bad example here), so I’m very excited by any initiatives that might help push things in the other direction.
2023
You can stop using user-scalable=no and maximum-scale=1 in viewport meta tags now. Luke Plant points out that your meta viewport tag should stick to just “width=device-width, initial-scale=1” these days—the user-scalable=no and maximum-scale=1 attributes are no longer necessary, and have a negative impact on accessibility, especially for Android users.
The Page With No Code
(via)
A fun demo by Dan Q, who created a web page with no HTML at all - but in Firefox it still renders content, thanks to a data URI base64 encoded stylesheet served in a link: header that uses html::before, html::after, body::before and body::after with content: properties to serve the content. It even has a background image, encoded as a base64 SVG nested inside another data URI.
2022
Introducing sqlite-html: query, parse, and generate HTML in SQLite (via) Another brilliant SQLite extension module from Alex Garcia, this time written in Go. sqlite-html adds a whole family of functions to SQLite for parsing and constructing HTML strings, built on the Go goquery and cascadia libraries. Once again, Alex uses an Observable notebook to describe the new features, with embedded interactive examples that are backed by a Datasette instance running in Fly.
Fastest way to turn HTML into text in Python (via) A light benchmark of the new-to-me selectolax Python library shows it performing extremely well for tasks such as extracting just the text from an HTML string, after first manipulating the DOM. selectolax is a Python binding over the Modest and Lexbor HTML parsing engines, which are written in no-outside-dependency C.