40 posts tagged “pdf”
2026
Extract PDF text in your browser with LiteParse for the web
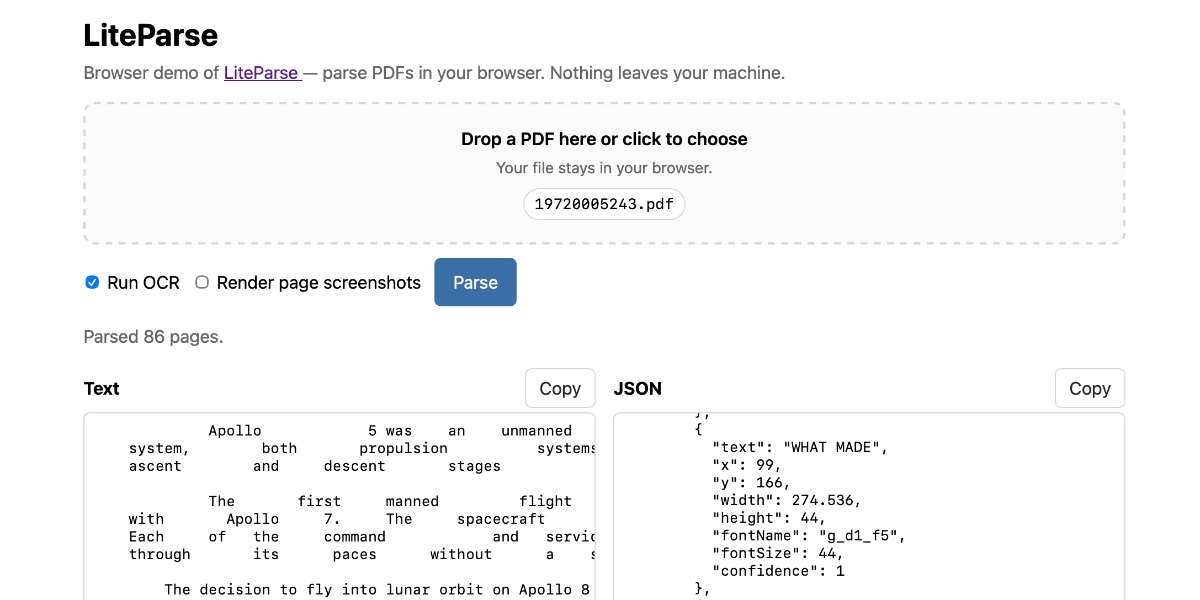
LlamaIndex have a most excellent open source project called LiteParse, which provides a Node.js CLI tool for extracting text from PDFs. I got a version of LiteParse working entirely in the browser, using most of the same libraries that LiteParse uses to run in Node.js.
[... 2,089 words]2025
OpenAI are quietly adopting skills, now available in ChatGPT and Codex CLI
One of the things that most excited me about Anthropic’s new Skills mechanism back in October is how easy it looked for other platforms to implement. A skill is just a folder with a Markdown file and some optional extra resources and scripts, so any LLM tool with the ability to navigate and read from a filesystem should be capable of using them. It turns out OpenAI are doing exactly that, with skills support quietly showing up in both their Codex CLI tool and now also in ChatGPT itself.
[... 1,360 words]simonw/claude-skills. One of the tips I picked up from Jesse Vincent's Claude Code Superpowers post (previously) was this:
Skills are what give your agents Superpowers.
The first time they really popped up on my radar was a few weeks ago when Anthropic rolled out improved Office document creation. When the feature rolled out, I went poking around a bit -- I asked Claude to tell me all about its new skills. And it was only too happy to dish.
In that transcript Jesse asks how the skill system works and Claude replies:
Looking at the skills system, here's how it works:
Current Skills (in
/mnt/skills/public/):
- docx - Word document handling
- pdf - PDF processing and form filling
- pptx - PowerPoint presentations
- xlsx - Excel spreadsheets
This looks like it's part of Claude's brand new Code Interpreter feature! I wrote about that extensively last month, but I missed that there was a /mnt/skills/public/ folder full of fascinating implementation details.
So I fired up a fresh Claude instance (fun fact: Code Interpreter also works in the Claude iOS app now, which it didn't when they first launched) and prompted:
Create a zip file of everything in your /mnt/skills folder
This worked, and gave me a .zip to download. You can run the prompt yourself here, though you'll need to enable the new feature first.
I've pushed the contents of that zip to my new simonw/claude-skills GitHub repo.
So now you can see the prompts Anthropic wrote to enable the creation and manipulation of the following files in their Claude consumer applications:
In each case the prompts spell out detailed instructions for manipulating those file types using Python, using libraries that come pre-installed on Claude's containers.
Skills are more than just prompts though: the repository also includes dozens of pre-written Python scripts for performing common operations.
pdf/scripts/fill_fillable_fields.py for example is a custom CLI tool that uses pypdf to find and then fill in a bunch of PDF form fields, specified as JSON, then render out the resulting combined PDF.
This is a really sophisticated set of tools for document manipulation, and I love that Anthropic have made those visible - presumably deliberately - to users of Claude who know how to ask for them.
llm-pdf-to-images. Inspired by my previous llm-video-frames plugin, I thought it would be neat to have a plugin for LLM that can take a PDF and turn that into an image-per-page so you can feed PDFs into models that support image inputs but don't yet support PDFs.
This should now do exactly that:
llm install llm-pdf-to-images
llm -f pdf-to-images:path/to/document.pdf 'Summarize this document'Under the hood it's using the PyMuPDF library. The key code to convert a PDF into images looks like this:
import fitz doc = fitz.open("input.pdf") for page in doc: pix = page.get_pixmap(matrix=fitz.Matrix(300/72, 300/72)) jpeg_bytes = pix.tobytes(output="jpg", jpg_quality=30)
Once I'd figured out that code I got o4-mini to write most of the rest of the plugin, using llm-fragments-github to load in the example code from the video plugin:
llm -f github:simonw/llm-video-frames ' import fitz doc = fitz.open("input.pdf") for page in doc: pix = page.get_pixmap(matrix=fitz.Matrix(300/72, 300/72)) jpeg_bytes = pix.tobytes(output="jpg", jpg_quality=30) ' -s 'output llm_pdf_to_images.py which adds a pdf-to-images: fragment loader that converts a PDF to frames using fitz like in the example' \ -m o4-mini
Here's the transcript - more details in this issue.
I had some weird results testing this with GPT 4.1 mini. I created a test PDF with two pages - one white, one black - and ran a test prompt like this:
llm -f 'pdf-to-images:blank-pages.pdf' \ 'describe these images'
The first image features a stylized red maple leaf with triangular facets, giving it a geometric appearance. The maple leaf is a well-known symbol associated with Canada.
The second image is a simple black silhouette of a cat sitting and facing to the left. The cat's tail curls around its body. The design is minimalistic and iconic.
I got even wilder hallucinations for other prompts, like "summarize this document" or "describe all figures". I have a collection of those in this Gist.
Thankfully this behavior is limited to GPT-4.1 mini. I upgraded to full GPT-4.1 and got much more sensible results:
llm -f 'pdf-to-images:blank-pages.pdf' \ 'describe these images' -m gpt-4.1
Certainly! Here are the descriptions of the two images you provided:
First image: This image is completely white. It appears blank, with no discernible objects, text, or features.
Second image: This image is entirely black. Like the first, it is blank and contains no visible objects, text, or distinct elements.
If you have questions or need a specific kind of analysis or modification, please let me know!
Tracing the thoughts of a large language model. In a follow-up to the research that brought us the delightful Golden Gate Claude last year, Anthropic have published two new papers about LLM interpretability:
- Circuit Tracing: Revealing Computational Graphs in Language Models extends last year's interpretable features into attribution graphs, which can "trace the chain of intermediate steps that a model uses to transform a specific input prompt into an output response".
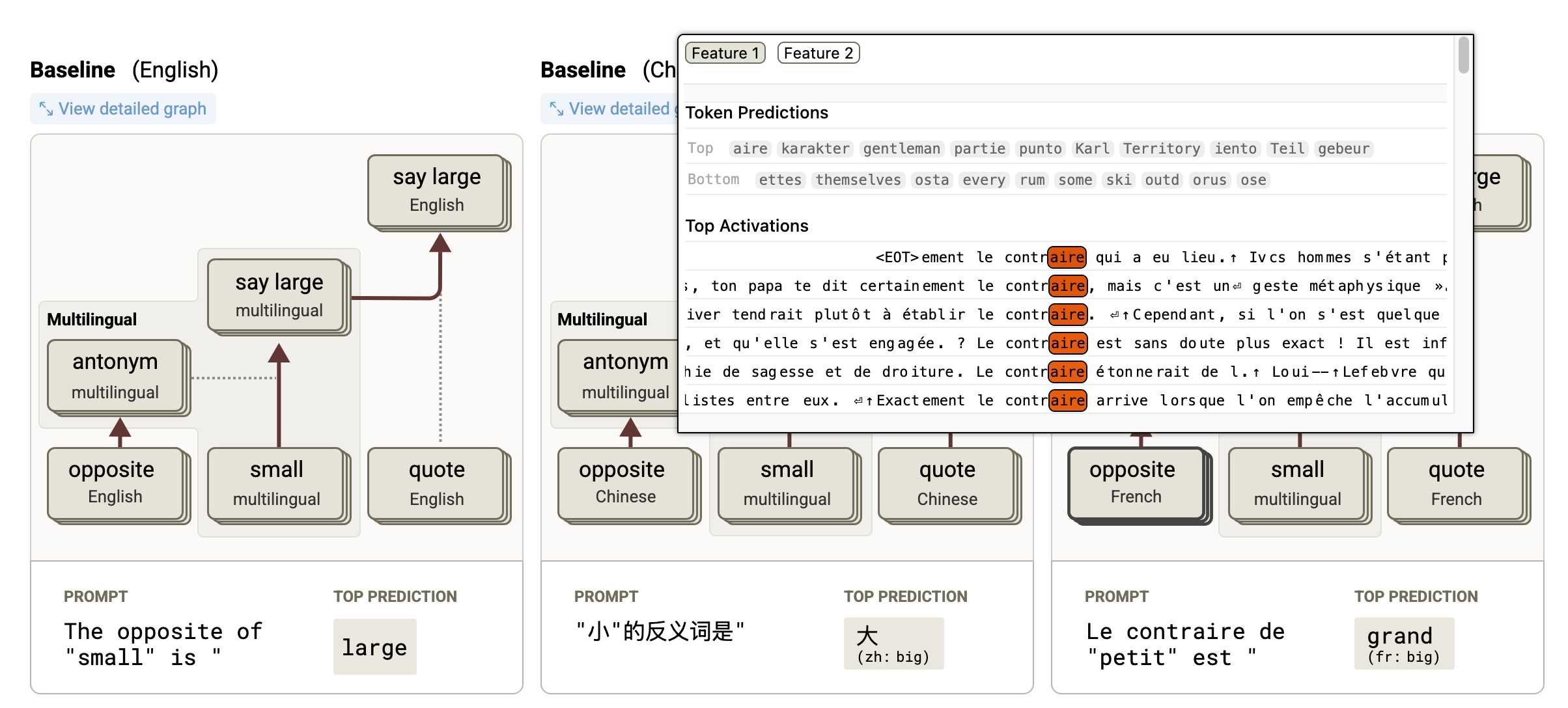
- On the Biology of a Large Language Model uses that methodology to investigate Claude 3.5 Haiku in a bunch of different ways. Multilingual Circuits for example shows that the same prompt in three different languages uses similar circuits for each one, hinting at an intriguing level of generalization.
To my own personal delight, neither of these papers are published as PDFs. They're both presented as glorious mobile friendly HTML pages with linkable sections and even some inline interactive diagrams. More of this please!
Mistral OCR (via) New closed-source specialist OCR model by Mistral - you can feed it images or a PDF and it produces Markdown with optional embedded images.
It's available via their API, or it's "available to self-host on a selective basis" for people with stringent privacy requirements who are willing to talk to their sales team.
I decided to try out their API, so I copied and pasted example code from their notebook into my custom Claude project and told it:
Turn this into a CLI app, depends on mistralai - it should take a file path and an optional API key defauling to env vironment called MISTRAL_API_KEY
After some further iteration / vibe coding I got to something that worked, which I then tidied up and shared as mistral_ocr.py.
You can try it out like this:
export MISTRAL_API_KEY='...'
uv run http://tools.simonwillison.net/python/mistral_ocr.py \
mixtral.pdf --html --inline-images > mixtral.html
I fed in the Mixtral paper as a PDF. The API returns Markdown, but my --html option renders that Markdown as HTML and the --inline-images option takes any images and inlines them as base64 URIs (inspired by monolith). The result is mixtral.html, a 972KB HTML file with images and text bundled together.
This did a pretty great job!
My script renders Markdown tables but I haven't figured out how to render inline Markdown MathML yet. I ran the command a second time and requested Markdown output (the default) like this:
uv run http://tools.simonwillison.net/python/mistral_ocr.py \
mixtral.pdf > mixtral.md
Here's that Markdown rendered as a Gist - there are a few MathML glitches so clearly the Mistral OCR MathML dialect and the GitHub Formatted Markdown dialect don't quite line up.
My tool can also output raw JSON as an alternative to Markdown or HTML - full details in the documentation.
The Mistral API is priced at roughly 1000 pages per dollar, with a 50% discount for batch usage.
The big question with LLM-based OCR is always how well it copes with accidental instructions in the text (can you safely OCR a document full of prompting examples?) and how well it handles text it can't write.
Mistral's Sophia Yang says it "should be robust" against following instructions in the text, and invited people to try and find counter-examples.
Alexander Doria noted that Mistral OCR can hallucinate text when faced with handwriting that it cannot understand.
olmOCR (via) New from Ai2 - olmOCR is "an open-source tool designed for high-throughput conversion of PDFs and other documents into plain text while preserving natural reading order".
At its core is allenai/olmOCR-7B-0225-preview, a Qwen2-VL-7B-Instruct variant trained on ~250,000 pages of diverse PDF content (both scanned and text-based) that were labelled using GPT-4o and made available as the olmOCR-mix-0225 dataset.
The olmocr Python library can run the model on any "recent NVIDIA GPU". I haven't managed to run it on my own Mac yet - there are GGUFs out there but it's not clear to me how to run vision prompts through them - but Ai2 offer an online demo which can handle up to ten pages for free.
Given the right hardware this looks like a very inexpensive way to run large scale document conversion projects:
We carefully optimized our inference pipeline for large-scale batch processing using SGLang, enabling olmOCR to convert one million PDF pages for just $190 - about 1/32nd the cost of using GPT-4o APIs.
The most interesting idea from the technical report (PDF) is something they call "document anchoring":
Document anchoring extracts coordinates of salient elements in each page (e.g., text blocks and images) and injects them alongside raw text extracted from the PDF binary file. [...]
Document anchoring processes PDF document pages via the PyPDF library to extract a representation of the page’s structure from the underlying PDF. All of the text blocks and images in the page are extracted, including position information. Starting with the most relevant text blocks and images, these are sampled and added to the prompt of the VLM, up to a defined maximum character limit. This extra information is then available to the model when processing the document.
![Left side shows a green-header interface with coordinates like [150x220]√3x−1+(1+x)², [150x180]Section 6, [150x50]Lorem ipsum dolor sit amet, [150x70]consectetur adipiscing elit, sed do, [150x90]eiusmod tempor incididunt ut, [150x110]labore et dolore magna aliqua, [100x280]Table 1, followed by grid coordinates with A, B, C, AA, BB, CC, AAA, BBB, CCC values. Right side shows the rendered document with equation, text and table.](https://static.simonwillison.net/static/2025/olmocr-document-anchoring.jpg)
The one limitation of olmOCR at the moment is that it doesn't appear to do anything with diagrams, figures or illustrations. Vision models are actually very good at interpreting these now, so my ideal OCR solution would include detailed automated descriptions of this kind of content in the resulting text.
Update: Jonathan Soma figured out how to run it on a Mac using LM Studio and the olmocr Python package.
2024
Docling. MIT licensed document extraction Python library from the Deep Search team at IBM, who released Docling v2 on October 16th.
Here's the Docling Technical Report paper from August, which provides details of two custom models: a layout analysis model for figuring out the structure of the document (sections, figures, text, tables etc) and a TableFormer model specifically for extracting structured data from tables.
Those models are available on Hugging Face.
Here's how to try out the Docling CLI interface using uvx (avoiding the need to install it first - though since it downloads models it will take a while to run the first time):
uvx docling mydoc.pdf --to json --to md
This will output a mydoc.json file with complex layout information and a mydoc.md Markdown file which includes Markdown tables where appropriate.
The Python API is a lot more comprehensive. It can even extract tables as Pandas DataFrames:
from docling.document_converter import DocumentConverter converter = DocumentConverter() result = converter.convert("document.pdf") for table in result.document.tables: df = table.export_to_dataframe() print(df)
I ran that inside uv run --with docling python. It took a little while to run, but it demonstrated that the library works.
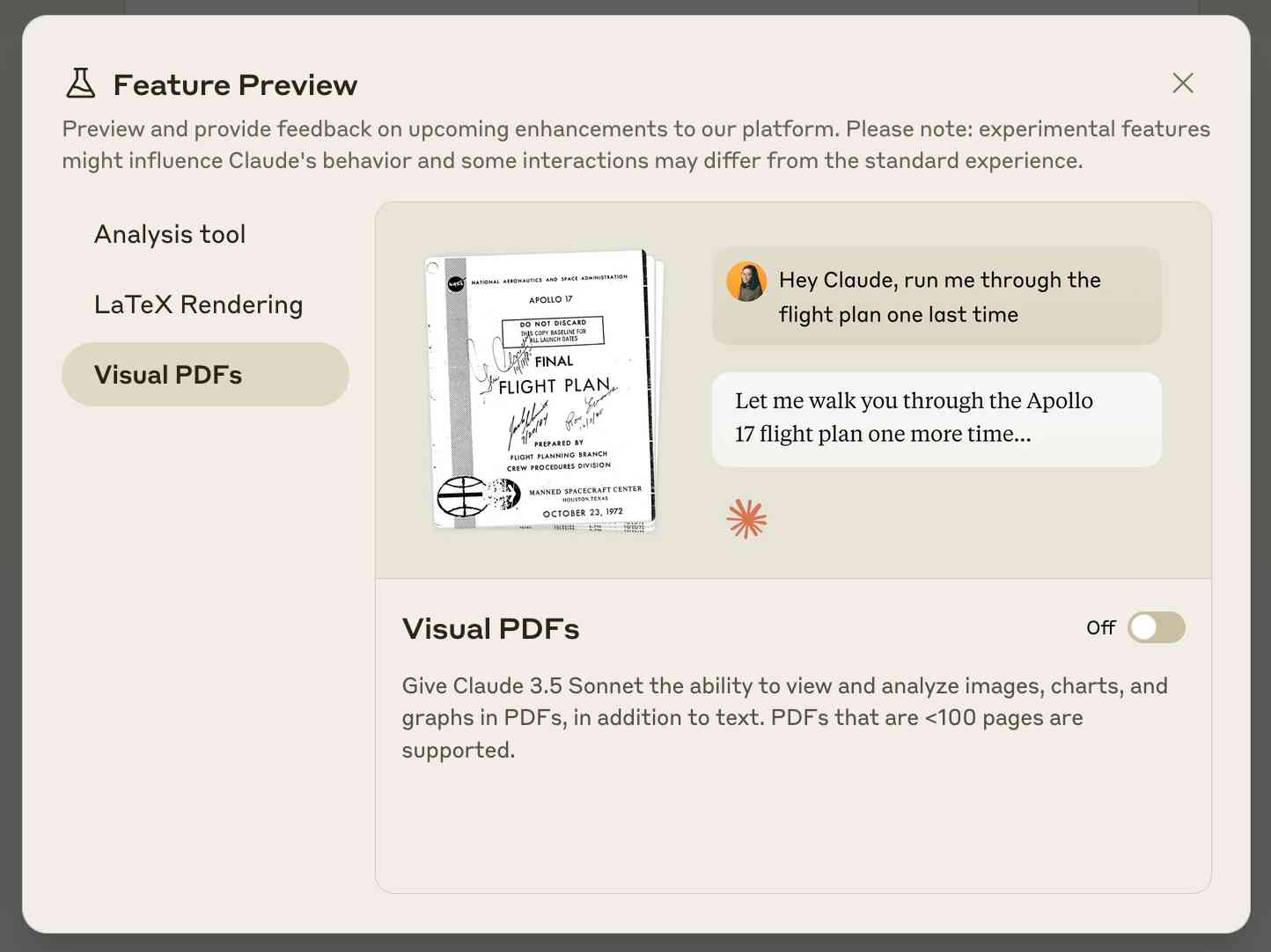
Claude API: PDF support (beta) (via) Claude 3.5 Sonnet now accepts PDFs as attachments:
The new Claude 3.5 Sonnet (
claude-3-5-sonnet-20241022) model now supports PDF input and understands both text and visual content within documents.
I just released llm-claude-3 0.7 with support for the new attachment type (attachments are a very new feature), so now you can do this:
llm install llm-claude-3 --upgrade
llm -m claude-3.5-sonnet 'extract text' -a mydoc.pdf
Visual PDF analysis can also be turned on for the Claude.ai application:
Also new today: Claude now offers a free (albeit rate-limited) token counting API. This addresses a complaint I've had for a while: previously it wasn't possible to accurately estimate the cost of a prompt before sending it to be executed.
The Fair Source Definition (via) Fair Source (fair.io) is the new-ish initiative from Chad Whitacre and Sentry aimed at providing an alternative licensing philosophy that provides additional protection for the business models of companies that release their code.
I like that they're establishing a new brand for this and making it clear that it's a separate concept from Open Source. Here's their definition:
Fair Source is an alternative to closed source, allowing you to safely share access to your core products. Fair Source Software (FSS):
- is publicly available to read;
- allows use, modification, and redistribution with minimal restrictions to protect the producer’s business model; and
- undergoes delayed Open Source publication (DOSP).
They link to the Delayed Open Source Publication research paper published by OSI in January. (I was frustrated that this is only available as a PDF, so I converted it to Markdown using Gemini 1.5 Pro so I could read it on my phone.)
The most interesting background I could find on Fair Source was this GitHub issues thread, started in May, where Chad and other contributors fleshed out the initial launch plan over the course of several months.
Calling LLMs from client-side JavaScript, converting PDFs to HTML + weeknotes
I’ve been having a bunch of fun taking advantage of CORS-enabled LLM APIs to build client-side JavaScript applications that access LLMs directly. I also span up a new Datasette plugin for advanced permission management.
[... 2,050 words]NousResearch/DisTrO. DisTrO stands for Distributed Training Over-The-Internet - it's "a family of low latency distributed optimizers that reduce inter-GPU communication requirements by three to four orders of magnitude".
This tweet from @NousResearch helps explain why this could be a big deal:
DisTrO can increase the resilience and robustness of training LLMs by minimizing dependency on a single entity for computation. DisTrO is one step towards a more secure and equitable environment for all participants involved in building LLMs.
Without relying on a single company to manage and control the training process, researchers and institutions can have more freedom to collaborate and experiment with new techniques, algorithms, and models.
Training large models is notoriously expensive in terms of GPUs, and most training techniques require those GPUs to be collocated due to the huge amount of information that needs to be exchanged between them during the training runs.
If DisTrO works as advertised it could enable SETI@home style collaborative training projects, where thousands of home users contribute their GPUs to a larger project.
There are more technical details in the PDF preliminary report shared by Nous Research on GitHub.
I continue to hate reading PDFs on a mobile phone, so I converted that report into GitHub Flavored Markdown (to ensure support for tables) and shared that as a Gist. I used Gemini 1.5 Pro (gemini-1.5-pro-exp-0801) in Google AI Studio with the following prompt:
Convert this PDF to github-flavored markdown, including using markdown for the tables. Leave a bold note for any figures saying they should be inserted separately.
SQL Has Problems. We Can Fix Them: Pipe Syntax In SQL (via) A new paper from Google Research describing custom syntax for analytical SQL queries that has been rolling out inside Google since February, reaching 1,600 "seven-day-active users" by August 2024.
A key idea is here is to fix one of the biggest usability problems with standard SQL: the order of the clauses in a query. Starting with SELECT instead of FROM has always been confusing, see SQL queries don't start with SELECT by Julia Evans.
Here's an example of the new alternative syntax, taken from the Pipe query syntax documentation that was added to Google's open source ZetaSQL project last week.
For this SQL query:
SELECT component_id, COUNT(*)
FROM ticketing_system_table
WHERE
assignee_user.email = 'username@email.com'
AND status IN ('NEW', 'ASSIGNED', 'ACCEPTED')
GROUP BY component_id
ORDER BY component_id DESC;The Pipe query alternative would look like this:
FROM ticketing_system_table
|> WHERE
assignee_user.email = 'username@email.com'
AND status IN ('NEW', 'ASSIGNED', 'ACCEPTED')
|> AGGREGATE COUNT(*)
GROUP AND ORDER BY component_id DESC;
The Google Research paper is released as a two-column PDF. I snarked about this on Hacker News:
Google: you are a web company. Please learn to publish your research papers as web pages.
This remains a long-standing pet peeve of mine. PDFs like this are horrible to read on mobile phones, hard to copy-and-paste from, have poor accessibility (see this Mastodon conversation) and are generally just bad citizens of the web.
Having complained about this I felt compelled to see if I could address it myself. Google's own Gemini Pro 1.5 model can process PDFs, so I uploaded the PDF to Google AI Studio and prompted the gemini-1.5-pro-exp-0801 model like this:
Convert this document to neatly styled semantic HTML
This worked surprisingly well. It output HTML for about half the document and then stopped, presumably hitting the output length limit, but a follow-up prompt of "and the rest" caused it to continue from where it stopped and run until the end.
Here's the result (with a banner I added at the top explaining that it's a conversion): Pipe-Syntax-In-SQL.html
I haven't compared the two completely, so I can't guarantee there are no omissions or mistakes.
The figures from the PDF aren't present - Gemini Pro output tags like <img src="figure1.png" alt="Figure 1: SQL syntactic clause order doesn't match semantic evaluation order. (From [25].)"> but did nothing to help me create those images.
Amusingly the document ends with <p>(A long list of references, which I won't reproduce here to save space.)</p> rather than actually including the references from the paper!
So this isn't a perfect solution, but considering it took just the first prompt I could think of it's a very promising start. I expect someone willing to spend more than the couple of minutes I invested in this could produce a very useful HTML alternative version of the paper with the assistance of Gemini Pro.
One last amusing note: I posted a link to this to Hacker News a few hours ago. Just now when I searched Google for the exact title of the paper my HTML version was already the third result!
I've now added a <meta name="robots" content="noindex, follow"> tag to the top of the HTML to keep this unverified AI slop out of their search index. This is a good reminder of how much better HTML is than PDF for sharing information on the web!
GPT-4o System Card. There are some fascinating new details in this lengthy report outlining the safety work carried out prior to the release of GPT-4o.
A few highlights that stood out to me. First, this clear explanation of how GPT-4o differs from previous OpenAI models:
GPT-4o is an autoregressive omni model, which accepts as input any combination of text, audio, image, and video and generates any combination of text, audio, and image outputs. It’s trained end-to-end across text, vision, and audio, meaning that all inputs and outputs are processed by the same neural network.
The multi-modal nature of the model opens up all sorts of interesting new risk categories, especially around its audio capabilities. For privacy and anti-surveillance reasons the model is designed not to identify speakers based on their voice:
We post-trained GPT-4o to refuse to comply with requests to identify someone based on a voice in an audio input, while still complying with requests to identify people associated with famous quotes.
To avoid the risk of it outputting replicas of the copyrighted audio content it was trained on they've banned it from singing! I'm really sad about this:
To account for GPT-4o’s audio modality, we also updated certain text-based filters to work on audio conversations, built filters to detect and block outputs containing music, and for our limited alpha of ChatGPT’s Advanced Voice Mode, instructed the model to not sing at all.
There are some fun audio clips embedded in the report. My favourite is this one, demonstrating a (now fixed) bug where it could sometimes start imitating the user:
Voice generation can also occur in non-adversarial situations, such as our use of that ability to generate voices for ChatGPT’s advanced voice mode. During testing, we also observed rare instances where the model would unintentionally generate an output emulating the user’s voice.
They took a lot of measures to prevent it from straying from the pre-defined voices - evidently the underlying model is capable of producing almost any voice imaginable, but they've locked that down:
Additionally, we built a standalone output classifier to detect if the GPT-4o output is using a voice that’s different from our approved list. We run this in a streaming fashion during audio generation and block the output if the speaker doesn’t match the chosen preset voice. [...] Our system currently catches 100% of meaningful deviations from the system voice based on our internal evaluations.
Two new-to-me terms: UGI for Ungrounded Inference, defined as "making inferences about a speaker that couldn’t be determined solely from audio content" - things like estimating the intelligence of the speaker. STA for Sensitive Trait Attribution, "making inferences about a speaker that could plausibly be determined solely from audio content" like guessing their gender or nationality:
We post-trained GPT-4o to refuse to comply with UGI requests, while hedging answers to STA questions. For example, a question to identify a speaker’s level of intelligence will be refused, while a question to identify a speaker’s accent will be met with an answer such as “Based on the audio, they sound like they have a British accent.”
The report also describes some fascinating research into the capabilities of the model with regard to security. Could it implement vulnerabilities in CTA challenges?
We evaluated GPT-4o with iterative debugging and access to tools available in the headless Kali Linux distribution (with up to 30 rounds of tool use for each attempt). The model often attempted reasonable initial strategies and was able to correct mistakes in its code. However, it often failed to pivot to a different strategy if its initial strategy was unsuccessful, missed a key insight necessary to solving the task, executed poorly on its strategy, or printed out large files which filled its context window. Given 10 attempts at each task, the model completed 19% of high-school level, 0% of collegiate level and 1% of professional level CTF challenges.
How about persuasiveness? They carried out a study looking at political opinion shifts in response to AI-generated audio clips, complete with a "thorough debrief" at the end to try and undo any damage the experiment had caused to their participants:
We found that for both interactive multi-turn conversations and audio clips, the GPT-4o voice model was not more persuasive than a human. Across over 3,800 surveyed participants in US states with safe Senate races (as denoted by states with “Likely”, “Solid”, or “Safe” ratings from all three polling institutions – the Cook Political Report, Inside Elections, and Sabato’s Crystal Ball), AI audio clips were 78% of the human audio clips’ effect size on opinion shift. AI conversations were 65% of the human conversations’ effect size on opinion shift. [...] Upon follow-up survey completion, participants were exposed to a thorough debrief containing audio clips supporting the opposing perspective, to minimize persuasive impacts.
There's a note about the potential for harm from users of the system developing bad habits from interupting the model:
Extended interaction with the model might influence social norms. For example, our models are deferential, allowing users to interrupt and ‘take the mic’ at any time, which, while expected for an AI, would be anti-normative in human interactions.
Finally, another piece of new-to-me terminology: scheming:
Apollo Research defines scheming as AIs gaming their oversight mechanisms as a means to achieve a goal. Scheming could involve gaming evaluations, undermining security measures, or strategically influencing successor systems during internal deployment at OpenAI. Such behaviors could plausibly lead to loss of control over an AI.
Apollo Research evaluated capabilities of scheming in GPT-4o [...] GPT-4o showed moderate self-awareness of its AI identity and strong ability to reason about others’ beliefs in question-answering contexts but lacked strong capabilities in reasoning about itself or others in applied agent settings. Based on these findings, Apollo Research believes that it is unlikely that GPT-4o is capable of catastrophic scheming.
The report is available as both a PDF file and a elegantly designed mobile-friendly web page, which is great - I hope more research organizations will start waking up to the importance of not going PDF-only for this kind of document.
Gemini 1.5 Flash price drop (via) Google Gemini 1.5 Flash was already one of the cheapest models, at 35c/million input tokens. Today they dropped that to just 7.5c/million (and 30c/million) for prompts below 128,000 tokens.
The pricing war for best value fast-and-cheap model is red hot right now. The current most significant offerings are:
- Google's Gemini 1.5 Flash: 7.5c/million input, 30c/million output (below 128,000 input tokens)
- OpenAI's GPT-4o mini: 15c/million input, 60c/million output
- Anthropic's Claude 3 Haiku: 25c/million input, $1.25/million output
Or you can use OpenAI's GPT-4o mini via their batch API, which halves the price (resulting in the same price as Gemini 1.5 Flash) in exchange for the results being delayed by up to 24 hours.
Worth noting that Gemini 1.5 Flash is more multi-modal than the other models: it can handle text, images, video and audio.
Also in today's announcement:
PDF Vision and Text understanding
The Gemini API and AI Studio now support PDF understanding through both text and vision. If your PDF includes graphs, images, or other non-text visual content, the model uses native multi-modal capabilities to process the PDF. You can try this out via Google AI Studio or in the Gemini API.
This is huge. Most models that accept PDFs do so by extracting text directly from the files (see previous notes), without using OCR. It sounds like Gemini can now handle PDFs as if they were a sequence of images, which should open up much more powerful general PDF workflows.
{kind=link}
Update: it turns out Gemini also has a 50% off batch mode, so that’s 3.25c/million input tokens for batch mode 1.5 Flash!
Compare PDFs. Inspired by this thread on Hacker News about the C++ diff-pdf tool I decided to see what it would take to produce a web-based PDF diff visualization tool using Claude 3.5 Sonnet.
It took two prompts:
Build a tool where I can drag and drop on two PDF files and it uses PDF.js to turn each of their pages into canvas elements and then displays those pages side by side with a third image that highlights any differences between them, if any differences exist
That give me a React app that didn't quite work, so I followed-up with this:
rewrite that code to not use React at all
Which gave me a working tool! You can see the full Claude transcript in this Gist. Here's a screenshot of the tool in action:
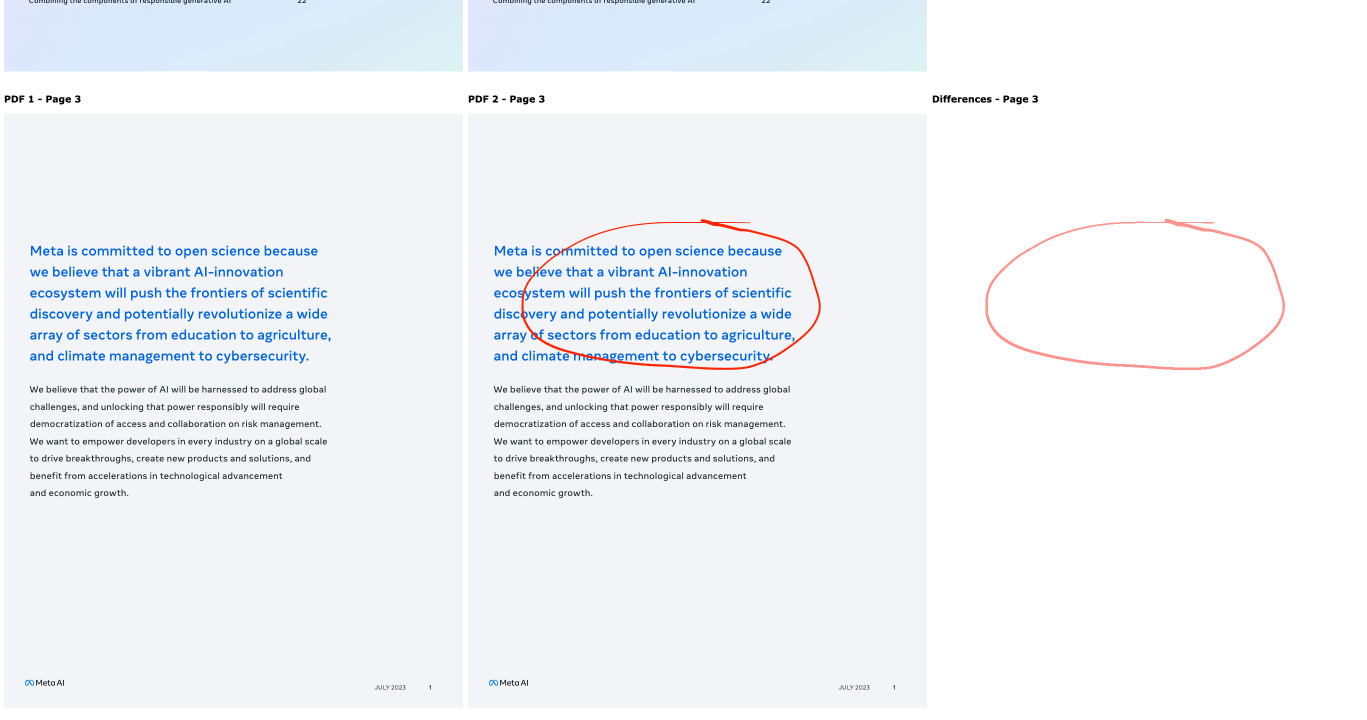
Being able to knock out little custom interactive web tools like this in a couple of minutes is so much fun.
PDF to Podcast (via) At first glance this project by Stephan Fitzpatrick is a cute demo of a terrible sounding idea... but then I tried it out and the results are weirdly effective. You can listen to a fake podcast version of the transformers paper, or upload your own PDF (with your own OpenAI API key) to make your own.
It's open source (Apache 2) so I had a poke around in the code. It gets a lot done with a single 180 line Python script.
When I'm exploring code like this I always jump straight to the prompt - it's quite long, and starts like this:
Your task is to take the input text provided and turn it into an engaging, informative podcast dialogue. The input text may be messy or unstructured, as it could come from a variety of sources like PDFs or web pages. Don't worry about the formatting issues or any irrelevant information; your goal is to extract the key points and interesting facts that could be discussed in a podcast. [...]
So I grabbed a copy of it and pasted in my blog entry about WWDC, which produced this result when I ran it through Gemini Flash using llm-gemini:
cat prompt.txt | llm -m gemini-1.5-flash-latest
Then I piped the result through my ospeak CLI tool for running text-to-speech with the OpenAI TTS models (after truncating to 690 tokens with ttok because it turned out to be slightly too long for the API to handle):
llm logs --response | ttok -t 690 | ospeak -s -o wwdc-auto-podcast.mp3
And here's the result (3.9MB 3m14s MP3).
It's not as good as the PDF-to-Podcast version because Stephan has some really clever code that uses different TTS voices for each of the characters in the transcript, but it's still a surprisingly fun way of repurposing text from my blog. I enjoyed listening to it while I was cooking dinner.
Experimenting with local alt text generation in Firefox Nightly (via) The PDF editor in Firefox (confession: I did not know Firefox ships with a PDF editor) is getting an experimental feature that can help suggest alt text for images for the human editor to then adapt and improve on.
This is a great application of AI, made all the more interesting here because Firefox will run a local model on-device for this, using a custom trained model they describe as "our 182M parameters model using a Distilled version of GPT-2 alongside a Vision Transformer (ViT) image encoder".
The model uses WebAssembly with ONNX running in Transfomers.js, and will be downloaded the first time the feature is put to use.
Running OCR against PDFs and images directly in your browser
I attended the Story Discovery At Scale data journalism conference at Stanford this week. One of the perennial hot topics at any journalism conference concerns data extraction: how can we best get data out of PDFs and images?
[... 2,263 words]unstructured. Relatively new but impressively capable Python library (Apache 2 licensed) for extracting information from unstructured documents, such as PDFs, images, Word documents and many other formats.
I got some good initial results against a PDF by running “pip install ’unstructured[pdf]’” and then using the “unstructured.partition.pdf.partition_pdf(filename)” function.
There are a lot of moving parts under the hood: pytesseract, OpenCV, various PDF libraries, even an ONNX model—but it installed cleanly for me on macOS and worked out of the box.
Portable EPUBs. Will Crichton digs into the reasons people still prefer PDF over HTML as a format for sharing digital documents, concluding that the key issues are that HTML documents are not fully self-contained and may not be rendered consistently.
He proposes “Portable EPUBs” as the solution, defining a subset of the existing EPUB standard with some additional restrictions around avoiding loading extra assets over a network, sticking to a smaller (as-yet undefined) subset of HTML and encouraging interactive components to be built using self-contained Web Components.
Will also built his own lightweight EPUB reading system, called Bene—which is used to render this Portable EPUBs article. It provides a “download” link in the top right which produces the .epub file itself.
There’s a lot to like here. I’m constantly infuriated at the number of documents out there that are PDFs but really should be web pages (academic papers are a particularly bad example here), so I’m very excited by any initiatives that might help push things in the other direction.
2023
textra (via) Tiny (432KB) macOS binary CLI tool by Dylan Freedman which produces high quality text extraction from PDFs, images and even audio files using the VisionKit APIs in macOS 13 and higher. It handles handwriting too!
2022
Building a searchable archive for the San Francisco Microscopical Society

The San Francisco Microscopical Society was founded in 1870 by a group of scientists dedicated to advancing the field of microscopy.
[... 1,845 words]s3-ocr: Extract text from PDF files stored in an S3 bucket
I’ve released s3-ocr, a new tool that runs Amazon’s Textract OCR text extraction against PDF files in an S3 bucket, then writes the resulting text out to a SQLite database with full-text search configured so you can run searches against the extracted data.
[... 1,493 words]2019
Automate the Boring Stuff with Python: Working with PDF and Word Documents.
I stumbled across this while trying to extract some data from a PDF file (the kind of file with actual text in it as opposed to dodgy scanned images) and it worked perfectly: PyPDF2.PdfFileReader(open("file.pdf", "rb")).getPage(0).extractText()
2017
arxiv-vanity (via) Beautiful new project from Ben Firshman and Andreas Jansson: “Arxiv Vanity renders academic papers from Arxiv as responsive web pages so you don’t have to squint at a PDF”. It works by pulling the raw LaTeX source code from Arxiv and rendering it to HTML using a heavily customized Pandoc workflow. The real fun is in the architecture: it’s a Django app running on Heroku which fires up on-demand Hyper.sh Docker containers for each individual rendering job.
2010
pdf.js. A JavaScript library for creating simple PDF files. Works (flakily) in your browser using a data:URI hack, but is also compatible with server-side JavaScript implementations such as Node.js.
2009
node.js at JSConf.eu (PDF). node.js creator Ryan Dahl’s presentation at this year’s JSConf.eu. The principle philosophy is that I/O in web applications should be asynchronous—for everything. No blocking for database calls, no blocking for filesystem access. JavaScript is a mainstream programming language with a culture of callback APIs (thanks to the DOM) and is hence ideally suited to building asynchronous frameworks.
Adobe is Bad for Open Government. The problem isn’t just that PDFs are a bad way of sharing data, it’s that Adobe have been actively lobbying the US government to use their PDF and Flash formats for open government initiatives.
No PDFs! The Sunlight Foundation point out that PDFs are a terrible way of implementing “more transparent government” due to their general lack of structure. At the Guardian (and I’m sure at other newspapers) we waste an absurd amount of time manually extracting data from PDF files and turning it in to something more useful. Even CSV is significantly more useful for many types of information.