26 posts tagged “ocr”
2026
Extract PDF text in your browser with LiteParse for the web
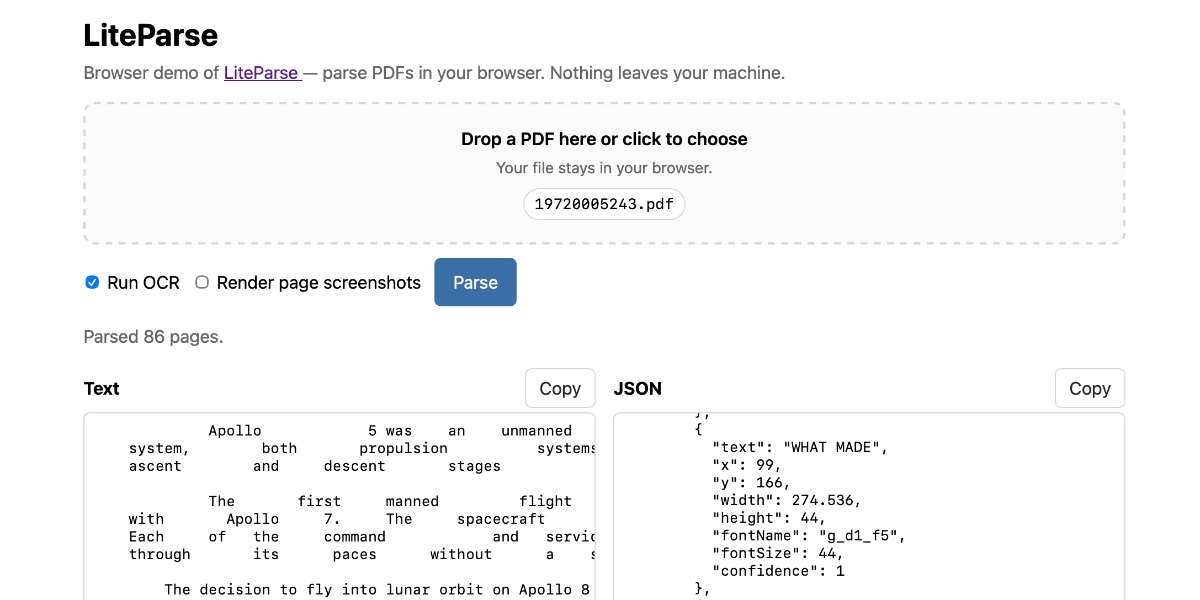
LlamaIndex have a most excellent open source project called LiteParse, which provides a Node.js CLI tool for extracting text from PDFs. I got a version of LiteParse working entirely in the browser, using most of the same libraries that LiteParse uses to run in Node.js.
[... 2,089 words]2025
Getting DeepSeek-OCR working on an NVIDIA Spark via brute force using Claude Code

DeepSeek released a new model yesterday: DeepSeek-OCR, a 6.6GB model fine-tuned specifically for OCR. They released it as model weights that run using PyTorch and CUDA. I got it running on the NVIDIA Spark by having Claude Code effectively brute force the challenge of getting it working on that particular hardware.
[... 1,971 words]The perils of vibe coding. I was interviewed by Elaine Moore for this opinion piece in the Financial Times, which ended up in the print edition of the paper too! I picked up a copy yesterday:
![The perils of vibe coding - A new OpenAI model arrived this month with a glossy livestream, group watch parties and a lingering sense of disappointment. The YouTube comment section was underwhelmed. “I think they are all starting to realize this isn’t going to become the world like they thought it would,” wrote one viewer. “I can see it on their faces.” But if the casual user was unimpressed, the AI model’s saving grace may be vibe. Coding is generative AI’s newest battleground. With big bills to pay, high valuations to live up to and a market wobble to erase, the sector needs to prove its corporate productivity chops. Coding is hardly promoted as a business use case that already works. For one thing, AI-generated code holds the promise of replacing programmers — a profession of very well paid people. For another, the work can be quantified. In April, Microsoft chief executive Satya Nadella said that up to 50 per cent of the company’s code was now being written by AI. Google chief executive Sundar Pichai has said the same thing. Salesforce has paused engineering hires and Mark Zuckerberg told podcaster Joe Rogan that Meta would use AI as a “mid-level engineer” that writes code. Meanwhile, start-ups such as Replit and Cursor’s Anysphere are trying to persuade people that with AI, anyone can code. In theory, every employee can become a software engineer. So why aren’t we? One possibility is that it’s all still too unfamiliar. But when I ask people who write code for a living they offer an alternative suggestion: unpredictability. As programmer Simon Willison put it: “A lot of people are missing how weird and funny this space is. I’ve been a computer programmer for 30 years and [AI models] don’t behave like normal computers.” Willison is well known in the software engineering community for his AI experiments. He’s an enthusiastic vibe coder — using LLMs to generate code using natural language prompts. OpenAI’s latest model GPT-3.1s, he is now favourite. Still, he predicts that a vibe coding crash is due if it is used to produce glitchy software. It makes sense that programmers — people who are interested in finding new ways to solve problems — would be early adopters of LLMs. Code is a language, albeit an abstract one. And generative AI is trained in nearly all of them, including older ones like Cobol. That doesn’t mean they accept all of its suggestions. Willison thinks the best way to see what a new model can do is to ask for something unusual. He likes to request an svg (an image made out of lines described with code) of a pelican on a bike and asks it to remember the chickens in his garden by name. Results can be bizarre. One model ignored key prompts in favour of composing a poem. Still, his adventures in vibe coding sound like an advert for the sector’s future. Anthropic’s Claude Code, the favoured model for developers, to make an OCR (optical character recognition) software loves screenshots) tool that will copy and paste text from a screenshot. He wrote software that summarises blog comments and has planned to cut a custom tool that will alert him when a whale is visible from his Pacific coast home. All this by typing prompts in English. It’s sounds like the sort of thing Bill Gates might have had in mind when he wrote that natural language AI agents would bring about “the biggest revolution in computing since we went from typing commands to tapping on icons”. But watching code appear and know how it works are two different things. My efforts to make my own comment summary tool produced something unworkable that gave overly long answers and then congratulated itself as a success. Willison says he wouldn’t use AI-generated code for projects he planned to ship out unless he had reviewed each line. Not only is there the risk of hallucination but the chatbot’s desire to be agreeable means it may an unusable idea works. That is a particular issue for those of us who don’t know how to fix the code. We risk creating software with hidden problems. It may not save time either. A study published in July by the non-profit Model Evaluation and Threat Research assessed work done by 16 developers — some with AI tools, some without. Those using AI assistance it had made them faster. In fact it took them nearly a fifth longer. Several developers I spoke to said AI was best used as a way to talk through coding problems. It’s a version of something they call rubber ducking (after their habit of talking to the toys on their desk) — only this rubber duck can talk back. As one put it, code shouldn’t be judged by volume or speed. Progress in AI coding is tangible. But measuring productivity gains is not as neat as a simple percentage calculation.](https://static.simonwillison.net/static/2025/ft.jpeg)
From the article, with links added by me to relevant projects:
Willison thinks the best way to see what a new model can do is to ask for something unusual. He likes to request an SVG (an image made out of lines described with code) of a pelican on a bike and asks it to remember the chickens in his garden by name. Results can be bizarre. One model ignored his prompts in favour of composing a poem.
Still, his adventures in vibe coding sound like an advert for the sector. He used Anthropic's Claude Code, the favoured model for developers, to make an OCR (optical character recognition - software loves acronyms) tool that will copy and paste text from a screenshot.
He wrote software that summarises blog comments and has plans to build a custom tool that will alert him when a whale is visible from his Pacific coast home. All this by typing prompts in English.
I've been talking about that whale spotting project for far too long. Now that it's been in the FT I really need to build it.
(On the subject of OCR... I tried extracting the text from the above image using GPT-5 and got a surprisingly bad result full of hallucinated details. Claude Opus 4.1 did a lot better but still made some mistakes. Gemini 2.5 did much better.)
How OpenElections Uses LLMs (via) The OpenElections project collects detailed election data for the USA, all the way down to the precinct level. This is a surprisingly hard problem: while county and state-level results are widely available, precinct-level results are published in thousands of different ad-hoc ways and rarely aggregated once the election result has been announced.
A lot of those precinct results are published as image-filled PDFs.
Derek Willis has recently started leaning on Gemini to help parse those PDFs into CSV data:
For parsing image PDFs into CSV files, Google’s Gemini is my model of choice, for two main reasons. First, the results are usually very, very accurate (with a few caveats I’ll detail below), and second, Gemini’s large context window means it’s possible to work with PDF files that can be multiple MBs in size.
Is this piece he shares the process and prompts for a real-world expert level data entry project, assisted by Gemini.
This example from Limestone County, Texas is a great illustration of how tricky this problem can get. Getting traditional OCR software to correctly interpret multi-column layouts like this always requires some level of manual intervention:
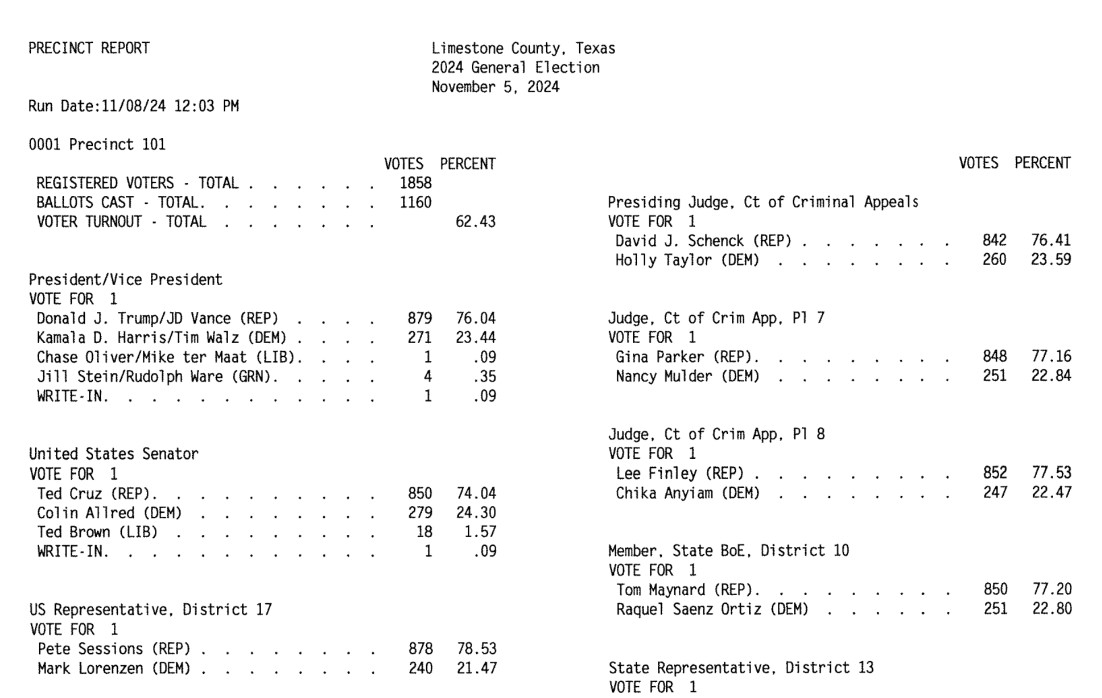
Derek's prompt against Gemini 2.5 Pro throws in an example, some special instructions and a note about the two column format:
Produce a CSV file from the attached PDF based on this example:
county,precinct,office,district,party,candidate,votes,absentee,early_voting,election_day
Limestone,Precinct 101,Registered Voters,,,,1858,,,
Limestone,Precinct 101,Ballots Cast,,,,1160,,,
Limestone,Precinct 101,President,,REP,Donald J. Trump,879,,,
Limestone,Precinct 101,President,,DEM,Kamala D. Harris,271,,,
Limestone,Precinct 101,President,,LIB,Chase Oliver,1,,,
Limestone,Precinct 101,President,,GRN,Jill Stein,4,,,
Limestone,Precinct 101,President,,,Write-ins,1,,,
Skip Write-ins with candidate names and rows with "Cast Votes", "Not Assigned", "Rejected write-in votes", "Unresolved write-in votes" or "Contest Totals". Do not extract any values that end in "%"
Use the following offices:
President/Vice President -> President
United States Senator -> U.S. Senate
US Representative -> U.S. House
State Senator -> State Senate
Quote all office and candidate values. The results are split into two columns on each page; parse the left column first and then the right column.
A spot-check and a few manual tweaks and the result against a 42 page PDF was exactly what was needed.
How about something harder? The results for Cameron County came as more than 600 pages and looked like this - note the hole-punch holes that obscure some of the text!
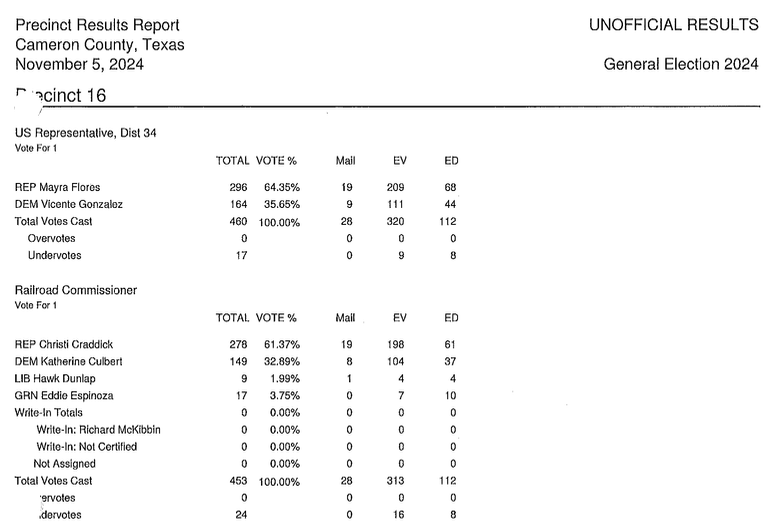
This file had to be split into chunks of 100 pages each, and the entire process still took a full hour of work - but the resulting table matched up with the official vote totals.
I love how realistic this example is. AI data entry like this isn't a silver bullet - there's still a bunch of work needed to verify the results and creative thinking needed to work through limitations - but it represents a very real improvement in how small teams can take on projects of this scale.
In the six weeks since we started working on Texas precinct results, we’ve been able to convert them for more than half of the state’s 254 counties, including many image PDFs like the ones on display here. That pace simply wouldn’t be possible with data entry or traditional OCR software.
qwen2.5vl in Ollama. Ollama announced a complete overhaul of their vision support the other day. Here's the first new model they've shipped since then - a packaged version of Qwen 2.5 VL which was first released on January 26th 2025. Here are my notes from that release.
I upgraded Ollama (it auto-updates so I just had to restart it from the tray icon) and ran this:
ollama pull qwen2.5vl
This downloaded a 6GB model file. I tried it out against my photo of Cleo rolling on the beach:
llm -a https://static.simonwillison.net/static/2025/cleo-sand.jpg \
'describe this image' -m qwen2.5vl
And got a pretty good result:
The image shows a dog lying on its back on a sandy beach. The dog appears to be a medium to large breed with a dark coat, possibly black or dark brown. It is wearing a red collar or harness around its chest. The dog's legs are spread out, and its belly is exposed, suggesting it might be rolling around or playing in the sand. The sand is light-colored and appears to be dry, with some small footprints and marks visible around the dog. The lighting in the image suggests it is taken during the daytime, with the sun casting a shadow of the dog to the left side of the image. The overall scene gives a relaxed and playful impression, typical of a dog enjoying time outdoors on a beach.
Qwen 2.5 VL has a strong reputation for OCR, so I tried it on my poster:
llm -a https://static.simonwillison.net/static/2025/poster.jpg \
'convert to markdown' -m qwen2.5vl
The result that came back:
It looks like the image you provided is a jumbled and distorted text, making it difficult to interpret. If you have a specific question or need help with a particular topic, please feel free to ask, and I'll do my best to assist you!
I'm not sure what went wrong here. My best guess is that the maximum resolution the model can handle is too small to make out the text, or maybe Ollama resized the image to the point of illegibility before handing it to the model?
Update: I think this may be a bug relating to URL handling in LLM/llm-ollama. I tried downloading the file first:
wget https://static.simonwillison.net/static/2025/poster.jpg
llm -m qwen2.5vl 'extract text' -a poster.jpg
This time it did a lot better. The results weren't perfect though - it ended up stuck in a loop outputting the same code example dozens of times.
I tried with a different prompt - "extract text" - and it got confused by the three column layout, misread Datasette as "Datasetette" and missed some of the text. Here's that result.
These experiments used qwen2.5vl:7b (6GB) - I expect the results would be better with the larger qwen2.5vl:32b (21GB) and qwen2.5vl:72b (71GB) models.
Fred Jonsson reported a better result using the MLX model via LM studio (~9GB model running in 8bit - I think that's mlx-community/Qwen2.5-VL-7B-Instruct-8bit). His full output is here - looks almost exactly right to me.
Mistral OCR (via) New closed-source specialist OCR model by Mistral - you can feed it images or a PDF and it produces Markdown with optional embedded images.
It's available via their API, or it's "available to self-host on a selective basis" for people with stringent privacy requirements who are willing to talk to their sales team.
I decided to try out their API, so I copied and pasted example code from their notebook into my custom Claude project and told it:
Turn this into a CLI app, depends on mistralai - it should take a file path and an optional API key defauling to env vironment called MISTRAL_API_KEY
After some further iteration / vibe coding I got to something that worked, which I then tidied up and shared as mistral_ocr.py.
You can try it out like this:
export MISTRAL_API_KEY='...'
uv run http://tools.simonwillison.net/python/mistral_ocr.py \
mixtral.pdf --html --inline-images > mixtral.html
I fed in the Mixtral paper as a PDF. The API returns Markdown, but my --html option renders that Markdown as HTML and the --inline-images option takes any images and inlines them as base64 URIs (inspired by monolith). The result is mixtral.html, a 972KB HTML file with images and text bundled together.
This did a pretty great job!
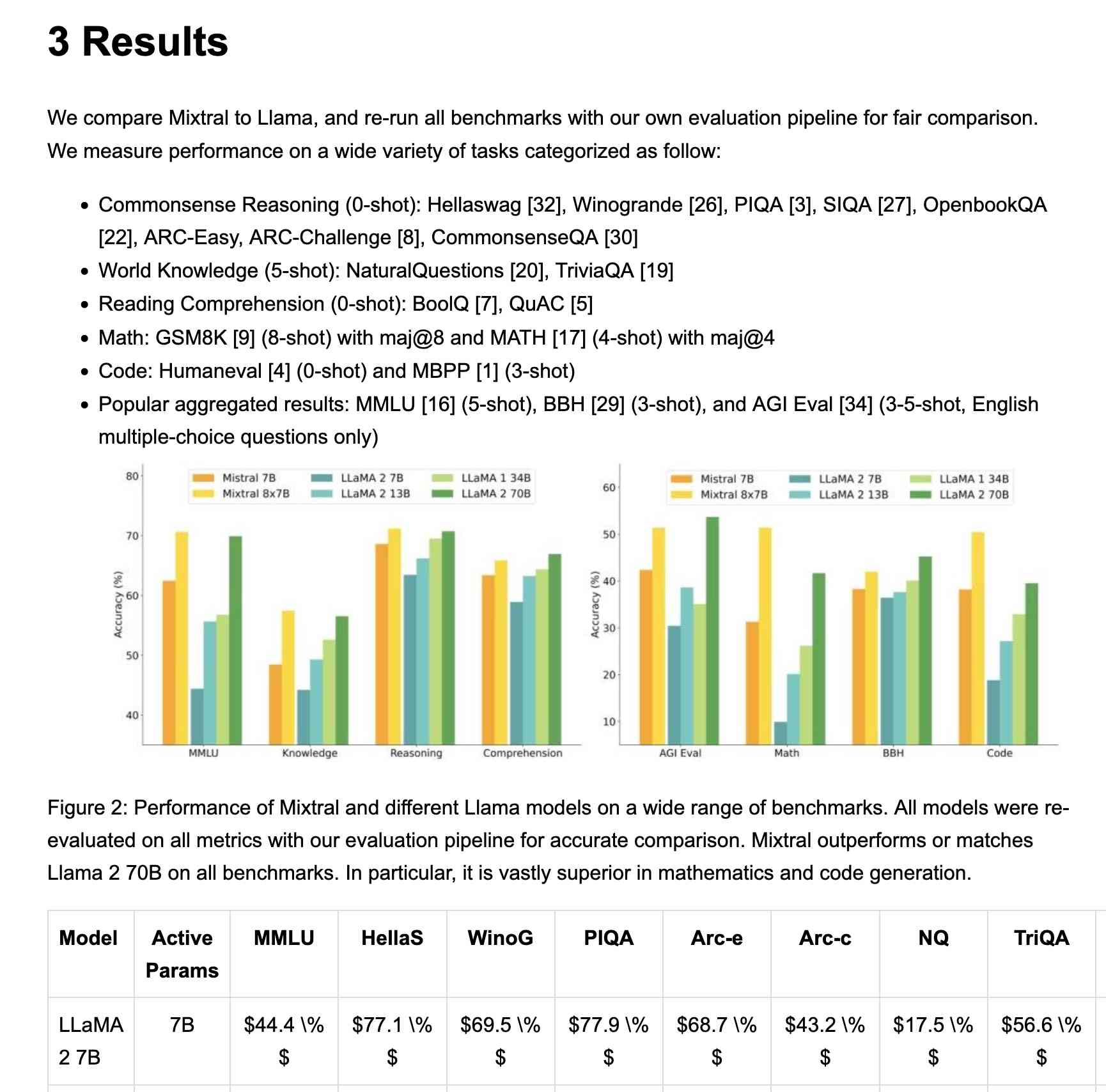
My script renders Markdown tables but I haven't figured out how to render inline Markdown MathML yet. I ran the command a second time and requested Markdown output (the default) like this:
uv run http://tools.simonwillison.net/python/mistral_ocr.py \
mixtral.pdf > mixtral.md
Here's that Markdown rendered as a Gist - there are a few MathML glitches so clearly the Mistral OCR MathML dialect and the GitHub Formatted Markdown dialect don't quite line up.
My tool can also output raw JSON as an alternative to Markdown or HTML - full details in the documentation.
The Mistral API is priced at roughly 1000 pages per dollar, with a 50% discount for batch usage.
The big question with LLM-based OCR is always how well it copes with accidental instructions in the text (can you safely OCR a document full of prompting examples?) and how well it handles text it can't write.
Mistral's Sophia Yang says it "should be robust" against following instructions in the text, and invited people to try and find counter-examples.
Alexander Doria noted that Mistral OCR can hallucinate text when faced with handwriting that it cannot understand.
olmOCR (via) New from Ai2 - olmOCR is "an open-source tool designed for high-throughput conversion of PDFs and other documents into plain text while preserving natural reading order".
At its core is allenai/olmOCR-7B-0225-preview, a Qwen2-VL-7B-Instruct variant trained on ~250,000 pages of diverse PDF content (both scanned and text-based) that were labelled using GPT-4o and made available as the olmOCR-mix-0225 dataset.
The olmocr Python library can run the model on any "recent NVIDIA GPU". I haven't managed to run it on my own Mac yet - there are GGUFs out there but it's not clear to me how to run vision prompts through them - but Ai2 offer an online demo which can handle up to ten pages for free.
Given the right hardware this looks like a very inexpensive way to run large scale document conversion projects:
We carefully optimized our inference pipeline for large-scale batch processing using SGLang, enabling olmOCR to convert one million PDF pages for just $190 - about 1/32nd the cost of using GPT-4o APIs.
The most interesting idea from the technical report (PDF) is something they call "document anchoring":
Document anchoring extracts coordinates of salient elements in each page (e.g., text blocks and images) and injects them alongside raw text extracted from the PDF binary file. [...]
Document anchoring processes PDF document pages via the PyPDF library to extract a representation of the page’s structure from the underlying PDF. All of the text blocks and images in the page are extracted, including position information. Starting with the most relevant text blocks and images, these are sampled and added to the prompt of the VLM, up to a defined maximum character limit. This extra information is then available to the model when processing the document.
![Left side shows a green-header interface with coordinates like [150x220]√3x−1+(1+x)², [150x180]Section 6, [150x50]Lorem ipsum dolor sit amet, [150x70]consectetur adipiscing elit, sed do, [150x90]eiusmod tempor incididunt ut, [150x110]labore et dolore magna aliqua, [100x280]Table 1, followed by grid coordinates with A, B, C, AA, BB, CC, AAA, BBB, CCC values. Right side shows the rendered document with equation, text and table.](https://static.simonwillison.net/static/2025/olmocr-document-anchoring.jpg)
The one limitation of olmOCR at the moment is that it doesn't appear to do anything with diagrams, figures or illustrations. Vision models are actually very good at interpreting these now, so my ideal OCR solution would include detailed automated descriptions of this kind of content in the resulting text.
Update: Jonathan Soma figured out how to run it on a Mac using LM Studio and the olmocr Python package.
Qwen2.5 VL! Qwen2.5 VL! Qwen2.5 VL! Hot on the heels of yesterday's Qwen2.5-1M, here's Qwen2.5 VL (with an excitable announcement title) - the latest in Qwen's series of vision LLMs.
They're releasing multiple versions: base models and instruction tuned models at 3B, 7B and 72B. There's a lot of additional information in their README.
The 72B model can be selected on Qwen's Qwen Chat interface. I gave it this image of our dog Cleo joy rolling on the beach:

And prompted:
Describe this image in detail, be flowery
(Since the Qwen team tends to use flowery language in their announcements.)
Here's what I got back:
In this enchanting tableau, a canine companion finds solace in the embrace of nature's softest bed. The sandy expanse stretches out like an endless canvas, its surface etched with the delicate imprints of countless wanderers who have come and gone, leaving behind a tapestry of footprints that whisper tales of joyous romps and serene strolls.
The dog, a vision of contentment, lies sprawled upon the sand, its dark fur gleaming under the gentle caress of the sun. Its body is relaxed, limbs splayed in abandon, as if it has surrendered to the soothing rhythm of the beach. A vibrant red collar adorns its neck, a splash of color against the muted tones of the surroundings, hinting at the care and love bestowed upon this cherished pet.
The sand itself is a work of art, its grains shimmering with a silvery sheen that catches the light. Here and there, small tufts of seaweed peek through, remnants of the ocean's bounty, adding a touch of wild beauty to the scene. The shadows cast by unseen objects dance across the sand, creating a play of light and dark that lends an air of mystery to the tranquil setting.
This moment, frozen in time, speaks of peace and harmony, where man's best friend finds respite in the simple pleasures of life. It is a scene that invites one to pause, breathe deeply, and revel in the serenity of nature's embrace.
I'm looking forward to trying out their smaller models - the 3B model in particular should be small enough to run comfortably even on an iPhone, so hopefully someone will wire up an example of that soon (maybe using MLX).
VB points out that the vision benchmarks for Qwen 2.5 VL 7B show it out-performing GPT-4o mini!
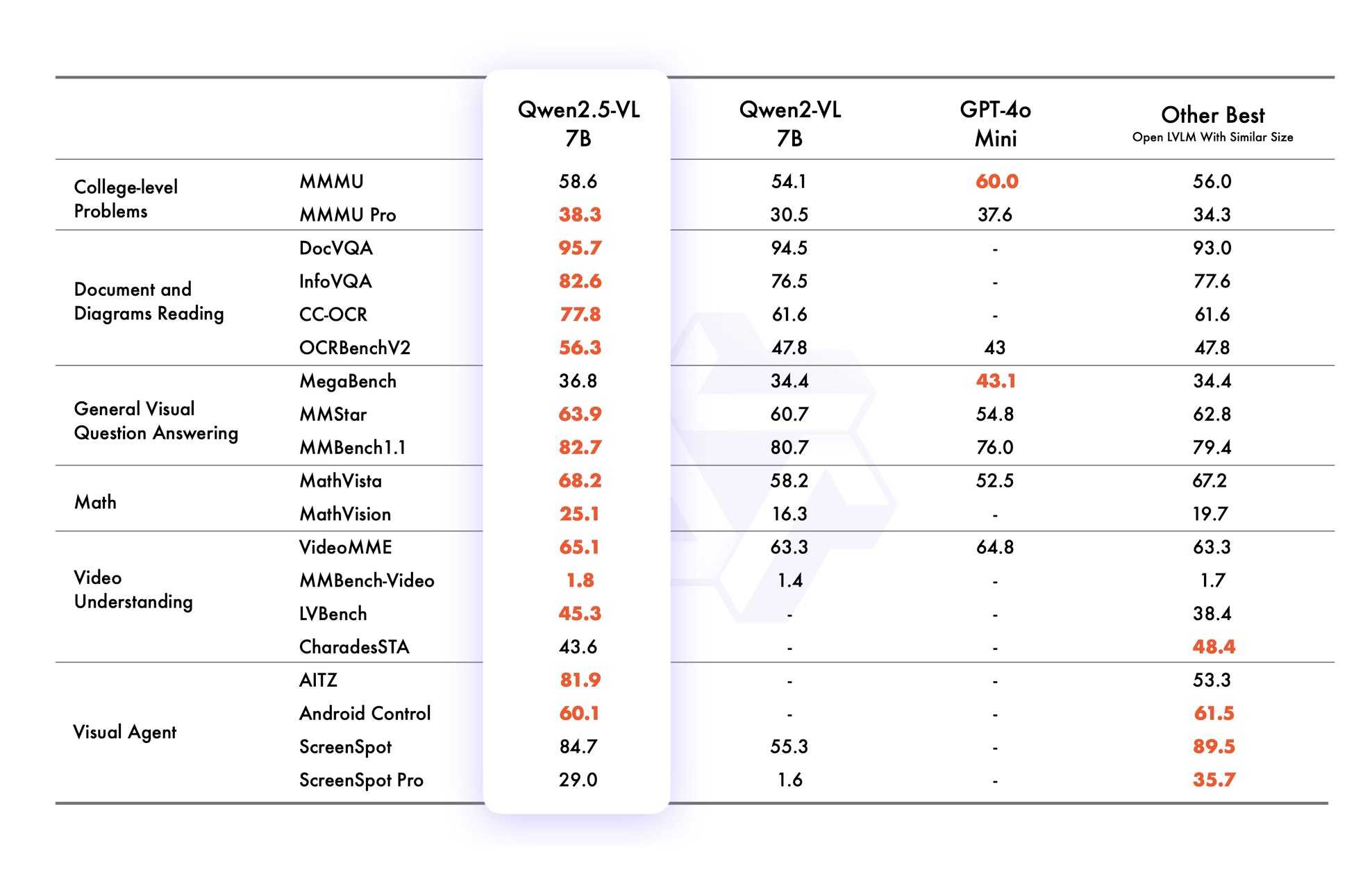
Qwen2.5 VL cookbooks
Qwen also just published a set of cookbook recipes:
- universal_recognition.ipynb demonstrates basic visual Q&A, including prompts like
Who are these in this picture? Please give their names in Chinese and Englishagainst photos of celebrities, an ability other models have deliberately suppressed. - spatial_understanding.ipynb demonstrates bounding box support, with prompts like
Locate the top right brown cake, output its bbox coordinates using JSON format. - video_understanding.ipynb breaks a video into individual frames and asks questions like
Could you go into detail about the content of this long video? - ocr.ipynb shows
Qwen2.5-VL-7B-Instructperforming OCR in multiple different languages. - document_parsing.ipynb uses Qwen to convert images of documents to HTML and other formats, and notes that "we introduce a unique Qwenvl HTML format that includes positional information for each component, enabling precise document reconstruction and manipulation."
- mobile_agent.ipynb runs Qwen with tool use against tools for controlling a mobile phone, similar to ChatGPT Operator or Claude Computer Use.
- computer_use.ipynb showcases "GUI grounding" - feeding in screenshots of a user's desktop and running tools for things like left clicking on a specific coordinate.
Running it with mlx-vlm
Update 30th January 2025: I got it working on my Mac using uv and mlx-vlm, with some hints from this issue. Here's the recipe that worked (downloading a 9GB model from mlx-community/Qwen2.5-VL-7B-Instruct-8bit):
uv run --with 'numpy<2' --with 'git+https://github.com/huggingface/transformers' \
--with mlx-vlm \
python -m mlx_vlm.generate \
--model mlx-community/Qwen2.5-VL-7B-Instruct-8bit \
--max-tokens 100 \
--temp 0.0 \
--prompt "Describe this image." \
--image path-to-image.pngI ran that against this image:
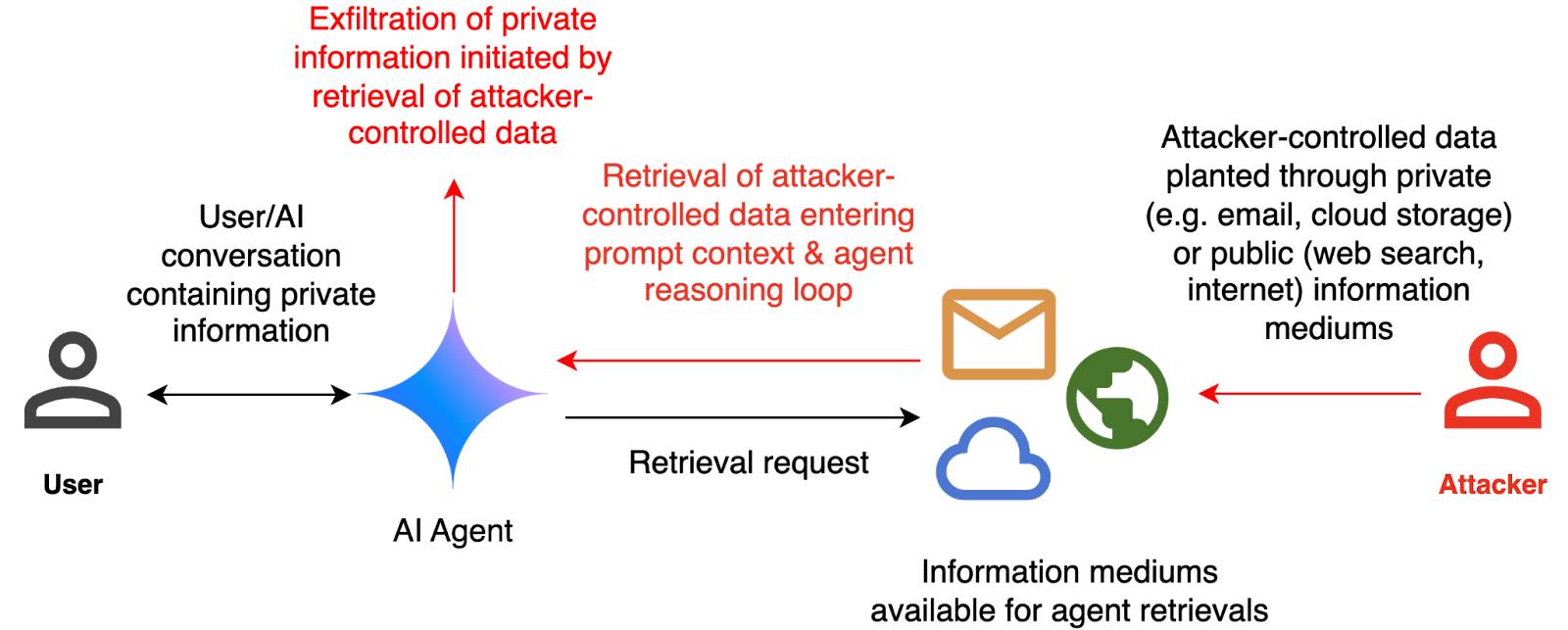
And got back this result:
The image appears to illustrate a flowchart or diagram related to a cybersecurity scenario. Here's a breakdown of the elements:
- User: Represented by a simple icon of a person.
- AI Agent: Represented by a blue diamond shape.
- Attacker: Represented by a red icon of a person.
- Cloud and Email Icons: Represented by a cloud and an envelope, indicating data or information being transferred.
- Text: The text
2024
Docling. MIT licensed document extraction Python library from the Deep Search team at IBM, who released Docling v2 on October 16th.
Here's the Docling Technical Report paper from August, which provides details of two custom models: a layout analysis model for figuring out the structure of the document (sections, figures, text, tables etc) and a TableFormer model specifically for extracting structured data from tables.
Those models are available on Hugging Face.
Here's how to try out the Docling CLI interface using uvx (avoiding the need to install it first - though since it downloads models it will take a while to run the first time):
uvx docling mydoc.pdf --to json --to md
This will output a mydoc.json file with complex layout information and a mydoc.md Markdown file which includes Markdown tables where appropriate.
The Python API is a lot more comprehensive. It can even extract tables as Pandas DataFrames:
from docling.document_converter import DocumentConverter converter = DocumentConverter() result = converter.convert("document.pdf") for table in result.document.tables: df = table.export_to_dataframe() print(df)
I ran that inside uv run --with docling python. It took a little while to run, but it demonstrated that the library works.
Running prompts against images and PDFs with Google Gemini.
New TIL. I've been experimenting with the Google Gemini APIs for running prompts against images and PDFs (in preparation for finally adding multi-modal support to LLM) - here are my notes on how to send images or PDF files to their API using curl and the base64 -i macOS command.
I figured out the curl incantation first and then got Claude to build me a Bash script that I can execute like this:
prompt-gemini 'extract text' example-handwriting.jpg
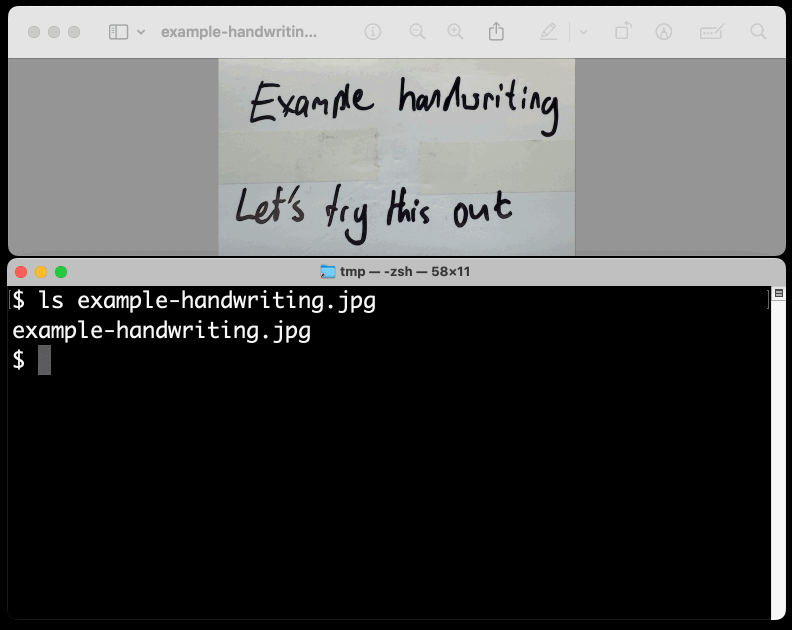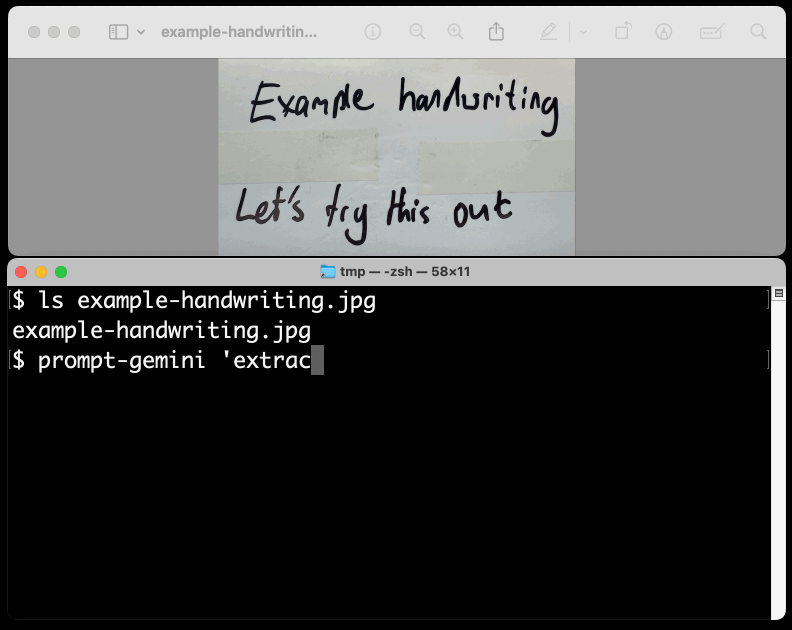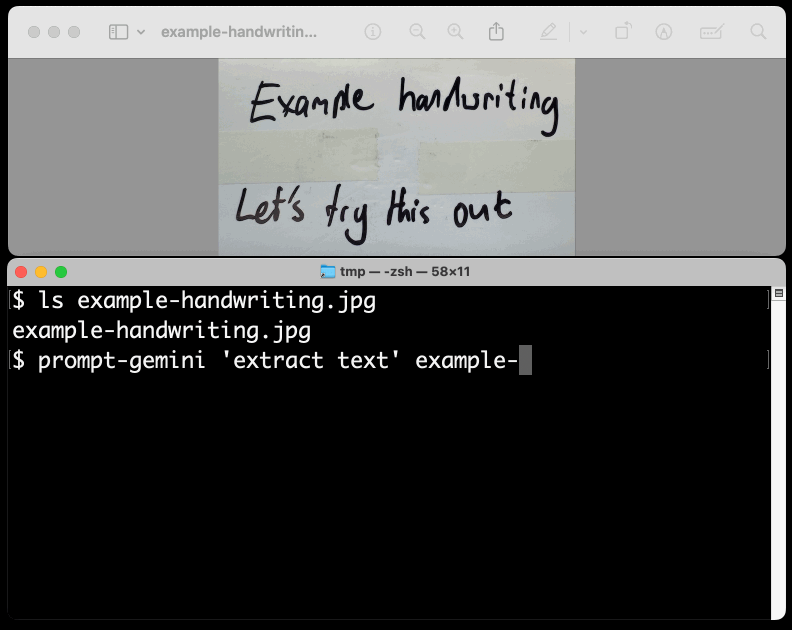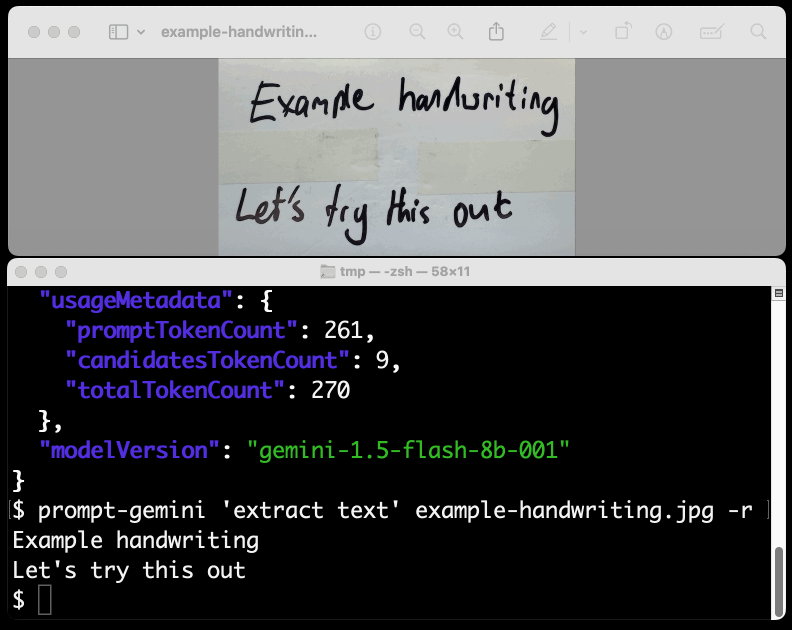
Playing with this is really fun. The Gemini models charge less than 1/10th of a cent per image, so it's really inexpensive to try them out.
State-of-the-art music scanning by Soundslice. It's been a while since I checked in on Soundslice, Adrian Holovaty's beautiful web application focused on music education.
The latest feature is spectacular. The Soundslice music editor - already one of the most impressive web applications I've ever experienced - can now import notation directly from scans or photos of sheet music.
The attention to detail is immaculate. The custom machine learning model can handle a wide variety of notation details, and the system asks the user to verify or correct details that it couldn't perfectly determine using a neatly designed flow.
Free accounts can scan two single page documents a month, and paid plans get a much higher allowance. I tried it out just now on a low resolution image I found on Wikipedia and it did a fantastic job, even allowing me to listen to a simulated piano rendition of the music once it had finished processing.
It's worth spending some time with the release notes for the feature to appreciate how much work they've out into improving it since the initial release.
If you're new to Soundslice, here's an example of their core player interface which syncs the display of music notation to an accompanying video.
Adrian wrote up some detailed notes on the machine learning behind the feature when they first launched it in beta back in November 2022.
OMR [Optical Music Recognition] is an inherently hard problem, significantly more difficult than text OCR. For one, music symbols have complex spatial relationships, and mistakes have a tendency to cascade. A single misdetected key signature might result in multiple incorrect note pitches. And there’s a wide diversity of symbols, each with its own behavior and semantics — meaning the problems and subproblems aren’t just hard, there are many of them.
Civic Band. Exciting new civic tech project from Philip James: 30 (and counting) Datasette instances serving full-text search enabled collections of OCRd meeting minutes for different civic governments. Includes 20,000 pages for Alameda, 17,000 for Pittsburgh, 3,567 for Baltimore and an enormous 117,000 for Maui County.
Philip includes some notes on how they're doing it. They gather PDF minute notes from anywhere that provides API access to them, then run local Tesseract for OCR (the cost of cloud-based OCR proving prohibitive given the volume of data). The collection is then deployed to a single VPS running multiple instances of Datasette via Caddy, one instance for each of the covered regions.
textract-cli. This is my other OCR project from yesterday: I built the thinnest possible CLI wrapper around Amazon Textract, out of frustration at how hard that tool is to use on an ad-hoc basis.
It only works with JPEGs and PNGs (not PDFs) up to 5MB in size, reflecting limitations in Textract’s synchronous API: it can handle PDFs amazingly well but you have to upload them to an S3 bucket yet and I decided to keep the scope tight for the first version of this tool.
Assuming you’ve configured AWS credentials already, this is all you need to know:
pipx install textract-cli
textract-cli image.jpeg > output.txt
Running OCR against PDFs and images directly in your browser
I attended the Story Discovery At Scale data journalism conference at Stanford this week. One of the perennial hot topics at any journalism conference concerns data extraction: how can we best get data out of PDFs and images?
[... 2,263 words]unstructured. Relatively new but impressively capable Python library (Apache 2 licensed) for extracting information from unstructured documents, such as PDFs, images, Word documents and many other formats.
I got some good initial results against a PDF by running “pip install ’unstructured[pdf]’” and then using the “unstructured.partition.pdf.partition_pdf(filename)” function.
There are a lot of moving parts under the hood: pytesseract, OpenCV, various PDF libraries, even an ONNX model—but it installed cleanly for me on macOS and worked out of the box.
2023
Our search for the best OCR tool in 2023, and what we found. DocumentCloud’s Sanjin Ibrahimovic reviews the best options for OCR. Tesseract scores highly for easily machine readable text, newcomer docTR is great for ease of use but still not great at handwriting. Amazon Textract is great for everything except non-Latin languages, Google Cloud Vision is great at pretty much everything except for ease-of-use. Azure AI Document Intelligence sounds worth considering as well.
How I make annotated presentations
Giving a talk is a lot of work. I go by a rule of thumb I learned from Damian Conway: a minimum of ten hours of preparation for every one hour spent on stage.
[... 2,128 words]textra (via) Tiny (432KB) macOS binary CLI tool by Dylan Freedman which produces high quality text extraction from PDFs, images and even audio files using the VisionKit APIs in macOS 13 and higher. It handles handwriting too!
2022
Building a searchable archive for the San Francisco Microscopical Society

The San Francisco Microscopical Society was founded in 1870 by a group of scientists dedicated to advancing the field of microscopy.
[... 1,845 words]Digitizing 55,000 pages of civic meetings (via) Philip James has been building public, searchable archives of city council meetings for various cities—Oakland and Alamedia so far—using my s3-ocr script to run Textract OCR against the PDFs of the minutes, and deploying them to Fly using Datasette. This is a really cool project, and very much the kind of thing I’ve been hoping to support with the tools I’ve been building.
Litestream backups for Datasette Cloud (and weeknotes)
My main focus this week has been adding robust backups to the forthcoming Datasette Cloud.
[... 1,604 words]s3-ocr: Extract text from PDF files stored in an S3 bucket
I’ve released s3-ocr, a new tool that runs Amazon’s Textract OCR text extraction against PDF files in an S3 bucket, then writes the resulting text out to a SQLite database with full-text search configured so you can run searches against the extracted data.
[... 1,493 words]2021
Organize and Index Your Screenshots (OCR) on macOS (via) Alexandru Nedelcu has a very neat recipe for creating an archive of searchable screenshots on macOS: set the default save location for screenshots to a Dropbox folder, then create a launch agent that runs a script against new files in that folder to run tesseract OCR to convert them into a searchable PDF.
2009
Google Docs OCR. Whoa, the Google Docs API just got really interesting—you can upload an image to it (POST /feeds/default/private/full?ocr=true) and it will OCR the text and turn it in to a document. Since this is Google, I imagine they’ll also be using the processed documents to further improve their OCR technology.
OCR and Neural Nets in JavaScript. John dissects the brilliant Greasemonkey script that solves simple captchas using the canvas element and HTML5’s getImageData API.
2007
tesseract-ocr. Open source OCR, sponsored by Google. I just sat in on a talk on this at OSCON and the complexity of the problem is pretty incredible.