3 posts tagged “tesseract”
2024
Civic Band. Exciting new civic tech project from Philip James: 30 (and counting) Datasette instances serving full-text search enabled collections of OCRd meeting minutes for different civic governments. Includes 20,000 pages for Alameda, 17,000 for Pittsburgh, 3,567 for Baltimore and an enormous 117,000 for Maui County.
Philip includes some notes on how they're doing it. They gather PDF minute notes from anywhere that provides API access to them, then run local Tesseract for OCR (the cost of cloud-based OCR proving prohibitive given the volume of data). The collection is then deployed to a single VPS running multiple instances of Datasette via Caddy, one instance for each of the covered regions.
Running OCR against PDFs and images directly in your browser
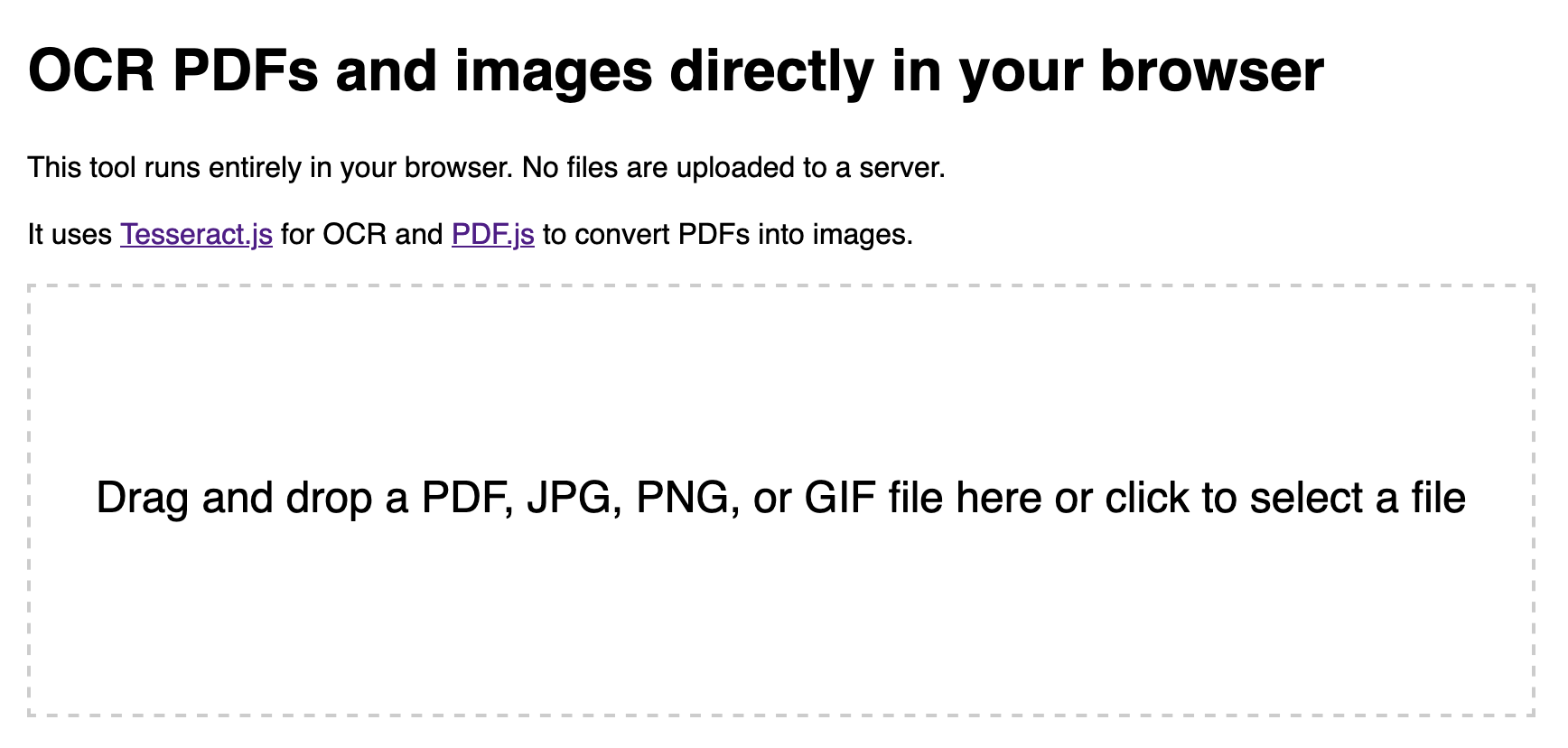
I attended the Story Discovery At Scale data journalism conference at Stanford this week. One of the perennial hot topics at any journalism conference concerns data extraction: how can we best get data out of PDFs and images?
[... 2,263 words]2007
tesseract-ocr. Open source OCR, sponsored by Google. I just sat in on a talk on this at OSCON and the complexity of the problem is pretty incredible.