Tuesday, 2nd July 2024
Weeknotes: a livestream, a surprise keynote and progress on Datasette Cloud billing

My first YouTube livestream with Val Town, a keynote at the AI Engineer World’s Fair and some work integrating Stripe with Datasette Cloud. Plus a bunch of upgrades to my blog.
[... 1,124 words]So VisiCalc came and went, but the software genre it pioneered – the spreadsheet – endured to become arguably the most influential type of code ever written, at least in the sense of touching the lives of millions of office workers. I’ve never worked in an organisation in which spreadsheet software was not at the heart of most accounting, budgeting and planning activities. I’ve even known professionals for whom it’s the only piece of PC software they’ve ever used: one elderly accountant of my acquaintance, for example, used Excel even for his correspondence; he simply widened column A to 80 characters, typed his text in descending cells and hit the “print” key.
Optimizing Large-Scale OpenStreetMap Data with SQLite (via) JT Archie describes his project to take 9GB of compressed OpenStreetMap protobufs data for the whole of the United States and load it into a queryable SQLite database.
OSM tags are key/value pairs. The trick used here for FTS-accelerated tag queries is really neat: build a SQLite FTS table containing the key/value pairs as space concatenated text, then run queries that look like this:
SELECT
id
FROM
entries e
JOIN search s ON s.rowid = e.id
WHERE
-- use FTS index to find subset of possible results
search MATCH 'amenity cafe'
-- use the subset to find exact matches
AND tags->>'amenity' = 'cafe';
JT ended up building a custom SQLite Go extension, SQLiteZSTD, to further accelerate things by supporting queries against read-only zstd compresses SQLite files. Apparently zstd has a feature that allows "compressed data to be stored so that subranges of the data can be efficiently decompressed without requiring the entire document to be decompressed", which works well with SQLite's page format.
Compare PDFs. Inspired by this thread on Hacker News about the C++ diff-pdf tool I decided to see what it would take to produce a web-based PDF diff visualization tool using Claude 3.5 Sonnet.
It took two prompts:
Build a tool where I can drag and drop on two PDF files and it uses PDF.js to turn each of their pages into canvas elements and then displays those pages side by side with a third image that highlights any differences between them, if any differences exist
That give me a React app that didn't quite work, so I followed-up with this:
rewrite that code to not use React at all
Which gave me a working tool! You can see the full Claude transcript in this Gist. Here's a screenshot of the tool in action:
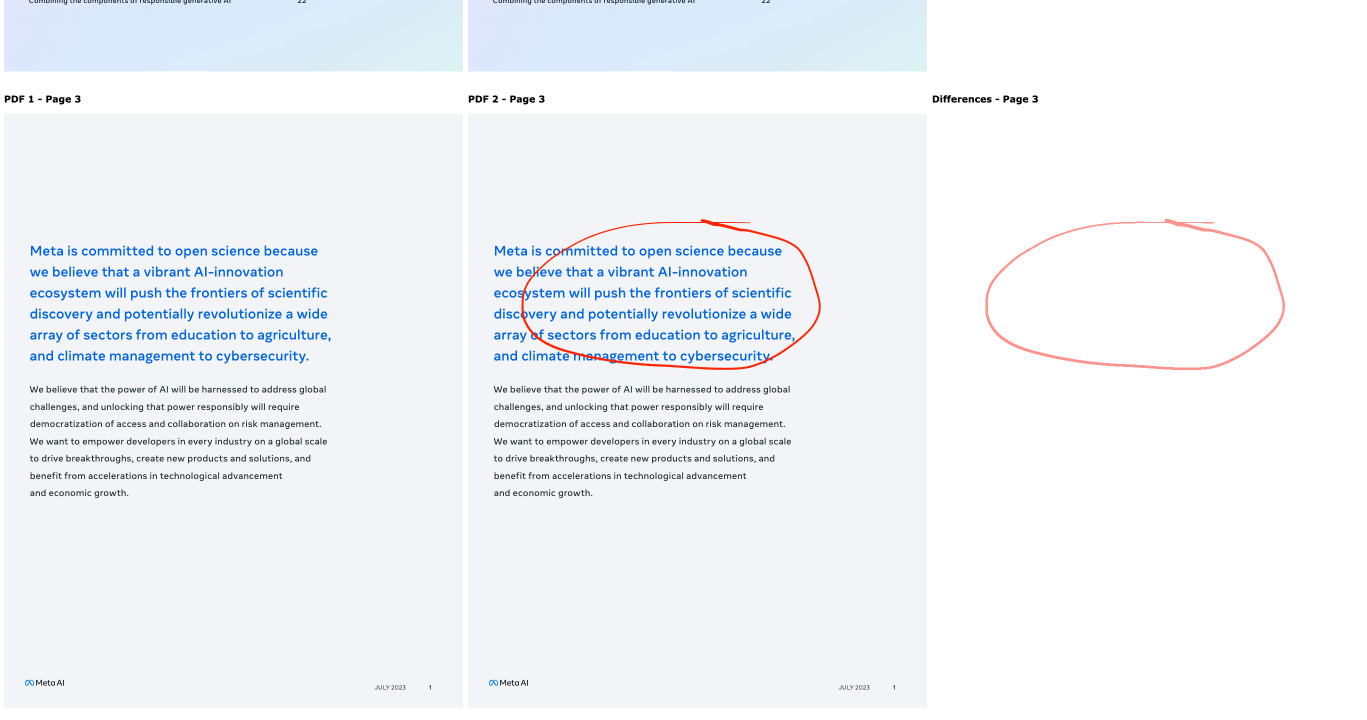
Being able to knock out little custom interactive web tools like this in a couple of minutes is so much fun.
gemma-2-27b-it-llamafile (via) Justine Tunney shipped llamafile packages of Google's new openly licensed (though definitely not open source) Gemma 2 27b model this morning.
I downloaded the gemma-2-27b-it.Q5_1.llamafile version (20.5GB) to my Mac, ran chmod 755 gemma-2-27b-it.Q5_1.llamafile and then ./gemma-2-27b-it.Q5_1.llamafile and now I'm trying it out through the llama.cpp default web UI in my browser. It works great.
It's a very capable model - currently sitting at position 12 on the LMSYS Arena making it the highest ranked open weights model - one position ahead of Llama-3-70b-Instruct and within striking distance of the GPT-4 class models.