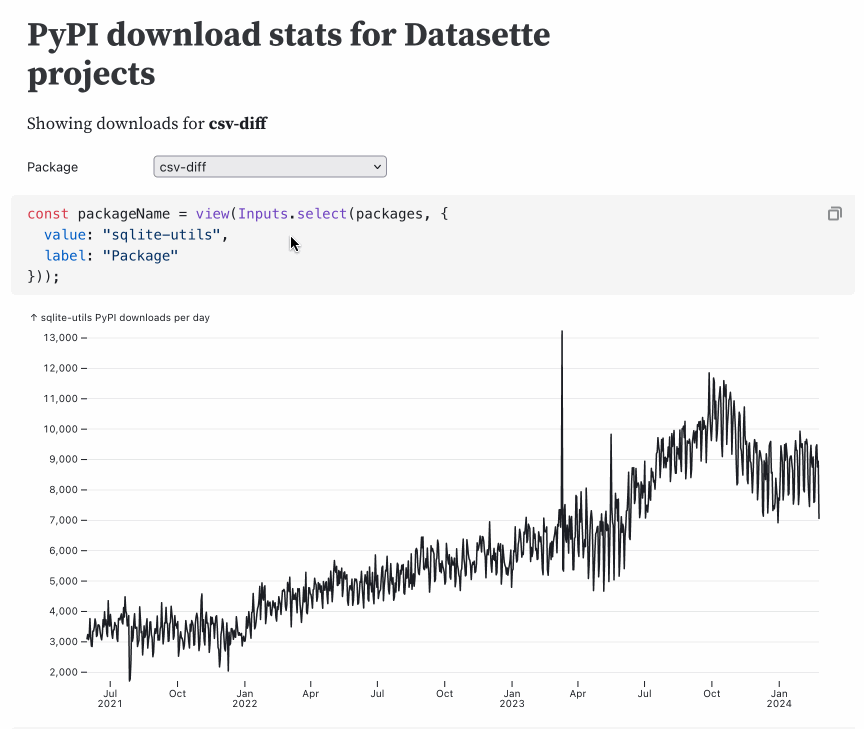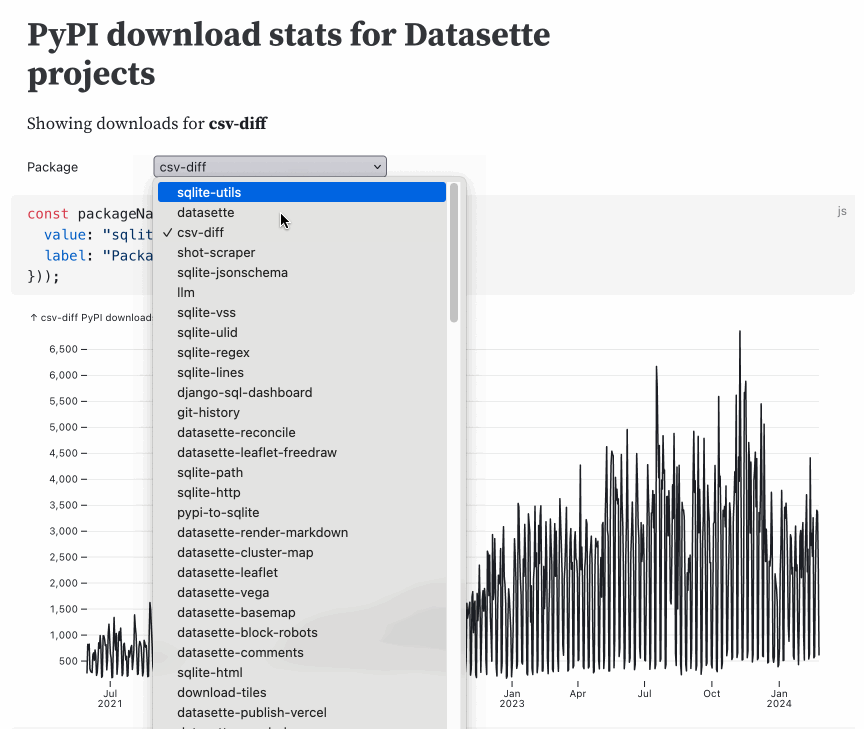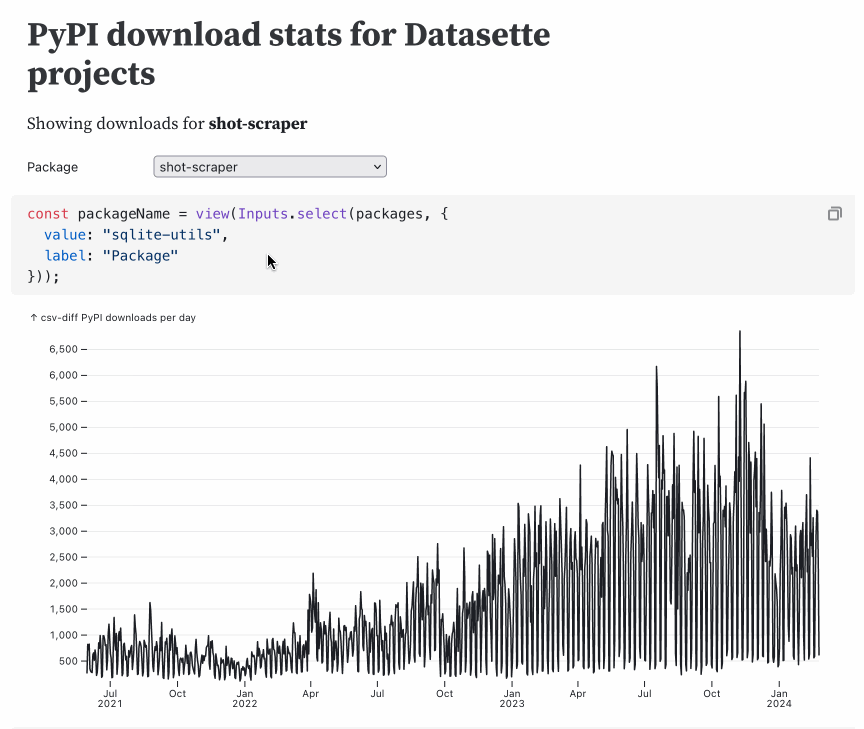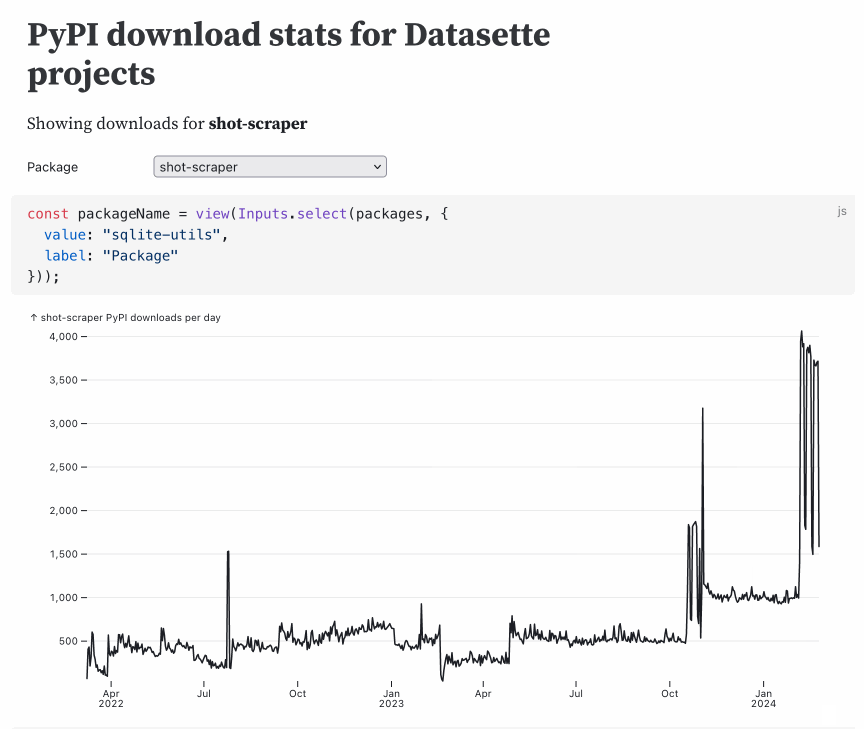
44 posts tagged “jupyter”
2025
Marimo is Joining CoreWeave (via) I don't usually cover startup acquisitions here, but this one feels relevant to several of my interests.
Marimo (previously) provide an open source (Apache 2 licensed) notebook tool for Python, with first-class support for an additional WebAssembly build plus an optional hosted service. It's effectively a reimagining of Jupyter notebooks as a reactive system, where cells automatically update based on changes to other cells - similar to how Observable JavaScript notebooks work.
The first public Marimo release was in January 2024 and the tool has "been in development since 2022" (source).
CoreWeave are a big player in the AI data center space. They started out as an Ethereum mining company in 2017, then pivoted to cloud computing infrastructure for AI companies after the 2018 cryptocurrency crash. They IPOd in March 2025 and today they operate more than 30 data centers worldwide and have announced a number of eye-wateringly sized deals with companies such as Cohere and OpenAI. I found their Wikipedia page very helpful.
They've also been on an acquisition spree this year, including:
- Weights & Biases in March 2025 (deal closed in May), the AI training observability platform.
- OpenPipe in September 2025 - a reinforcement learning platform, authors of the Agent Reinforcement Trainer Apache 2 licensed open source RL framework.
- Monolith AI in October 2025, a UK-based AI model SaaS platform focused on AI for engineering and industrial manufacturing.
- And now Marimo.
Marimo's own announcement emphasizes continued investment in that tool:
Marimo is joining CoreWeave. We’re continuing to build the open-source marimo notebook, while also leveling up molab with serious compute. Our long-term mission remains the same: to build the world’s best open-source programming environment for working with data.
marimo is, and always will be, free, open-source, and permissively licensed.
Give CoreWeave's buying spree only really started this year it's impossible to say how well these acquisitions are likely to play out - they haven't yet established a track record.
2024
Announcing Deno 2. The big focus of Deno 2 is compatibility with the existing Node.js and npm ecosystem:
Deno 2 takes all of the features developers love about Deno 1.x — zero-config, all-in-one toolchain for JavaScript and TypeScript development, web standard API support, secure by default — and makes it fully backwards compatible with Node and npm (in ESM).
The npm support is documented here. You can write a script like this:
import * as emoji from "npm:node-emoji";
console.log(emoji.emojify(`:sauropod: :heart: npm`));And when you run it Deno will automatically fetch and cache the required dependencies:
deno run main.js
Another new feature that caught my eye was this:
deno jupyternow supports outputting images, graphs, and HTML
Deno has apparently shipped with a Jupyter notebook kernel for a while, and it's had a major upgrade in this release.
Here's Ryan Dahl's demo of the new notebook support in his Deno 2 release video.
I tried this out myself, and it's really neat. First you need to install the kernel:
deno juptyer --install
I was curious to find out what this actually did, so I dug around in the code and then further in the Rust runtimed dependency. It turns out installing Jupyter kernels, at least on macOS, involves creating a directory in ~/Library/Jupyter/kernels/deno and writing a kernel.json file containing the following:
{
"argv": [
"/opt/homebrew/bin/deno",
"jupyter",
"--kernel",
"--conn",
"{connection_file}"
],
"display_name": "Deno",
"language": "typescript"
}That file is picked up by any Jupyter servers running on your machine, and tells them to run deno jupyter --kernel ... to start a kernel.
I started Jupyter like this:
jupyter-notebook /tmp
Then started a new notebook, selected the Deno kernel and it worked as advertised:
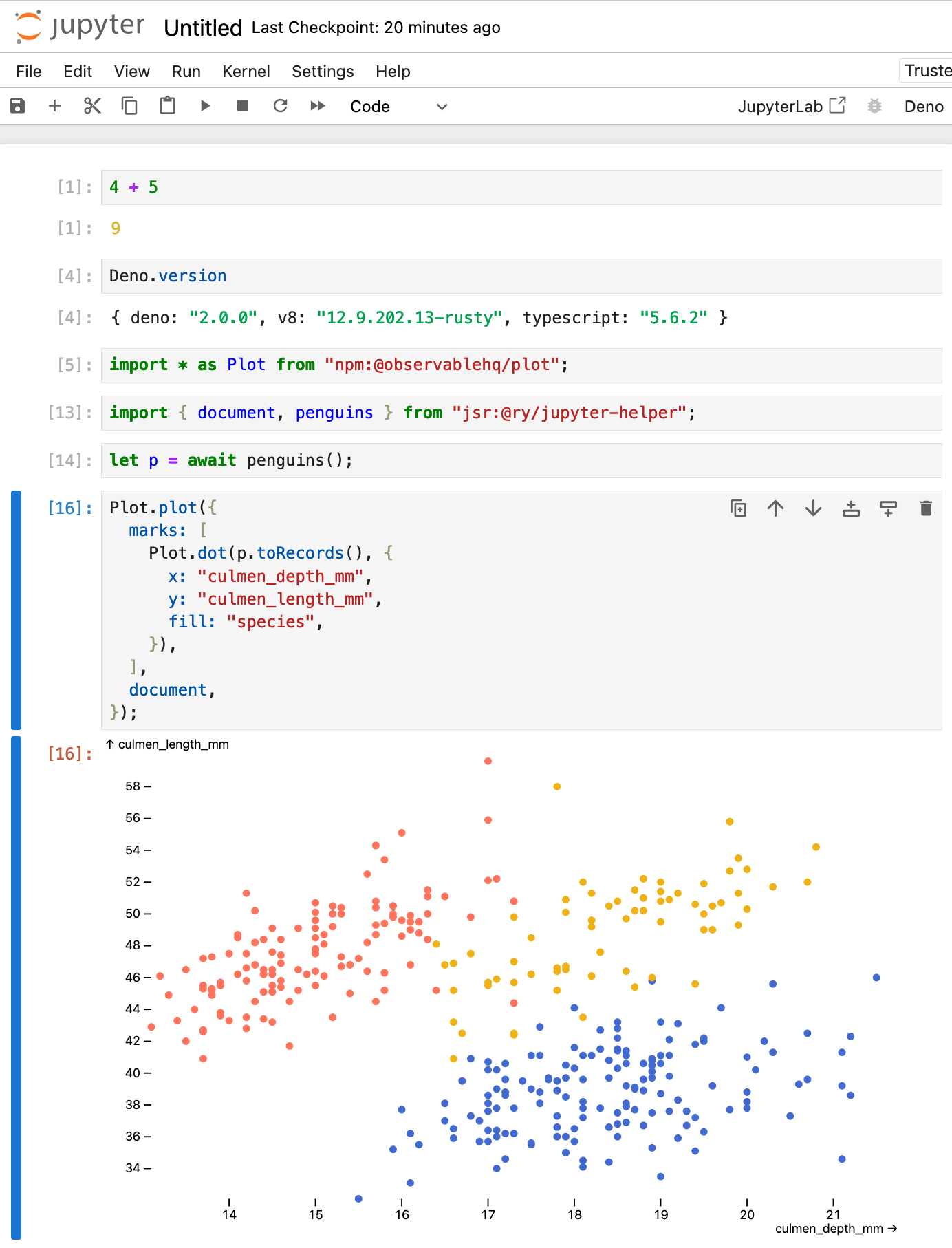
import * as Plot from "npm:@observablehq/plot";
import { document, penguins } from "jsr:@ry/jupyter-helper";
let p = await penguins();
Plot.plot({
marks: [
Plot.dot(p.toRecords(), {
x: "culmen_depth_mm",
y: "culmen_length_mm",
fill: "species",
}),
],
document,
});Anthropic’s Prompt Engineering Interactive Tutorial (via) Anthropic continue their trend of offering the best documentation of any of the leading LLM vendors. This tutorial is delivered as a set of Jupyter notebooks - I used it as an excuse to try uvx like this:
git clone https://github.com/anthropics/courses
uvx --from jupyter-core jupyter notebook coursesThis installed a working Jupyter system, started the server and launched my browser within a few seconds.
The first few chapters are pretty basic, demonstrating simple prompts run through the Anthropic API. I used %pip install anthropic instead of !pip install anthropic to make sure the package was installed in the correct virtual environment, then filed an issue and a PR.
One new-to-me trick: in the first chapter the tutorial suggests running this:
API_KEY = "your_api_key_here" %store API_KEY
This stashes your Anthropic API key in the IPython store. In subsequent notebooks you can restore the API_KEY variable like this:
%store -r API_KEY
I poked around and on macOS those variables are stored in files of the same name in ~/.ipython/profile_default/db/autorestore.
Chapter 4: Separating Data and Instructions included some interesting notes on Claude's support for content wrapped in XML-tag-style delimiters:
Note: While Claude can recognize and work with a wide range of separators and delimeters, we recommend that you use specifically XML tags as separators for Claude, as Claude was trained specifically to recognize XML tags as a prompt organizing mechanism. Outside of function calling, there are no special sauce XML tags that Claude has been trained on that you should use to maximally boost your performance. We have purposefully made Claude very malleable and customizable this way.
Plus this note on the importance of avoiding typos, with a nod back to the problem of sandbagging where models match their intelligence and tone to that of their prompts:
This is an important lesson about prompting: small details matter! It's always worth it to scrub your prompts for typos and grammatical errors. Claude is sensitive to patterns (in its early years, before finetuning, it was a raw text-prediction tool), and it's more likely to make mistakes when you make mistakes, smarter when you sound smart, sillier when you sound silly, and so on.
Chapter 5: Formatting Output and Speaking for Claude includes notes on one of Claude's most interesting features: prefill, where you can tell it how to start its response:
client.messages.create( model="claude-3-haiku-20240307", max_tokens=100, messages=[ {"role": "user", "content": "JSON facts about cats"}, {"role": "assistant", "content": "{"} ] )
Things start to get really interesting in Chapter 6: Precognition (Thinking Step by Step), which suggests using XML tags to help the model consider different arguments prior to generating a final answer:
Is this review sentiment positive or negative? First, write the best arguments for each side in <positive-argument> and <negative-argument> XML tags, then answer.
The tags make it easy to strip out the "thinking out loud" portions of the response.
It also warns about Claude's sensitivity to ordering. If you give Claude two options (e.g. for sentiment analysis):
In most situations (but not all, confusingly enough), Claude is more likely to choose the second of two options, possibly because in its training data from the web, second options were more likely to be correct.
This effect can be reduced using the thinking out loud / brainstorming prompting techniques.
A related tip is proposed in Chapter 8: Avoiding Hallucinations:
How do we fix this? Well, a great way to reduce hallucinations on long documents is to make Claude gather evidence first.
In this case, we tell Claude to first extract relevant quotes, then base its answer on those quotes. Telling Claude to do so here makes it correctly notice that the quote does not answer the question.
I really like the example prompt they provide here, for answering complex questions against a long document:
<question>What was Matterport's subscriber base on the precise date of May 31, 2020?</question>
Please read the below document. Then, in <scratchpad> tags, pull the most relevant quote from the document and consider whether it answers the user's question or whether it lacks sufficient detail. Then write a brief numerical answer in <answer> tags.
Anthropic cookbook: multimodal. I'm currently on the lookout for high quality sources of information about vision LLMs, including prompting tricks for getting the most out of them.
This set of Jupyter notebooks from Anthropic (published four months ago to accompany the original Claude 3 models) is the best I've found so far. Best practices for using vision with Claude includes advice on multi-shot prompting with example, plus this interesting think step-by-step style prompt for improving Claude's ability to count the dogs in an image:
You have perfect vision and pay great attention to detail which makes you an expert at counting objects in images. How many dogs are in this picture? Before providing the answer in
<answer>tags, think step by step in<thinking>tags and analyze every part of the image.
marimo.app. The Marimo reactive notebook (previously) - a Python notebook that's effectively a cross between Jupyter and Observable - now also has a version that runs entirely in your browser using WebAssembly and Pyodide. Here's the documentation.
fastlite (via) New Python library from Jeremy Howard that adds some neat utility functions and syntactic sugar to my sqlite-utils Python library, specifically for interactive use in Jupyter notebooks.
The autocomplete support through newly exposed dynamic properties is particularly neat, as is the diagram(db.tables) utility for rendering a graphviz diagram showing foreign key relationships between all of the tables.
Interesting ideas in Observable Framework
Mike Bostock, Announcing: Observable Framework:
[... 2,123 words]Marimo (via) This is a really interesting new twist on Python notebooks.
The most powerful feature is that these notebooks are reactive: if you change the value or code in a cell (or change the value in an input widget) every other cell that depends on that value will update automatically. It’s the same pattern implemented by Observable JavaScript notebooks, but now it works for Python.
There are a bunch of other nice touches too. The notebook file format is a regular Python file, and those files can be run as “applications” in addition to being edited in the notebook interface. The interface is very nicely built, especially for such a young project—they even have GitHub Copilot integration for their CodeMirror cell editors.
2023
Bottleneck T5 Text Autoencoder (via) Colab notebook by Linus Lee demonstrating his Contra Bottleneck T5 embedding model, which can take up to 512 tokens of text, convert that into a 1024 floating point number embedding vector... and then then reconstruct the original text (or a close imitation) from the embedding again.
This allows for some fascinating tricks, where you can do things like generate embeddings for two completely different sentences and then reconstruct a new sentence that combines the weights from both.
codespaces-jupyter (via) This is really neat. Click “Use this template” -> “Open in a codespace” and you get a full in-browser VS Code interface where you can open existing notebook files (or create new ones) and start playing with them straight away.
2022
Grokking Stable Diffusion (via) Jonathan Whitaker built this interactive Jupyter notebook that walks through how to use Stable Diffusion from Python step-by-step, and then dives deep into helping understand the different components of the implementation, including how text is encoded, how the diffusion loop works and more. This is by far the most useful tool I’ve seen yet for understanding how this model actually works. You can run Jonathan’s notebook directly on Google Colab, with a GPU.
storysniffer (via) Ben Welsh built a small Python library that guesses if a URL points to an article on a news website, or if it’s more likely to be a category page or /about page or similar. I really like this as an example of what you can do with a tiny machine learning model: the model is bundled as a ~3MB pickle file as part of the package, and the repository includes the Jupyter notebook that was used to train it.
2021
Weeknotes: datasette-jupyterlite, s3-credentials and a Python packaging talk
My big project this week was s3-credentials, described yesterday—but I also put together a fun expermiental Datasette plugin bundling JupyterLite and wrote up my PyGotham talk on Python packaging.
[... 476 words]2020
Proof of concept: sqlite_utils magic for Jupyter (via) Tony Hirst has been experimenting with building a Jupyter “magic” that adds special syntax for using sqlite-utils to insert data and run queries. Query results come back as a Pandas DataFrame, which Jupyter then displays as a table.
Estimating COVID-19’s Rt in Real-Time. I’m not qualified to comment on the mathematical approach, but this is a really nice example of a Jupyter Notebook explanatory essay by Kevin Systrom.
Weeknotes: Datasette 0.39 and many other projects
This week’s theme: Well, I’m not going anywhere. So a ton of progress to report on various projects.
[... 806 words]2019
selenium-demoscraper (via) Really useful minimal example of a Binder project. Click the button to launch a Jupyter notebook in Binder that can take screenshots of URLs using Selenium-controlled headless Firefox. The binder/ folder uses an apt.txt file to install Firefox, requirements.txt to get some Python dependencies and a postBuild Python script to download the Gecko Selenium driver.
Los Angeles Weedmaps analysis (via) Ben Welsh at the LA Times published this Jupyter notebook showing the full working behind a story they published about LA’s black market weed dispensaries. I picked up several useful tricks from it—including how to load points into a geopandas GeoDataFrame (in epsg:4326 aka WGS 84) and how to then join that against the LA Times neighborhoods GeoJSON boundaries file.
2018
Fast Autocomplete Search for Your Website (via) I wrote a tutorial for the 24 ways advent calendar on building fast autocomplete search for a website on top of Datasette and SQLite. I built the demo against 24 ways itself—I used wget to recursively fetch all 330 articles as HTML, then wrote code in a Jupyter notebook to extract the raw data from them (with BeautifulSoup) and load them into SQLite using my sqlite-utils Python library. I deployed the resulting database using Datasette, then wrote some vanilla JavaScript to implement autocomplete using fast SQL queries against the Datasette JSON API.
The _repr_html_ method in Jupyter notebooks (via) Today I learned that if you add a _repr_html_ method returning a string of HTML to any Python class Jupyter notebooks will render that HTML inline to represent that object.
repo2docker (via) Neat tool from the Jupyter project team: run “jupyter-repo2docker https://github.com/norvig/pytudes” and it will pull a GitHub repository, create a new Docker container for it, install Jupyter and launch a Jupyter instance for you to start trying out the library. I’ve been doing this by hand using virtual environments, but using Docker for even cleaner isolation seems like a smart improvement.
Helicopter accident analysis notebook (via) Ben Welsh worked on an article for the LA Times about helicopter accident rates, and has published the underlying analysis as an extremely detailed Jupyter notebook. Lots of neat new (to me) notebook tricks in here as well.
Tracking Jupyter: Newsletter, the Third... (via) Tony Hirst’s tracking Jupyter newsletter is fantastic. The Jupyter ecosystem is incredibly exciting and fast moving at the moment as more and more groups discover how productive it is, and Tony’s newsletter is a wealth of information on what’s going on out there.
Computational and Inferential Thinking: The Foundations of Data Science. Free online textbook written for the UC Berkeley Foundations of Data Science class. The examples are all provided as Jupyter notebooks, using the mybinder web application to allow students to launch interactive notebooks for any of the examples without having to install any software on their own machines.
The Future of Notebooks: Lessons from JupyterCon (via) It sounds like reactive notebooks (where cells keep track of their dependencies on other cells and re-evaluate when those update) were a hot topic at JupyterCon this year.
In case you missed it: @GoogleColab can open any @ProjectJupyter notebook directly from @github!
To run the notebook, just replace "github.com" with "colab.research.google.com/github/" in the notebook URL, and it will be loaded into Colab.
I don’t like Jupyter Notebooks—a presentation by Joel Grus (via) Fascinating talk by Joel Grus at the Jupyter conference in New York. He highlights some of the drawbacks of he Jupyter way of working, including the huge confusion that can come from the ability to execute cells out of order (something Observable notebooks solve brilliantly using spreadsheet-style reactive cell associations). He also makes strong arguments that notebooks encourage a way of working that discourages people from producing stable, repeatable and well tested code.
Beyond Interactive: Notebook Innovation at Netflix. Netflix have been investing heavily in their internal Jupyter notebooks infrastructure: it’s now the most popular tool for working with data at Netflix. They also use parameterized notebooks to make it easy to create templates for reusable operations, and scheduled notebooks for recurring tasks. “When a Spark or Presto job executes from the scheduler, the source code is injected into a newly-created notebook and executed. That notebook then becomes an immutable historical record, containing all related artifacts — including source code, parameters, runtime config, execution logs, error messages, and so on.”
Every day more than 1 trillion events are written into a streaming ingestion pipeline, which is processed and written to a 100PB cloud-native data warehouse. And every day, our users run more than 150,000 jobs against this data, spanning everything from reporting and analysis to machine learning and recommendation algorithms.
At Harvard we've built out an infrastructure to allow us to deploy JupyterHub to courses with authentication managed by Canvas. It has allowed us to easily deploy complex set-ups to students so they can do really cool stuff without having to spend hours walking them through setup. Instructors are writing their lectures as IPython notebooks, and distributing them to students, who then work through them in their JupyterHub environment. Our most ambitious so far has been setting up each student in the course with a p2.xlarge machine with cuda and TensorFlow so they could do deep learning work for their final projects. We supported 15 courses last year, and got deployment time for an implementation down to only 2-3 hours.