Datasette 0.50: The annotated release notes
9th October 2020
I released Datasette 0.50 this morning, with a new user-facing column actions menu feature and a way for plugins to make internal HTTP requests to consume the JSON API of their parent Datasette instance.
The column actions menu
The key new feature in this release is the column actions menu on the table page (#891). This can be used to sort a column in ascending or descending order, facet data by that column or filter the table to just rows that have a value for that column.
The table page is the most important page within Datasette: it’s where users interact with database tables.
Prior to 0.50 users could sort those tables by clicking on the column header. If they wanted to sort in descending order they had to click it, wait for the table to reload and then click it a second time.
In 0.50 I’ve introduced a new UI element which I’m calling the column actions menu. Here’s an animation showing it in action on the facetable demo table:
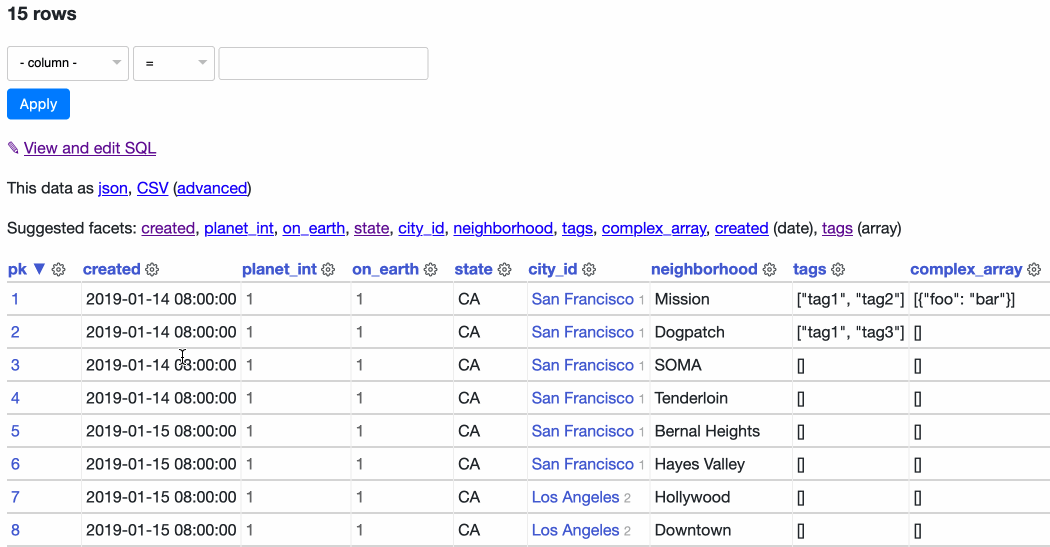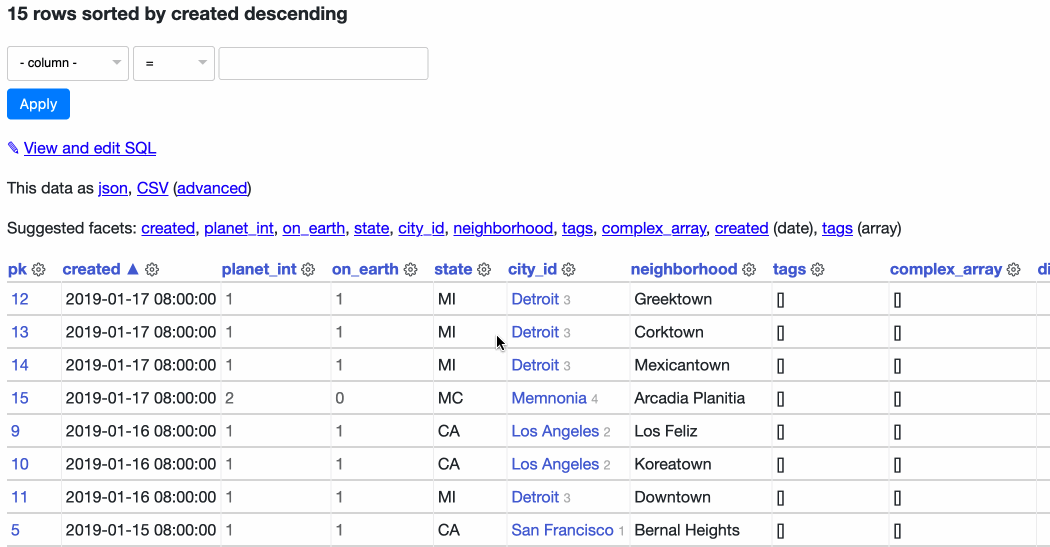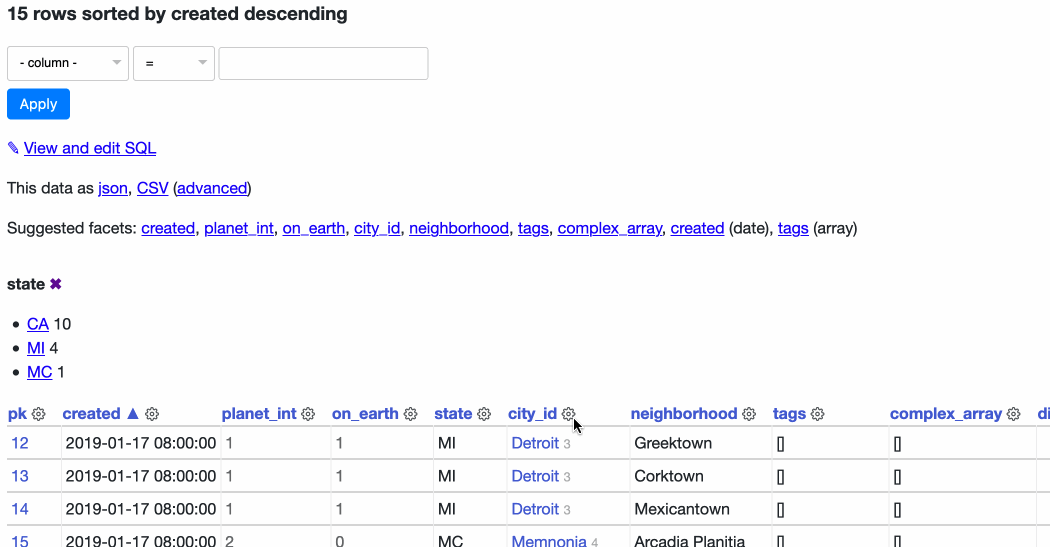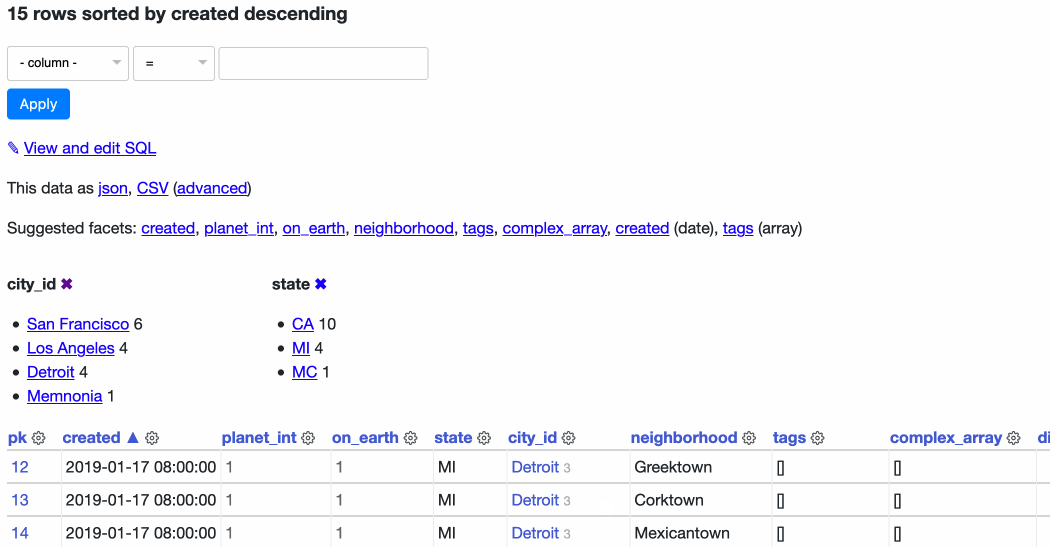
Right now the menu can be used to sort ascending, sort descending or add the column to the current set of select facets. If a column has any blank values on the current page a menu option to “Show not-blank rows” appears too—you can try that out on the sortable table.
I plan to extend this with more options in the future. I’d also like to make it a documented plugin extension point, so plugins can add their own column-specific actions. I need to figure out a JavaScript equivalent of the Python pluggy plugins mechanism first though, see issue 983.
datasette.client
Plugin authors can use the new datasette.client object to make internal HTTP requests from their plugins, allowing them to make use of Datasette’s JSON API. (#943)
In building the datasette-graphql plugin I ran into an interesting requirement. I wanted to provide efficient keyset pagination within the GraphQL schema, which is actually quite a complex things to implement.
Datasette already has a robust implementation of keyset pagination, but it’s tangled up in the implementation of the internal TableView class.
It’s not available as a documented, stable Python API... but it IS available via the Datasette JSON API.
Wouldn’t it be great if Datasette plugins could make direct calls to the same externally facing, documented HTTP JSON API that Datasette itself exposes to end users?
That’s what the new datasette.client object does. It’s a thin wrapper around HTTPX AsyncClient (the excellent new Python HTTP library which takes the Requests API and makes it fully asyncio compliant) which dispatches requests internally to Datasette’s ASGI application, without any of the network overhead of an external HTTP request.
One of my goals for Datasette 1.0 is to bring the externally facing JSON API to full, documented, stable status.
The idea of Python plugins being able to efficiently use that same API feels really elegant to me. I’m looking forward to taking advantage of this in my own plugins.
Deploying Datasette documentation
New Deploying Datasette documentation with guides for deploying Datasette on a Linux server using systemd or to hosting providers that support buildpacks. (#514, #997)
The buildpack documenation was inspired by my experiments with the new DigitialOcean App Platform this week. App Platform is a Heroku-style PaaS hosting platform that implements the Cloud Native Buildpacks standard which emerged based on Heroku’s architecture a few years ago.
I hadn’t realized quite how easy it is to run a custom Python application (such as Datasette) using buildpacks—it’s literally just a GitHub repository with two single-line files in it, requirements.txt and Procfile—the buildpacks mechanism detects the requirements.txt and configures a Python environment automatically.
I deployed my new simonw/buildpack-datasette-demo repo on DigitalOcean, Heroku and Scalingo to try this out. It worked on all three providers with no changes—and all three offer continuous deployment against GitHub where any changes to that repository automatically trigger a deployment (optionally guarded by a CI test suite).
Since I was creating a deployment documenatation page I decided to finally address issue 514 and document how I’ve used systemd to deploy Datasette on some of my own projects. I’m very keen to hear from people who try out this recipe so I can continue to improve it over time.
This is part of a series: see also the annotated release notes for Datasette 0.44, 0.45 and 0.49.