Series: Git scraping
A technique for scraping content into a Git repository to track changes to it over time.
Scraping hurricane Irma
The Irma Response project is a team of volunteers working together to make information available during and after the storm. There is a huge amount of information out there, on many different websites. The Irma API is an attempt to gather key information in one place, verify it and publish it in a reuseable way. It currently powers the irmashelters.org website.
[... 438 words]Changelogs to help understand the fires in the North Bay
The situation in the counties north of San Francisco is horrifying right now. I’ve repurposed some of the tools I built to for the Irma Response project last month to collect and track some data that might be of use to anyone trying to understand what’s happening up there. I’m sharing these now in the hope that they might prove useful.
[... 383 words]Generating a commit log for San Francisco’s official list of trees
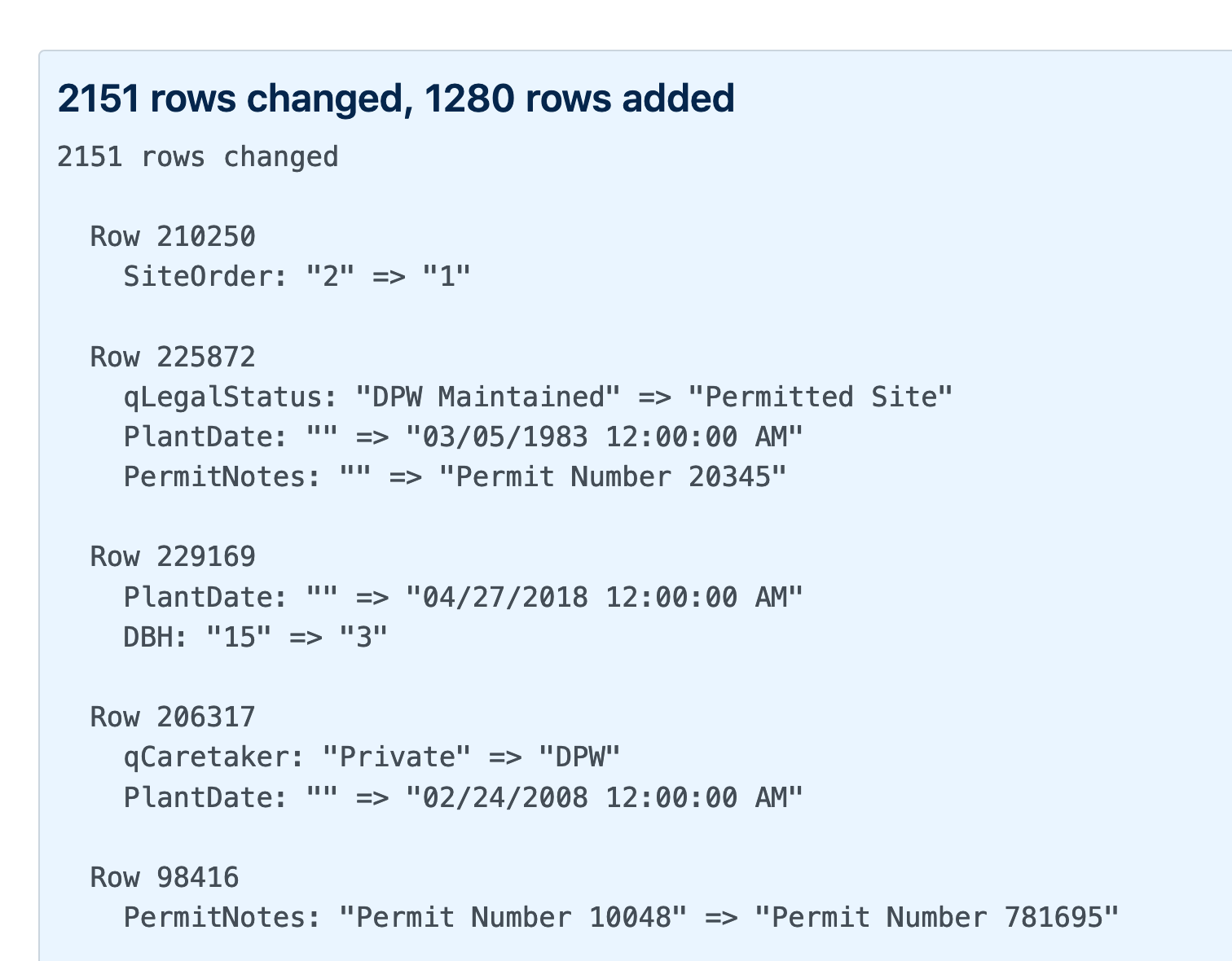
San Francisco has a neat open data portal (as do an increasingly large number of cities these days). For a few years my favourite file on there has been Street Tree List, a list of all 190,000 trees in the city maintained by the Department of Public Works.
[... 1,051 words]Tracking PG&E outages by scraping to a git repo
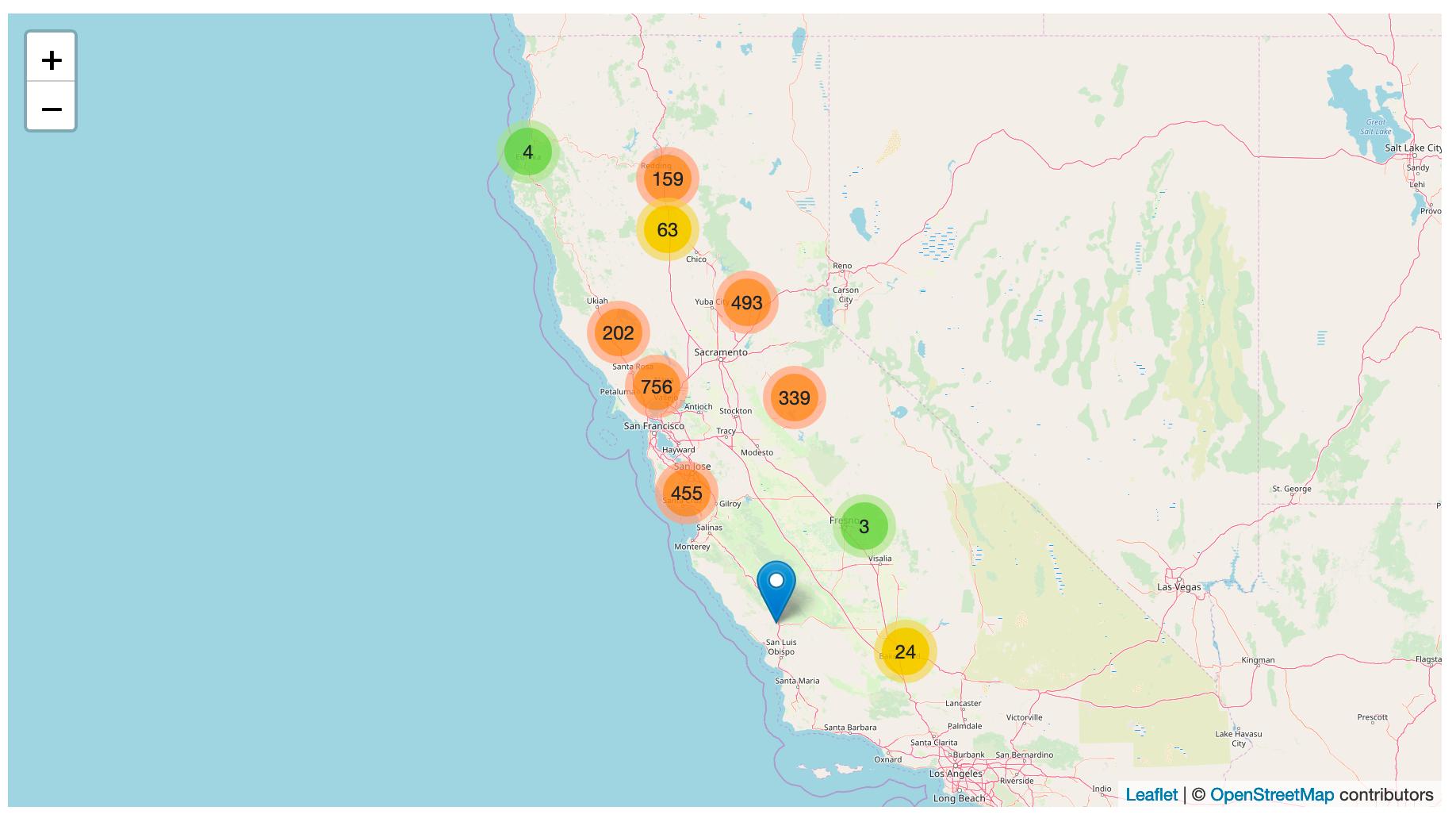
PG&E have cut off power to several million people in northern California, supposedly as a precaution against wildfires.
[... 868 words]Git scraping: track changes over time by scraping to a Git repository
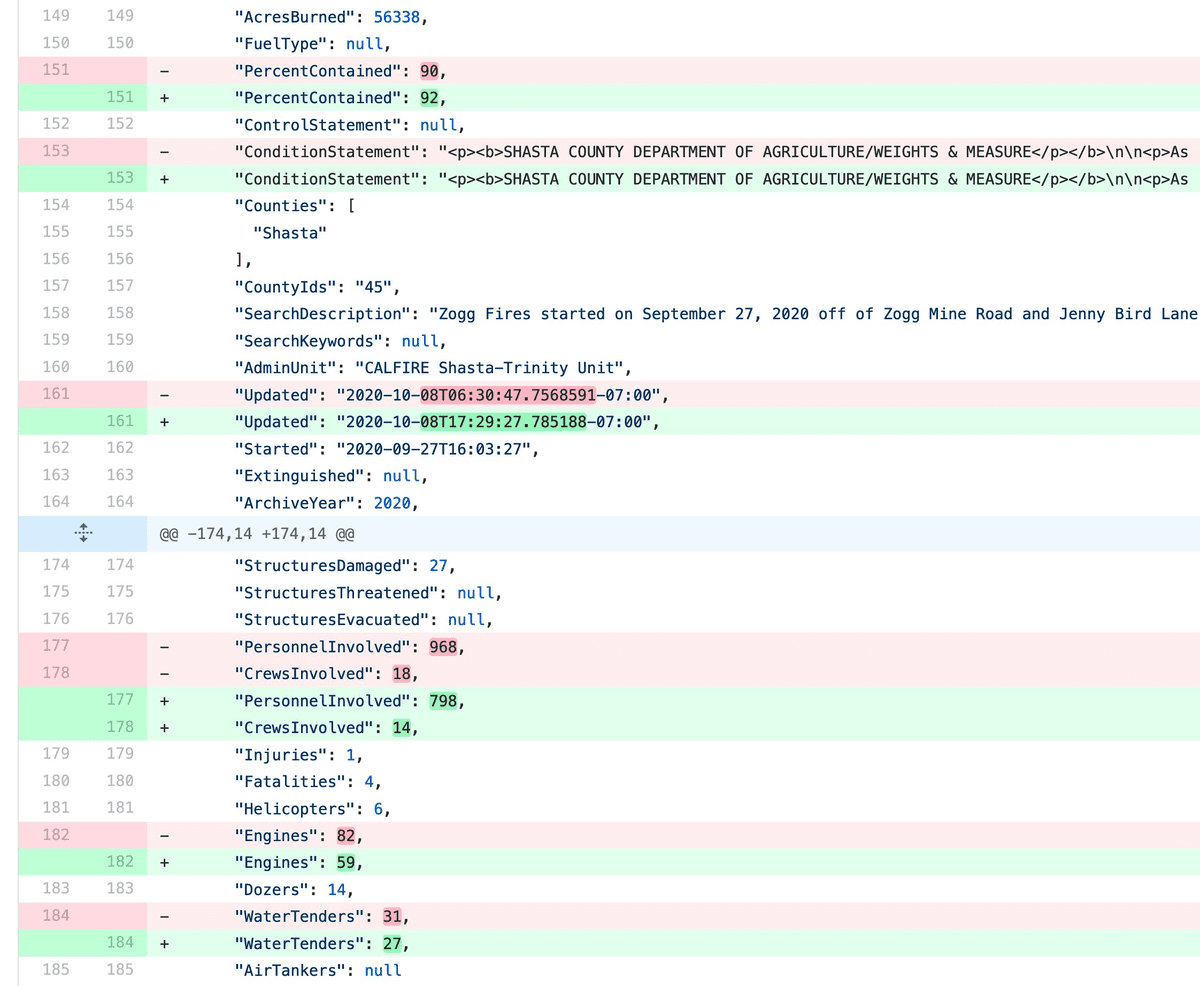
Git scraping is the name I’ve given a scraping technique that I’ve been experimenting with for a few years now. It’s really effective, and more people should use it.
[... 963 words]Git scraping, the five minute lightning talk
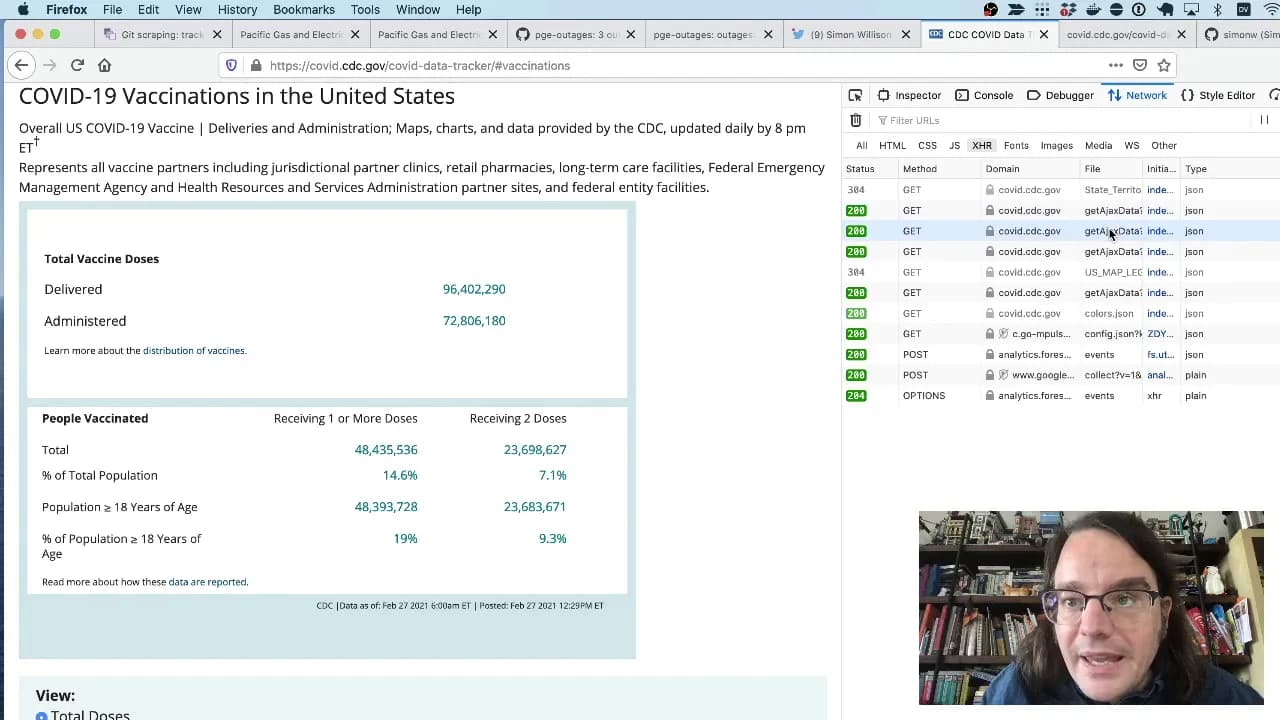
I prepared a lightning talk about Git scraping for the NICAR 2021 data journalism conference. In the talk I explain the idea of running scheduled scrapers in GitHub Actions, show some examples and then live code a new scraper for the CDC’s vaccination data using the GitHub web interface. Here’s the video.
[... 289 words]git-history: a tool for analyzing scraped data collected using Git and SQLite
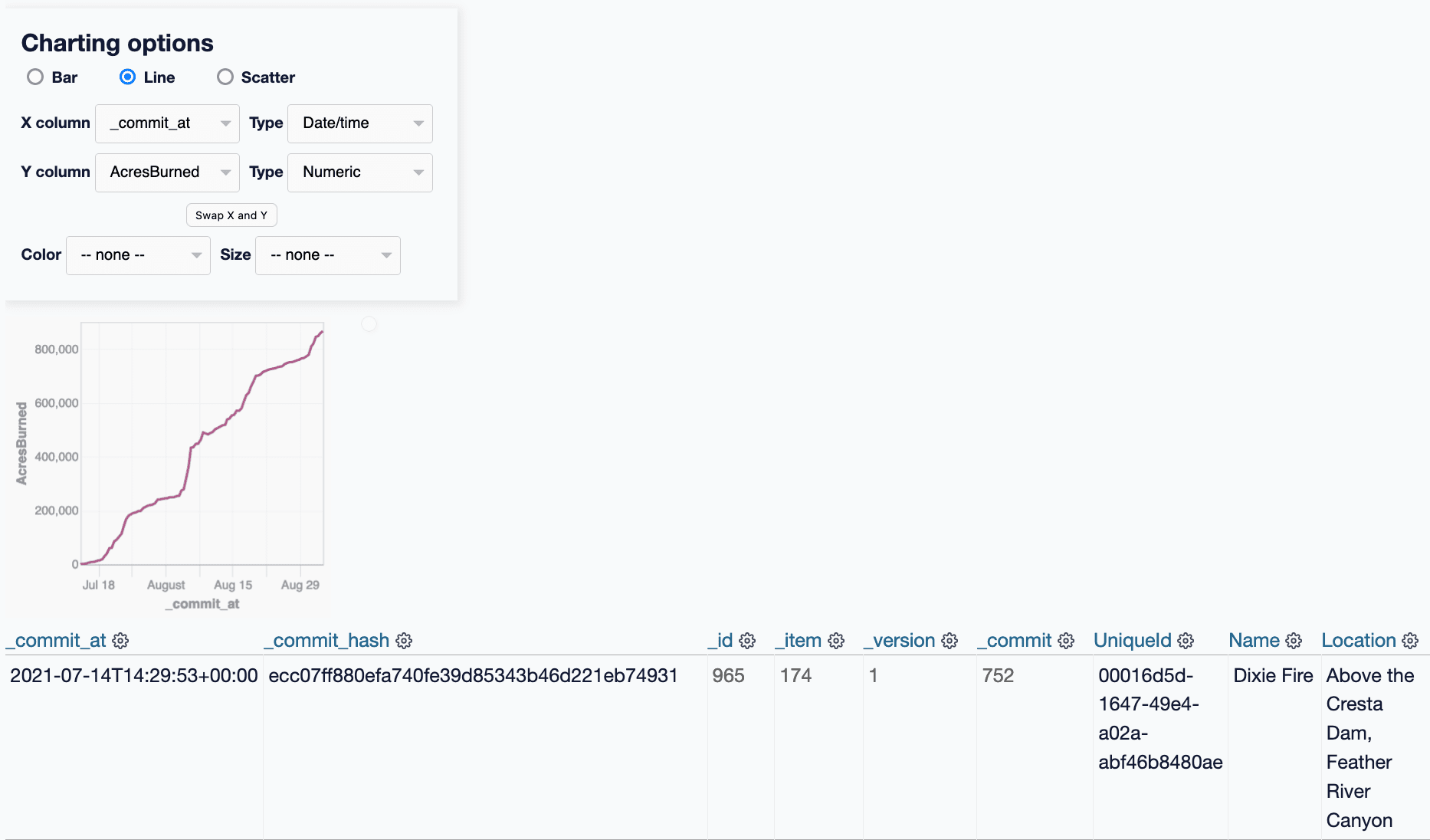
I described Git scraping last year: a technique for writing scrapers where you periodically snapshot a source of data to a Git repository in order to record changes to that source over time.
[... 2,002 words]Help scraping: track changes to CLI tools by recording their --help using Git
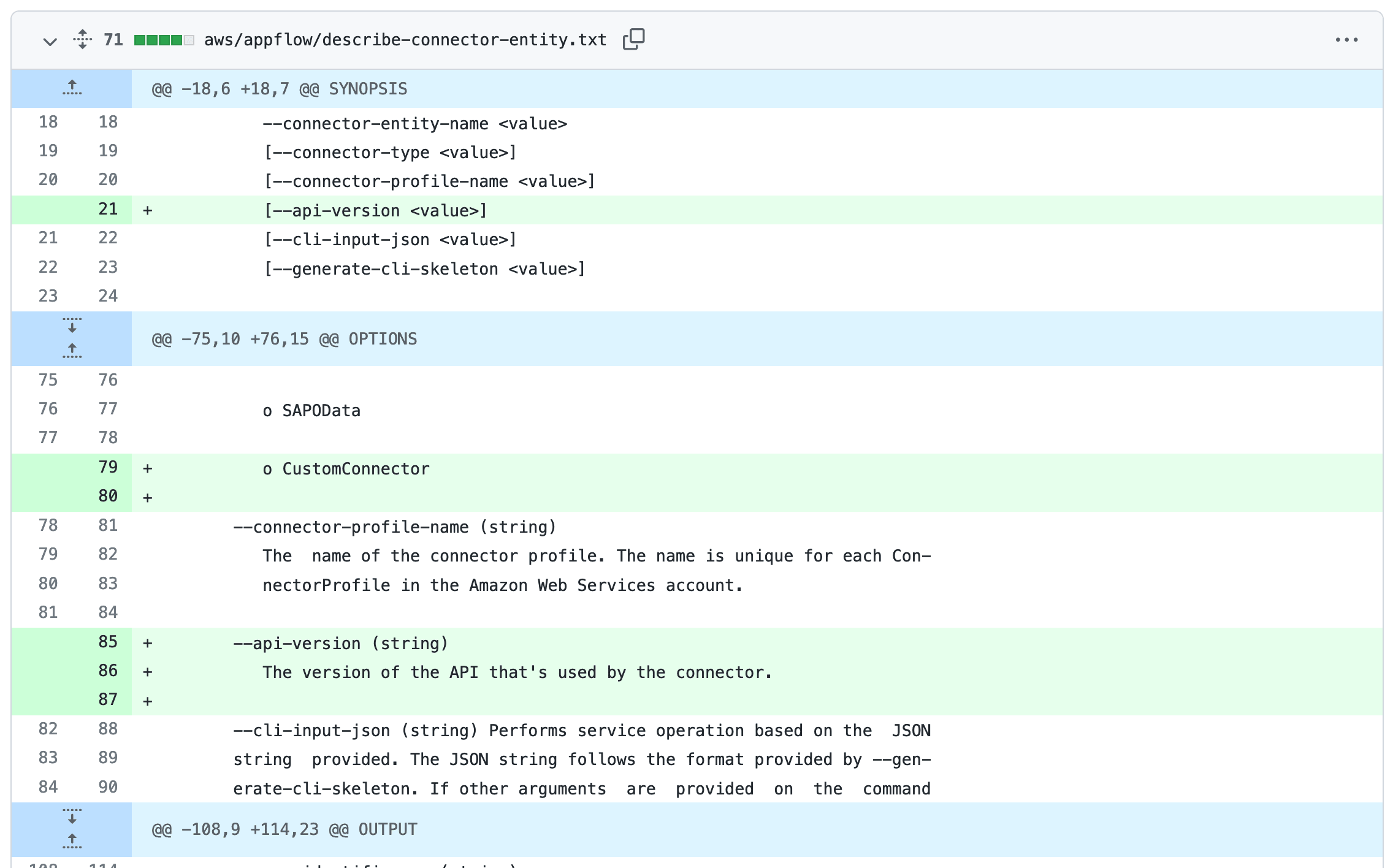
I’ve been experimenting with a new variant of Git scraping this week which I’m calling Help scraping. The key idea is to track changes made to CLI tools over time by recording the output of their --help commands in a Git repository.
shot-scraper: automated screenshots for documentation, built on Playwright
shot-scraper is a new tool that I’ve built to help automate the process of keeping screenshots up-to-date in my documentation. It also doubles as a scraping tool—hence the name—which I picked as a complement to my git scraping and help scraping techniques.
[... 1,802 words]Scraping web pages from the command line with shot-scraper
I’ve added a powerful new capability to my shot-scraper command line browser automation tool: you can now use it to load a web page in a headless browser, execute JavaScript to extract information and return that information back to the terminal as JSON.
[... 1,277 words]Automatically opening issues when tracked file content changes
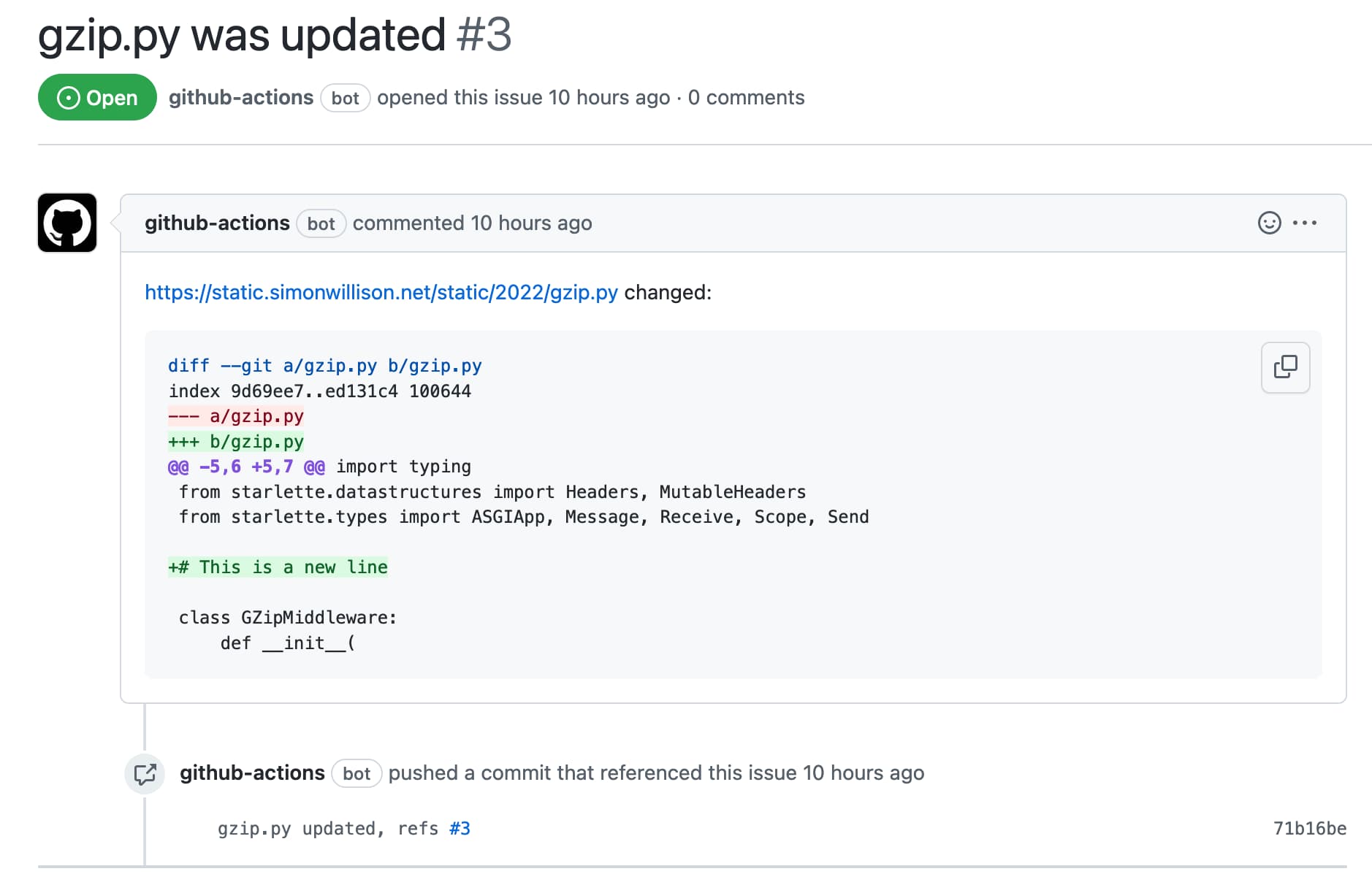
I figured out a GitHub Actions pattern to keep track of a file published somewhere on the internet and automatically open a new repository issue any time the contents of that file changes.
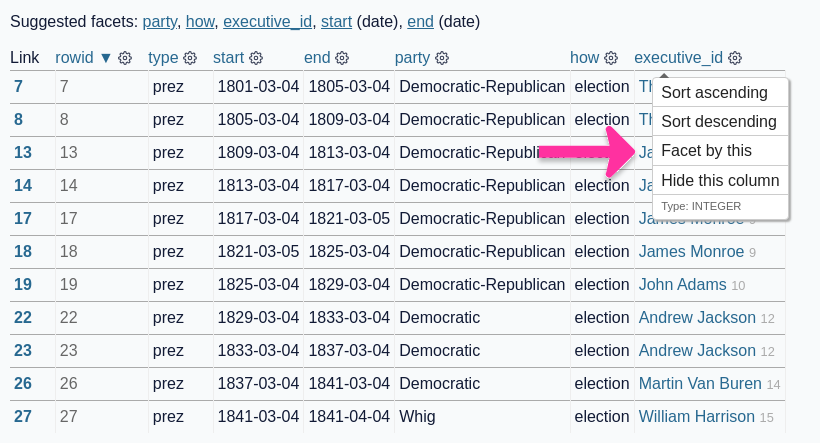
[... 1,211 words]Measuring traffic during the Half Moon Bay Pumpkin Festival
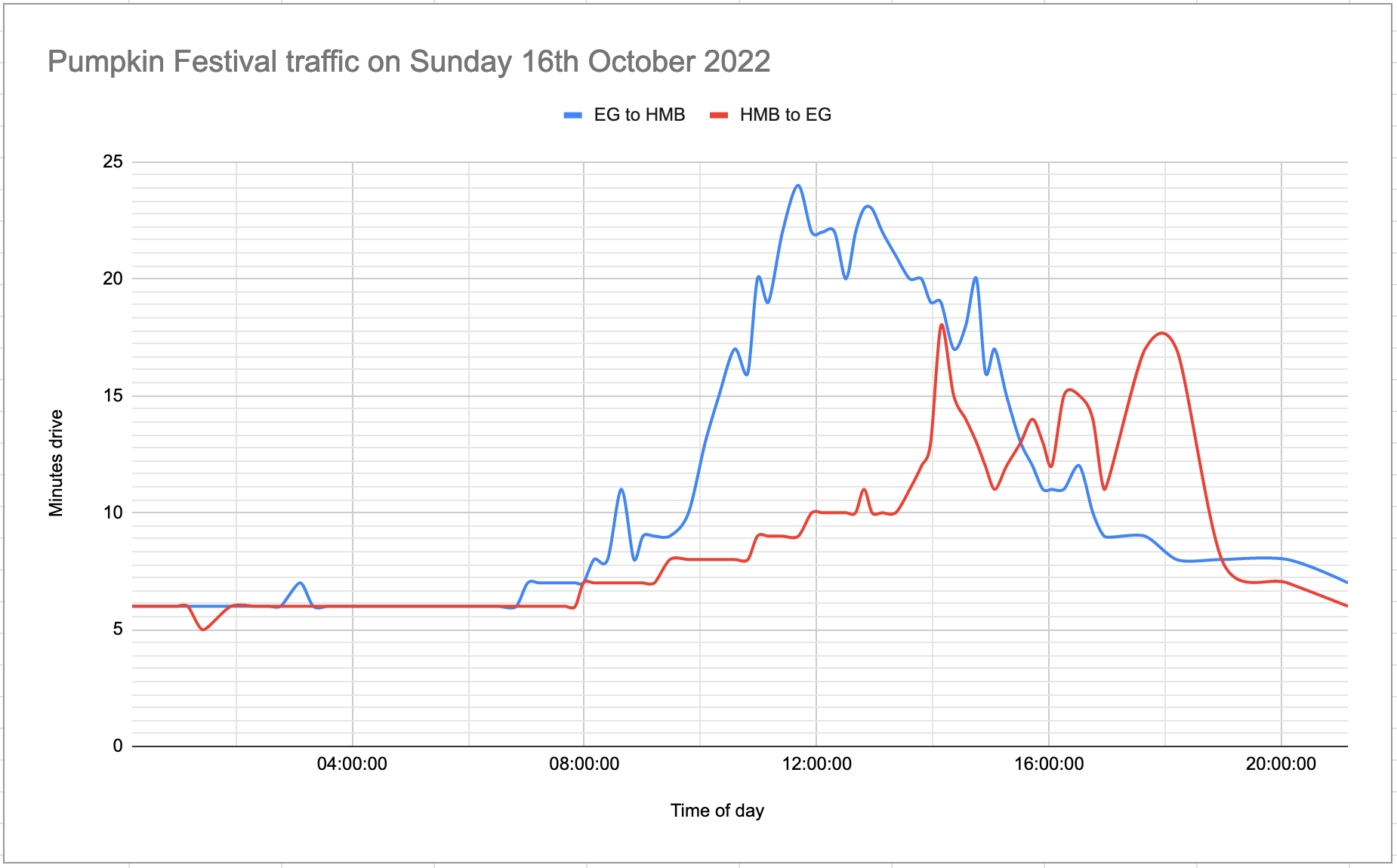
This weekend was the 50th annual Half Moon Bay Pumpkin Festival.
[... 2,693 words]Tracking Mastodon user numbers over time with a bucket of tricks
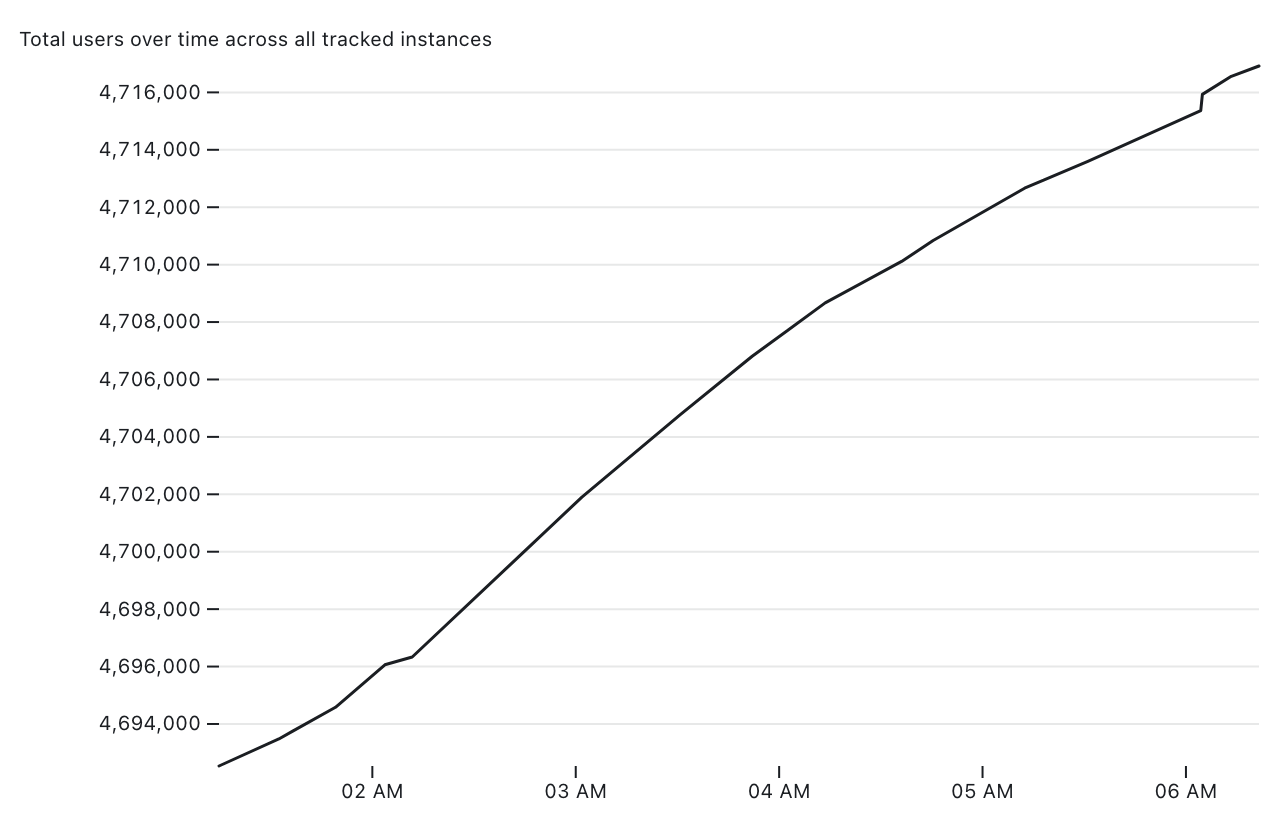
Mastodon is definitely having a moment. User growth is skyrocketing as more and more people migrate over from Twitter.
[... 1,534 words]