How to implement Q&A against your documentation with GPT3, embeddings and Datasette
13th January 2023
If you’ve spent any time with GPT-3 or ChatGPT, you’ve likely thought about how useful it would be if you could point them at a specific, current collection of text or documentation and have it use that as part of its input for answering questions.
It turns out there is a neat trick for doing exactly that. I’ve been experimenting with it using my Datasette web application as a rapid prototyping platform for trying out new AI techniques using custom SQL functions.
Here’s how to do this:
- Run a text search (or a semantic search, described later) against your documentation to find content that looks like it could be relevant to the user’s question
- Grab extracts of that content and glue them all together into a blob of text
- Construct a prompt consisting of that text followed by “Given the above content, answer the following question: ” and the user’s question
- Send the whole thing through the GPT-3 API and see what comes back
I’ve been calling this the semantic search answers pattern. Update: Since publishing this post I’ve learned that this technique is known as Retrieval-Augmented Generation or RAG, as described in this paper from May 2020. I’ve also been pointed to the Question Answering using Embeddings notebook in the OpenAI cookbook which describes this same technique.
This is a form of prompt engineering (and hence is prone to prompt injection attacks, so bear that in mind). You need to fit your overall prompt into the token limit for GPT-3, which is currently 4,000 tokens. A token is more-or-less the same thing as a word.
In this post I’ll show how I implemented this pattern using SQLite, Datasette and some custom SQL functions and tools written in Python.
First, some demos
I’ve implemented this pattern against my blog—3,000 posts going back over twenty years. I built it using some custom SQLite SQL functions that call the OpenAI APIs.
First, some examples of questions and answers I ran against my blog:
What does shot scraper do?
Shot-scraper is a command-line tool that helps automate the process of taking screenshots of web pages and scraping data from them using JavaScript. It can be used to take one-off screenshots or take multiple screenshots in a repeatable way by defining them in a YAML file. It can also be used to execute JavaScript on a page and return the resulting value.
shot-scraper is a tool I released in 2022—after the 2021 GPT-3 training cut-off date. This is a very good summary—better I think than anything I’ve written about shot-scraper myself.
What museums has Simon been to?
Simon has been to the Pitt Rivers museum, the British Museum, the Science Museum, the Natural History Museum, the V&A, the Victoria and Albert Museum, and the Pioneer Museum in Paso Robles. He has also seen the Giant Squid at the Natural History Museum and Charles Darwin’s collection at the spirit building.
This is entirely correct, though I’ve talked about a lot more museums than that on my blog.
What are some unconventional things you can do with GitHub Actions?
- Create dynamic content for GitHub repository templates using cookiecutter and GitHub Actions
- Automate repetitive tasks like code linting, testing, and deployment using GitHub Actions
- Run scheduled scrapers in GitHub Actions
- Use GitHub Actions to trigger a webhook call when a repository is forked
- Create an automated issue-tracking system with GitHub Issues and GitHub Actions
- Automatically extract captions and transcripts from online videos using Whisper and GitHub Actions.
Some of my relevant posts:
- Dynamic content for GitHub repository templates using cookiecutter and GitHub Actions
- Git scraping: track changes over time by scraping to a Git repository
- A tool to run caption extraction against online videos using Whisper and GitHub Issues/Actions
I’ve never written anything about triggering webhook calls or issue-tracking systems though, so 4 and 5 in that list are a little suspicious.
What is the big grey box at the top of the utility pole? What does it do?
The big grey box at the top of the utility pole is likely a transformer. Transformers are used to step down the voltage of electricity from the high-voltage lines that run along the pole to the lower-voltage lines that are used to provide electricity to homes and businesses.
I’m including this example because I’ve never written anything even remotely related to transformers and utility poles on my blog. This demonstrates that in the lack of useful context GPT-3 will answer the question entirely by itself—which may or may not be what you want from this system.
Try this out yourself
If you want to try this out yourself you’ll need to get your own API key from OpenAI. I don’t want to foot the bill for people using my blog as a free source of GPT-3 prompt answers!
You can sign up for one here. I believe they are still running a free trial period.
Now head over to this page:
https://datasette.simonwillison.net/simonwillisonblog/answer_question?_hide_sql=1
You’ll need to paste in your OpenAI key. I am not logging these anywhere, and the form stores these in a cookie in order to avoid transmitting it over a GET query string where it could be accidentally logged somewhere.
Then type in your question and see what comes back!
Let’s talk about how this all works—in a whole lot of detail.
Semantic search using embeddings
You can implement the first step of this sequence using any search engine you like—but there’s a catch: we are encouraging users here to ask questions, which increases the chance that they might include text in their prompt which doesn’t exactly match documents in our index.
“What are the key features of Datasette?” for example might miss blog entries that don’t include the word “feature” even though they describe functionality of the software in detail.
What we want here is semantic search—we want to find documents that match the meaning of the user’s search term, even if the matching keywords are not present.
OpenAI have a less well-known API that can help here, which had a big upgrade (and major price reduction) back in December: their embedding model.
Update 31st January 2023: I figured out how to run an alternative embeddings model that can execute entirely on my laptop, described here: Calculating embeddings with gtr-t5-large in Python.
An embedding is a list of floating point numbers.
As an example, consider a latitude/longitude location: it’s a list of two floating point numbers. You can use those numbers to find other nearby points by calculating distances between them.
Add a third number and now you can plot locations in three dimensional space—and still calculate distances between them to find the closest points.
This idea keeps on working even as we go beyond three dimensions: you can calculate distances between vectors of any length, no matter how many dimensions they have.
So if we can represent some text in a many-multi-dimensional vector space, we can calculate distances between those vectors to find the closest matches.
The OpenAI embedding model lets you take any string of text (up to a ~8,000 word length limit) and turn that into a list of 1,536 floating point numbers. We’ll call this list the “embedding” for the text.
These numbers are derived from a sophisticated language model. They take a vast amount of knowledge of human language and flatten that down to a list of floating point numbers—at 4 bytes per floating point number that’s 4*1,536 = 6,144 bytes per embedding—6KiB.
The distance between two embeddings represents how semantically similar the text is to each other.
The two most obvious applications of this are search and similarity scores.
Take a user’s search term. Calculate its embedding. Now find the distance between that embedding and every pre-calculated embedding in a corpus and return the 10 closest results.
Or for document similarity: calculate embeddings for every document in a collection, then look at each one in turn and find the closest other embeddings: those are the documents that are most similar to it.
For my semantic search answers implementation, I use an embedding-based semantic search as the first step to find the best matches for the question. I then assemble these top 5 matches into the prompt to pass to GPT-3.
Calculating embeddings
Embeddings can be calculated from text using the OpenAI embeddings API. It’s really easy to use:
curl https://api.openai.com/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{"input": "Your text string goes here",
"model":"text-embedding-ada-002"}'The documentation doesn’t mention this, but you can pass a list of strings (up to 2048 according to the official Python library source code) as "input" to run embeddings in bulk:
curl https://api.openai.com/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{"input": ["First string", "Second string", "Third string"],
"model":"text-embedding-ada-002"}'The returned data from this API looks like this:
{
"data": [
{
"embedding": [
-0.006929283495992422,
-0.005336422007530928,
...
-4.547132266452536e-05,
-0.024047505110502243
],
"index": 0,
"object": "embedding"
}
]As expected, it’s a list of 1,536 floating point numbers.
I’ve been storing embeddings as a binary string that appends all of the floating point numbers together, using their 4-byte representation.
Here are the tiny Python functions I’ve been using for doing that:
import struct def decode(blob): return struct.unpack("f" * 1536, blob) def encode(values): return struct.pack("f" * 1536, *values)
I then store them in SQLite blob columns in my database.
I wrote a custom tool for doing this, called openai-to-sqlite. I can run it like this:
openai-to-sqlite embeddings simonwillisonblog.db \
--sql 'select id, title, body from blog_entry' \
--table blog_entry_embeddingsThis concatenates together the title and body columns from that table, runs them through the OpenAI embeddings API and stores the results in a new table called blog_entry_embeddings with the following schema:
CREATE TABLE [blog_entry_embeddings] (
[id] INTEGER PRIMARY KEY,
[embedding] BLOB
)I can join this against the blog_entry table by ID later on.
Finding the closest matches
The easiest way to calculate similarity between two embedding arrays is to use cosine similarity. A simple Python function for that looks like this:
def cosine_similarity(a, b): dot_product = sum(x * y for x, y in zip(a, b)) magnitude_a = sum(x * x for x in a) ** 0.5 magnitude_b = sum(x * x for x in b) ** 0.5 return dot_product / (magnitude_a * magnitude_b)
You can brute-force find the top matches for a table by executing that comparison for every row and returning the ones with the highest score.
I added this to my datasette-openai Datasette plugin as a custom SQL function called openai_embedding_similarity(). Here’s a query that uses it:
with input as (
select
embedding
from
blog_entry_embeddings
where
id = :entry_id
),
top_n as (
select
id,
openai_embedding_similarity(
blog_entry_embeddings.embedding,
input.embedding
) as score
from
blog_entry_embeddings,
input
order by
score desc
limit
20
)
select
score,
blog_entry.id,
blog_entry.title
from
blog_entry
join top_n on blog_entry.id = top_n.idThis takes as input the ID of one of my blog entries and returns a list of the other entries, ordered by their similarity score.
Unfortunately this is pretty slow! It takes over 1.3s to run against all 3,000 embeddings in my blog.
I did some research and found that a highly regarded solutions for fast vector similarity calculations is FAISS, by Facebook AI research. It has neat Python bindings and can be installed using pip install faiss-cpu (the -gpu version requires a GPU).
FAISS works against an in-memory index. My blog’s Datasette instance uses the baked data pattern which means the entire thing is re-deployed any time the data changes—as such, I can spin up an in-memory index once on startup without needing to worry about updating the index continually as rows in the database change.
So I built another plugin to do that: datasette-faiss—which can be configured to build an in-memory FAISS index against a configured table on startup, and can then be queried using another custom SQL function.
Here’s the related entries query from above rewritten to use the FAISS index:
with input as (
select
embedding
from
blog_entry_embeddings
where
id = :entry_id
),
top_n as (
select value as id from json_each(
faiss_search(
'simonwillisonblog',
'blog_entry_embeddings',
input.embedding,
20
)
), input
)
select
blog_entry.id,
blog_entry.title
from
blog_entry
join top_n on blog_entry.id = top_n.idThis one runs in 4.8ms!
faiss_search(database_name, table_name, embedding, n) returns a JSON array of the top n IDs from the specified embeddings table, based on distance scores from the provided embedding.
The json_each() trick here is a workaround for the fact that Python’s SQLite driver doesn’t yet provide an easy way to write table-valued functions—SQL functions that return something in the shape of a table.
Instead, I use json_each() to turn the string JSON array of IDs from datasette_faiss() into a table that I can run further joins against.
Implementing semantic search with embeddings
So far we’ve just seen embeddings used for finding similar items. Let’s implement semantic search, using a user-provided query.
This is going to need an API key again, because it involves a call to OpenAI to run embeddings against the user’s search query.
Here’s the SQL query:
select
value,
blog_entry.title,
substr(blog_entry.body, 0, 500)
from
json_each(
faiss_search(
'simonwillisonblog',
'blog_entry_embeddings',
(
select
openai_embedding(:query, :_cookie_openai_api_key)
),
10
)
)
join blog_entry on value = blog_entry.id
where length(coalesce(:query, '')) > 0Try that here (with extra some cosmetic tricks.)
We’re using a new function here: openai_embedding()—which takes some text and an API key and returns an embedding for that text.
The API key comes from :_cookie_openai_api_key—this is a special Datasette mechanism called magic parameters which can read variables from cookies.
The datasette-cookies-for-magic-parameters plugin notices these and turns them into an interface for the user to populate the cookies with, decsribed earlier.
One last trick: adding where length(coalesce(:query, '')) > 0 to the query means that the query won’t run if the user hasn’t entered any text into the search box.
Constructing a prompt from semantic search query results
Getting back to our semantic search answers pattern.
We need a way to construct a prompt for GPT-3 using the results of our semantic search query.
There’s one big catch: GPT-3 has a length limit, and it’s strictly enforced. If you pass even one token over that limit you’ll get an error.
We want to use as much material from the top five search results as possible, leaving enough space for the rest of the prompt (the user’s question and our own text) and the prompt response.
I ended up solving this with another custom SQL function:
select openai_build_prompt(content, 'Context:
------------
', '
------------
Given the above context, answer the following question: ' || :question,
500
) from search_resultsThis function works as an aggregate function—it takes a table of results and returns a single string.
It takes the column to aggregate—in this case content—as the first argument. Then it takes a prefix and a suffix, which are concatenated together with the aggregated content in the middle.
The third argument is the number of tokens to allow for the response.
The function then attempts to truncate each of the input values to the maximum length that will still allow them all to be concatenated together while staying inside that 4,000 token limit.
Adding it all together
With all of the above in place, the following query is my full implementation of semantic search answers against my blog:
with query as (
select
openai_embedding(:question, :_cookie_openai_api_key) as q
),
top_n as (
select
value
from json_each(
faiss_search(
'simonwillisonblog',
'blog_entry_embeddings',
(select q from query),
5
)
)
where length(coalesce(:question, '')) > 0
),
texts as (
select 'Created: ' || created || ', Title: ' || title ||
', Body: ' || openai_strip_tags(body) as text
from blog_entry where id in (select value from top_n)
),
prompt as (
select openai_build_prompt(text, 'Context:
------------
', '
------------
Given the above context, answer the following question: ' || :question,
500
) as prompt from texts
)
select
'Response' as title,
openai_davinci(
prompt,
500,
0.7,
:_cookie_openai_api_key
) as value
from prompt
where length(coalesce(:question, '')) > 0
union all
select
'Prompt' as title,
prompt from promptAs you can see, I really like using CTEs (the with name as (...) pattern) to assemble complex queries like this.
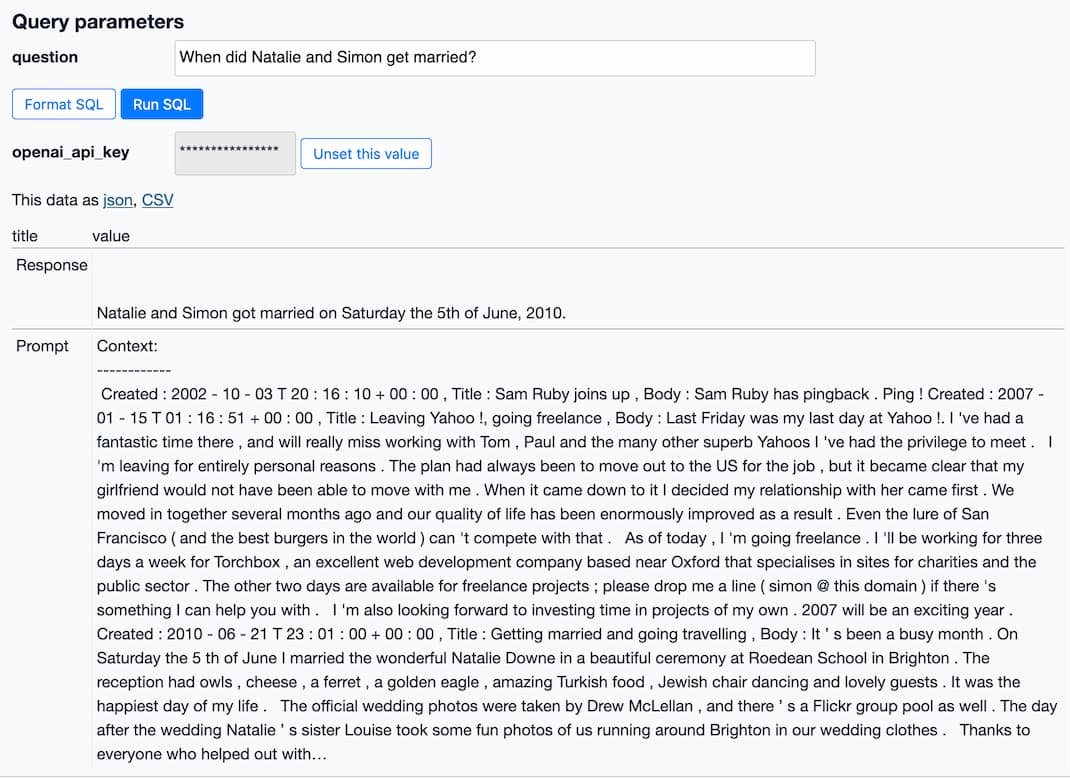
The texts as ... CTE is where I strip HTML tags from my content (using another custom function from the datasete-openai plugin called openai_strip_tags()) and assemble it along with the Created and Title metadata. Adding these gave the system a better chance of answering questions like “When did Natalie and Simon get married?” with the correct year.
The last part of this query uses a handy debugging trick: it returns two rows via a union all—the first has a Response label and shows the response from GPT-3, while the second has a Prompt label and shows the prompt that I passed to the model.
Next steps
There are so many ways to improve this system.
- Smarter prompt design. My prompt here is the first thing that I got to work—I’m certain there are all kinds of tricks that could be used to make this more effective.
- Better selection of the content to include in the prompt. I’m using embedding search but then truncating to the first portion: a smarter implementation would attempt to crop out the most relevant parts of each entry, maybe by using embeddings against smaller chunks of text.
- Yoz tipped me off to GPT Index, a project which aims to solve this exact problem by using a pre-trained LLM to help summarize text to better fit in a prompt used for these kinds of queries.
- Spotted this idea from Hassan Hayat: “don’t embed the question when searching. Ask GPT-3 to generate a fake answer, embed this answer, and use this to search”. See also this paper about Hypothetical Document Embeddings, via Jay Hack.
- Hold out for GPT-4: I’ve heard rumours that the next version of the model will have a significantly larger token limit, which should result in much better results from this mechanism.
More recent articles
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026
- The new GPT-5.6 family: Luna, Terra, Sol - 9th July 2026
- sqlite-utils 4.0, now with database schema migrations - 7th July 2026