23 posts tagged “whisper”
2025
Inspired by this conversation on Hacker News I decided to upgrade MacWhisper to try out NVIDIA Parakeet and the new Automatic Speaker Recognition feature.
It appears to work really well! Here's the result against this 39.7MB m4a file from my Gemini 3 Pro write-up this morning:
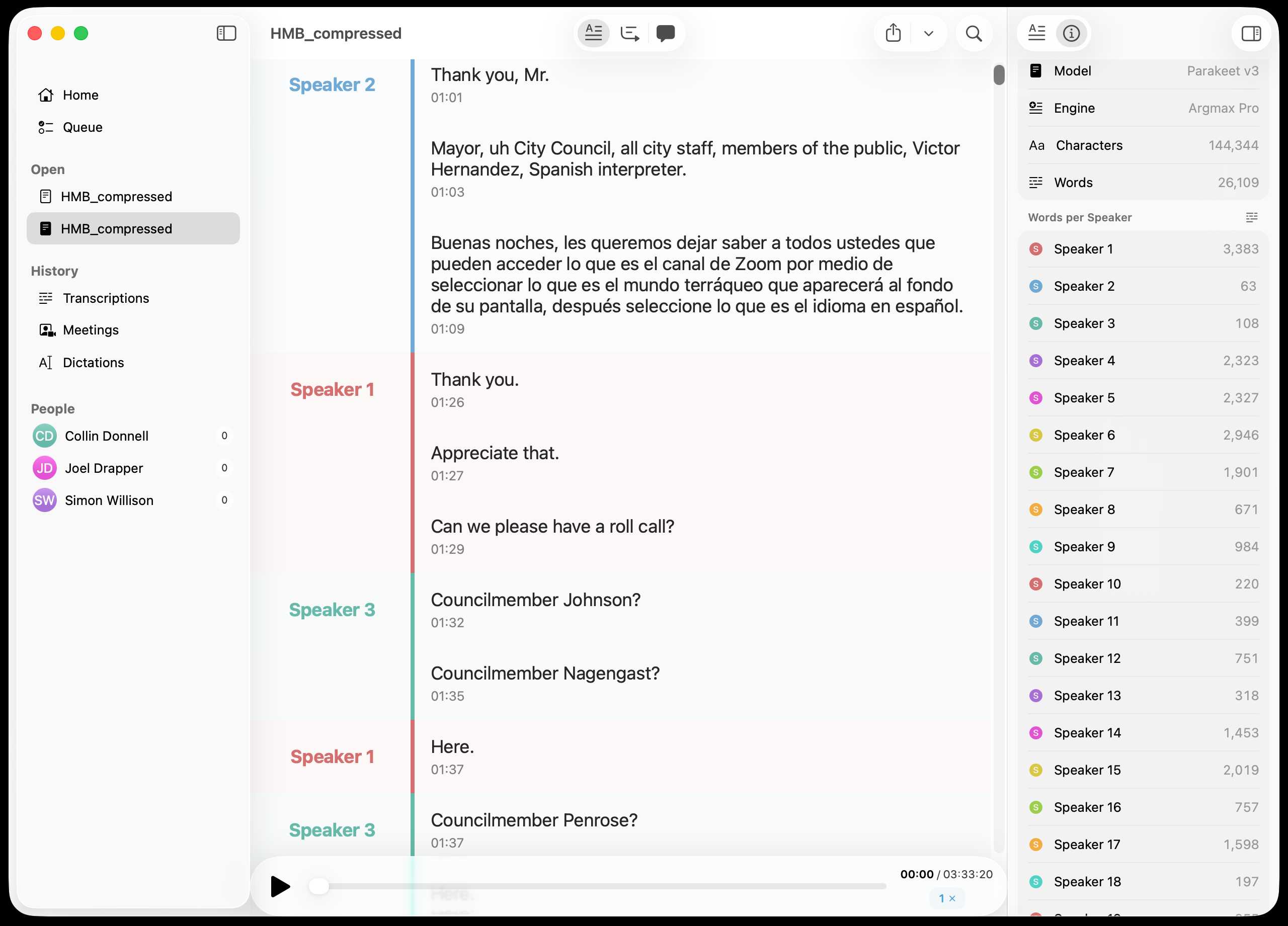
You can export the transcript with both timestamps and speaker names using the Share -> Segments > .json menu item:
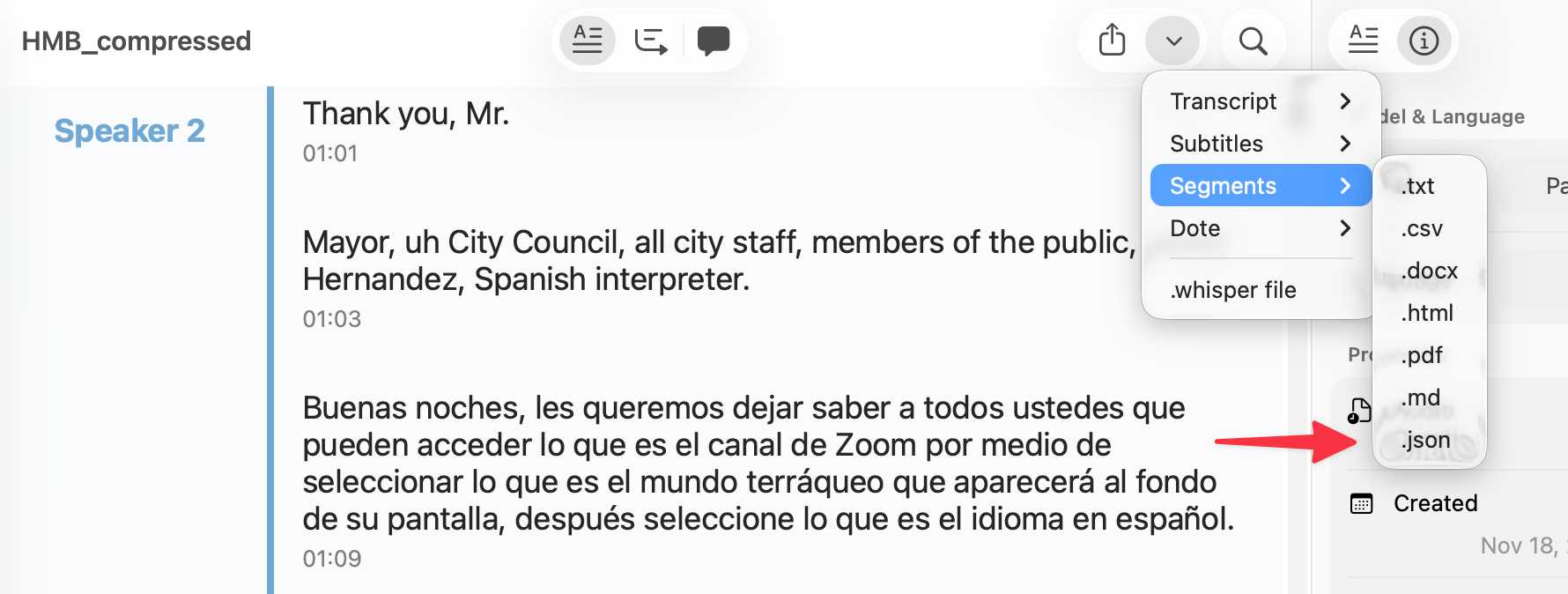
Here's the resulting JSON.
New audio models from OpenAI, but how much can we rely on them?
OpenAI announced several new audio-related API features today, for both text-to-speech and speech-to-text. They’re very promising new models, but they appear to suffer from the ever-present risk of accidental (or malicious) instruction following.
[... 866 words]TIL: Downloading every video for a TikTok account. TikTok may or may not be banned in the USA within the next 24 hours or so. I figured out a gnarly pattern for downloading every video from a specified account, using browser console JavaScript to scrape the video URLs and yt-dlp to fetch each video. As a bonus, I included a recipe for generating a Whisper transcript of every video with mlx-whisper and a hacky way to show a progress bar for the downloads.
2024
llm-whisper-api. I wanted to run an experiment through the OpenAI Whisper API this morning so I knocked up a very quick plugin for LLM that provides the following interface:
llm install llm-whisper-api
llm whisper-api myfile.mp3 > transcript.txt
It uses the API key that you previously configured using the llm keys set openai command. If you haven't configured one you can pass it as --key XXX instead.
It's a tiny plugin: the source code is here.
If we had $1,000,000…. Jacob Kaplan-Moss gave my favorite talk at DjangoCon this year, imagining what the Django Software Foundation could do if it quadrupled its annual income to $1 million and laying out a realistic path for getting there. Jacob suggests leaning more into large donors than increasing our small donor base:
It’s far easier for me to picture convincing eight or ten or fifteen large companies to make large donations than it is to picture increasing our small donor base tenfold. So I think a major donor strategy is probably the most realistic one for us.
So when I talk about major donors, who am I talking about? I’m talking about four major categories: large corporations, high net worth individuals (very wealthy people), grants from governments (e.g. the Sovereign Tech Fund run out of Germany), and private foundations (e.g. the Chan Zuckerberg Initiative, who’s given grants to the PSF in the past).
Also included: a TIL on Turning a conference talk into an annotated presentation. Jacob used my annotated presentation tool to OCR text from images of keynote slides, extracted a Whisper transcript from the YouTube livestream audio and then cleaned that up a little with LLM and Claude 3.5 Sonnet ("Split the content of this transcript up into paragraphs with logical breaks. Add newlines between each paragraph.") before editing and re-writing it all into the final post.
Whisper large-v3-turbo model. It’s OpenAI DevDay today. Last year they released a whole stack of new features, including GPT-4 vision and GPTs and their text-to-speech API, so I’m intrigued to see what they release today (I’ll be at the San Francisco event).
Looks like they got an early start on the releases, with the first new Whisper model since November 2023.
Whisper Turbo is a new speech-to-text model that fits the continued trend of distilled models getting smaller and faster while maintaining the same quality as larger models.
large-v3-turbo is 809M parameters - slightly larger than the 769M medium but significantly smaller than the 1550M large. OpenAI claim its 8x faster than large and requires 6GB of VRAM compared to 10GB for the larger model.
The model file is a 1.6GB download. OpenAI continue to make Whisper (both code and model weights) available under the MIT license.
It’s already supported in both Hugging Face transformers - live demo here - and in mlx-whisper on Apple Silicon, via Awni Hannun:
import mlx_whisper
print(mlx_whisper.transcribe(
"path/to/audio",
path_or_hf_repo="mlx-community/whisper-turbo"
)["text"])
Awni reports:
Transcribes 12 minutes in 14 seconds on an M2 Ultra (~50X faster than real time).
llamafile v0.8.13 (and whisperfile)
(via)
The latest release of llamafile (previously) adds support for Gemma 2B (pre-bundled llamafiles available here), significant performance improvements and new support for the Whisper speech-to-text model, based on whisper.cpp, Georgi Gerganov's C++ implementation of Whisper that pre-dates his work on llama.cpp.
I got whisperfile working locally by first downloading the cross-platform executable attached to the GitHub release and then grabbing a whisper-tiny.en-q5_1.bin model from Hugging Face:
wget -O whisper-tiny.en-q5_1.bin \
https://huggingface.co/ggerganov/whisper.cpp/resolve/main/ggml-tiny.en-q5_1.bin
Then I ran chmod 755 whisperfile-0.8.13 and then executed it against an example .wav file like this:
./whisperfile-0.8.13 -m whisper-tiny.en-q5_1.bin -f raven_poe_64kb.wav --no-prints
The --no-prints option suppresses the debug output, so you just get text that looks like this:
[00:00:00.000 --> 00:00:12.000] This is a LibraVox recording. All LibraVox recordings are in the public domain. For more information please visit LibraVox.org.
[00:00:12.000 --> 00:00:20.000] Today's reading The Raven by Edgar Allan Poe, read by Chris Scurringe.
[00:00:20.000 --> 00:00:40.000] Once upon a midnight dreary, while I pondered weak and weary, over many a quaint and curious volume of forgotten lore. While I nodded nearly napping, suddenly there came a tapping as of someone gently rapping, rapping at my chamber door.
There are quite a few undocumented options - to write out JSON to a file called transcript.json (example output):
./whisperfile-0.8.13 -m whisper-tiny.en-q5_1.bin -f /tmp/raven_poe_64kb.wav --no-prints --output-json --output-file transcript
I had to convert my own audio recordings to 16kHz .wav files in order to use them with whisperfile. I used ffmpeg to do this:
ffmpeg -i runthrough-26-oct-2023.wav -ar 16000 /tmp/out.wav
Then I could transcribe that like so:
./whisperfile-0.8.13 -m whisper-tiny.en-q5_1.bin -f /tmp/out.wav --no-prints
Update: Justine says:
I've just uploaded new whisperfiles to Hugging Face which use miniaudio.h to automatically resample and convert your mp3/ogg/flac/wav files to the appropriate format.
With that whisper-tiny model this took just 11s to transcribe a 10m41s audio file!
I also tried the much larger Whisper Medium model - I chose to use the 539MB ggml-medium-q5_0.bin quantized version of that from huggingface.co/ggerganov/whisper.cpp:
./whisperfile-0.8.13 -m ggml-medium-q5_0.bin -f out.wav --no-prints
This time it took 1m49s, using 761% of CPU according to Activity Monitor.
I tried adding --gpu auto to exercise the GPU on my M2 Max MacBook Pro:
./whisperfile-0.8.13 -m ggml-medium-q5_0.bin -f out.wav --no-prints --gpu auto
That used just 16.9% of CPU and 93% of GPU according to Activity Monitor, and finished in 1m08s.
I tried this with the tiny model too but the performance difference there was imperceptible.
mlx-whisper
(via)
Apple's MLX framework for running GPU-accelerated machine learning models on Apple Silicon keeps growing new examples. mlx-whisper is a Python package for running OpenAI's Whisper speech-to-text model. It's really easy to use:
pip install mlx-whisper
Then in a Python console:
>>> import mlx_whisper
>>> result = mlx_whisper.transcribe(
... "/tmp/recording.mp3",
... path_or_hf_repo="mlx-community/distil-whisper-large-v3")
.gitattributes: 100%|███████████| 1.52k/1.52k [00:00<00:00, 4.46MB/s]
config.json: 100%|██████████████| 268/268 [00:00<00:00, 843kB/s]
README.md: 100%|████████████████| 332/332 [00:00<00:00, 1.95MB/s]
Fetching 4 files: 50%|████▌ | 2/4 [00:01<00:01, 1.26it/s]
weights.npz: 63%|██████████ ▎ | 944M/1.51G [02:41<02:15, 4.17MB/s]
>>> result.keys()
dict_keys(['text', 'segments', 'language'])
>>> result['language']
'en'
>>> len(result['text'])
100105
>>> print(result['text'][:3000])
This is so exciting. I have to tell you, first of all ...Here's Activity Monitor confirming that the Python process is using the GPU for the transcription:

This example downloaded a 1.5GB model from Hugging Face and stashed it in my ~/.cache/huggingface/hub/models--mlx-community--distil-whisper-large-v3 folder.
Calling .transcribe(filepath) without the path_or_hf_repo argument uses the much smaller (74.4 MB) whisper-tiny-mlx model.
A few people asked how this compares to whisper.cpp. Bill Mill compared the two and found mlx-whisper to be about 3x faster on an M1 Max.
Update: this note from Josh Marshall:
That '3x' comparison isn't fair; completely different models. I ran a test (14" M1 Pro) with the full (non-distilled) large-v2 model quantised to 8 bit (which is my pick), and whisper.cpp was 1m vs 1m36 for mlx-whisper.
I've now done a better test, using the MLK audio, multiple runs and 2 models (distil-large-v3, large-v2-8bit)... and mlx-whisper is indeed 30-40% faster
The Zen of Python, Unix, and LLMs. Here’s the YouTube recording of my 1.5 hour conversation with Hugo Bowne-Anderson yesterday.
I fed a Whisper transcript to Google Gemini Pro 1.5 and asked it for the themes from our conversation, and it said we talked about “Python’s success and versatility, the rise and potential of LLMs, data sharing and ethics in the age of LLMs, Unix philosophy and its influence on software development and the future of programming and human-computer interaction”.
GPUs on Fly.io are available to everyone! We’ve been experimenting with GPUs on Fly for a few months for Datasette Cloud. They’re well documented and quite easy to use—any example Python code you find that uses NVIDIA CUDA stuff generally Just Works. Most interestingly of all, Fly GPUs can scale to zero—so while they cost $2.50/hr for a A100 40G (VRAM) and $3.50/hr for a A100 80G you can configure them to stop running when the machine runs out of things to do.
We’ve successfully used them to run Whisper and to experiment with running various Llama 2 LLMs as well.
To look forward to: “We are working on getting some lower-cost A10 GPUs in the next few weeks”.
Talking about Open Source LLMs on Oxide and Friends

I recorded an episode of the Oxide and Friends podcast on Monday, talking with Bryan Cantrill and Adam Leventhal about Open Source LLMs.
[... 1,995 words]2023
LLaMA voice chat, with Whisper and Siri TTS. llama.cpp author Georgi Gerganov has stitched together the LLaMA language model, the Whisper voice to text model (with his whisper.cpp library) and the macOS “say” command to create an entirely offline AI agent that he can talk to with his voice and that can speak replies straight back to him.
Large language models are having their Stable Diffusion moment
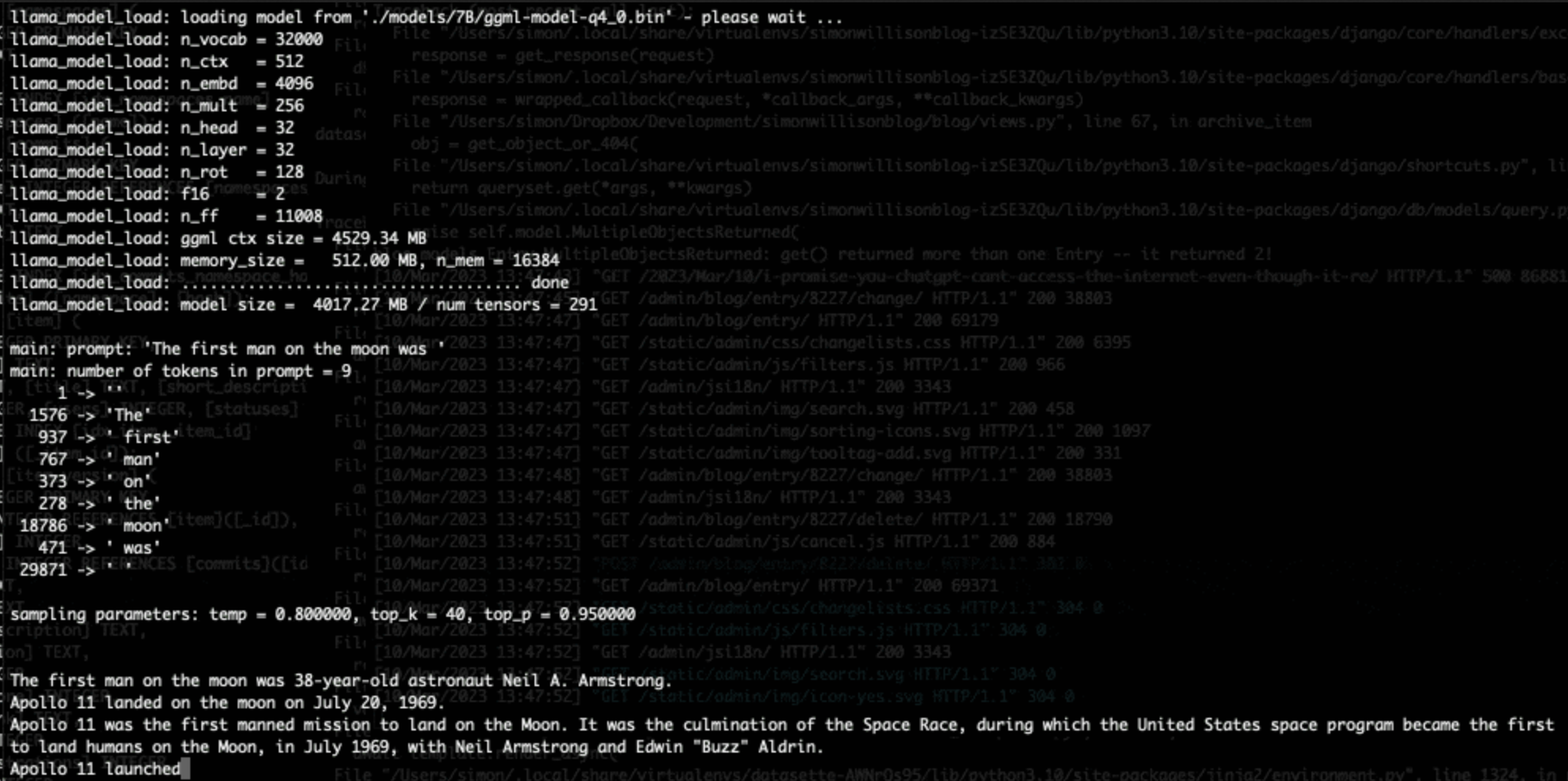
The open release of the Stable Diffusion image generation model back in August 2022 was a key moment. I wrote how Stable Diffusion is a really big deal at the time.
[... 1,815 words]Weeknotes: NICAR, and an appearance on KQED Forum
I spent most of this week at NICAR 2023, the data journalism conference hosted this year in Nashville, Tennessee.
[... 1,941 words]OpenAI: Introducing ChatGPT and Whisper APIs. The ChatGPT API is a new model called “gpt-3.5-turbo” and is priced at 1/10th of the price of text-davinci-003, previously the most powerful GPT-3 model. Whisper (speech to text transcription) is now available via an API as well, priced at 36 cents per hour of audio.
OpenAI’s Whisper is another case study in Colonisation (via) Really interesting perspective on Whisper from the Papa Reo project - a group working to nurture and proliferate the Māori language.
The main questions we ask when we see papers like FLEURS and Whisper are: where did they get their indigenous data from, who gave them access to it, and who gave them the right to create a derived work from that data and then open source the derivation?
2022
Speech-to-text with Whisper: How I Use It & Why. Sumana Harihareswara’s in-depth review of Whisper, the shockingly effective open source text-to-speech transcription model release by OpenAI a few months ago. Includes an extremely thoughtful section considering the ethics of using this model—some of the most insightful short-form writing I’ve seen on AI model ethics generally.
talk.wasm (via) “Talk with an Artificial Intelligence in your browser”. Absolutely stunning demo which loads the Whisper speech recognition model (75MB) and a GPT-2 model (240MB) and executes them both in your browser via WebAssembly, then uses the Web Speech API to talk back to you. The result is a full speak-with-an-AI interface running entirely client-side. GPT-2 sadly mostly generates gibberish but the fact that this works at all is pretty astonishing.
A tool to run caption extraction against online videos using Whisper and GitHub Issues/Actions
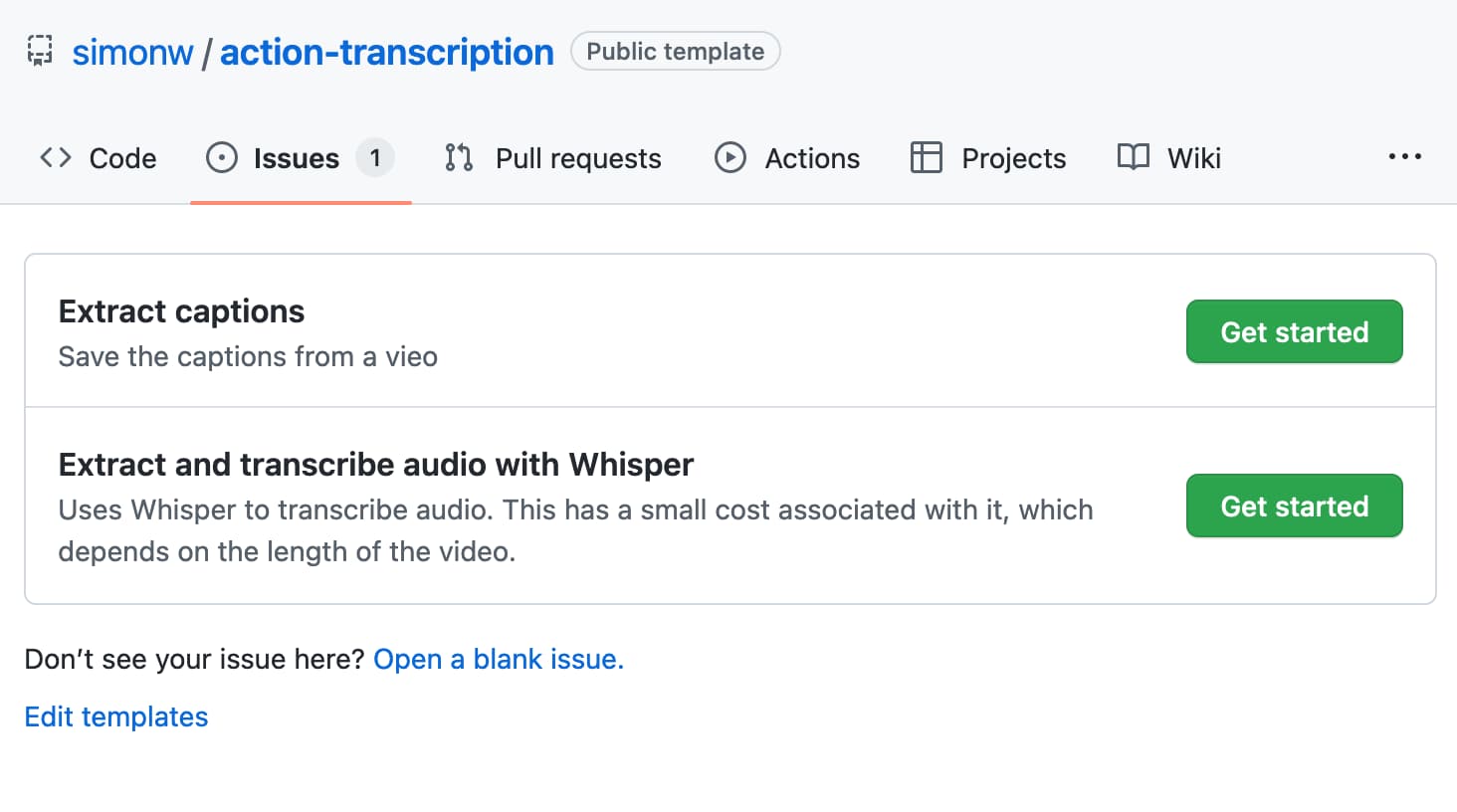
I released a new project this weekend, built during the Bellingcat Hackathon (I came second!) It’s called Action Transcription and it’s a tool for caturing captions and transcripts from online videos.
[... 1,362 words]