10 posts tagged “mlc”
2024
Structured Generation w/ SmolLM2 running in browser & WebGPU (via) Extraordinary demo by Vaibhav Srivastav (VB). Here's Hugging Face's SmolLM2-1.7B-Instruct running directly in a web browser (using WebGPU, so requires Chrome for the moment) demonstrating structured text extraction, converting a text description of an image into a structured GitHub issue defined using JSON schema.
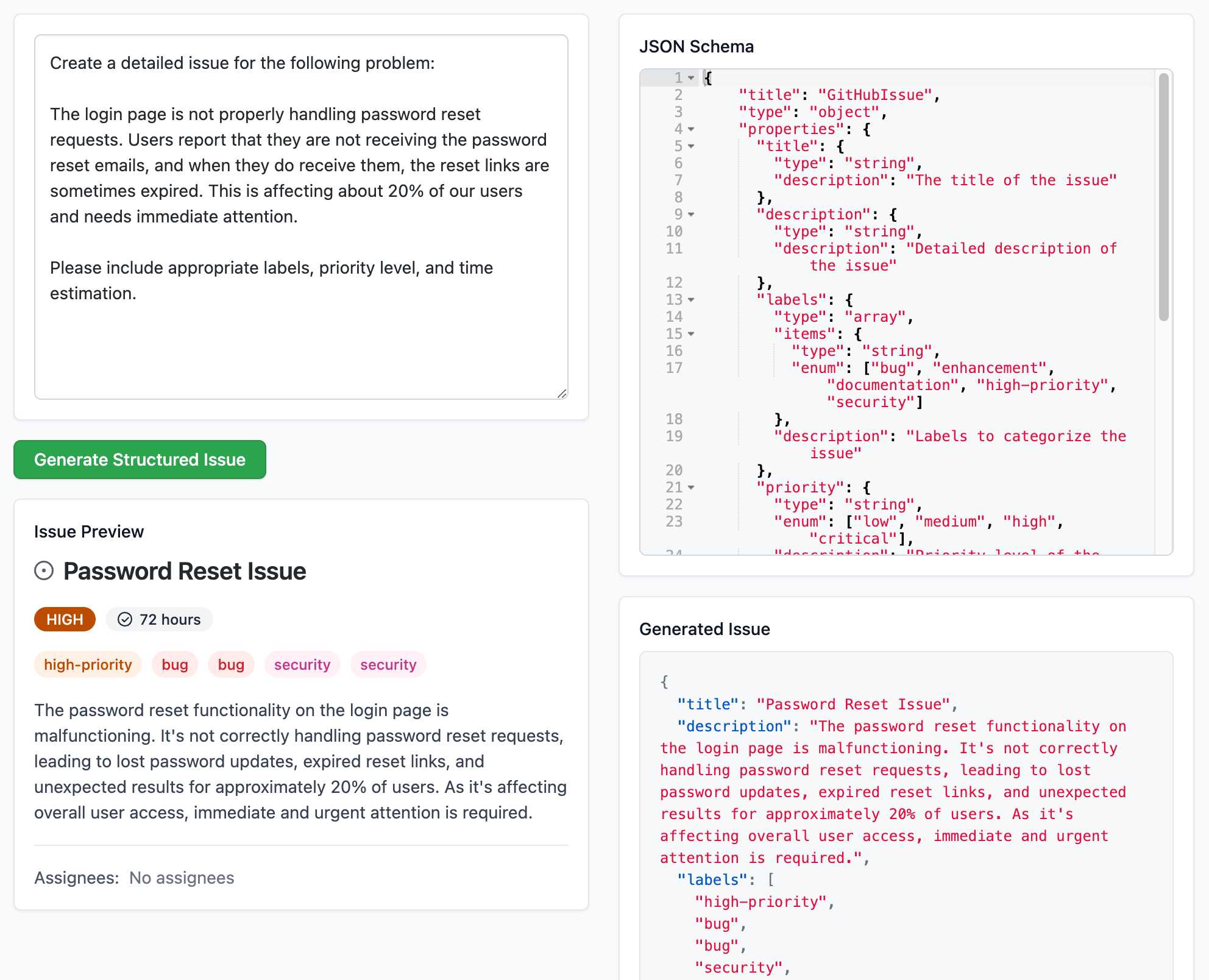
The page loads 924.8MB of model data (according to this script to sum up files in window.caches) and performs everything in-browser. I did not know a model this small could produce such useful results.
Here's the source code for the demo. It's around 200 lines of code, 50 of which are the JSON schema describing the data to be extracted.
The real secret sauce here is web-llm by MLC. This library has made loading and executing prompts through LLMs in the browser shockingly easy, and recently incorporated support for MLC's XGrammar library (also available in Python) which implements both JSON schema and EBNF-based structured output guidance.
2023
A practical guide to deploying Large Language Models Cheap, Good *and* Fast. Joel Kang’s extremely comprehensive notes on what he learned trying to run Vicuna-13B-v1.5 on an affordable cloud GPU server (a T4 at $0.615/hour). The space is in so much flux right now—Joel ended up using MLC but the best option could change any minute.
Vicuna 13B quantized to 4-bit integers needed 7.5GB of the T4’s 16GB of VRAM, and returned tokens at 20/second.
An open challenge running MLC right now is around batching and concurrency: “I did try making 3 concurrent requests to the endpoint, and while they all stream tokens back and the server doesn’t OOM, the output of all 3 streams seem to actually belong to a single prompt.”
WebLLM supports Llama 2 70B now. The WebLLM project from MLC uses WebGPU to run large language models entirely in the browser. They recently added support for Llama 2, including Llama 2 70B, the largest and most powerful model in that family.
To my astonishment, this worked! I used a M2 Mac with 64GB of RAM and Chrome Canary and it downloaded many GBs of data... but it worked, and spat out tokens at a slow but respectable rate of 3.25 tokens/second.
llm-mlc (via) My latest plugin for LLM adds support for models that use the MLC Python library—which is the first library I’ve managed to get to run Llama 2 with GPU acceleration on my M2 Mac laptop.
MLC: Bringing Open Large Language Models to Consumer Devices (via) “We bring RedPajama, a permissive open language model to WebGPU, iOS, GPUs, and various other platforms.” I managed to get this running on my Mac (see via link) with a few tweaks to their official instructions.
Let’s be bear or bunny
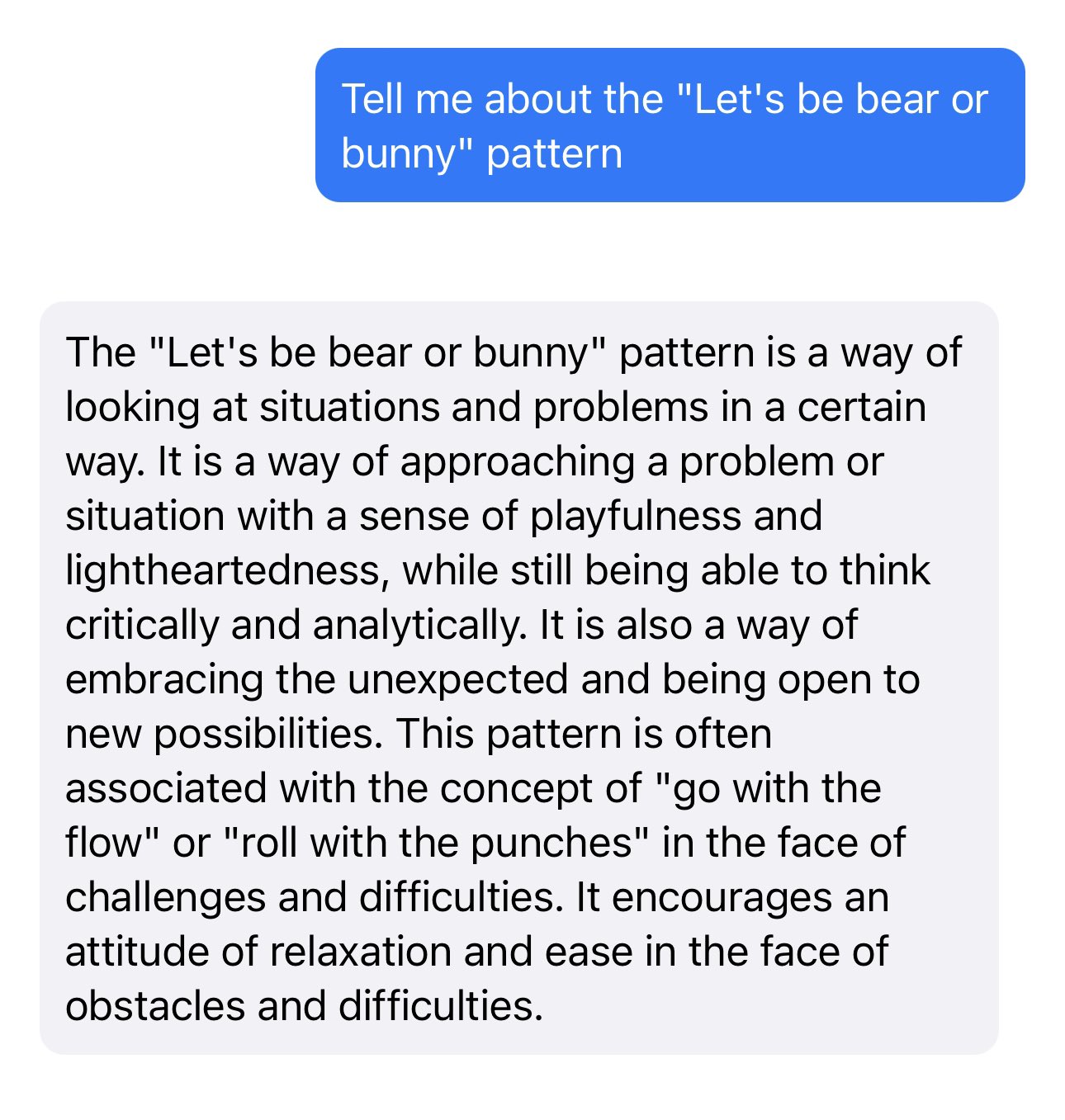
The Machine Learning Compilation group (MLC) are my favourite team of AI researchers at the moment.
[... 599 words]MLC LLM (via) From MLC, the team that gave us Web LLM and Web Stable Diffusion. “MLC LLM is a universal solution that allows any language model to be deployed natively on a diverse set of hardware backends and native applications”. I installed their iPhone demo from TestFlight this morning and it does indeed provide an offline LLM that runs on my phone. It’s reasonably capable—the underlying model for the app is vicuna-v1-7b, a LLaMA derivative.
Web LLM runs the vicuna-7b Large Language Model entirely in your browser, and it’s very impressive

A month ago I asked Could you train a ChatGPT-beating model for $85,000 and run it in a browser?. $85,000 was a hypothetical training cost for LLaMA 7B plus Stanford Alpaca. “Run it in a browser” was based on the fact that Web Stable Diffusion runs a 1.9GB Stable Diffusion model in a browser, so maybe it’s not such a big leap to run a small Large Language Model there as well.
[... 2,276 words]Could you train a ChatGPT-beating model for $85,000 and run it in a browser?
I think it’s now possible to train a large language model with similar functionality to GPT-3 for $85,000. And I think we might soon be able to run the resulting model entirely in the browser, and give it capabilities that leapfrog it ahead of ChatGPT.
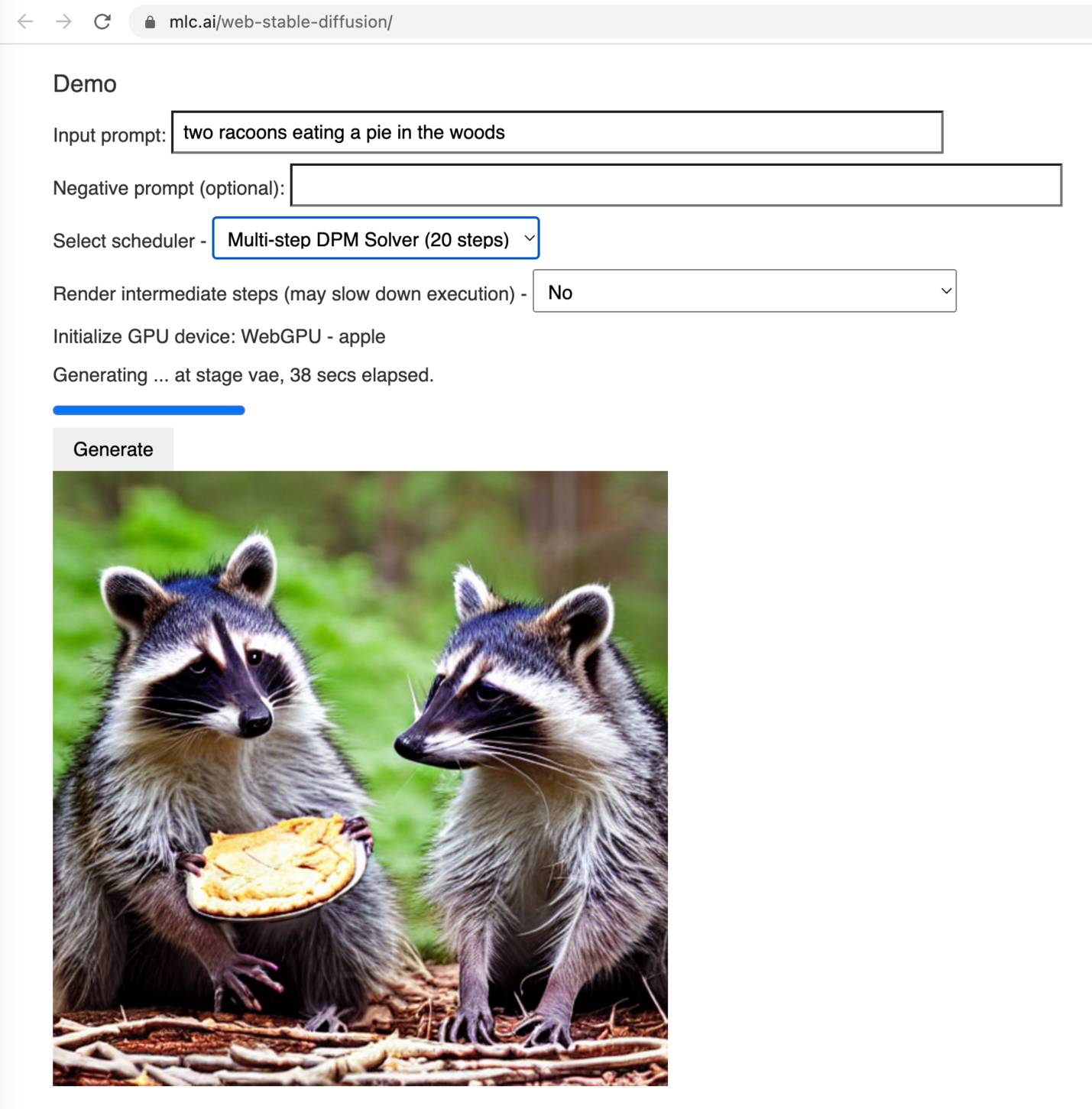
[... 1,751 words]Web Stable Diffusion (via) I just ran the full Stable Diffusion image generation model entirely in my browser, and used it to generate an image of two raccoons eating pie in the woods. I had to use Google Chrome Canary since this depends on WebGPU which still isn't fully rolled out, but it worked perfectly.