Instantly create a GitHub repository to take screenshots of a web page
14th March 2022
I just released shot-scraper-template, a GitHub repository template that helps you start taking automated screenshots of a web page by filling out a form.
shot-scraper is my command line tool for taking screenshots of web pages and scraping data from them using JavaScript.
One of its uses is to help create and maintain screenshots for documentation, making it easy to update them to include changes to the design of the underlying pages.
To make this as easy as possible, I’ve created a GitHub repository template that automates the process of setting up shot-scraper to run against a URL.
To try it out, start here:
https://github.com/simonw/shot-scraper-template/generate
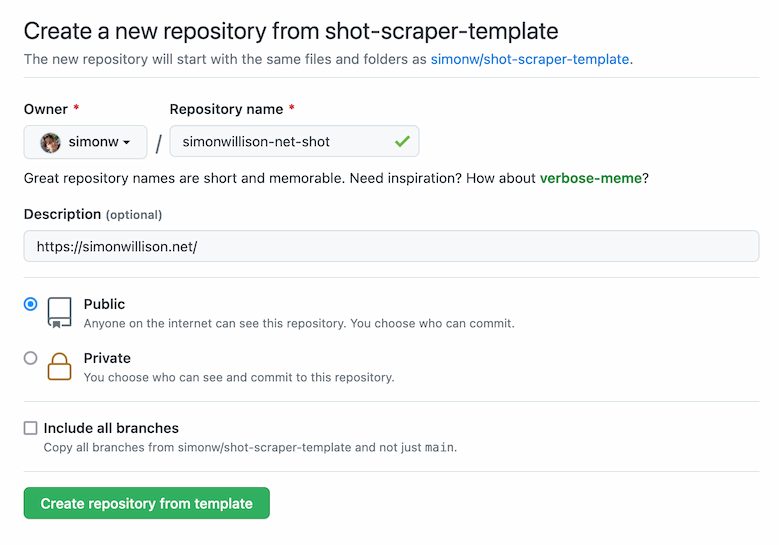
Pick a name for your new repository and paste the URL of the page you want to screenshot into the description field.
Then click “Create repository from template”.
That’s it! Your new repository will be created, a GitHub Actions automation script will run for a few seconds and your new screenshot will be added to the repository as a file called shot.png.
Here’s an example repository I created using the template: simonw/simonwillison-net-shot—and here’s the shot.png file from that repo:
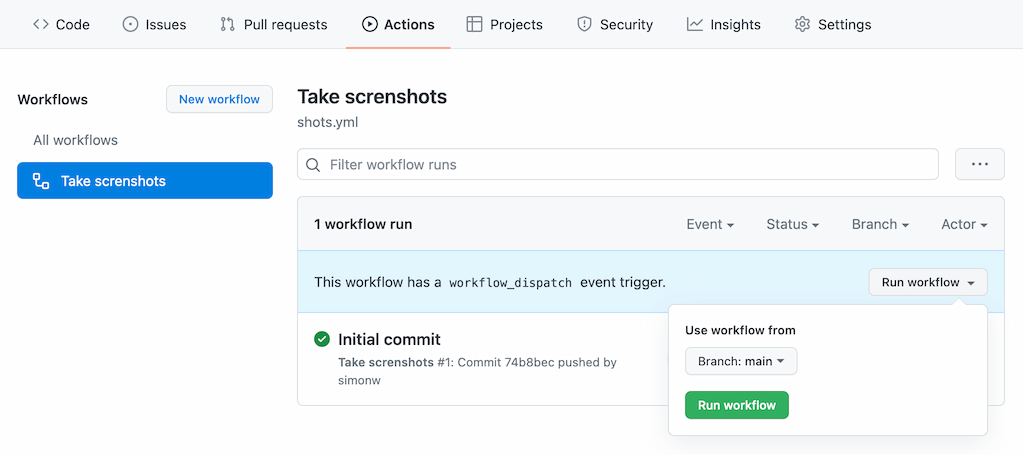
You can re-take the screenshot any time you want by clicking the “Run workflow” button in the Actions tab:
Your repository will have a file in it called shots.yml that initially looks like this:
- url: https://simonwillison.net/
output: shot.png
height: 800You can edit that file to change the settings that apply to your screenshot, or to add further URLs to take shots of like this:
- url: https://simonwillison.net/
output: shot.png
height: 800
- url: https://www.example.com/
output: example.png
height: 800Further options are available here, as described in the shot-scraper README.
How this works
This entire system is based around a single GitHub Actions workflow, in .github/workflows/shots.yml.
Here’s an annotated copy of that workflow showing how it all works.
name: Take screnshots
on:
push:
workflow_dispatch:The workflow triggers when a change is made to the repository (including edits to the shots.yml file) or when the user manually clicks “Run workflow”.
jobs:
shot-scraper:
runs-on: ubuntu-latest
if: ${{ github.repository != 'simonw/shot-scraper-template' }}This is the trick that makes everything else work, which I picked up from Bruno Rocha last year. It ensures that this workflow job only runs on copies of the template, not on the initial template repository itself.
This is necessary because a later step creates a file in the repository if it doesn’t yet exist based on the description URL provided by the user.
steps:
- uses: actions/checkout@v2
- name: Set up Python 3.10
uses: actions/setup-python@v2
with:
python-version: "3.10"
- uses: actions/cache@v2
name: Configure pip caching
with:
path: ~/.cache/pip
key: ${{ runner.os }}-pip-${{ hashFiles('requirements.txt') }}
restore-keys: |
${{ runner.os }}-pip-This is boilerplate that I use in most of my GitHub Actions workflows: it sets up Python 3.10, and also configures a cache such that Python requirements in a requirements.txt file persist from one invocation to another without having to be re-downloaded from PyPI.
- name: Cache Playwright browsers
uses: actions/cache@v2
with:
path: ~/.cache/ms-playwright/
key: ${{ runner.os }}-browsersshot-scraper uses Microsoft’s open source Playwright browser automation tool. Playwright works by installing its own full Chromium browser. This line configures a cache for that browser, such that future invocations of the Action don’t need to download another copy.
- name: Install dependencies
run: |
pip install -r requirements.txt
- name: Install Playwright dependencies
run: |
shot-scraper installThe pip install line here installs the shot-scraper CLI tool, which is written in Python.
That shot-scraper install line then triggers the Playwright mechanism to download and install the browser. This will do nothing if the browser has already been cached.
- uses: actions/github-script@v6
name: Create shots.yml if missing on first run
with:
script: |
const fs = require('fs');
if (!fs.existsSync('shots.yml')) {
const desc = context.payload.repository.description;
let line = '';
if (desc && (desc.startsWith('http://') || desc.startsWith('https://'))) {
line = `- url: ${desc}` + '\n output: shot.png\n height: 800';
} else {
line = '# - url: https://www.example.com/\n# output: shot.png\n# height: 800';
}
fs.writeFileSync('shots.yml', line + '\n');
}This is the other key piece of magic. This uses GitHub’s github-script action, which provides a Node.js environment with a context object containing details about the actions run.
It starts by reading the repository description from context.payload.repository.description.
Then it creates a shots.yml file based on that description—but only if the file does not exist already.
If there’s no repository description it creates one with a commented-out configuration instead, that looks like this:
# - url: https://www.example.com/
# output: shot.png
# height: 800The next step is to take the screenshots:
- name: Take shots
run: |
shot-scraper multi shots.ymlshot-scraper multi is documented here—it runs through the YAML file and takes each of the screenshots configured there in turn.
Final step is to commit and push the new shots.yml and shot.png files to the repository:
- name: Commit and push
run: |-
git config user.name "Automated"
git config user.email "actions@users.noreply.github.com"
git add -A
timestamp=$(date -u)
git commit -m "${timestamp}" || exit 0
git pull --rebase
git pushThis uses a pattern I describe in this TIL.
GitHub Actions as a platform
I tweeted this the other day, shortly before I came up with the idea for the shot-scraper-template repository.
Genuinely think GitHub Actions might be my favourite serverless platform right now
- Simon Willison (@simonw) March 13, 2022
This project demonstrates why. The amount of complex moving parts involved in shot-scraper-template is pretty bewildering, but the end result is a free tool that anyone can use to start taking automated screenshots.
And it doesn’t cost me anything to provide the tool either!
More recent articles
- OpenAI’s accidental cyberattack against Hugging Face is science fiction that happened - 22nd July 2026
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026