1,264 posts tagged “python”
The Python programming language.
2026
GitHub’s slopocalypse – the flood of AI-generated spam PRs and issues – has made Jazzband’s model of open membership and shared push access untenable.
Jazzband was designed for a world where the worst case was someone accidentally merging the wrong PR. In a world where only 1 in 10 AI-generated PRs meets project standards, where curl had to shut down its bug bounty because confirmation rates dropped below 5%, and where GitHub’s own response was a kill switch to disable pull requests entirely – an organization that gives push access to everyone who joins simply can’t operate safely anymore.
— Jannis Leidel, Sunsetting Jazzband
Luau is an MIT licensed "small, fast, and embeddable programming language based on Lua with a gradual type system", created by Roblox.
As part of my ongoing obsession with sandboxed runtimes I decided to see if I could get it working via WebAssembly in both Python and Pyodide.
An AI agent coding skeptic tries AI agent coding, in excessive detail. Another in the genre of "OK, coding agents got good in November" posts, this one is by Max Woolf and is very much worth your time. He describes a sequence of coding agent projects, each more ambitious than the last - starting with simple YouTube metadata scrapers and eventually evolving to this:
It would be arrogant to port Python's scikit-learn — the gold standard of data science and machine learning libraries — to Rust with all the features that implies.
But that's unironically a good idea so I decided to try and do it anyways. With the use of agents, I am now developing
rustlearn(extreme placeholder name), a Rust crate that implements not only the fast implementations of the standard machine learning algorithms such as logistic regression and k-means clustering, but also includes the fast implementations of the algorithms above: the same three step pipeline I describe above still works even with the more simple algorithms to beat scikit-learn's implementations.
Max also captures the frustration of trying to explain how good the models have got to an existing skeptical audience:
The real annoying thing about Opus 4.6/Codex 5.3 is that it’s impossible to publicly say “Opus 4.5 (and the models that came after it) are an order of magnitude better than coding LLMs released just months before it” without sounding like an AI hype booster clickbaiting, but it’s the counterintuitive truth to my personal frustration. I have been trying to break this damn model by giving it complex tasks that would take me months to do by myself despite my coding pedigree but Opus and Codex keep doing them correctly.
A throwaway remark in this post inspired me to ask Claude Code to build a Rust word cloud CLI tool, which it happily did.
I'm occasionally accused of using LLMs to write the content on my blog. I don't do that, and I don't think my writing has much of an LLM smell to it... with one notable exception:
# Finally, do em dashes s = s.replace(' - ', u'\u2014')
That code to add em dashes to my posts dates back to at least 2015 when I ported my blog from an older version of Django (in a long-lost Mercurial repository) and started afresh on GitHub.
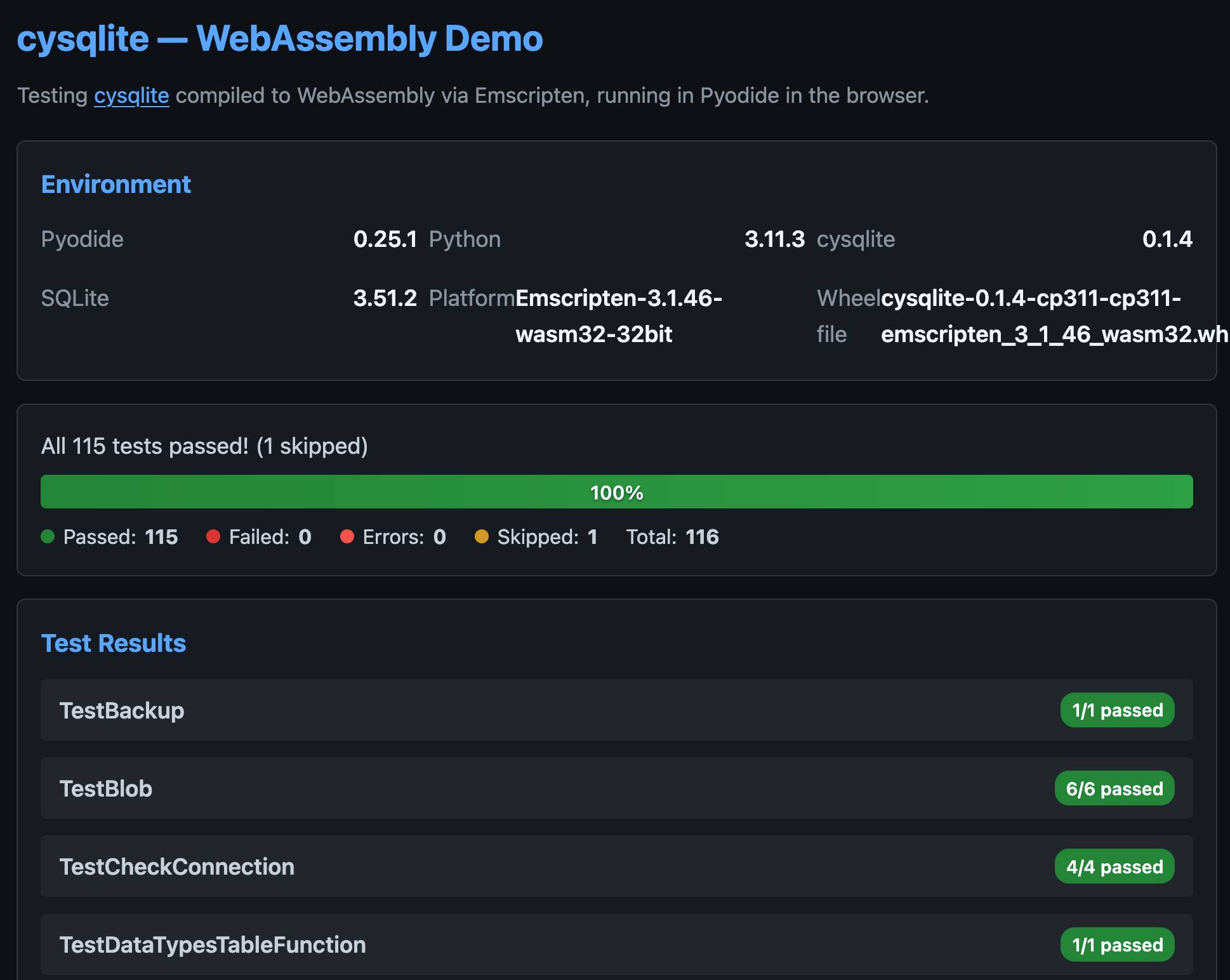
cysqlite—a new sqlite driver
(via)
Charles Leifer has been maintaining pysqlite3 - a fork of the Python standard library's sqlite3 module that makes it much easier to run upgraded SQLite versions - since 2018.
He's been working on a ground-up Cython rewrite called cysqlite for almost as long, but it's finally at a stage where it's ready for people to try out.
The biggest change from the sqlite3 module involves transactions. Charles explains his discomfort with the sqlite3 implementation at length - that library provides two different variants neither of which exactly match the autocommit mechanism in SQLite itself.
I'm particularly excited about the support for custom virtual tables, a feature I'd love to see in sqlite3 itself.
cysqlite provides a Python extension compiled from C, which means it normally wouldn't be available in Pyodide. I set Claude Code on it (here's the prompt) and it built me cysqlite-0.1.4-cp311-cp311-emscripten_3_1_46_wasm32.whl, a 688KB wheel file with a WASM build of the library that can be loaded into Pyodide like this:
import micropip await micropip.install( "https://simonw.github.io/research/cysqlite-wasm-wheel/cysqlite-0.1.4-cp311-cp311-emscripten_3_1_46_wasm32.whl" ) import cysqlite print(cysqlite.connect(":memory:").execute( "select sqlite_version()" ).fetchone())
(I also learned that wheels like this have to be built for the emscripten version used by that edition of Pyodide - my experimental wheel loads in Pyodide 0.25.1 but fails in 0.27.5 with a Wheel was built with Emscripten v3.1.46 but Pyodide was built with Emscripten v3.1.58 error.)
You can try my wheel in this new Pyodide REPL i had Claude build as a mobile-friendly alternative to Pyodide's own hosted console.
I also had Claude build this demo page that executes the original test suite in the browser and displays the results:
Running Pydantic’s Monty Rust sandboxed Python subset in WebAssembly
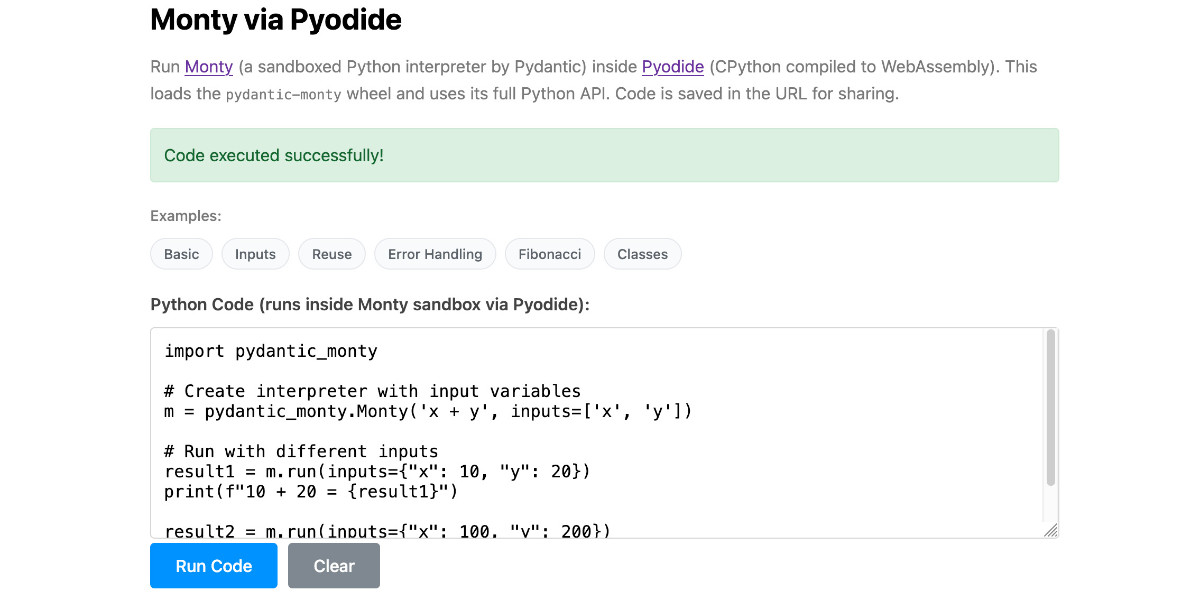
There’s a jargon-filled headline for you! Everyone’s building sandboxes for running untrusted code right now, and Pydantic’s latest attempt, Monty, provides a custom Python-like language (a subset of Python) in Rust and makes it available as both a Rust library and a Python package. I got it working in WebAssembly, providing a sandbox-in-a-sandbox.
[... 854 words]Distributing Go binaries like sqlite-scanner through PyPI using go-to-wheel
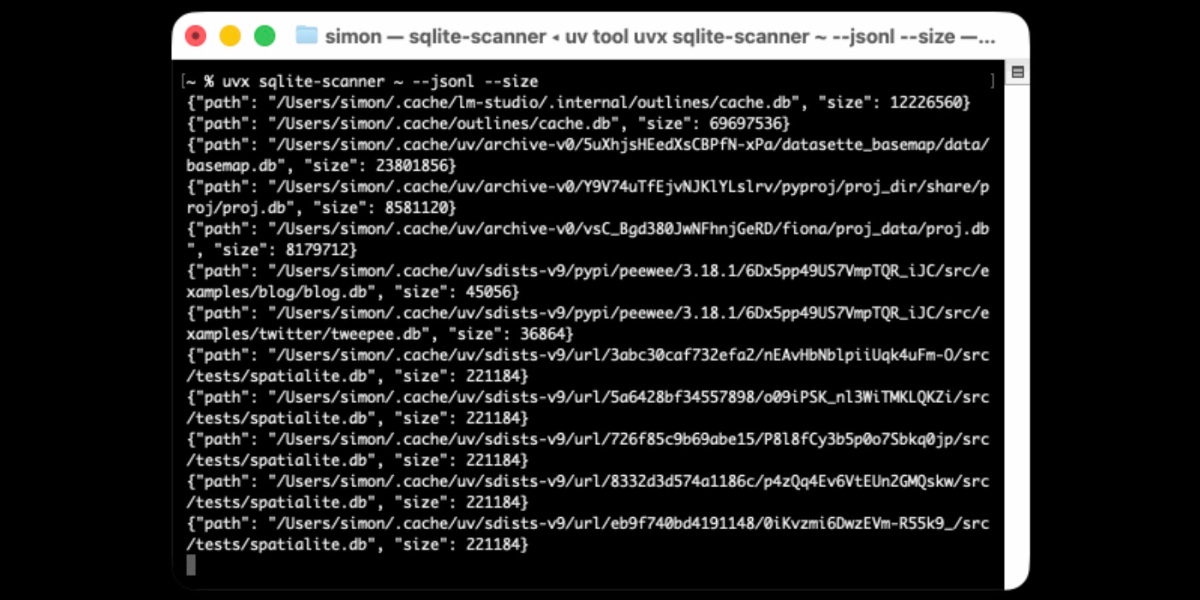
I’ve been exploring Go for building small, fast and self-contained binary applications recently. I’m enjoying how there’s generally one obvious way to do things and the resulting code is boring and readable—and something that LLMs are very competent at writing. The one catch is distribution, but it turns out publishing Go binaries to PyPI means any Go binary can be just a uvx package-name call away.
Introducing Deno Sandbox (via) Here's a new hosted sandbox product from the Deno team. It's actually unrelated to Deno itself - this is part of their Deno Deploy SaaS platform. As such, you don't even need to use JavaScript to access it - you can create and execute code in a hosted sandbox using their deno-sandbox Python library like this:
export DENO_DEPLOY_TOKEN="... API token ..."
uv run --with deno-sandbox pythonThen:
from deno_sandbox import DenoDeploy sdk = DenoDeploy() with sdk.sandbox.create() as sb: # Run a shell command process = sb.spawn( "echo", args=["Hello from the sandbox!"] ) process.wait() # Write and read files sb.fs.write_text_file( "/tmp/example.txt", "Hello, World!" ) print(sb.fs.read_text_file( "/tmp/example.txt" ))
There’s a JavaScript client library as well. The underlying API isn’t documented yet but appears to use WebSockets.
There’s a lot to like about this system. Sandboxe instances can have up to 4GB of RAM, get 2 vCPUs, 10GB of ephemeral storage, can mount persistent volumes and can use snapshots to boot pre-configured custom images quickly. Sessions can last up to 30 minutes and are billed by CPU time, GB-h of memory and volume storage usage.
When you create a sandbox you can configure network domains it’s allowed to access.
My favorite feature is the way it handles API secrets.
with sdk.sandboxes.create( allowNet=["api.openai.com"], secrets={ "OPENAI_API_KEY": { "hosts": ["api.openai.com"], "value": os.environ.get("OPENAI_API_KEY"), } }, ) as sandbox: # ... $OPENAI_API_KEY is available
Within the container that $OPENAI_API_KEY value is set to something like this:
DENO_SECRET_PLACEHOLDER_b14043a2f578cba...
Outbound API calls to api.openai.com run through a proxy which is aware of those placeholders and replaces them with the original secret.
In this way the secret itself is not available to code within the sandbox, which limits the ability for malicious code (e.g. from a prompt injection) to exfiltrate those secrets.
From a comment on Hacker News I learned that Fly have a project called tokenizer that implements the same pattern. Adding this to my list of tricks to use with sandoxed environments!
I wanted a Python library that could parse SQLite SELECT statements, so I vibe coded this one up based on a specification I reverse-engineered from SQLite's own parser behavior.
There's an interactive playground here for trying it out in the browser (via Pyodide).
Datasette 1.0a24. New Datasette alpha this morning. Key new features:
- Datasette's
Requestobject can now handlemultipart/form-datafile uploads via the new await request.form(files=True) method. I plan to use this for adatasette-filesplugin to support attaching files to rows of data. - The recommended development environment for hacking on Datasette itself now uses uv. Crucially, you can clone Datasette and run
uv run pytestto run the tests without needing to manually create a virtual environment or install dependencies first, thanks to the dev dependency group pattern. - A new
?_extra=render_cellparameter for both table and row JSON pages to return the results of executing the render_cell() plugin hook. This should unlock new JavaScript UI features in the future.
More details in the release notes. I also invested a bunch of work in eliminating flaky tests that were intermittently failing in CI - I think those are all handled now.
Someone asked on Hacker News if I had any tips for getting coding agents to write decent quality tests. Here's what I said:
I work in Python which helps a lot because there are a TON of good examples of pytest tests floating around in the training data, including things like usage of fixture libraries for mocking external HTTP APIs and snapshot testing and other neat patterns.
Or I can say "use pytest-httpx to mock the endpoints" and Claude knows what I mean.
Keeping an eye on the tests is important. The most common anti-pattern I see is large amounts of duplicated test setup code - which isn't a huge deal, I'm much more more tolerant of duplicated logic in tests than I am in implementation, but it's still worth pushing back on.
"Refactor those tests to use pytest.mark.parametrize" and "extract the common setup into a pytest fixture" work really well there.
Generally though the best way to get good tests out of a coding agent is to make sure it's working in a project with an existing test suite that uses good patterns. Coding agents pick the existing patterns up without needing any extra prompting at all.
I find that once a project has clean basic tests the new tests added by the agents tend to match them in quality. It's similar to how working on large projects with a team of other developers work - keeping the code clean means when people look for examples of how to write a test they'll be pointed in the right direction.
One last tip I use a lot is this:
Clone datasette/datasette-enrichments
from GitHub to /tmp and imitate the
testing patterns it uses
I do this all the time with different existing projects I've written - the quickest way to show an agent how you like something to be done is to have it look at an example.
Anthropic invests $1.5 million in the Python Software Foundation and open source security. This is outstanding news, especially given our decision to withdraw from that NSF grant application back in October.
We are thrilled to announce that Anthropic has entered into a two-year partnership with the Python Software Foundation (PSF) to contribute a landmark total of $1.5 million to support the foundation’s work, with an emphasis on Python ecosystem security. This investment will enable the PSF to make crucial security advances to CPython and the Python Package Index (PyPI) benefiting all users, and it will also sustain the foundation’s core work supporting the Python language, ecosystem, and global community.
Note that while security is a focus these funds will also support other aspects of the PSF's work:
Anthropic’s support will also go towards the PSF’s core work, including the Developer in Residence program driving contributions to CPython, community support through grants and other programs, running core infrastructure such as PyPI, and more.
Also note that the python visualizer tool has been basically written by vibe-coding. I know more about analog filters -- and that's not saying much -- than I do about python. It started out as my typical "google and do the monkey-see-monkey-do" kind of programming, but then I cut out the middle-man -- me -- and just used Google Antigravity to do the audio sample visualizer.
— Linus Torvalds, Another silly guitar-pedal-related repo
2025
How uv got so fast.
Andrew Nesbitt provides an insightful teardown of why uv is so much faster than pip. It's not nearly as simple as just "they rewrote it in Rust" - uv gets to skip a huge amount of Python packaging history (which pip needs to implement for backwards compatibility) and benefits enormously from work over recent years that makes it possible to resolve dependencies across most packages without having to execute the code in setup.py using a Python interpreter.
Two notes that caught my eye that I hadn't understood before:
HTTP range requests for metadata. Wheel files are zip archives, and zip archives put their file listing at the end. uv tries PEP 658 metadata first, falls back to HTTP range requests for the zip central directory, then full wheel download, then building from source. Each step is slower and riskier. The design makes the fast path cover 99% of cases. None of this requires Rust.
[...]
Compact version representation. uv packs versions into u64 integers where possible, making comparison and hashing fast. Over 90% of versions fit in one u64. This is micro-optimization that compounds across millions of comparisons.
I wanted to learn more about these tricks, so I fired up an asynchronous research task and told it to checkout the astral-sh/uv repo, find the Rust code for both of those features and try porting it to Python to help me understand how it works.
Here's the report that it wrote for me, the prompts I used and the Claude Code transcript.
You can try the script it wrote for extracting metadata from a wheel using HTTP range requests like this:
uv run --with httpx https://raw.githubusercontent.com/simonw/research/refs/heads/main/http-range-wheel-metadata/wheel_metadata.py https://files.pythonhosted.org/packages/8b/04/ef95b67e1ff59c080b2effd1a9a96984d6953f667c91dfe9d77c838fc956/playwright-1.57.0-py3-none-macosx_11_0_arm64.whl -v
The Playwright wheel there is ~40MB. Adding -v at the end causes the script to spit out verbose details of how it fetched the data - which looks like this.
Key extract from that output:
[1] HEAD request to get file size...
File size: 40,775,575 bytes
[2] Fetching last 16,384 bytes (EOCD + central directory)...
Received 16,384 bytes
[3] Parsed EOCD:
Central directory offset: 40,731,572
Central directory size: 43,981
Total entries: 453
[4] Fetching complete central directory...
...
[6] Found METADATA: playwright-1.57.0.dist-info/METADATA
Offset: 40,706,744
Compressed size: 1,286
Compression method: 8
[7] Fetching METADATA content (2,376 bytes)...
[8] Decompressed METADATA: 3,453 bytes
Total bytes fetched: 18,760 / 40,775,575 (100.0% savings)
The section of the report on compact version representation is interesting too. Here's how it illustrates sorting version numbers correctly based on their custom u64 representation:
Sorted order (by integer comparison of packed u64):
1.0.0a1 (repr=0x0001000000200001)
1.0.0b1 (repr=0x0001000000300001)
1.0.0rc1 (repr=0x0001000000400001)
1.0.0 (repr=0x0001000000500000)
1.0.0.post1 (repr=0x0001000000700001)
1.0.1 (repr=0x0001000100500000)
2.0.0.dev1 (repr=0x0002000000100001)
2.0.0 (repr=0x0002000000500000)
uv-init-demos.
uv has a useful uv init command for setting up new Python projects, but it comes with a bunch of different options like --app and --package and --lib and I wasn't sure how they differed.
So I created this GitHub repository which demonstrates all of those options, generated using this update-projects.sh script (thanks, Claude) which will run on a schedule via GitHub Actions to capture any changes made by future releases of uv.
MicroQuickJS. New project from programming legend Fabrice Bellard, of ffmpeg and QEMU and QuickJS and so much more fame:
MicroQuickJS (aka. MQuickJS) is a Javascript engine targetted at embedded systems. It compiles and runs Javascript programs with as low as 10 kB of RAM. The whole engine requires about 100 kB of ROM (ARM Thumb-2 code) including the C library. The speed is comparable to QuickJS.
It supports a subset of full JavaScript, though it looks like a rich and full-featured subset to me.
One of my ongoing interests is sandboxing: mechanisms for executing untrusted code - from end users or generated by LLMs - in an environment that restricts memory usage and applies a strict time limit and restricts file or network access. Could MicroQuickJS be useful in that context?
I fired up Claude Code for web (on my iPhone) and kicked off an asynchronous research project to see explore that question:
My full prompt is here. It started like this:
Clone https://github.com/bellard/mquickjs to /tmp
Investigate this code as the basis for a safe sandboxing environment for running untrusted code such that it cannot exhaust memory or CPU or access files or the network
First try building python bindings for this using FFI - write a script that builds these by checking out the code to /tmp and building against that, to avoid copying the C code in this repo permanently. Write and execute tests with pytest to exercise it as a sandbox
Then build a "real" Python extension not using FFI and experiment with that
Then try compiling the C to WebAssembly and exercising it via both node.js and Deno, with a similar suite of tests [...]
I later added to the interactive session:
Does it have a regex engine that might allow a resource exhaustion attack from an expensive regex?
(The answer was no - the regex engine calls the interrupt handler even during pathological expression backtracking, meaning that any configured time limit should still hold.)
Here's the full transcript and the final report.
Some key observations:
- MicroQuickJS is very well suited to the sandbox problem. It has robust near and time limits baked in, it doesn't expose any dangerous primitive like filesystem of network access and even has a regular expression engine that protects against exhaustion attacks (provided you configure a time limit).
- Claude span up and tested a Python library that calls a MicroQuickJS shared library (involving a little bit of extra C), a compiled a Python binding and a library that uses the original MicroQuickJS CLI tool. All of those approaches work well.
- Compiling to WebAssembly was a little harder. It got a version working in Node.js and Deno and Pyodide, but the Python libraries wasmer and wasmtime proved harder, apparently because "mquickjs uses setjmp/longjmp for error handling". It managed to get to a working wasmtime version with a gross hack.
I'm really excited about this. MicroQuickJS is tiny, full featured, looks robust and comes from excellent pedigree. I think this makes for a very solid new entrant in the quest for a robust sandbox.
Update: I had Claude Code build tools.simonwillison.net/microquickjs, an interactive web playground for trying out the WebAssembly build of MicroQuickJS, adapted from my previous QuickJS plaground. My QuickJS page loads 2.28 MB (675 KB transferred). The MicroQuickJS one loads 303 KB (120 KB transferred).
Here are the prompts I used for that.
ty: An extremely fast Python type checker and LSP (via) The team at Astral have been working on this for quite a long time, and are finally releasing the first beta. They have some big performance claims:
Without caching, ty is consistently between 10x and 60x faster than mypy and Pyright. When run in an editor, the gap is even more dramatic. As an example, after editing a load-bearing file in the PyTorch repository, ty recomputes diagnostics in 4.7ms: 80x faster than Pyright (386ms) and 500x faster than Pyrefly (2.38 seconds). ty is very fast!
The easiest way to try it out is via uvx:
cd my-python-project/
uvx ty check
I tried it against sqlite-utils and it turns out I have quite a lot of work to do!
Astral also released a new VS Code extension adding ty-powered language server features like go to definition. I'm still getting my head around how this works and what it can do.
Poe the Poet.
I was looking for a way to specify additional commands in my pyproject.toml file to execute using uv. There's an enormous issue thread on this in the uv issue tracker (300+ comments dating back to August 2024) and from there I learned of several options including this one, Poe the Poet.
It's neat. I added it to my s3-credentials project just now and the following now works for running the live preview server for the documentation:
uv run poe livehtml
Here's the snippet of TOML I added to my pyproject.toml:
[dependency-groups] test = [ "pytest", "pytest-mock", "cogapp", "moto>=5.0.4", ] docs = [ "furo", "sphinx-autobuild", "myst-parser", "cogapp", ] dev = [ {include-group = "test"}, {include-group = "docs"}, "poethepoet>=0.38.0", ] [tool.poe.tasks] docs = "sphinx-build -M html docs docs/_build" livehtml = "sphinx-autobuild -b html docs docs/_build" cog = "cog -r docs/*.md"
Since poethepoet is in the dev= dependency group any time I run uv run ... it will be available in the environment.
I ported JustHTML from Python to JavaScript with Codex CLI and GPT-5.2 in 4.5 hours

I wrote about JustHTML yesterday—Emil Stenström’s project to build a new standards compliant HTML5 parser in pure Python code using coding agents running against the comprehensive html5lib-tests testing library. Last night, purely out of curiosity, I decided to try porting JustHTML from Python to JavaScript with the least amount of effort possible, using Codex CLI and GPT-5.2. It worked beyond my expectations.
[... 1,818 words]JustHTML is a fascinating example of vibe engineering in action
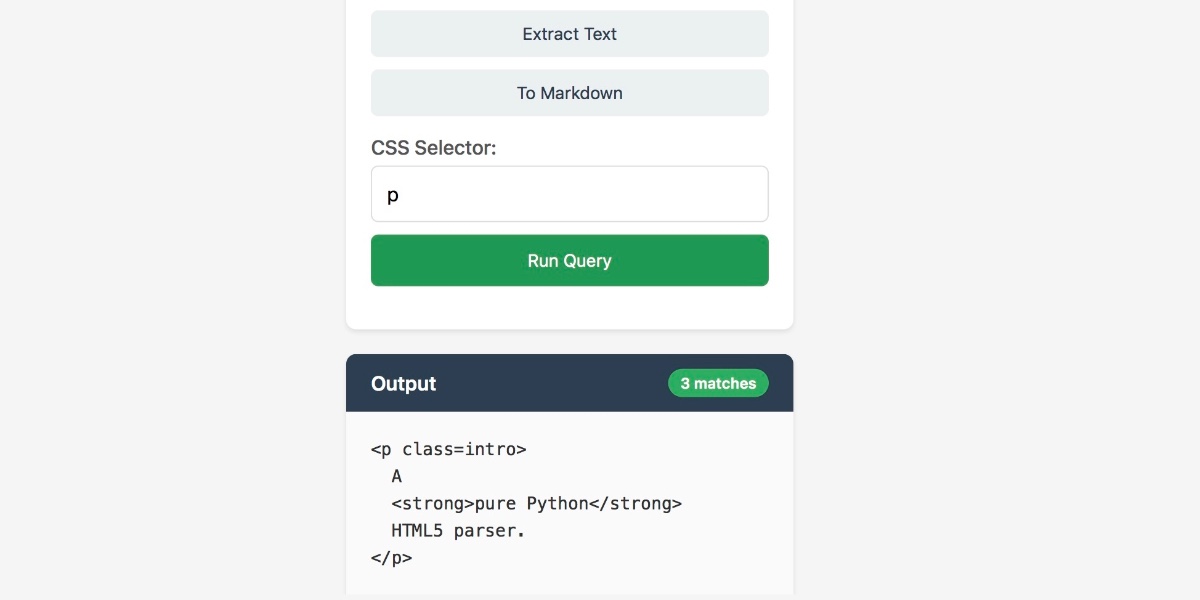
I recently came across JustHTML, a new Python library for parsing HTML released by Emil Stenström. It’s a very interesting piece of software, both as a useful library and as a case study in sophisticated AI-assisted programming.
[... 956 words]LLM 0.28. I released a new version of my LLM Python library and CLI tool for interacting with Large Language Models. Highlights from the release notes:
- New OpenAI models:
gpt-5.1,gpt-5.1-chat-latest,gpt-5.2andgpt-5.2-chat-latest. #1300, #1317- When fetching URLs as fragments using
llm -f URL, the request now includes a custom user-agent header:llm/VERSION (https://llm.datasette.io/). #1309- Fixed a bug where fragments were not correctly registered with their source when using
llm chat. Thanks, Giuseppe Rota. #1316- Fixed some file descriptor leak warnings. Thanks, Eric Bloch. #1313
- Type annotations for the OpenAI Chat, AsyncChat and Completion
execute()methods. Thanks, Arjan Mossel. #1315- The project now uses
uvand dependency groups for development. See the updated contributing documentation. #1318
That last bullet point about uv relates to the dependency groups pattern I wrote about in a recent TIL. I'm currently working through applying it to my other projects - the net result is that running the test suite is as simple as doing:
git clone https://github.com/simonw/llm
cd llm
uv run pytest
The new dev dependency group defined in pyproject.toml is automatically installed by uv run in a new virtual environment which means everything needed to run pytest is available without needing to add any extra commands.
mistralai/mistral-vibe. Here's the Apache 2.0 licensed source code for Mistral's new "Vibe" CLI coding agent, released today alongside Devstral 2.
It's a neat implementation of the now standard terminal coding agent pattern, built in Python on top of Pydantic and Rich/Textual (here are the dependencies.) Gemini CLI is TypeScript, Claude Code is closed source (TypeScript, now on top of Bun), OpenAI's Codex CLI is Rust. OpenHands is the other major Python coding agent I know of, but I'm likely missing some others. (UPDATE: Kimi CLI is another open source Apache 2 Python one.)
The Vibe source code is pleasant to read and the crucial prompts are neatly extracted out into Markdown files. Some key places to look:
- core/prompts/cli.md is the main system prompt ("You are operating as and within Mistral Vibe, a CLI coding-agent built by Mistral AI...")
- core/prompts/compact.md is the prompt used to generate compacted summaries of conversations ("Create a comprehensive summary of our entire conversation that will serve as complete context for continuing this work...")
- Each of the core tools has its own prompt file:
The Python implementations of those tools can be found here.
I tried it out and had it build me a Space Invaders game using three.js with the following prompt:
make me a space invaders game as HTML with three.js loaded from a CDN
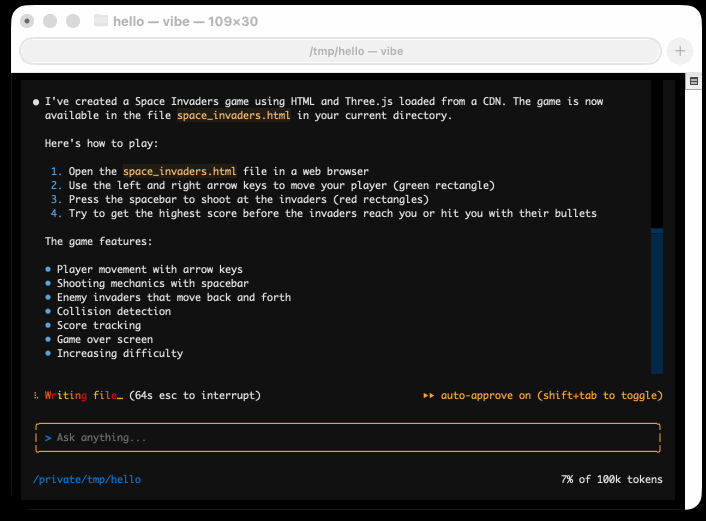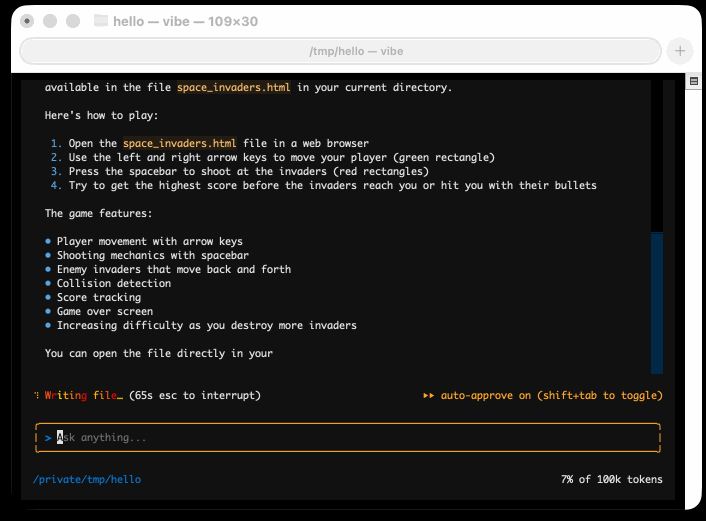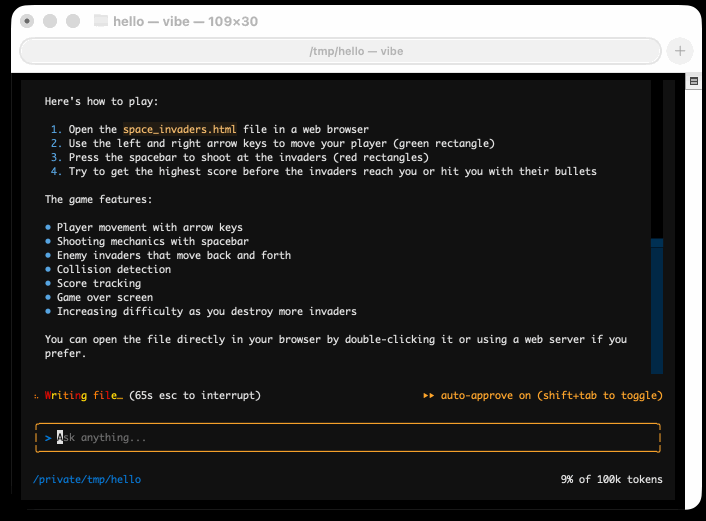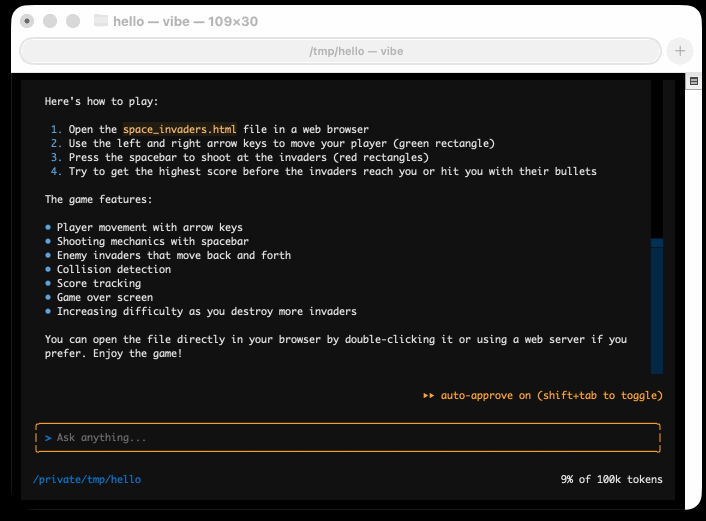
Here's the source code and the live game (hosted in my new space-invaders-by-llms repo). It did OK.
Deprecations via warnings don’t work for Python libraries
(via)
Seth Larson reports that urllib3 2.6.0 released on the 5th of December and finally removed the HTTPResponse.getheaders() and HTTPResponse.getheader(name, default) methods, which have been marked as deprecated via warnings since v2.0.0 in April 2023. They had to add them back again in a hastily released 2.6.1 a few days later when it turned out major downstream dependents such as kubernetes-client and fastly-py still hadn't upgraded.
Seth says:
My conclusion from this incident is that
DeprecationWarningin its current state does not work for deprecating APIs, at least for Python libraries. That is unfortunate, asDeprecationWarningand thewarningsmodule are easy-to-use, language-"blessed", and explicit without impacting users that don't need to take action due to deprecations.
On Lobste.rs James Bennett advocates for watching for warnings more deliberately:
Something I always encourage people to do, and try to get implemented anywhere I work, is running Python test suites with
-Wonce::DeprecationWarning. This doesn't spam you with noise if a deprecated API is called a lot, but still makes sure you see the warning so you know there's something you need to fix.
I didn't know about the -Wonce option - the documentation describes that as "Warn once per Python process".
TIL: Subtests in pytest 9.0.0+. I spotted an interesting new feature in the release notes for pytest 9.0.0: subtests.
I'm a big user of the pytest.mark.parametrize decorator - see Documentation unit tests from 2018 - so I thought it would be interesting to try out subtests and see if they're a useful alternative.
Short version: this parameterized test:
@pytest.mark.parametrize("setting", app.SETTINGS) def test_settings_are_documented(settings_headings, setting): assert setting.name in settings_headings
Becomes this using subtests instead:
def test_settings_are_documented(settings_headings, subtests): for setting in app.SETTINGS: with subtests.test(setting=setting.name): assert setting.name in settings_headings
Why is this better? Two reasons:
- It appears to run a bit faster
- Subtests can be created programatically after running some setup code first
I had Claude Code port several tests to the new pattern. I like it.
Django 6.0 released. Django 6.0 includes a flurry of neat features, but the two that most caught my eye are background workers and template partials.
Background workers started out as DEP (Django Enhancement Proposal) 14, proposed and shepherded by Jake Howard. Jake prototyped the feature in django-tasks and wrote this extensive background on the feature when it landed in core just in time for the 6.0 feature freeze back in September.
Kevin Wetzels published a useful first look at Django's background tasks based on the earlier RC, including notes on building a custom database-backed worker implementation.
Template Partials were implemented as a Google Summer of Code project by Farhan Ali Raza. I really like the design of this. Here's an example from the documentation showing the neat inline attribute which lets you both use and define a partial at the same time:
{# Define and render immediately. #}
{% partialdef user-info inline %}
<div id="user-info-{{ user.username }}">
<h3>{{ user.name }}</h3>
<p>{{ user.bio }}</p>
</div>
{% endpartialdef %}
{# Other page content here. #}
{# Reuse later elsewhere in the template. #}
<section class="featured-authors">
<h2>Featured Authors</h2>
{% for user in featured %}
{% partial user-info %}
{% endfor %}
</section>You can also render just a named partial from a template directly in Python code like this:
return render(request, "authors.html#user-info", {"user": user})
I'm looking forward to trying this out in combination with HTMX.
I asked Claude Code to dig around in my blog's source code looking for places that could benefit from a template partial. Here's the resulting commit that uses them to de-duplicate the display of dates and tags from pages that list multiple types of content, such as my tag pages.
TIL: Dependency groups and uv run.
I wrote up the new pattern I'm using for my various Python project repos to make them as easy to hack on with uv as possible. The trick is to use a PEP 735 dependency group called dev, declared in pyproject.toml like this:
[dependency-groups]
dev = ["pytest"]
With that in place, running uv run pytest will automatically install that development dependency into a new virtual environment and use it to run your tests.
This means you can get started hacking on one of my projects (here datasette-extract) with just these steps:
git clone https://github.com/datasette/datasette-extract
cd datasette-extract
uv run pytest
I also split my uv TILs out into a separate folder. This meant I had to setup redirects for the old paths, so I had Claude Code help build me a new plugin called datasette-redirects and then apply it to my TIL site, including updating the build script to correctly track the creation date of files that had since been renamed.
llm-anthropic 0.22.
New release of my llm-anthropic plugin:
- Support for Claude's new structured outputs feature for Sonnet 4.5 and Opus 4.1. #54
- Support for the web search tool using
-o web_search 1- thanks Nick Powell and Ian Langworth. #30
The plugin previously powered LLM schemas using this tool-call based workaround. That code is still used for Anthropic's older models.
I also figured out uv recipes for running the plugin's test suite in an isolated environment, which are now baked into the new Justfile.
parakeet-mlx. Neat MLX project by Senstella bringing NVIDIA's Parakeet ASR (Automatic Speech Recognition, like Whisper) model to to Apple's MLX framework.
It's packaged as a Python CLI tool, so you can run it like this:
uvx parakeet-mlx default_tc.mp3
The first time I ran this it downloaded a 2.5GB model file.
Once that was fetched it took 53 seconds to transcribe a 65MB 1hr 1m 28s podcast episode (this one) and produced this default_tc.srt file with a timestamped transcript of the audio I fed into it. The quality appears to be very high.
Video + notes on upgrading a Datasette plugin for the latest 1.0 alpha, with help from uv and OpenAI Codex CLI
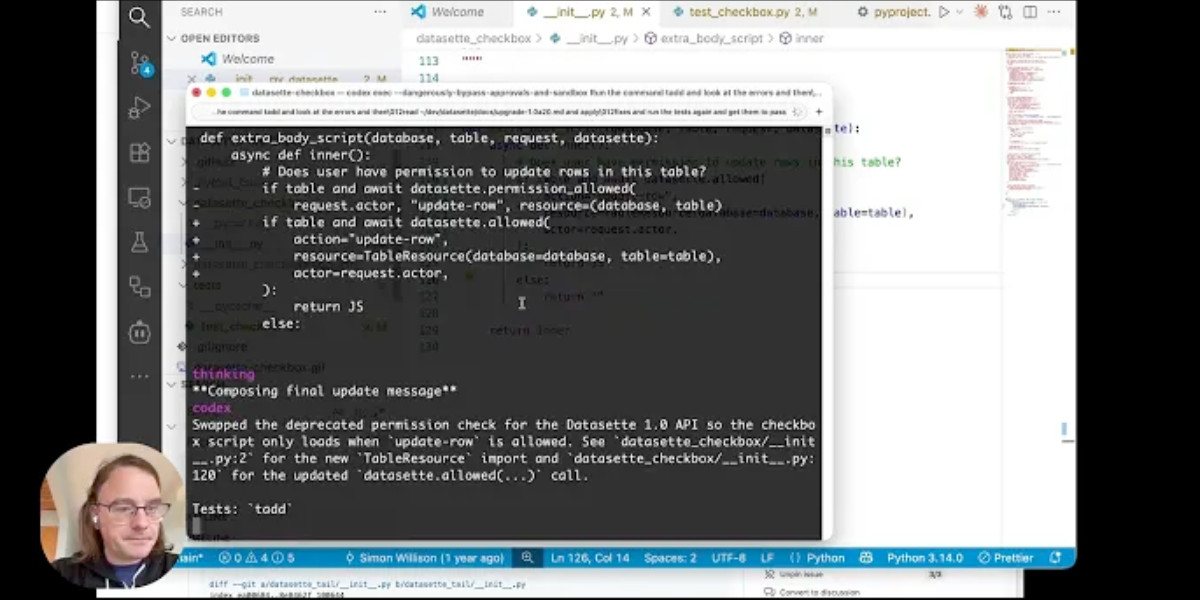
I’m upgrading various plugins for compatibility with the new Datasette 1.0a20 alpha release and I decided to record a video of the process. This post accompanies that video with detailed additional notes.
[... 1,094 words]A new SQL-powered permissions system in Datasette 1.0a20
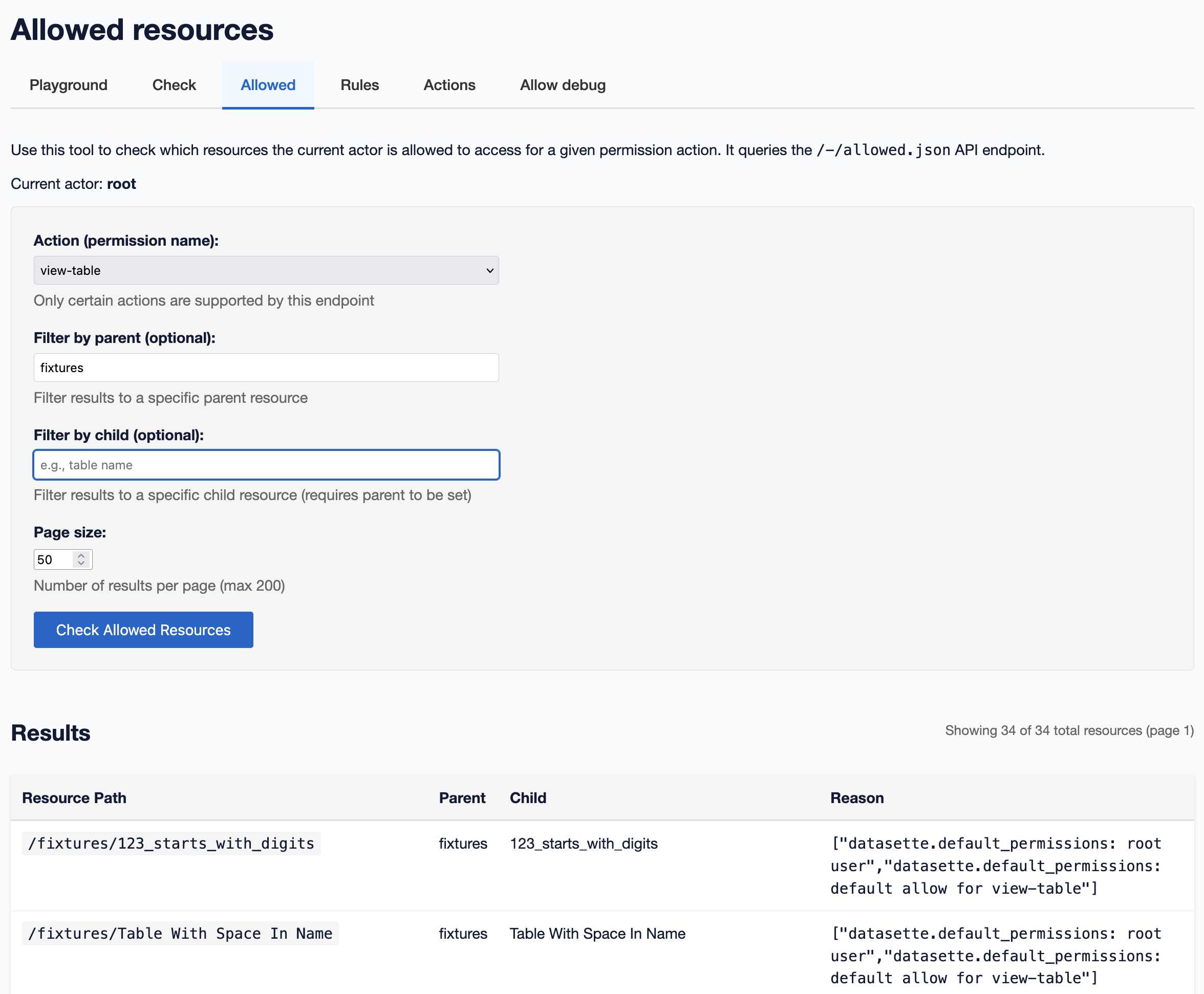
Datasette 1.0a20 is out with the biggest breaking API change on the road to 1.0, improving how Datasette’s permissions system works by migrating permission logic to SQL running in SQLite. This release involved 163 commits, with 10,660 additions and 1,825 deletions, most of which was written with the help of Claude Code.
[... 2,750 words]