2nd November 2024 - Link Blog
SmolLM2 (via) New from Loubna Ben Allal and her research team at Hugging Face:
SmolLM2 is a family of compact language models available in three size: 135M, 360M, and 1.7B parameters. They are capable of solving a wide range of tasks while being lightweight enough to run on-device. [...]
It was trained on 11 trillion tokens using a diverse dataset combination: FineWeb-Edu, DCLM, The Stack, along with new mathematics and coding datasets that we curated and will release soon.
The model weights are released under an Apache 2 license. I've been trying these out using my llm-gguf plugin for LLM and my first impressions are really positive.
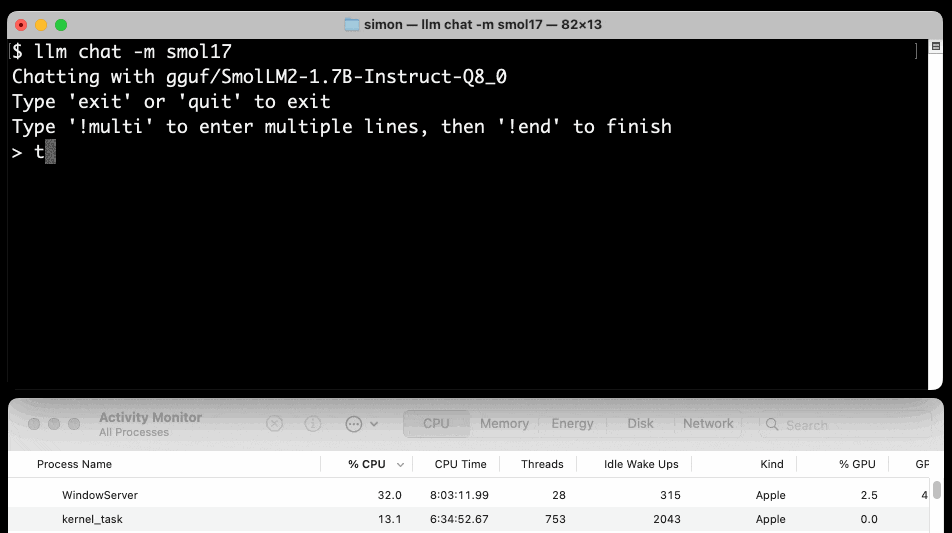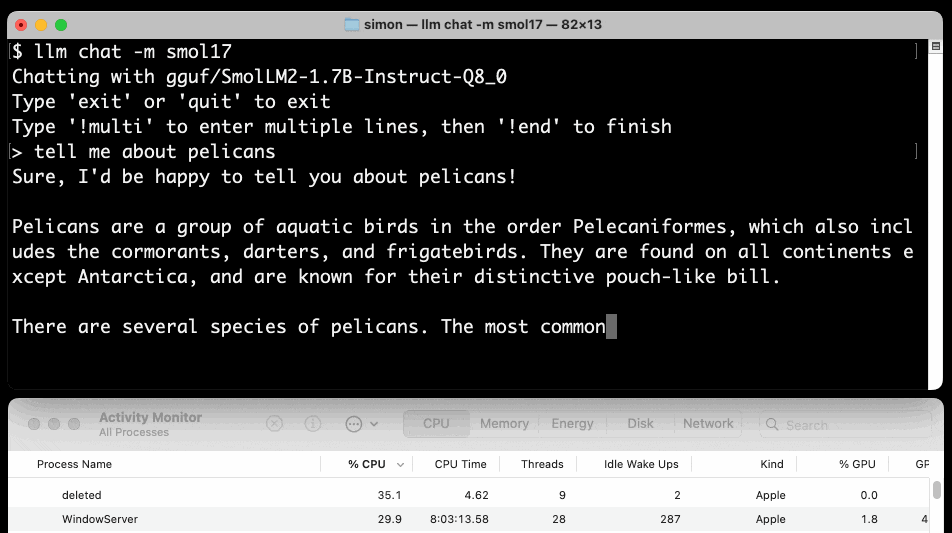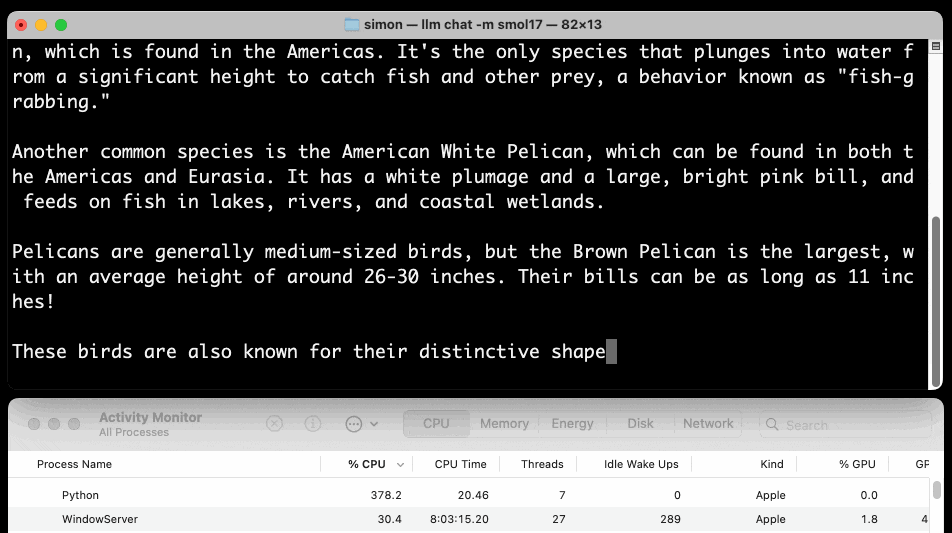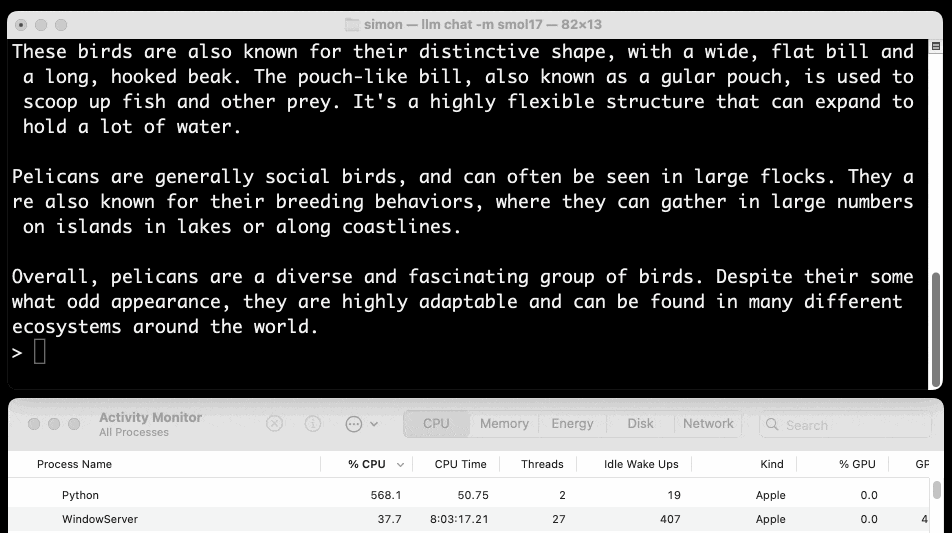
Here's a recipe to run a 1.7GB Q8 quantized model from lmstudio-community:
llm install llm-gguf
llm gguf download-model https://huggingface.co/lmstudio-community/SmolLM2-1.7B-Instruct-GGUF/resolve/main/SmolLM2-1.7B-Instruct-Q8_0.gguf -a smol17
llm chat -m smol17
Or at the other end of the scale, here's how to run the 138MB Q8 quantized 135M model:
llm gguf download-model https://huggingface.co/lmstudio-community/SmolLM2-135M-Instruct-GGUF/resolve/main/SmolLM2-135M-Instruct-Q8_0.gguf' -a smol135m
llm chat -m smol135m
The blog entry to accompany SmolLM2 should be coming soon, but in the meantime here's the entry from July introducing the first version: SmolLM - blazingly fast and remarkably powerful .