467 posts tagged “sqlite”
SQLite is the world's most widely deployed database engine.
2025
Litestream v0.5.0 is Here (via) I've been running Litestream to backup SQLite databases in production for a couple of years now without incident. The new version has been a long time coming - Ben Johnson took a detour into the FUSE-based LiteFS before deciding that the single binary Litestream approach is more popular - and Litestream 0.5 just landed with this very detailed blog posts describing the improved architecture.
SQLite stores data in pages - 4096 (by default) byte blocks of data. Litestream replicates modified pages to a backup location - usually object storage like S3.
Most SQLite tables have an auto-incrementing primary key, which is used to decide which page the row's data should be stored in. This means sequential inserts to a small table are sent to the same page, which caused previous Litestream to replicate many slightly different copies of that page block in succession.
The new LTX format - borrowed from LiteFS - addresses that by adding compaction, which Ben describes as follows:
We can use LTX compaction to compress a bunch of LTX files into a single file with no duplicated pages. And Litestream now uses this capability to create a hierarchy of compactions:
- at Level 1, we compact all the changes in a 30-second time window
- at Level 2, all the Level 1 files in a 5-minute window
- at Level 3, all the Level 2’s over an hour.
Net result: we can restore a SQLite database to any point in time, using only a dozen or so files on average.
I'm most looking forward to trying out the feature that isn't quite landed yet: read-replicas, implemented using a SQLite VFS extension:
The next major feature we’re building out is a Litestream VFS for read replicas. This will let you instantly spin up a copy of the database and immediately read pages from S3 while the rest of the database is hydrating in the background.
After struggling for years trying to figure out why people think [Cloudflare] Durable Objects are complicated, I'm increasingly convinced that it's just that they sound complicated.
Feels like we can solve 90% of it by renaming
DurableObjecttoStatefulWorker?It's just a worker that has state. And because it has state, it also has to have a name, so that you can route to the specific worker that has the state you care about. There may be a sqlite database attached, there may be a container attached. Those are just part of the state.
Serving 200 million requests per day with a cgi-bin (via) Jake Gold tests how well 90s-era CGI works today, using a Go + SQLite CGI program running on a 16-thread AMD 3700X.
Using CGI on modest hardware, it’s possible to serve 2400+ requests per second or 200M+ requests per day.
I got my start in web development with CGI back in the late 1990s - I was a huge fan of NewsPro, which was effectively a weblog system before anyone knew what a weblog was.
CGI works by starting, executing and terminating a process for every incoming request. The nascent web community quickly learned that this was a bad idea, and invented technologies like PHP and FastCGI to help avoid that extra overhead and keep code resident in-memory instead.
This lesson ended up baked into my brain, and I spent the next twenty years convinced that you should never execute a full process as part of serving a web page.
Of course, computers in those two decades got a lot faster. I finally overcame that twenty-year core belief in 2020, when I built datasette-ripgrep, a Datasette plugin that shells out to the lightning fast ripgrep CLI tool (written in Rust) to execute searches. It worked great!
As was pointed out on Hacker News, part of CGI's problem back then was that we were writing web scripts in languages like Perl, Python and Java which had not been designed for lightning fast startup speeds. Using Go and Rust today helps make CGI-style requests a whole lot more effective.
Jake notes that CGI-style request handling is actually a great way to take advantage of multiple CPU cores:
These days, we have servers with 384 CPU threads. Even a small VM can have 16 CPUs. The CPUs and memory are much faster as well.
Most importantly, CGI programs, because they run as separate processes, are excellent at taking advantage of many CPUs!
Maybe we should start coding web applications like it's 1998, albeit with Go and Rust!
To clarify, I don't think most people should do this. I just think it's interesting that it's not as bad an idea as it was ~25 years ago.
Phoenix.new is Fly’s entry into the prompt-driven app development space
Here’s a fascinating new entrant into the AI-assisted-programming / coding-agents space by Fly.io, introduced on their blog in Phoenix.new – The Remote AI Runtime for Phoenix: describe an app in a prompt, get a full Phoenix application, backed by SQLite and running on Fly’s hosting platform. The official Phoenix.new YouTube launch video is a good way to get a sense for what this does.
[... 1,361 words]TIL: SQLite triggers. I've been doing some work with SQLite triggers recently while working on sqlite-chronicle, and I decided I needed a single reference to exactly which triggers are executed for which SQLite actions and what data is available within those triggers.
I wrote this triggers.py script to output as much information about triggers as possible, then wired it into a TIL article using Cog. The Cog-powered source code for the TIL article can be seen here.
sqlite-utils 4.0a0. New alpha release of sqlite-utils, my Python library and CLI tool for manipulating SQLite databases.
It's the first 4.0 alpha because there's a (minor) backwards-incompatible change: I've upgraded the .upsert() and .upsert_all() methods to use SQLIte's UPSERT mechanism, INSERT INTO ... ON CONFLICT DO UPDATE. Details in this issue.
That feature was added to SQLite in version 3.24.0, released 2018-06-04. I'm pretty cautious about my SQLite version support since the underlying library can be difficult to upgrade, depending on your platform and operating system.
I'm going to leave the new alpha to bake for a little while before pushing a stable release. Since this is a major version bump I'm going to take the opportunity to see if there are any other minor API warts that I can clean up at the same time.
SQLite CREATE TABLE: The DEFAULT clause. If your SQLite create table statement includes a line like this:
CREATE TABLE alerts (
-- ...
alert_created_at text default current_timestamp
)
current_timestamp will be replaced with a UTC timestamp in the format 2025-05-08 22:19:33. You can also use current_time for HH:MM:SS and current_date for YYYY-MM-DD, again using UTC.
Posting this here because I hadn't previously noticed that this defaults to UTC, which is a useful detail. It's also a strong vote in favor of YYYY-MM-DD HH:MM:SS as a string format for use with SQLite, which doesn't otherwise provide a formal datetime type.
SQLite File Format Viewer (via) Neat browser-based visual interface for exploring the structure of a SQLite database file, built by Visal In using React and a custom parser implemented in TypeScript.
Stevens: a hackable AI assistant using a single SQLite table and a handful of cron jobs. Geoffrey Litt reports on Stevens, a shared digital assistant he put together for his family using SQLite and scheduled tasks running on Val Town.
The design is refreshingly simple considering how much it can do. Everything works around a single memories table. A memory has text, tags, creation metadata and an optional date for things like calendar entries and weather reports.
Everything else is handled by scheduled jobs to popular weather information and events from Google Calendar, a Telegram integration offering a chat UI and a neat system where USPS postal email delivery notifications are run through Val's own email handling mechanism to trigger a Claude prompt to add those as memories too.
Here's the full code on Val Town, including the daily briefing prompt that incorporates most of the personality of the bot.
Stop syncing everything. In which Carl Sverre announces Graft, a fascinating new open source Rust data synchronization engine he's been working on for the past year.
Carl's recent talk at the Vancouver Systems meetup explains Graft in detail, including this slide which helped everything click into place for me:

Graft manages a volume, which is a collection of pages (currently at a fixed 4KB size). A full history of that volume is maintained using snapshots. Clients can read and write from particular snapshot versions for particular pages, and are constantly updated on which of those pages have changed (while not needing to synchronize the actual changed data until they need it).
This is a great fit for B-tree databases like SQLite.
The Graft project includes a SQLite VFS extension that implements multi-leader read-write replication on top of a Graft volume. You can see a demo of that running at 36m15s in the video, or consult the libgraft extension documentation and try it yourself.
The section at the end on What can you build with Graft? has some very useful illustrative examples:
Offline-first apps: Note-taking, task management, or CRUD apps that operate partially offline. Graft takes care of syncing, allowing the application to forget the network even exists. When combined with a conflict handler, Graft can also enable multiplayer on top of arbitrary data.
Cross-platform data: Eliminate vendor lock-in and allow your users to seamlessly access their data across mobile platforms, devices, and the web. Graft is architected to be embedded anywhere
Stateless read replicas: Due to Graft's unique approach to replication, a database replica can be spun up with no local state, retrieve the latest snapshot metadata, and immediately start running queries. No need to download all the data and replay the log.
Replicate anything: Graft is just focused on consistent page replication. It doesn't care about what's inside those pages. So go crazy! Use Graft to sync AI models, Parquet or Lance files, Geospatial tilesets, or just photos of your cats. The sky's the limit with Graft.
What to do about SQLITE_BUSY errors despite setting a timeout
(via)
Bert Hubert takes on the challenge of explaining SQLite's single biggest footgun: in WAL mode you may see SQLITE_BUSY errors even when you have a generous timeout set if a transaction attempts to obtain a write lock after initially running at least one SELECT. The fix is to use BEGIN IMMEDIATE if you know your transaction is going to make a write.
Bert provides the clearest explanation I've seen yet of why this is necessary:
When the transaction on the left wanted to upgrade itself to a read-write transaction, SQLite could not allow this since the transaction on the right might already have made changes that the transaction on the left had not yet seen.
This in turn means that if left and right transactions would commit sequentially, the result would not necessarily be what would have happened if all statements had been executed sequentially within the same transaction.
I've written about this a few times before, so I just started a sqlite-busy tag to collect my notes together on a single page.
files-to-prompt 0.5.
My files-to-prompt tool (originally built using Claude 3 Opus back in April) had been accumulating a bunch of issues and PRs - I finally got around to spending some time with it and pushed a fresh release:
- New
-n/--line-numbersflag for including line numbers in the output. Thanks, Dan Clayton. #38- Fix for utf-8 handling on Windows. Thanks, David Jarman. #36
--ignorepatterns are now matched against directory names as well as file names, unless you pass the new--ignore-files-onlyflag. Thanks, Nick Powell. #30
I use this tool myself on an almost daily basis - it's fantastic for quickly answering questions about code. Recently I've been plugging it into Gemini 2.0 with its 2 million token context length, running recipes like this one:
git clone https://github.com/bytecodealliance/componentize-py
cd componentize-py
files-to-prompt . -c | llm -m gemini-2.0-pro-exp-02-05 \
-s 'How does this work? Does it include a python compiler or AST trick of some sort?'
I ran that question against the bytecodealliance/componentize-py repo - which provides a tool for turning Python code into compiled WASM - and got this really useful answer.
Here's another example. I decided to have o3-mini review how Datasette handles concurrent SQLite connections from async Python code - so I ran this:
git clone https://github.com/simonw/datasette
cd datasette/datasette
files-to-prompt database.py utils/__init__.py -c | \
llm -m o3-mini -o reasoning_effort high \
-s 'Output in markdown a detailed analysis of how this code handles the challenge of running SQLite queries from a Python asyncio application. Explain how it works in the first section, then explore the pros and cons of this design. In a final section propose alternative mechanisms that might work better.'
Here's the result. It did an extremely good job of explaining how my code works - despite being fed just the Python and none of the other documentation. Then it made some solid recommendations for potential alternatives.
I added a couple of follow-up questions (using llm -c) which resulted in a full working prototype of an alternative threadpool mechanism, plus some benchmarks.
One final example: I decided to see if there were any undocumented features in Litestream, so I checked out the repo and ran a prompt against just the .go files in that project:
git clone https://github.com/benbjohnson/litestream
cd litestream
files-to-prompt . -e go -c | llm -m o3-mini \
-s 'Write extensive user documentation for this project in markdown'
Once again, o3-mini provided a really impressively detailed set of unofficial documentation derived purely from reading the source.
sqlite-s3vfs (via) Neat open source project on the GitHub organisation for the UK government's Department for Business and Trade: a "Python virtual filesystem for SQLite to read from and write to S3."
I tried out their usage example by running it in a Python REPL with all of the dependencies
uv run --python 3.13 --with apsw --with sqlite-s3vfs --with boto3 python
It worked as advertised. When I listed my S3 bucket I found it had created two files - one called demo.sqlite/0000000000 and another called demo.sqlite/0000000001, both 4096 bytes because each one represented a SQLite page.
The implementation is just 200 lines of Python, implementing a new SQLite Virtual Filesystem on top of apsw.VFS.
The README includes this warning:
No locking is performed, so client code must ensure that writes do not overlap with other writes or reads. If multiple writes happen at the same time, the database will probably become corrupt and data be lost.
I wonder if the conditional writes feature added to S3 back in November could be used to protect against that happening. Tricky as there are multiple files involved, but maybe it (or a trick like this one) could be used to implement some kind of exclusive lock between multiple processes?
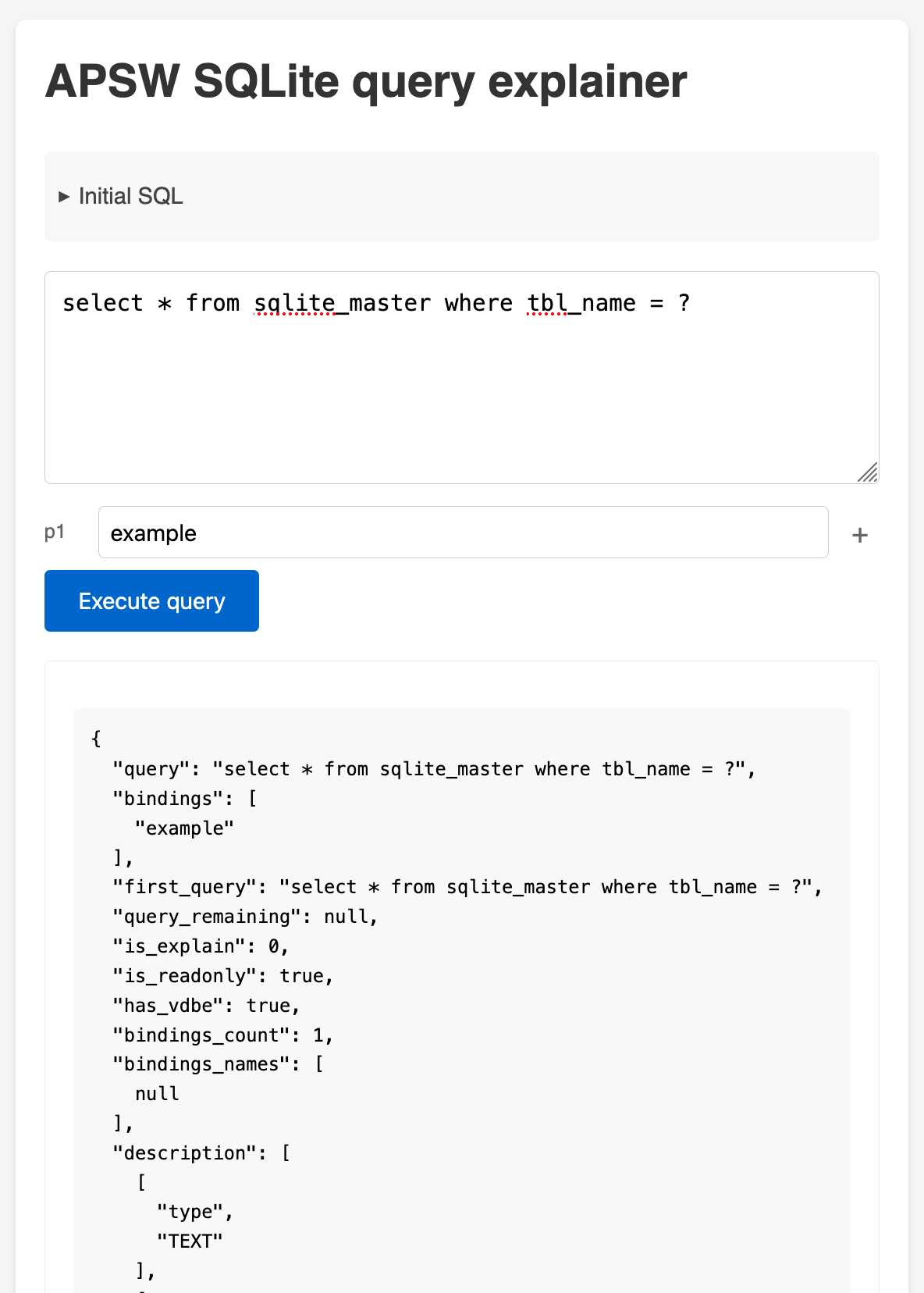
APSW SQLite query explainer. Today I found out about APSW's (Another Python SQLite Wrapper, in constant development since 2004) apsw.ext.query_info() function, which takes a SQL query and returns a very detailed set of information about that query - all without executing it.
It actually solves a bunch of problems I've wanted to address in Datasette - like taking an arbitrary query and figuring out how many parameters (?) it takes and which tables and columns are represented in the result.
I tried it out in my console (uv run --with apsw python) and it seemed to work really well. Then I remembered that the Pyodide project includes WebAssembly builds of a number of Python C extensions and was delighted to find apsw on that list.
... so I got Claude to build me a web interface for trying out the function, using Pyodide to run a user's query in Python in their browser via WebAssembly.
Claude didn't quite get it in one shot - I had to feed it the URL to a more recent Pyodide and it got stuck in a bug loop which I fixed by pasting the code into a fresh session.
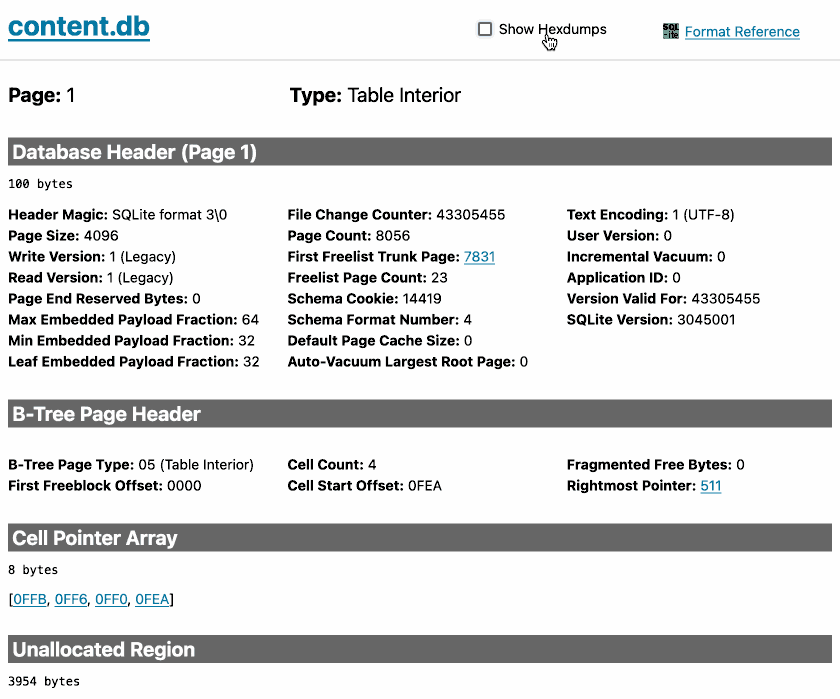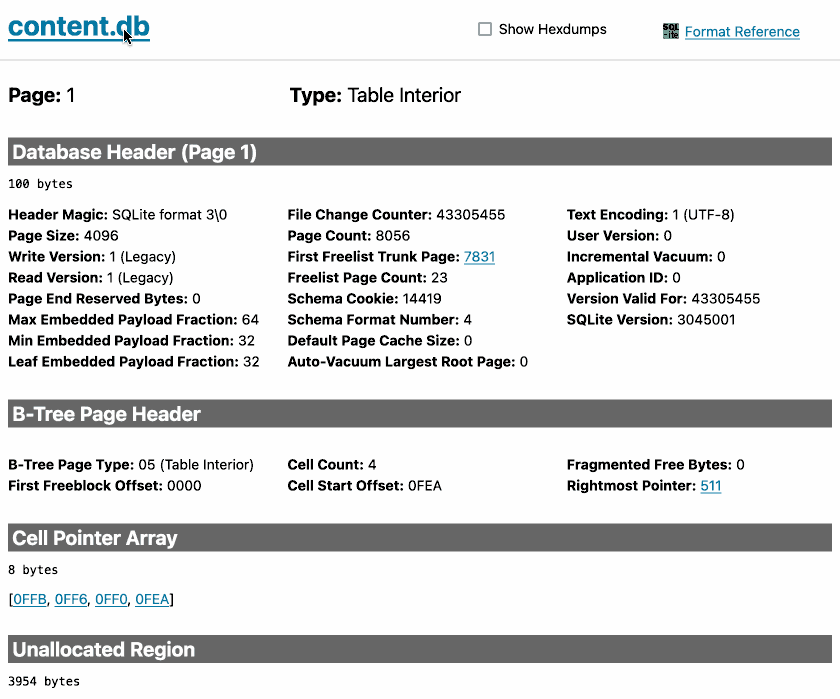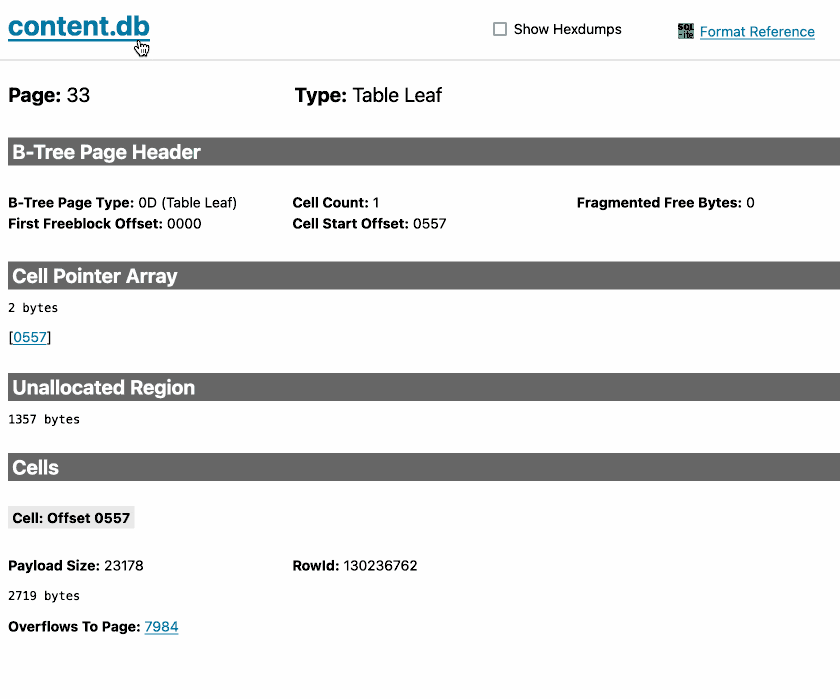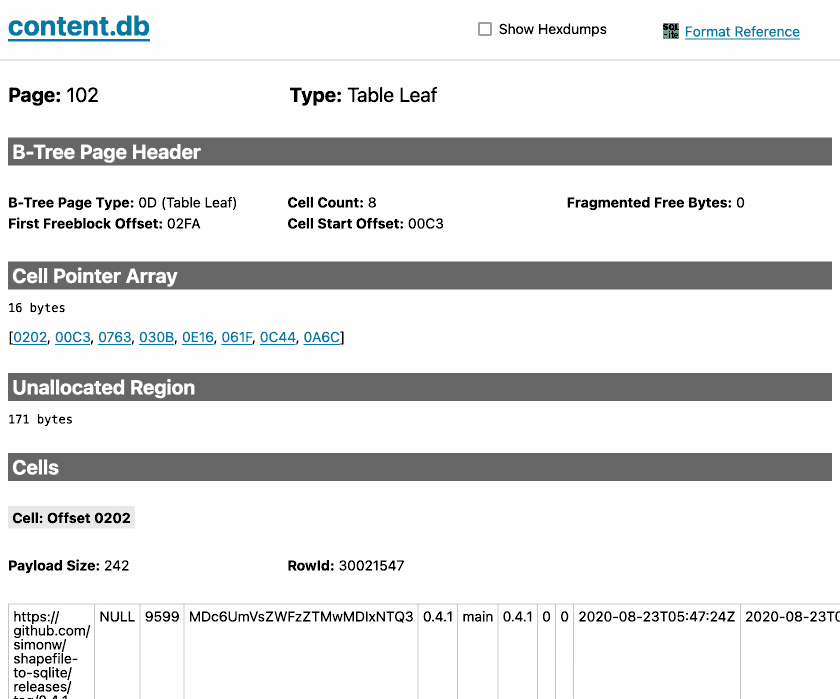
sqlite-page-explorer (via) Outstanding tool by Luke Rissacher for understanding the SQLite file format. Download the application (built using redbean and Cosmopolitan, so the same binary runs on Windows, Mac and Linux) and point it at a SQLite database to get a local web application with an interface for exploring how the file is structured.
Here's it running against the datasette.io/content database that runs the official Datasette website:
2024
Open WebUI. I tried out this open source (MIT licensed, JavaScript and Python) localhost UI for accessing LLMs today for the first time. It's very nicely done.
I ran it with uvx like this:
uvx --python 3.11 open-webui serve
On first launch it installed a bunch of dependencies and then downloaded 903MB to ~/.cache/huggingface/hub/models--sentence-transformers--all-MiniLM-L6-v2 - a copy of the all-MiniLM-L6-v2 embedding model, presumably for its RAG feature.
It then presented me with a working Llama 3.2:3b chat interface, which surprised me because I hadn't spotted it downloading that model. It turns out that was because I have Ollama running on my laptop already (with several models, including Llama 3.2:3b, already installed) - and Open WebUI automatically detected Ollama and gave me access to a list of available models.
I found a "knowledge" section and added all of the Datasette documentation (by dropping in the .rst files from the docs) - and now I can type # in chat to search for a file, add that to the context and then ask questions about it directly.
I selected the spatialite.rst.txt file, prompted it with "How do I use SpatiaLite with Datasette" and got back this:
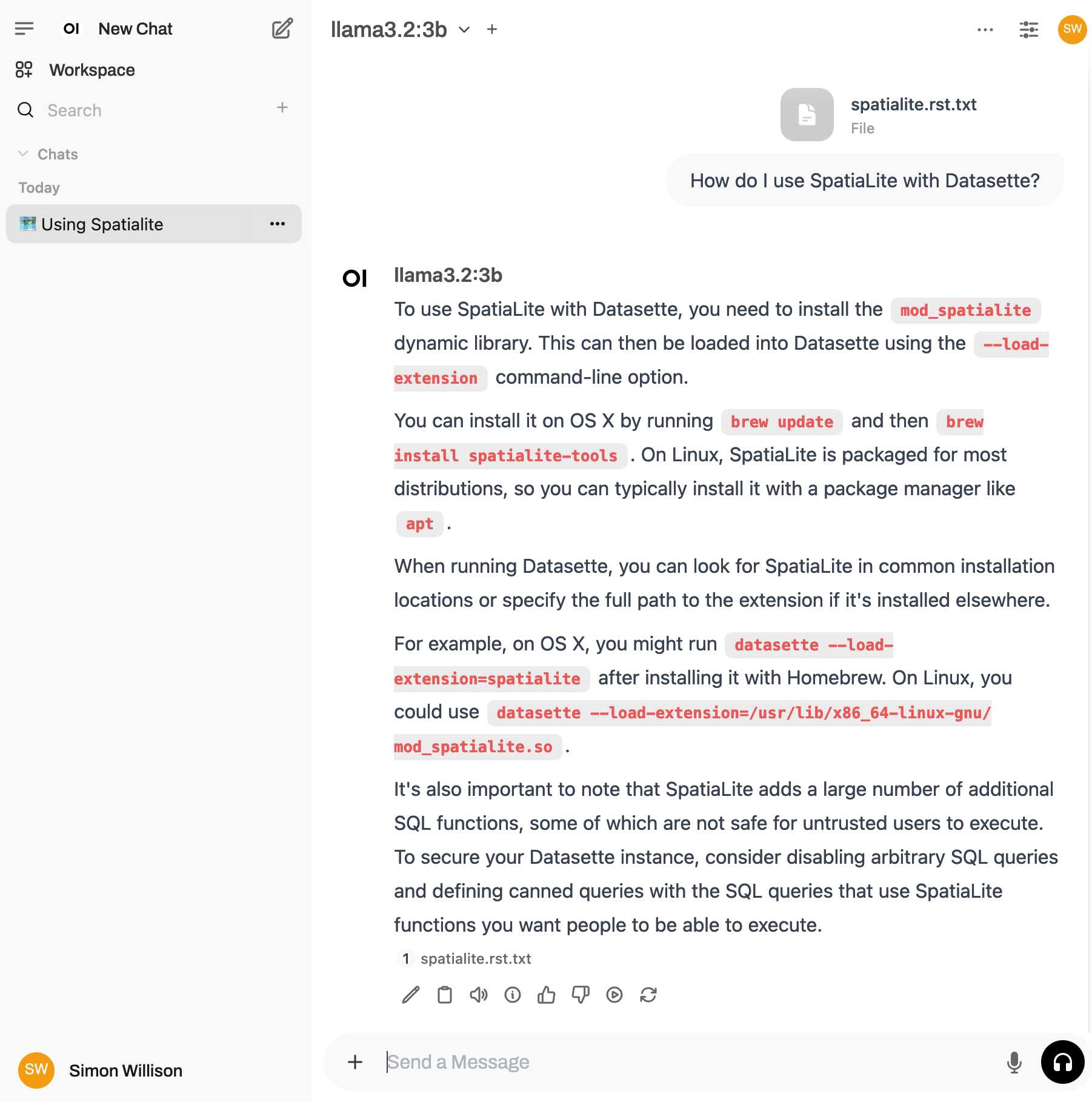
That's honestly a very solid answer, especially considering the Llama 3.2 3B model from Ollama is just a 1.9GB file! It's impressive how well that model can handle basic Q&A and summarization against text provided to it - it somehow has a 128,000 token context size.
Open WebUI has a lot of other tricks up its sleeve: it can talk to API models such as OpenAI directly, has optional integrations with web search and custom tools and logs every interaction to a SQLite database. It also comes with extensive documentation.
In search of a faster SQLite (via) Turso developer Avinash Sajjanshetty (previously) shares notes on the April 2024 paper Serverless Runtime / Database Co-Design With Asynchronous I/O by Turso founder and CTO Pekka Enberg, Jon Crowcroft, Sasu Tarkoma and Ashwin Rao.
The theme of the paper is rearchitecting SQLite for asynchronous I/O, and Avinash describes it as "the foundational paper behind Limbo, the SQLite rewrite in Rust."
From the paper abstract:
We propose rearchitecting SQLite to provide asynchronous byte-code instructions for I/O to avoid blocking in the library and de-coupling the query and storage engines to facilitate database and serverless runtime co-design. Our preliminary evaluation shows up to a 100x reduction in tail latency, suggesting that our approach is conducive to runtime/database co-design for low latency.
Introducing Limbo: A complete rewrite of SQLite in Rust (via) This looks absurdly ambitious:
Our goal is to build a reimplementation of SQLite from scratch, fully compatible at the language and file format level, with the same or higher reliability SQLite is known for, but with full memory safety and on a new, modern architecture.
The Turso team behind it have been maintaining their libSQL fork for two years now, so they're well equipped to take on a challenge of this magnitude.
SQLite is justifiably famous for its meticulous approach to testing. Limbo plans to take an entirely different approach based on "Deterministic Simulation Testing" - a modern technique pioneered by FoundationDB and now spearheaded by Antithesis, the company Turso have been working with on their previous testing projects.
Another bold claim (emphasis mine):
We have both added DST facilities to the core of the database, and partnered with Antithesis to achieve a level of reliability in the database that lives up to SQLite’s reputation.
[...] With DST, we believe we can achieve an even higher degree of robustness than SQLite, since it is easier to simulate unlikely scenarios in a simulator, test years of execution with different event orderings, and upon finding issues, reproduce them 100% reliably.
The two most interesting features that Limbo is planning to offer are first-party WASM support and fully asynchronous I/O:
SQLite itself has a synchronous interface, meaning driver authors who want asynchronous behavior need to have the extra complication of using helper threads. Because SQLite queries tend to be fast, since no network round trips are involved, a lot of those drivers just settle for a synchronous interface. [...]
Limbo is designed to be asynchronous from the ground up. It extends
sqlite3_step, the main entry point API to SQLite, to be asynchronous, allowing it to return to the caller if data is not ready to consume immediately.
Datasette provides an async API for executing SQLite queries which is backed by all manner of complex thread management - I would be very interested in a native asyncio Python library for talking to SQLite database files.
I successfully tried out Limbo's Python bindings against a demo SQLite test database using uv like this:
uv run --with pylimbo python
>>> import limbo
>>> conn = limbo.connect("/tmp/demo.db")
>>> cursor = conn.cursor()
>>> print(cursor.execute("select * from foo").fetchall())
It crashed when I tried against a more complex SQLite database that included SQLite FTS tables.
The Python bindings aren't yet documented, so I piped them through LLM and had the new google-exp-1206 model write this initial documentation for me:
files-to-prompt limbo/bindings/python -c | llm -m gemini-exp-1206 -s 'write extensive usage documentation in markdown, including realistic usage examples'
Introducing the Model Context Protocol (via) Interesting new initiative from Anthropic. The Model Context Protocol aims to provide a standard interface for LLMs to interact with other applications, allowing applications to expose tools, resources (contant that you might want to dump into your context) and parameterized prompts that can be used by the models.
Their first working version of this involves the Claude Desktop app (for macOS and Windows). You can now configure that app to run additional "servers" - processes that the app runs and then communicates with via JSON-RPC over standard input and standard output.
Each server can present a list of tools, resources and prompts to the model. The model can then make further calls to the server to request information or execute one of those tools.
(For full transparency: I got a preview of this last week, so I've had a few days to try it out.)
The best way to understand this all is to dig into the examples. There are 13 of these in the modelcontextprotocol/servers GitHub repository so far, some using the Typesscript SDK and some with the Python SDK (mcp on PyPI).
My favourite so far, unsurprisingly, is the sqlite one. This implements methods for Claude to execute read and write queries and create tables in a SQLite database file on your local computer.
This is clearly an early release: the process for enabling servers in Claude Desktop - which involves hand-editing a JSON configuration file - is pretty clunky, and currently the desktop app and running extra servers on your own machine is the only way to try this out.
The specification already describes the next step for this: an HTTP SSE protocol which will allow Claude (and any other software that implements the protocol) to communicate with external HTTP servers. Hopefully this means that MCP will come to the Claude web and mobile apps soon as well.
A couple of early preview partners have announced their MCP implementations already:
- Cody supports additional context through Anthropic's Model Context Protocol
- The Context Outside the Code is the Zed editor's announcement of their MCP extensions.
Ask questions of SQLite databases and CSV/JSON files in your terminal
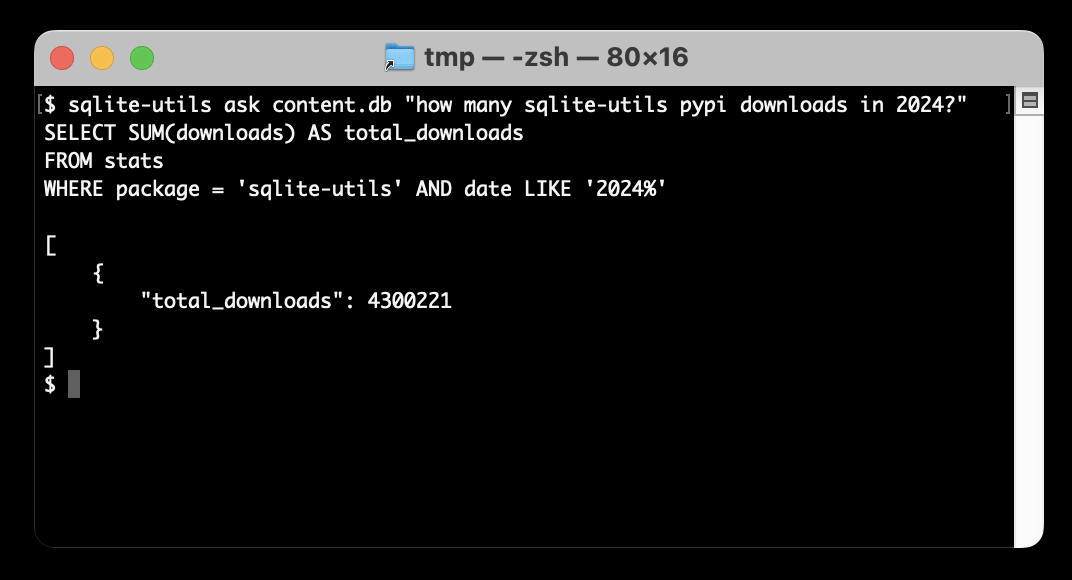
I built a new plugin for my sqlite-utils CLI tool that lets you ask human-language questions directly of SQLite databases and CSV/JSON files on your computer.
[... 723 words]Project: Civic Band—scraping and searching PDF meeting minutes from hundreds of municipalities
I interviewed Philip James about Civic Band, his “slowly growing collection of databases of the minutes from civic governments”. Philip demonstrated the site and talked through his pipeline for scraping and indexing meeting minutes from many different local government authorities around the USA.
[... 762 words]From Naptime to Big Sleep: Using Large Language Models To Catch Vulnerabilities In Real-World Code (via) Google's Project Zero security team used a system based around Gemini 1.5 Pro to find a previously unreported security vulnerability in SQLite (a stack buffer underflow), in time for it to be fixed prior to making it into a release.
A key insight here is that LLMs are well suited for checking for new variants of previously reported vulnerabilities:
A key motivating factor for Naptime and now for Big Sleep has been the continued in-the-wild discovery of exploits for variants of previously found and patched vulnerabilities. As this trend continues, it's clear that fuzzing is not succeeding at catching such variants, and that for attackers, manual variant analysis is a cost-effective approach.
We also feel that this variant-analysis task is a better fit for current LLMs than the more general open-ended vulnerability research problem. By providing a starting point – such as the details of a previously fixed vulnerability – we remove a lot of ambiguity from vulnerability research, and start from a concrete, well-founded theory: "This was a previous bug; there is probably another similar one somewhere".
LLMs are great at pattern matching. It turns out feeding in a pattern describing a prior vulnerability is a great way to identify potential new ones.
I'm of the opinion that you should never use mmap, because if you get an I/O error of some kind, the OS raises a signal, which SQLite is unable to catch, and so the process dies. When you are not using mmap, SQLite gets back an error code from an I/O error and is able to take remedial action, or at least compose an error message.
Supercharge the One Person Framework with SQLite: Rails World 2024 (via) Stephen Margheim shares an annotated transcript of the YouTube video of his recent talk at this year's Rails World conference in Toronto.
The Rails community is leaning hard into SQLite right now. Stephen's talk is some of the most effective evangelism I've seen anywhere for SQLite as a production database for web applications, highlighting several new changes in Rails 8:
... there are two additions coming with Rails 8 that merit closer consideration. Because these changes make Rails 8 the first version of Rails (and, as far as I know, the first version of any web framework) that provides a fully production-ready SQLite experience out-of-the-box.
Those changes: Ensure SQLite transaction default to IMMEDIATE mode to avoid "database is locked" errors when a deferred transaction attempts to upgrade itself with a write lock (discussed here previously, and added to Datasette 1.0a14 in August) and SQLite non-GVL-blocking, fair retry interval busy handler - a lower-level change that ensures SQLite's busy handler doesn't hold Ruby's Global VM Lock (the Ruby version of Python's GIL) while a thread is waiting on a SQLite lock.
The rest of the talk makes a passionate and convincing case for SQLite as an option for production deployments, in line with the Rails goal of being a One Person Framework - "a toolkit so powerful that it allows a single individual to create modern applications upon which they might build a competitive business".

Back in April Stephen published SQLite on Rails: The how and why of optimal performance describing some of these challenges in more detail (including the best explanation I've seen anywhere of BEGIN IMMEDIATE TRANSACTION) and promising:
Unfortunately, running SQLite on Rails out-of-the-box isn’t viable today. But, with a bit of tweaking and fine-tuning, you can ship a very performant, resilient Rails application with SQLite. And my personal goal for Rails 8 is to make the out-of-the-box experience fully production-ready.
It looks like he achieved that goal!
Zero-latency SQLite storage in every Durable Object (via) Kenton Varda introduces the next iteration of Cloudflare's Durable Object platform, which recently upgraded from a key/value store to a full relational system based on SQLite.
For useful background on the first version of Durable Objects take a look at Cloudflare's durable multiplayer moat by Paul Butler, who digs into its popularity for building WebSocket-based realtime collaborative applications.
The new SQLite-backed Durable Objects is a fascinating piece of distributed system design, which advocates for a really interesting way to architect a large scale application.
The key idea behind Durable Objects is to colocate application logic with the data it operates on. A Durable Object comprises code that executes on the same physical host as the SQLite database that it uses, resulting in blazingly fast read and write performance.
How could this work at scale?
A single object is inherently limited in throughput since it runs on a single thread of a single machine. To handle more traffic, you create more objects. This is easiest when different objects can handle different logical units of state (like different documents, different users, or different "shards" of a database), where each unit of state has low enough traffic to be handled by a single object
Kenton presents the example of a flight booking system, where each flight can map to a dedicated Durable Object with its own SQLite database - thousands of fresh databases per airline per day.
Each DO has a unique name, and Cloudflare's network then handles routing requests to that object wherever it might live on their global network.
The technical details are fascinating. Inspired by Litestream, each DO constantly streams a sequence of WAL entries to object storage - batched every 16MB or every ten seconds. This also enables point-in-time recovery for up to 30 days through replaying those logged transactions.
To ensure durability within that ten second window, writes are also forwarded to five replicas in separate nearby data centers as soon as they commit, and the write is only acknowledged once three of them have confirmed it.
The JavaScript API design is interesting too: it's blocking rather than async, because the whole point of the design is to provide fast single threaded persistence operations:
let docs = sql.exec(`
SELECT title, authorId FROM documents
ORDER BY lastModified DESC
LIMIT 100
`).toArray();
for (let doc of docs) {
doc.authorName = sql.exec(
"SELECT name FROM users WHERE id = ?",
doc.authorId).one().name;
}This one of their examples deliberately exhibits the N+1 query pattern, because that's something SQLite is uniquely well suited to handling.
The system underlying Durable Objects is called Storage Relay Service, and it's been powering Cloudflare's existing-but-different D1 SQLite system for over a year.
I was curious as to where the objects are created. According to this (via Hacker News):
Durable Objects do not currently change locations after they are created. By default, a Durable Object is instantiated in a data center close to where the initial
get()request is made. [...] To manually create Durable Objects in another location, provide an optionallocationHintparameter toget().
And in a footnote:
Dynamic relocation of existing Durable Objects is planned for the future.
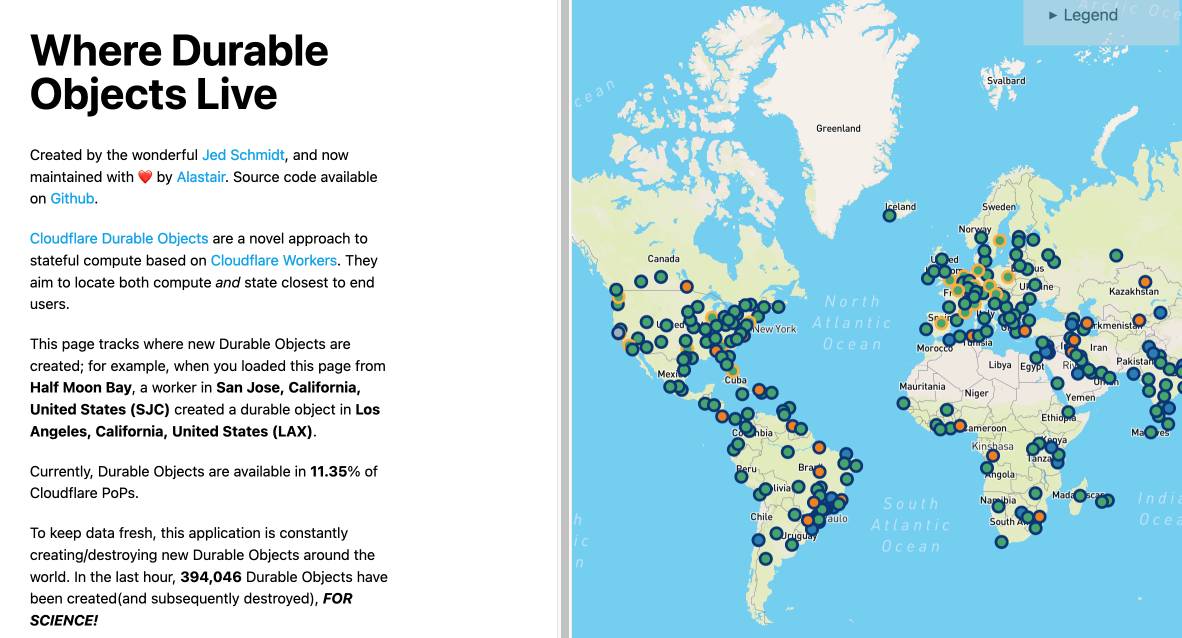
where.durableobjects.live is a neat site that tracks where in the Cloudflare network DOs are created - I just visited it and it said:
This page tracks where new Durable Objects are created; for example, when you loaded this page from Half Moon Bay, a worker in San Jose, California, United States (SJC) created a durable object in San Jose, California, United States (SJC).
PostgreSQL 17: SQL/JSON is here! (via) Hubert Lubaczewski dives into the new JSON features added in PostgreSQL 17, released a few weeks ago on the 26th of September. This is the latest in his long series of similar posts about new PostgreSQL features.
The features are based on the new SQL:2023 standard from June 2023. If you want to actually read the specification for SQL:2023 it looks like you have to buy a PDF from ISO for 194 Swiss Francs (currently $226). Here's a handy summary by Peter Eisentraut: SQL:2023 is finished: Here is what's new.
There's a lot of neat stuff in here. I'm particularly interested in the json_table() table-valued function, which can convert a JSON string into a table with quite a lot of flexibility. You can even specify a full table schema as part of the function call:
SELECT * FROM json_table(
'[{"a":10,"b":20},{"a":30,"b":40}]'::jsonb,
'$[*]'
COLUMNS (
id FOR ORDINALITY,
column_a int4 path '$.a',
column_b int4 path '$.b',
a int4,
b int4,
c text
)
);SQLite has solid JSON support already and often imitates PostgreSQL features, so I wonder if we'll see an update to SQLite that reflects some aspects of this new syntax.