467 posts tagged “sqlite”
SQLite is the world's most widely deployed database engine.
2024
otterwiki (via) It's been a while since I've seen a new-ish Wiki implementation, and this one by Ralph Thesen is really nice. It's written in Python (Flask + SQLAlchemy + mistune for Markdown + GitPython) and keeps all of the actual wiki content as Markdown files in a local Git repository.
The installation instructions are a little in-depth as they assume a production installation with Docker or systemd - I figured out this recipe for trying it locally using uv:
git clone https://github.com/redimp/otterwiki.git
cd otterwiki
mkdir -p app-data/repository
git init app-data/repository
echo "REPOSITORY='${PWD}/app-data/repository'" >> settings.cfg
echo "SQLALCHEMY_DATABASE_URI='sqlite:///${PWD}/app-data/db.sqlite'" >> settings.cfg
echo "SECRET_KEY='$(echo $RANDOM | md5sum | head -c 16)'" >> settings.cfg
export OTTERWIKI_SETTINGS=$PWD/settings.cfg
uv run --with gunicorn gunicorn --bind 127.0.0.1:8080 otterwiki.server:app
What’s New In Python 3.13. It's Python 3.13 release day today. The big signature features are a better REPL with improved error messages, an option to run Python without the GIL and the beginnings of the new JIT. Here are some of the smaller highlights I spotted while perusing the release notes.
iOS and Android are both now Tier 3 supported platforms, thanks to the efforts of Russell Keith-Magee and the Beeware project. Tier 3 means "must have a reliable buildbot" but "failures on these platforms do not block a release". This is still a really big deal for Python as a mobile development platform.
There's a whole bunch of smaller stuff relevant to SQLite.
Python's dbm module has long provided a disk-backed key-value store against multiple different backends. 3.13 introduces a new backend based on SQLite, and makes it the default.
>>> import dbm
>>> db = dbm.open("/tmp/hi", "c")
>>> db["hi"] = 1The "c" option means "Open database for reading and writing, creating it if it doesn’t exist".
After running the above, /tmp/hi was a SQLite database containing the following data:
sqlite3 /tmp/hi .dump
PRAGMA foreign_keys=OFF;
BEGIN TRANSACTION;
CREATE TABLE Dict (
key BLOB UNIQUE NOT NULL,
value BLOB NOT NULL
);
INSERT INTO Dict VALUES(X'6869',X'31');
COMMIT;
The dbm.open() function can detect which type of storage is being referenced. I found the implementation for that in the whichdb(filename) function.
I was hopeful that this change would mean Python 3.13 deployments would be guaranteed to ship with a more recent SQLite... but it turns out 3.15.2 is from November 2016 so still quite old:
SQLite 3.15.2 or newer is required to build the
sqlite3extension module. (Contributed by Erlend Aasland in gh-105875.)
The conn.iterdump() SQLite method now accepts an optional filter= keyword argument taking a LIKE pattern for the tables that you want to dump. I found the implementation for that here.
And one last change which caught my eye because I could imagine having code that might need to be updated to reflect the new behaviour:
pathlib.Path.glob()andrglob()now return both files and directories if a pattern that ends with "**" is given, rather than directories only. Add a trailing slash to keep the previous behavior and only match directories.
With the release of Python 3.13, Python 3.8 is officially end-of-life. Łukasz Langa:
If you're still a user of Python 3.8, I don't blame you, it's a lovely version. But it's time to move on to newer, greater things. Whether it's typing generics in built-in collections, pattern matching,
except*, low-impact monitoring, or a new pink REPL, I'm sure you'll find your favorite new feature in one of the versions we still support. So upgrade today!
What’s New in Ruby on Rails 8 (via)
Rails 8 takes SQLite from a lightweight development tool to a reliable choice for production use, thanks to extensive work on the SQLite adapter and Ruby driver.
With the introduction of the solid adapters discussed above, SQLite now has the capability to power Action Cable, Rails.cache, and Active Job effectively, expanding its role beyond just prototyping or testing environments. [...]
- Transactions default to
IMMEDIATEmode to improve concurrency.
Also included in Rails 8: Kamal, a new automated deployment system by 37signals for self-hosting web applications on hardware or virtual servers:
Kamal basically is Capistrano for Containers, without the need to carefully prepare servers in advance. No need to ensure that the servers have just the right version of Ruby or other dependencies you need. That all lives in the Docker image now. You can boot a brand new Ubuntu (or whatever) server, add it to the list of servers in Kamal, and it’ll be auto-provisioned with Docker, and run right away.
More from the official blog post about the release:
At 37signals, we're building a growing suite of apps that use SQLite in production with ONCE. There are now thousands of installations of both Campfire and Writebook running in the wild that all run SQLite. This has meant a lot of real-world pressure on ensuring that Rails (and Ruby) is working that wonderful file-based database as well as it can be. Through proper defaults like WAL and IMMEDIATE mode. Special thanks to Stephen Margheim for a slew of such improvements and Mike Dalessio for solving a last-minute SQLite file corruption issue in the Ruby driver.
Database Remote-Copy Tool For SQLite (draft)
(via)
Neat new SQLite utilities often show up in branches of the SQLite repository. Here's a new one from last month: sqlite3-rsync, providing tools for efficiently creating and updating copies of WAL-mode SQLite databases on either the same machine or across remote machines via SSH.
The way it works is neat, inspired by rsync (hence the tool's name):
The protocol is for the replica to send a cryptographic hash of each of its pages over to the origin side, then the origin sends back the complete content of any page for which the hash does not match.
SQLite's default page size is 4096 bytes and a hash is 20 bytes, so if nothing has changed then the client will transmit 0.5% of the database size in hashes and get nothing back in return.
The tool takes full advantage of SQLite's WAL mode - when you run it you'll get an exact snapshot of the database state as it existed at the moment the copy was initiated, even if the source database continues to apply changes.
I wrote up a TIL on how to compile it - short version:
cd /tmp
git clone https://github.com/sqlite/sqlite.git
cd sqlite
git checkout sqlite3-rsync
./configure
make sqlite3.c
cd tool
gcc -o sqlite3-rsync sqlite3-rsync.c ../sqlite3.c -DSQLITE_ENABLE_DBPAGE_VTAB
./sqlite3-rsync --help
Update: It turns out you can now just run ./configure && make sqlite_rsync in the root checkout.
Something I’ve worried about in the past is that if I want to make a snapshot backup of a SQLite database I need enough additional free disk space to entirely duplicate the current database first (using the backup mechanism or VACUUM INTO). This tool fixes that - I don’t need any extra disk space at all, since the pages that have been updated will be transmitted directly over the wire in 4096 byte chunks.
I tried feeding the 1800 lines of C through OpenAI’s o1-preview with the prompt “Explain the protocol over SSH part of this” and got a pretty great high level explanation - markdown copy here.
Hybrid full-text search and vector search with SQLite. As part of Alex’s work on his sqlite-vec SQLite extension - adding fast vector lookups to SQLite - he’s been investigating hybrid search, where search results from both vector similarity and traditional full-text search are combined together.
The most promising approach looks to be Reciprocal Rank Fusion, which combines the top ranked items from both approaches. Here’s Alex’s SQL query:
-- the sqlite-vec KNN vector search results
with vec_matches as (
select
article_id,
row_number() over (order by distance) as rank_number,
distance
from vec_articles
where
headline_embedding match lembed(:query)
and k = :k
),
-- the FTS5 search results
fts_matches as (
select
rowid,
row_number() over (order by rank) as rank_number,
rank as score
from fts_articles
where headline match :query
limit :k
),
-- combine FTS5 + vector search results with RRF
final as (
select
articles.id,
articles.headline,
vec_matches.rank_number as vec_rank,
fts_matches.rank_number as fts_rank,
-- RRF algorithm
(
coalesce(1.0 / (:rrf_k + fts_matches.rank_number), 0.0) * :weight_fts +
coalesce(1.0 / (:rrf_k + vec_matches.rank_number), 0.0) * :weight_vec
) as combined_rank,
vec_matches.distance as vec_distance,
fts_matches.score as fts_score
from fts_matches
full outer join vec_matches on vec_matches.article_id = fts_matches.rowid
join articles on articles.rowid = coalesce(fts_matches.rowid, vec_matches.article_id)
order by combined_rank desc
)
select * from final;I’ve been puzzled in the past over how to best do that because the distance scores from vector similarity and the relevance scores from FTS are meaningless in comparison to each other. RRF doesn’t even attempt to compare them - it uses them purely for row_number() ranking within each set and combines the results based on that.
django-plugin-datasette. I did some more work on my DJP plugin mechanism for Django at the DjangoCon US sprints today. I added a new plugin hook, asgi_wrapper(), released in DJP 0.3 and inspired by the similar hook in Datasette.
The hook only works for Django apps that are served using ASGI. It allows plugins to add their own wrapping ASGI middleware around the Django app itself, which means they can do things like attach entirely separate ASGI-compatible applications outside of the regular Django request/response cycle.
Datasette is one of those ASGI-compatible applications!
django-plugin-datasette uses that new hook to configure a new URL, /-/datasette/, which serves a full Datasette instance that scans through Django’s settings.DATABASES dictionary and serves an explore interface on top of any SQLite databases it finds there.
It doesn’t support authentication yet, so this will expose your entire database contents - probably best used as a local debugging tool only.
I did borrow some code from the datasette-mask-columns plugin to ensure that the password column in the auth_user column is reliably redacted. That column contains a heavily salted hashed password so exposing it isn’t necessarily a disaster, but I like to default to keeping hashes safe.
We used this model [periodically transmitting configuration to different hosts] to distribute translations, feature flags, configuration, search indexes, etc at Airbnb. But instead of SQLite we used Sparkey, a KV file format developed by Spotify. In early years there was a Cron job on every box that pulled that service’s thingies; then once we switched to Kubernetes we used a daemonset & host tagging (taints?) to pull a variety of thingies to each host and then ensure the services that use the thingies only ran on the hosts that had the thingies.
Python Developers Survey 2023 Results (via) The seventh annual Python survey is out. Here are the things that caught my eye or that I found surprising:
25% of survey respondents had been programming in Python for less than a year, and 33% had less than a year of professional experience.
37% of Python developers reported contributing to open-source projects last year - a new question for the survey. This is delightfully high!
6% of users are still using Python 2. The survey notes:
Almost half of Python 2 holdouts are under 21 years old and a third are students. Perhaps courses are still using Python 2?
In web frameworks, Flask and Django neck and neck at 33% each, but FastAPI is a close third at 29%! Starlette is at 6%, but that's an under-count because it's the basis for FastAPI.
The most popular library in "other framework and libraries" was BeautifulSoup with 31%, then Pillow 28%, then OpenCV-Python at 22% (wow!) and Pydantic at 22%. Tkinter had 17%. These numbers are all a surprise to me.
pytest scores 52% for unit testing, unittest from the standard library just 25%. I'm glad to see pytest so widely used, it's my favourite testing tool across any programming language.
The top cloud providers are AWS, then Google Cloud Platform, then Azure... but PythonAnywhere (11%) took fourth place just ahead of DigitalOcean (10%). And Alibaba Cloud is a new entrant in sixth place (after Heroku) with 4%. Heroku's ending of its free plan dropped them from 14% in 2021 to 7% now.
Linux and Windows equal at 55%, macOS is at 29%. This was one of many multiple-choice questions that could add up to more than 100%.
In databases, SQLite usage was trending down - 38% in 2021 to 34% for 2023, but still in second place behind PostgreSQL, stable at 43%.
The survey incorporates quotes from different Python experts responding to the numbers, it's worth reading through the whole thing.
My goal is to keep SQLite relevant and viable through the year 2050. That's a long time from now. If I knew that standard SQL was not going to change any between now and then, I'd go ahead and make non-standard extensions that allowed for FROM-clause-first queries, as that seems like a useful extension. The problem is that standard SQL will not remain static. Probably some future version of "standard SQL" will support some kind of FROM-clause-first query format. I need to ensure that whatever SQLite supports will be compatible with the standard, whenever it drops. And the only way to do that is to support nothing until after the standard appears.
When will that happen? A month? A year? Ten years? Who knows.
I'll probably take my cue from PostgreSQL. If PostgreSQL adds support for FROM-clause-first queries, then I'll do the same with SQLite, copying the PostgreSQL syntax. Until then, I'm afraid you are stuck with only traditional SELECT-first queries in SQLite.
System prompt for val.town/townie (via) Val Town (previously) provides hosting and a web-based coding environment for Vals - snippets of JavaScript/TypeScript that can run server-side as scripts, on a schedule or hosting a web service.
Townie is Val's new AI bot, providing a conversational chat interface for creating fullstack web apps (with blob or SQLite persistence) as Vals.
In the most recent release of Townie Val added the ability to inspect and edit its system prompt!
I've archived a copy in this Gist, as a snapshot of how Townie works today. It's surprisingly short, relying heavily on the model's existing knowledge of Deno and TypeScript.
I enjoyed the use of "tastefully" in this bit:
Tastefully add a view source link back to the user's val if there's a natural spot for it and it fits in the context of what they're building. You can generate the val source url via import.meta.url.replace("esm.town", "val.town").
The prompt includes a few code samples, like this one demonstrating how to use Val's SQLite package:
import { sqlite } from "https://esm.town/v/stevekrouse/sqlite";
let KEY = new URL(import.meta.url).pathname.split("/").at(-1);
(await sqlite.execute(`select * from ${KEY}_users where id = ?`, [1])).rows[0].idIt also reveals the existence of Val's very own delightfully simple image generation endpoint Val, currently powered by Stable Diffusion XL Lightning on fal.ai.
If you want an AI generated image, use https://maxm-imggenurl.web.val.run/the-description-of-your-image to dynamically generate one.
Here's a fun colorful raccoon with a wildly inappropriate hat.
Val are also running their own gpt-4o-mini proxy, free to users of their platform:
import { OpenAI } from "https://esm.town/v/std/openai";
const openai = new OpenAI();
const completion = await openai.chat.completions.create({
messages: [
{ role: "user", content: "Say hello in a creative way" },
],
model: "gpt-4o-mini",
max_tokens: 30,
});Val developer JP Posma wrote a lot more about Townie in How we built Townie – an app that generates fullstack apps, describing their prototyping process and revealing that the current model it's using is Claude 3.5 Sonnet.
Their current system prompt was refined over many different versions - initially they were including 50 example Vals at quite a high token cost, but they were able to reduce that down to the linked system prompt which includes condensed documentation and just one templated example.
Explain ACLs by showing me a SQLite table schema for implementing them. Here’s an example transcript showing one of the common ways I use LLMs. I wanted to develop an understanding of ACLs - Access Control Lists - but I’ve found previous explanations incredibly dry. So I prompted Claude 3.5 Sonnet:
Explain ACLs by showing me a SQLite table schema for implementing them
Asking for explanations using the context of something I’m already fluent in is usually really effective, and an great way to take advantage of the weird abilities of frontier LLMs.
I exported the transcript to a Gist using my Convert Claude JSON to Markdown tool, which I just upgraded to support syntax highlighting of code in artifacts.
Optimizing Datasette (and other weeknotes)
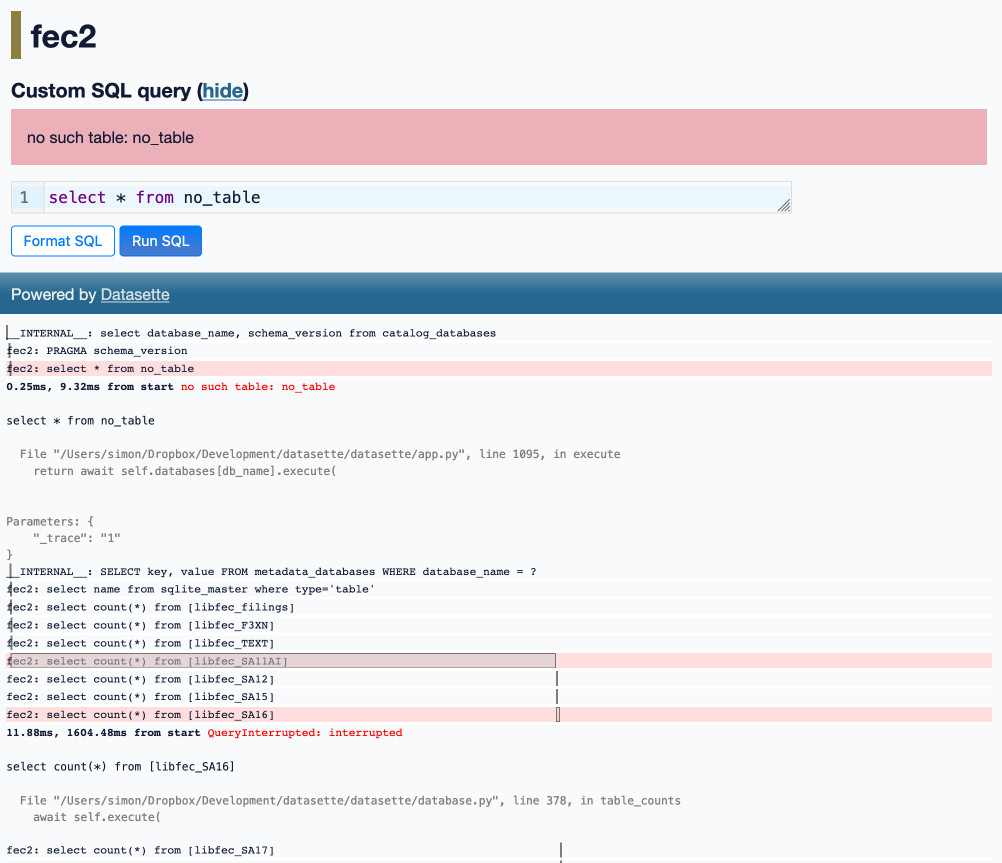
I’ve been working with Alex Garcia on an experiment involving using Datasette to explore FEC contributions. We currently have a 11GB SQLite database—trivial for SQLite to handle, but at the upper end of what I’ve comfortably explored with Datasette in the past.
[... 2,069 words]New Django {% querystring %} template tag. Django 5.1 came out last week and includes a neat new template tag which solves a problem I've faced a bunch of times in the past.
{% querystring color="red" size="S" %}
Adds ?color=red&size=S to the current URL - keeping any other existing parameters and replacing the current value for color or size if it's already set.
{% querystring color=None %}
Removes the ?color= parameter if it is currently set.
If the value passed is a list it will append ?color=red&color=blue for as many items as exist in the list.
You can access values in variables and you can also assign the result to a new template variable rather than outputting it directly to the page:
{% querystring page=page.next_page_number as next_page %}
Other things that caught my eye in Django 5.1:
- PostgreSQL connection pools.
- The new LoginRequiredMiddleware for making every page in an application require login.
- The SQLite database backend now accepts init_command for settings things like
PRAGMA cache_size=2000on new connections. - SQLite can also be passed
"transaction_mode": "IMMEDIATE"to configure the behaviour of transactions.
Using sqlite-vec with embeddings in sqlite-utils and Datasette. My notes on trying out Alex Garcia's newly released sqlite-vec SQLite extension, including how to use it with OpenAI embeddings in both Datasette and sqlite-utils.
High-precision date/time in SQLite
(via)
Another neat SQLite extension from Anton Zhiyanov. sqlean-time (C source code here) implements high-precision time and date functions for SQLite, modeled after the design used by Go.
A time is stored as a 64 bit signed integer seconds 0001-01-01 00:00:00 UTC - signed so you can represent dates in the past using a negative number - plus a 32 bit integer of nanoseconds - combined into a a 13 byte internal representation that can be stored in a BLOB column.
A duration uses a 64-bit number of nanoseconds, representing values up to roughly 290 years.
Anton includes dozens of functions for parsing, displaying, truncating, extracting fields and converting to and from Unix timestamps.
Datasette 1.0a14: The annotated release notes

Released today: Datasette 1.0a14. This alpha includes significant contributions from Alex Garcia, including some backwards-incompatible changes in the run-up to the 1.0 release.
[... 1,424 words]How to Get or Create in PostgreSQL (via) Get or create - for example to retrieve an existing tag record from a database table if it already exists or insert it if it doesn’t - is a surprisingly difficult operation.
Haki Benita uses it to illustrate a variety of interesting PostgreSQL concepts.
New to me: a pattern that runs INSERT INTO tags (name) VALUES (tag_name) RETURNING *; and then catches the constraint violation and returns a record instead has a disadvantage at scale: “The table contains a dead tuple for every attempt to insert a tag that already existed” - so until vacuum runs you can end up with significant table bloat!
Haki’s conclusion is that the best solution relies on an upcoming feature coming in PostgreSQL 17: the ability to combine the MERGE operation with a RETURNING clause:
WITH new_tags AS (
MERGE INTO tags
USING (VALUES ('B'), ('C')) AS t(name)
ON tags.name = t.name
WHEN NOT MATCHED THEN
INSERT (name) VALUES (t.name)
RETURNING *
)
SELECT * FROM tags WHERE name IN ('B', 'C')
UNION ALL
SELECT * FROM new_tags;
I wonder what the best pattern for this in SQLite is. Could it be as simple as this?
INSERT OR IGNORE INTO tags (name) VALUES ('B'), ('C');
The SQLite INSERT documentation doesn't currently provide extensive details for INSERT OR IGNORE, but there are some hints in this forum thread. This post by Rob Hoelz points out that INSERT OR IGNORE will silently ignore any constraint violation, so INSERT INTO tags (tag) VALUES ('C'), ('D') ON CONFLICT(tag) DO NOTHING may be a better option.
Introducing sqlite-lembed: A SQLite extension for generating text embeddings locally (via) Alex Garcia's latest SQLite extension is a C wrapper around the llama.cpp that exposes just its embedding support, allowing you to register a GGUF file containing an embedding model:
INSERT INTO temp.lembed_models(name, model)
select 'all-MiniLM-L6-v2',
lembed_model_from_file('all-MiniLM-L6-v2.e4ce9877.q8_0.gguf');
And then use it to calculate embeddings as part of a SQL query:
select lembed(
'all-MiniLM-L6-v2',
'The United States Postal Service is an independent agency...'
); -- X'A402...09C3' (1536 bytes)
all-MiniLM-L6-v2.e4ce9877.q8_0.gguf here is a 24MB file, so this should run quite happily even on machines without much available RAM.
What if you don't want to run the models locally at all? Alex has another new extension for that, described in Introducing sqlite-rembed: A SQLite extension for generating text embeddings from remote APIs. The rembed is for remote embeddings, and this extension uses Rust to call multiple remotely-hosted embeddings APIs, registered like this:
INSERT INTO temp.rembed_clients(name, options)
VALUES ('text-embedding-3-small', 'openai');
select rembed(
'text-embedding-3-small',
'The United States Postal Service is an independent agency...'
); -- X'A452...01FC', Blob<6144 bytes>
Here's the Rust code that implements Rust wrapper functions for HTTP JSON APIs from OpenAI, Nomic, Cohere, Jina, Mixedbread and localhost servers provided by Ollama and Llamafile.
Both of these extensions are designed to complement Alex's sqlite-vec extension, which is nearing a first stable release.
sqlite-jiff
(via)
I linked to the brand new Jiff datetime library yesterday. Alex Garcia has already used it for an experimental SQLite extension providing a timezone-aware jiff_duration() function - a useful new capability since SQLite's built in date functions don't handle timezones at all.
select jiff_duration(
'2024-11-02T01:59:59[America/Los_Angeles]',
'2024-11-02T02:00:01[America/New_York]',
'minutes'
) as result; -- returns 179.966
The implementation is 65 lines of Rust.
My architecture is a monolith written in Go (this is intentional, I sacrificed scalability to improve my shipping speed), and this is where SQLite shines. With a DB located on the local NVMe disk, a 5$ VPS can deliver a whopping 60K reads and 20K writes per second.
UK Parliament election results, now with Datasette. The House of Commons Library maintains a website of UK parliamentary election results data, currently listing 2010 through 2019 and with 2024 results coming soon.
The site itself is a Rails and PostgreSQL app, but I was delighted to learn today that they're also running a Datasette instance with the election results data, linked to from their homepage!
The raw data is also available as CSV files in their GitHub repository. Here's their Datasette configuration, which includes a copy of their SQLite database.
Optimizing Large-Scale OpenStreetMap Data with SQLite (via) JT Archie describes his project to take 9GB of compressed OpenStreetMap protobufs data for the whole of the United States and load it into a queryable SQLite database.
OSM tags are key/value pairs. The trick used here for FTS-accelerated tag queries is really neat: build a SQLite FTS table containing the key/value pairs as space concatenated text, then run queries that look like this:
SELECT
id
FROM
entries e
JOIN search s ON s.rowid = e.id
WHERE
-- use FTS index to find subset of possible results
search MATCH 'amenity cafe'
-- use the subset to find exact matches
AND tags->>'amenity' = 'cafe';
JT ended up building a custom SQLite Go extension, SQLiteZSTD, to further accelerate things by supporting queries against read-only zstd compresses SQLite files. Apparently zstd has a feature that allows "compressed data to be stored so that subranges of the data can be efficiently decompressed without requiring the entire document to be decompressed", which works well with SQLite's page format.
Optimal SQLite settings for Django
(via)
Giovanni Collazo put the work in to figure out settings to make SQLite work well for production Django workloads. WAL mode and a busy_timeout of 5000 make sense, but the most interesting recommendation here is "transaction_mode": "IMMEDIATE" to avoid locking errors when a transaction is upgraded to a write transaction.
Giovanni's configuration depends on the new "init_command" support for SQLite PRAGMA options introduced in Django 5.1alpha.
Datasette 0.64.7.
A very minor dot-fix release for Datasette stable, addressing this bug where Datasette running against the latest version of SQLite - 3.46.0 - threw an error on canned queries that included :named parameters in their SQL.
The root cause was Datasette using a now invalid clever trick I came up with against the undocumented and unstable opcodes returned by a SQLite EXPLAIN query.
I asked on the SQLite forum and learned that the feature I was using was removed in this commit to SQLite. D. Richard Hipp explains:
The P4 parameter to OP_Variable was not being used for anything. By omitting it, we make the prepared statement slightly smaller, reduce the size of the SQLite library by a few bytes, and help sqlite3_prepare() and similar run slightly faster.
My Twitter thread figuring out the AI features in Microsoft’s Recall. I posed this question on Twitter about why Microsoft Recall (previously) is being described as "AI":
Is it just that the OCR uses a machine learning model, or are there other AI components in the mix here?
I learned that Recall works by taking full desktop screenshots and then applying both OCR and some sort of CLIP-style embeddings model to their content. Both the OCRd text and the vector embeddings are stored in SQLite databases (schema here, thanks Daniel Feldman) which can then be used to search your past computer activity both by text but also by semantic vision terms - "blue dress" to find blue dresses in screenshots, for example. The si_diskann_graph table names hint at Microsoft's DiskANN vector indexing library
A Microsoft engineer confirmed on Hacker News that Recall uses on-disk vector databases to provide local semantic search for both text and images, and that they aren't using Microsoft's Phi-3 or Phi-3 Vision models. As far as I can tell there's no LLM used by the Recall system at all at the moment, just embeddings.
Stealing everything you’ve ever typed or viewed on your own Windows PC is now possible with two lines of code — inside the Copilot+ Recall disaster (via) Recall is a new feature in Windows 11 which takes a screenshot every few seconds, runs local device OCR on it and stores the resulting text in a SQLite database. This means you can search back through your previous activity, against local data that has remained on your device.
The security and privacy implications here are still enormous because malware can now target a single file with huge amounts of valuable information:
During testing this with an off the shelf infostealer, I used Microsoft Defender for Endpoint — which detected the off the shelve infostealer — but by the time the automated remediation kicked in (which took over ten minutes) my Recall data was already long gone.
I like Kevin Beaumont's argument here about the subset of users this feature is appropriate for:
At a surface level, it is great if you are a manager at a company with too much to do and too little time as you can instantly search what you were doing about a subject a month ago.
In practice, that audience’s needs are a very small (tiny, in fact) portion of Windows userbase — and frankly talking about screenshotting the things people in the real world, not executive world, is basically like punching customers in the face.
fastlite (via) New Python library from Jeremy Howard that adds some neat utility functions and syntactic sugar to my sqlite-utils Python library, specifically for interactive use in Jupyter notebooks.
The autocomplete support through newly exposed dynamic properties is particularly neat, as is the diagram(db.tables) utility for rendering a graphviz diagram showing foreign key relationships between all of the tables.
The default prefix used to be "sqlite_". But then Mcafee started using SQLite in their anti-virus product and it started putting files with the "sqlite" name in the c:/temp folder. This annoyed many windows users. Those users would then do a Google search for "sqlite", find the telephone numbers of the developers and call to wake them up at night and complain. For this reason, the default name prefix is changed to be "sqlite" spelled backwards.
— D. Richard Hipp, 18 years ago
Modern SQLite: Generated columns (via) The second in Anton Zhiyanov's series on SQLite features you might have missed.
It turns out I had an incorrect mental model of generated columns. In SQLite these can be "virtual" or "stored" (written to disk along with the rest of the table, a bit like a materialized view). Anton noted that "stored are rarely used in practice", which surprised me because I thought that storing them was necessary for them to participate in indexes.
It turns out that's not the case. Anton's example here shows a generated column providing indexed access to a value stored inside a JSON key:
create table events (
id integer primary key,
event blob,
etime text as (event ->> 'time'),
etype text as (event ->> 'type')
);
create index events_time on events(etime);
insert into events(event) values (
'{"time": "2024-05-01", "type": "credit"}'
);
Update: snej reminded me that this isn't a new capability either: SQLite has been able to create indexes on expressions for years.