Running Python micro-benchmarks using the ChatGPT Code Interpreter alpha
12th April 2023
Today I wanted to understand the performance difference between two Python implementations of a mechanism to detect changes to a SQLite database schema. I rendered the difference between the two as this chart:
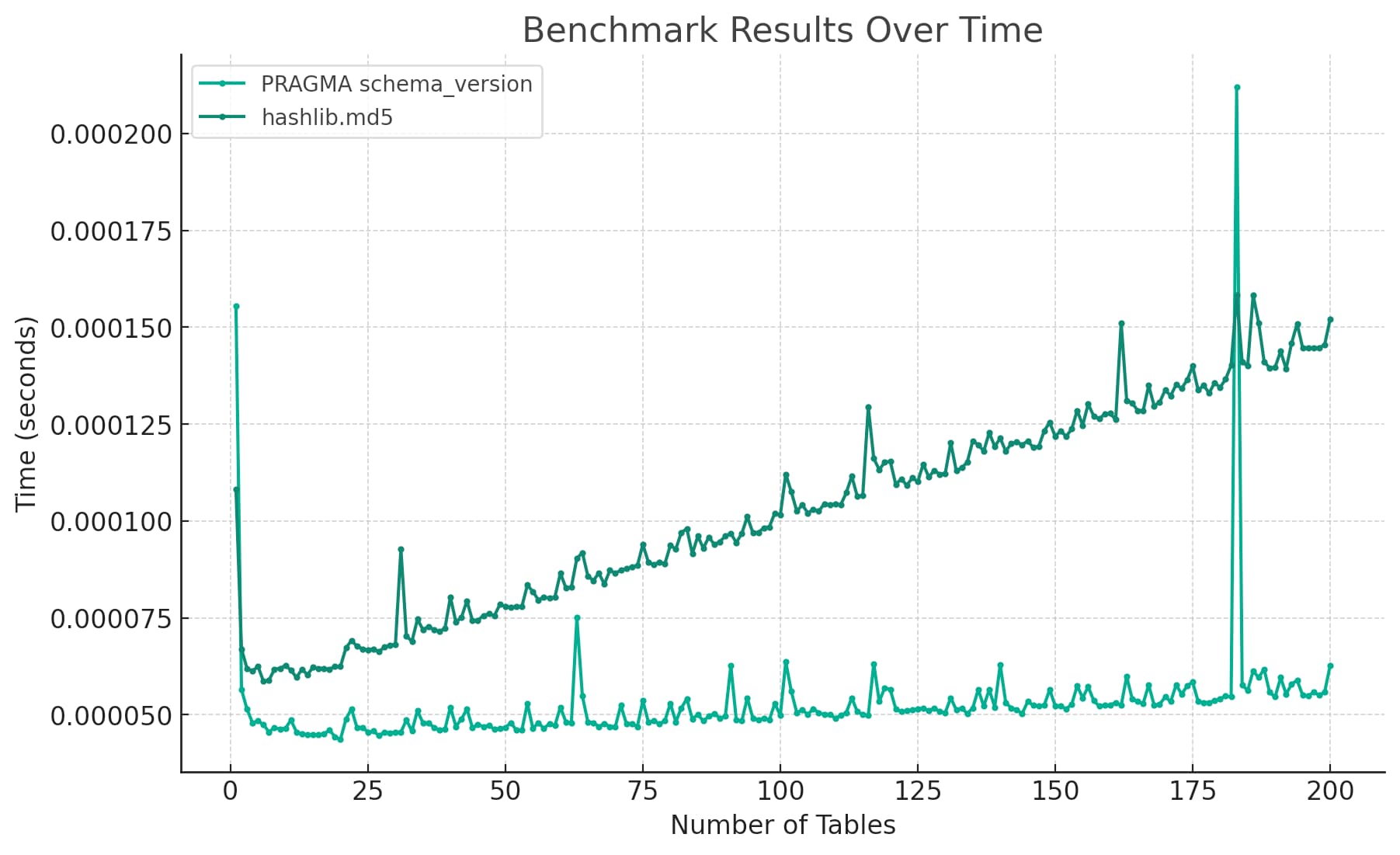
From start to finish, this entire benchmarking exercise took me less than five minutes—because ChatGPT did almost all of the work for me.
ChatGPT Code Interpreter alpha
I ran the benchmark using the new ChatGPT “Code Interpreter” alpha, which I recently gained access to, presumably due to being in the alpha for ChatGPT Plugins.
Code Interpreter mode provides ChatGPT with a single additional tool: it can now generate Python code and execute it in a restricted sandbox. The sandbox does not have network access and only has access to a set of pre-approved libraries. One of those libraries is matplotlib.pyplot, and it knows how to both render and display charts using it.
Here’s the initial prompt I sent it:
In Python create an in-memory SQLite database with 100 tables each with 10 columns.
Time how long it takes to execute
PRAGMA schema_versionagainst that database 100 times.Then add another 100 tables and time PRAGMA schema_version 100 times again.
Now run the whole benchmark a second time, but instead of
PRAGMA schema_versiontime how long it takes to run hashlib.md5(db.execute(“select group_concat(sql) from sqlite_master”).fetchall()[0]).hexdigest() instead
Background—why compare these two things?
A bit of background on this. Datasette needs to detect any time a SQLite schema changes—which could happen if a table is added or altered in some way. It needs to know so it can update its own in-memory cache of the schema, in order to (eventually) power fast table search across all known databases.
SQLite has a neat mechanism for doing this: you can run PRAGMA schema_version and it will return a number that increments every time the schema changes. This is a very fast operation.
I’m currently investigating a confounding bug where a user has reported the error message “attempt to write a readonly database” when this PRAGMA schema_version read operation is executed.
I’m still investigating, but this could mean that I need to find an alternative way of detecting changes to the schema.
One option is to calculate an MD5 hash of the full schema of the database, using the following:
schema = db.execute( "select group_concat(sql) from sqlite_master" ).fetchall()[0] hash = hashlib.md5(schema).hexdigest()
I can then compare that hash to the previous hash to see if the schema has changed.
The question I wanted to answer was how much of a performance hit this would represent—especially for databases with large number of tables.
Hence my desire to run a quick micro-benchmark.
ChatGPT’s initial benchmark
ChatGPT started by writing the following:
import sqlite3 import time import hashlib # Define a function to create tables and run benchmarks def run_benchmark(db, num_tables, num_columns, benchmark_query): # Start timing start_time = time.time() # Create tables for i in range(num_tables): columns = ', '.join([f"col{j} INTEGER" for j in range(num_columns)]) db.execute(f"CREATE TABLE table{i} ({columns})") # Benchmark for i in range(100): if benchmark_query == "PRAGMA schema_version": db.execute("PRAGMA schema_version") else: hashlib.md5(db.execute("SELECT group_concat(sql) FROM sqlite_master").fetchall()[0][0].encode()).hexdigest() # Calculate time taken elapsed_time = time.time() - start_time return elapsed_time # Initialize in-memory SQLite database db = sqlite3.connect(":memory:") # Run the first benchmark benchmark1_time1 = run_benchmark(db, num_tables=100, num_columns=10, benchmark_query="PRAGMA schema_version") benchmark1_time2 = run_benchmark(db, num_tables=100, num_columns=10, benchmark_query="PRAGMA schema_version") # Run the second benchmark db2 = sqlite3.connect(":memory:") benchmark2_time1 = run_benchmark(db2, num_tables=100, num_columns=10, benchmark_query="hashlib.md5") benchmark2_time2 = run_benchmark(db2, num_tables=100, num_columns=10, benchmark_query="hashlib.md5") benchmark1_time1, benchmark1_time2, benchmark2_time1, benchmark2_time2
This is a pretty solid attempt at a benchmark! It has good comments, abstracts the two benchmarks into a single function and runs that function twice to test against a total of 200 tables.
Then it ran the code... and this happened:
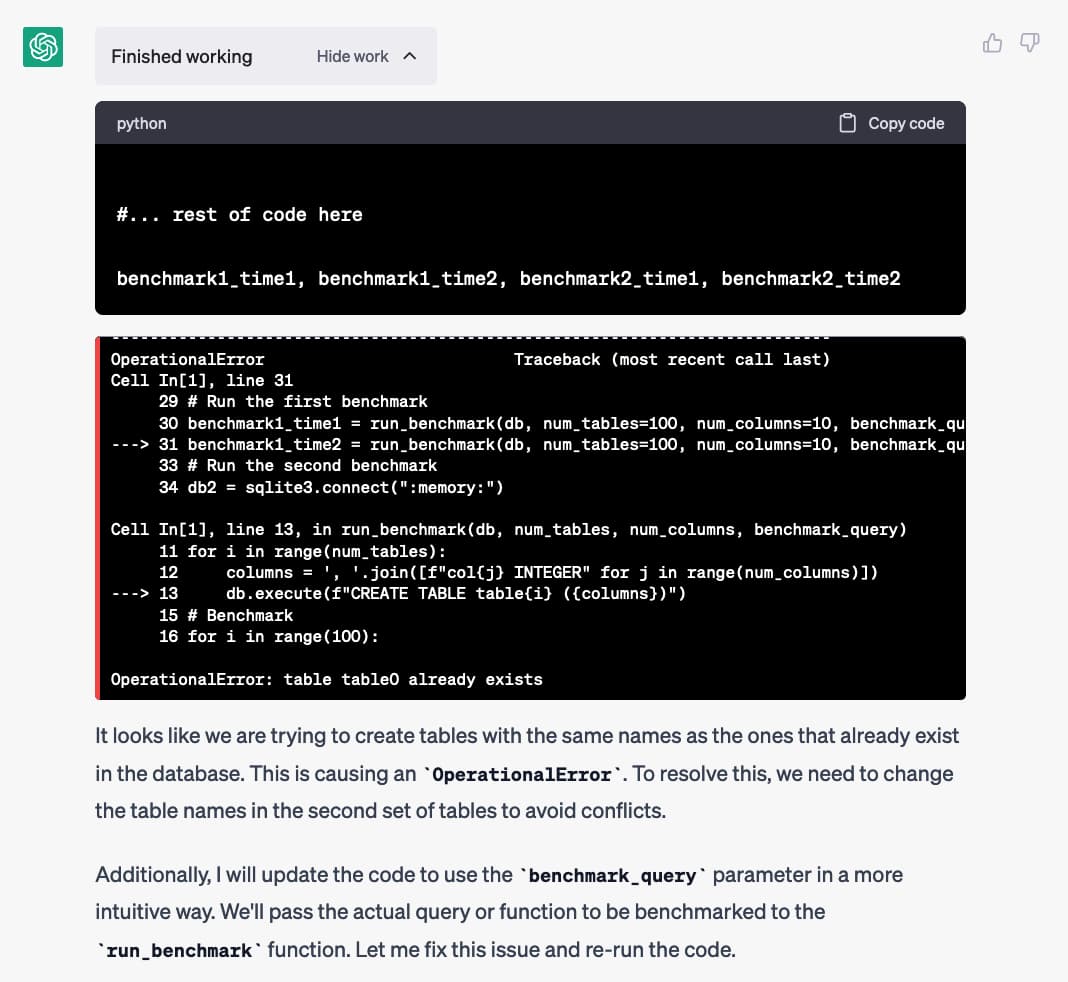
It ran the code it generated... and got a OperationalError: table table0 already exists error.
That’s because it ran that run_benchmark() function twice against the same database, and the function attempted to re-create a table it had created the first time.
But it didn’t just stop at the error... it output an explanation of what it thought would happen, and then without any input from me wrote a second version of the benchmark script:
# Define a function to create tables and run benchmarks def run_benchmark(db, num_tables, num_columns, benchmark_query, initial_table_index=0): # Start timing start_time = time.time() # Create tables for i in range(initial_table_index, initial_table_index + num_tables): columns = ', '.join([f"col{j} INTEGER" for j in range(num_columns)]) db.execute(f"CREATE TABLE table{i} ({columns})") # Benchmark for i in range(100): if benchmark_query == "PRAGMA schema_version": db.execute("PRAGMA schema_version") else: hashlib.md5(db.execute("SELECT group_concat(sql) FROM sqlite_master").fetchall()[0][0].encode()).hexdigest() # Calculate time taken elapsed_time = time.time() - start_time return elapsed_time # Initialize in-memory SQLite databases db1 = sqlite3.connect(":memory:") db2 = sqlite3.connect(":memory:") # Run the first benchmark with PRAGMA schema_version benchmark1_time1 = run_benchmark(db1, num_tables=100, num_columns=10, benchmark_query="PRAGMA schema_version") benchmark1_time2 = run_benchmark(db1, num_tables=100, num_columns=10, benchmark_query="PRAGMA schema_version", initial_table_index=100) # Run the second benchmark with hashlib.md5 benchmark2_time1 = run_benchmark(db2, num_tables=100, num_columns=10, benchmark_query="hashlib.md5") benchmark2_time2 = run_benchmark(db2, num_tables=100, num_columns=10, benchmark_query="hashlib.md5", initial_table_index=100) benchmark1_time1, benchmark1_time2, benchmark2_time1, benchmark2_time2
And this time it worked!
![RESULT: (0.008260965347290039, 0.006290912628173828, 011242151260375977, 0.014682292938232422) - Here are the results of the benchmarks: For the first benchmark using PRAGMA schema_version: The time taken to create 100 tables and run PRAGMA schema_version 100 times: approximately 0.0083 seconds. The time taken to create another 100 tables (totaling 200 tables) and run PRAGMA schema_version 100 times: approximately 0.0063 seconds. For the second benchmark using hashlib.md5: The time taken to create 100 tables and run hashlib.md5(db.execute("SELECT group_concat(sql) FROM sqlite_master").fetchall()[0]).hexdigest() 100 times: approximately 0.0112 seconds. The time taken to create another 100 tables (totaling 200 tables) and run hashlib.md5(db.execute("SELECT group_concat(sql) FROM sqlite_master").fetchall()[0]).hexdigest() 100 times: approximately 0.0147 seconds. Please note that the time taken for these benchmarks may vary slightly with each run due to factors such as system performance and other processes running on the system.](https://static.simonwillison.net/static/2023/benchmark-result.jpg)
Adding a chart
This is a very solid answer to my question. I checked it through and it mostly looks good—I would have written more-or-less the same thing, but it would have taken me a lot longer to do it.
So I asked it for a plot:
Plot those benchmark results over time on a chart
It wrote more code. ChatGPT writes and executes code in the same code session, so it had access to the variables that it had previously populated:
import matplotlib.pyplot as plt # Data for benchmark results benchmark1_times = [benchmark1_time1, benchmark1_time2] benchmark2_times = [benchmark2_time1, benchmark2_time2] # x-axis representing the number of tables at each benchmark num_tables = [100, 200] # Plotting the benchmark results plt.plot(num_tables, benchmark1_times, label='PRAGMA schema_version', marker='o') plt.plot(num_tables, benchmark2_times, label='hashlib.md5', marker='o') # Labels and title plt.xlabel('Number of Tables') plt.ylabel('Time (seconds)') plt.title('Benchmark Results Over Time') plt.legend() # Show the plot plt.show()
I’m not very good at using the matplotlib charting libraries—I have to painstakingly piece everything together every time I use them. ChatGPT just did it.
Here’s the chart it drew me:
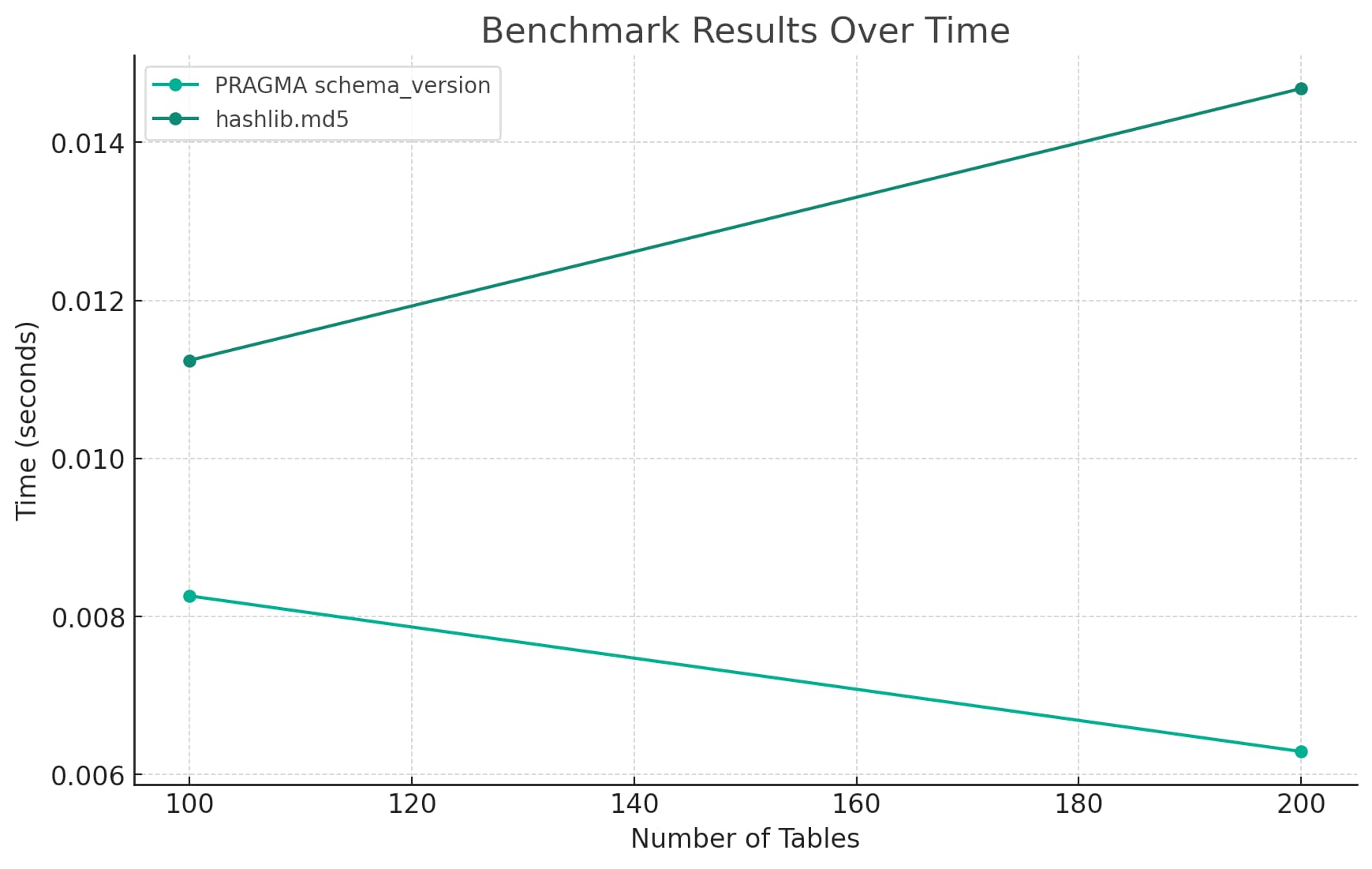
This chart looks pretty good at first glance—it has an appropriate title, axis labels and a legend.
In terms of information density though it’s rubbish. Charting just two points for each of the implementations, at 100 tables and 200 tables, is hardly worth visualizing at all.
So I fed it a final prompt:
Run the benchmark again in order to draw a better chart with measurements for every point between 1 and 200 tables
And that resulted in the chart I showed at the top of my post:
Here’s the code it wrote:
# Define a function to create tables and run a single benchmark iteration def run_single_benchmark(db, num_tables, num_columns, benchmark_query, initial_table_index=0): # Start timing start_time = time.time() # Create tables for i in range(initial_table_index, initial_table_index + num_tables): columns = ', '.join([f"col{j} INTEGER" for j in range(num_columns)]) db.execute(f"CREATE TABLE table{i} ({columns})") # Benchmark if benchmark_query == "PRAGMA schema_version": db.execute("PRAGMA schema_version") else: hashlib.md5(db.execute("SELECT group_concat(sql) FROM sqlite_master").fetchall()[0][0].encode()).hexdigest() # Calculate time taken elapsed_time = time.time() - start_time return elapsed_time # Initialize in-memory SQLite databases db1 = sqlite3.connect(":memory:") db2 = sqlite3.connect(":memory:") # Lists to store benchmark results benchmark1_times = [] benchmark2_times = [] # Run the benchmarks for every point between 1 and 200 tables for num in range(1, 201): # Run the benchmark with PRAGMA schema_version benchmark1_time = run_single_benchmark(db1, num_tables=1, num_columns=10, benchmark_query="PRAGMA schema_version", initial_table_index=num-1) benchmark1_times.append(benchmark1_time) # Run the benchmark with hashlib.md5 benchmark2_time = run_single_benchmark(db2, num_tables=1, num_columns=10, benchmark_query="hashlib.md5", initial_table_index=num-1) benchmark2_times.append(benchmark2_time) # x-axis representing the number of tables at each benchmark num_tables = list(range(1, 201)) # Plotting the benchmark results plt.plot(num_tables, benchmark1_times, label='PRAGMA schema_version', marker='.') plt.plot(num_tables, benchmark2_times, label='hashlib.md5', marker='.') # Labels and title plt.xlabel('Number of Tables') plt.ylabel('Time (seconds)') plt.title('Benchmark Results Over Time') plt.legend() # Show the plot plt.show()
Full transcript
The entire project was completed using just the three prompts listed above!
I used my Observable notebook to convert the ChatGPT transcript JSON (extracted using the Network pane in the browser tools) to Markdown, and pasted it into this Gist: https://gist.github.com/simonw/2fc46effbfbe49e6de0bcfdc9e31b235
(I like using “secret” Gists to share this kind of thing because they are automatically marked by GitHub as <meta name="robots" content="noindex">—which should hopefully prevent them from polluting the web with LLM-generated content. Though I’ve pasted a LOT of ChatGPT-written code into this search-indexed blog entry in this particular case.)
A really weird kind of intern
Here’s another analogy for large language models (since we can never have too many of those). It honestly feels a little like having a coding intern, with a strange set of characteristics:
- They’ve read and memorized all of the world’s public coding documentation, though they stopped reading in September 2021.
- They’re unbelievably fast—they take just seconds to output entire programs from scratch.
- If their code produces an error they can read the error message and attempt to update their code to fix it.
- They won’t argue with you. That’s not necessarily a good thing: if you ask them to build something that’s clearly a bad idea they’ll likely just go ahead and do it anyway.
- They respond incredibly well to feedback—they’ll apply it within seconds.
- You have to know how to prompt them. I’ve got pretty good at this now, but it takes a lot of trial and error, and I think requires a pretty deep understanding of how they work.
- You have to closely review EVERYTHING they do.
- They work for free.
And of course, they have zero understanding of anything at all. They’re a next-token-predicting machine with an unimaginably large training set.
The fact they can do even a fraction of the things they can do is, quite frankly, unbelievable. I’m still not sure I believe it myself.
Something I missed
After publishing this post, I realized that I’d missed a mistake ChatGPT had made.
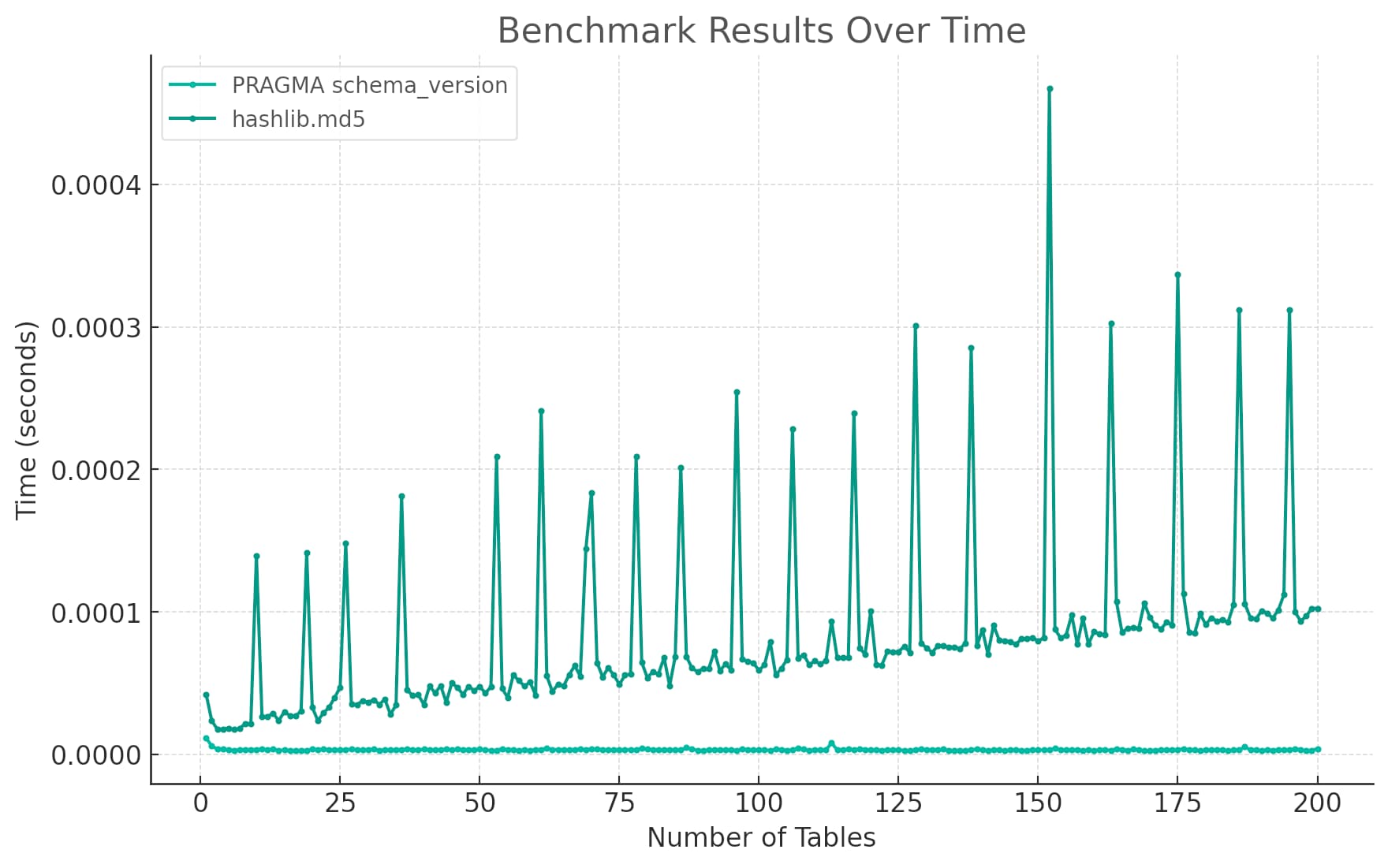
I wanted to compare the time taken to execute PRAGMA schema_version v.s. calculating the MD5 hash of select group_concat(sql) from sqlite_master. But... ChatGPT had started the timer with start_time = time.time() before creating the tables—so the time measurement included the table creation time.
This didn’t affect the comparison between the two, but it did mean that I wasn’t getting the underlying numbers that I most cared about.
Like I said earlier, You have to closely review EVERYTHING they do. I’m embarrassed I missed this!
I fixed it with one last prompt:
Record the start time after the # Benchmark comment, then re-run and re-plot
It rewrote that block of code to look like this:
# Benchmark # Start timing start_time = time.time() if benchmark_query == "PRAGMA schema_version": db.execute("PRAGMA schema_version") else: hashlib.md5(db.execute( "SELECT group_concat(sql) FROM sqlite_master" ).fetchall()[0][0].encode()).hexdigest() # Calculate time taken elapsed_time = time.time() - start_time return elapsed_time
And generated the following chart:
Better colors
A commenter on Hacker News pointed out that the two lines had colors that were too similar to each other.
Prompt:
One more chart plot, this time with colors that differ more (and are OK for people who are color blind)
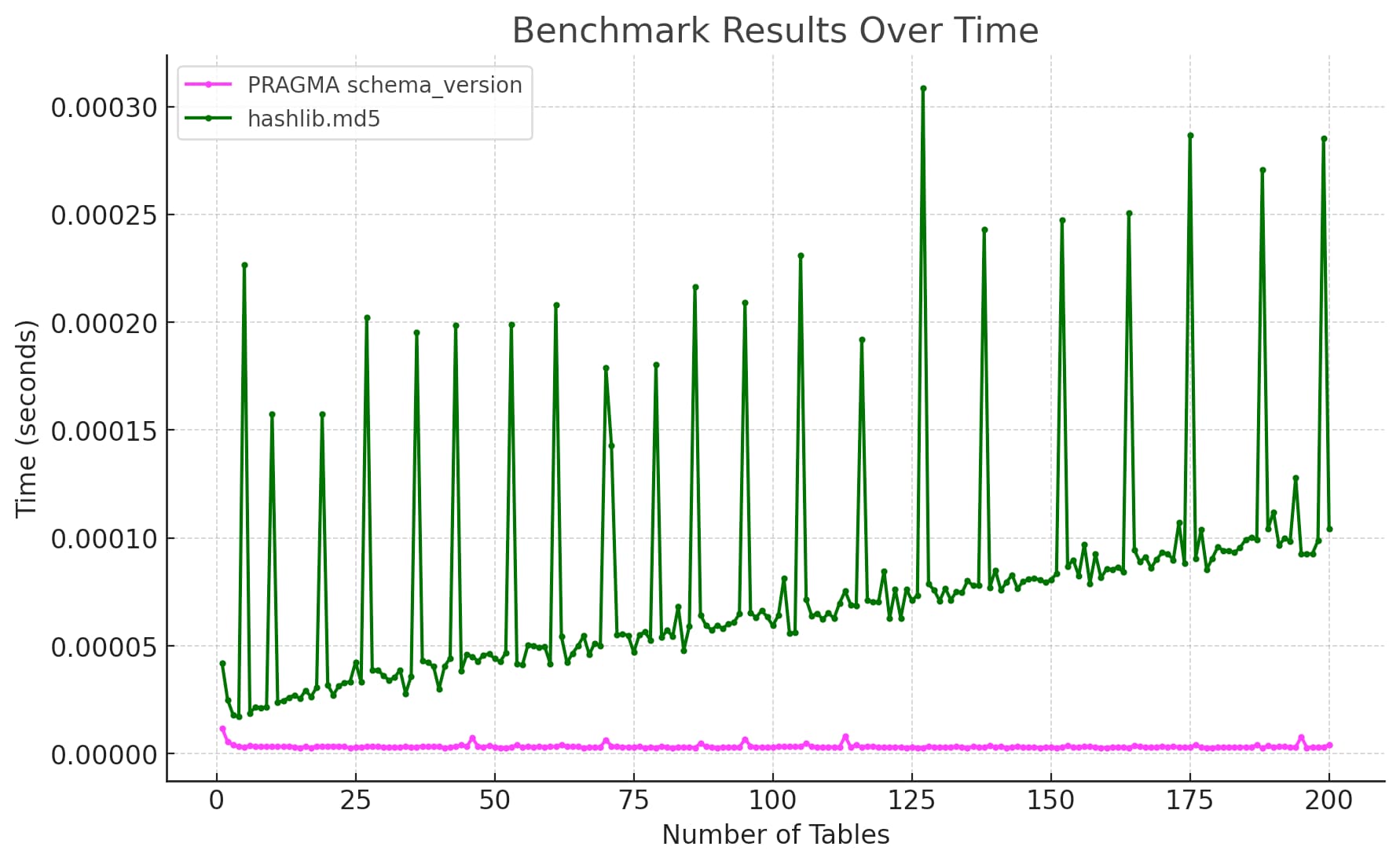
It picked magenta and dark green.
More recent articles
- OpenAI’s accidental cyberattack against Hugging Face is science fiction that happened - 22nd July 2026
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026